prefacio
Antes de estudiar este capítulo, asegúrese de hacer los siguientes preparativos:
1. Instale e inicie Zookeeper [ sitio web oficial ] , si necesita ayuda, haga clic para ingresar ;
2. Instalé e inicié Kafka [ sitio web oficial ] , si necesita ayuda, haga clic para ingresar .
Nota: La instalación e introducción de zk y kafka, este artículo no se centra en la introducción, consulte el enlace anterior para obtener más detalles.
_ _ _
1. Preparación
1.1 Crear un nuevo proyecto web Spring Boot 2.x
1.1.1 Demostración de los pasos de creación de proyectos
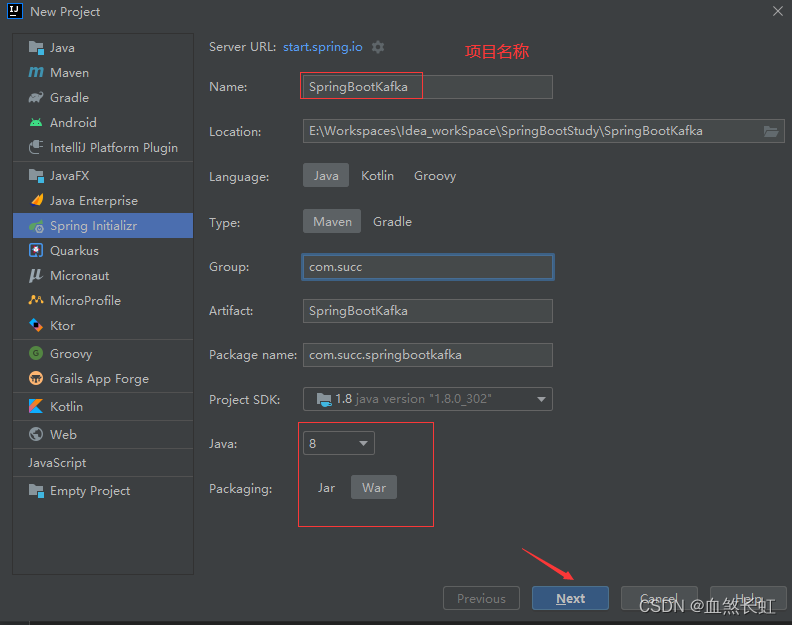 ¡Asegúrate de revisar las opciones a continuación!
¡Asegúrate de revisar las opciones a continuación!

1.1.2 Visualización del catálogo de proyectos
Nota: Después de que el proyecto se haya creado correctamente, primero cree el paquete y los archivos java para allanar el camino para el siguiente trabajo de escritura de código.

1.2, pom.xml agrega dependencias relacionadas con spring-kafka
Nota: Hay tres dependencias principales añadidas, a saber, el sistema se ha configurado automáticamente, dependencias principales de kafka + dependencias de prueba y otras dependencias auxiliares relacionadas (por ejemplo: lombok).
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.succ</groupId>
<artifactId>SpringBootKafaka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringBootKafaka</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 阿里巴巴 fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
1.3 En el archivo application.yml , agregue la configuración relacionada con kafka
spring:
kafka:
# 指定 kafka 地址,我这里部署在的虚拟机,开发环境是Windows,kafkahost是虚拟机的地址, 若外网地址,注意修改为外网的IP( 集群部署需用逗号分隔)
bootstrap-servers: kafkahost:9092
consumer:
# 指定 group_id
group-id: group_id
auto-offset-reset: earliest
# 指定消息key和消息体的序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# 指定消息key和消息体的序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringSerializer
value-deserializer: org.apache.kafka.common.serialization.StringSerializer
Nota: El alias de kafkahost debe configurarse por separado . Si necesita ayuda , haga clic para ingresar ; por supuesto, también puede escribir directamente la dirección IP de la máquina virtual aquí (porque el entorno de desarrollo es Windows y kafka se implementa en el máquina virtual, por lo que no puede escribir localhost aquí (equivalente a 127.0 .0.1) , de lo contrario, el acceso es el host local de Windows y no se puede acceder al kafka de la máquina virtual).
auto.offset.reset tiene 3 valores que se pueden configurar:
más temprano: cuando haya una compensación enviada en cada partición, comience el consumo desde la compensación enviada; cuando no haya una compensación enviada, comience el consumo desde el principio;
más reciente: cuando hay un desplazamiento enviado en cada partición, comience a consumir desde el desplazamiento enviado, cuando no haya ningún desplazamiento enviado, consuma los datos recién generados en la partición;
ninguno: cuando hay un desplazamiento enviado en cada partición del tema, el consumo comenzará después del desplazamiento; siempre que haya una partición sin un desplazamiento enviado, se lanzará una excepción;
De forma predeterminada, se recomienda usar la más temprana . Después de configurar este parámetro, Kafka se reinicia después de que se produzca un error. Si encuentra compensaciones no consumidas, puede continuar consumiendo.La configuración más reciente es fácil de perder mensajes . Si hay un problema con kafka y todavía hay datos escritos en el tema, reinicie kafka en este momento, esta configuración comenzará a consumir desde la última compensación, y aquellos que tienen problemas en el medio será ignorado.
Nota: Para obtener información de configuración más detallada, consulte la extensión en la parte inferior
2. Escritura de código
2.1, Codificación de bean de entidad de pedido (order)
package model;
import lombok.*;
import java.time.LocalDateTime;
/**
* @create 2022-10-08 1:25
* @describe 订单类javaBean实体
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class Order {
/**
* 订单id
*/
private long orderId;
/**
* 订单号
*/
private String orderNum;
/**
* 订单创建时间
*/
private LocalDateTime createTime;
}
2.2 Redacción de KafkaProvider (proveedor de mensajes)
package com.succ.springbootkafaka.provider;
import com.alibaba.fastjson.JSONObject;
import com.succ.springbootkafaka1.model.Order;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import java.time.LocalDateTime;
/**
* @create 2022-10-14 21:39
* @describe 话题的创建类,使用它向kafka中创建一个关于Order的订单主题
*/
@Component
@Slf4j
public class KafkaProvider {
/**
* 消息 TOPIC
*/
private static final String TOPIC = "shopping";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(long orderId, String orderNum, LocalDateTime createTime) {
// 构建一个订单类
Order order = Order.builder()
.orderId(orderId)
.orderNum(orderNum)
.createTime(createTime)
.build();
// 发送消息,订单类的 json 作为消息体
ListenableFuture<SendResult<String, String>> future =
kafkaTemplate.send(TOPIC, JSONObject.toJSONString(order));
// 监听回调
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.info("## Send message fail ...");
}
@Override
public void onSuccess(SendResult<String, String> result) {
log.info("## Send message success ...");
}
});
}
}
2.3, escritura de código KafkaConsumer (consumidor)
package consumer;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* @create 2022-10-08 1:25
* @describe 通过指定的话题和分组来消费对应的话题
*/
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = "shopping", groupId = "group_id") //这个groupId是在yml中配置的
public void consumer(String message) {
log.info("## consumer message: {}", message);
}
}
3. Pruebas unitarias
3.1 Preparativos
3.1.1 Ver el estado de inicio de Zookeeper
Use el comando cd para ingresar al directorio de instalación de zk
Inicie la instancia de nodo único de zk a través del script de inicio zookeeper-server-start.sh en el directorio bin :
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
Dado que la configuración básica de esta máquina virtual zk está en su lugar, se puede iniciar directamente ( si necesita ayuda con la instalación de zk , haga clic para ingresar )
#zkServer.sh status 查看服务状态
#zkServer.sh start 启动zk
#zkServer.sh stop 停掉zk
#zkServer.sh restart 重启zk

Como se muestra en la figura anterior, el modo de inicio de zk es el modo singleton independiente (sin clúster) y se ha iniciado.
3.1.2, iniciar kafka
Use el comando cd para ingresar al directorio bin en el directorio de instalación de kafka
Ingrese al directorio de descompresión e inicie Kafka en segundo plano a través del script kafka-server-start.sh en el directorio bin :
pwd
./kafka-server-start.sh ../config/server.properties

Comience normalmente, como se muestra en la siguiente figura:

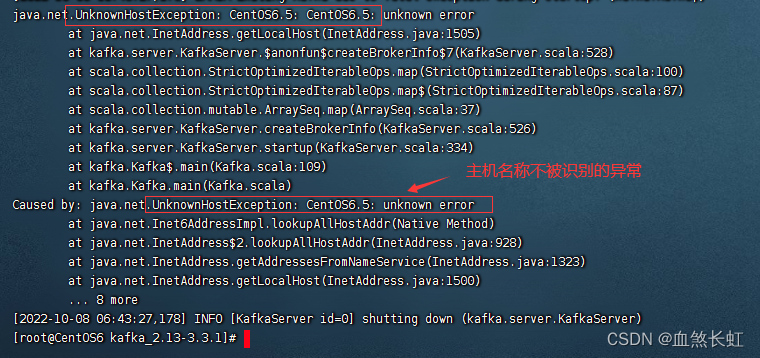
Recordatorio: la solución al problema de que el error de inicio de Kafka no reconoce el nombre del host, haga clic para ingresar .
java.net.UnknownHostException|error desconocido en java.net.Inet6AddressImpl.lookupAllHost
3.1.3 Tres formas de ver el estado de inicio de kafka
jps -ml #方式一,通过jps命令查看(尾部的-ml为非必须参数)
netstat -nalpt | grep 9092 #方式二,通过查看端口号查看 lsof -i:9092 #方式三3.2, escritura de código de prueba de unidad
package com.succ.springbootkafaka;
import com.succ.springbootkafaka.provider.KafkaProvider;
import org.junit.jupiter.api.Test;//注意,这个junit用自带的就可以
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.time.LocalDateTime;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
@SpringBootTest
class SpringBootKafakaApplicationTests {
@Autowired
private KafkaProvider kafkaProvider;
@Test
public void sendMessage() throws InterruptedException {
//如果这里打印为null,要么是zk或kafka没正常启动,此时进入linux分别查看他们状态接口,另外也需要排查一下你的yum文件配置的kafka的地址,最后排查自己的注解是否引入错误的package
System.out.println("是否为空??+"+kafkaProvider);
// 发送 1000 个消息
for (int i = 0; i < 1000; i++) {
long orderId = i+1;
String orderNum = UUID.randomUUID().toString();
kafkaProvider.sendMessage(orderId, orderNum, LocalDateTime.now());
}
TimeUnit.MINUTES.sleep(1);
}
}
3.3 Prueba
3.3.1 Enviar 1000 mensajes para ver si los mensajes se pueden publicar y consumir normalmente
El registro de la consola es el siguiente:

3.3.2 Verifique la lista de temas de Kafka para ver si el tema "compras" se crea normalmente
Ejecute el script kafka-topics.sh para ver la lista de temas en el directorio bin :
Nota: si su versión de kafka es superior a 2.2+=, use el siguiente comando para ver
bin/kafka-topics.sh --list --bootstrap-server kafkahost:9092

Como se muestra en la figura anterior, puede ver el tema de compras que acaba de crear
Nota: si su versión de kafka es inferior a 2.2-, use el siguiente comando para ver
bin/kafka-topics.sh --list --zookeeper kafkahost:2181El kafkahost anterior está configurado en vim /etc/host , y la IP se obtiene a través del comando ifconfig

¡Hasta ahora, la prueba es exitosa!
4. ¿Por qué empezar zk primero y luego kafka?
Porque el funcionamiento de kafka depende del arranque de zk.
Específicamente, puede ingresar al directorio /conf/ del directorio de descompresión de kafka
cd /usr/src/kafka_2.13-3.3.1/config/ && ls
vi server.properties


Para obtener más tutoriales de kafka , haga clic para ingresar
5. Trabajo de acabado
1. Cerrar Zookeeper
zkServer.sh status
zkServer.sh stop
zkServer.sh status 
2. Cerrar kafka
cd /usr/src/kafka_2.13-3.3.1/ && ls
jps
bin/kafka-server-stop.sh
jps 
Nota: Si está instalando y utilizando kafka por primera vez, el comando de apagado no tendrá efecto. Debe ingresar al archivo de configuración de kafka para realizar algunos cambios en la configuración, de la siguiente manera:
vim bin/kafka-server-stop.sh Encuentre el código en la figura a continuación y modifíquelo.

#PIDS=$(ps ax | grep ' kafka\.Kafka ' | grep java | grep -v grep | awk '{print $1}') PIDS=$(jps -lm | grep -i 'kafka.Kafka' |
awk '{imprimir $1}')
La función del comando modificado: use el comando jps -lm para enumerar todos los procesos java y luego use la canalización para filtrar el proceso kafka con grep -i 'kafka.

Resumir
A través de un pequeño caso, este artículo presenta inicialmente la integración de Spring Boot a Kafka y completa el llamado de productores (creando temas para Kafka) y consumidores (consumiendo información) de Spring Boot para completar llamados a Kafka.
Por supuesto, el uso de kafka es mucho más que eso, y se introducirán más y más introducciones en profundidad en diferentes páginas más adelante.
Epílogo
Sigue el camino recorrido por los antecesores y pisa el foso para los rezagados.
En el proceso de integración, es inevitable encontrar baches y baches, afortunadamente, estoy caminando contigo, y algunos escollos encontrados en él están básicamente marcados.
Si crees que el artículo no es malo, ¡bienvenido a darle me gusta y coleccionarlo!
expandir
Configuración más detallada sobre archivos yum
spring:
kafka:
bootstrap-servers: 172.101.203.33:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
notas
2. Colección Kafka (1): Introducción e instalación de Kafka, resumida en detalle