Tabla de contenido
Descomprimir y modificar el nombre de la carpeta
Copie la clave secreta a esta máquina
Configuración del entorno Java y configuración del entorno Hadoop
ejecutar secuencia de comandos
Modificar el archivo de configuración de hadoop
Configuración de inicialización de Hadoop
puesto de trabajo
Declaración, para la comodidad de la operación, todo el contenido se encuentra en la carpeta [/opt].
cd /optSubir paquete comprimido
Se requieren dos paquetes, java y hadoop, versiones 1.8 y 3.1.3.
Enlace de descarga:
https://download.csdn.net/download/feng8403000/88074219
subir a /optar

Descomprimir y modificar el nombre de la carpeta
descomprimir comando
tar -zxvf jdk-8u212-linux-x64.tar.gz
tar -zxvf hadoop-3.1.3.tar.gz
comando modificar carpeta
mv 文件夹名 jdk
mv 文件夹名 hadoop

Puede ver que se ha cambiado el nombre de la carpeta para facilitar la configuración de las variables del sistema.
configuración sin contraseña
ssh-keygen -t rsa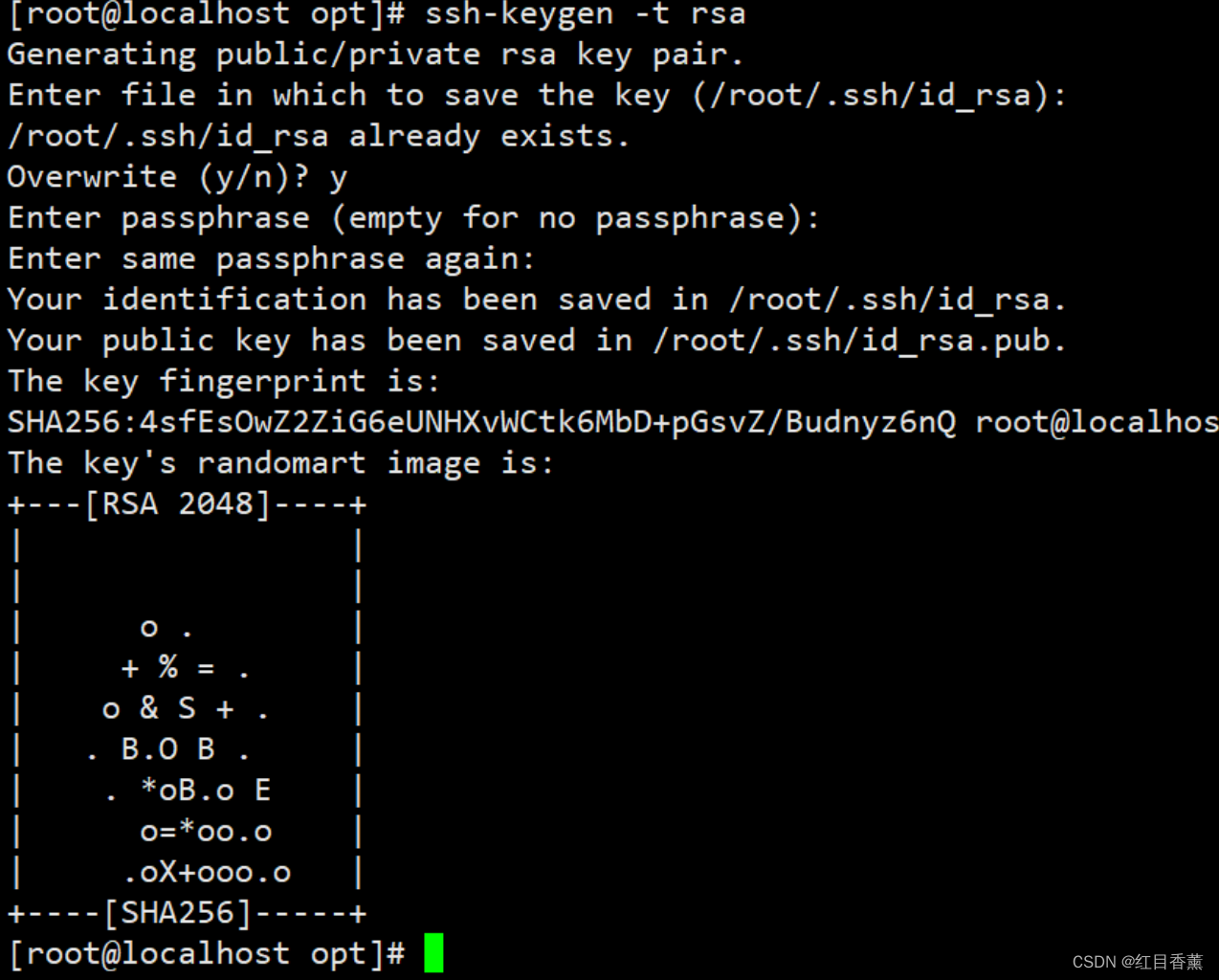
Copie la clave secreta a esta máquina
ssh-copy-id -i root@localhostNecesita ingresar [sí] y [contraseña de root]

autenticación ssh:
ssh 'root@localhost'
Como puede verse en la ruta, opt se convierte en ~.
Configuración del entorno Java y configuración del entorno Hadoop
Cree un archivo de script como: archivo [hadoop3.sh], agregue la siguiente configuración de ruta
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
ejecutar secuencia de comandos
source hadoop3.shconfirmación de configuración
hadoop version
Modificar el archivo de configuración de hadoop
Aquí agregamos y modificamos uno por uno
1. Modificar hadoop-env.sh
Simplemente agregue el siguiente código a la línea superior del archivo.
export JAVA_HOME=/opt/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2. Modificar yarn-env.sh
export JAVA_HOME=/opt/jdk
3. Modificar core-site.xml
Optimista sobre dónde agregar, en la etiqueta de configuración.
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-record/temp</value>
</property>
4. Modificar hdfs-sitio.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-record/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-record/dataNode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
5. Modificar mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6. Modificar hilo-sitio.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
Aquí hemos modificado un total de 6 archivos, todos deben ser cambiados, no se equivoquen.
Configuración de inicialización de Hadoop
hdfs namenode -format
Necesito esperar un rato aquí.
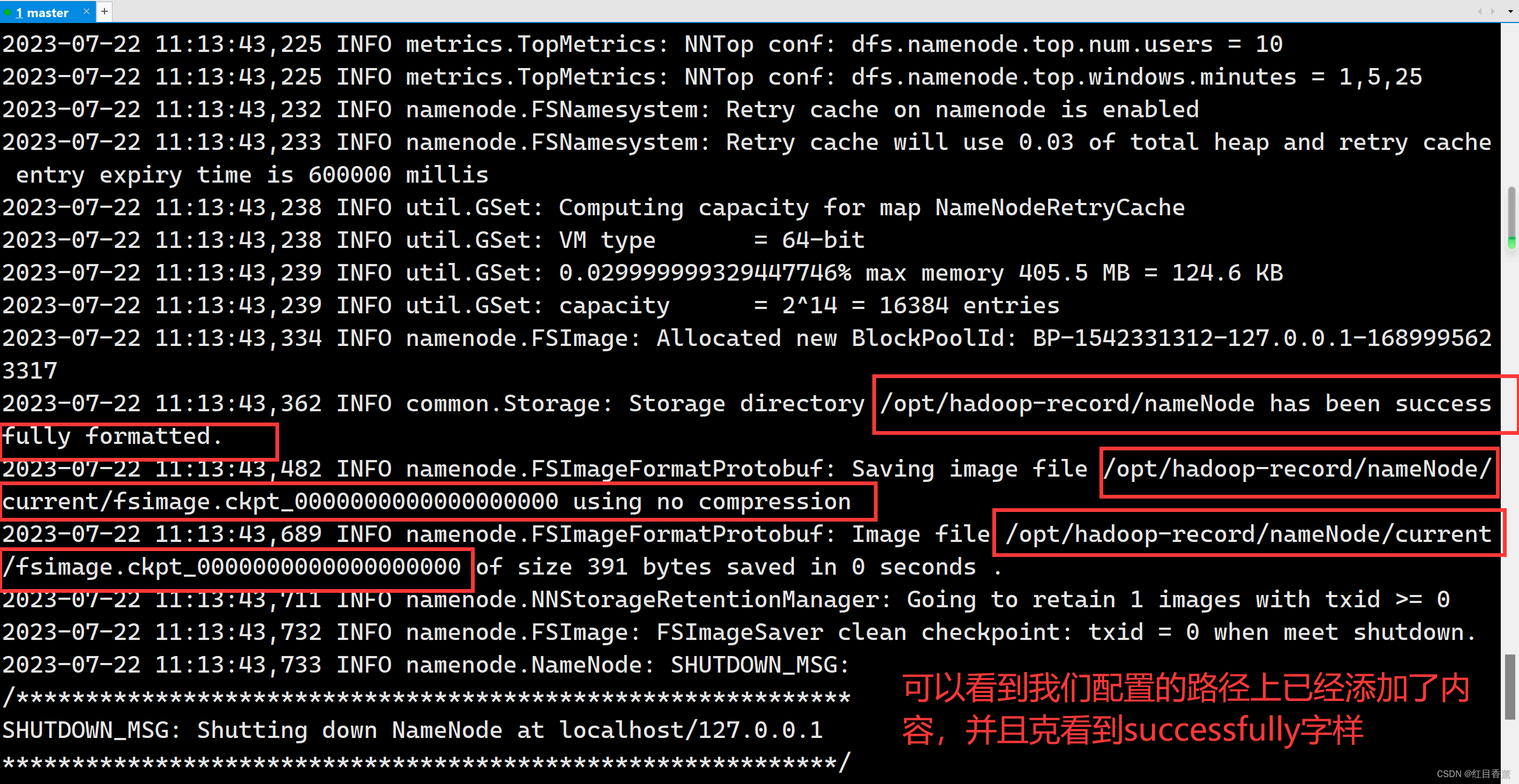
La inicialización está completa.
Inicie el servicio Hadoop
start-all.sh
jps

servicio de acceso
El método de acceso es 【ip:9870】, el número de puerto aquí es diferente al 50070 en 2.7.3, no se equivoque.
Por ejemplo: 【http://192.168.200.132:9870/】
Si no hay acceso es porque el firewall no está cerrado [systemctl stop firewalld]
systemctl stop firewalldAcceda a los resultados después del cierre:

Muestra que la configuración de nuestra máquina única se ha completado, y la configuración posterior de un maestro y dos esclavos también se basa en este método, no es más que cambiar la configuración de la relación entre el maestro y el esclavo.