
Hace unos días, Kaggle lanzó el ICR - Competencia de identificación de enfermedades relacionadas con la edad. Esta es una tarea de clasificación binaria en el aprendizaje automático . Debe usar el método ML para diagnosticar pacientes y determinar si los pacientes tienen enfermedades relacionadas, a fin de proporcionar a los médicos una base para un diagnóstico razonable.
Esta competencia proporciona 4 piezas de datos, a saber:
tren, prueba, sample_submission, griegos. en:
El archivo de tren marca las características y etiquetas relevantes de cada paciente.
test y sample_submission se utilizan al enviar respuestas.
griegos son metadatos complementarios y solo se aplican al conjunto de entrenamiento.
Para ayudar a los estudiantes a sumar puntos y obtener tarjetas, les he traído grandes beneficios:
¡El precio original de 198 yuanes es gratis para ver la conferencia de la competencia!
¡Completa la línea de base de puntaje alto gratis!
" Introducción clásica a la competencia de algoritmos (2ª edición ) " ¡ envío gratis! (Detalles al final del artículo)

¡Escanee el código QR para ver las conferencias, obtener la línea de base y recoger libros gratis!
Conferencia de competencia

Análisis de datos de entrenamiento
Number of rows in train data: 617
Number of columns data: 58Muestra de datos:

Distribución de datos:

Análisis de correlación:
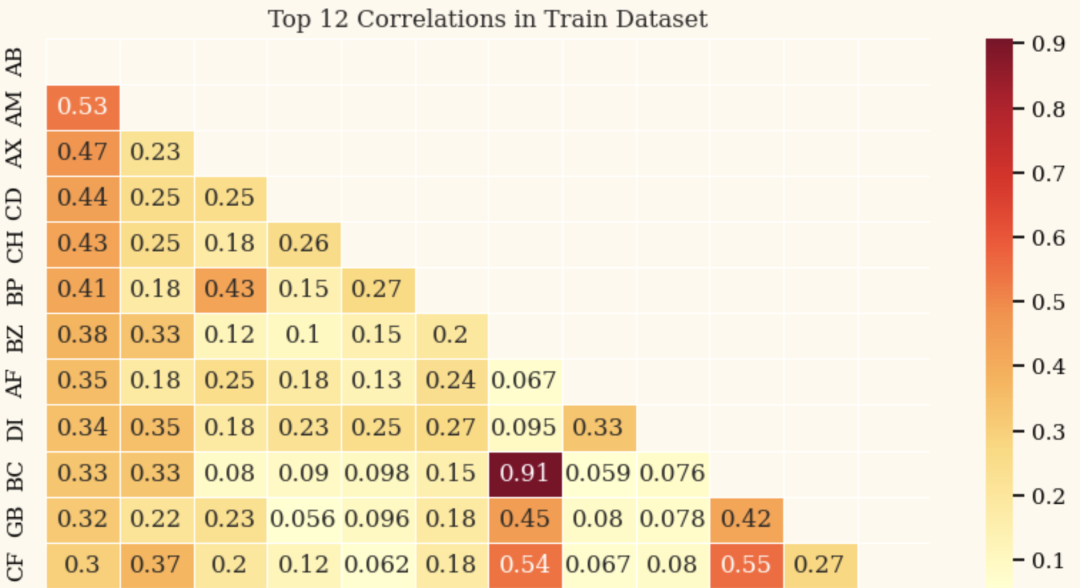
Crear datos de entrenamiento
Lea los datos, vea el código de referencia para obtener más detalles, que tiene una introducción más detallada
train = pd.read_csv('/kaggle/input/icr-identify-age-related-conditions/train.csv')
test = pd.read_csv('/kaggle/input/icr-identify-age-related-conditions/test.csv')
greeks = pd.read_csv('/kaggle/input/icr-identify-age-related-conditions/greeks.csv')
sample_submission = pd.read_csv('/kaggle/input/icr-identify-age-related-conditions/sample_submission.csv')Proceso de línea de base
Cargar datos, procesamiento de características:
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
# Combine numeric and categorical features
FEATURES = num_cols + cat_cols
# Fill missing values with mean for numeric variables
imputer = SimpleImputer(strategy='mean')
numeric_df = pd.DataFrame(imputer.fit_transform(train[num_cols]), columns=num_cols)
# Scale numeric variables using min-max scaling
scaler = MinMaxScaler()
scaled_numeric_df = pd.DataFrame(scaler.fit_transform(numeric_df), columns=num_cols)
# Encode categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse=False, handle_unknown='ignore')
encoded_cat_df = pd.DataFrame(encoder.fit_transform(train[cat_cols]), columns=encoder.get_feature_names_out(cat_cols))
# Concatenate the scaled numeric and encoded categorical variables
processed_df = pd.concat([scaled_numeric_df, encoded_cat_df], axis=1)Defina la función de entrenamiento:
from sklearn.utils import class_weight
FOLDS = 10
SEED = 1004
xgb_models = []
xgb_oof = []
f_imp = []
counter = 1
X = processed_df
y = train['Class']
# Calculate the sample weights
weights = class_weight.compute_sample_weight('balanced', y)
skf = StratifiedKFold(n_splits=FOLDS, shuffle=True, random_state=SEED)
for fold, (train_idx, val_idx) in enumerate(skf.split(X, y)):
if (fold + 1)%5 == 0 or (fold + 1) == 1:
print(f'{"#"*24} Training FOLD {fold+1} {"#"*24}')
X_train, y_train = X.iloc[train_idx], y.iloc[train_idx]
X_valid, y_valid = X.iloc[val_idx], y.iloc[val_idx]
watchlist = [(X_train, y_train), (X_valid, y_valid)]
# Apply weights in the XGBClassifier
model = XGBClassifier(n_estimators=1000, n_jobs=-1, max_depth=4, eta=0.2, colsample_bytree=0.67)
model.fit(X_train, y_train, sample_weight=weights[train_idx], eval_set=watchlist, early_stopping_rounds=300, verbose=0)
val_preds = model.predict_proba(X_valid)[:, 1]
# Apply weights in the log_loss
val_score = log_loss(y_valid, val_preds, sample_weight=weights[val_idx])
best_iter = model.best_iteration
idx_pred_target = np.vstack([val_idx, val_preds, y_valid]).T
f_imp.append({i: j for i, j in zip(X.columns, model.feature_importances_)})
print(f'{" "*20} Log-loss: {val_score:.5f} {" "*6} best iteration: {best_iter}')
xgb_oof.append(idx_pred_target)
xgb_models.append(model)
print('*'*45)
print(f'Mean Log-loss: {np.mean([log_loss(item[:, 2], item[:, 1], sample_weight=weights[item[:, 0].astype(int)]) for item in xgb_oof]):.5f}')Vista de importancia de la función:
# Confusion Matrix for the last fold
cm = confusion_matrix(y_valid, model.predict(X_valid))
# Feature Importance for the last model
feature_imp = pd.DataFrame({'Value':xgb_models[-1].feature_importances_, 'Feature':X.columns})
feature_imp = feature_imp.sort_values(by="Value", ascending=False)
feature_imp_top20 = feature_imp.iloc[:20]
fig, ax = plt.subplots(1, 2, figsize=(14, 4))
# Subplot 1: Confusion Matrix
sns.heatmap(cm, annot=True, fmt='d', ax=ax[0], cmap='YlOrRd')
ax[0].set_title('Confusion Matrix')
ax[0].set_xlabel('Predicted')
ax[0].set_ylabel('True')
# Subplot 2: Feature Importance
sns.barplot(x="Value", y="Feature", data=feature_imp_top20, ax=ax[1], palette='YlOrRd_r')
ax[1].set_title('Feature Importance')
plt.tight_layout()
plt.show()
¡Escanee el código QR para ver las conferencias, obtener la línea de base y recoger libros gratis!
Beneficios del libro de envío gratis

Agrega servicio al cliente y participa en la lotería para enviar libros con la captura de pantalla del artículo actual. ¡Se seleccionarán 50 estudiantes y se enviará "Introducción a la competencia de algoritmos (segunda edición)" con envío gratuito!
Los libros se enviarán por correo a fin de mes, gracias por su paciencia~

¡Escanee el código QR para ver las conferencias, obtener la línea de base y recoger libros gratis!