Introducción
Este artículo presenta principalmente un problema de gran retraso en la sincronización de datos entre regiones que CKafka encontró en el escenario transoceánico.El problema del retraso entre regiones es típico, por lo que se registra en detalle para hacer un resumen.
1. Antecedentes
Con el fin de satisfacer las demandas de los clientes de recuperación ante desastres interregional y copia de seguridad en frío, la cola de mensajes CKafka proporciona capacidades de sincronización de datos interregionales a través de la función de conector y admite la sincronización de datos casi en tiempo real de segundo nivel interregional.
El diagrama de arquitectura general:
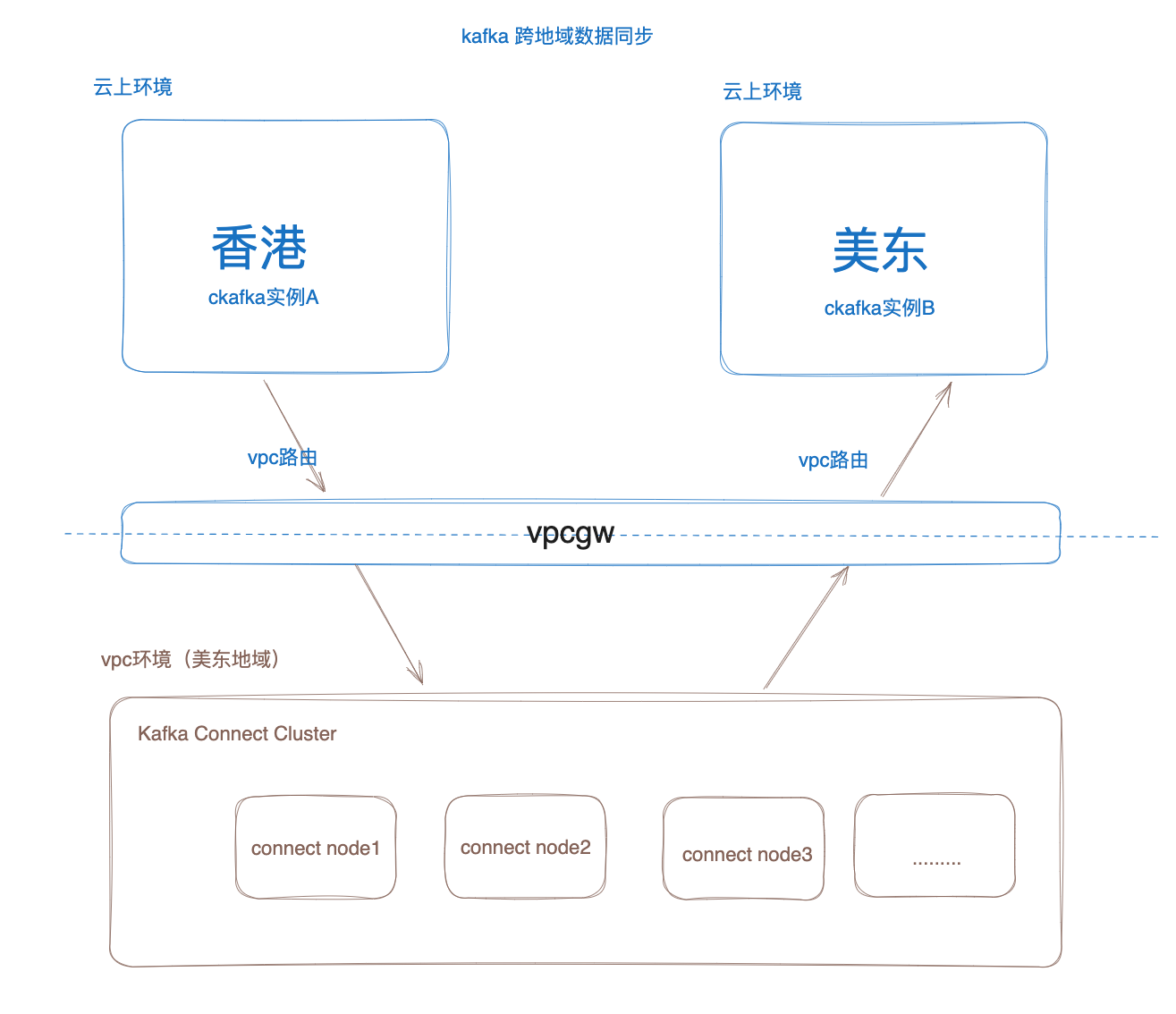
Como se muestra en la figura anterior, la capacidad de sincronización de datos entre regiones de CKafka se implementa en función del clúster de Kafka Connect en la capa inferior y el entorno de nube se abre a través de Vpcgw Privatelink.
El proceso principal de sincronización de datos es el siguiente:
1. El clúster de Connect inicializa la tarea de conexión y cada tarea creará varios Worker ConsumerClients (el número específico depende del número de particiones de la instancia de origen) para extraer datos de la instancia de CKafka de origen.
2. Después de que el clúster de Connect extraiga datos de la instancia de origen, iniciará Producer para enviar los datos a la instancia de CKafka de destino.
En un escenario comercial de un cliente, el cliente espera sincronizar los datos de la instancia de CKafka en Hong Kong con la instancia de CKafka en el este de EE. UU. a través de la capacidad de sincronización entre regiones, lo que provoca un extraño problema de retraso entre regiones durante el uso.
2. Fenómeno problema
Cuando los clientes usan la capacidad de sincronización entre regiones, descubren que el retraso de sincronización de datos desde Hong Kong -> Este de EE. UU. es muy grande, y se puede ver claramente que Connect actúa como un consumidor para consumir y extraer datos de la instancia de origen (Hong Kong). La acumulación de mensajes es muy grande.
acumulacion de noticias
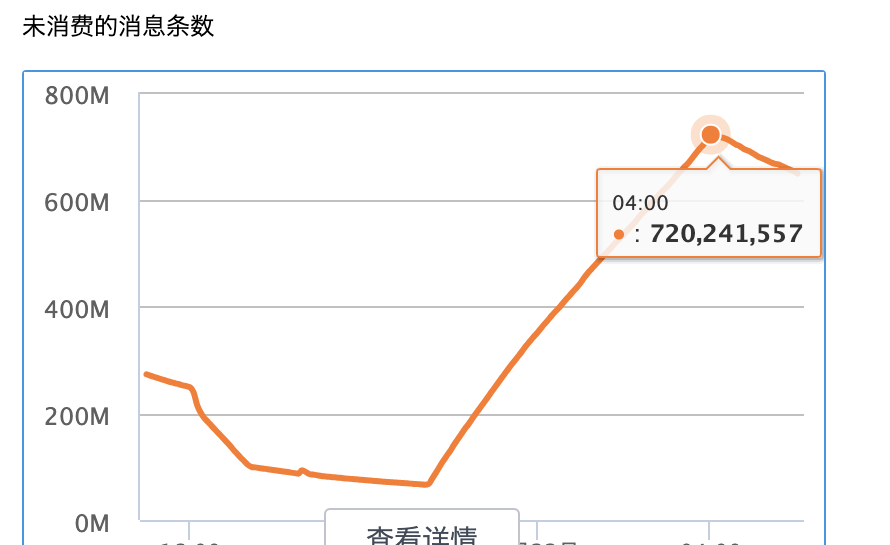
Según la experiencia pasada, no habrá un retraso tan grande en la sincronización de nuestras regiones nacionales. ¿Por qué hay un retraso tan grande esta vez entre regiones?
3. Análisis de problemas
Causas comunes de acumulación de mensajes
En el proceso de producción y consumo de Kafka, las razones comunes para la acumulación de mensajes son las siguientes:
● La carga del clúster de agentes es demasiado alta: incluye CPU alta, memoria alta, E/S de disco alta, lo que da como resultado un rendimiento de consumo lento.
● Capacidad de procesamiento insuficiente de los consumidores: si la capacidad de procesamiento de los consumidores es insuficiente para consumir los mensajes de manera oportuna, los mensajes se acumularán. Este problema se puede resolver aumentando el número de consumidores u optimizando la lógica de procesamiento de los consumidores.
● Salida anormal del consumidor: si el consumidor sale de manera anormal, los mensajes no se pueden consumir a tiempo y se acumulará una gran cantidad de mensajes no consumidos en el Broker. Las anomalías se pueden detectar y tratar a tiempo al monitorear el estado y la salud de los consumidores.
● Los consumidores no envían las compensaciones: si los consumidores no envían las compensaciones, los mensajes se consumirán o perderán repetidamente y se acumulará una gran cantidad de mensajes no consumidos en el agente. La atomicidad y la coherencia de las compensaciones se pueden garantizar mediante la optimización de la lógica de envío de compensaciones del consumidor o mediante el uso del mecanismo de transacción de Kafka.
● Falla de red o falla del Broker: Si ocurre la falla de la red o falla del Broker, los mensajes no pueden ser transmitidos ni almacenados a tiempo, acumulando así una gran cantidad de mensajes no consumidos en el Broker. Este problema se puede resolver optimizando la estabilidad y confiabilidad de la red, o aumentando el número y la tolerancia a fallas de los Brokers.
● El productor envía mensajes demasiado rápido: si el productor envía mensajes demasiado rápido y supera la capacidad de procesamiento del consumidor, los mensajes se acumularán. Este problema se puede resolver ajustando la velocidad de envío del productor o aumentando el número de consumidores.
Con base en las razones anteriores, primero verificamos la carga de todos los nodos en el clúster de Connect y todos los nodos de las instancias de CKafka de origen y de destino, y encontramos que todos los indicadores de monitoreo estaban en buen estado, la carga del clúster era muy baja y no había anomalías ni cuellos de botella en el rendimiento en la capacidad de consumo de ConnectConsumer.

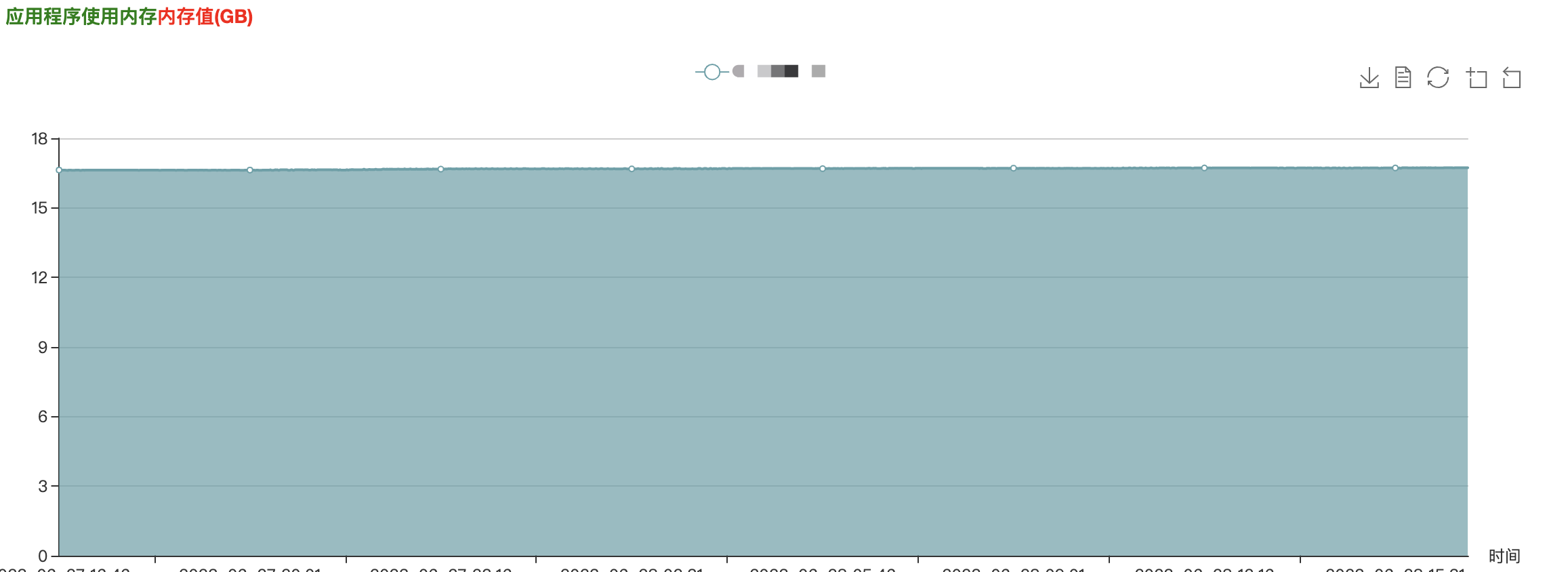
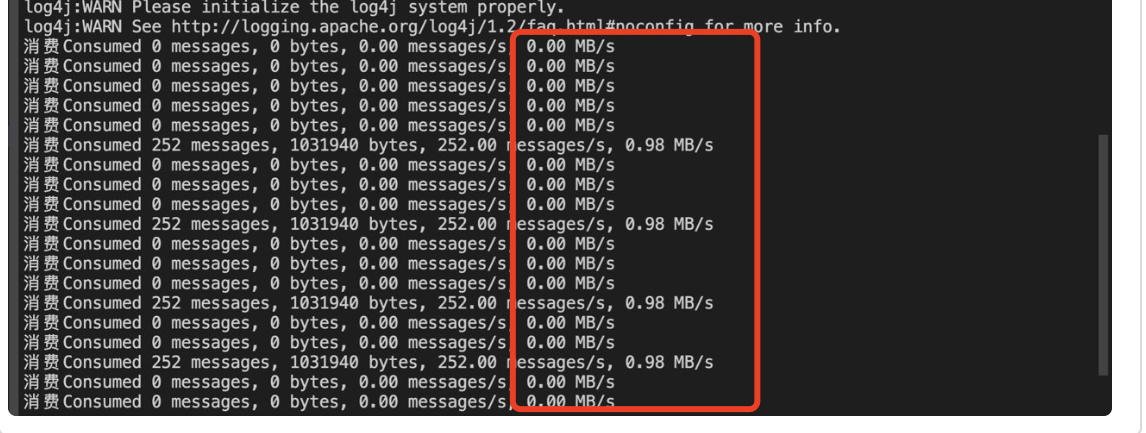
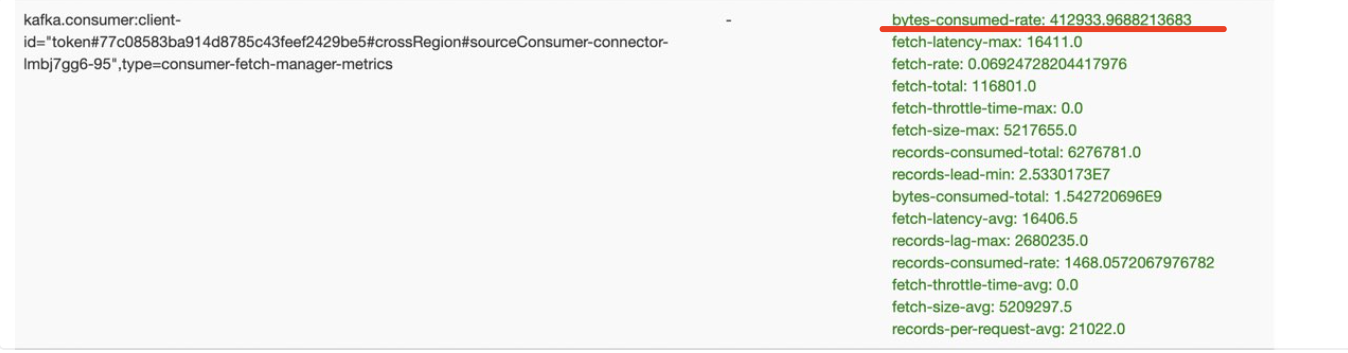
Sin embargo, la tasa de extracción de mensajes a la vez es muy baja, con una tasa de consumo promedio de 325 KB/s, que no está en línea con las expectativas.

(Nota: el indicador de tasa de bytes consumidos en la figura anterior representa la cantidad de bytes consumidos por segundo)
Dado que no hay ningún problema con la carga del clúster, llevamos a cabo una investigación y un análisis más profundos:
La primera etapa de análisis: comprobar la velocidad de la red
El retraso del mensaje es largo y lo primero que pensamos fue el problema de la red, por lo que inmediatamente comenzamos a realizar pruebas de estrés en la red. Detecta la velocidad de la red a través de Iperf3 y Wget.
Prueba de presión Iperf3, la velocidad es de 225 Mbps.
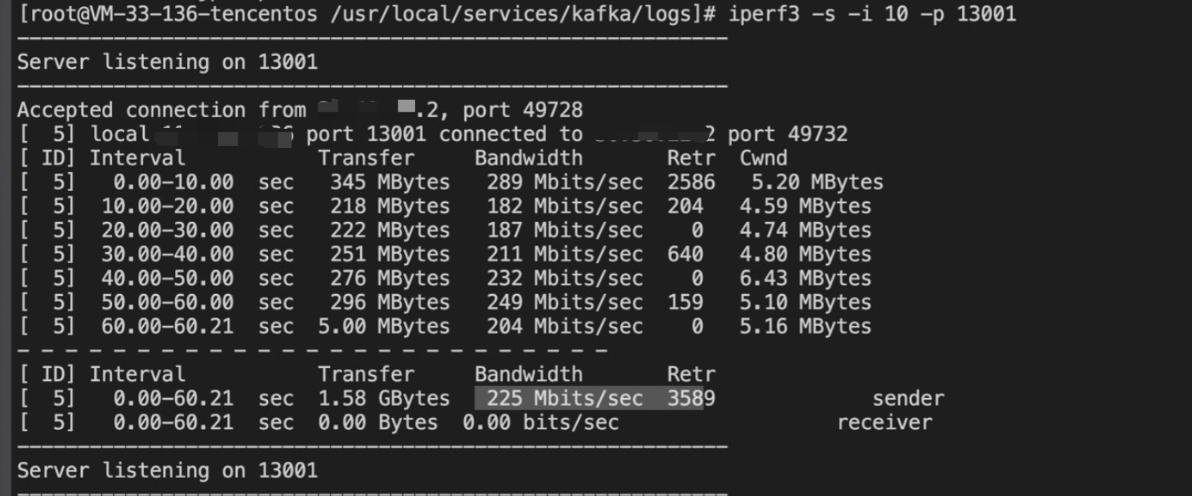
Wget se conecta directamente a Hong Kong en el clúster Connect y la velocidad de descarga es de 20 MB/s.

Estas dos pruebas muestran que: en el mismo entorno, la velocidad de transmisión de la red no es baja y puede alcanzar los 20 MB/s. Entonces, dado que el ancho de banda de la red no es un problema, ¿dónde está el problema?
Análisis de fase 2: parámetros de ajuste del kernel
No hay ningún problema con la red. ¿Podría ser que los parámetros de la aplicación relacionados con la red de Kafka y los parámetros relacionados con la red del núcleo estén configurados de manera irrazonable?
1. Primero ajustamos los parámetros del kernel.Los parámetros del kernel relacionados con la red incluyen principalmente:
系统默认值:
net.core.rmem_max=212992
net.core.wmem_max=212992
net.core.rmem_default=212992
net.core.wmem_default=212992
net.ipv4.tcp_rmem="4096 87380 67108864"
net.ipv4.tcp_wmem="4096 65536 67108864"
---------------------------------------------------------
调整内核参数:
sysctl -w net.core.rmem_max=51200000
sysctl -w net.core.wmem_max=51200000
sysctl -w net.core.rmem_default=2097152
sysctl -w net.core.wmem_default=2097152
sysctl -w net.ipv4.tcp_rmem="40960 873800 671088640"
sysctl -w net.ipv4.tcp_wmem="40960 655360 671088640"
调整TCP的拥塞算法为bbr:
sysctl -w net.ipv4.tcp_congestion_control=bbr
Hemos aumentado el valor de los parámetros generales del kernel (aunque creemos que el valor predeterminado del kernel del sistema no es pequeño) y también hemos ajustado el algoritmo de congestión de TCP.
Aquí hay una explicación de por qué se debe ajustar el algoritmo de congestión de TCP.
(Referencia: [[Traducción] [Papel] BBR: Control de congestión basado en la congestión (no pérdida de paquetes) (ACM, 2017)]( [Traducción] [Papel] BBR: Control de congestión basado en la congestión (no pérdida de paquetes) (ACM, 2017) ) )
Debido a que este retraso ocurre entre regiones y océanos, el uso de BBR puede mejorar significativamente el rendimiento de la red y reducir la latencia. Las mejoras en el rendimiento son especialmente notables en rutas de larga distancia, como archivos transpacíficos o grandes transferencias de datos, especialmente en condiciones de red con una ligera pérdida de paquetes. La mejora de la latencia se ve principalmente en la última milla de la ruta, que a menudo se ve afectada por la sobrecarga del búfer. La llamada "inflación de búfer" se refiere a un dispositivo o sistema de red que diseña innecesariamente un búfer excesivamente grande. La hinchazón del búfer ocurre cuando los enlaces de red están congestionados, lo que hace que los paquetes permanezcan en cola durante largos períodos de tiempo en estos búferes muy grandes. En un sistema de cola FIFO, un búfer excesivamente grande dará como resultado una cola más larga y una mayor latencia, y no mejorará el rendimiento de la red. Dado que BBR no intenta llenar el búfer, tiende a hacer un mejor trabajo al evitar que se llene el búfer.
Después de ajustar los parámetros del kernel, la verificación encontró que la demora no ha mejorado mucho.
2. Bajo el recordatorio del experto en servicio técnico del producto en la nube, se confirma que la configuración del búfer de recepción de la conexión es demasiado pequeña, y el ajuste de los parámetros del kernel no tiene efecto.Se sospecha que la capa de aplicación lo ha configurado.
Así que ajustamos los valores de los parámetros de red de la aplicación Kafka Socket.Send.Buffer y Socket.Recevie.Buffer:
(1) Ajuste el parámetro Socket.Send.Buffer.Bytes del agente de la instancia de CKafka de destino de origen desde los 64 KB predeterminados para usar el búfer de envío de socket del sistema.
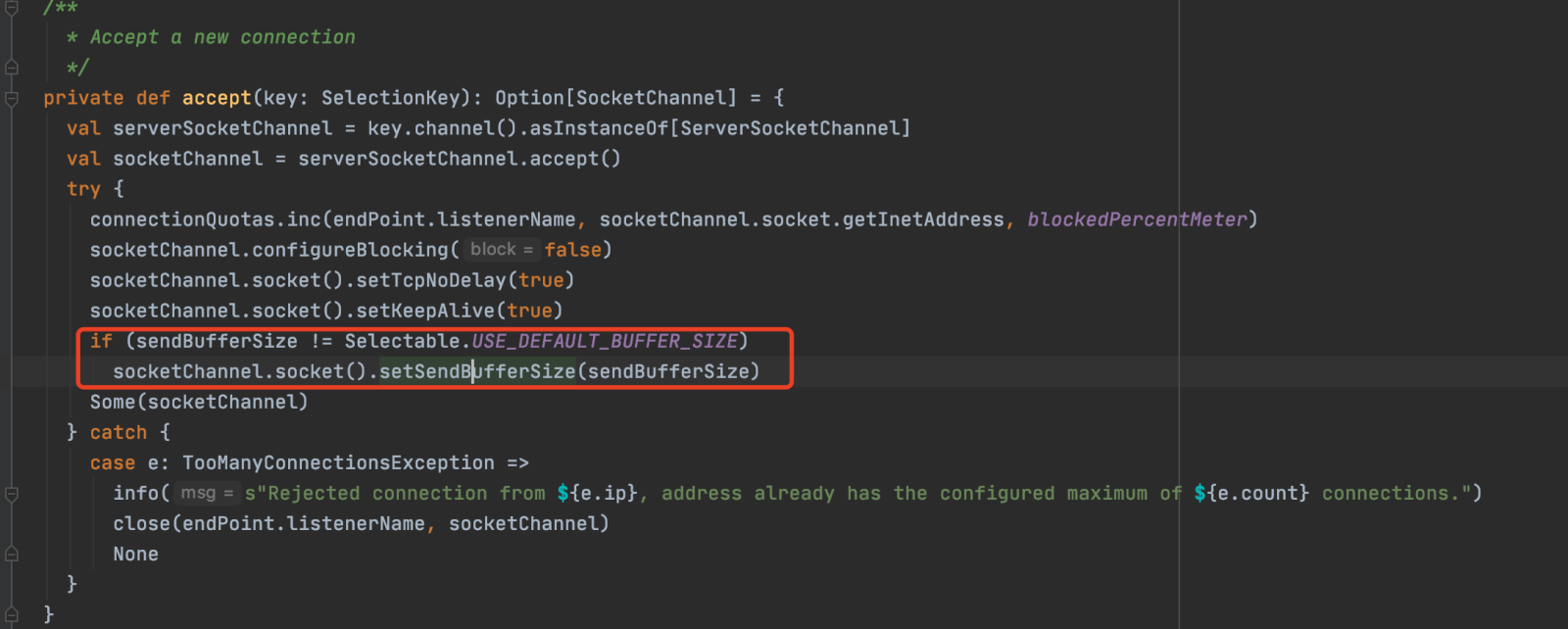
Código del kernel de Kafka sobre el búfer de envío de socket:
【Consejos】:
En Kafka, el tamaño del búfer de envío TCP lo determinan conjuntamente la aplicación y el sistema operativo. El programa de aplicación puede controlar el tamaño del búfer de envío TCP configurando el parámetro Socket.Send.Buffer.Bytes, y el sistema operativo también puede controlar el tamaño del búfer de envío TCP configurando los parámetros de la pila de protocolos TCP/IP.
El parámetro Socket.Send.Buffer.Bytes establecido por la aplicación afectará el tamaño del búfer de envío de TCP, pero el sistema operativo también limitará el tamaño del búfer de envío de TCP. Si el parámetro Socket.Send.Buffer.Bytes establecido por la aplicación excede el límite del sistema operativo, el tamaño del búfer de envío TCP se limitará dentro del límite del sistema operativo. Si la aplicación establece Socket.Send.Buffer.Bytes=-1, el tamaño del búfer de envío de TCP será el tamaño predeterminado del búfer de envío de TCP del sistema operativo. Cabe señalar que el tamaño del búfer de envío TCP afecta el rendimiento y la latencia de la red. Si el tamaño del búfer de envío TCP es demasiado pequeño, el rendimiento y el rendimiento de la red disminuirán; si el tamaño del búfer de envío TCP es demasiado grande, el tiempo de retraso de la red aumentará. Por lo tanto, debe ajustarse de acuerdo con la situación real para lograr un rendimiento y una fiabilidad óptimos.
(2) Ajuste el parámetro Receive.Buffer.Bytes del cliente Connect Consumer del valor predeterminado de 64 KB para usar el búfer de recepción de socket del sistema. Se ajustó el tamaño máximo de recuperación de la partición Max.Partition.Fetch.Bytes del cliente a 5 MB.
Después del ajuste, coordinamos rápidamente con el cliente el reinicio del clúster para verificar el ajuste. Después del ajuste, el efecto es obvio: la velocidad promedio de una sola conexión aumentó de 300 KB/s a más de 2 MB/s:
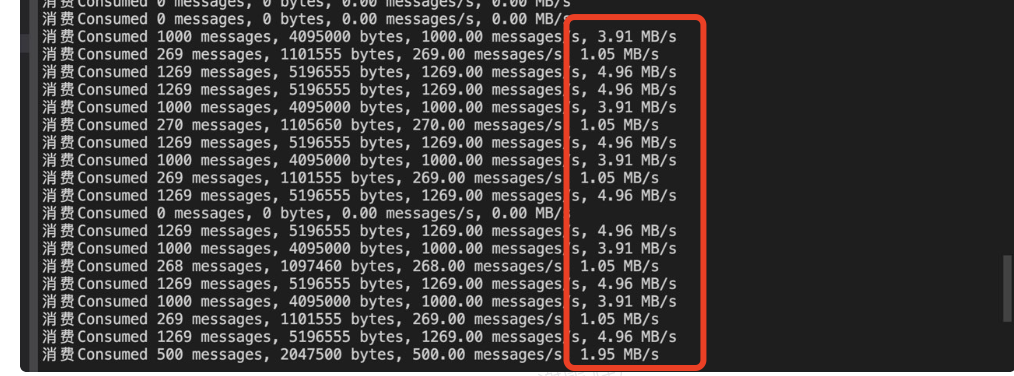
Se puede ver que después de aumentar los parámetros de recepción y envío de Socket de Kafka, el efecto es realmente obvio y la tasa de sincronización ha aumentado. Justo cuando pensábamos que el problema de la demora estaba resuelto, ¡el problema apareció nuevamente!
La tercera etapa del análisis: profundizar en la causa raíz
El ajuste de parámetros de Kafka en la segunda etapa anterior se aplicó al clúster del cliente. Después de un día de observación, el cliente informó que el retraso general del clúster ha mejorado, pero el retraso de algunas particiones sigue siendo muy grande. También observamos que la tasa de sincronización de aproximadamente la mitad de las particiones sigue siendo muy baja.
(Nota: el indicador de tasa de bytes consumidos en la figura anterior representa la cantidad de bytes consumidos por segundo)
(1) ¿Por qué algunas velocidades de conexión siguen siendo muy bajas?
Primero determinamos el ConsumerGroupID correspondiente a la partición con una tasa de consumo baja a través del fondo de la operación y usamos este ConsumerGroupID para capturar paquetes para ubicar la conexión TCP lenta correspondiente.
Después de ubicar la conexión, realice un análisis de captura de paquetes:

De lo anterior se puede ver que después de que el servidor envía un dato, se detendrá por un período de tiempo y luego continuará enviando aproximadamente un RTT. Cuente el tamaño total de los paquetes de datos entre cada intervalo de envío, alrededor de 64 KB. Básicamente, esto significa que la ventana de envío de TCP está limitada a 64 KB. Sin embargo, no se encuentra tal limitación al capturar otras conexiones con velocidad normal. En términos generales, el tamaño real de la ventana de envío de TCP está relacionado con la escala de la ventana, que solo se puede confirmar cuando se establece la conexión.
【Consejos】:Escala de ventana TCP, factor de escala de ventana TCP. (Referencia: ¿ Cómo determinar el tamaño de la ventana inicial de TCP y la opción de escalado? ¿Qué factores afectan la determinación? - Portal del cliente de Red Hat )
En el protocolo TCP tradicional, el tamaño máximo de la ventana TCP solo puede alcanzar los 64 KB, lo que limita la velocidad de transmisión y la eficiencia del protocolo TCP. Para resolver este problema, el mecanismo TCP Window Scale se introduce en el protocolo TCP.
Tamaño de ventana de TCP = (tamaño de ventana del receptor) * (2 ^ valor de la opción Escala de ventana de TCP)
Cabe señalar que el mecanismo de escala de ventana TCP debe negociarse cuando se establece la conexión de protocolo de enlace de tres vías TCP para determinar el método de expansión y los parámetros del tamaño de la ventana TCP.
Para capturar la situación de establecer una conexión, intentamos reiniciar la tarea de consumo de una sola partición, pero descubrimos que siempre que se reinicie, la velocidad de consumo se puede restaurar y no habrá cuellos de botella en el tamaño de la ventana.
(2) ¿Por qué la ventana de envío es limitada?
Para reproducir el problema, simulamos y construimos el escenario de uso del cliente y llevamos a cabo la reproducción del escenario general. Finalmente se confirma que este problema solo ocurrirá cuando la tarea se reinicie por completo. Durante el proceso de reinicio de la tarea, realizamos una captura general de paquetes en el lado del servidor. Después de localizar la conexión normal y la conexión anormal, comparando el proceso de establecimiento de la conexión, ¡finalmente se confirma que la escala de ventana no tiene efecto en la conexión lenta!
Proceso normal de establecimiento de conexión:

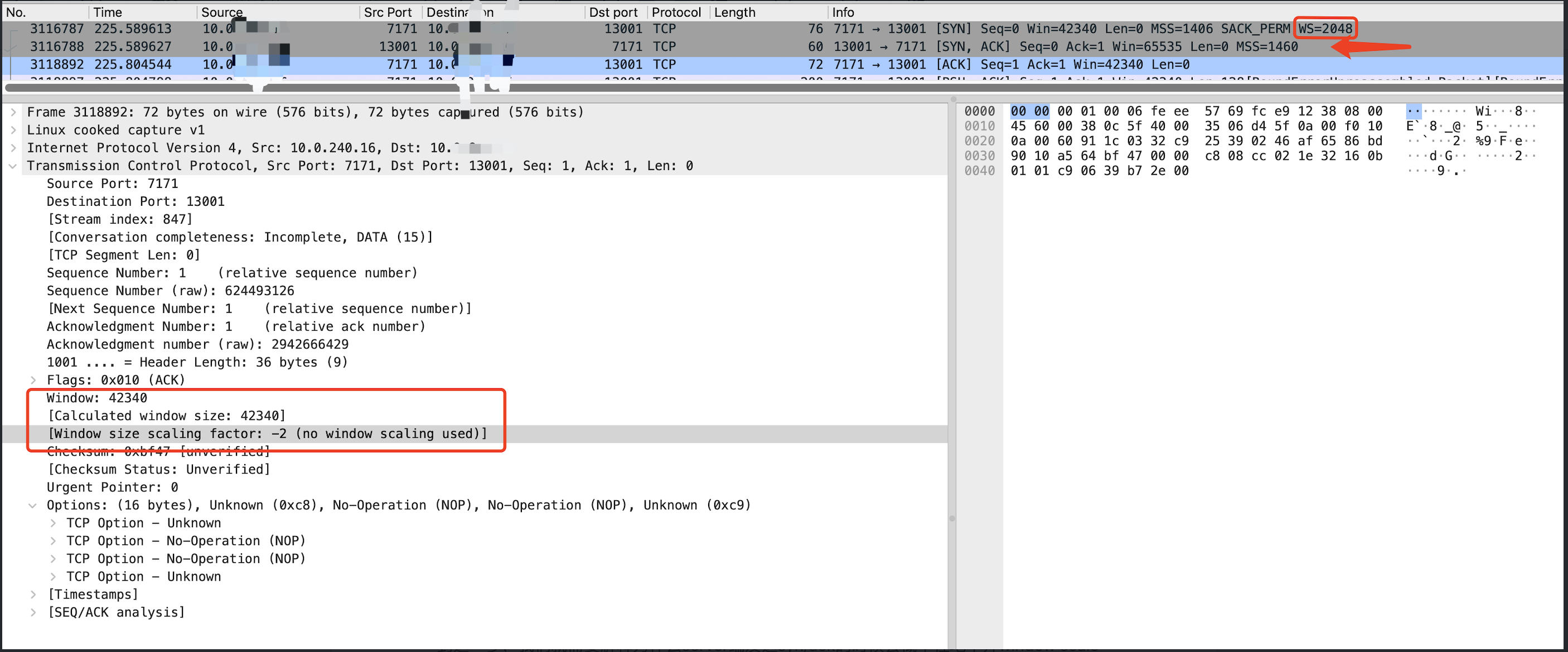
Proceso de establecimiento de conexión lento:

Como se puede ver en la figura anterior, en la conexión lenta, cuando el servidor devuelve el paquete Syn/Ack, no hay "WS=2", lo que indica que la opción Window Scale no está habilitada, lo que lleva a que la ventana de envío de toda la conexión se limite a 64 KB, y el rendimiento no se puede aumentar. Cuando el Cliente devolvió el último Ack, también mostró claramente "no se usó escalado de ventana".
(3) ¿Por qué Window Scale probabilísticamente no tiene efecto?
En este punto, debemos explicar por qué el servidor no abre Window Scale de forma probabilística al enviar Syn/Ack. Aquí, el tipo grande del grupo de computación nos dio un caso similar para que aprendamos: kubernetes - revisión profunda - excepción causada por reiniciar etcd - artículo personal - SegmentFault Pensando si recibir un mensaje: parece que cuando la cookie SYN está en efecto, la otra parte no pasa la opción de marca de tiempo (en realidad, de acuerdo con el principio de la cookie SYN, el paquete de retorno enviado al otro extremo guardará la información de la opción codificada en los 6 bits inferiores del campo Tsval), y llamará a T cp_Clear_Options para borrar opciones como el factor de ampliación de la ventana. Desde el registro del sistema, también podemos observar que SYN Flood se activa cuando la tarea se reinicia en su totalidad.

(4) ¿Por qué el servidor no recibió Tsval (valor de marca de tiempo TCP)?
Como se mencionó anteriormente, nuestra sincronización de datos pasó a través de un VPCGW dentro de la empresa, capturamos paquetes en el Cliente y el Servidor respectivamente, y finalmente confirmamos que el VPCGW se tragó el Tsval enviado por el Cliente. Al mismo tiempo, también confirmé con los estudiantes de investigación y desarrollo de VPCGW que en el entorno NAT, no reenviar la marca de tiempo es el comportamiento esperado, principalmente para resolver el problema de pérdida de paquetes en casos especiales, y el problema tcp_timestamps en el entorno NAT_centos nat tcp_timestamps_Qingfeng Xulai 918 Blog-CSDN Blog . Sin embargo, este problema ya no existe en el nuevo núcleo, por lo que se puede programar para proporcionar la capacidad de abrir la marca de tiempo.
ubicación de la causa raíz
Después de analizar y cavar todo el camino, la causa raíz del problema es clara:
Connect Consumer comenzó en lotes, activando una gran cantidad de nuevas conexiones TCP, y una gran cantidad de nuevas conexiones en un corto período de tiempo activaron la lógica de verificación de protección de cookies SYN. Sin embargo, debido a que el cliente no envió la opción de marca de tiempo, el servidor borró el factor de ampliación de la ventana, lo que finalmente provocó que la ventana de envío de conexión máxima fuera de 64 KB, lo que afectó el rendimiento de la transmisión en el caso de grandes retrasos.
4. Nuestras soluciones
Una vez que se encuentra la causa raíz del problema, la solución se vuelve clara.
● Solución de prevención: ajustamos la simultaneidad de la inicialización de Connect Woker, redujimos la velocidad del establecimiento de la conexión de inicialización de TCP y nos aseguramos de que no se active ninguna cookie SYN para garantizar el rendimiento de la sincronización de datos posterior.
● Solución final: Promover la capacidad de VPCGW para abrir TCP Timestamp.
V. Resumen
En la superficie, el problema es el problema de las solicitudes lentas de sincronización de datos interregionales, pero de hecho es un problema de red de muy bajo nivel después de investigar todo el camino.
La ocurrencia de este problema es relativamente rara, porque las condiciones para que ocurra este problema son relativamente complejas, principalmente debido a la existencia de retrasos en la red entre regiones, una gran cantidad de conexiones TCP al mismo tiempo y el consumo del parámetro TCP Timestamp durante el proceso de transmisión de enrutamiento de VPCGW, que se superpone para causar este problema.
¡Necesitamos mantener el asombro frente a los problemas y profundizar hasta el fondo!
Los 8 lenguajes de programación más demandados en 2023: Fuerte PHP, baja demanda de C/C++ Notas del programador CherryTree 1.0.0.0 lanzado Proyecto CentOS declarado "abierto a todos" MySQL 8.1 y MySQL 8.0.34 lanzados oficialmente GPT-4 ¿cada vez más estúpido? La tasa de precisión cayó del 97,6 % al 2,4 %.Microsoft : mayores esfuerzos para usar Rust Meta en Windows 11 Acercar: lanzar el modelo de lenguaje grande de código abierto Llama 2, que es gratuito para uso comercial.El padre de C# y TypeScript anunció el último proyecto de código abierto: ¿TypeChat no quiere mover ladrillos, pero también quiere cumplir con los requisitos? Tal vez este proyecto de código abierto de GitHub de 5k estrellas pueda ayudar: el 25.° aniversario de MetaGPT Wireshark, el analizador de paquetes de red de código abierto más poderoso