논문: 2307. 고해상도 이미지 합성을 위한 잠재 확산 모델 개선 (고해상도 이미지 합성을 위한 향상된 잠재 변수 확장 모델)

관련 링크 및 해석
Code: https://github.com/Stability-AI/generative-models
공식 홈페이지 모델 설명 : https://huggingface.co/stabilityai/
【SDXL0.9 로컬 安装部署教程】https://www.bilibili.com/video/BV1oV4y18791
【모델 다운로드] https://pan.baidu.com/s/1wuOibq3dYW_e_LrIgnr2Jg?pwd=0710 추출 코드: 0710
I. 개요
SDXL, DeepFloyd IF, DALLE-2, Bing, Midjourney v5.2
왼쪽에서 오른쪽으로 각 열은 생성 모델 또는 소프트웨어에 해당합니다.

1.1 성능 향상
1. SDXL은
用户偏好效果v1.5 및 v2.1을 크게 ** 능가한 것으로 보입니다midjourney v5.1. ! !
2. SDXL은 매우 큽니다(2.6B Unet 참조) --> 이전 SD보다 느리고 VRAM이 더 많습니다.
3. 하나의 조정 벡터를 직렬로 연결하는 대신 두 개의 CLIP txt 인코더가 더 나은 텍스트 이미지 정렬을 갖습니다(더 4.
약간 개선된 VAE).
5. 저해상도 교육 이미지(이미지 크기에 따라 조건이 지정된 모델), 무작위로 잘린(자르기 위치에 따라 조건이 지정된 모델) 및 정사각형이 아닌 이미지(종횡비 모델에 따라 조건이 지정된 모델)를 처리합니다
. 특히 고품질 이미지를 위해 소량의 노이즈(이미 많은 정보가 있는 경우)를 제거하기 위한 것입니다.
발신: 스테이션 B의 Qinglong Saint
1.2 특정 오픈 소스 모델
SD-XL 0.9-base: 기본 모델은 다양한 종횡비에서 1024x1024 해상도의 이미지로 학습됩니다. 기본 모델은 텍스트 인코딩에 OpenCLIP-ViT/G 및 CLIP-ViT/L을 사용하는 반면 개선된 모델은 OpenCLIP 모델만 사용합니다.
SD-XL 0.9- refiner(Refiner 모델): 개선된 모델은 고품질 데이터에서 작은 노이즈 레벨을 제거하도록 훈련되어 있으므로 text-to-image 모델로 적합하지 않고 대신 image-to 에만 적용됩니다. -이미지 모델.
2. 원문 소개
2.1 요약
文本到图像合成(텍스트-이미지 합성)을 위한 잠재확산모델 (latent diffusion model ) 인 SDXL(XL code of Stable Diffusion)을 제안하였다 .
이전의 안정적인 확산 버전과 비교하여 SDXL은 三倍大UNet 백본 네트워크 (3배 더 큰 UNet 백본)를 사용하며 모델 매개변수의 증가는 주로 다음에서 발생합니다.
- 더 많은 주의 차단
- (두 번째 텍스트 인코더.)를 사용하여
第二个文本编码器더 큰 교차 주의 컨텍스트를 얻습니다(교차 주의: 여러 입력 간에 주의 메커니즘을 공유하는 기술을 의미함). - 우리는 다양한 참신한 컨디셔닝 체계를 설계하고 여러 종횡비에서 SDXL을 교육합니다.
改进模型또한 Post-hoc image-to-image 기술을 통해 SDXL로 생성된 샘플의 시각적 충실도를 개선하기 위한 정제 모델을 소개합니다 .
우리는 SDXL이 이전의 안정적인 확산 버전에 비해 극적으로 향상된 성능을 보여주고 최첨단 블랙박스 이미지 생성기에 필적하는 결과를 달성한다는 것을 보여줍니다. 공개 연구를 추진하고 대규모 모델 교육 및 평가의 투명성을 촉진하기 위해 코드 및 모델 가중치에 대한 액세스를 제공합니다.
2.2 모델 구조
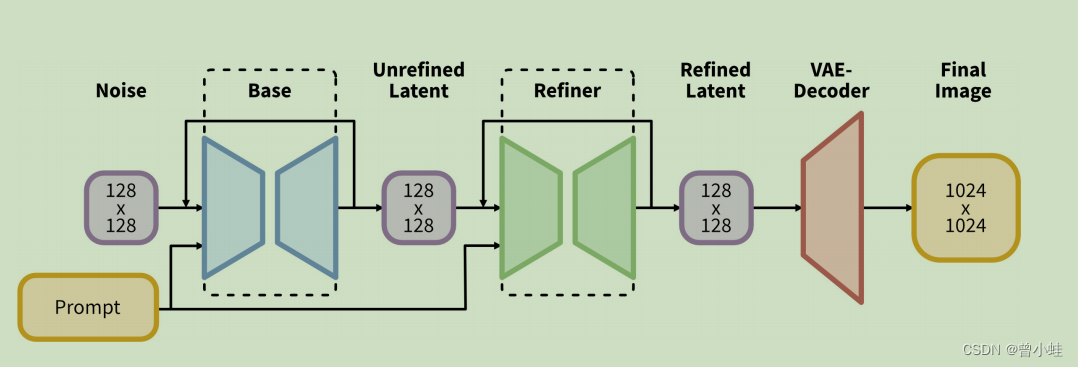
SDXL을 사용하여 128×128 크기의 초기 잠재 변수를 생성합니다. 그런 다음 특수한 고해상도 정제 모델을 활용하고 동일한 힌트를 사용하여 첫 번째 단계에서 생성된 잠재 변수에 SDEdit[28]를 적용합니다. SDXL 및 개선된 모델은 동일한 자동 인코더를 사용합니다.
2108.SDEdit: 확률적 미분 방정식을 사용한 유도 이미지 합성 및 편집 : 확률적 미분 방정식을 사용한 유도 이미지 합성 및 편집.
2.3 SDXL과 SD1.5/SD2.0의 비교
모델 구성요소 및 매개변수

동일한 프롬프트의 효과

3. 향후 작업(최적화할 곳)
• 단일 단계: 현재 2단계 접근 방식을 사용하여 추가 정제 모델을 사용하여 SDXL에서 최상의 샘플을 생성합니다. 이로 인해 두 개의 대형 모델을 메모리에 로드해야 했고, 접근성과 샘플링 속도가 제한되었습니다. 향후 작업은 동일하거나 더 나은 품질의 단일 단계 방법을 제공하는 방법을 모색해야 합니다.
• 텍스트 합성: 스케일 및 더 큰 텍스트 인코더(OpenCLIP ViT-bigG [19])가 텍스트 렌더링을 개선하는 데 도움이 되지만 바이트 수준 토크나이저[52, 27]를 결합하면 모델을 확장할 수 있습니다. 텍스트 합성.
• 아키텍처: 탐색 단계에서 UViT[16] 및 DiT[33]와 같은 트랜스포머 기반 아키텍처를 간단히 시도했지만 즉각적인 이점을 찾지 못했습니다. 그러나 신중한 하이퍼파라미터 연구를 통해 결국 더 큰 Transformer가 지배하는 아키텍처로 확장할 수 있을 것이라고 낙관합니다.
• 증류 : 원래의 정상 상태 확산 모델에 비해 상당한 개선을 이루었지만 비용이 발생합니다 推理成本的增加(VRAM 및 샘플링 속도 포함). 따라서 향후 작업은 유도[29], 지식 기반[6, 22, 24] 및 점진적 증류[41, 2, 29] .
• 우리 모델은 2006.Denoising Diffusion Probabilistic Models에 따라 훈련되었으며 미학적으로 만족스러운 결과를 위해 노이즈를 상쇄해야 합니다 . 离散时间公式Karras 등의 EDM 프레임워크 ** 2206.확산 기반 생성 모델의 설계 공간 설명候选方案 ** 은 연속 시간의 공식화로 인해 샘플링 유연성이 증가하고 노이즈 스케줄링 수정이 필요하지 않기 때문에 모델 교육의 유망한 미래입니다 .
중요한 영어 설명:
2단계 접근 방식: 2단계 방법
텍스트 합성: 텍스트 합성
아키텍처: 아키텍처
디스틸레이션: 증류
오프셋 노이즈: 오프셋 노이즈
EDM 프레임워크: EDM 프레임워크(등시 이산화 공식)
연속 시간: 연속 시간
노이즈 일정 수정: 노이즈 일정 수정