Directorio de artículos
Los microservicios son un patrón arquitectónico o una solución para sistemas distribuidos. Divide una aplicación grande y compleja en muchos servicios pequeños e independientes que se pueden desarrollar, implementar y escalar de forma independiente. A continuación, seguiremos este esquema y profundizaremos en las partes clave de la implementación de microservicios en Java.
1. Descubrimiento de registro de servicio
En una arquitectura de microservicios, el registro y el descubrimiento de servicios son infraestructuras clave que respaldan la comunicación y la coordinación entre microservicios. El patrón de registro y descubrimiento de servicios incluye principalmente dos componentes principales: registro de servicios y cliente.
El registro de servicios es una base de datos que almacena los servicios disponibles. Cada instancia de servicio registrará su propia dirección de red y otros metadatos con el registro de servicios cuando se inicie. Antes de llamar al servicio, el consumidor del servicio primero obtendrá la dirección de red del proveedor del servicio del registro del servicio y luego llamará directamente al proveedor del servicio. El registro del servicio proporciona un mecanismo de verificación del estado del servicio para verificar periódicamente si el servicio registrado está disponible y, si la verificación falla, la instancia del servicio se eliminará del registro del servicio.
En Java, hay muchas soluciones maduras para el registro y descubrimiento de servicios, como Eureka de Netflix, Zookeeper de Apache y Consul de HashiCorp. Todas estas herramientas son compatibles con la arquitectura de microservicios.
Aquí, tomamos Eureka como ejemplo para presentar brevemente cómo implementar el registro y descubrimiento de servicios en aplicaciones Spring Boot.
Registro de servicios de Eureka
Primero, necesitamos crear un servidor Eureka como registro de servicio. En una aplicación Spring Boot, @EnableEurekaServerse puede iniciar un servidor Eureka a través de anotaciones.
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
Luego configure la información del servidor Eureka en el archivo application.yml.
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
La configuración anterior define el puerto de inicio y el nombre de host de Eureka Server, y cierra la función de registrarse consigo mismo y obtener información de registro, ya que este es un centro de registro de servicios, no es necesario realizar estas operaciones.
cliente eureka
Luego, necesitamos crear un Cliente Eureka y registrarlo con el Servidor Eureka. En una aplicación Spring Boot, se puede iniciar un cliente Eureka a través de @EnableEurekaClientanotaciones @EnableDiscoveryClient.
@SpringBootApplication
@EnableEurekaClient
public class ServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceApplication.class, args);
}
}
Luego configure la información del Cliente Eureka en el archivo application.yml.
spring:
application:
name: service-a
server:
port: 8080
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
La configuración anterior define el nombre del servicio, el puerto de inicio y la dirección del servidor Eureka.
Hasta ahora, hemos creado un registro de servicios de Eureka y un cliente de Eureka, y completamos el proceso básico de registro y descubrimiento de servicios. En el desarrollo real, también es necesario considerar las comprobaciones del estado del servicio, cómo los consumidores del servicio llaman a los proveedores de servicios a través de los nombres de los servicios y la implementación de servicios de alta disponibilidad.
1.2 Puerta de enlace API
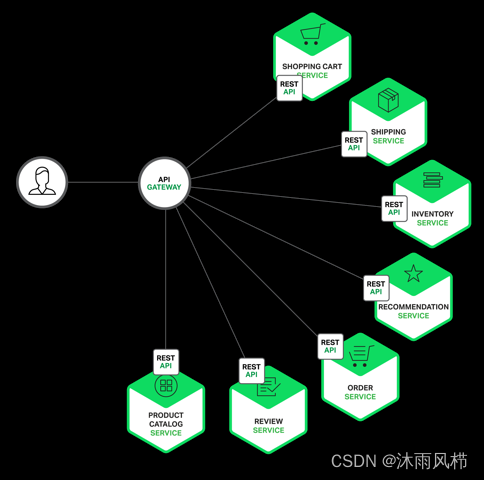
La puerta de enlace API juega un papel muy importante en la arquitectura de microservicios. Actúa como una capa intermedia entre el cliente y varios microservicios.Todas las solicitudes de los clientes pasarán primero a través de la puerta de enlace API y luego se distribuirán a los microservicios correspondientes. Esto tiene muchas ventajas, incluida la simplificación de las llamadas de los clientes, la ocultación de detalles de los servicios internos, la protección de seguridad unificada y el manejo centralizado de problemas entre servicios.
En Java, Spring Cloud Gateway y Netflix Zuul son dos soluciones de puerta de enlace API de uso común. Tomemos Spring Cloud Gateway como ejemplo para ver cómo implementar API Gateway en la aplicación Spring Boot.
Primero, necesitamos crear un proyecto Spring Boot y agregar las dependencias de Spring Cloud Gateway al proyecto.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
Luego, podemos configurar las reglas de enrutamiento en el archivo application.yml. La siguiente configuración indica que todas las solicitudes cuya ruta de solicitud comience con /api/users se enrutarán al servicio de servicio de usuario.
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates:
- Path=/api/users/**
filters:
- StripPrefix=1
En esta configuración, lb://user-servicees la dirección del servicio de servicio al usuario, Path=/api/users/**la condición para la coincidencia de rutas StripPrefix=1y un filtro que elimina el prefijo /api/users en la ruta de la solicitud.
Además, Spring Cloud Gateway también proporciona muchas funciones potentes, que incluyen la limitación de corriente de solicitud, el interruptor de circuito, el reintento, la verificación de seguridad, etc. Estas funciones se pueden realizar de manera muy conveniente configurando los filtros correspondientes y los filtros globales.
Por ejemplo, la siguiente configuración indica que solo se permiten 100 solicitudes por segundo para el acceso al servicio de usuario.
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates:
- Path=/api/users/**
filters:
- StripPrefix=1
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 100
redis-rate-limiter.burstCapacity: 100
Lo anterior es el proceso básico de implementación de la puerta de enlace API en la aplicación Spring Boot. En el desarrollo real, también es necesario personalizar varias reglas de enrutamiento y filtros según las necesidades específicas.
1.3 Centro de configuración
En la arquitectura de microservicios, debido a la gran cantidad de servicios, la información de configuración se encuentra dispersa en cada servicio, lo que trae grandes desafíos para la gestión de la configuración. Para resolver este problema, podemos introducir un centro de configuración para almacenar y gestionar de forma centralizada toda la información de configuración. Cuando la información de configuración cambia, el centro de configuración puede enviar actualizaciones en tiempo real para garantizar que todos los servicios utilicen la información de configuración más reciente.
En Java, Spring Cloud Config es una solución de centro de configuración de uso común. Tomemos Spring Cloud Config como ejemplo para ver cómo implementar un centro de configuración en una aplicación Spring Boot.
Primero, necesitamos crear un Spring Cloud Config Server como centro de configuración. En una aplicación Spring Boot, @EnableConfigServerse puede iniciar un servidor de configuración a través de anotaciones.
@SpringBootApplication
@EnableConfigServer
public class ConfigServerApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigServerApplication.class, args);
}
}
Luego, debemos configurar la información del servidor de configuración en el archivo application.yml, así como la ubicación de almacenamiento del archivo de configuración. La siguiente configuración indica que Config Server leerá los archivos de configuración del repositorio local de git.
server:
port: 8888
spring:
cloud:
config:
server:
git:
uri: file://${
user.home}/config-repo
En esta configuración, file://${user.home}/config-repoes la ubicación de almacenamiento del archivo de configuración y el servidor de configuración leerá el archivo de configuración desde esta ubicación.
Luego, necesitamos crear un Spring Cloud Config Client para leer la información de configuración del Config Server. En una aplicación Spring Boot, spring-cloud-starter-configse puede iniciar un Config Client.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
Luego, debemos configurar la información de Config Client en el archivo bootstrap.yml. La siguiente configuración indica que Config Client leerá la información de configuración llamada my-service desde Config Server en localhost:8888.
spring:
application:
name: my-service
cloud:
config:
uri: http://localhost:8888
En esta configuración, http://localhost:8888es la dirección del Config Server my-servicey el nombre del servicio, y el Config Client leerá la información de configuración correspondiente a este nombre del Config Server.
Lo anterior es el proceso básico de implementación del centro de configuración en la aplicación Spring Boot. En el desarrollo real, también es necesario considerar el cifrado de la información de configuración, la inserción en tiempo real de los cambios de configuración y la gestión de versiones de la configuración.
1.4 Programación de eventos (Kafka)
En la arquitectura de microservicios, la comunicación entre servicios a menudo adopta una forma síncrona o asíncrona. Sin embargo, a medida que aumenta la escala y la complejidad del sistema, este método de comunicación puede dar lugar a un aumento del acoplamiento entre servicios. La arquitectura dirigida por eventos (EDA) es una forma efectiva de resolver este problema, que se basa en el modelo de publicación-suscripción basado en eventos para lograr el desacoplamiento entre servicios.
Kafka es una popular plataforma de transmisión de eventos que almacena y transmite eventos como flujos de tiempo a microservicios individuales. Kafka proporciona procesamiento de flujo de eventos con alto rendimiento, baja latencia y sólidas garantías de consistencia.
En Spring Boot, podemos usar Spring Kafka para las operaciones de Kafka. Primero, debemos introducir las dependencias de Spring Kafka en el proyecto.
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
productor de kafka
Los productores de Kafka se utilizan para enviar mensajes a Kafka. Aquí hay un ejemplo de un productor de Kafka simple:
@Service
public class KafkaProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void send(String topic, String message) {
kafkaTemplate.send(topic, message);
}
}
En este ejemplo, KafkaTemplatepara enviar mensajes a Kafka. Solo necesitamos llamar a su sendmétodo y especificar el asunto y el contenido del mensaje.
consumidor kafka
Los consumidores de Kafka están acostumbrados a recibir mensajes de Kafka. Aquí hay un ejemplo de un consumidor de Kafka simple:
@Service
public class KafkaConsumer {
@KafkaListener(topics = "${kafka.topic}")
public void receive(String message) {
System.out.println("Received message: " + message);
}
}
En este ejemplo, @KafkaListenerel método marcado con la anotación se utilizará como método de procesamiento del mensaje. ${kafka.topic}Este método se llamará cuando se reciba un mensaje con asunto .
El código anterior muestra el proceso básico de cómo usar Spring Kafka para la programación de eventos en Spring Boot. En el desarrollo real, se deben tratar problemas como la serialización y deserialización de mensajes, el manejo de errores, la gestión de transacciones y la partición de mensajes.
1.5 Seguimiento del servicio (starter-sleuth)
En la arquitectura de microservicios, las solicitudes pueden completarse a través de múltiples servicios, si hay un problema en un enlace determinado, es difícil localizarlo rápidamente. Para resolver este problema, necesitamos introducir el seguimiento del servicio. El seguimiento del servicio puede registrar la ruta completa de la solicitud en el sistema y proporcionar un enlace de llamada visual para ayudarnos a localizar el problema.
En Java, Spring Cloud Sleuth es una solución de uso común para el seguimiento de servicios. En la aplicación Spring Boot, podemos habilitar el seguimiento del servicio introduciendo la dependencia de spring-cloud-starter-sleuth.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
Sleuth generará automáticamente un ID de seguimiento único y varios ID de tramo para cada solicitud. El ID de seguimiento representa un enlace de solicitud completo y el ID de tramo representa un enlace en el enlace de solicitud. Podemos ver estos ID en el registro y también podemos cooperar con herramientas como Zipkin para visualización.
1.6 Fusible de servicio (Hystrix)
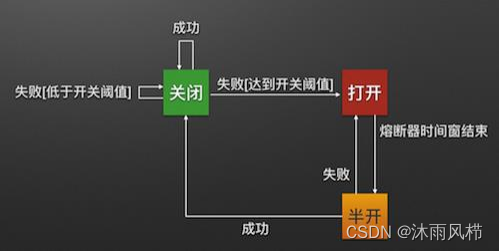
En la arquitectura de microservicios, debido a las dependencias entre servicios, una vez que un servicio falla, todo el sistema puede quedar paralizado, lo que es el llamado efecto avalancha. Para evitar el efecto de avalancha, debemos introducir un mecanismo de fusión de servicio. Cuando hay un problema con un servicio, el fusible del servicio puede desconectar la llamada al servicio a tiempo para evitar que el problema se extienda aún más.
En Java, Hystrix de Netflix es una biblioteca de procesamiento tolerante a fallas y de fusión de servicios de uso común. En la aplicación Spring Boot, podemos habilitar el fusible del servicio introduciendo la dependencia de spring-cloud-starter-netflix-hystrix.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
Luego, podemos agregar la anotación @HystrixCommand al método que necesita protección de fusible para especificar el método de degradación.
@HystrixCommand(fallbackMethod = "fallbackMethod")
public String hystrixMethod() {
// your code
}
public String fallbackMethod() {
return "fallback value";
}
En este ejemplo, cuando hystrixMethodla ejecución del método falla o se agota, Hystrix llamará automáticamente fallbackMethodal método y devolverá el resultado de degradación.
Lo anterior es el proceso básico para implementar el seguimiento de servicios y la fusión de servicios en las aplicaciones Spring Boot. En el desarrollo real, también es necesario considerar el almacenamiento y la consulta del seguimiento del servicio, la configuración de políticas y el monitoreo de la fusión del servicio, etc.
1.7 Gestión de API
La gestión de API es una parte importante de la arquitectura de microservicios, que incluye principalmente el diseño de API, el lanzamiento, la gestión de versiones, el control de acceso, la limitación actual, la facturación, la supervisión y otras funciones. A través de la gestión de API, podemos proporcionar una interfaz API coherente, garantizar la disponibilidad y seguridad de la API y mejorar la experiencia de uso de la API.
En Java, hay muchas herramientas de administración de API, como Swagger, Postman, etc. En las aplicaciones Spring Boot, podemos usar Swagger para la gestión de API.
Primero, debemos introducir las dependencias de Swagger en el proyecto.
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
Luego, debemos configurar Swagger para generar documentación API.
@Configuration
@EnableSwagger2
public class SwaggerConfig {
@Bean
public Docket api() {
return new Docket(DocumentationType.SWAGGER_2)
.select()
.apis(RequestHandlerSelectors.any())
.paths(PathSelectors.any())
.build();
}
}
En esta configuración, @EnableSwagger2Swagger está habilitado apis(RequestHandlerSelectors.any())y paths(PathSelectors.any())se generan documentos API para todos los Controladores.
Además, también podemos usar anotaciones Swagger en los métodos del controlador para proporcionar información API más detallada.
@RestController
@RequestMapping("/api/users")
public class UserController {
@ApiOperation(value = "Get all users", notes = "Get a list of all users")
@GetMapping("/")
public List<User> getAllUsers() {
// your code
}
// other methods
}
En este ejemplo, @ApiOperationlas anotaciones representan las operaciones y anotaciones de esta API.
Resumir
La arquitectura de microservicios es una arquitectura distribuida que divide un sistema complejo en un conjunto de servicios independientes, cada servicio tiene su propia base de datos y lógica comercial, y los servicios se comunican a través de API.
En este artículo, presentamos siete componentes clave de la arquitectura de microservicios, incluidos el registro y descubrimiento de servicios, la puerta de enlace de API, el centro de configuración, la programación de eventos, el seguimiento de servicios, la fusión de servicios y la gestión de API, y usamos Spring Boot de Java para lograr resultados detallados.
Esta es solo la punta del iceberg de la arquitectura de microservicios, que también involucra muchos otros aspectos, como la implementación y el monitoreo del servicio, la consistencia y el aislamiento de los datos, las pruebas y la evolución del servicio, etc. Espero que este artículo pueda ayudarlo a tener una comprensión básica de los microservicios y sentar una base sólida para su estudio posterior de los microservicios.