Referenciado del documento A Survey on Session-based Recommender Systems
Este documento primero presenta la motivación y los antecedentes de la recomendación basada en la conversación,
luego explica su diferencia con la recomendación secuencial
y brinda los subcampos de la recomendación conversacional
y el marco de clasificación de varios métodos utilizados actualmente, y
finalmente propone la perspectiva futura en el campo actual.
—— Cincuain
Recomendación general (RS) frente a recomendación basada en sesiones (SBRS)
recomendación general
Los sistemas de recomendación pueden ayudar a los usuarios a encontrar artículos de interés relacionados. En los sistemas de recomendación generales, todas las interacciones históricas entre los usuarios y los artículos se utilizan normalmente para conocer las preferencias estáticas a largo plazo de los usuarios por los artículos. Tal operación en realidad implica una suposición: toda la información de interacción histórica es igualmente importante para predecir la preferencia actual del usuario.
Pero esta suposición no es correcta en escenarios reales porque:
- Los usuarios no solo tienen preferencias pasadas a largo plazo, sino también preferencias a corto plazo. Estas preferencias a corto plazo se pueden caracterizar por información de interacción reciente. (por ejemplo: aunque siempre he escuchado música clásica, hay una o dos canciones pop que son muy populares recientemente, así que también las escucharé)
- Las preferencias del usuario también cambian con el tiempo y son dinámicas en lugar de estáticas. (por ejemplo: aunque antes me gustaba escuchar música clásica, pero ahora no me gusta, ya me he tirado al abrazo de la música pop)
Recomendaciones basadas en sesiones
Por lo tanto, para cerrar estas brechas, en los últimos años se han propuesto sistemas de recomendación basados en sesiones (SBRS). SBRS utiliza cada sesión como la unidad de entrada básica, que puede capturar las preferencias a corto plazo del usuario y las preferencias dinámicas reflejadas por la transferencia de intereses entre sesiones , mejorando así la precisión y puntualidad de las recomendaciones.
Un SBRS amplio puede tener los siguientes subcampos:
- Predecir la próxima interacción (next-interaction), por ejemplo: predecir el próximo producto, canción/película, PDI, página web, noticias, etc.
- Predecir la interacción del resto de la sesión actual (recomendación de la próxima sesión parcial), por ejemplo: predecir el siguiente elemento, finalización de la sesión/canasta
- Predecir la próxima sesión*(next-session)*p. ej.: recomendación de cesta siguiente, recomendación de paquete siguiente
En sentido estricto, SBRS se refiere al primer tipo. (Basado en la sesión actual, predecir la próxima interacción)
Recomendación secuencial (SRS) frente a recomendación basada en sesiones (SBRS)
(Ambigüedad: Inter-sesión: se refiere al interior de una sesión, ¿o entre sesiones? Es lo último, pero hay que explicarlo)
Los sistemas de recomendación secuencial son recomendaciones basadas en datos de secuencia , mientras que las recomendaciones de sesión se basan en datos de sesión . Los dos están muy relacionados y superficialmente similares, lo que puede causar mucha confusión.
Primero dé la definición de datos de sesión y datos de secuencia:
- sesión : una sesión es una secuencia de interacciones usuario-elementocon distintos límites de inicio y final. Estas interacciones dentro de una sesión pueden estar ordenadas (ordered) o desordenadas (unordered). Los datos de sesión consisten en muchassesiones que ocurren en diferentes momentos y están separadas por muchos límites . Hay diferentes intervalos de tiempo entre sesiones (intervalo de tiempo).
- secuencia : Una secuencia es una colección ordenada de interacciones. Todas las interacciones de un usuario forman una secuencia, por lo que solo hay un límite .
Hay un límite, lo que implica que hay dependencias basadas en la co-ocurrencia entre elementos en un cierto período de tiempo. Esta dependencia basada en la co-ocurrencia forma la base de SBRS. (Especialmente cuando los elementos en la sesión están fuera de servicio) (p .
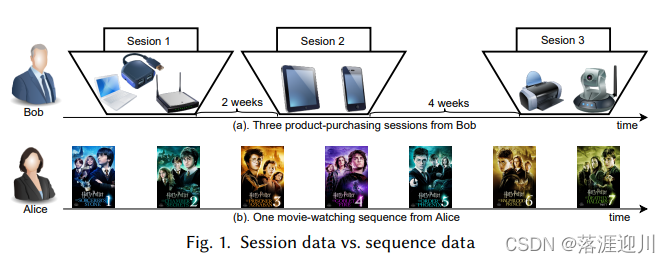
En la parte experimental de cada modelo SBRS, hay una descripción operativa de la segmentación de secuencias de interacción usuario-elemento en sesiones. Por lo general, especificando un umbral de intervalo de tiempo (por ejemplo: 30 minutos / 8 horas). Si se supera este umbral y el usuario aún no tiene actividad nueva, divida la interacción anterior en una sesión.
Ahora, podemos distinguir entre recomendaciones basadas en sesiones y secuenciales:
- Recomendación basada en la sesión : prediga las interacciones restantes/próximas sesiones de la siguiente interacción/sesión y explote las dependencias basadas en la co-ocurrencia. En principio, SBRS no requiere que se ordenen las interacciones usuario-elemento , por lo que no utiliza dependencias secuenciales, por supuesto, si se ordena la sesión, también podemos utilizarla.
- Recomendación de secuencia : en función de los datos de secuencia, prediga el siguiente elemento. Aproveche las dependencias de secuencia.
Es fácil para nosotros confundir la recomendación de sesión y la recomendación de secuencia, porque muchas investigaciones de SBRS se basan en sesiones secuenciadas y predicen la próxima interacción (compare la segunda y la tercera fila de la tabla a continuación).
La esencia de la distinción es: si usar dependencias basadas en co-ocurrencia

Subcampos para recomendaciones basadas en sesiones

Los algoritmos de recomendación basados en sesiones del Sistema de recomendación basado en sesión (SBRM) se pueden dividir en tres categorías:
- Enfoques SBRS convencionales
- Enfoques basados en representación latente (modelo de representación latente)
- Enfoques basados en redes neuronales profundas (método basado en redes neuronales profundas)
Este artículo primero presenta en detalle el primer tipo de enfoque SBRS convencional. Como recomendación, los primeros métodos tradicionales generalmente usan técnicas como la minería de datos y el aprendizaje automático para capturar las dependencias en los datos de secuencia, incluidos los conocidos Item-KNN, FPMC y otros modelos de referencia que se usan a menudo para comparar. Comprender esta parte del contenido es de gran ayuda para comenzar. Los cuatro algoritmos de recomendación tradicionales se presentarán en detalle a continuación.
SBRS basados en minería de patrones/reglas (minería basada en patrones/reglas)
Se incluyen dos algoritmos:
Minería de reglas de asociación (enfoques basados en minería de reglas de asociación/patrones frecuentes):
Dividido en tres pasos: ——Evaluación: Primero debe introducirse la idea, no los pasos del algoritmo. Resumir como un todo.
(1) Buscar conjuntos de elementos frecuentes y reglas de asociación En todas las sesiones (consideradas como secuencias de interacción usuario-elemento), primero busque todos los conjuntos de elementos que cumplan con el umbral de escala mínimo. Estos conjuntos de elementos se denominan conjuntos de elementos frecuentes FP // Calcular P(AB) Los conjuntos de elementos frecuentes que cumplen los requisitos mínimos de confianza se denominan reglas de asociación (regla de asociación) // Calcular P(B|A) (3) Generar
elementos recomendados: Para un elemento candidato, si su FP cumple con el requisito de confianza (regla de asociación), se puede agregar
a la lista de recomendaciones
Comentarios: Puedes ver que este método no requiere que se ordene la sesión, pero no tiene en cuenta la secuencia. Para decirlo sin rodeos, solo se puede calcular la probabilidad de co-ocurrencia. Las reglas de asociación obtenidas solo pueden interpretarse como que la probabilidad de que estos dos artículos se compren juntos es alta.
Enfoques basados en la minería de patrones secuenciales
La minería de patrones secuenciales tiene en cuenta la secuencialidad. Según el último comportamiento de compra (sesión), recomendar los artículos de la próxima sesión a partir de esta sesión (como artículos candidatos) que aparecen en el modo secuencia.
La entrada de la minería de patrones secuenciales es diferente de la minería de conjuntos de elementos frecuentes anterior: conjunto de secuencia VS conjunto de elementos. La entrada de la
minería de patrones de secuencia son tales datos: los datos de una línea son todas las sesiones de un usuario. Los

datos de entrada de la minería de conjuntos de elementos frecuentes son así: una línea es una sesión. Probablemente las filas 1, 2, 3 sean todas del mismo usuario (independientemente del usuario). Aunque se ordena la entrada, no se considera el orden entre los elementos al recomendar, solo se considera la co-ocurrencia.

Se puede ver que si la duración de cada sesión del usuario es 1, la minería de patrones secuenciales puede considerarse como minería frecuente de conjuntos de elementos.
Paso de minería de secuencias: similar a la minería de reglas de asociación, es equivalente a cambiar un elemento de un objeto a una secuencia. Eso es todo
(1) Minería de patrones de secuencia
(2) Coincidencia de secuencias
(3) Generar recomendaciones: Elementos candidatos: en las reglas de secuencia que se extraen, los elementos de la siguiente secuencia que coinciden con la última secuencia. Luego se calcula la confianza para cada elemento.