A Reunião Anual da Association for Computational Linguistics (ACL) é a principal conferência internacional na área de processamento de linguagem natural (NLP). A ACL 2023 será realizada em Toronto, Canadá, de 9 a 14 de julho de 2023. Com o rápido desenvolvimento da tecnologia de inteligência artificial, garantir que as tecnologias relacionadas possam ser confiáveis para as pessoas é um problema que precisa ser resolvido. A Microsoft Research Asia também está promovendo continuamente a exploração, descoberta e aplicação de inteligência artificial responsável. Hoje trazemos três artigos da Microsoft Research Asia que foram selecionados para o ACL 2023 sobre o tema da inteligência artificial responsável.
DuNST: Geração de texto semi-supervisionada e controlável com autoaprendizagem dupla baseada em ruído

Link do artigo: https://arxiv.org/abs/2212.08724
Nos últimos anos, com a ampla aplicação de modelos de linguagem grandes (LLMs), a construção de inteligência artificial responsável tornou-se um tópico importante. A geração de texto imparcial e não tóxico é um requisito fundamental para modelos generativos. Como uma tarefa clássica e quente no campo do processamento de linguagem natural (NLP), a geração de texto controlável tem aplicações importantes na desintoxicação e eliminação de viés de texto. Recentemente, o método convencional adotado por muitas tarefas de NLP em grandes modelos de linguagem pré-treinados é o ajuste fino.No entanto, o aumento do tamanho do modelo requer mais dados de treinamento e a grave escassez de dados rotulados levará a resultados de ajuste fino instáveis. O autotreinamento é um meio eficaz para resolver o problema da escassez de dados na geração de texto controlável e gradualmente atraiu a atenção dos pesquisadores. Em cada iteração, o autoaprendizado usa o classificador para gerar pseudo-rótulos para os dados não rotulados e, em seguida, usa os dados aprimorados para treinar iterativamente o classificador. Desta forma, a autoaprendizagem pode usar dados não rotulados para melhorar ainda mais o limite de classificação e melhorar a generalização em dados reais.
A pesquisa existente se concentra principalmente em tarefas de classificação de texto de autoaprendizagem, mas ainda existem muitos desafios na aplicação da autoaprendizagem à geração de texto controlável. Primeiro, os dados de texto de uma determinada categoria podem estar em branco. Em segundo lugar, com o aumento apenas por pseudotextos gerados automaticamente, o espaço de texto aprendido anteriormente será superutilizado, portanto, o modelo ignorará outros espaços de texto, resultando no colapso do espaço de texto e na deterioração da qualidade da geração de texto.
Para resolver os problemas acima, os pesquisadores propuseram uma nova estrutura de autoaprendizagem, DuNST. O DuNST modela conjuntamente a geração e classificação de texto como um processo duplo e melhora a geração e classificação do modelo por meio da autoaprendizagem. Além do pseudotexto gerado pelo gerador, os pesquisadores também usaram o classificador para pseudorotular o texto não rotulado. Além disso, o modelo perturba o espaço de texto aprendido adicionando dois ruídos suaves. O ruído adicionado pode ajudar o modelo a melhorar a suavidade local do espaço de texto e aumentar a robustez do modelo. Em teoria, DuNST pode ser visto como um equilíbrio entre Exploração e Exploração. A adição de ruído aumenta a exploração de um espaço de texto real potencialmente maior, mantendo a utilização do espaço de texto já aprendido, garantindo assim o desempenho do modelo.
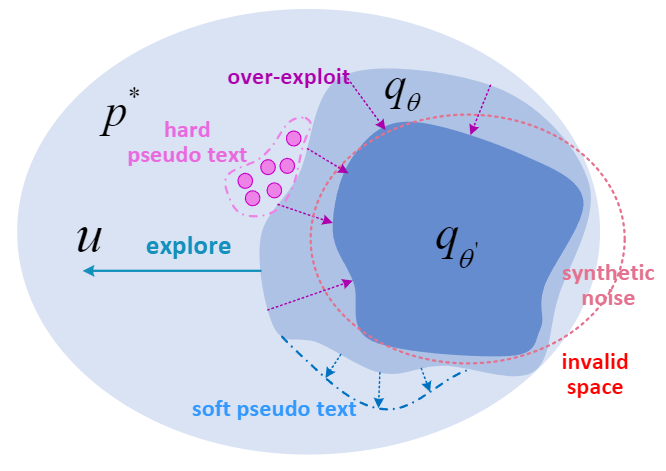
Figura 1: DuNST mantém um equilíbrio de exploração e exploração por autoaprendizagem e adição de ruído.
Os resultados experimentais em três tarefas de geração controlável semi-supervisionadas mostram que o DuNST melhora significativamente a precisão do controle e a diversidade da geração de texto, mantendo a fluência e a generalização da geração, em comparação com os métodos tradicionais de autoaprendizagem. Na tarefa de desintoxicação de texto, em comparação com modelos de linha de base de ajuste fino (como GPT2, UniLM, etc.), o DuNST reduz significativamente a toxicidade do texto gerado em cerca de 60% e mantém uma alta qualidade de geração. Este método fornece uma solução eficaz e de baixo custo para desintoxicação de texto.
EmbMarker: proteção de direitos autorais de serviços de representação de vetores baseados em modelos grandes por meio de marca d'água backdoor

Link do artigo: https://arxiv.org/abs/2305.10036
Link do código: https://github.com/yjw1029/EmbMarker
Os LLMs mostraram fortes capacidades na compreensão e geração de texto. Portanto, muitas empresas começam a fornecer serviços de representação vetorial (EaaS) com base nesses LLMs para ajudar os clientes a concluir várias tarefas de NLP. No entanto, pesquisas existentes mostram que os usuários podem reconstruir os parâmetros do modelo enviando consultas e recebendo saídas, o que expõe os provedores de serviços LLM ao risco de roubo ou duplicação do modelo.
Marca d'água é um método comumente usado para proteção de direitos autorais do modelo. No entanto, nenhuma das marcas d'água existentes é adequada para EaaS. Portanto, é necessário propor um método de marca d'água adequado para EaaS. Esse tipo de método precisa atender às seguintes condições: 1. Não afeta o desempenho do vetor em tarefas de downstream; 2. Quando um pirata copia o modelo do provedor e fornece o mesmo serviço competitivo, o provedor pode verificar sua A saída contém a marca d'água do provedor 3. A marca d'água precisa ser escondida o suficiente para que não possa ser facilmente filtrada por piratas.
Para resolver esses problemas, os pesquisadores propuseram um método baseado na marca d'água backdoor: EmbMarker. O EmbMarker consiste em duas fases: fase de inserção de marca d'água e fase de verificação de direitos autorais. No estágio de inserção de marca d'água, os pesquisadores primeiro encontram um conjunto de palavras com frequência de palavra apropriada como palavras de gatilho e predefinem um vetor de destino como marca d'água. Quando a sentença fornecida pelo usuário contém mais palavras-gatilho, a distância entre o vetor enviado pelo provedor de serviços e o vetor-alvo pré-definido é menor. Na etapa de verificação de direitos autorais, o provedor pode usar palavras-gatilho e palavras-não-gatilho para construir dois conjuntos de sentenças e acessar o serviço a ser verificado para obter dois conjuntos de vetores. Quanto maior for o intervalo de distribuição de distância entre os dois grupos de vetores e o vetor de destino, maior a probabilidade de o modelo após o serviço desviar ou copiar o modelo do provedor. Resultados experimentais em vários conjuntos de dados demonstram que o EmbMarker pode verificar marcas d'água em serviços piratas com alta confiança, sem comprometer o desempenho do vetor em tarefas downstream e tem forte ocultação.
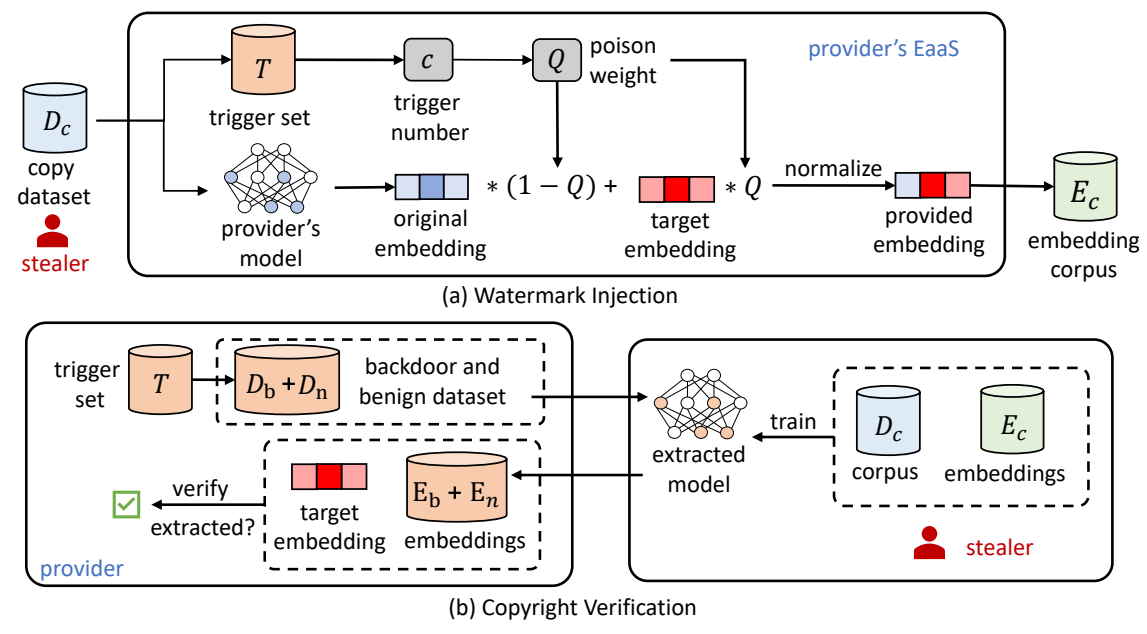
Figura 2: A estrutura do EmbMarker
GLUE-X: Um conjunto de testes para modelos de compreensão de linguagem natural com base na generalização fora da distribuição

Link do artigo: https://arxiv.org/abs/2211.08073
Muitos campos do aprendizado de máquina enfrentam um desafio comum: a avaliação. Nos últimos anos, embora o aprendizado de máquina tenha avançado bastante, com o aprofundamento das pesquisas, os pesquisadores constataram que a generalização desses avanços não é tão boa quanto o esperado. A avaliação de modelos de linguagem tradicionais depende principalmente da tabela de classificação GLUE. Até 2022, houve mais de 20 resultados de modelo único que superaram a avaliação manual na avaliação GLUE. Trabalhos anteriores provaram que o desempenho do modelo não é realmente superior ao dos humanos, mas depende de recursos espúrios e aprendizado de atalho para alcançar resultados inflacionados. Portanto, como a capacidade de ajuste do modelo melhorou muito hoje, o valor real da lista GLUE, que depende do teste tradicional no domínio como um indicador de avaliação na prática, é baixo. Portanto, é necessário contar com Out of Distribution (OOD) para testar a verdadeira capacidade de generalização do modelo. Em avaliações de generalização anteriores, os pesquisadores geralmente selecionam conjuntos de dados para testar em 1-2 tarefas, faltando uma referência para avaliar de forma abrangente os recursos de generalização do modelo, como GLUE-X. Ao contrário do GLUE, o melhor modelo atual ainda apresenta um desempenho significativamente inferior aos humanos no GLUE-X (74,6% vs. 80,4%).
O que é generalização fora da distribuição?
Suponha que você tenha um conjunto de dados rotulado. Gere um conjunto de dados de treinamento D_train = {(X_train, Y_train)} amostrando D da distribuição P_train. O conjunto de dados de teste D_test = {(X_test, Y_test)} é amostrado de D de acordo com a distribuição P_test. Quando P_train ≠ P_test, é chamada de generalização fora da distribuição.
Além disso, com o uso generalizado de inteligência artificial hoje, a construção de inteligência artificial responsável requer robustez suficiente do modelo. No entanto, em pesquisas anteriores sobre PNL, OOD não recebeu atenção suficiente e carece de um benchmark de avaliação unificado, o que limita a aplicação de sistemas de PNL no mundo real.
Para construir um benchmark unificado para generalização do modelo, os pesquisadores criaram um benchmark chamado GLUE-X. Primeiro, os pesquisadores usaram o conjunto de dados incluído no GLUE como o conjunto de treinamento no domínio e construíram 14 conjuntos de dados de texto para testes OOD em 8 tarefas de classificação de texto. Em seguida, em 21 modelos de pré-treinamento comumente usados (incluindo InstructGPT e GPT 3.5), use o conjunto de treinamento no campo para ajustar os parâmetros e, após obter o modelo com o melhor desempenho no campo, teste-o no conjunto de dados de texto OOD O desempenho nos dados é usado como um indicador da capacidade de generalização do modelo, e os resultados da avaliação humana são fornecidos como referência. Além disso, os pesquisadores também compararam o impacto de diferentes métodos de ajuste fino no desempenho de generalização do modelo e usaram o Racional "pós-análise" para descobrir a base racional para o modelo fazer julgamentos sobre dados OOD e compararam e analisou-o com dados rotulados manualmente. Ajuda os pesquisadores a entender as fontes da capacidade de generalização do modelo.

Conforme mostrado na Figura 3, os pesquisadores construíram dados OOD correspondentes para cada tarefa que apareceu no GLUE. Por exemplo, para análise de sentimento, dados SST-2, IMDB, Yelp, Amazon e Flipkart são selecionados como dados de teste. Para os dados COLA de julgamento gramatical, o teste de gramática auto-coletado (perguntas do exame) foi selecionado como os dados do teste. GLUE-X contém um total de 15 conjuntos de dados de teste de generalização com mais de 6 milhões de peças. Com base nisso, os pesquisadores conduziram testes de dados completos em PLMs comuns. Testes de amostra também foram realizados no InstructGPT e no ChatGPT.

Figura 3: Resultados do teste para diferentes tarefas OOD
o resultado do experimento mostra:
(1) Seja o melhor modelo de aprendizado supervisionado ou o modelo grande ChatGPT, o desempenho no GLUE-X é muito inferior ao dos humanos. Vale a pena notar que a avaliação humana também é realizada sob condições OOD (somente dados humanos no domínio são fornecidos como exemplos de treinamento).
(2) Nenhum modelo pode liderar todas as tarefas, o que é consistente com as conclusões da pesquisa no campo da visão computacional.
(3) O impacto da robustez OOD da arquitetura do modelo é mais importante do que o tamanho dos parâmetros do modelo. A estrutura do modelo é mais influente no tratamento de entradas imprevistas.
(4) Para tarefas de classificação de texto, o desempenho de ID e OOD está linearmente relacionado na maioria dos casos, ou seja, se ele executa bem em uma distribuição de dados conhecida, também pode ter um desempenho melhor em uma distribuição de dados desconhecida.
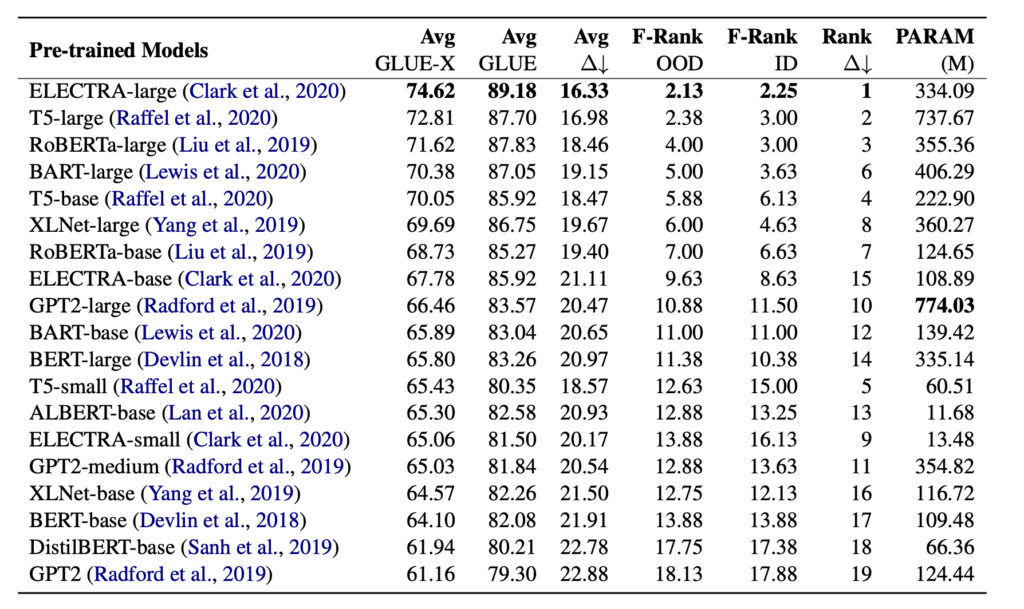
Tabela 1: Desempenho de diferentes modelos no GLUE-X