Tabla de contenido
1. La carga de archivos más fácil
2. Arrastrar + pegar + optimización de estilo
3. Resumen del punto de interrupción + segunda transmisión + barra de progreso
Resumen del punto de interrupción + segunda transmisión (parte delantera)
Resumen de punto de interrupción + segunda transmisión (backend)
4. Muestreo de hash y webWorker
Determinar el tipo de archivo por encabezado de archivo
6. Control de concurrencia asíncrono (importante)
7. Reintento de error simultáneo
Este artículo es adecuado para estudiantes de front-end que tienen cierta base de back-end de nodo. Si no conoce el back-end en absoluto, compense el conocimiento previo.
Sin más preámbulos, vayamos directo al grano.
Echemos un vistazo a cómo se ven los componentes de carga de archivos de cada versión
| calificación | Función |
|---|---|
| Bronce - Basura | nativo+axios.post |
| Plata: actualización de experiencia | Pegar, arrastrar y soltar, barra de progreso |
| Oro: actualización de funciones | Resumen de punto de interrupción, segunda transmisión, juicio de tipo |
| Platino - Mejora de velocidad | trabajador web, corte de tiempo, hash de muestreo |
| Diamante - Actualización de red | Control de concurrencia asíncrono, reintento de error de segmento |
| Rey - finamente elaborado | Control de inicio lento, desfragmentación y más |
1. La carga de archivos más fácil
Para cargar un archivo, necesitamos obtener el objeto del archivo y luego usar formData para enviarlo al backend para recibirlo.
function upload(file){
let formData = new FormData();
formData.append('newFile', file);
axios.post(
'http://localhost:8000/uploader/upload',
formData,
{ headers: { 'Content-Type': 'multipart/form-data' } }
)
}2. Arrastrar + pegar + optimización de estilo
Demasiado perezoso para escribir, puede buscar bibliotecas en Internet, hay de todo en Internet o directamente bibliotecas de componentes para resolver el problema
3. Resumen del punto de interrupción + segunda transmisión + barra de progreso
rebanada de archivo
Dividimos un archivo en varias piezas pequeñas, las guardamos en una matriz y las enviamos al backend una por una para realizar la transmisión de reanudación del punto de interrupción.
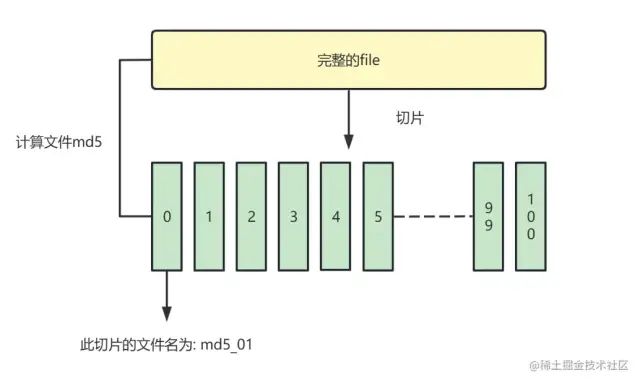
// 计算文件hash作为id
const { hash } = await calculateHashSample(file)
//todo 生成文件分片列表
// 使用file.slice()将文件切片
const fileList = [];
const count = Math.ceil(file.size / globalProp.SIZE);
const partSize = file.size / count;
let cur = 0 // 记录当前切片的位置
for (let i = 0; i < count; i++) {
let item = {
chunk: file.slice(cur, cur + partSize),
filename: `${hash}_${i}`
};
fileList.push(item);
}calcular hash
Para que el backend sepa que este segmento es parte de un archivo para que pueda agregarse en un archivo completo. Necesitamos calcular el valor único (md5) del archivo completo como el nombre de archivo del segmento.
// 通过input的event获取到file
<input type="file" @change="getFile">
// 使用SparkMD5计算文件hash,读取文件为blob,计算hash
let fileReader = new FileReader();
fileReader.onload = (e) => {
let hexHash = SparkMD5.hash(e.target.result);
console.log(hexHash);
};Resumen del punto de interrupción + segunda transmisión (parte delantera)
Tenemos una matriz de 100 segmentos de archivos guardados en este momento, simplemente recorra los segmentos y envíe solicitudes axios.post al backend de forma continua. Configure un interruptor para implementar la función de inicio-pausa.
¿Y si pasamos de las 50 copias y cerramos el navegador?
En este punto, necesitamos la cooperación del backend. Antes de cargar archivos, debemos verificar cuántos archivos ha recibido el backend .
Por supuesto, si se encuentra que el backend ya cargó este archivo, mostrará directamente que la carga está completa (segunda transmisión)
// 解构出已经上传的文件数组 文件是否已经上传完毕
// 通过文件hash和后缀查询当前文件有多少已经上传的部分
const {isFileUploaded, uploadedList} = await axios.get(
`http://localhost:8000/uploader/count
?hash=${hash}
&suffix=${fileSuffix}`
)Resumen de punto de interrupción + segunda transmisión (backend)
En cuanto al funcionamiento del back-end, es relativamente sencillo
-
Cree carpetas basadas en hashes de archivos y guarde segmentos de archivos
-
Verifique el estado de carga de un archivo y devuélvalo al front-end a través de la interfaz
Por ejemplo, la siguiente carpeta de segmento de archivo
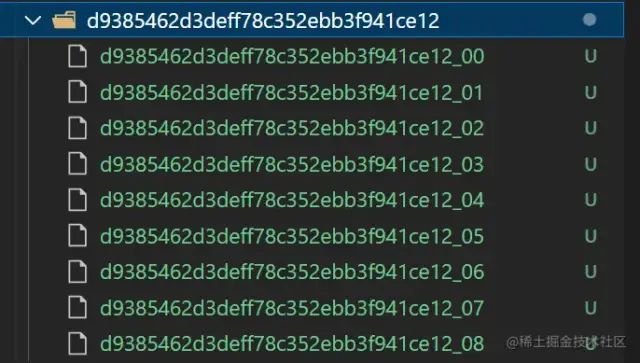
//! --------通过hash查询服务器中已经存放了多少份文件(或者是否已经存在文件)------
function checkChunks(hash, suffix) {
//! 查看已经存在多少文件 获取已上传的indexList
const chunksPath = `${uploadChunksDir}${hash}`;
const chunksList = (fs.existsSync(chunksPath) && fs.readdirSync(chunksPath)) || [];
const indexList = chunksList.map((item, index) =>item.split('_')[1])
//! 通过查询文件hash+suffix 判断文件是否已经上传
const filename = `${hash}${suffix}`
const fileList = (fs.existsSync(uploadFileDir) && fs.readdirSync(uploadFileDir)) || [];
const isFileUploaded = fileList.indexOf(filename) === -1 ? false : true
console.log('已经上传的chunks', chunksList.length);
console.log('文件是否存在', isFileUploaded);
return {
code: 200,
data: {
count: chunksList.length,
uploadedList: indexList,
isFileUploaded: isFileUploaded
}
}
}
barra de progreso
No es suficiente calcular los fragmentos cargados con éxito en tiempo real, realicémoslo nosotros mismos
4. Muestreo de hash y webWorker
Porque antes de cargar, necesitamos calcular el valor md5 del archivo y usarlo como la identificación del segmento. El cálculo de md5 es una tarea que consume mucho tiempo. Si el archivo es demasiado grande, js se quedará atascado en el paso de calcular md5, lo que provocará que la página se congele durante mucho tiempo.
Aquí proporcionamos tres ideas para la optimización:
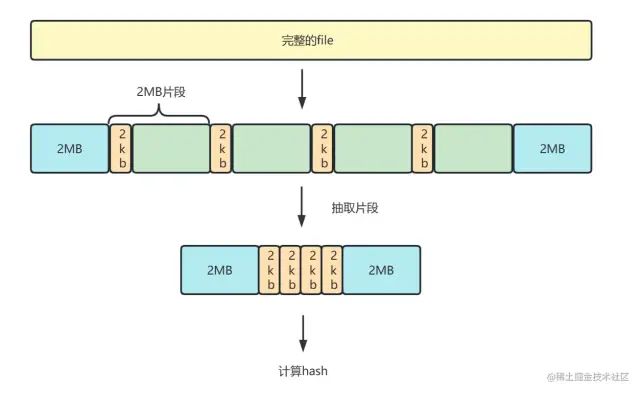
Hash de muestreo (md5)
Hash de muestreo significa que interceptamos una parte del archivo completo, calculamos el hash y mejoramos la velocidad de cálculo.
1. Analizamos el archivo en datos de búfer binarios,
2. Extraiga 2mb desde el principio y el final del archivo, y extraiga 2kb de la parte media cada 2mb
3. Combine estos fragmentos en un nuevo búfer para el cálculo de md5.
Ilustración:
Código de muestra
//! ---------------抽样md5计算-------------------
function calculateHashSample(file) {
return new Promise((resolve) => {
//!转换文件类型(解析为BUFFER数据 用于计算md5)
const spark = new SparkMD5.ArrayBuffer();
const { size } = file;
const OFFSET = Math.floor(2 * 1024 * 1024); // 取样范围 2M
const reader = new FileReader();
let index = OFFSET;
// 头尾全取,中间抽2字节
const chunks = [file.slice(0, index)];
while (index < size) {
if (index + OFFSET > size) {
chunks.push(file.slice(index));
} else {
const CHUNK_OFFSET = 2;
chunks.push(file.slice(index, index + 2),
file.slice(index + OFFSET - CHUNK_OFFSET, index + OFFSET)
);
}
index += OFFSET;
}
// 将抽样后的片段添加到spark
reader.onload = (event) => {
spark.append(event.target.result);
resolve({
hash: spark.end(),//Promise返回hash
});
}
reader.readAsArrayBuffer(new Blob(chunks));
});
}trabajador web
Además de muestrear hash, también podemos abrir un subproceso webWorker para calcular md5.
webWorker: es para crear un entorno de ejecución de subprocesos múltiples para JS, lo que permite que el subproceso principal cree subprocesos de trabajo y asigne tareas a este último. Mientras se ejecuta el subproceso principal, los subprocesos de trabajo también se ejecutan sin interferir entre sí. Después se ejecutan los subprocesos de trabajo, los resultados se devuelven al subproceso principal.
Para métodos de uso específicos, consulte MDN u otros artículos:
Uso de Web Workers \- Referencia de la interfaz API web | MDN \(mozilla.org\)[1]
Aprenda a usar Web Worker a fondo en un artículo \- Nuggets\(juejin.cn\)[2]
porción de tiempo
Los estudiantes que están familiarizados con la división del tiempo de reacción también pueden intentarlo, pero personalmente creo que esta solución no es tan buena como las dos anteriores.
Los estudiantes que no estén familiarizados con él pueden averiguarlo por sí mismos, todavía hay muchos artículos. No hay mucha discusión aquí, solo proporcione ideas.
requestIdleCallback,requestAnimationFrame La división de tiempo son las dos API legendarias , o puede ser encapsulada por messageChannel en un nivel superior.
Slice calcula el hash, distribuye múltiples tareas cortas en cada marco y reduce el retraso de la página.
5. Tipo de archivo sentencia
Más simple, podemos juzgar el tipo a través del atributo de aceptación de la etiqueta de entrada, o interceptando el nombre del archivo
<input id="file" type="file" accept="image/*" />
const ext = file.name.substring(file.name.lastIndexOf('.') + 1);Por supuesto, esta limitación se puede romper simplemente modificando la extensión del archivo, lo cual no es riguroso.
Determinar el tipo de archivo por encabezado de archivo
Convertimos el archivo en un blob binario. Los primeros bytes del archivo indican el tipo de archivo y podemos leerlo para juzgar.
Por ejemplo, el siguiente código
// 判断是否为 .jpg
async function isJpg(file) {
// 截取前几个字节,转换为string
const res = await blobToString(file.slice(0, 3))
return res === 'FF D8 FF'
}
// 判断是否为 .png
async function isPng(file) {
const res = await blobToString(file.slice(0, 4))
return res === '89 50 4E 47'
}
// 判断是否为 .gif
async function isGif(file) {
const res = await blobToString(file.slice(0, 4))
return res === '47 49 46 38'
}Por supuesto, tenemos bibliotecas listas para usar que pueden hacer esto, como la biblioteca de tipo de archivo
tipo de archivo \- npm \(npmjs.com\)[3]
6. Control de concurrencia asíncrono (importante)
Necesitamos cargar múltiples fragmentos de archivos al backend, ¿no podemos enviarlos uno por uno? Aquí usamos la concurrencia TCP + para implementar la concurrencia de control para la carga.
Primero, encapsulamos 100 fragmentos de archivos como función axios.post y los almacenamos en el grupo de tareas
-
Cree un grupo simultáneo, ejecute tareas en el grupo simultáneo y envíe fragmentos
-
Establezca el contador i, cuando i<número de concurrencia, la tarea se puede enviar al grupo concurrente
-
Se devolverá la solicitud que se ejecuta primero a través del método promise.race y se puede llamar a su método .then para pasar la siguiente solicitud (recursivo)
-
Cuando se envía la última solicitud, se realiza una solicitud al backend para fusionar fragmentos de archivos
diagrama

el código
//! 传入请求列表 最大并发数 全部请求完毕后的回调
function concurrentSendRequest(requestArr: any, max = 3, callback: any) {
let i = 0 // 执行任务计数器
let concurrentRequestArr: any[] = [] //并发请求列表
let toFetch: any = () => {
// (每次执行i+1) 如果i=arr.length 说明是最后一个任务
// 返回一个resolve 作为最后的toFetch.then()执行
// (执行Promise.all() 全部任务执行完后执行回调函数 发起文件合并请求)
if (i === requestArr.length) {
return Promise.resolve()
}
//TODO 执行异步任务 并推入并发列表(计数器+1)
let it = requestArr[i++]()
concurrentRequestArr.push(it)
//TODO 任务执行后 从并发列表中删除
it.then(() => {
concurrentRequestArr.splice(concurrentRequestArr.indexOf(it), 1)
})
//todo 如果并发数达到最大数,则等其中一个异步任务完成再添加
let p = Promise.resolve()
if (concurrentRequestArr.length >= max) {
//! race方法 返回fetchArr中最快执行的任务结果
p = Promise.race(concurrentRequestArr)
}
//todo race中最快完成的promise,在其.then递归toFetch函数
if (globalProp.stop) { return p.then(() => { console.log('停止发送') }) }
return p.then(() => toFetch())
}
// 最后一组任务全部执行完再执行回调函数(发起合并请求)(如果未合并且未暂停)
toFetch().then(() =>
Promise.all(concurrentRequestArr).then(() => {
if (!globalProp.stop && !globalProp.finished) { callback() }
})
)
}
7. Reintento de error simultáneo
-
Use catch para detectar errores de tareas. Después de que falle la ejecución de la tarea axios.post anterior, vuelva a colocar la tarea en la cola de tareas.
-
Establezca una etiqueta para cada objeto de tarea para registrar el número de reintentos de tareas
-
Si una tarea de corte falla más de 3 veces, será rechazada directamente. Y puede terminar directamente la transferencia de archivos
8. Control de arranque lento
Debido a los diferentes tamaños de archivo, es un poco complicado establecer el tamaño de cada segmento para que sea fijo.Podemos referirnos a 慢启动la estrategia del protocolo TCP. Establezca un tamaño inicial y ajuste dinámicamente el tamaño del siguiente segmento de acuerdo con la finalización de la tarea de carga para asegurarse de que el tamaño del segmento del archivo coincida con la velocidad actual de la red.
-
Traiga el valor del tamaño en el fragmento, pero la cantidad de barras de progreso es incierta, modifique createFileChunk, solicite agregar estadísticas de tiempo
-
·Por ejemplo, nuestro ideal es pasar uno en 30 segundos. El tamaño inicial se establece en 1M, si la carga tarda 10 segundos, el siguiente tamaño de bloque se convierte en 3M. Si la carga tardó 60 segundos, el siguiente tamaño de bloque se convierte en 500 KB y así sucesivamente.
9. Limpieza de escombros
Si el usuario carga el archivo y termina a la mitad, y no lo cargará en el futuro, los fragmentos de archivo guardados en el backend serán inútiles.
Podemos establecer una tarea programada en el lado del nodo setIntervalpara verificar y limpiar archivos fragmentados innecesarios de vez en cuando.
Se puede usar node-schedule para administrar tareas programadas, como revisar el directorio una vez al día y, si el archivo es de hace un mes, eliminarlo directamente.
archivo basura
posdata
Lo anterior son todas las funciones de un componente de carga de archivos completo y más avanzado. Espero que tengas la paciencia para ver que los amigos novatos aquí pueden dominarlo. Haz progresos pequeños pero diarios.
Referencias
[1] https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Workers_API/Using_web_workers: https://link.juejin.cn?target=https%3A%2F%2Fdeveloper.mozilla.org %2Fzh-CN%2Fdocs%2FWeb%2FAPI%2FWeb_Workers_API%2FUsing_web_workers
[2] https://juejin.cn/post/7139718200177983524: https://juejin.cn/post/7139718200177983524
[3] https://www.npmjs.com/package/file-type: https://link.juejin.cn?target=https%3A%2F%2Fwww.npmjs.com%2Fpackage%2Ffile-type