Al realizar el proyecto de graduación de pregrado, la sucursal de CNN de Sketchmate usó Resnet50, ahora revise la red neuronal residual nuevamente. Este artículo resuelve principalmente, ¿cómo trata Resnet la desaparición del gradiente? ¿Por qué se puede entrenar un modelo profundo? Aquí hay un resumen desde la perspectiva del gradiente.
Si tiene preguntas sobre la estructura de Resnet, consulte la Sección 7.6 de "Aprendizaje profundo práctico":
1. ¿Cómo lidiar con el gradiente de fuga?
Convierte la multiplicación en suma. (ResNet hace esto, especialmente la conexión residual (Conexión Residual))
2. ¿Cómo lidia el bloque residual con la desaparición del gradiente?
(1) Considere un modelo predictivo:
en:
- x: entrada
- f: representa el modelo de red neuronal
- y: salida
- w: red de pesos a entrenar
Luego para la actualización de los pesos, están:
Aquí η denota la tasa de aprendizaje. Como todos sabemos, la tasa de aprendizaje representa el tamaño del paso y el gradiente representa la dirección del paso. Por lo tanto, el gradiente de y a w no puede ser demasiado pequeño, si es demasiado pequeño, no importa cuán grande sea η, no funcionará y también afectará la estabilidad del valor.
Debido a que la retropropagación se propaga desde la capa de salida a la de entrada, los pesos de las capas más cercanas a la entrada son más propensos al problema de la desaparición del gradiente.
(2) Ahora apilamos (serializamos) otra red encima de una red :
Su término derivado con respecto a los pesos se obtiene fácilmente mediante la regla de la cadena para la derivación de funciones compuestas:
Después de la expansión por la regla de la cadena: el gradiente del segundo elemento y con respecto a w es el mismo que el resultado de la primera parte anterior, sin ningún cambio; el gradiente del primer elemento g(y) con respecto a y es el salida de la capa recién agregada a la entrada La derivada, que está relacionada con la diferencia entre el valor predicho y el valor real. Suponiendo que la diferencia entre el valor predicho y el valor real es relativamente pequeña, el valor del primer término será particularmente pequeño. Esto se debe a que, asumiendo que la capa añadida tiene una fuerte capacidad de ajuste, el primer término será particularmente pequeño. En este caso, después de multiplicar por el segundo término, el valor del producto será particularmente pequeño, es decir, el gradiente será muy pequeña. Solo puede aumentar la tasa de aprendizaje, pero puede que no sea muy útil aumentarla, porque se trata de una actualización cerca de la capa de datos inferior. Si la tasa de aprendizaje aumenta demasiado, es probable que w en la capa recién agregada ya sea grande, lo que puede generar inestabilidad numérica.
Es precisamente debido a la multiplicación de gradiente causada por la regla de la cadena después de apilar la red, si hay un elemento relativamente pequeño en el medio, puede causar que el producto de toda la fórmula sea relativamente pequeño, y el producto será más pequeño como llega a la capa inferior.
(3) Utilice el método de conexión residual para profundizar el modelo original:
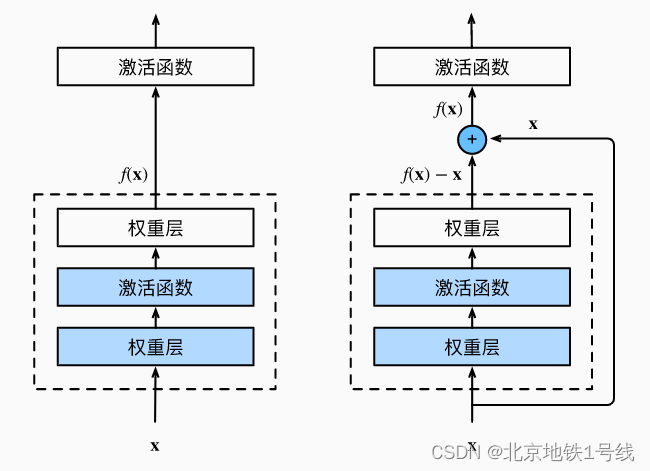
El término derivado en este momento:
Usa la derivación de la suma para expandir la expresión del modelo y obtener dos elementos. El primer elemento es el mismo que el anterior, que es la parte inicial.
Para estos dos artículos, incluso si el valor del segundo artículo es relativamente pequeño, el valor del primer artículo todavía se complementa (un número grande más un decimal sigue siendo un número grande, pero un número grande multiplicado por un decimal puede convertirse en un número grande). decimal ), es precisamente debido a la existencia de rutas de datos entre capas que el peso de la capa inferior del modelo no se reducirá mucho en comparación con antes de profundizar el modelo.
El peso w cerca del final de los datos es difícil de entrenar, pero debido a la adición de una ruta de datos de capa cruzada, al calcular el gradiente, la pérdida de la capa superior se puede pasar directa y rápidamente a la capa inferior a través de la cruz. -ruta de conexión de capa, por lo que al principio, la capa inferior también puede obtener un gradiente más grande.
Desde la perspectiva del tamaño del gradiente , la conexión residual permite que el peso w de la capa cercana a los datos obtenga un gradiente relativamente grande, por lo tanto, no importa qué tan profunda sea la red, la capa inferior puede obtener un gradiente lo suficientemente grande como para que la red puede actualizarse de manera más eficiente.