1. Introducción al registro de nubes de puntos
1. El concepto de registro de nubes de puntos
El registro de imágenes es un problema típico y una dificultad técnica en el campo de la investigación del procesamiento de imágenes. Su propósito es comparar o fusionar imágenes adquiridas en diferentes condiciones para el mismo objeto. Por ejemplo, las imágenes provendrán de diferentes dispositivos de adquisición, tomadas en diferentes momentos, diferentes ángulos de disparo, etc. A veces también se requiere el registro de imágenes para diferentes objetos. Específicamente, para dos imágenes en un conjunto de conjuntos de datos de imágenes, una imagen se asigna a otra imagen al encontrar una transformación espacial, de modo que los puntos correspondientes a la misma posición espacial en las dos imágenes correspondan uno a uno, para lograr el propósito de fusión de información. Una aplicación clásica es la reconstrucción de escenas. Por ejemplo, hay muchas tazas en una mesa de café y se usa una cámara de profundidad para escanear la escena. Por lo general, es imposible escanear todos los objetos en la escena a través de una adquisición. Solo puede obtener nubes de puntos desde diferentes ángulos de la escena, y luego fusionar estas nubes de puntos para obtener una escena completa.
En pocas palabras, el registro de nubes de puntos (Registro de nubes de puntos) se refiere a ingresar dos nubes de puntos (fuente) y
(objetivo), y generar una transformación
para que
la
coincidencia de la suma sea lo más alta posible. En otras palabras, para dos sistemas de coordenadas bajo diferentes ángulos de visión, como el sistema de coordenadas del mundo y el sistema de coordenadas de la cámara, necesitamos encontrar una transformación
para transformar los dos sistemas de coordenadas en un ángulo de visión unificado. Aquí solo consideramos la transformación rígida, es decir, la transformación solo incluye la rotación y la traslación.
2. El proceso de registro de nubes de puntos
En la actualidad, la tecnología tradicional de registro de nube de puntos convencional incluye principalmente dos etapas de registro grueso y registro fino . El propósito de la etapa de registro grueso es alinear aproximadamente las dos nubes de puntos para cualquier estado inicial de las dos nubes de puntos y proporcionar valores iniciales para la matriz de rotación R y el vector de traducción T. El registro fino se basa en el registro grueso y realiza un registro más preciso y fino. Con todo, el proceso de registro de nubes de puntos es el proceso de transformación de matriz.
2. Algoritmo de registro grueso de nube de puntos
El registro de nubes de puntos gruesos, también conocido como registro inicial de nubes de puntos, tiene como objetivo alinear aproximadamente dos nubes de puntos en cualquier posición inicial, a fin de proporcionar una buena posición inicial para el registro de nubes de puntos finos. El algoritmo de registro aproximado de la nube de puntos se divide principalmente en dos categorías, a saber, el método de registro basado en la idea de búsqueda global y el método de registro basado en la descripción de características geométricas .
1. Método de registro basado en la idea de búsqueda global
El método de registro basado en la idea de búsqueda global generalmente selecciona aleatoriamente varios puntos (generalmente tres) de los datos de origen y encuentra los puntos correspondientes de los datos de destino de acuerdo con la búsqueda exhaustiva de los datos de destino, calcula todas las matrices de transformación posibles y determina la transformación óptima votando o seleccionando el método con la función de error más pequeña. Al considerar todas las correspondencias posibles, se puede obtener un mejor efecto de registro, pero a menudo produce una gran carga de cálculo. Uno de los marcos algorítmicos más utilizados es el algoritmo RANSAC (Random Sampling Consensus) .
1.1 Algoritmo de registro de nube de puntos RANSAC
El algoritmo RANSAC se propuso por primera vez en el campo de las matemáticas/estadística.Es un método que utiliza muestras recolectadas al azar para ajustar con precisión los parámetros del modelo matemático general. Su idea principal es seleccionar aleatoriamente algunas muestras de un conjunto de muestras dado y estimar un modelo matemático, y llevar el resto de las muestras al modelo matemático para su verificación. Si hay suficientes errores de muestra dentro del rango dado, el modelo matemático es óptimo; de lo contrario, continúe con este paso.
Posteriormente, el algoritmo RANSAC se introdujo en el campo del registro de nubes de puntos 3D y se produjo un algoritmo de registro de nubes de puntos RANSAC basado en el pensamiento de RANSAC. El proceso del algoritmo es principalmente el siguiente:

Su esencia es muestrear continuamente muestras aleatorias de la nube de puntos de origen y obtener el modelo de transformación correspondiente, luego probar cada modelo de transformación aleatoria y continuar ciclando el proceso hasta que se seleccione el modelo de transformación óptimo como resultado final. De acuerdo con la ley de los grandes números, se puede saber que en el caso de un gran número de experimentos de muestreo repetidos, la simulación aleatoria puede aproximarse al resultado correcto. Por supuesto, el algoritmo de registro RANSAC también tiene desventajas, como un registro inestable y una gran cantidad de cálculos provocados por la aleatoriedad finita.
1.2 Algoritmo 4PCS
El nombre completo del algoritmo 4PCS es Conjuntos congruentes de 4 puntos, es decir, algoritmo de registro de conjuntos congruentes de 4 puntos. El algoritmo también se basa en el marco del algoritmo RANSAC, que no impone restricciones en las poses iniciales de las dos nubes de puntos , optimiza la estrategia para buscar los puntos correspondientes y expande los tres conjuntos básicos de puntos correspondientes a cuatro conjuntos de puntos correspondientes con ciertas restricciones, lo que aumenta en gran medida la solidez del algoritmo y mejora la eficiencia de búsqueda del algoritmo. La complejidad temporal del algoritmo es de aprox . La idea central del algoritmo es usar la invariancia geométrica (relación vector/segmento de línea, distancia euclidiana entre puntos) en la transformación de cuerpo rígido , de acuerdo con las características de la proporción invariable del segmento de línea ocupado por el punto de intersección y la distancia euclidiana invariable entre los puntos después de la transformación rígida, intente encontrar cuatro puntos aproximadamente coplanares (cuatro conjuntos de puntos aproximadamente congruentes) correspondientes a ellos en la nube de puntos de destino, y luego use el método de mínimos cuadrados para calcular la matriz de transformación . .
(1) Conjunto congruente de cuatro puntos
En el algoritmo 4PCS, expandimos la nube de puntos de registro local de tres puntos a cuatro puntos, y estos cuatro puntos tienen ciertas restricciones adicionales.Si el conjunto de cuatro puntos correspondiente que satisface aproximadamente las restricciones se puede encontrar en la nube de puntos de destino, llamamos a estos dos conjuntos de cuatro puntos correspondientes.Los conjuntos de cuatro puntos congruentes se utilizan para resolver la transformación de la nube de puntos. En comparación con el método de muestreo completamente aleatorio en el algoritmo de registro RANSAC tradicional, a través de la aplicación de conjuntos congruentes de cuatro puntos, por un lado, el algoritmo reduce la cantidad de cálculo, mejora la eficiencia y hace que la búsqueda global sea más específica; por otro lado, el algoritmo utiliza registro local de cuatro puntos con restricciones, que tiene mayor precisión y robustez. Los criterios de selección y restricción del conjunto de cuatro puntos son los siguientes:
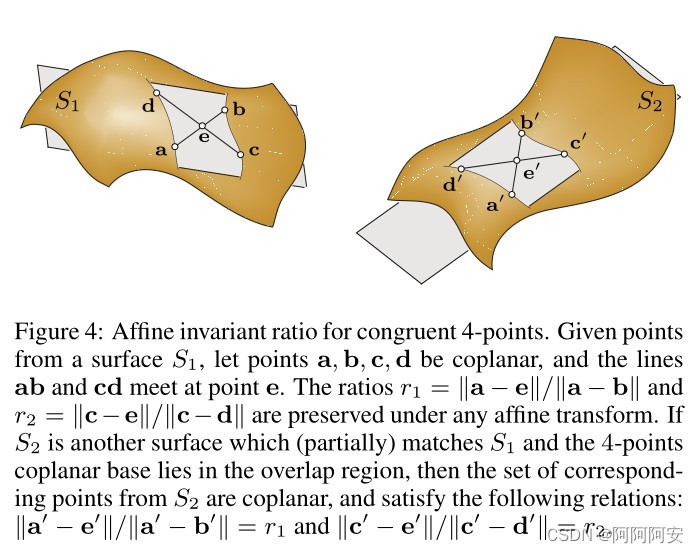
- En primer lugar, se seleccionan aleatoriamente tres puntos en la nube de puntos de origen, y se requiere que el área del triángulo formado por estos tres puntos sea lo más grande posible (los tres puntos determinan un plano y el producto vectorial puede calcular el área), pero la distancia entre los tres puntos no puede exceder un cierto límite superior del umbral, que está determinado por la tasa de superposición f dada de las dos nubes de puntos. Porque cuanto mayor es la distancia entre los tres puntos, mayor es la solidez del registro, pero si la distancia es demasiado grande, los tres puntos están todos fuera del área superpuesta de las dos nubes de puntos y el efecto de registro no es bueno. Por lo tanto, es necesario asegurar un área de forma terciaria grande tanto como sea posible sobre la base de satisfacer el límite superior. Si no se proporciona la tasa de superposición de la nube de puntos f, entonces f=1,0, 0,75, 0,5... Se puede realizar la prueba de disminución de la tasa de superposición para seleccionar la transformación óptima.
- Después de determinar los tres puntos, el método de selección del cuarto punto en el conjunto de cuatro puntos de la nube de puntos de origen es el siguiente: recorrer todos los puntos en la nube de puntos de origen, calcular y verificar cada punto y seleccionar el cuarto punto óptimo. El cuarto punto debe ser lo más coplanar posible con el plano formado por los otros tres puntos (es decir, no es obligatorio que los cuatro puntos sean coplanares, pero la distancia entre el cuarto punto y el plano de los otros tres puntos debe ser lo más pequeña posible), y la distancia entre el cuarto punto y los otros tres puntos también debe cumplir con el rango del umbral de distancia (ni demasiado cerca ni demasiado lejos).
- Una vez completada la selección del conjunto de cuatro puntos en la nube de puntos de origen, se puede calcular la relación invariante de transformación del punto de intersección de los dos segmentos de línea formados por los cuatro puntos. De acuerdo con la relación invariante, todos los conjuntos de cuatro puntos que satisfacen la restricción se recorren en la nube de puntos de destino para el cálculo del registro. Este es el conjunto de cuatro puntos (aproximadamente) congruente.
(2) Flujo de algoritmo 4PCS
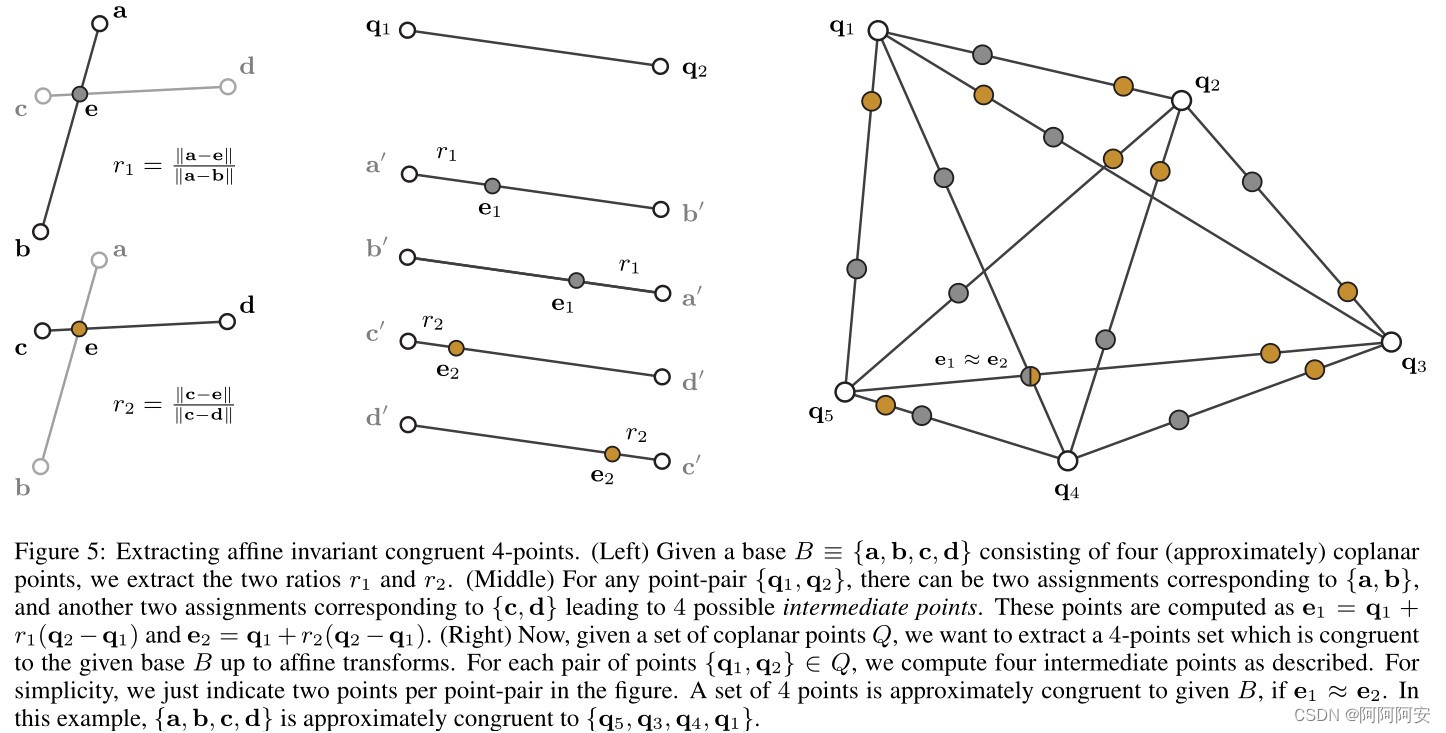
Después de comprender el concepto central de los conjuntos de cuatro puntos congruentes, introduzcamos los pasos del algoritmo de 4PCS para encontrar los puntos correspondientes basados en conjuntos de cuatro puntos congruentes de la siguiente manera:
- PASO 1: en la nube de puntos de origen P, utilice el método de selección de conjunto de cuatro puntos anterior para seleccionar aleatoriamente un conjunto de cuatro puntos B={b1,b2,b3,b4}, donde (b1,b2) determina el segmento de línea 1 y (b3,b4) determina el segmento de línea 2. Luego calcule el invariante d1=|b1-b2|, d2=|b3-b4|, la relación constante r1=|b1-e|/|b1-b2|, r2=|b3-e|/|b3-b4|. Tenga en cuenta que debido a que los cuatro puntos no son necesariamente coplanares y los dos segmentos de línea no necesariamente se cruzan, puede usar el punto central del punto más cercano que conecta los dos segmentos de línea como el "punto de intersección".
- PASO 2: en la nube de puntos de destino Q, recorra todos los pares de puntos y filtre los conjuntos de pares de puntos R1, R2 que satisfacen la primera restricción (la longitud del segmento de línea está dentro del rango de error de d1 o d2). que se expresa como:

- PASO 3: Atraviese todos los elementos de pares de puntos en el conjunto de pares de puntos R1 , calcule el punto de intersección de destino
en su segmento de línea que satisfaga la relación invariable r1
, y luego almacene todos los resultados de cálculo e en el árbol de búsqueda ANN Tree (árbol de búsqueda vecino más cercano aproximado, el más común es el algoritmo KD Tree) y construya el mapeo correspondiente
- PASO 4: Atraviese todos los elementos de pares de puntos en el conjunto de pares de puntos R2
, calcule el punto de intersección de destino en el segmento de línea que satisface la relación invariante r2
y construya el mapeo correspondiente
. Luego, recorra todos los puntos y busque los puntos coincidentes dentro del rango de error aceptable
- PASO 5: Recorra todos los conjuntos de cuatro puntos aproximadamente congruentes
y, para cada uno
, calcule su matriz de transformación correspondiente con B mediante el método de mínimos cuadrados
. Luego use la matriz de transformación para transformar la nube de puntos de origen P para obtener P', cuente el conjunto de puntos comunes más grande (LCP) en P' y Q , registre la matriz de transformación de max(LCP) como la matriz de transformación óptima T de esta iteración y consérvela.
- PASO 6: iterar continuamente este proceso y registrar la transformación óptima. La matriz de transformación obtenida después de la iteración es la matriz de transformación óptima. El marco del algoritmo del artículo original es el siguiente:

Nota: Algunas mejoras también se utilizan en la implementación de este algoritmo . Por ejemplo, sobre la base de las invariantes anteriores, se suma el cálculo del vector normal del punto correspondiente. Solo cuando la longitud del segmento de línea es aproximadamente igual y el ángulo entre los vectores normales de los puntos finales también es aproximadamente igual , se puede considerar como un par de segmentos de línea/vectores correspondientes, lo que fortalece aún más las condiciones de búsqueda y reduce el número de búsquedas.
(3) Dirección original en papel y código
- Dirección en papel: Conjuntos congruentes de 4 puntos para el registro robusto de superficies (stanford.edu)
- Dirección del código: http://vecg.cs.ucl.ac.uk/Projects/SmartGeometry/fpcs/paper_docs/4pcs_1.3.tar.gz
2. Método de registro basado en la descripción de características geométricas
Para ser llenado
2.1 Algoritmo FPFH
Para ser llenado
3. Algoritmo de registro fino de nube de puntos
Después de un registro aproximado, las partes superpuestas de las dos nubes de puntos se pueden alinear aproximadamente, pero la precisión está lejos de cumplir con nuestros requisitos. El algoritmo de registro fino consiste en realizar un registro adicional sobre la base de un registro aproximado para mejorar la precisión del registro. En la actualidad, la corriente principal de los algoritmos de registro fino es el algoritmo ICP (punto más cercano iterativo, punto más cercano iterativo) .
1. Algoritmo ICP
El algoritmo ICP requiere que las dos nubes de puntos a registrar tengan mejores posiciones iniciales (transformaciones iniciales R y T), es decir, se requiere que las dos nubes de puntos estén aproximadamente alineadas. La idea básica es seleccionar el punto más cercano en las dos nubes de puntos como el punto correspondiente, resolver la matriz de transformación de rotación y traslación a través de todos los pares de puntos correspondientes, y hacer que el error entre las dos nubes de puntos sea cada vez más pequeño a través de la iteración continua hasta que se cumpla el requisito de umbral o el número de iteración establecido de antemano. El marco del algoritmo del algoritmo ICP es el siguiente:

Se puede ver que toda la iteración del algoritmo ICP se puede desmontar en dos subproblemas centrales, a saber, encontrar el punto de coincidencia más cercano y calcular la transformación óptima. A continuación, explicaremos estos dos temas centrales por separado.
1.1 Descripción básica del algoritmo ICP
(1) Encuentra el punto de coincidencia más cercano
Utilice la transformación inicial o la transformación obtenida en la última iteración
para transformar la nube de puntos inicial P para obtener una nube de puntos transformada temporal P'. Luego use esta nube de puntos P' para hacer coincidir la nube de puntos de destino Q, encuentre el punto vecino más cercano de cada punto en la nube de puntos de origen en la nube de puntos de destino como el punto correspondiente y prepárese para el próximo cálculo de la transformación óptima. Los métodos comunes de coincidencia de vecinos más cercanos son:
- Método de ciclo violento: realice un ciclo doble en las dos nubes de puntos, recorra y haga coincidir cada par de puntos, calcule su distancia euclidiana, seleccione el punto más cercano como el punto correspondiente del punto y guárdelo. La complejidad de este método es
- Búsqueda ANN (vecino más cercano aproximado): use el algoritmo de búsqueda de vecino más cercano aproximado para insertar puntos en la estructura de árbol de búsqueda. El algoritmo de estructura de árbol de búsqueda más común es KD Tree para acelerar el proceso de búsqueda y coincidencia. La complejidad de este método es
. Utilizamos principalmente el algoritmo KD Tree para acelerar la búsqueda.
(2) Calcular la transformación óptima
Después de encontrar el punto correspondiente más cercano, necesitamos calcular los parámetros de transformación óptimos R y T que hacen que se registren las dos nubes de puntos correspondientes. Suponiendo que la nube de puntos de origen y la nube de puntos de destino estén representadas respectivamente, nuestra función de optimización objetiva es minimizar la distancia entre los puntos correspondientes después de la transformación , a saber:

Aquí usaremos la descomposición de valor singular SVD para calcular los parámetros de transformación óptimos , y los resultados finales de la fórmula de cálculo se dan a continuación. Para la prueba de este teorema, consulte mi blog o artículo anterior: https://zhuanlan.zhihu.com/p/104735380

1.2 Implementación del código del algoritmo ICP
import numpy as np
#计算最优变换参数R、T(SVD奇异值分解)
def best_fit_transform(A, B):
'''
Calculates the least-squares best-fit transform between corresponding 3D points A->B
Input:
A: Nx3 numpy array of corresponding 3D points
B: Nx3 numpy array of corresponding 3D points
Returns:
T: 4x4 homogeneous transformation matrix 齐次坐标
R: 3x3 rotation matrix
t: 3x1 column vector
'''
assert len(A) == len(B)
# translate points to their centroids
# 求点云质心,并变换坐标,消除平移的影响
centroid_A = np.mean(A, axis=0)
centroid_B = np.mean(B, axis=0)
AA = A - centroid_A
BB = B - centroid_B
# rotation matrix
# 变换后的坐标对应点相乘得到W
W = np.dot(BB.T, AA)
U, s, VT = np.linalg.svd(W) #对W进行SVD分解,得到矩阵
R = np.dot(U, VT) #最优旋转矩阵=UV^T
# special reflection case
# 反射特殊情况考虑
if np.linalg.det(R) < 0:
VT[2,:] *= -1
R = np.dot(U, VT)
# translation
# 最优平移
t = centroid_B.T - np.dot(R,centroid_A.T)
# homogeneous transformation
# 构造齐次坐标
T = np.identity(4)
T[0:3, 0:3] = R
T[0:3, 3] = t
return T, R, t
#寻找最近匹配点(暴力二重循环法),可以使用NearestNeighbors替换搜索
def nearest_neighbor(src, dst):
'''
Find the nearest (Euclidean) neighbor in dst for each point in src
Input:
src: Nx3 array of points
dst: Nx3 array of points
Output:
distances: Euclidean distances (errors) of the nearest neighbor
indecies: dst indecies of the nearest neighbor
'''
indecies = np.zeros(src.shape[0], dtype=np.int)
distances = np.zeros(src.shape[0])
for i, s in enumerate(src):
min_dist = np.inf
for j, d in enumerate(dst):
dist = np.linalg.norm(s-d)
if dist < min_dist:
min_dist = dist
indecies[i] = j
distances[i] = dist
return distances, indecies
#ICP算法迭代
def icp(A, B, init_pose=None, max_iterations=50, tolerance=0.001):
'''
The Iterative Closest Point method
Input:
A: Nx3 numpy array of source 3D points 原点云
B: Nx3 numpy array of destination 3D point 目标点云
init_pose: 4x4 homogeneous transformation 初始变换参数
max_iterations: exit algorithm after max_iterations 最大迭代次数
tolerance: convergence criteria 收敛误差
Output:
T: final homogeneous transformation 齐次坐标变换矩阵
distances: Euclidean distances (errors) of the nearest neighbor 误差
'''
# make points homogeneous, copy them so as to maintain the originals
src = np.ones((4,A.shape[0]))
dst = np.ones((4,B.shape[0]))
src[0:3,:] = np.copy(A.T)
dst[0:3,:] = np.copy(B.T)
# apply the initial pose estimation
# 点云初始变换
if init_pose is not None:
src = np.dot(init_pose, src)
prev_error = 0
for i in range(max_iterations):
# find the nearest neighbours between the current source and destination points
#1.找最近匹配点对应
distances, indices = nearest_neighbor(src[0:3,:].T, dst[0:3,:].T)
# compute the transformation between the current source and nearest destination points
#2.计算最优变换参数(SVD)
T,_,_ = best_fit_transform(src[0:3,:].T, dst[0:3,indices].T)
# update the current source
# refer to "Introduction to Robotics" Chapter2 P28. Spatial description and transformations
#3.更新变换点云
src = np.dot(T, src)
# check error
#4.检查误差是否收敛 MSELoss
mean_error = np.sum(distances) / distances.size
if abs(prev_error-mean_error) < tolerance:
break
prev_error = mean_error
# calculcate final tranformation
#5.迭代结束或误差收敛后,计算最终的变换参数(初始A->当前src,因为变换T没有迭代累计)
T,_,_ = best_fit_transform(A, src[0:3,:].T)
return T, distances
if __name__ == "__main__":
A = np.random.randint(0,101,(20,3)) # 20 points for test 随机源点云
rotz = lambda theta: np.array([[np.cos(theta),-np.sin(theta),0],
[np.sin(theta),np.cos(theta),0],
[0,0,1]])
trans = np.array([2.12,-0.2,1.3])
B = A.dot(rotz(np.pi/4).T) + trans #随即扰动->目标点云
T, distances = icp(A, B) #ICP算法计算得到最优参数
np.set_printoptions(precision=3,suppress=True)
print T