Imagine que es un ingeniero de robótica o aprendizaje automático (ML) encargado de desarrollar un modelo para detectar palets para que una carretilla elevadora pueda maniobrarlos. Está familiarizado con las canalizaciones tradicionales de aprendizaje profundo, ha organizado conjuntos de datos etiquetados manualmente y ha entrenado modelos exitosos.

Recomendación: use NSDT Designer para crear rápidamente escenas 3D programables.
Está listo para el próximo desafío, grandes pilas de palets densamente empaquetados. Te estarás preguntando, ¿por dónde debería empezar uno? ¿Sería más útil para esta tarea la detección de cuadros delimitadores 2D o la segmentación de instancias? ¿Debe hacerse la detección del cuadro delimitador 3D? En caso afirmativo, ¿cómo lo etiquetaría? ¿Es mejor usar cámaras monoculares, cámaras estéreo o lidar para la detección? Teniendo en cuenta la gran cantidad de palets que se producen en los escenarios de almacén natural, el etiquetado manual no es una tarea fácil. Si me equivoco, podría ser costoso.
Esto es lo que pienso cuando estoy en una situación similar. Afortunadamente, tengo una manera fácil de comenzar con una inversión relativamente baja: datos sintéticos.
1. Descripción general de los datos sintéticos
La generación de datos sintéticos (SDG: Synthetic Data Generation) es una técnica que utiliza imágenes renderizadas en lugar de imágenes reales para generar datos para entrenar redes neuronales. La ventaja de usar datos de representación sintética es que conoce implícitamente la forma y la posición completas de los objetos en la escena y puede generar anotaciones como cuadros delimitadores 2D, puntos clave, cuadros delimitadores 3D, máscaras de segmentación, etc.
Los datos sintéticos son una excelente manera de iniciar proyectos de aprendizaje profundo porque le permiten iterar ideas rápidamente antes de realizar mucho trabajo manual de etiquetado de datos, o cuando los datos son limitados, restringidos o inexistentes. Para este caso, puede encontrar que los datos sintéticos con aleatorización de dominio son un buen primer intento para su aplicación lista para usar y también ahorran tiempo.
O bien, puede encontrar que necesita redefinir la tarea o usar una modalidad de sensor diferente. Usando datos sintéticos, estas decisiones pueden probarse sin costosos esfuerzos de etiquetado.
En muchos casos, aún puede beneficiarse del uso de algunos datos del mundo real. Lo bueno es que al experimentar con datos sintéticos, se familiarizará más con el problema y podrá poner sus esfuerzos de etiquetado donde más importa. Cada tarea de aprendizaje automático tiene sus propios desafíos, por lo que puede ser difícil determinar exactamente cómo encajarán los datos sintéticos, si es necesario usar datos reales o una combinación de datos sintéticos y reales.
2. Entrene el modelo de segmentación de paletas usando datos sintéticos
Al considerar cómo usar datos sintéticos para entrenar un modelo de detección de tarimas, nuestro equipo comenzó poco a poco. Antes de pensar en la detección de cajas 3D o algo complejo, primero queremos ver si podemos detectar algo utilizando un modelo entrenado en datos sintéticos. Para hacer esto, renderizamos un conjunto de datos de escena simple que consta de solo una o dos paletas con una caja en la parte superior. Usamos estos datos para entrenar un modelo de segmentación semántica.
Elegimos entrenar un modelo de segmentación semántica porque la tarea está bien definida y la arquitectura del modelo es relativamente simple. También es posible identificar visualmente dónde falla el modelo (píxeles mal segmentados).
Para entrenar el modelo de segmentación, el equipo primero representó una escena sintética aproximada (Figura 1).

Figura 1. Representación compuesta rugosa de dos bandejas con una caja encima
El equipo sospecha que estas imágenes renderizadas por sí solas carecen de la diversidad para entrenar modelos significativos de detección de palets. También decidimos experimentar con el aumento de la representación sintética con IA generativa para producir imágenes más realistas. Antes del entrenamiento, aplicamos inteligencia artificial generativa a estas imágenes para agregar variación, lo que creemos mejorará la capacidad del modelo para generalizar al mundo real.
Esto se hace usando un modelo generativo condicional de profundidad que preserva aproximadamente la pose de los objetos en la escena renderizada. Tenga en cuenta que no se requiere IA generativa para usar los ODS. También puede experimentar con la aleatorización de dominio tradicional, como cambiar la textura, el color, la posición y la orientación de la composición de la paleta. Puede encontrar que la aleatorización de dominio tradicional al cambiar las texturas de renderizado es suficiente para su aplicación.

Figura 2. Representación compuesta mejorada con IA generativa
Después de renderizar unas 2000 imágenes sintéticas, entrenamos un modelo de segmentación de Unet basado en resnet18 mediante PyTorch. Pronto, los resultados mostraron una gran promesa en las imágenes del mundo real (Figura 3).

Figura 3. Imágenes reales de paletas probadas con modelo de segmentación
El modelo puede dividir con precisión el palet. Según este resultado, tenemos más confianza en nuestro flujo de trabajo, pero el desafío está lejos de terminar. Hasta ahora, el método del equipo no distinguía entre instancias de palés, ni detectaba palés que no estaban colocados en el suelo. Para imágenes como las que se muestran en la Figura 4, los resultados son apenas utilizables. Esto probablemente signifique que necesitamos ajustar nuestra distribución de entrenamiento.

Figura 4. El modelo de segmentación semántica no detecta palets apilados
3. Aumentar iterativamente la diversidad de datos para mejorar la precisión
Para mejorar la precisión del modelo de segmentación, el equipo agregó más imágenes de varias paletas apiladas en diferentes configuraciones aleatorias. Agregamos unas 2000 imágenes al conjunto de datos, lo que elevó el número total de imágenes a unas 4000. Creamos la escena de paletas apiladas utilizando el proyecto de código abierto USD Scene Construction Utilities.
Las utilidades de construcción de escena de USD se utilizan para posicionar paletas entre sí en una configuración que refleja la distribución que uno podría ver en el mundo real. Usamos la descripción de escena común (OpenUSD) SimReady Assets, que proporciona una variedad de modelos de paletas para elegir.

Figura 5. Se creó una escena estructurada con la API de Python de USD y la utilidad de creación de escenas de USD, se aleatorizó más y se procesó con Omniverse Replicator
Al entrenar con bandejas apiladas y una gama más amplia de vistas, pudimos mejorar la precisión del modelo en estas situaciones.
Si agregar estos datos ayuda al modelo, ¿por qué solo generar 2000 imágenes sin aumentar el costo de etiquetado? No comenzamos con muchas imágenes porque tomamos muestras de la misma distribución sintética. Agregar más imágenes no necesariamente agrega mucha diversidad a nuestro conjunto de datos. En cambio, podríamos agregar muchas imágenes similares sin mejorar la precisión del modelo en el mundo real.
Comenzando poco a poco, el equipo pudo entrenar rápidamente el modelo, ver dónde estaba fallando, ajustar la canalización de los ODS y agregar más datos. Por ejemplo, después de notar que el modelo estaba sesgado hacia colores y formas específicos de paletas, agregamos más datos sintéticos para abordar estos casos de falla.

Figura 6. Representaciones de tarimas de plástico en varios colores.
Estos cambios de datos mejoraron la capacidad del modelo para manejar los escenarios de falla encontrados (paletas de plástico y de colores).
Si los datos cambian bien, ¿por qué no hacer todo lo posible y agregar muchos cambios a la vez? Fue difícil juzgar qué diferencias podrían ser necesarias hasta que nuestro equipo comenzó a realizar pruebas con datos reales. Es posible que nos falte un factor importante necesario para que el modelo funcione bien. O bien, podemos sobreestimar la importancia de otros factores, agotando nuestros esfuerzos innecesariamente. Al iterar, tenemos una mejor idea de qué datos necesitan las tareas.
4. Detección del centro del lateral del palet
Una vez que tengamos algunos resultados prometedores sobre la segmentación, el siguiente paso es adaptar la tarea de la segmentación semántica a algo más práctico. Decidimos que la siguiente tarea de evaluación más sencilla era detectar el centro de los lados del palet.

Figura 7. Datos de ejemplo para la tarea de detección del centro del lado del palé
El punto central del lado del palé es donde el montacargas se centrará al maniobrar el palé. Si bien, en la práctica, es posible que se necesite más información para manipular el palet (como la distancia y el ángulo en este punto), vemos esto como un siguiente paso fácil en el proceso, lo que permite al equipo evaluar nuestros datos para cualquier aplicación posterior. Qué tan útil es el programa es.
La detección de estos puntos se puede hacer con la regresión del mapa de calor, que al igual que la segmentación, se hace en el dominio de la imagen, que es fácil de implementar y fácil de interpretar de forma intuitiva. Al entrenar un modelo para esta tarea, podemos evaluar rápidamente la utilidad de nuestro conjunto de datos sintéticos para entrenar un modelo para detectar puntos clave operativos importantes.
Los resultados después del entrenamiento son prometedores, como se muestra en la Figura 8.

Figura 8. Resultados de detección reales del modelo de detección del lado del palé
El equipo confirmó la capacidad de utilizar datos sintéticos para detectar los lados de los palés, incluso los que están apilados muy juntos. Continuamos iterando en los datos, el modelo y la canalización de capacitación para mejorar el modelo para esta tarea.
5. Detección de esquinas
Cuando estuvimos satisfechos con el modelo de detección lateral central, exploramos llevar la tarea a un nuevo nivel: detectar esquinas de cajas. El enfoque original era usar un mapa de calor para cada esquina, similar al enfoque para el centro del costado de la bandeja.
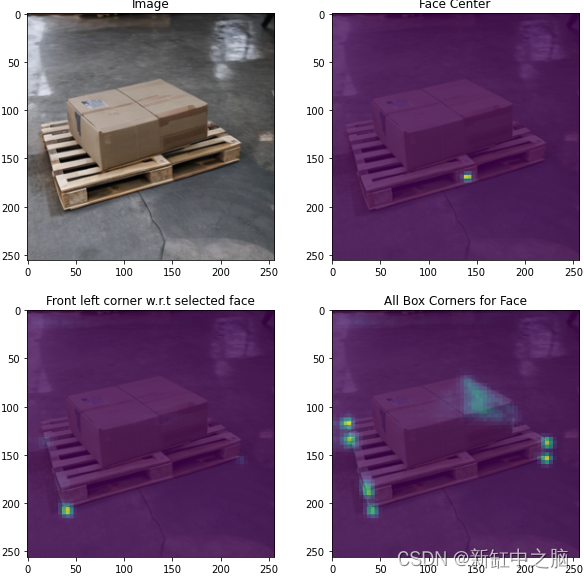
Figura 9. Modelo de detección de esquinas de paletas usando mapa de calor
Sin embargo, este enfoque rápidamente presentó desafíos. Dado que se desconocen las dimensiones de los objetos detectados, es difícil para el modelo inferir exactamente dónde deben estar las esquinas del palet si no son directamente visibles. Con los mapas de calor, si los picos son inconsistentes, puede ser difícil resolverlos de manera confiable.
Por lo tanto, en lugar de usar un mapa de calor, optamos por retroceder en las posiciones de las esquinas después de detectar un pico en el centro de la cara. Entrenamos un modelo para inferir un campo vectorial que contiene las compensaciones de los puntos de las esquinas en relación con el centro de una cara de palet determinada. Este enfoque rápidamente se mostró prometedor para esta tarea y pudimos proporcionar estimaciones significativas de las posiciones diagonales incluso con oclusiones grandes.

Figura 10. Resultados de la detección de tarimas mediante el mapa de calor del centro de la cara y la regresión de las esquinas según el campo vectorial
Ahora que el equipo tenía un flujo de trabajo prometedor, lo iteramos y lo ampliamos para abordar los diferentes casos de falla que surgieron. En total, nuestro modelo final se entrenó en aproximadamente 25 000 imágenes renderizadas. Nuestro modelo se entrenó a una resolución relativamente baja (256 x 256 píxeles) y pudo detectar paletas pequeñas ejecutando inferencias a una resolución más alta. Finalmente, podemos detectar escenas desafiantes como la anterior con una precisión relativamente alta.
Aquí hay algo que podemos usar, todo creado con datos sintéticos. Aquí es donde se encuentra hoy nuestro modelo de detección de palés.

Figura 11. Los resultados finales de la detección del modelo de paleta, para facilitar la visualización, solo se muestra la parte frontal de la detección

Figura 12. Modelo de detección de palets ejecutándose en tiempo real
6. Construye tus propios modelos con datos sintéticos
A través del desarrollo iterativo utilizando datos sintéticos, nuestro equipo desarrolló un modelo de detección de tarimas que funciona con imágenes reales. Con más iteraciones, puede ser posible un mayor progreso. Más allá de eso, nuestra tarea podría beneficiarse al agregar datos del mundo real. Sin embargo, sin la generación de datos sintéticos, no podemos iterar rápidamente porque cada cambio que hacemos requiere un nuevo trabajo de etiquetado.
Si está interesado en probar este modelo o está desarrollando una aplicación que pueda usar el modelo de detección de palets, puede encontrar el modelo y el código de inferencia visitando SDG Pallet Model en GitHub. Este repositorio incluye modelos ONNX previamente entrenados e instrucciones para usar TensorRT para optimizar los modelos y ejecutar inferencias en imágenes. El modelo puede ejecutarse en tiempo real en NVIDIA Jetson AGX Orin, por lo que podrá ejecutarlo en dispositivos periféricos.
También puede consultar el reciente proyecto de código abierto USD Scene Construction Utilities, que contiene ejemplos y utilidades para crear escenas USD utilizando la API Python de USD.
Esperamos que nuestra experiencia lo inspire a explorar cómo se pueden usar los datos sintéticos para guiar sus aplicaciones de IA. Si desea comenzar a generar datos sintéticos, NVIDIA proporciona un conjunto de herramientas para simplificar el proceso. Éstas incluyen:
- Descripción de escena universal (OpenUSD): USD se describe como el HTML del metaverso, que es un marco para describir completamente el mundo 3D. USD no solo contiene primitivas como mallas de objetos 3D, sino que también tiene la capacidad de describir materiales, iluminación, cámaras, física y más.
- NVIDIA Omniverse Replicator: Replicator es una extensión central de la plataforma NVIDIA Omniverse que permite a los desarrolladores generar datos de entrenamiento sintéticos grandes y diversos para guiar el entrenamiento del modelo de percepción. Con funciones como una API fácil de usar, aleatorización de dominios y simulación multisensor, Replicator resuelve desafíos de escasez de datos y acelera el proceso de entrenamiento del modelo.
- Activos de SimReady: los activos de SimReady son objetos 3D físicamente precisos que contienen propiedades físicas precisas, comportamiento y flujo de datos conectados para representar el mundo real dentro de un mundo digital simulado. NVIDIA proporciona una colección de activos y materiales realistas que se pueden usar de inmediato para crear escenas en 3D. Esto incluye diversos activos relacionados con la logística del almacén, como tarimas, carros y cajas de cartón. Para buscar, mostrar, inspeccionar y configurar los activos de SimReady antes de agregarlos a una etapa activa, puede usar la extensión SimReady Explorer. Cada recurso de SimReady tiene sus propias etiquetas semánticas predefinidas, lo que facilita la generación de datos etiquetados para segmentación o modelos de detección de objetos.
Si tiene preguntas sobre los modelos de palets, la generación de datos sintéticos de NVIDIA Omniverse o la inferencia de NVIDIA Jetson, visite GitHub o visite el foro de desarrolladores de generación de datos sintéticos de NVIDIA Omniverse y el foro de desarrolladores de NVIDIA Jetson Orin Nano.
Enlace original: Detección de paletas basada en datos sintéticos—BimAnt