[Cómo cargar con éxito el conjunto de datos de HuggingFace] Sin usar Colab, tome el conjunto de datos de ChnSentiCorp como ejemplo
Frente
- Huggingface ChnSentiCorp
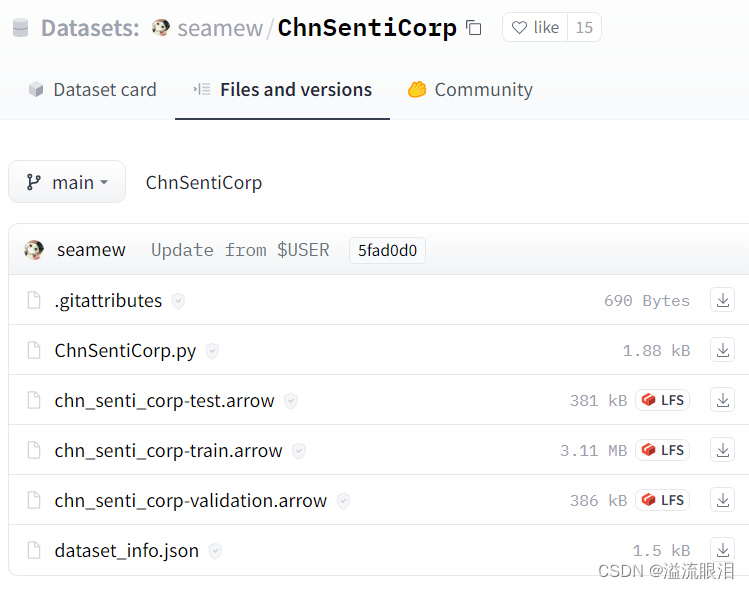
puede ver que la biblioteca huggingface contiene punteros a datos óptimos del conjunto de prueba, el conjunto de entrenamiento y el conjunto de verificación , y los datos reales están montados en GoogleDrive
cargar conjunto de datos
Intento 1: código de base de datos de carga estándar
- Use el siguiente código para cargar, que también es el código dado en algunos videos de bloggers de la estación B
import torch
from datasets import load_dataset
class Dataset(torch.utils.data.Dataset):
def __init__(self, split):
self.dataset = load_dataset(
path = "seamew/ChnSentiCorp",
split = split
)
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
text = self.dataset[i]["text"]
label = self.dataset[i]["label"]
return text, label
dataset = Dataset("train")
print(len(dataset), dataset[0])
Salida de la consola de comandos:
Using the latest cached version of the module from C:\Users\admin\.cache\huggingface\modules\datasets_modules\datasets\seamew--ChnSentiCorp\1f242195a37831906957a11a2985a4329167e60657c07dc95ebe266c03fdfb85 (last modified on Fri Jul 7 21:11:26 2023) since it couldn't be found locally at seamew/ChnSentiCorp., or remotely on the Hugging Face Hub.
Using custom data configuration default
D:\Softwares\Anaconda3\Anaconda3\lib\site-packages\scipy\__init__.py:155: UserWarning: A NumPy version >=1.18.5 and <1.25.0 is required for this version of SciPy (detected version 1.25.0
warnings.warn(f"A NumPy version >={np_minversion} and <{np_maxversion}"
Downloading and preparing dataset chn_senti_corp/default to C:\Users\admin\.cache\huggingface\datasets\seamew___chn_senti_corp\default\0.0.0\1f242195a37831906957a11a2985a4329167e60657c07dc95ebe266c03fdfb85...
Al ejecutar train_path = dl_manager.download_and_extract(_TRAIN_DOWNLOAD_URL)esta línea, se informa
un error ConnectionError
Motivo: Google Cloud Disk no se puede vincular
Intento 2: Internet científico
- Use Internet científico
para ejecutar el mismo código
e informarFileNotFoundError
un error Motivo: ¿Qué diablos? No puedo encontrar el archivo de alguna manera, ¿la versión de la biblioteca es demasiado antigua?
Intento 3: descargar la base de datos de Huggingface localmente
- Estos archivos se pueden descargar localmente usando
gitcomandos, etc.
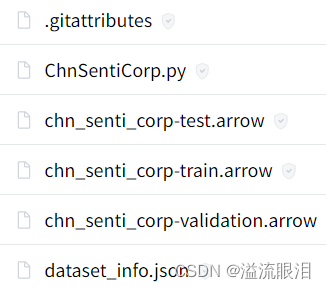
load_from_diskCargue la base de datos usando el nuevo método de carga ( )
import torch
from datasets import load_from_disk
class Dataset(torch.utils.data.Dataset):
def __init__(self, split):
self.dataset = load_from_disk(
"E:/Repo/NLP/23.7.7 Huggingface_Learn/ChnSentiCorp"
)
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
text = self.dataset[i]["text"]
label = self.dataset[i]["label"]
return text, label
dataset = Dataset("train")
print(len(dataset), dataset[0])
error de nuevoFile Not Found

Pruebe 3.5 para crear state.json
state.jsonCree un archivo en la carpeta del conjunto de datos
filenameque acaba de descargar como el archivo que desea cargar en el directorio.trainLos datos cargados aquí
_splittambién se cambian atrain
otras cosas tal como son, y el fantasma sabe_fingerprintlo que hay detrás de ellos...
{
"_data_files": [
{
"filename": "chn_senti_corp-train.arrow"
}
],
"_fingerprint": "24c4fd9824d8b978",
"_format_columns": null,
"_format_kwargs": {
},
"_format_type": null,
"_indexes": {
},
"_output_all_columns": false,
"_split": "train"
}
- Como resultado, la operación fue un éxito.

huevos
- El archivo del tutorial de un blogger
jsones el siguiente:
{
"_data_files": [
{
# 对应上图中的文件名
"filename": "chn_senti_corp-train.arrow"
}
],
"_fingerprint": "24c4fd9824d8b978",
"_format_columns": null,
"_format_kwargs": {
},
"_format_type": null,
"_indexes": {
},
"_output_all_columns": false,
# 加载训练集数据 若为验证集 'validation' 测试集 'test'
"_split": "train"
}
- Después de llamarlo, se genera un nuevo error y la codificación de vscode cambia a No funciona
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 43: invgbk - Después de tantear, descubrí que borrar los comentarios en chino en el json es suficiente...
Por cierto, esta es la segunda vez en mi vida que puedo ejecutar después de borrar los comentarios en chino, lo cual es realmente bueno.