1. Análisis de la demanda
La función de comparación de trabajos orientada a RR. HH. ayuda a RR. HH. a seleccionar currículos de manera eficiente. El modelo puede seleccionar varios currículos que mejor se adapten a los requisitos del trabajo de la base de datos de currículos y recomendarlos a Recursos Humanos de acuerdo con los diferentes requisitos del trabajo dados. Los requisitos comunes para los puestos incluyen: edad, educación y años de trabajo. El currículum también tiene las siguientes características: la edad del solicitante, la educación, la escuela de posgrado, los años de trabajo y el puesto de destino. El modelo debe coincidir y recomendar en función de los requisitos del trabajo y las características del currículum.
2. Selección de algoritmo
El problema es esencialmente un problema de recomendación, y los sistemas de recomendación comunes incluyen las siguientes tres categorías: recomendación de filtrado colaborativo, recomendación basada en contenido y recomendación híbrida. Aunque el algoritmo de recomendación tradicional puede resolver la mayoría de los problemas de filtrado de información, no puede resolver los problemas de escasez de datos, arranque en frío, recomendación repetida, etc. [1] Los autores de este proyecto observaron que el aprendizaje de refuerzo profundo puede lograr mejores resultados de recomendación de currículum.
3. Aprendizaje por refuerzo profundo
1. Aprendizaje por refuerzo
La base para el aprendizaje por refuerzo proviene del modelo de decisión de Markov. Su idea básica es impulsar a un agente agente a realizar acciones en el entorno para maximizar su recompensa acumulativa. Los agentes están motivados por castigos por mal comportamiento y recompensas por buen comportamiento.
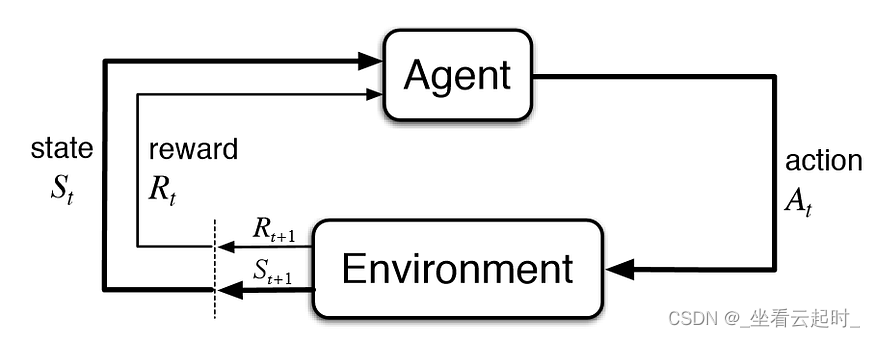
Figura 1 Modelo de decisión de Markov
Arrancamos el agente agent con un entorno inicial. Todavía no tiene ninguna recompensa asociada, pero tiene un estado (S_t).
Luego, para cada iteración, el agente toma el estado actual (S_t), elige la mejor acción (A_t) (según la predicción del modelo) y la ejecuta en el entorno. Posteriormente, el entorno devuelve la recompensa (R_t+1) por la acción dada, el nuevo estado (S_t+1) e información si el nuevo estado es terminal. Este proceso se repite hasta que se termina.
Se pueden encontrar más detalles sobre el aprendizaje por refuerzo en:
Literatura [2]:
Literatura[3]
literatura [4]
El más utilizado en el aprendizaje por refuerzo es el algoritmo Q-learning.
El algoritmo Q-learning utiliza una tabla Q (Qtable) de valores de estado-acción. Esta tabla Q representa un estado para cada fila y una acción para cada columna. Cada celda contiene el valor Q estimado para el par estado-acción correspondiente.
Primero inicializamos todos los valores de Q a cero. A medida que el agente interactúa con el entorno y recibe retroalimentación, el algoritmo mejora iterativamente estos valores Q hasta que convergen en un valor Q óptimo.
Para conocer la teoría detallada del algoritmo Q-learning, consulte:
literatura [5]
y la literatura [4].
2. Aprendizaje por refuerzo profundo
Esta parte es el foco de este artículo.Hay tres tipos de aprendizaje de refuerzo profundo: (1) Red Q profunda basada en valores: DQN y otros algoritmos (2) Algoritmo de gradiente de política (3) Algoritmo actor-crítico
El algoritmo de este proyecto usa Deep Q Network (DQN) en el aprendizaje de refuerzo profundo. Por qué existe una teoría de DQN, debemos comenzar con el algoritmo Q-learning. En Q-learning, se usa una estructura de datos-Qtable. Para registrar el valor Q está determinado por el estado y la acción, pero en la escena real, el espacio de estado suele ser grande y el espacio de acción también puede ser grande, y organizar una tabla Q enorme requiere una gran sobrecarga del sistema.

Figura 2 Qtabla
Si se puede usar una función (función Q) para ingresar el par estado-acción, se puede generar el valor Q correspondiente y se puede asignar un estado al valor Q de todas las operaciones que se pueden realizar desde el estado, entonces el el rendimiento mejorará considerablemente, como la imagen:

Figura 3 Función Q
La red neuronal es perfecta para esta función.El algoritmo DQN utiliza la red neuronal en el aprendizaje profundo para optimizar el algoritmo de aprendizaje por refuerzo.

Figura 4 Red Q profunda (DQN)
Este algoritmo tiene dos características maravillosas, una se llama repetición de experiencia y la otra es una red neuronal dual: Q Network y Target Network .
2.1 Experiencia de reproducción
Sabemos que entrenar un modelo de toma de decisiones de IA requiere una recopilación continua de datos de retroalimentación después de que el modelo realice acciones en el entorno, pero cómo recopilar datos y qué datos recopilar afectará directamente el efecto de entrenamiento del modelo. Si los datos recopilados son una sola muestra, cada muestra y el gradiente correspondiente tendrán demasiada variación y el peso de la red neuronal no convergerá. ¿Qué pasa con la recolección secuencial de un lote de muestras? También hay fallas que pueden conducir a un "olvido catastrófico". Por ejemplo, si hay un robot en un rincón de una gran fábrica, el robot aprende la experiencia en este pequeño rincón cada vez que camina, y los datos recopilados y la experiencia de aprendizaje son limitados En este pequeño rincón, esto es similar a lo que llamamos muestras de lotes secuenciales. En este momento, si el robot se lleva a otro rincón completamente diferente de la fábrica, el robot comenzará a aprender experiencia en el nuevo rincón, y la experiencia aprendida en el rincón original pronto se olvidará por completo.Esto se debe a que las muestras de entrenamiento son demasiado dependientes razón fuerte.
Si usamos un grupo, cargue las muestras por lotes recolectadas cada vez, cuando se haya acumulado una cierta cantidad de muestras en el grupo, recolecte aleatoriamente un lote de muestras del grupo cada vez y envíelas a la red neuronal para aprendizaje, así que las muestras aprendidas cada vez son diversas. El enriquecimiento reducirá en gran medida la dependencia de las muestras y mejorará el efecto del aprendizaje.
Es como si los padres reunieran las preguntas incorrectas que sus hijos han hecho cada vez y les pidieran que las vuelvan a hacer. Cuantos más tipos de preguntas incorrectas recopilen, mejor para que los niños aprendan de diferentes tipos de preguntas, para que puedan hacer nuevos ejercicios. mejor.
2.2 Red neuronal dual——Q-Network y Target Network
El algoritmo DQN original tiene solo una Red Q única, y la Red Q es responsable de predecir el valor Q de cada acción en un estado cada vez, y luego el agente tomará decisiones basadas en el valor Q de diferentes comportamientos, pero entrenamos la red neuronal, cada vez que se calcula el valor de pérdida para retropropagarse y actualizar los pesos de cada neurona, si se usa una sola red neuronal, ocurrirá un fenómeno llamado "arranque", y cada iteración de Q Network se acercará a sí misma y se usará a sí misma como objetivo, para seguir persiguiendo, porque el peso cambia, la red Q se entrena cada vez, usa el yo antes del entrenamiento para ponerse al día con el yo después del entrenamiento, y nunca lo alcanzarás, como si te levantaras y persiguieras a tu Al igual que la sombra, aporta una gran inestabilidad a la formación del modelo.
Si creamos una red neuronal que es exactamente igual a como es, simplemente no es como Q Network que actualiza el peso cada vez, la red actualiza el peso en un intervalo determinado (le asigna el peso de Q Network) y es entrenado En este caso, use Q Network Para ponerse al día, puede acercarse gradualmente, llamamos a esta red neuronal "Target Network".
Por poner un ejemplo: una persona es muy pobre, su riqueza es M1 en este momento, y su grado de satisfacción con poseer 1 millón es A1, si baja no se conforma con 1 millón, y si quiere tiene 10 millones, entonces perseguirá objetivos cada vez más altos y nunca estará satisfecho. Si cuando tenga 800.000, estará satisfecho con la cantidad o estará satisfecho con 1 millón cuando no tenga nada, entonces estará satisfecho mientras obtenga otros 200.000. Target Network es como lo satisfecho que está con 1 millón cuando no tiene nada, para que pueda acercarse a la satisfacción cada vez que gana.
2.3 Flujo del algoritmo DQN
Inicialmente, el estado se envía a la Red Q, y la red neuronal predice el valor Q de cada acción en este estado.De acuerdo con el método ε-Greedy, existe una cierta probabilidad de que la acción se seleccione aleatoriamente para su ejecución, de lo contrario, la la acción con el mayor valor de Q se selecciona para su ejecución. Después de la ejecución, el entorno le dará a la acción una recompensa de valor de retroalimentación. En este momento, los datos de esta acción (estado actual (estado actual), acción actual (acción (i)), valor de retroalimentación (recompensa), siguiente estado ( siguiente state)) en el grupo de reproducción de experiencias. Repita el proceso anterior hasta que el agente llegue al estado de terminación, actualice los pesos de la red Q, el proceso de actualización es: recopile un lote de muestras del grupo de reproducción de experiencia, envíelas a la red Q y la red de destino, y la red Q utiliza el estado actual de estas muestras respectivamente y la acción (i) calculan el valor Q de la muestra - QValue. Target Network utiliza el siguiente estado y recompensa de estas muestras respectivamente para calcular el valor objetivo de la muestra. El método de cálculo del valor objetivo es:
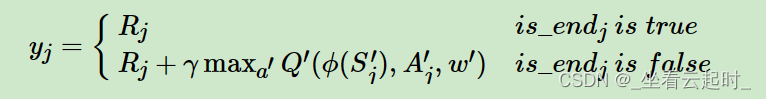
Figura 5 Cálculo del valor objetivo
Is_endj se utiliza para juzgar si el agente ha alcanzado el estado final, es decir, el punto final. Si llega, el valor del valor objetivo es el valor de retroalimentación de la acción de acción seleccionada (i) en este estado. Si no llega el punto final, el valor objetivo es igual al valor de retroalimentación más el siguiente estado. El valor máximo entre los valores objetivo de cada acción se multiplica por el factor de descuento, y cada muestra se calcula de acuerdo con el método anterior.
Después de obtener el valor predicho de Q Network y el valor objetivo predicho por Target Network, use la fórmula del error cuadrático medio ( MSE ):

Figura 6 Fórmula del error cuadrático medio
Calcule el valor de pérdida de Q Network, luego use el gradiente para calcular el optimizador y retropropague para actualizar el peso de Q Network. El siguiente es el flujo de todo el modelo:

Figura 7 Flujo del algoritmo DQN
El algoritmo DQN se describe en detalle en [6], con un análisis paso a paso y maravillosas ilustraciones:
literatura [6]
4. Modelización del modelo de emparejamiento personal-puesto
Debido a que esta función se desarrolló para RR. hojas de vida. Es decir, cada hoja de vida corresponde a una acción, y se retroalimenta según el grado de coincidencia entre las características de la hoja de vida y las características del puesto. A mayor grado de coincidencia, mejor valor de retroalimentación de la hoja de vida. . En este modelo, el puesto puede considerarse como un agente, y cada coincidencia con un currículum es una acción.
Todo lo que hay que decir es el estado:
El estado inicial es seleccionar aleatoriamente un currículum del conjunto de currículums como estado inicial. Durante el proceso de entrenamiento del modelo, la acción realizada por esta decisión se utiliza como el siguiente estado. Es decir, cada estado es en realidad un currículum.
- Espacio de estado S: conjunto de currículos
- Espacio de acción A: colección de currículums
- Comentarios del reclutador R: proporcione comentarios basados en el grado de coincidencia entre el currículum y las características del trabajo
- Factor de descuento γ: Indica el descuento para diferentes devoluciones de tiempo
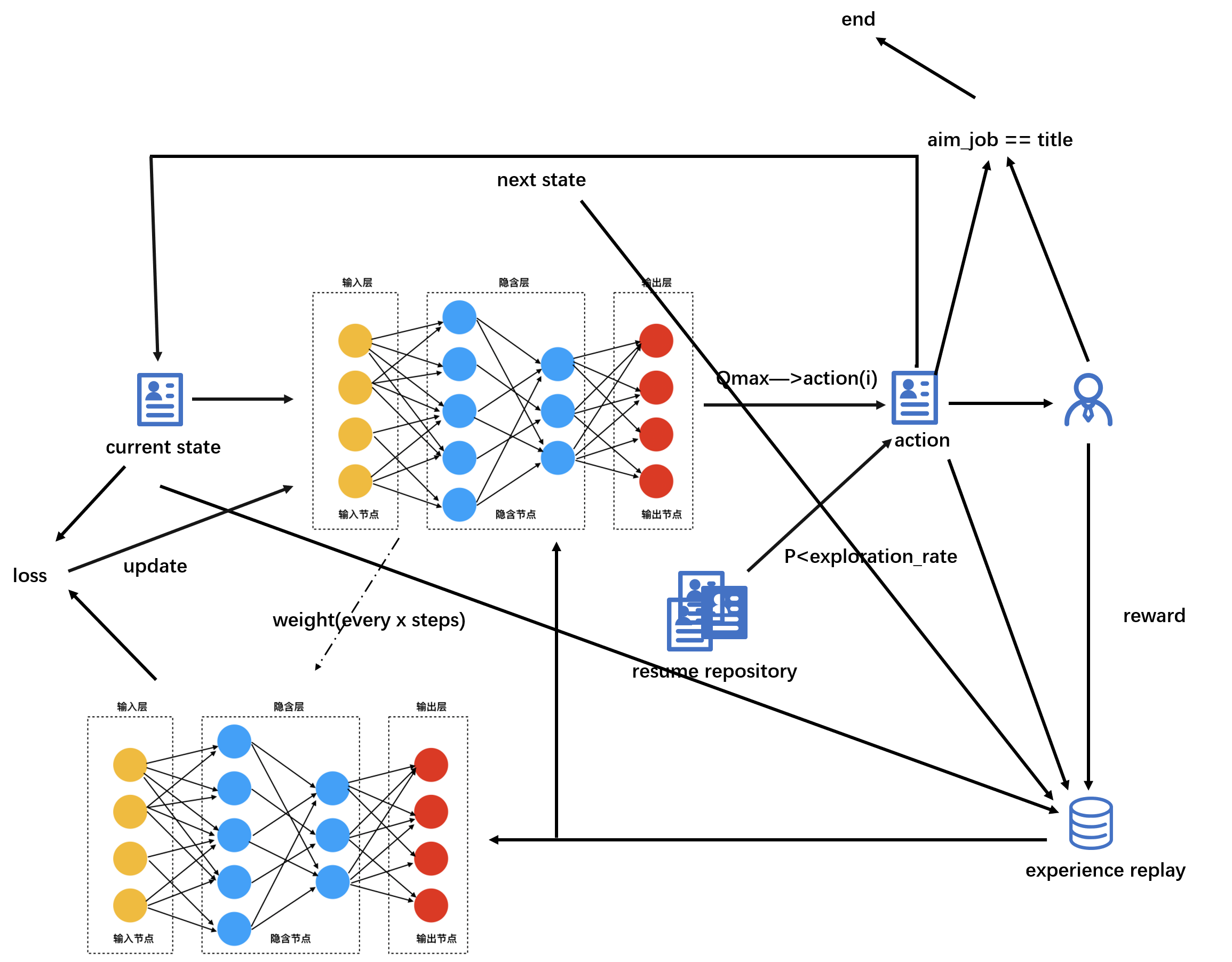
Figura 8 Diagrama esquemático del algoritmo
5. Problemas encontrados durante la codificación y depuración
1. Si un buscador de empleo en un currículum tiene dos puestos de destino, ¿cómo solucionarlo?
El conjunto de datos es un archivo de Excel y todas las posiciones de destino existen en una celda, por ejemplo:

Figura 9 Problemas en la columna de la publicación de destino
Puede usar la función de despecho para separar cuando se encuentra "," y luego dividir la columna de trabajo de destino original en dos columnas (objetivo_trabajo1, objetivo_trabajo2). Si el currículum no especifica la posición de destino, las posiciones correspondientes de las dos columnas se establecen en ninguna. Si se da una posición de destino, se coloca en aim_job1, y aim_job2 se establece en ninguno. Si se dan dos posiciones de destino, se colocan en aim_job1 y aim_job2 a su vez. .
2. ¿Cómo diseñar la función de recompensa y castigo?
Las recompensas y los castigos deben determinarse de acuerdo con el grado de coincidencia del valor característico del puesto y el valor característico del currículum:
Primero, codifique el valor característico del currículum y el valor característico del puesto, y reemplace la cadena con un número:
Códigos correspondientes a las calificaciones académicas: 'Escuela secundaria técnica': 1, 'Junior College': 2, 'Licenciatura': 3, 'Máster': 4, 'Doctorado': 5
Códigos correspondientes de los puestos objetivo: 'Operación de productos': 0, 'Diseñador gráfico': 1, 'Finanzas': 2, 'Marketing': 3, 'Supervisor de proyectos': 4, 'Ingeniero de desarrollo': 5, 'Operario' ' : 6, 'Operación de comercio electrónico': 7, 'Gestión de recursos humanos': 8, 'Especialista en control de riesgos': 9, 'Ninguno': 10
(1) Si la posición objetivo del currículum no es la posición, la recompensa es -30
(2) Si el puesto objetivo del currículum es el puesto, pero la educación, los años de trabajo y la edad no cumplen con los requisitos del trabajo , los puntos de recompensa se deducirán de acuerdo con el peso. Aquí, el peso de la educación es 2 y el peso de los años de trabajo (experiencia) El peso es 1, y el método de cálculo de la recompensa es:
self.reward = -5 + self.W[0] * (currículum_experiencia - experiencia_min) + self.W[1] * (
currículum_educación - educación_necesaria)
(3) Si el puesto objetivo del currículum es el puesto, y la formación académica, los años de trabajo y la edad cumplen con los requisitos del trabajo , cuanto mayor sea la formación académica y más larga la experiencia laboral, mayor será el valor de la recompensa del currículum. Esto se puede lograr utilizando los antecedentes educativos del currículum Hay una diferencia entre el valor de los años de trabajo y los valores correspondientes de educación y años de trabajo requeridos para el puesto. Cuanto mayor sea la diferencia, mayor será la educación y más tiempo el años de trabajo, y el peso también se incluye en el cálculo de la recompensa.
5 + 1 * (resume_experience – job_experience_min) + 2 * (currículum_educación – job_education_required)
3. ¿Cómo tomar muestras para calcular el peso de actualización inversa de pérdida?
Tome un lote de muestras del grupo de reproducción de experiencia, extraiga la misma cantidad en un lote de muestras, como el estado actual, y empáquelas en matrices, de modo que pueda obtener cuatro matrices, envíe la matriz con el siguiente estado a La matriz con el estado actual se envía a la red Q, y el QValue de la acción correspondiente se extrae usando la máscara one-hot, y el valor de pérdida se calcula junto con el valor objetivo y la recompensa calculada. por la red de destino.
4. Nota: ValueError: Llamó a set_weights(weights) en la capa "match_model_1" con una lista de pesos de longitud 4, pero la capa esperaba 0 pesos. Pesos proporcionados: [matriz([[-1.56753018e-01, 5.38734198e-02, 2.8747...
Después de muchas veces de depuración, el autor descubrió que se debía a la incoherencia entre el intervalo de paso de Q Network que asigna pesos a Target Network y la cantidad de muestras recopiladas del grupo de reproducción de experiencia cada vez. pool Si la cantidad de muestras es demasiado grande y el intervalo de paso de Q Network que asigna el peso a la red de destino es demasiado pequeño, se informará este error, pero el motivo teórico aún no está claro para el autor. Si alguien puede explicarlo , espero señalarlo en el área de comentarios, este error se solucionará indirectamente más adelante.
5. El algoritmo está atascado en un óptimo local y la convergencia es demasiado lenta
Establecemos el número de tiempos de entrenamiento en 5000 iteraciones:
Establezca los parámetros de entrenamiento como:
tasa_de_aprendizaje=0,10, factor_descuento=0,85, tasa_de_exploración=0,5

Podemos ver que el valor promedio de la recompensa ha estado fluctuando mucho, y la clasificación del valor Q de cada currículum tiene la siguiente situación:
Resultados de clasificación de valor Q:
1 Número: 38, Nombre: Hong Zifen, Edad: 38, Experiencia: 12, Educación: 3, Escuela: Universidad Normal de Beijing, aim_job_1: 3, aim_job_2: 4 Valor Q: 0.91416574
2 Num: 22, Nombre: Lei Jinbao, Edad: 38, Experiencia: 9, Educación: 4, Escuela: Universidad de Geociencias de China, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.826052
3 Número: 16, Nombre: Liu Ziting, Edad: 36, Experiencia: 10, Educación: 3, Escuela: Universidad de Wuhan, aim_job_1: 3, aim_job_2: 4 Valor Q: 0.77591
4 Número: 23, Nombre: Wu Meilong, Edad: 37, Experiencia: 6, Educación: 4, Escuela: Universidad de Hunan, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.7495003
5 Número: 18, Nombre: Lu Zhiying, Edad: 38, Experiencia: 12, Educación: 3, Escuela: Universidad Tecnológica de Wuhan, aim_job_1: 3, aim_job_2: 4 Valor Q: 0.73388803
6 Número: 48, Nombre: Lin Yingwei, Edad: 34, Experiencia: 7, Educación: 3, Escuela: Universidad de Nankai, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.61048335
7 Número: 21, Nombre: Zheng Yiwen, Edad: 39, Experiencia: 8, Educación: 4, Escuela: Universidad Agrícola de Huazhong, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.604043
8 Número: 55, Nombre: Yao Yangyun, Edad: 35, Experiencia: 6, Educación: 4, Escuela: Universidad de Comunicación de China, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
9 Número: 58, Nombre: Tang Xinyi, Edad: 34, Experiencia: 11, Educación: 1, Escuela: Hebei Industrial Vocational and Technical College, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
10 Núm.: 53, Nombre: Zheng Xingyu, Edad: 26, Experiencia: 3, Educación: 1, Escuela: Colegio Técnico y Vocacional Agrícola de Xinjiang, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
11 Número: 35, Nombre: Lin Jialun, Edad: 28, Experiencia: 5, Educación: 2, Escuela: Universidad Jiaotong de Shanghai, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
12 Número: 45, Nombre: Hu Tai, Edad: 33, Experiencia: 10, Educación: 2, Escuela: Universidad Sun Yat-sen, aim_job_1: 0, aim_job_2: 4 Valor Q: 0.0
13 Número: 59, Nombre: Chen Zhengsheng, Edad: 32, Experiencia: 10, Educación: 1, Escuela: Beijing Medical College, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
14 Num: 60, Nombre: Li Shushu, Edad: 28, Experiencia: 5, Educación: 1, Escuela: Fujian Vocational College of Shipbuilding and Transportation, aim_job_1: 10, aim_job_2: 10 Q value: 0.0
15 Num: 44, Nombre: Zheng Yaqian, Edad: 36, Experiencia: 7, Educación: 4, Escuela: Instituto de Tecnología de Harbin, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.0
16 Número: 41, Nombre: Ren Yuwen, Edad: 29, Experiencia: 3, Educación: 3, Escuela: Universidad Jiaotong de Shanghai, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
17 Num: 100, Nombre: Lin Yuting, Edad: 31, Experiencia: 7, Educación: 2, Escuela: Universidad Normal de Beijing, aim_job_1: 0, aim_job_2: 10 Valor Q: 0.0
18 Num: 25, Nombre: Wang Meizhu, Edad: 35, Experiencia: 4, Educación: 4, Escuela: Universidad Normal de Hunan, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.0
19 Num: 32, Nombre: Wu Meiyu, Edad: 34, Experiencia: 8, Educación: 2, Escuela: Universidad de Ciencia y Tecnología Electrónica de China, Chengdu College, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.0
20 Número: 29, Nombre: Cao Minyou, Edad: 29, Experiencia: 6, Educación: 2, Escuela: Universidad de Shandong, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
21 Número: 69, Nombre: Liu Tingbao, Edad: 26, Experiencia: 6, Educación: 0, Escuela: Jinan Media School, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
22 Num: 24, Nombre: Wu Xinzhen, Edad: 36, Experiencia: 7, Educación: 4, Escuela: Central South University, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.0
23 Número: 20, Nombre: Li Yungui, Edad: 40, Experiencia: 14, Educación: 3, Escuela: Universidad Normal de China Central, aim_job_1: 3, aim_job_2: 4 Valor Q: 0.0
24 Número: 19, Nombre: Fang Yiqiang, Edad: 39, Experiencia: 13, Educación: 3, Escuela: Universidad de Economía y Derecho de Zhongnan, aim_job_1: 3, aim_job_2: 4 Q value: 0.0
25 Número: 17, Nombre: Rong Zikang, Edad: 37, Experiencia: 11, Educación: 3, Escuela: Universidad de Ciencia y Tecnología de Huazhong, aim_job_1: 3, aim_job_2: 4 Valor Q: 0.0
26 Número: 11, Nombre: Li Zhongbing, Edad: 24, Experiencia: 5, Educación: 0, Escuela: Shunde Technical Secondary School, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
27 Número: 5, Nombre: Jiang Yiyun, Edad: 28, Experiencia: 5, Educación: 2, Escuela: Universidad Tecnológica del Sur de China, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.0
28 Num: 3, Nombre: Lin Wenshu, Edad: 28, Experiencia: 4, Educación: 2, Escuela: Southern University of Science and Technology, aim_job_1: 10, aim_job_2: 10 Q value: 0.0
29 Num: 2, Nombre: Lin Guorui, Edad: 34, Experiencia: 11, Educación: 2, Escuela: Universidad de Comunicación de China, aim_job_1: 3, aim_job_2: 10 Valor Q: 0.0
30 Número: 68, Nombre: Lin Chengchen, Edad: 25, Experiencia: 7, Educación: 0, Escuela: Escuela de aplicación de nuevas tecnologías de Jinan, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
31 Num: 50, Nombre: Li Xiuling, Edad: 32, Experiencia: 7, Educación: 2, Escuela: Universidad de Comunicación de China, aim_job_1: 0, aim_job_2: 4 Q value: 0.0
32 Num: 84, Nombre: Liu Xiaozi, Edad: 30, Experiencia: 6, Educación: 2, Escuela: Universidad del Sureste, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.0
33 Número: 96, Nombre: Du Yi, Edad: 30, Experiencia: 8, Educación: 2, Escuela: Universidad de la Ciudad de Beijing, aim_job_1: 2, aim_job_2: 10 Valor Q: 0.0
34 Número: 92, Nombre: Shen Huimei, Edad: 30, Experiencia: 6, Educación: 2, Escuela: Shanghai Ocean University, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
35 Número: 75, Nombre: Lian Shuzhong, Edad: 32, Experiencia: 8, Educación: 3, Escuela: Universidad Sun Yat-sen, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
36 Número: 90, Nombre: Huang Kanggang, Edad: 29, Experiencia: 8, Educación: 2, Escuela: Universidad de Ciencia y Tecnología de Beijing, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
37 Número: 88, Nombre: Wu Tingting, Edad: 29, Experiencia: 3, Educación: 3, Escuela: Universidad Central de Finanzas y Economía, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
38 Número: 87, Nombre: Lin Yizi, Edad: 26, Experiencia: 0, Educación: 3, Escuela: Universidad Renmin de China, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
39 Número: 89, Nombre: Yang Yijun, Edad: 27, Experiencia: 4, Educación: 2, Escuela: Universidad Tsinghua de Beijing, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
40 Número: 97, Nombre: Pan Xiaodong, Edad: 23, Experiencia: 0, Educación: 2, Escuela: Academia Central de Ópera China, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
41 Número: 98, Nombre: Zhou Zhihe, Edad: 27, Experiencia: 4, Educación: 2, Escuela: Universidad de Shenzhen, aim_job_1: 0, aim_job_2: 4 Valor Q: 0.0
42 Número: 43, Nombre: Lin Shimei, Edad: 34, Experiencia: 11, Educación: 2, Escuela: Universidad de Chongqing, aim_job_1: 3, aim_job_2: 4 Valor Q: -0.17997088
43 Número: 4, Nombre: Lin Yanan, Edad: 28, Experiencia: 5, Educación: 2, Escuela: Universidad Normal del Sur de China, aim_job_1: 4, aim_job_2: 10 Valor Q: -0.35405895
44 Número: 42, Nombre: Li Zhi, Edad: 32, Experiencia: 9, Educación: 2, Escuela: Universidad de Tongji, aim_job_1: 4, aim_job_2: 10 Valor Q: -0.36112082
……
Encontramos que algunos currículums, la posición objetivo coincide con la posición, pero el valor Q es 0, y la experiencia y la educación de Li Yungui son mejores que las de Hong Zifen, que ocupa el primer lugar, pero su valor Q es 0, lo que muestra que estos valores Q son resume de 0 no ha sido entrenado en absoluto, y el algoritmo caerá en el óptimo local en un momento determinado. es ser aleatorio Seleccione una acción y aumente este valor para evitar caer en un óptimo local, porque nuestra tasa de exploración también decaerá con el número de iteraciones.
Ahora ajuste los parámetros a:
tasa_de_aprendizaje=0,10, factor_descuento=0,85, tasa_de_exploración=1

Figura 11 Resultados de la convergencia del algoritmo
Descubrimos que el algoritmo converge rápidamente, pero la convergencia no es perfecta, y la clasificación del valor Q ha vuelto a caer en un óptimo local:
Resultados de clasificación de valor Q:
1 Número: 48, Nombre: Lin Yingwei, Edad: 34, Experiencia: 7, Educación: 3, Escuela: Universidad de Nankai, aim_job_1: 4, aim_job_2: 10 Valor Q: 2.521024
2 Número: 20, Nombre: Li Yungui, Edad: 40, Experiencia: 14, Educación: 3, Escuela: Universidad Normal de China Central, aim_job_1: 3, aim_job_2: 4 Valor Q: 2.4513242
3 Num: 19, Nombre: Fang Yiqiang, Edad: 39, Experiencia: 13, Educación: 3, Escuela: Universidad de Economía y Derecho de Zhongnan, aim_job_1: 3, aim_job_2: 4 Valor Q: 2.3784618
4 Número: 17, Nombre: Rong Zikang, Edad: 37, Experiencia: 11, Educación: 3, Escuela: Universidad de Ciencia y Tecnología de Huazhong, aim_job_1: 3, aim_job_2: 4 Valor Q: 2.372804
5 Número: 24, Nombre: Wu Xinzhen, Edad: 36, Experiencia: 7, Educación: 4, Escuela: Central South University, aim_job_1: 4, aim_job_2: 10 Valor Q: 2.3390896
6 Num: 22, Nombre: Lei Jinbao, Edad: 38, Experiencia: 9, Educación: 4, Escuela: Universidad de Geociencias de China, aim_job_1: 4, aim_job_2: 10 Valor Q: 2.235163
7 Número: 18, Nombre: Lu Zhiying, Edad: 38, Experiencia: 12, Educación: 3, Escuela: Universidad Tecnológica de Wuhan, aim_job_1: 3, aim_job_2: 4 Valor Q: 2.152625
8 Número: 38, Nombre: Hong Zifen, Edad: 38, Experiencia: 12, Educación: 3, Escuela: Universidad Normal de Beijing, aim_job_1: 3, aim_job_2: 4 Valor Q: 2.1127188
9 Num: 16, Nombre: Liu Ziting, Edad: 36, Experiencia: 10, Educación: 3, Escuela: Universidad de Wuhan, aim_job_1: 3, aim_job_2: 4 Valor Q: 2.1125493
10 Num: 21, Nombre: Zheng Yiwen, Edad: 39, Experiencia: 8, Educación: 4, Escuela: Universidad Agrícola de Huazhong, aim_job_1: 4, aim_job_2: 10 Valor Q: 2.1001434
11 Num: 44, Nombre: Zheng Yaqian, Edad: 36, Experiencia: 7, Educación: 4, Escuela: Instituto de Tecnología de Harbin, aim_job_1: 4, aim_job_2: 10 Valor Q: 2.089555
12 Num: 25, Nombre: Wang Meizhu, Edad: 35, Experiencia: 4, Educación: 4, Escuela: Universidad Normal de Hunan, aim_job_1: 4, aim_job_2: 10 Valor Q: 1.840682
13 Num: 23, Nombre: Wu Meilong, Edad: 37, Experiencia: 6, Educación: 4, Escuela: Universidad de Hunan, aim_job_1: 4, aim_job_2: 10 Valor Q: 1.2011623
14 Número: 83, Nombre: Peng Zhengren, Edad: 25, Experiencia: 2, Educación: 2, Escuela: Universidad de Ciencia y Tecnología de Huazhong, aim_job_1: 0, aim_job_2: 10 Valor Q: 0.0
15 Número: 35, Nombre: Lin Jialun, Edad: 28, Experiencia: 5, Educación: 2, Escuela: Shanghai Jiaotong University, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
16 Número: 43, Nombre: Lin Shimei, Edad: 34, Experiencia: 11, Educación: 2, Escuela: Universidad de Chongqing, aim_job_1: 3, aim_job_2: 4 Valor Q: 0.0
17 Num: 52, Nombre: Ye Weizhi, Edad: 34, Experiencia: 3, Educación: 4, Escuela: Universidad de Comunicación de China, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
18 Num: 62, Nombre: Lin Yahui, Edad: 24, Experiencia: 5, Educación: 0, Escuela: Guangzhou Light Industry Vocational School, aim_job_1: 0, aim_job_2: 10 Valor Q: 0.0
19 Núm.: 66, Nombre: Lai Shuzhen, Edad: 27, Experiencia: 1, Educación: 0, Escuela: Escuela Técnica y Vocacional de Changsha, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
20 Num: 15, Nombre: Hong Zhenxia, Edad: 23, Experiencia: 4, Educación: 0, Escuela: Escuela Secundaria Técnica de Shenzhen, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
21 Num: 8, Nombre: Lin Zifan, Edad: 28, Experiencia: 6, Educación: 1, Escuela: Yangjiang Vocational College, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
22 Num: 6, Nombre: Liu Bohong, Edad: 31, Experiencia: 9, Educación: 1, Escuela: Guangdong Teachers College, aim_job_1: 10, aim_job_2: 10 Valor Q: 0.0
23 Número: 4, Nombre: Lin Yanan, Edad: 28, Experiencia: 5, Educación: 2, Escuela: Universidad Normal del Sur de China, aim_job_1: 4, aim_job_2: 10 Valor Q: 0.0
24 Número: 45, Nombre: Hu Tai, Edad: 33, Experiencia: 10, Educación: 2, Escuela: Universidad Sun Yat-sen, aim_job_1: 0, aim_job_2: 4 Valor Q: -0.3499998
25 Número: 42, Nombre: Li Zhi, Edad: 32, Experiencia: 9, Educación: 2, Escuela: Universidad de Tongji, aim_job_1: 4, aim_job_2: 10 Valor Q: -0.36110973
Muestra que incluso si la tasa de exploración se lleva a 1, es difícil resolver el problema de que cuando se alcanza el estado terminal de la última ronda de iteración, el valor Q de algunas acciones no se ha predicho con éxito, es decir, el no se ha ejecutado la acción, que puede contener el desvinculado óptimo.
La solución es establecer la condición de alcanzar el estado terminal para ejecutar todas las acciones en la primera ronda de iteración:
if episode == 0:
if set(range(12, 112)).issubset(set(action_union)):
done = True
else:
done = FalseDe esta manera, cada acción se puede ejecutar por completo y se evita que el valor de la recompensa sea demasiado escaso.

Figura 12 El algoritmo converge rápidamente

Figura 13 Diagrama de valor Q correspondiente estado-acción tridimensional
6. El problema de la baja precisión
Al volver a probar al final, se encontró que la tasa de precisión fue muy baja durante mucho tiempo durante la iteración, lo que no era completamente consistente con los resultados estándar. El autor consideró que la razón era que la cantidad de muestras tomadas del la reproducción de experiencia se limitó cada vez, y el grupo de reproducción de experiencia al final de la iteración El número total de muestras en el medio es mucho mayor que el número de muestras tomadas cada vez, por lo que el autor lo estableció. Cada vez que el resultado estándar es hit, el número de muestras tomadas cada vez aumenta en 100, de modo que las muestras aprendidas por la red neuronal sean más suficientes y la predicción sea más precisa.
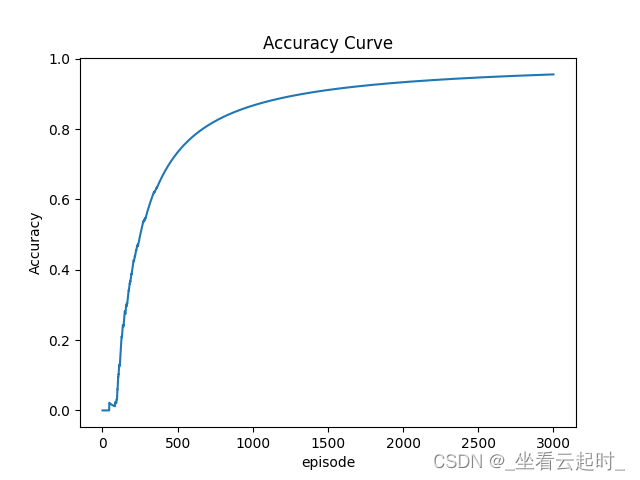
Figura 14 La precisión del algoritmo aumenta con el número de iteraciones
6. Resumen y perspectiva
Para el problema de la coincidencia de persona-publicación para la coincidencia de funciones, personalmente creo que DQN no es una solución excelente, y se debe usar la tecnología de procesamiento de lenguaje natural. Debido al tiempo limitado del proyecto, no hay tiempo para cambiar la solución y desarrollar la modelo desde cero. El algoritmo Actor-Critic se puede utilizar para desarrollar publicaciones humanas. La coincidencia del modelo debería tener mejores resultados.
7. Referencias
[1] Lu Yamin. Algoritmo de recomendación de video basado en la combinación de FM y DQN [J] Computer and Digital Engineering, 2021,49(09):1771-1776.
[2] https://gsurma.medium.com/cartpole-introduction-to-reinforcement-learning-ed0eb5b58288
[3]
[6]
[10] ¿Qué es la reproducción de experiencia DQN de aprendizaje por refuerzo?