1 Beantragen Sie die Erlaubnis zum Herunterladen von Modellen
https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Füllen Sie eine kleine Authentifizierung aus, dieses Mal habe ich sie in etwa 10 Minuten bestanden
Der Inhalt der Mail ist wie folgt:

2 Laden Sie den Lama-Quellcode herunter
Git-Klon [email protected]:facebookresearch/llama.git
3 Laden Sie das Modell herunter
Verwenden Sie zum Herunterladen download.sh im Quellcode
Wie nachfolgend dargestellt

Im ersten Schritt werden Sie aufgefordert, die Autorisierungs-URL in die E-Mail einzugeben, die sehr lang ist und mit https://download.llamameta.net beginnt
Im zweiten Schritt können Sie den Namen des Modells eingeben, das Sie herunterladen möchten, hier ist 70B-Chat
Danach werden mehrere LIZENZ- und tokenizer.model-Dateien usw. heruntergeladen.
Danach ist die Modelldatei, die wir am meisten brauchen. Wie nachfolgend dargestellt

4 Extras herunterladen
22.07.2023 11:20:30 Uhr, die Zeit zum Starten des Downloads ist 21.07.2023 17:30 Uhr, in der Vergangenheit habe ich viele Modelle heruntergeladen, aber ich habe gerade herausgefunden, dass ein Fehler gemeldet wurde. . . .
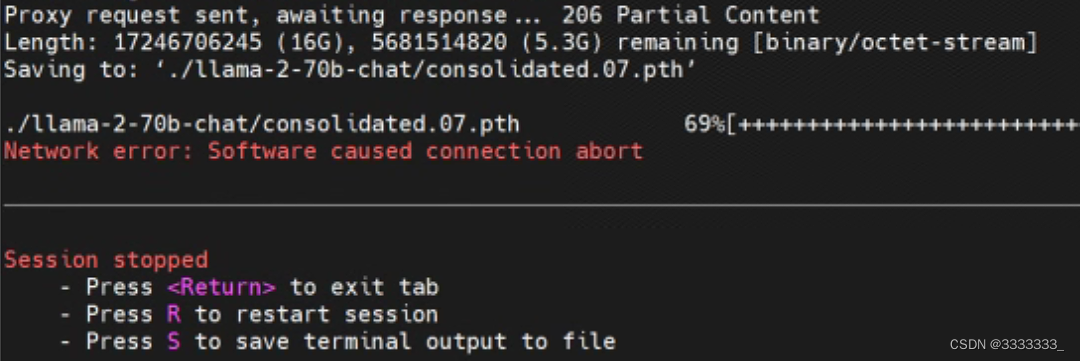
Ich weiß nicht, ob ich weitermachen kann
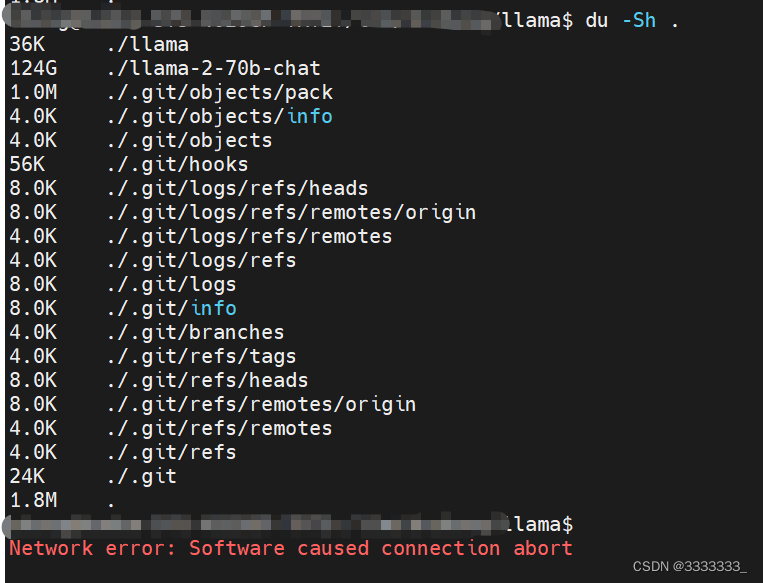
Führen Sie dann das Skript download.sh erneut aus und stellen Sie fest, dass das heruntergeladene Modell erneut heruntergeladen wird. ε=(´ο`*))) Leider! ! ! !
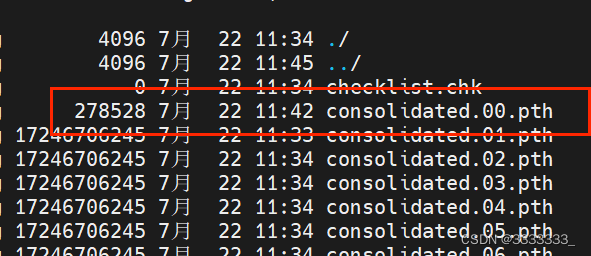
Sie können nur den Quellcode ändern und die heruntergeladenen überspringen.
Ich habe 00 01 02 03 04 05 06 und 07 heruntergeladen. Da 07 das letzte ist, bin ich nicht sicher, ob der Download abgeschlossen ist, daher wird er als nicht heruntergeladen betrachtet. Außerdem wurde 00 überschrieben, als ich den Download erneut versuchte. sh-Skript. Es ist ebenfalls unvollständig, daher habe ich das download.sh-Skript in das folgende Bild geändert
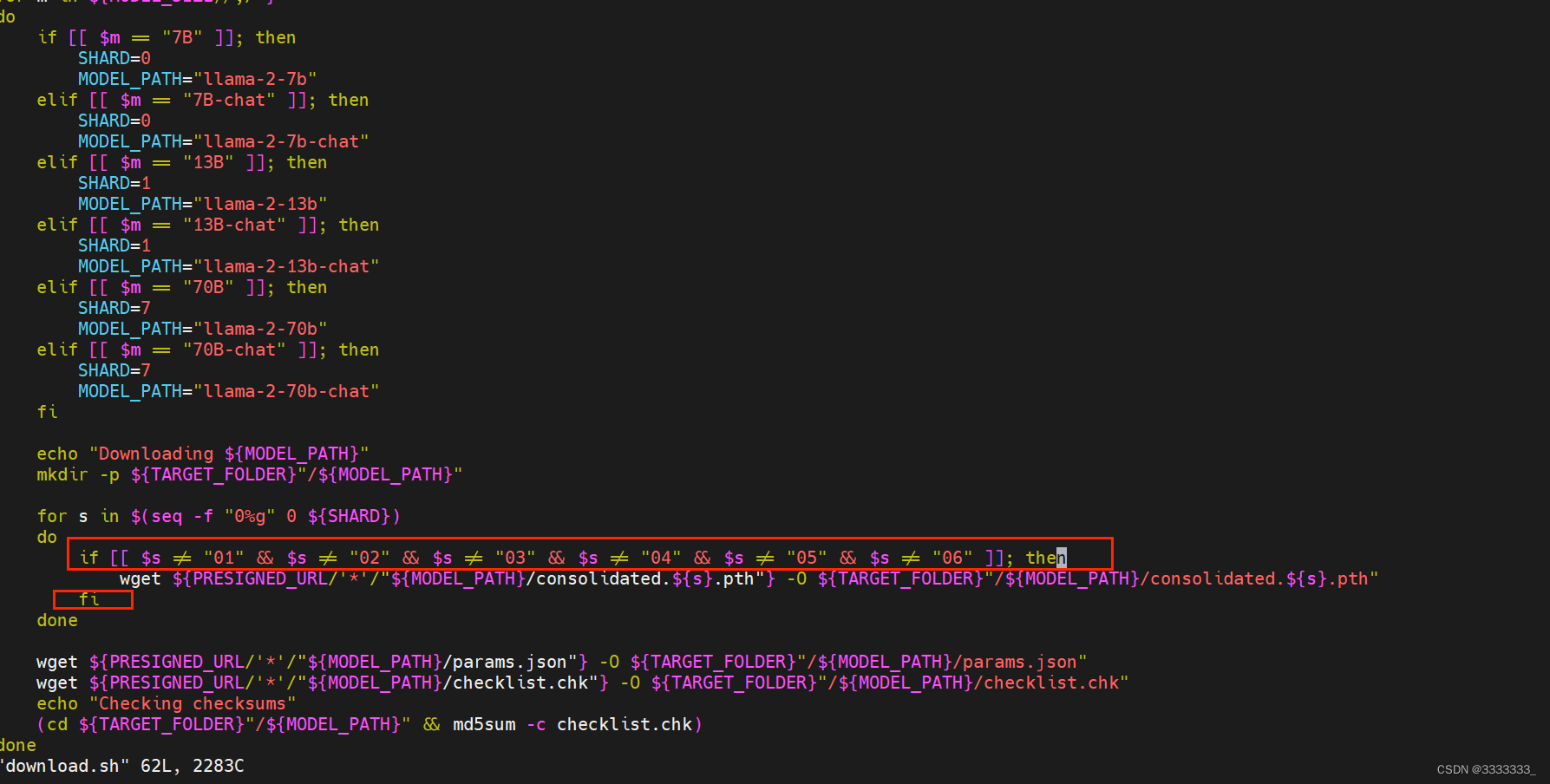
if [[ $s != "01" && $s != "02" && $s != "03" && $s != "04" && $s != "05" && $s != "06" ]]
wget xxxx
fi
22.07.2023 14:50:21 Endlich ist der Download abgeschlossen
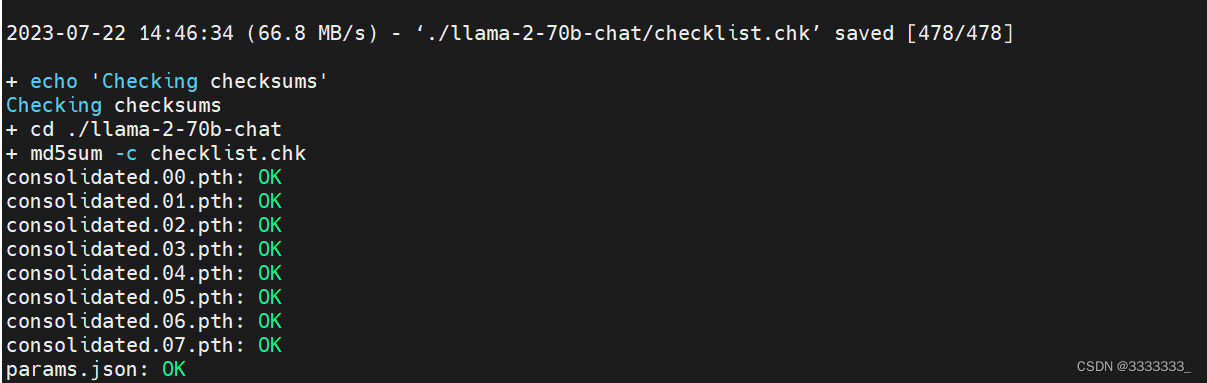
Das Modell ist etwa 129G groß

5 Führen Sie die offizielle Demo aus
24.07.2023 22:10

Der Beamte sagte, dass hier 8 MPs benötigt werden, also habe ich beim Ausführen 8 GPUs angegeben
CUDA_VISIBLE_DEVICES=1,2,3,4,6,7,8,9 Torchrun --nproc_per_node 8 --master_port=29501 example_chat_completion.py --ckpt_dir llama-2-70b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
Überprüfen Sie nach dem Starten des Befehls den GPU-Status, wie in der folgenden Abbildung dargestellt

Terminalausgabe anzeigen
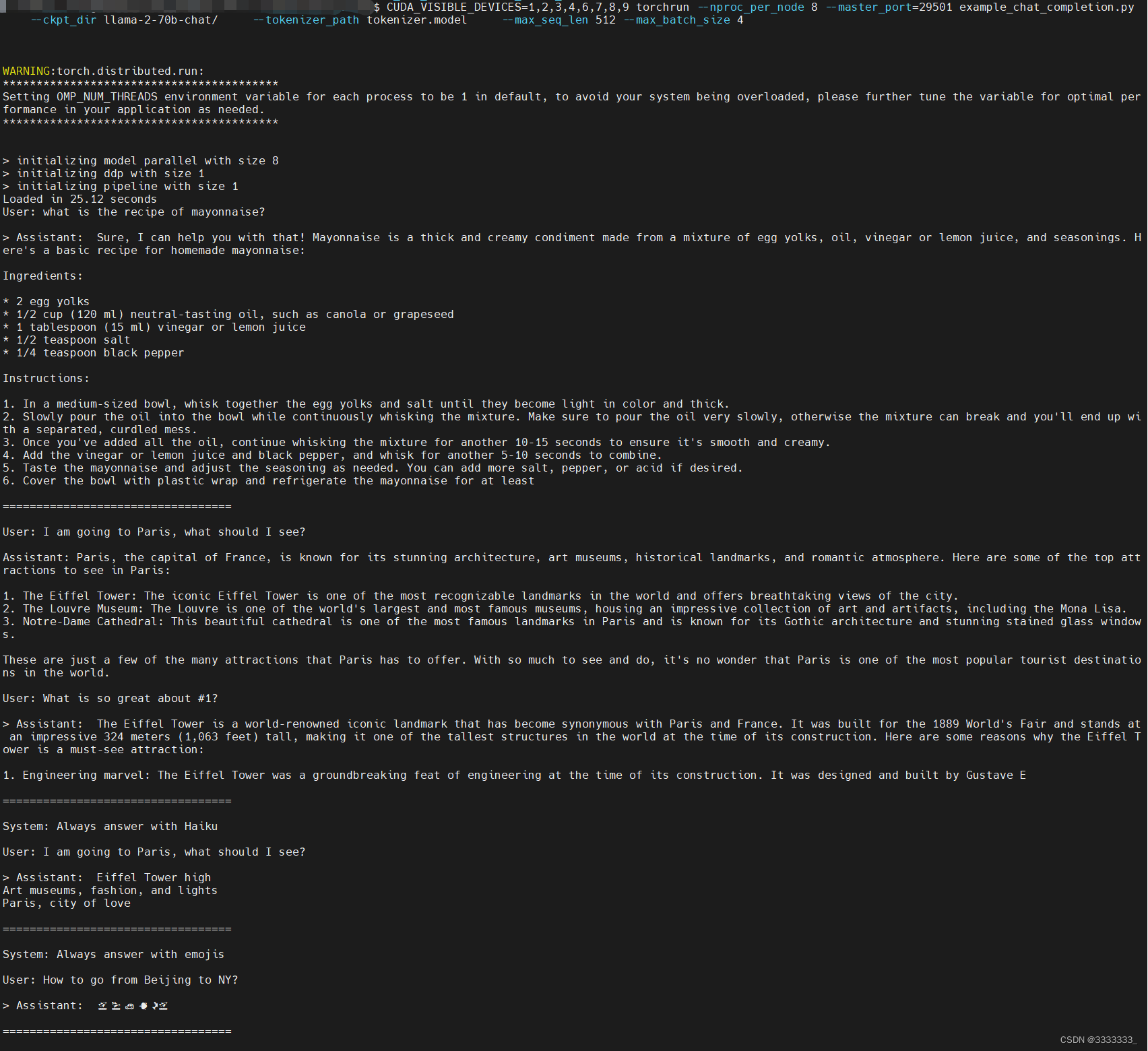
Es lief reibungslos!
6 Feinabstimmung
Nachtragsergänzung