Tabla de contenido
- Introducción Introducción
- Fondo
- idea principal
-
- Preprocesamiento de datos
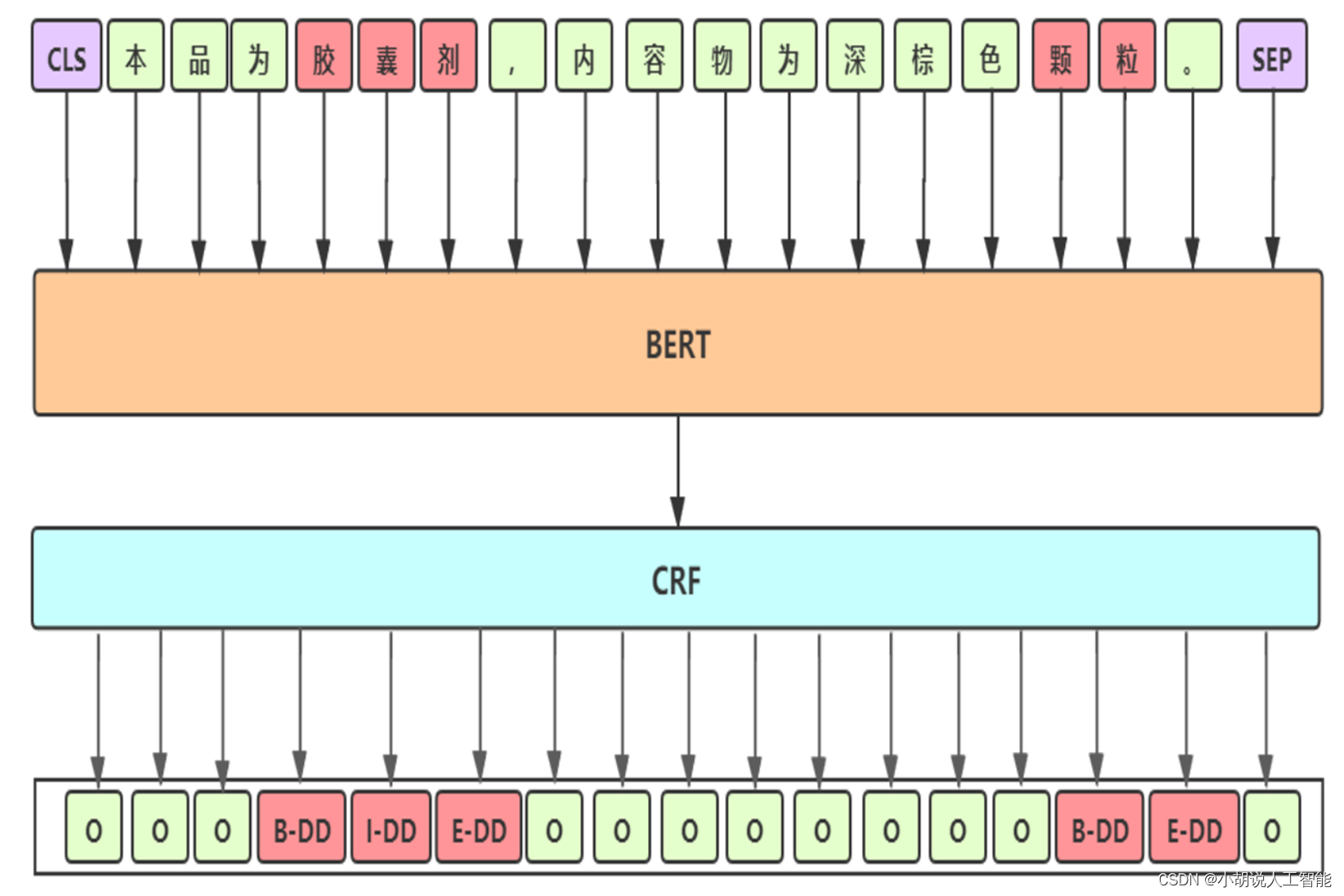
- Línea base: BERT-CRF
- Optimización 1: Entrenamiento adversario
- Optimización 2: Entrenamiento mixto de precisión (FP16)
- Optimización 3: Fusión multimodelo
- Optimización 4: aprendizaje semisupervisado
- Otros intentos sin mejoría significativa
- El puntaje final en línea es 72.90%, Rango 1 en la revancha y Rango 1 en la final
- Referencias
- Descarga de otra información
Introducción Introducción
La inteligencia artificial ha jugado un papel importante en la aceleración de la herencia y el desarrollo innovador del campo de la medicina tradicional china. Entre ellos, la extracción de información de texto de TCM es el componente central de la construcción del mapa de conocimiento de TCM, que sienta las bases para la construcción de aplicaciones de nivel superior como el sistema auxiliar de diagnóstico y tratamiento clínico (CDSS).
En este desafío NER, nuestro objetivo es extraer información clave de las instrucciones de las medicinas tradicionales chinas, incluidos 13 tipos de entidades como medicamentos, ingredientes medicinales, enfermedades, síntomas y síndromes, y construir una base de conocimiento de las medicinas tradicionales chinas.
Al aplicar técnicas de procesamiento de lenguaje natural y aprendizaje profundo, podemos realizar análisis semánticos y extracción de entidades en las instrucciones de medicamentos de la medicina tradicional china. Al entrenar el modelo, podemos identificar y extraer información importante, como nombres de medicamentos, ingredientes de medicamentos, enfermedades relacionadas, síntomas y síndromes, y almacenarlos en la base de conocimiento de medicamentos de la medicina tradicional china.
La creación de una base de conocimientos sobre los medicamentos de la MTC es de gran importancia para promover la investigación y la práctica clínica de la MTC. Esta base de conocimientos puede proporcionar información de referencia conveniente y rápida para los investigadores y médicos de la MTC para ayudarlos a obtener una comprensión más profunda de las características, la eficacia y el rango de aplicación de la MTC. Al mismo tiempo, la base de conocimientos también proporciona una base de datos para aplicaciones inteligentes en el campo de la medicina tradicional china, como la construcción de sistemas CDSS y otros sistemas de soporte de decisiones médicas.
El proyecto de código abierto esta vez es la solución campeona del Desafío de reconocimiento de entidades de instrucciones de medicina tradicional china de Tianchi Cinese-DeepNER-Pytorch.
Fondo
detalles de la misión
La inteligencia artificial ha jugado un papel importante en la herencia, innovación y desarrollo del campo de la medicina tradicional china, entre ellos, la extracción de información de los textos de medicina tradicional china es el componente central de la construcción de mapas de conocimiento de la medicina tradicional china. Esto proporciona una base para crear aplicaciones de nivel superior, como el sistema auxiliar de diagnóstico y tratamiento clínico (CDSS). El objetivo de este desafío de Reconocimiento de entidades nombradas (NER) es extraer información clave de las instrucciones de medicamentos de la MTC, incluidos 13 tipos de entidades como medicamentos, ingredientes de medicamentos, enfermedades, síntomas y síndromes, para construir una base de conocimiento de medicamentos de la MTC.
Exploración y análisis de datos
Los datos de entrenamiento para esta competición tienen tres características:
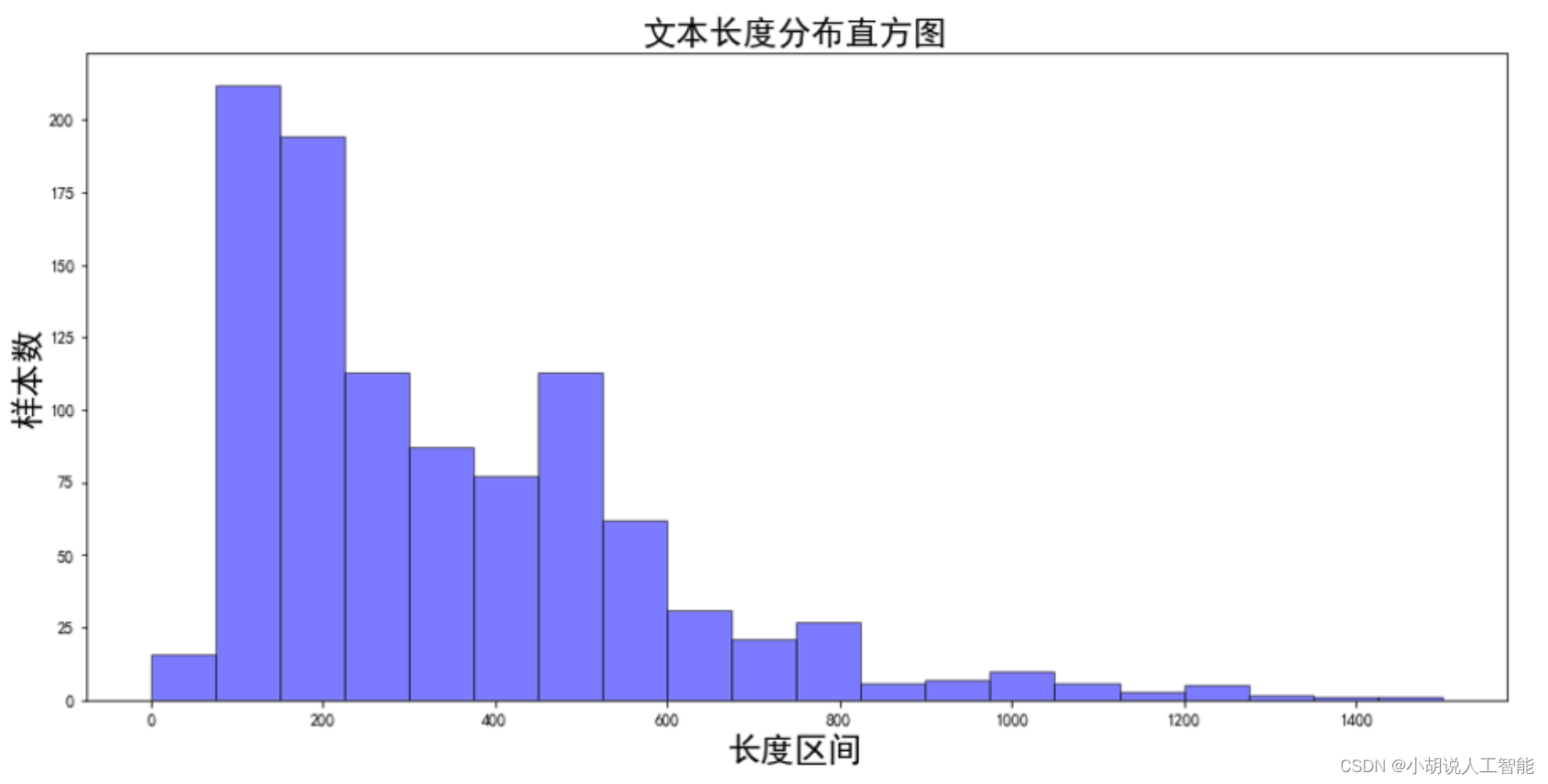
- La mayoría de las instrucciones de medicamentos de la medicina tradicional china se presentan en forma de texto extenso.
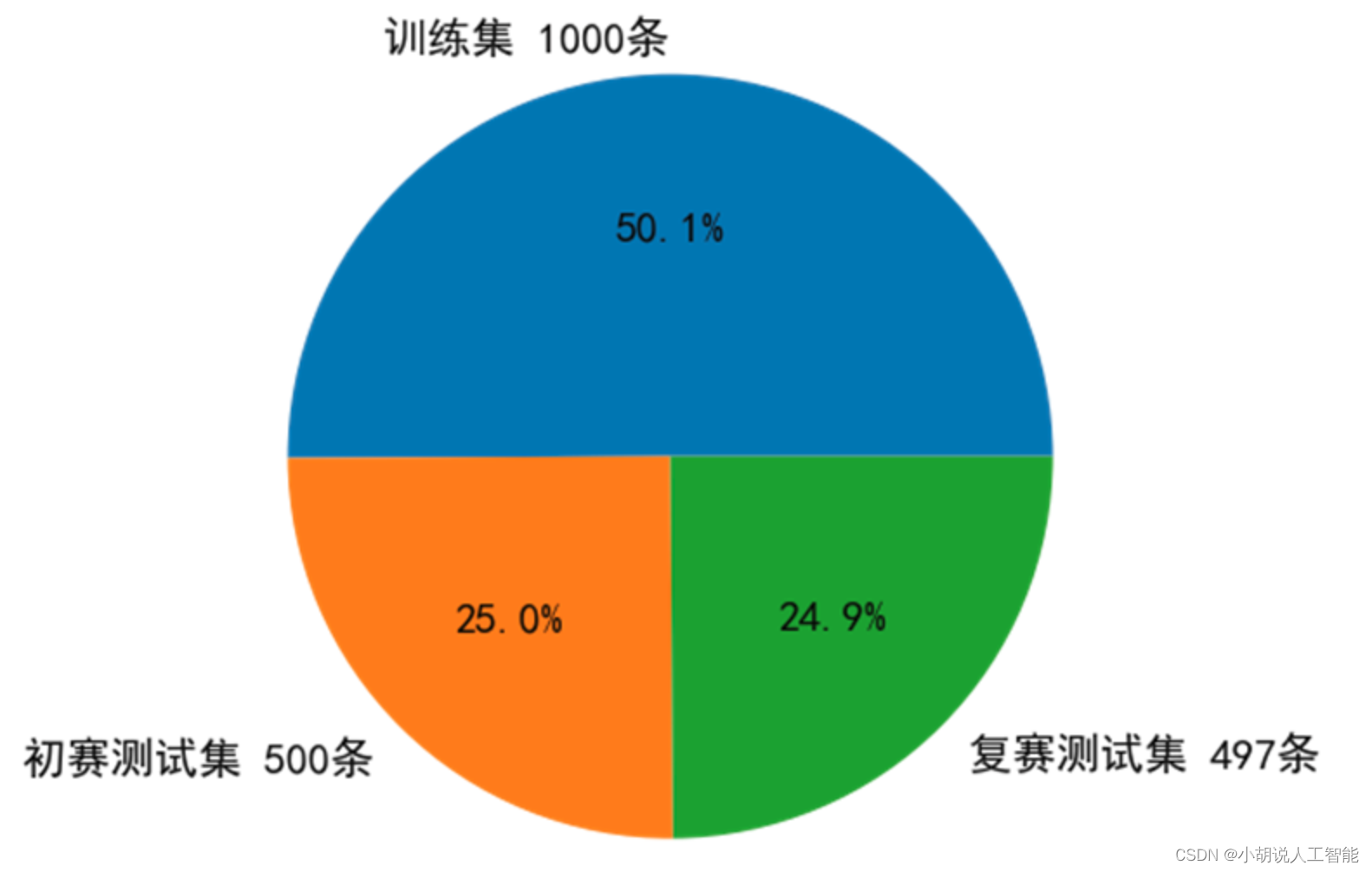
- En escenarios médicos, a menudo enfrentamos el desafío de muestras etiquetadas insuficientes
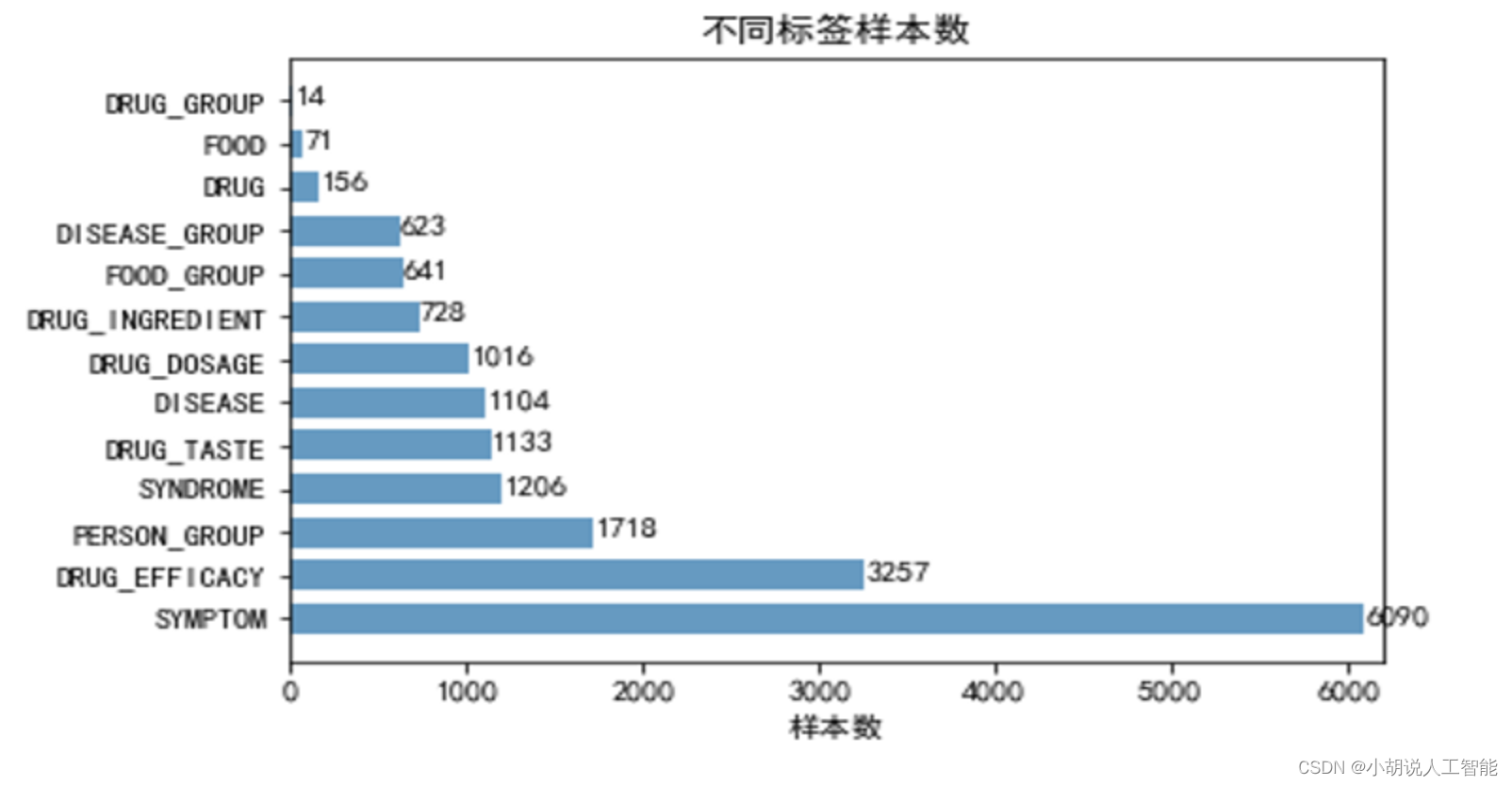
- En el campo médico, la distribución de etiquetas suele ser desequilibrada.
idea principal
Preprocesamiento de datos
En primer lugar, para el texto manual, debemos realizar una limpieza previa y una segmentación de texto largo. El objetivo de la etapa de limpieza previa es filtrar los caracteres no válidos y garantizar la precisión y usabilidad del texto. Para el problema de texto largo, adoptamos una estrategia de segmentación de texto de dos niveles. Al segmentar textos largos en oraciones más cortas, el contenido del texto se puede procesar y comprender mejor.
Sin embargo, dado que las oraciones segmentadas pueden ser demasiado cortas, debemos fusionar los textos cortos para garantizar que la longitud del texto fusionado no exceda la longitud máxima preestablecida. Esto mantiene la coherencia e integridad del texto.
Además, también podemos usar todos los datos etiquetados para construir bases de conocimiento de entidades como un diccionario a priori para el dominio. Tal base de conocimiento puede proporcionar información y contexto sobre las entidades, y proporcionar un fuerte apoyo y referencia para las tareas posteriores de extracción de entidades.
Línea base: BERT-CRF
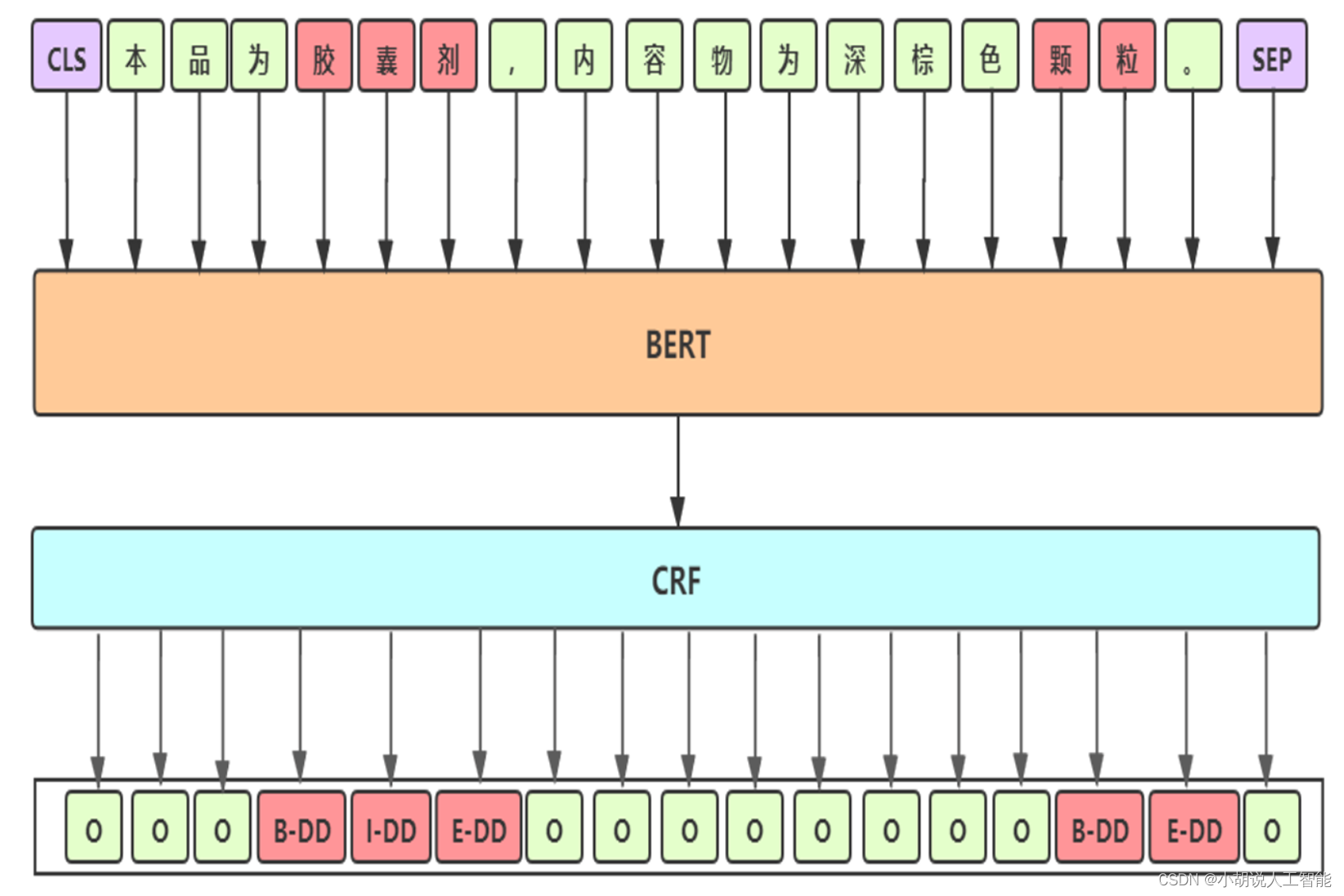
-
Detalles de línea de base
- Modelo de preentrenamiento: Seleccionado
UER-large-24 layer[1], UERRoBerta-wwmutiliza corpus chino de alta calidad a gran escala para continuar el entrenamiento bajo el marco, modo único primero en la tarea CLUE - Tasa de aprendizaje diferencial: tasa de aprendizaje de capa BERT
2e-5; tasa de aprendizaje de otra capa2e-3 - Inicialización de parámetros: otros módulos del modelo adoptan el mismo método de inicialización que BERT
- Promedio de parámetros deslizantes: promedio ponderado de los pesos de los últimos modelos de época para obtener un modelo más suave y con mejor rendimiento
- Modelo de preentrenamiento: Seleccionado
-
Análisis de casos malos de referencia
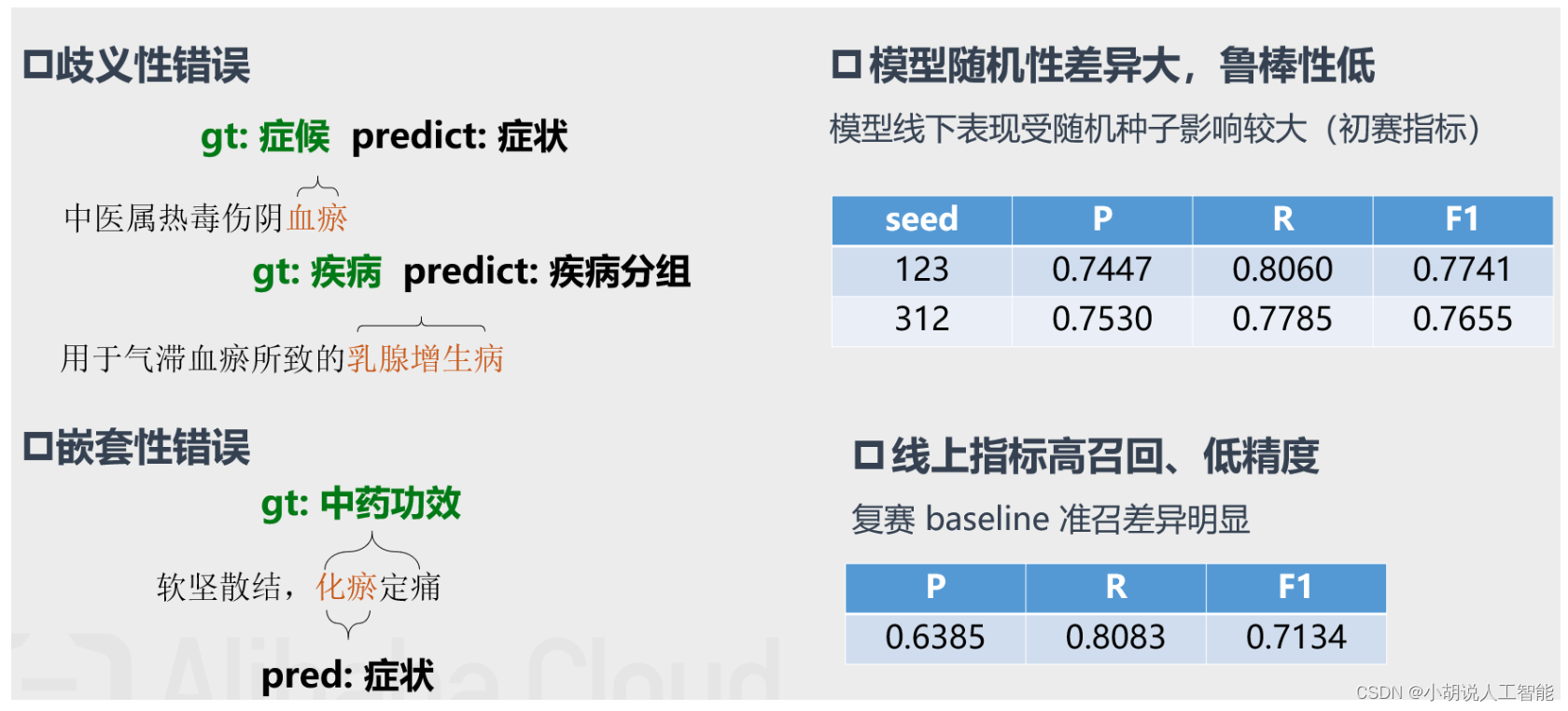
Optimización 1: Entrenamiento adversario
- Motivación: utilizar el entrenamiento de confrontación para aliviar el problema de la poca robustez del modelo y mejorar la capacidad de generalización del modelo
- El entrenamiento adversarial es un método de entrenamiento que introduce ruido, que puede regularizar los parámetros y mejorar la solidez del modelo y la capacidad de generalización.
- Método de gradiente rápido (FGM): agregue perturbaciones a la capa de incrustación en la dirección del gradiente
- Descenso de gradiente proyectado (PGD) [2]: Perturbación iterativa, cada perturbación se proyecta en el rango especificado
Optimización 2: Entrenamiento mixto de precisión (FP16)
- Motivación: el entrenamiento adversario reduce la eficiencia computacional, use entrenamiento de precisión mixto para optimizar el consumo de tiempo de entrenamiento
- Entrenamiento mixto de precisión
- Use FP16 para almacenamiento y multiplicación en la memoria para acelerar
- Use FP32 para hacer la acumulación para evitar errores de redondeo
- amplificación de pérdida
- Expanda la pérdida 2^k veces antes de la retropropagación para evitar que la pérdida se desborde
- Restaurar el gradiente de peso después de la retropropagación
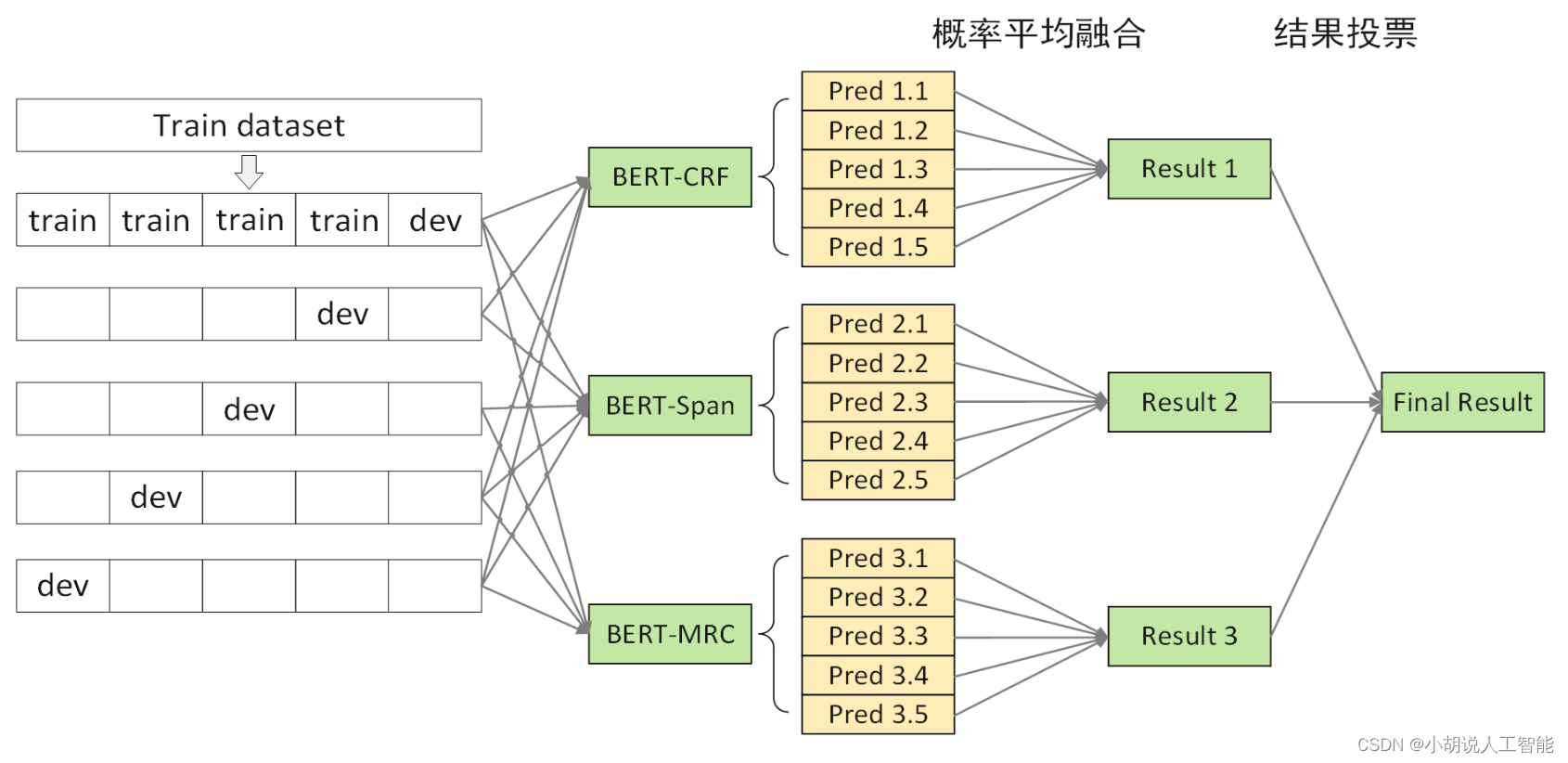
Optimización 3: Fusión multimodelo
-
Motivación: los errores de referencia se centran en los errores de ambigüedad, adoptar un sistema de reconocimiento de entidades nombradas médicas de varios niveles para eliminar la ambigüedad
-
Método: Un Sistema Diferenciado de Fusión de Modelos Multinivel
- Diferenciación del marco del modelo: BERT-CRF, BERT-SPAN y BERT-MRC
- Diferenciación de datos de entrenamiento: cambie la semilla aleatoria, cambie la longitud de segmentación de oraciones (256, 512)
- Estrategia de fusión de modelos multinivel
-
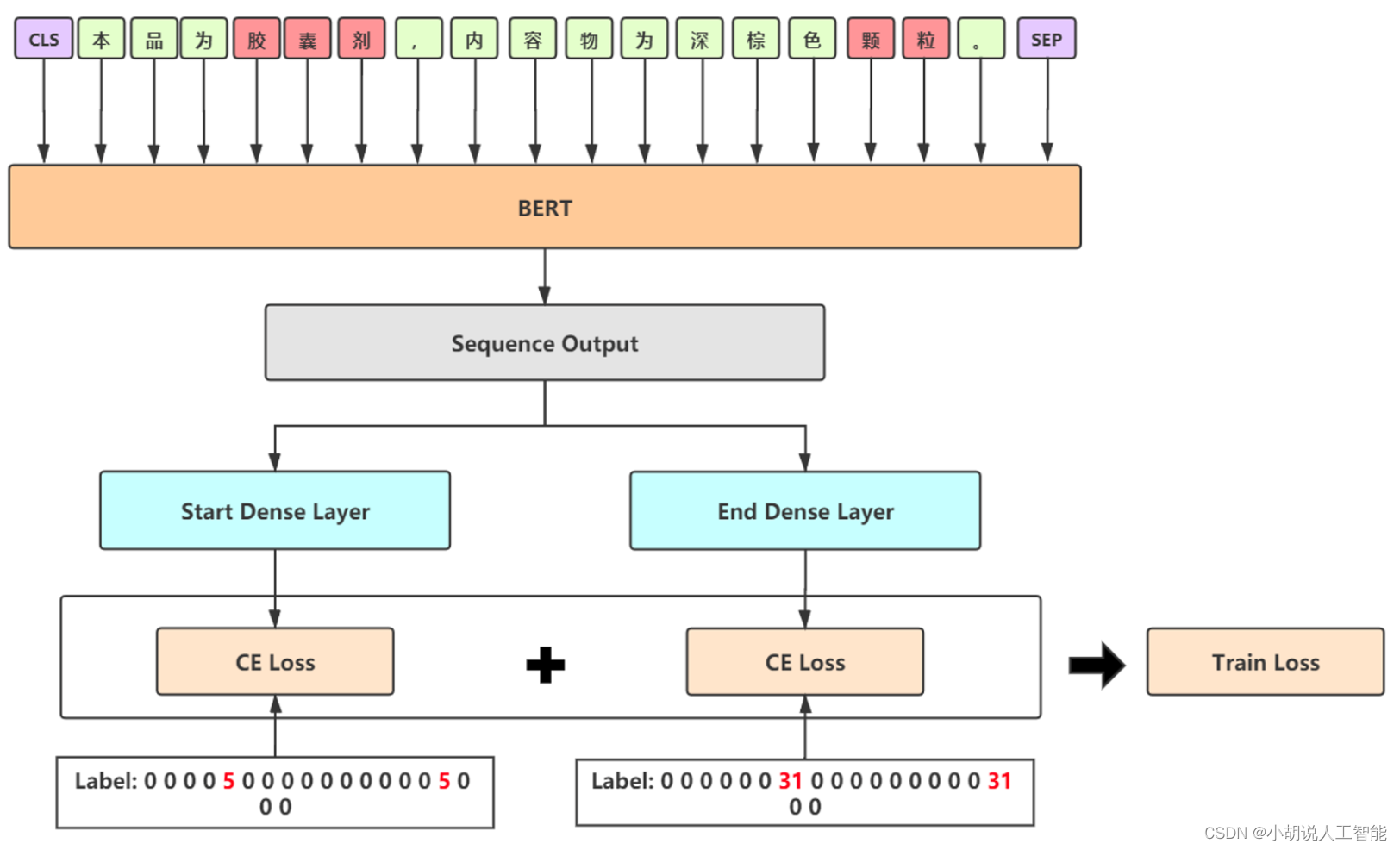
Fusión Modelo 1 - BERT-SPAN
- Use la forma de puntero SPAN para reemplazar el módulo CRF para acelerar la velocidad de entrenamiento
- Prediga la posición inicial de la entidad con una estructura de mitad de puntero, mitad de etiqueta y asigne la categoría de entidad durante el proceso de etiquetado
- Se adopta una decodificación estricta y la entidad superpuesta selecciona la que tiene los logits más grandes para garantizar la precisión.
- Use la etiqueta suave para aliviar los problemas de sobreajuste
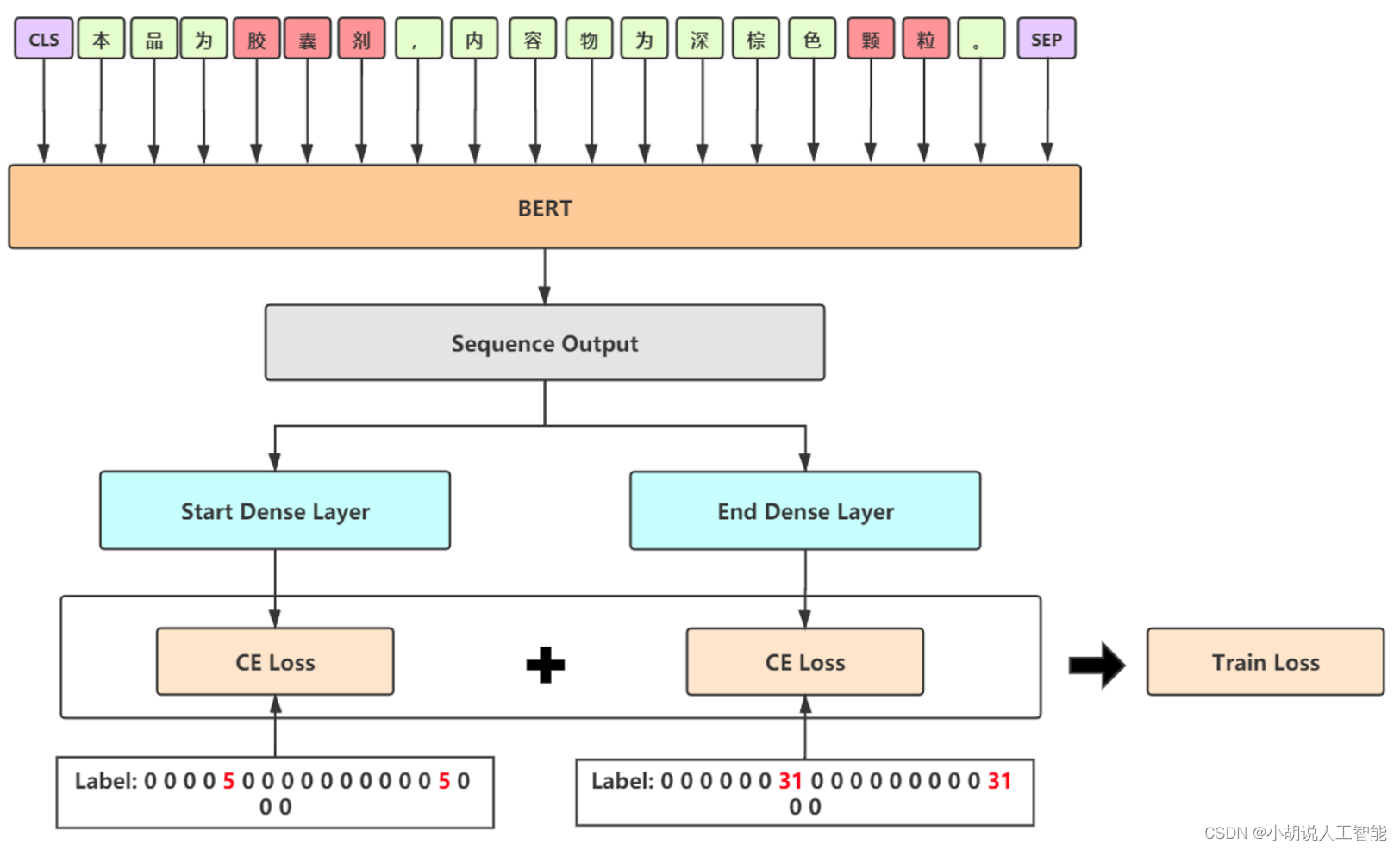
- Fusión Modelo 2 - BERT-MRC
- Procesamiento de tareas NER basadas en comprensión lectora
- consulta: la descripción del tipo de entidad como consulta
- doc: el texto original después de la oración se usa como doc
- Construya una muestra para cada tipo, hay una gran cantidad de muestras negativas durante el entrenamiento, puede seleccionar aleatoriamente el 30% para unirse al entrenamiento y descartar el resto para garantizar la eficiencia
- Al predecir, es necesario construir una muestra para cada categoría, y no hay límite para la salida de decodificación para garantizar la tasa de recuperación
- Use la etiqueta suave para aliviar los problemas de sobreajuste
- La precisión de MRC en este conjunto de datos no es buena y la eficiencia del entrenamiento y el razonamiento es baja. Solo se usa como una solución para mejorar la tasa de recuperación. El código proporcionado es solo para aprender y no se recomienda para el uso diario.
- Procesamiento de tareas NER basadas en comprensión lectora
- estrategia de fusión multinivel
- El modelo obtenido por validación cruzada de 5 veces CRF/SPAN/MRC se somete a la fusión de probabilidad de primer nivel, y los logits se promedian para decodificar la entidad
- El modelo después de la fusión de probabilidad CRF/SPAN/MRC realiza la fusión de votación de segundo nivel para obtener el resultado final
Optimización 4: aprendizaje semisupervisado
- Motivación: para aliviar el problema de la escasez de corpus etiquetados en escenarios médicos, utilizamos el aprendizaje semisupervisado (pseudo-etiqueta) para hacer un uso completo del conjunto de pruebas preliminares 500 sin etiquetar.
- Estrategia: pseudo-etiquetas dinámicas
- Primero entrene un modelo de referencia M utilizando datos etiquetados sin procesar
- Use el modelo de referencia M para predecir el conjunto de prueba preliminar para obtener pseudoetiquetas
- Agregue la pseudoetiqueta al conjunto de entrenamiento, asigne a la pseudoetiqueta un peso de aprendizaje dinámico (alfa en la figura) y únase a los datos de la etiqueta real para el entrenamiento conjunto para obtener el modelo M'
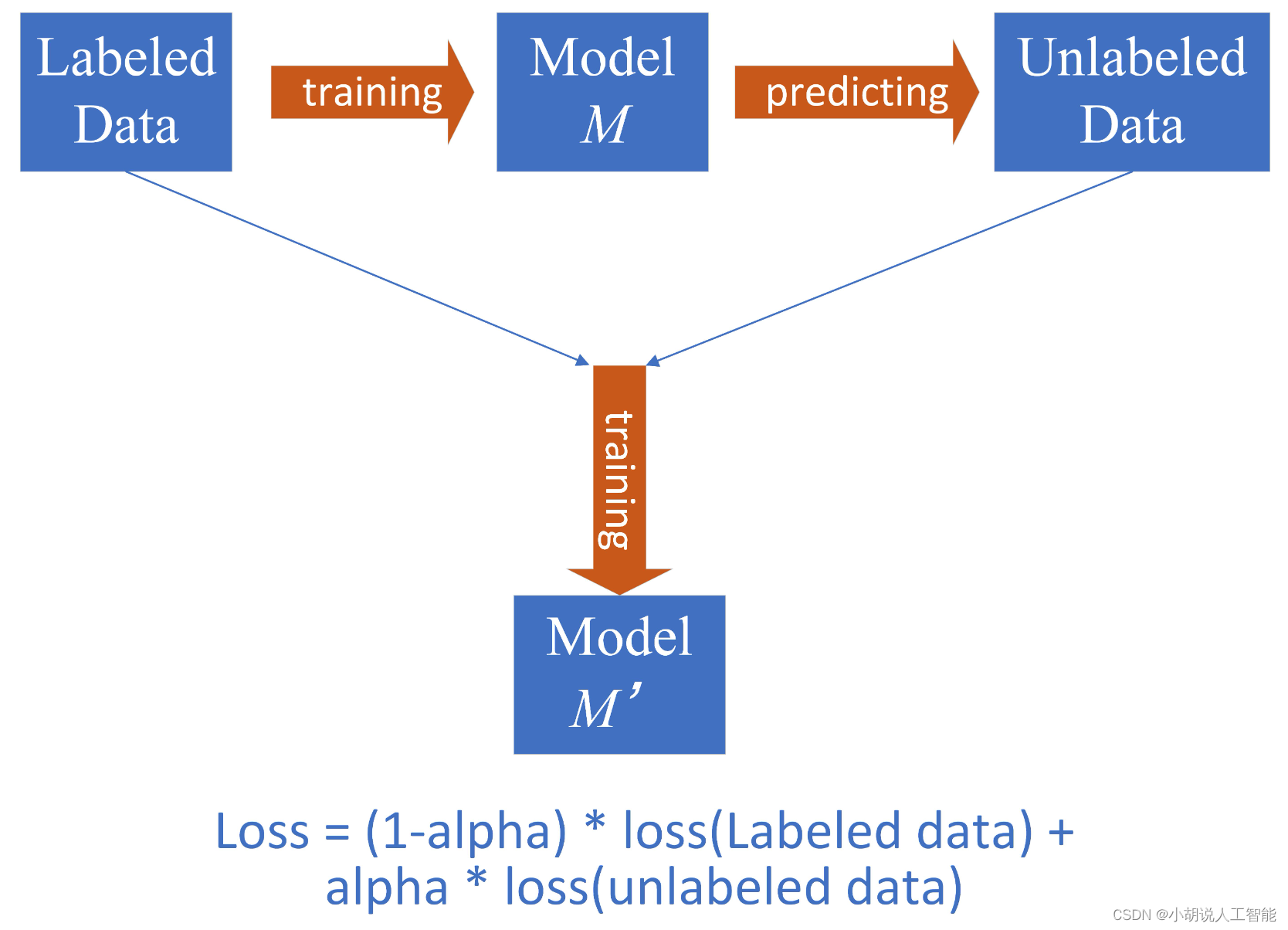
- consejos: use el modelo de referencia de fusión multimodo para reducir el ruido de la pseudoetiqueta; el peso también se puede arreglar y elegir cuál necesita probar más para obtener el mejor efecto. En esencia, es para reducir el pérdida de peso de la pseudoetiqueta, que es un método para aliviar el ruido de la pseudoetiqueta.
Otros intentos sin mejoría significativa
- Después de tomar BERT, la salida ponderada dinámica de cuatro capas no tiene una mejora obvia
- Agregue el módulo BiLSTM / IDCNN después de la salida BERT, el sobreajuste es grave y la velocidad de entrenamiento se reduce considerablemente
- Mejora de datos, reemplazo aleatorio de palabras de entidades similares para expandir los datos de entrenamiento
- El modelo BERT-SPAN/MRC utiliza pérdida focal/pérdida de dados para aliviar el desequilibrio de la etiqueta
- Uso del diccionario de dominio construido para revisar el resultado del modelo
El puntaje final en línea es 72.90%, Rango 1 en la revancha y Rango 1 en la final
Referencias
[1] Zhao et al., UER: An Open-Source Toolkit for Pre-training Models, EMNLP-IJCNLP, 2019. [2] Madry et al.,
Towards Deep Learning Models Resistant to Adversarial Attacks, ICLR, 2018.
[3 ] ] Instrucciones de medicina tradicional china de Tianchi Desafío de reconocimiento de entidad Solución de campeón Código abierto
Descarga de otra información
Si desea continuar aprendiendo sobre rutas de aprendizaje y sistemas de conocimiento relacionados con la inteligencia artificial, bienvenido a leer mi otro blog " Pesado | Ruta de aprendizaje de conocimiento básico de aprendizaje de inteligencia artificial completa, todos los materiales se pueden descargar directamente desde el disco de la red sin pagar atención a las rutinas "
Este blog se refiere a la conocida plataforma de código abierto de Github, la plataforma de tecnología de IA y expertos en campos relacionados: Datawhale, ApacheCN, AI Youdao y Dr. Huang Haiguang, etc. Hay alrededor de 100G de materiales relacionados, y espero ayuda a todos tus amigos.