Nota del editor: los compiladores han sido un tema de investigación importante en la ciencia informática tradicional. Hoy, con el rápido desarrollo y la amplia aplicación de la tecnología de inteligencia artificial, los modelos de inteligencia artificial deben implementarse en una variedad de arquitecturas de hardware de computadora. Al mismo tiempo, al entrenar e implementar modelos de inteligencia artificial a gran escala, existen mayores requisitos para el rendimiento del hardware y, a veces, es necesario personalizar el código de acuerdo con el hardware. Todos estos presentan requisitos nuevos y más altos para los compiladores en la era de la inteligencia artificial.
Con el fin de satisfacer las necesidades de modelos de inteligencia artificial y hardware acelerado en rápido desarrollo, Microsoft Research Asia tiene como objetivo diseñar y construir una arquitectura de compilador de IA altamente flexible, eficiente y escalable, realizar investigaciones con colaboradores en el país y en el extranjero y proponer un conjunto de métodos sistemáticos. Las soluciones que incluyen cuatro compiladores de IA: Rammer, Roller, Welder y Grinder resolverán varios problemas importantes, como mejorar la utilización paralela del hardware, mejorar la eficiencia de compilación, optimizar la eficiencia de acceso a la memoria global y optimizar la ejecución eficiente del flujo de control. Cuatro documentos relacionados han sido aceptados por las conferencias OSDI en 2020, 2022 y 2023.
La compilación es un paso importante en el desarrollo de programas: traducir el código fuente escrito en un lenguaje de alto nivel en un código de máquina ejecutable en el hardware de la computadora, y un compilador es un programa de aplicación especial que implementa esta función. Hoy en día, la tecnología de inteligencia artificial y los modelos grandes son, sin duda, los C-bits en el campo informático actual, y sus propias características también plantean nuevos desafíos a los compiladores.
Desde el RNN original, CNN hasta Transformer, la arquitectura del modelo principal de inteligencia artificial cambia constantemente, lo que significa que las aplicaciones de nivel superior también cambian en consecuencia. Al mismo tiempo, el hardware acelerador subyacente, como GPU, NPU, etc., también se actualiza rápidamente de forma iterativa, y algunos diseños de hardware nuevos incluso subvierten la arquitectura anterior. Luego, para que el nuevo modelo de inteligencia artificial funcione mejor en nuevos chips y otro hardware informático, se necesita un nuevo compilador de IA.
En este sentido, investigadores del Instituto de Investigación de Microsoft Asia y colaboradores nacionales y extranjeros han llevado a cabo una serie de trabajos de investigación en torno a los problemas centrales de los compiladores de IA y, sucesivamente, lanzaron la "tetralogía industrial de metales pesados" en el mundo de los compiladores de IA. : Rammer, Roller, Welder, Grinder, brindan soluciones sistemáticas e innovadoras para los modelos actuales de inteligencia artificial y la compilación de hardware.
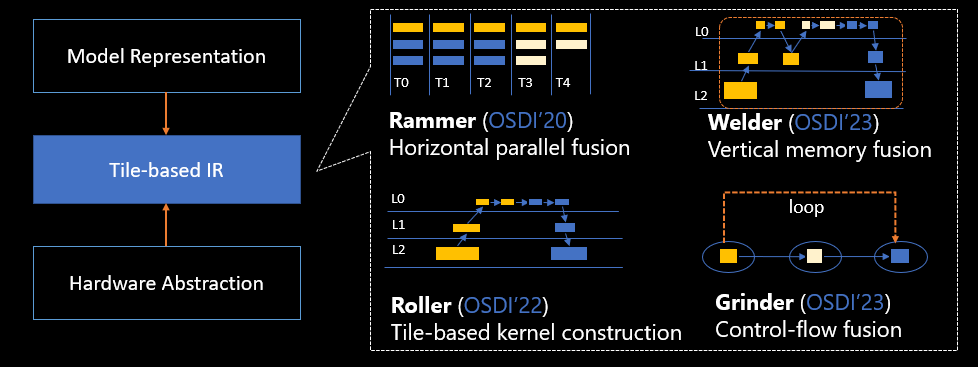
Cuatro tecnologías principales de compilación de IA basadas en la abstracción unificada de mosaicos
Compilación de IA "Rammer" Rammer: mejora la utilización paralela del hardware
Las redes neuronales profundas (DNN) son actualmente métodos ampliamente adoptados en la clasificación de imágenes, el procesamiento del lenguaje natural y muchas otras tareas de inteligencia artificial. Debido a su importancia, muchos dispositivos informáticos como CPU, GPU, FPGA y aceleradores DNN especialmente diseñados se utilizan para realizar cálculos DNN. Uno de los factores clave que afectan la eficiencia computacional de las DNN es la programación, que consiste en determinar el orden en que se ejecutan varias tareas computacionales en el hardware de destino. Los marcos y compiladores de DNN existentes generalmente tratan a los operadores de DNN en el gráfico de flujo de datos como funciones de biblioteca opaca y los envían al acelerador para su ejecución por separado. Al mismo tiempo, este proceso también se basa en otra capa de programadores (generalmente implementados en hardware) para aprovechar el paralelismo disponible en los operadores. Este enfoque de dos niveles genera una sobrecarga de programación significativa y, a menudo, no utiliza completamente los recursos de hardware disponibles.
Con este fin, los investigadores propusieron un nuevo compilador de DNN, Rammer, que puede optimizar la ejecución de cargas de trabajo de DNN en aceleradores paralelos masivos. De hecho, podemos imaginar el espacio de programación para la compilación de IA como un espacio bidimensional y pensar en las tareas informáticas como "ladrillos" que se pueden dividir en diferentes tamaños y formas. Estos "ladrillos" están dispuestos de cerca en la unidad informática como una pared, y la unidad de cómputo se usa en la mayor medida sin dejar espacios, porque una vez que hay un espacio, no solo el espacio existente no se utilizará de manera efectiva, sino que también la "pared" se verá afectada "velocidad. Y Rammer es una "máquina embestida" en este espacio bidimensional. Después de traducir el programa DNN en "ladrillos", se puede colocar en diferentes unidades informáticas del chip para compactarlos.
Marco técnico del apisonador
En otras palabras, Rammer genera un programa espaciotemporal estático eficiente para las DNN en el momento de la compilación, lo que minimiza la sobrecarga de programación. Al mismo tiempo, al proponer varias abstracciones nuevas independientes del hardware para tareas informáticas y aceleradores de hardware, Rammer obtuvo un espacio de programación más rico y realizó una programación cooperativa entre operadores y dentro de los operadores, de modo que el paralelismo se puede utilizar por completo. Estos métodos novedosos y heurísticos permiten a Rammer explorar mejor el espacio y encontrar horarios eficientes, lo que mejora en gran medida la utilización del hardware.
Los investigadores probaron Rammer en múltiples backends de hardware, incluidas las GPU NVIDIA, las GPU AMD y las IPU Graphcore. Los experimentos muestran que Rammer supera significativamente a los compiladores de última generación como XLA y TVM en GPU NVIDIA y AMD, con una aceleración de hasta 20,1 veces. En comparación con TensorRT, la biblioteca de razonamiento DNN patentada de NVIDIA, la tasa de aceleración es 3,1 veces.
论文:Rammer: habilitación de optimizaciones holísticas del compilador de aprendizaje profundo con rTasks
Roller "Roller" de compilación de IA: mejora la eficiencia de la compilación
No solo hay unidades de cómputo paralelas en el chip de la computadora, sino también múltiples capas de memoria. Una gran tarea de cómputo debe pasar capa por capa y, en el proceso, la tarea se divide en "ladrillos" más pequeños capa por capa. y finalmente entregado al procesador superior para el cálculo. La dificultad radica en cómo llenar el espacio de la memoria con grandes "ladrillos", para hacer un mejor uso de la memoria y mejorar la eficiencia. El método existente es buscar a través del aprendizaje automático para encontrar una mejor estrategia de segmentación de "ladrillos", pero esto generalmente requiere miles de pasos de búsqueda, cada paso se evalúa en el acelerador para encontrar una solución razonable, por lo que esto llevará mucho tiempo. , como la compilación de un modelo completo, incluso puede llevar días o semanas.
Los investigadores creen que después de conocer los parámetros de la lógica de cómputo y cada capa de memoria, es decir, conocer la información del software y del hardware, es posible estimar el mejor método y tamaño del corte del "ladrillo", para lograr un corte más rápido. compilar. Esta es también la idea de diseño de Roller. Es equivalente a un rodillo compactador. Bajo la premisa de considerar las características de la memoria, convierte datos de tensor de alta dimensión en memoria bidimensional como si fuera un piso, y encuentra la forma óptima. tamaño del bloque de corte (baldosa). Al mismo tiempo, también encapsula la forma del tensor de acuerdo con las características del hardware del acelerador subyacente y logra una compilación eficiente al limitar la selección de la forma.

Marco técnico de rodillos
Las evaluaciones de 6 modelos DNN principales y 119 operadores DNN populares muestran que Roller puede generar kernels altamente optimizados en segundos, especialmente para operadores personalizados grandes y costosos. En última instancia, Roller logra una mejora de tres órdenes de magnitud en el tiempo de compilación con respecto a los compiladores existentes. El rendimiento de los núcleos generados por Roller es comparable al de los compiladores de tensor de última generación, incluidas las bibliotecas DNN, y algunos operadores incluso funcionan mejor. Al mismo tiempo, Roller también se ha utilizado en el kernel DNN personalizado desarrollado internamente por Microsoft, y el desarrollo real ha verificado el rendimiento superior de Roller que puede acelerar significativamente el ciclo de desarrollo.
论文:ROLLER: compilación de tensores rápida y eficiente para el aprendizaje profundo
Soldador "Electric Welder" de compilación de IA: reduzca el acceso a la memoria y mejore la eficiencia computacional
Los modelos modernos de DNN tienen requisitos cada vez más altos para la memoria de alta velocidad. Después de analizar algunos de los últimos modelos de DNN, los investigadores descubrieron que la mayoría de los cuellos de botella informáticos actuales de DNN se encuentran principalmente en el acceso a la memoria de la GPU, como la utilización del ancho de banda de la memoria de estos modelos. Hasta el 96,7 %, pero la utilización media de los núcleos informáticos es solo del 51,6 %, y con el desarrollo continuo de hardware y modelos DNN, la brecha entre los dos seguirá aumentando. En particular, los modelos de IA actuales necesitan procesar datos de alta fidelidad, como imágenes más grandes, oraciones más largas y gráficos de mayor definición, que ocupan más ancho de banda de memoria en los cálculos. Al mismo tiempo, los núcleos informáticos patentados más eficientes (como TensorCore) han aumentado aún más la presión de la memoria.
Para resolver el problema de la memoria, los investigadores propusieron el compilador de aprendizaje profundo Welder, que optimiza completamente la eficiencia de acceso a la memoria del modelo DNN de extremo a extremo compuesto por operadores generales. De hecho, el modelo DNN se puede considerar como un gráfico compuesto por múltiples operadores. Todo el proceso de cálculo involucra múltiples etapas, es decir, los datos deben fluir a través de diferentes operadores y los tensores deben dividirse en bloques en cada etapa. , primero muévalo al procesador para el cálculo y luego muévalo de nuevo a la memoria, lo que causará una gran sobrecarga de manejo. Dado que todo el proceso de cálculo incluye múltiples procesos, este proceso también se puede imaginar como una escena en la que se mueven "ladrillos" capa por capa, en la que el primer "trabajador" sube los "ladrillos" para procesarlos y luego los vuelve a colocar. Los "trabajadores" lo toman y lo tallan, luego lo vuelven a colocar, y luego el tercero, el cuarto ..., transportando repetidamente, se puede esperar que el costo sea evidente. Entonces, ¿es posible dejar que el primer "trabajador" complete parte de las subtareas en el nivel superior y pasarlas al siguiente "trabajador" para continuar con el procesamiento y luego "unir" varias tareas para lograr operaciones optimizadas? Welder desempeña el papel de una máquina de soldadura eléctrica. Al vincular a diferentes operadores, puede procesar bloques de datos en una línea de ensamblaje, lo que reduce en gran medida la cantidad de acceso a la memoria. En los últimos años, los modelos de inteligencia artificial tienen requisitos cada vez más altos para la eficiencia del acceso a la memoria. En el caso de , la eficiencia de cálculo se puede mejorar mucho.

Marco técnico del soldador
Después de evaluar 10 modelos principales de DNN (incluidas estructuras de modelo clásicas y más recientes para varias tareas, como visión, procesamiento de lenguaje natural, gráficos 3D, etc.), se puede demostrar que Welder supera significativamente el rendimiento de las GPU de NVIDIA y AMD. los principales marcos y compiladores existentes, como PyTorch, ONNXRuntime y Ansor, los aumentos de velocidad alcanzaron 21,4 veces, 8,7 veces y 2,8 veces respectivamente. La optimización automática de Welder incluso supera a TensorRT y Faster Transformer, logrando aceleraciones de hasta 3.0x y 1.7x. Además, el rendimiento de estos modelos mejoró aún más cuando se ejecutaron en hardware con núcleos de cómputo más rápidos, como TensorCore, lo que subraya la importancia de la optimización de la memoria para los futuros aceleradores de IA.
Molinillo "Grinder" de compilación AI: permite que el flujo de control se ejecute de manera eficiente en el acelerador
En el programa de cálculo, el proceso de mover bloques de datos a veces necesita introducir una lógica de control más compleja, que es el flujo de control fuera del flujo de datos del programa de inteligencia artificial, como recorrer cada palabra en una oración, o según el input Decide dinámicamente qué parte del programa ejecutar. La mayoría de los compiladores actuales están resolviendo problemas de flujo de datos y el soporte para el flujo de control no es eficiente, como resultado, los modelos con más flujo de control no pueden utilizar eficientemente el rendimiento del acelerador. Los investigadores creen que el flujo de control y el flujo de datos se pueden segmentar y reorganizar para una optimización más eficiente, y se lanzó Grinder[1]. Grinder es como una máquina de corte y pulido portátil. Después de dividir el flujo de datos en bloques de cálculo paralelos de diferentes tamaños, integrará el flujo de control en el flujo de datos, de modo que el flujo de control también se pueda ejecutar de manera eficiente en el acelerador.

Marco técnico de la amoladora
Grinder puede optimizar conjuntamente la ejecución del flujo de control y el flujo de datos en los aceleradores de hardware, y unificar la representación de los modelos de inteligencia artificial, incluido el flujo de control y el flujo de datos a través de una nueva abstracción, lo que permite a Grinder reducir los niveles de paralelismo del hardware. para reprogramar el flujo de control. Grinder utiliza una estrategia heurística para encontrar un esquema de programación efectivo y puede mover automáticamente el flujo de control al núcleo del dispositivo, logrando así la optimización a través de los límites del flujo de control. Los experimentos muestran que Grinder puede acelerar el modelo DNN con un flujo de control intensivo en 8,2 veces, y actualmente es el más rápido entre los marcos y compiladores de DNN para el flujo de control.
Título: Cocktailer: análisis y optimización del flujo de control dinámico en el aprendizaje profundo
[1] Grinder es el nombre del proyecto y el nombre del sistema en el documento es Cocktailer
Basados en el mismo conjunto de abstracción y capa de representación intermedia unificada (Representación intermedia, IR), estos cuatro compiladores de IA resuelven diferentes problemas en los compiladores de IA actuales: paralelismo, eficiencia de compilación, memoria y flujo de control, formando un conjunto completo de solución compilada. En el proceso de promover la investigación, el sistema de compilación de prototipos del Instituto de Investigación de Microsoft Asia ha brindado asistencia para la implementación y optimización de modelos de productos de Microsoft como Office, Bing y Xbox, y también ha desempeñado un papel en la personalización y optimización de Microsoft. nuevos operadores.
"A medida que los modelos grandes se generalizan hoy en día, los modelos de inteligencia artificial tienen mayores requisitos de eficiencia y poder de cómputo. Por un lado, los compiladores de IA deben realizar una fusión extrema de operadores, personalización y optimización de los recursos de hardware; por otro lado, el soporte de compilación del sistema para También se requieren nuevas arquitecturas de hardware a gran escala, como chips de interconexión de red (NoC) en el chip, arquitecturas de memoria híbrida, etc., e incluso guiar la personalización del hardware a través de métodos de compilación de caja blanca. demostrado ser capaz de Mejorar significativamente la eficiencia de la compilación de IA puede facilitar mejor el entrenamiento y el despliegue de modelos de inteligencia artificial. Al mismo tiempo, el desarrollo de modelos grandes también brinda oportunidades para la compilación de IA. En el futuro, el modelo grande en sí mismo puede ayúdenos a lograr la optimización y la compilación”, dijo Xue Jilong, investigador jefe de Microsoft Research Asia.