Directorio de artículos
1. Mensaje de error
Mensaje de error principal:
- WARN Shell: no se encontró winutils.exe: java.io.FileNotFoundException:
- java.io.FileNotFoundException: HADOOP_HOME y hadoop.home.dir no están configurados.
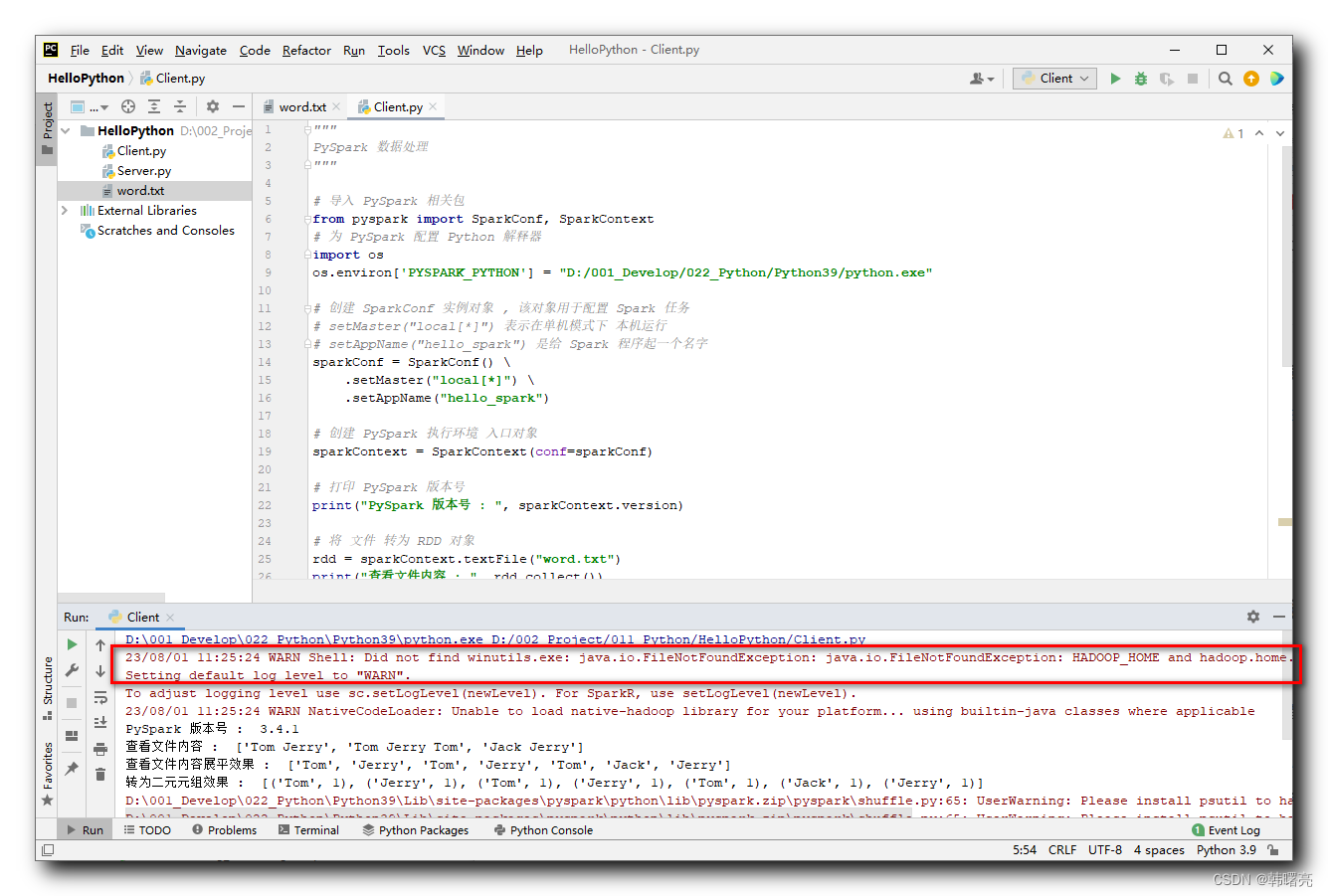
En PyCharm, llamar a PySpark para realizar tareas de cálculo informará el siguiente error:
D:\001_Develop\022_Python\Python39\python.exe D:/002_Project/011_Python/HelloPython/Client.py
23/08/01 11:25:24 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/08/01 11:25:24 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PySpark 版本号 : 3.4.1
查看文件内容 : ['Tom Jerry', 'Tom Jerry Tom', 'Jack Jerry']
查看文件内容展平效果 : ['Tom', 'Jerry', 'Tom', 'Jerry', 'Tom', 'Jack', 'Jerry']
转为二元元组效果 : [('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jack', 1), ('Jerry', 1)]
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
最终统计单词 : [('Tom', 3), ('Jack', 1), ('Jerry', 3)]
Process finished with exit code 0
2. Solución (instalar entorno operativo Hadoop)
Mensaje de error principal:
- WARN Shell: no se encontró winutils.exe: java.io.FileNotFoundException:
- java.io.FileNotFoundException: HADOOP_HOME y hadoop.home.dir no están configurados.
PySpark generalmente se ejecuta con el entorno de Hadoop, si el entorno de tiempo de ejecución de Hadoop no está instalado en Windows, se informará el error anterior;
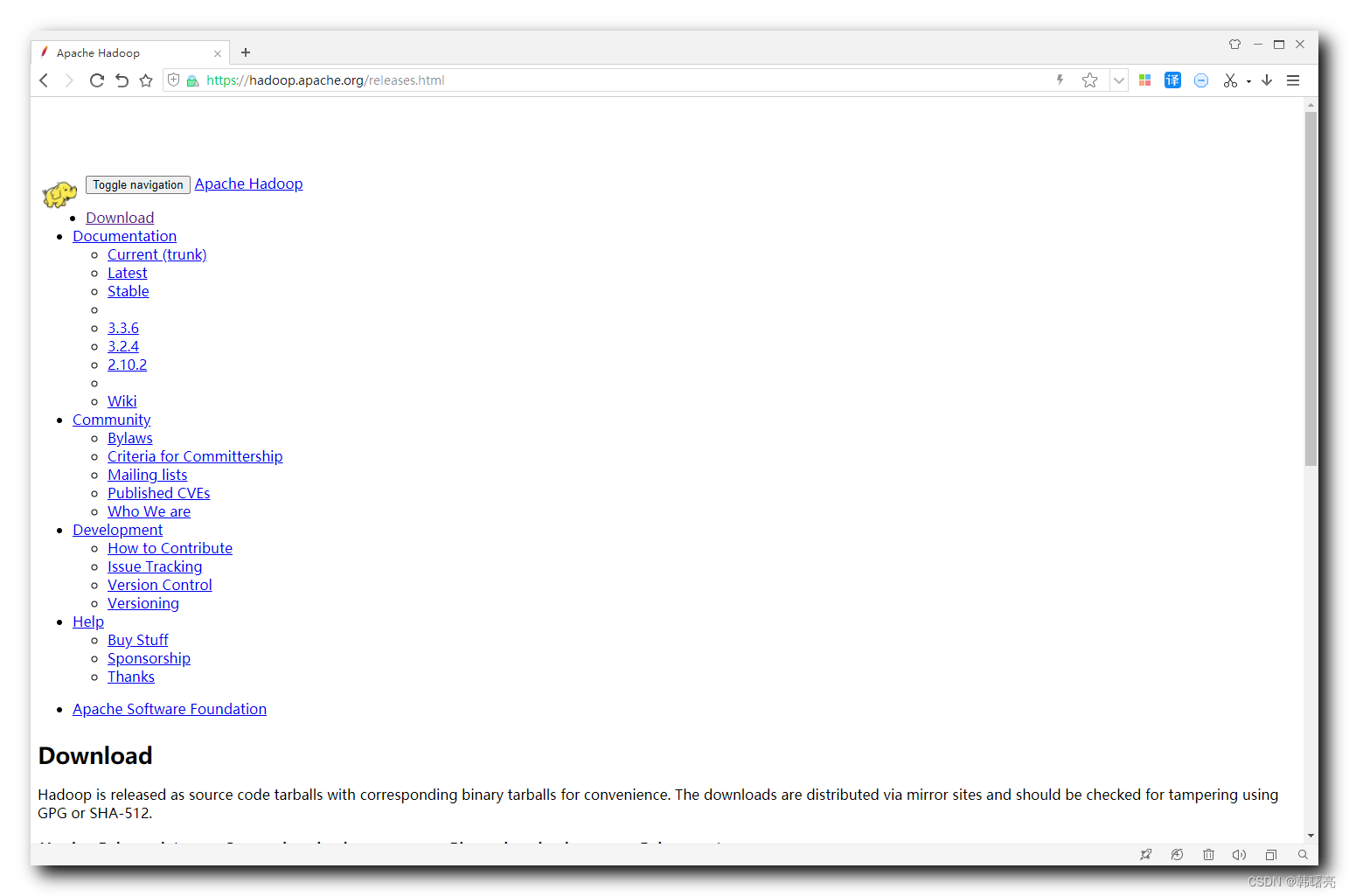
Las versiones de Hadoop están disponibles para descargar en https://hadoop.apache.org/releases.html ;
La última versión es 3.3.6, haga clic en el enlace binario (firma de suma de control) en Descarga binaria
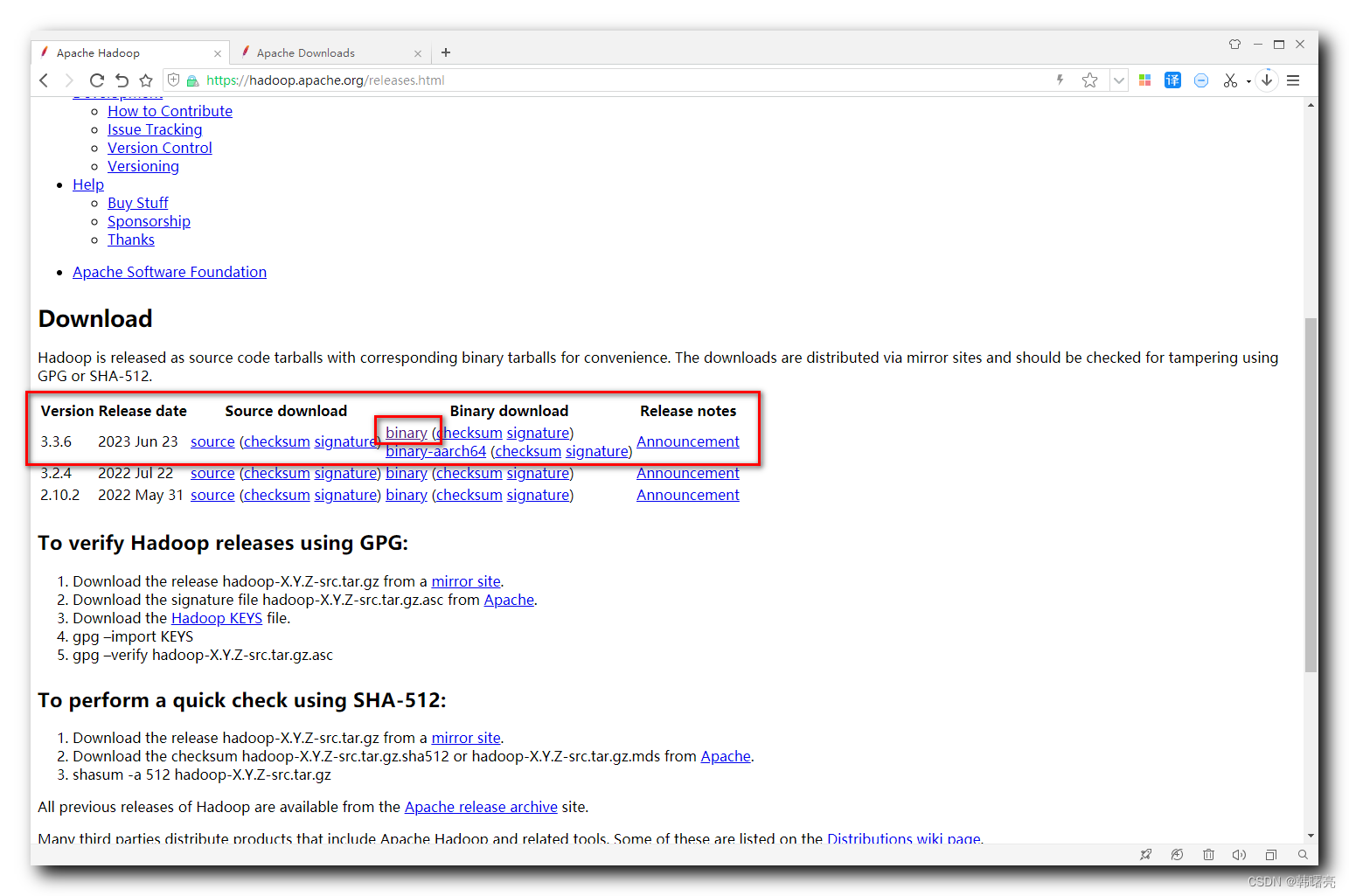
para ingresar a la página de descarga de Hadoop 3.3.6:
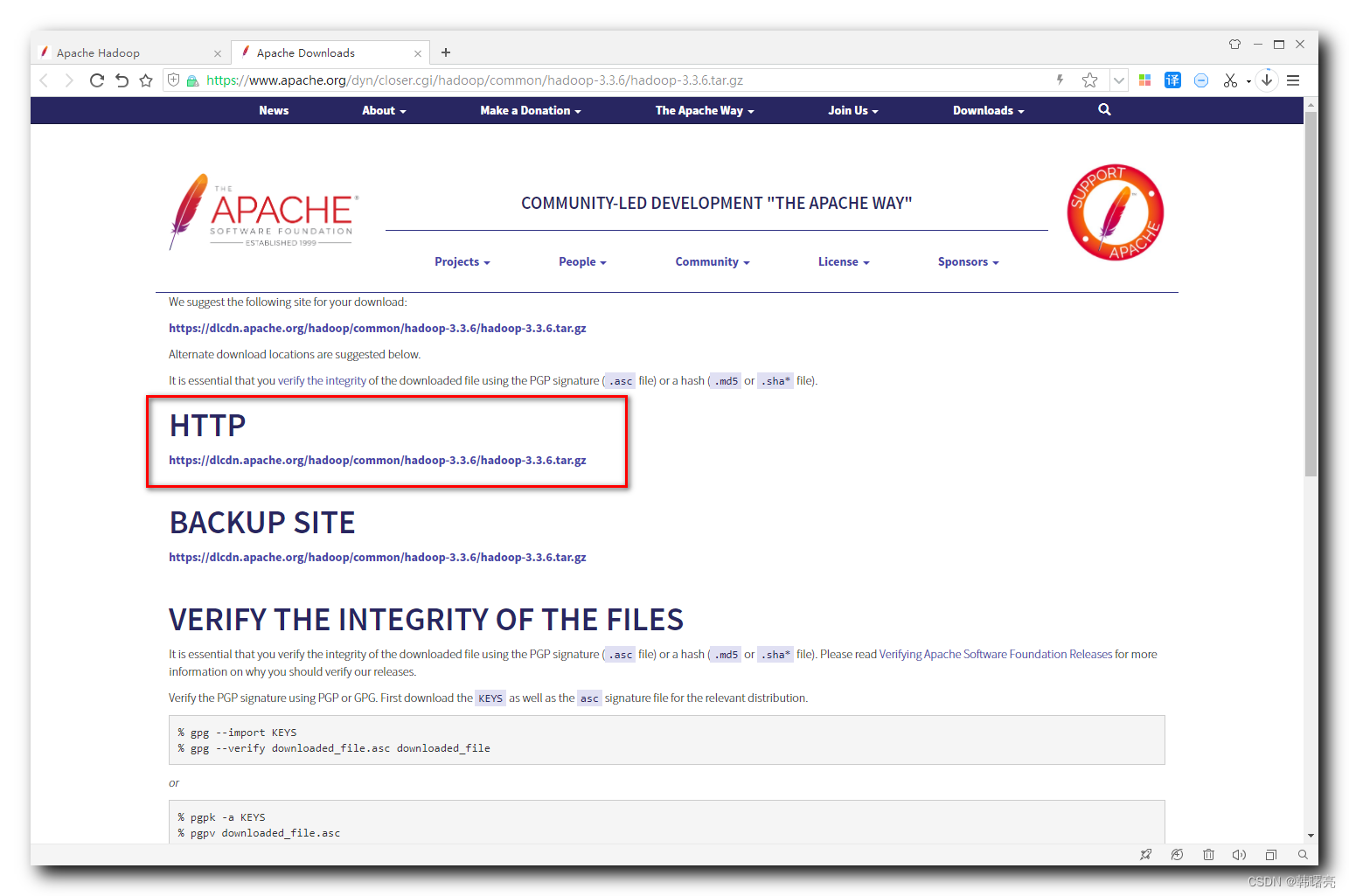
La dirección de descarga es:
https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
La velocidad de descarga oficial es muy lenta;

Aquí hay una versión de Hadoop, Hadoop 3.3.4 + winutils, CSDN 0 dirección de descarga de puntos:
Después de descargar, descomprima Hadoop, la ruta de instalación es D:\001_Develop\052_Hadoop\hadoop-3.3.4\hadoop-3.3.4;
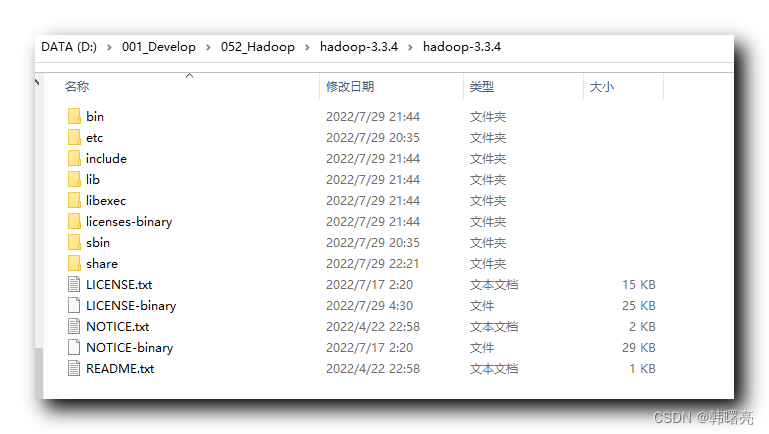
En las variables de entorno, establecer
HADOOP_INICIO = D:\001_Desarrollo\052_Hadoop\hadoop-3.3.4\hadoop-3.3.4
Variables de entorno del sistema;
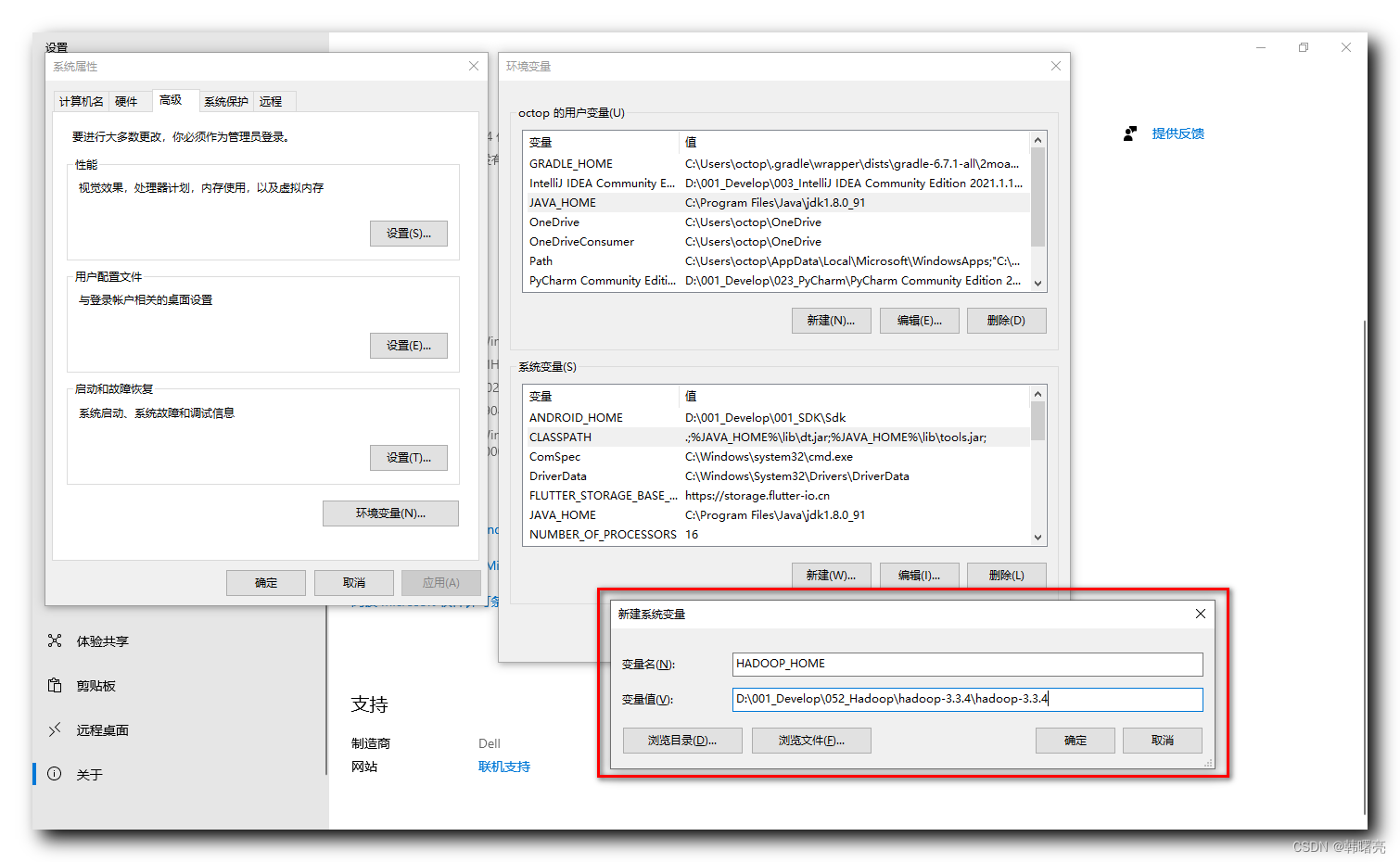
En la variable de entorno Ruta, agregue
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
Variable ambiental;
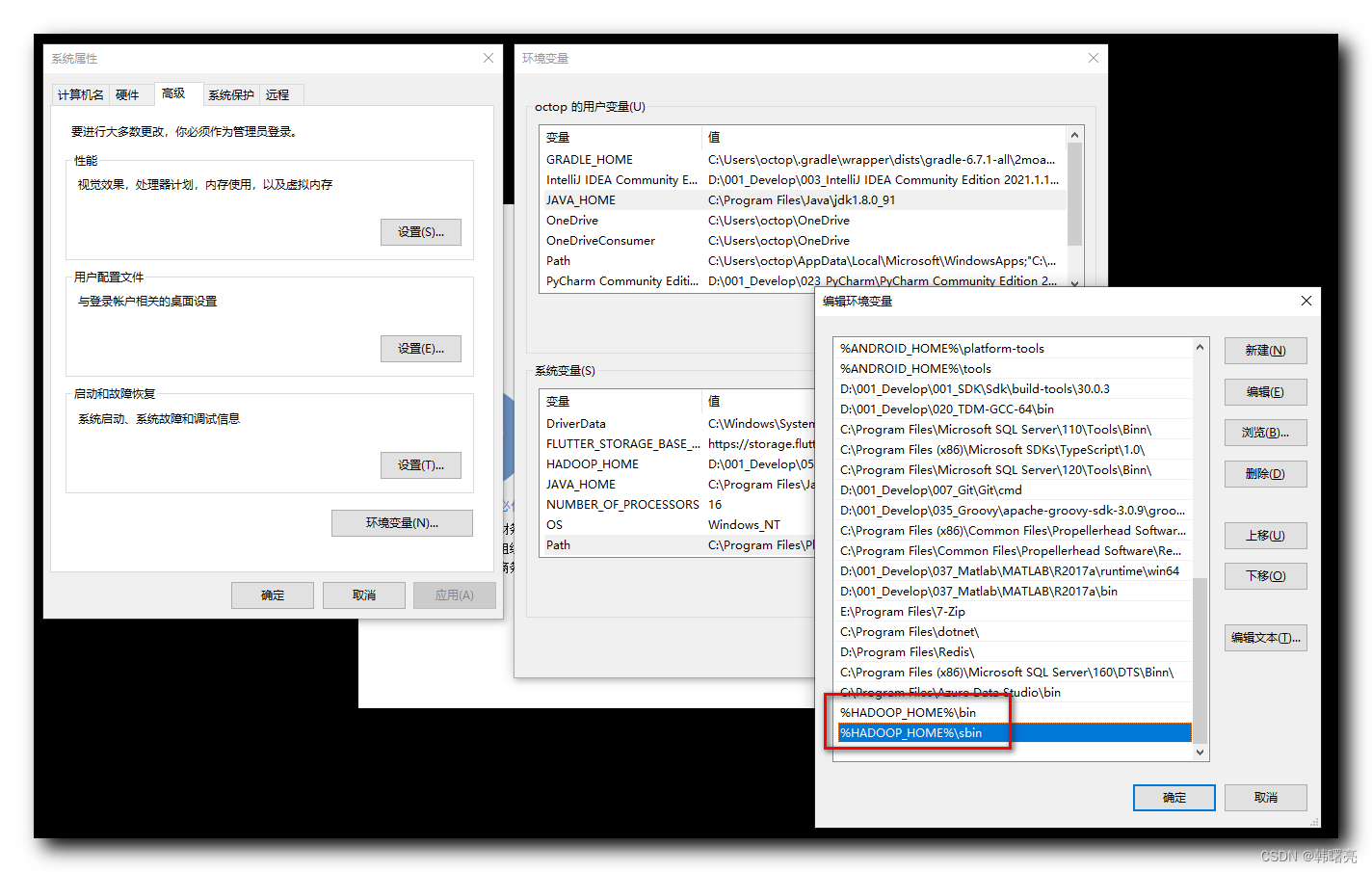
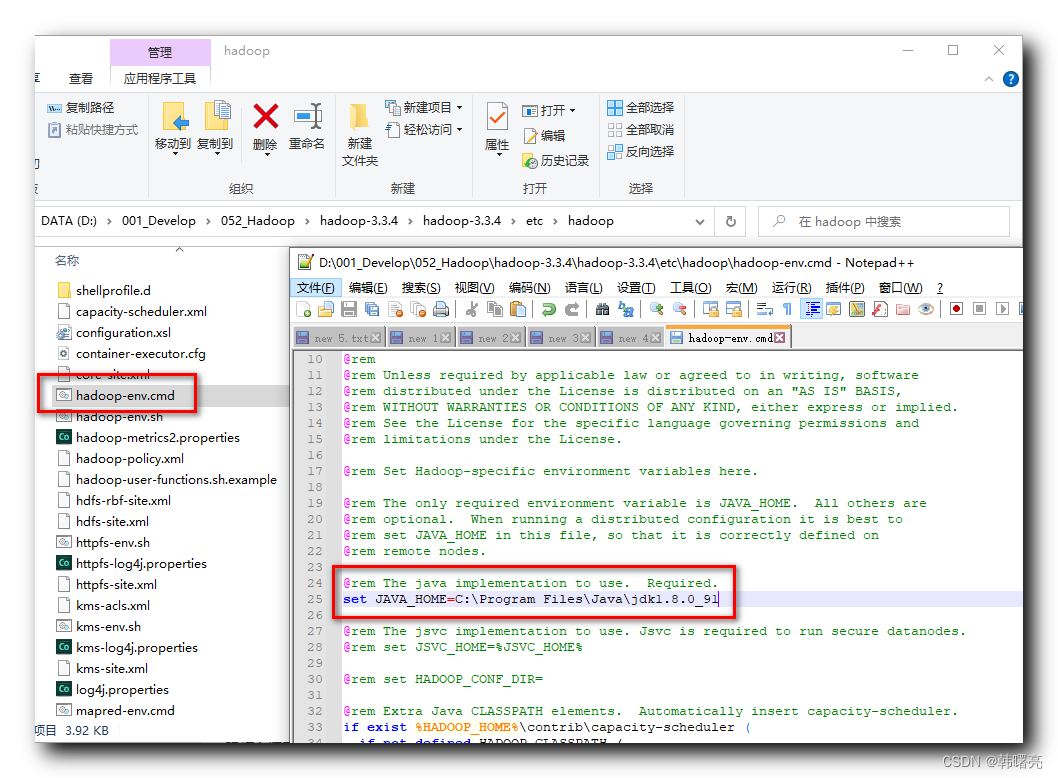
Establezca JAVA_HOME en el script D:\001_Develop\052_Hadoop\hadoop-3.3.4\hadoop-3.3.4\etc\hadoop\hadoop-env.cmd en la ruta real de JDK;
Voluntad
set JAVA_HOME=%JAVA_HOME%
cambie a
set JAVA_HOME=C:\Program Files\Java\jdk1.8.0_91
Copie los archivos hadoop.dll y winutils.exe en winutils-master\hadoop-3.3.0\bin en el directorio C:\Windows\System32;
Reinicie la computadora, asegúrese de reiniciar;
Luego, en la línea de comando, ejecute
hadoop -version
Verifique que Hadoop esté instalado;