1. Introducción al sistema
El sistema de registro de navegación se utiliza principalmente para registrar los registros de navegación en tiempo real de los usuarios de Jingdong y proporciona la función de consulta de datos de navegación en tiempo real. Cuando un usuario en línea visita la página de detalles del producto una vez, el sistema de registro de navegación registrará una parte de los datos de navegación del usuario y realizará una serie de procesamiento y almacenamiento, como la deduplicación de las dimensiones del producto para los datos de navegación. Luego, el usuario puede consultar los registros de productos de navegación en tiempo real del usuario a través de My Jingdong u otros portales, y el rendimiento en tiempo real puede alcanzar el nivel de milisegundos. En la actualidad, este sistema puede proporcionar a cada usuario de JD.com una consulta y visualización de los últimos 200 registros de navegación.
2. Diseño e implementación del sistema
2.1 Diseño general de la arquitectura del sistema
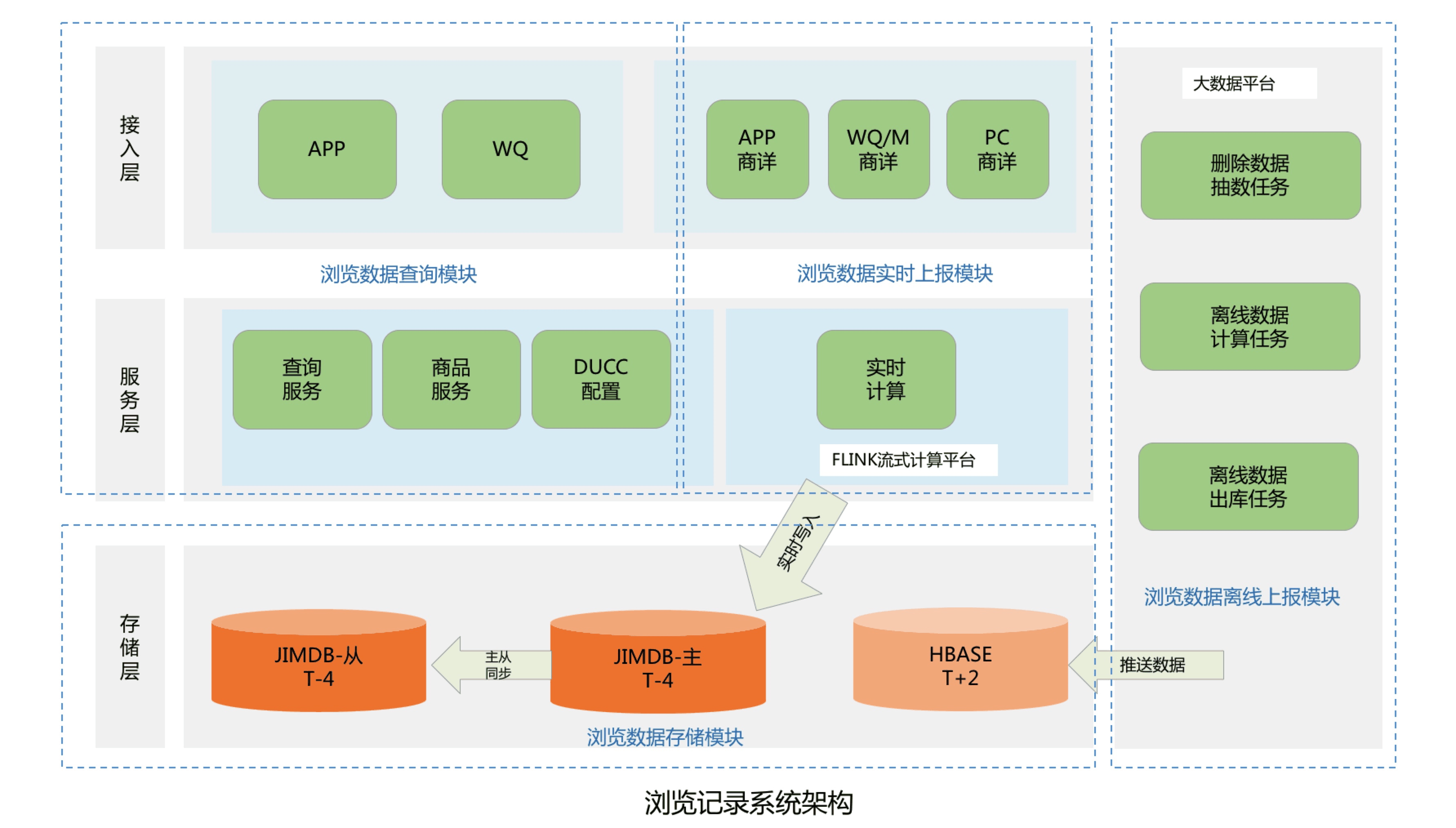
Toda la arquitectura del sistema se divide principalmente en cuatro módulos, incluido el módulo de almacenamiento de datos de navegación, el módulo de consulta de datos de navegación, el módulo de informes en tiempo real de datos de navegación y el módulo de informes fuera de línea de datos de navegación:
- Módulo de almacenamiento de datos de navegación: se utiliza principalmente para almacenar el historial de navegación de los usuarios de JD.Actualmente, JD.com tiene casi 500 millones de usuarios activos.De acuerdo con cada usuario que conserva al menos 200 registros del historial de navegación, es necesario diseñar y almacenar casi 100 mil millones de datos del historial de navegación del usuario;
- Módulo de consulta de datos de navegación: proporciona principalmente una interfaz de microservicio para la recepción, que incluye funciones como consultar el número total de registros de navegación de los usuarios, listas de registros de navegación en tiempo real y operaciones de eliminación de registros de navegación;
- Módulo de informes de datos de navegación en tiempo real: procesa principalmente datos de PV en tiempo real de todos los usuarios en línea de JD.com y almacena los datos de navegación en una base de datos en tiempo real;
- Módulo de informes de datos de navegación fuera de línea: se utiliza principalmente para procesar los datos de PV fuera de línea de todos los usuarios de JD, limpiar, deduplicar y filtrar los datos históricos de PV del usuario y, finalmente, enviar los datos de navegación a la base de datos fuera de línea.
2.1.1 Diseño e implementación del módulo de almacenamiento de datos
Teniendo en cuenta la necesidad de almacenar casi 100 mil millones de registros de navegación de usuarios y cumplir con el almacenamiento en tiempo real de registros de navegación de nivel de milisegundos y funciones de consulta de front-end de los usuarios de JD Online, separamos los datos del historial de navegación fríos y calientes. Jimdb opera únicamente en la memoria y tiene una velocidad de acceso rápida, por lo que almacenamos los datos de registro de navegación del usuario (T-4) en la memoria de Jimdb, que puede cumplir con el almacenamiento en tiempo real y la consulta de los usuarios activos de JD Online. Los datos de navegación fuera de línea que no sean (T+4) se envían directamente a Hbase y se almacenan en el disco para ahorrar costos de almacenamiento. Si un usuario inactivo consulta datos inactivos, los datos inactivos se copiarán en Jimdb para mejorar el rendimiento de la siguiente consulta.
Los datos calientes usan el conjunto ordenado de JIMDB para almacenar los registros de navegación en tiempo real del usuario. El nombre de usuario se usa como la CLAVE del conjunto pedido, el SKU del producto buscado se usa como el elemento del conjunto pedido, y la marca de tiempo del producto buscado se usa como la puntuación del elemento, y el tiempo de vencimiento se establece en 4 días para la CLAVE.
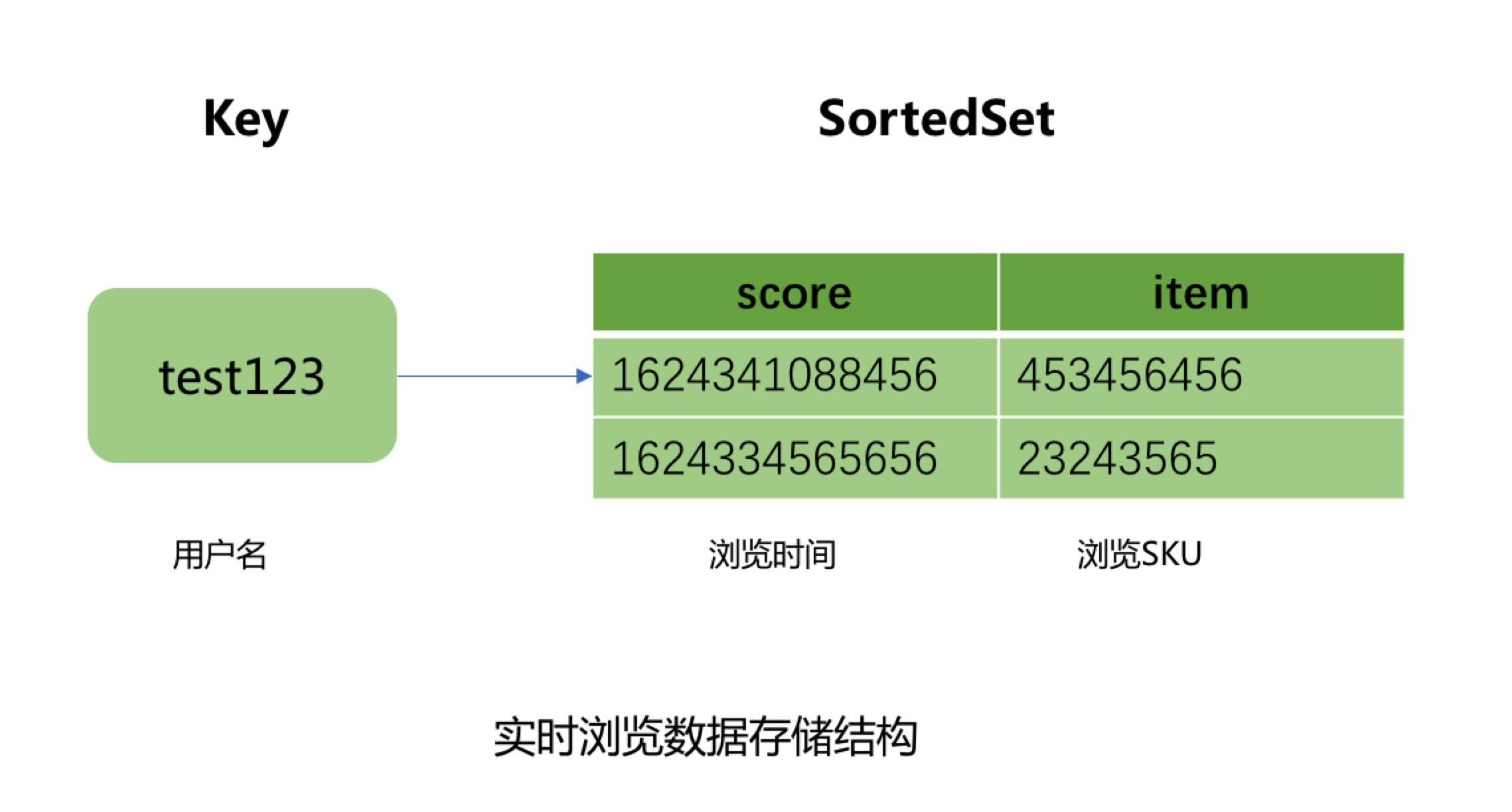
¿Por qué elegir 4 días para el tiempo de caducidad de datos calientes aquí?
Esto se debe a que los datos de navegación fuera de línea de nuestra plataforma de big data se informan y resumen en T + 1. Ya es al día siguiente cuando comenzamos a procesar los datos de navegación fuera de línea de los usuarios.Además de nuestro propio procesamiento de procesos comerciales y el proceso de limpieza y filtrado de datos, también lleva más de diez horas ejecutarlo y enviarlo a Hbase. Por lo tanto, el tiempo de caducidad de los datos activos debe establecerse en al menos 2 días, pero teniendo en cuenta el proceso de falla y reintento de ejecución de tareas de datos grandes, es necesario reservar 2 días para el reintento de tareas y el tiempo de reparación de datos, por lo que el tiempo de caducidad de los datos activos se establece en 4 días. Por lo tanto, cuando el usuario no ha navegado por nuevos productos en 4 días, los registros de navegación vistos por el usuario se consultan y muestran directamente desde Hbase.
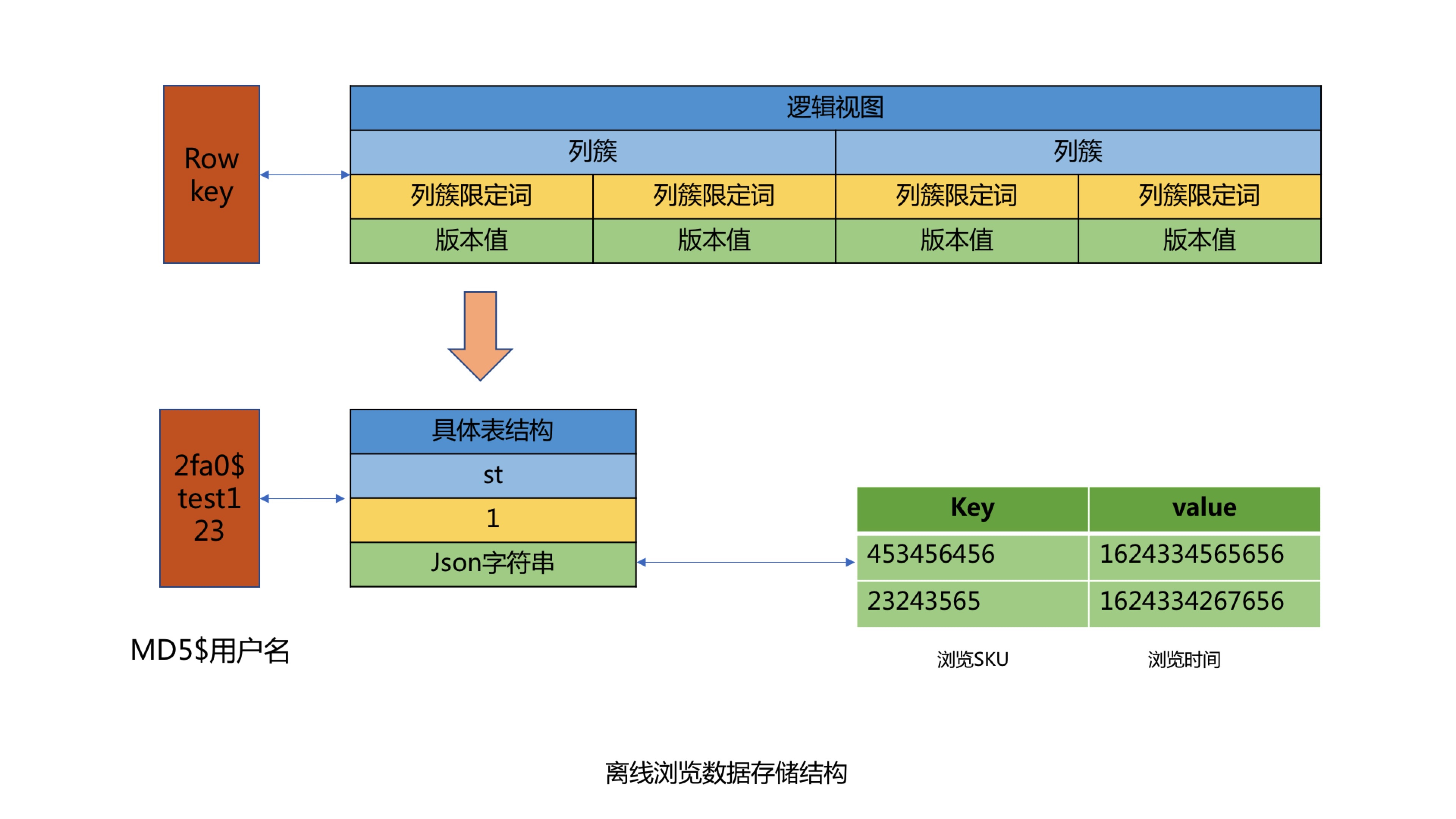
Los datos fríos utilizan el formato KV para almacenar los datos de navegación del usuario, utilizando el nombre de usuario como CLAVE, y la cadena Json correspondiente al producto de navegación del usuario y el tiempo de navegación como Valor para el almacenamiento. Al almacenar, se debe garantizar el orden de navegación del usuario para evitar una clasificación secundaria. Al usar el nombre de usuario como CLAVE, dado que la mayoría de los nombres de usuario tienen el mismo prefijo, habrá un problema de sesgo de datos, por lo que realizamos el procesamiento MD5 en el nombre de usuario y luego interceptamos los cuatro dígitos del medio después del MD5 como el prefijo de la CLAVE, resolviendo así el problema de sesgo de datos de Hbase. Finalmente, configure el tiempo de caducidad de KEY en 62 días para realizar la función de limpieza automática de caducidad de datos fuera de línea.
2.1.2 Diseño e implementación del módulo de servicio de consultas
El módulo de servicio de consulta incluye principalmente tres interfaces de microservicio, incluida la interfaz de consulta del número total de registros de navegación de usuarios, consulta de la lista de registros de navegación de usuarios y eliminación de registros de navegación de usuarios.
- Problemas enfrentados en el diseño de la interfaz de consulta del número total de registros de navegación de los usuarios
1. ¿Cómo resolver el problema de la limitación de corriente y el anticepillado?
Basado en el limitador de corriente RateLimiter de Guava y el caché local de Caffeine, se implementan las tres dimensiones del método global, la persona que llama y el nombre de usuario. La estrategia específica es que al llamar al método por primera vez, se generará un limitador actual de la dimensión correspondiente, y el limitador actual se guardará en el caché local implementado por Caffeine, y luego se establecerá un tiempo de vencimiento fijo.Cuando se llame al método la próxima vez, se generará la clave del limitador actual correspondiente y se obtendrá el limitador actual correspondiente del caché local.
2. ¿Cómo consultar el número total de registros de navegación de los usuarios?
Primero consulte la memoria caché del número total de registros de navegación del usuario. Si se alcanza la memoria caché, el resultado se devolverá directamente. Si no se alcanza la memoria caché, debe consultar la lista de registros de navegación en tiempo real del usuario desde Jimdb y luego agregar la información del producto en lotes. Dado que la lista de SKU de navegación del usuario puede ser grande, aquí puede consultar la información del producto en lotes. El número de lote se puede ajustar dinámicamente para evitar que el rendimiento de la consulta se vea afectado por demasiados productos en una sola consulta. Dado que la lista de productos de navegación que se muestra en la recepción debe desduplicarse para el mismo producto SPU, los campos de información del producto que deben complementarse incluyen el nombre del producto, la imagen del producto y el SPUID del producto. Después de la desduplicación del campo SPUID, determine si desea consultar los datos de navegación fuera de línea de Hbase. Aquí, puede juzgar si necesita consultar los registros de navegación fuera de línea de Hbase a través del interruptor de consulta fuera de línea, el indicador de borrado del usuario y la cantidad de registros de navegación después de la desduplicación de SPUID. Si la cantidad de registros de navegación ha alcanzado la cantidad máxima de registros de navegación establecida por el sistema después de la deduplicación, no se consultarán los registros fuera de línea. Si no está satisfecho, continúe consultando la lista de registros de navegación fuera de línea, combínela con la lista de registros de navegación en tiempo real del usuario y filtre los productos SKU de navegación duplicados. Después de obtener la lista completa de registros de navegación del usuario, filtre los registros de navegación eliminados del usuario, luego cuente la longitud de la lista y compárela con el número máximo de registros de navegación del usuario establecido por el sistema para obtener el valor mínimo, que es el número total de registros de navegación del usuario.
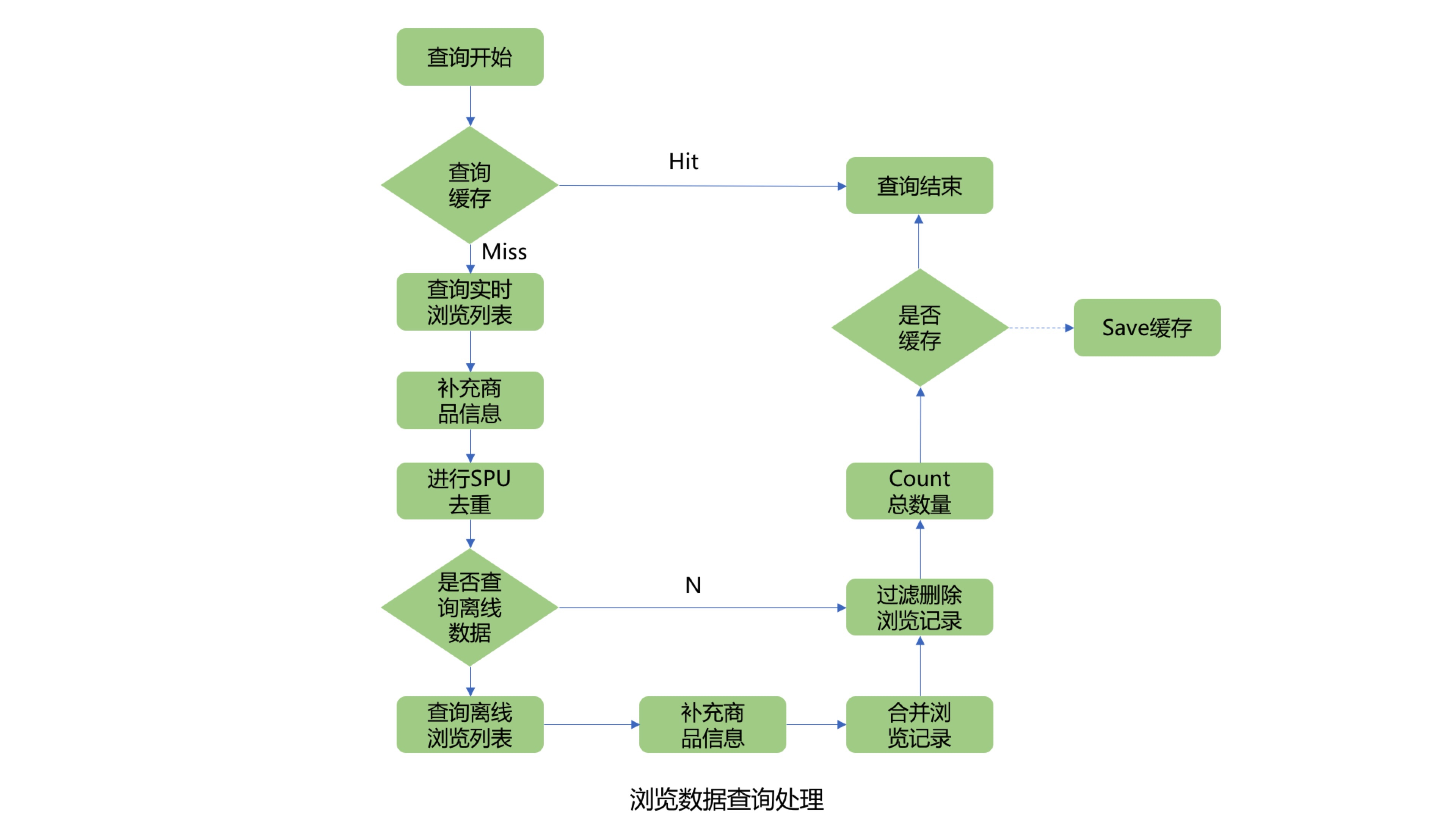
3. Consultar la lista de registros de navegación de usuarios
El proceso de consulta de la lista de registros de navegación de usuarios es básicamente el mismo que el proceso de consulta del número total de registros de navegación de usuarios.
2.1.2 Diseño e implementación del módulo de informes en tiempo real de datos de navegación
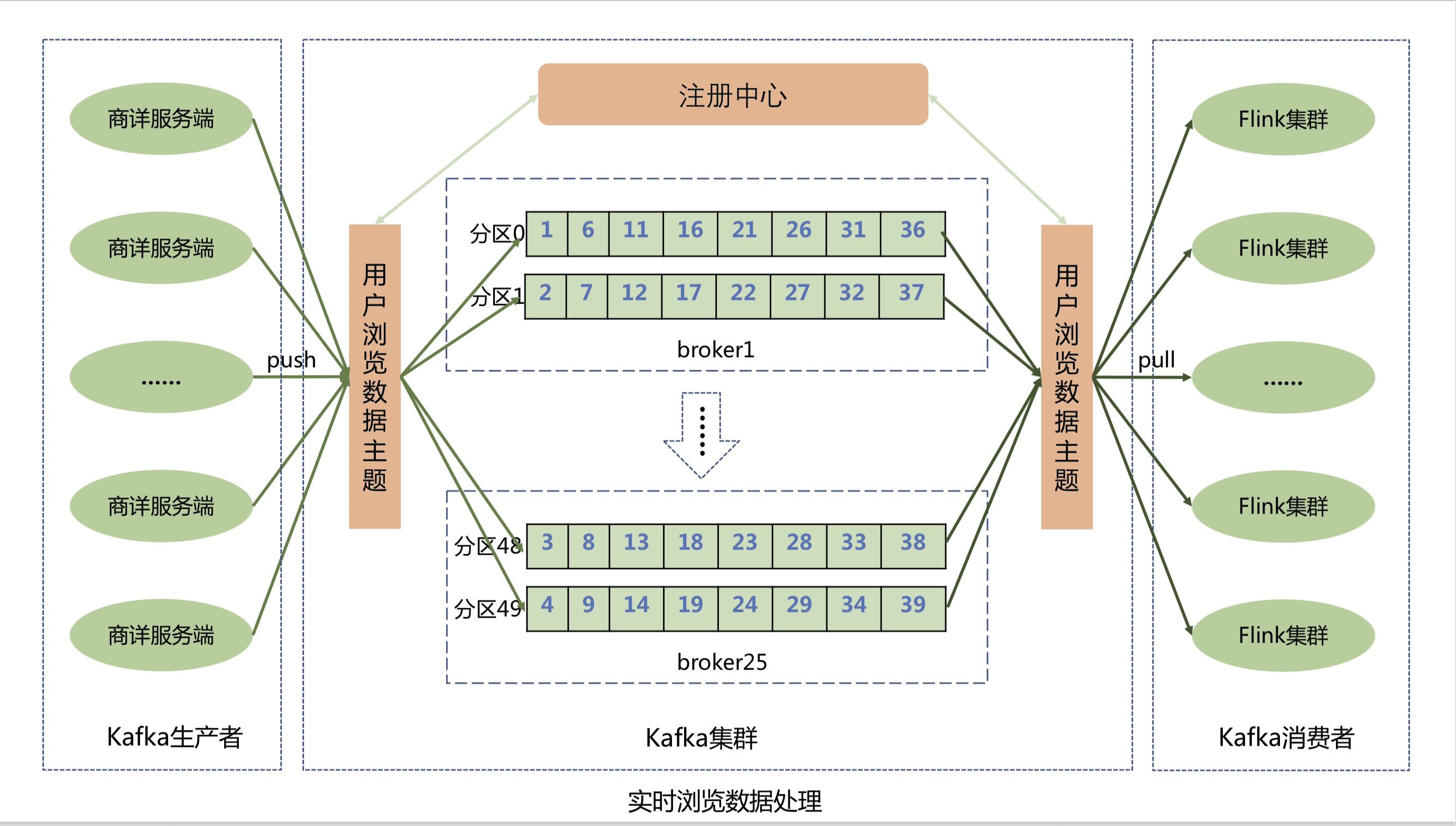
El servidor Shangxiang informa los datos de navegación en tiempo real del usuario a la cola de mensajes del clúster Kafka a través del cliente Kafka. Para mejorar el rendimiento de los informes de datos, el tema de datos de navegación del usuario se divide en 50 particiones. Kafka puede distribuir uniformemente los mensajes de navegación del usuario a las 50 colas de partición, lo que mejora en gran medida el rendimiento del sistema.
El sistema de registro de navegación consume los datos de navegación del usuario en la cola de Kafka a través del clúster de Flink y luego almacena los datos de navegación en la memoria de Jimdb en tiempo real. El clúster de Flink no solo realiza una expansión dinámica horizontal, mejora aún más el rendimiento del clúster de Flink, evita la acumulación de mensajes, sino que también garantiza que los mensajes de navegación del usuario se consuman exactamente una vez y que los datos del usuario no se pierdan y se puedan restaurar automáticamente cuando se produzca una excepción. La implementación de almacenamiento en clúster de Flink utiliza secuencias de comandos de Lua para combinar y ejecutar varios comandos de Jimdb, incluida la inserción de sku, la evaluación de la cantidad de registros de sku, la eliminación de sku y la configuración del tiempo de vencimiento, etc., optimizando múltiples operaciones de E/S de red en una sola.
¿Por qué elegir el motor de procesamiento de flujo Flink y Kafka en lugar de escribir directamente los datos de navegación en la memoria Jimdb en el servidor Shangxiang?
En primer lugar, JD.com es un sitio web de comercio electrónico las 24 horas del día, los 7 días de la semana con más de 500 millones de usuarios activos. Cada segundo, habrá usuarios navegando por la página de detalles del producto, que es como agua que fluye, lo cual es muy adecuado para el escenario de procesamiento de datos de transmisión distribuida.
En comparación con otros marcos de procesamiento de flujo, la solución basada en instantáneas distribuidas de Flink tiene muchas ventajas en términos de función y rendimiento, que incluyen:
- Baja latencia: dado que el almacenamiento del estado del operador puede ser asíncrono, el proceso de tomar una instantánea básicamente no bloqueará el procesamiento del mensaje, por lo que no afectará negativamente la demora del mensaje.
- Alto rendimiento: cuando el estado del operador es pequeño, básicamente no hay impacto en el rendimiento. Cuando hay muchos estados de operador, en comparación con otros mecanismos tolerantes a fallas, el intervalo de tiempo de las instantáneas distribuidas lo define el usuario, por lo que los usuarios pueden ajustar el intervalo de tiempo de las instantáneas distribuidas sopesando el tiempo de recuperación de errores y los requisitos de rendimiento.
- Aislamiento de la lógica comercial: el mecanismo de instantáneas distribuidas de Flink está completamente aislado de la lógica comercial del usuario, y la lógica comercial del usuario no dependerá ni tendrá ningún impacto en la instantánea distribuida.
- Costo de recuperación de errores: cuanto más corto sea el intervalo de tiempo de las instantáneas distribuidas, menor será el tiempo para la recuperación de errores, lo que se correlaciona negativamente con el rendimiento.
En segundo lugar, JD.com tiene muchas actividades de seguridad todos los días, como la prisa por comprar de Moutai, con millones de usuarios de reservas, y millones de usuarios actualizan la página de detalles comerciales en el mismo segundo, lo que generará una inundación de tráfico Si todo está escrito en tiempo real, ejercerá mucha presión sobre nuestro almacenamiento en tiempo real y afectará el rendimiento de la interfaz de consulta de front-end. Por lo tanto, usamos Kafka para realizar el procesamiento de reducción de picos y también desacoplar el sistema, de modo que el sistema Shangxiang no tenga que depender del sistema de registro de navegación.
¿Por qué elegir Kafka aquí?
Aquí necesitas entender primero las características de Kakfa.
- Alto rendimiento y baja latencia: la característica más importante de kakfa es que envía y recibe mensajes muy rápidamente. Kafka puede procesar cientos de miles de mensajes por segundo, y su retraso mínimo es de solo unos pocos milisegundos.
- Alta escalabilidad: cada tema (tema) contiene múltiples particiones (particiones), y las particiones en el tema se pueden distribuir entre diferentes hosts (intermediarios).
- Persistencia y confiabilidad: Kafka puede permitir el almacenamiento persistente de datos, los mensajes se conservan en el disco y admite la copia de seguridad de datos para evitar la pérdida de datos. El almacenamiento de datos subyacente de Kafka se basa en el almacenamiento de Zookeeper, y Zookeeper sabemos que sus datos se pueden almacenar de manera persistente.
- Tolerancia a fallas: permita que los nodos del clúster fallen, un nodo se caiga y el clúster de Kafka pueda funcionar con normalidad.
- Alta concurrencia: admite miles de clientes para leer y escribir al mismo tiempo.
¿Por qué Kafka es tan rápido?
-
Kafka utiliza el principio de copia cero para mover datos rápidamente, evitando cambiar entre núcleos.
-
Kafka puede enviar registros de datos en lotes, desde productores hasta sistemas de archivos y consumidores, y ver estos lotes de datos de principio a fin.
-
Durante el procesamiento por lotes, la compresión de datos se realiza de manera más eficiente y se reduce la latencia de E/S.
-
Kafka escribe en el disco secuencialmente, evitando el desperdicio de direccionamiento de disco aleatorio.
En la actualidad, el sistema ha experimentado muchas pruebas importantes de promoción y el sistema no se ha degradado. No hay acumulación de mensajes de navegación en tiempo real de los usuarios, y la capacidad de procesamiento de nivel de milisegundos se ha realizado básicamente. El rendimiento del método de TP999 ha alcanzado los 11 ms.
2.1.3 Diseño e implementación del módulo de informes de datos de navegación fuera de línea
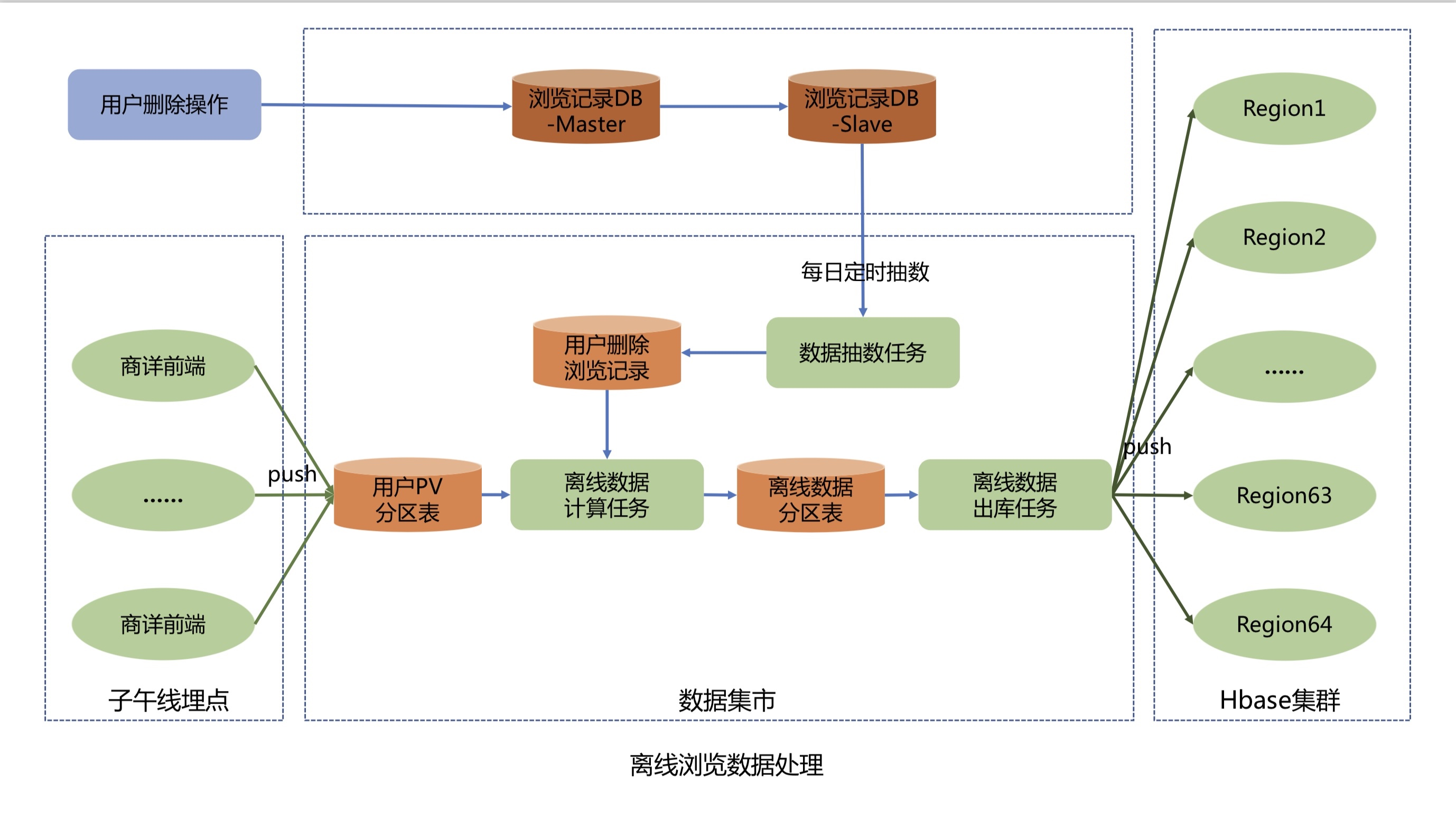
El proceso de informe de datos fuera de línea es el siguiente:
-
El front-end de detalles comerciales informa los datos de PV del usuario a través de la API de Meridian, y Meridian escribe los datos de PV del usuario en la tabla de partición de PV del usuario en el data mart.
-
La tarea de muestreo de datos extrae datos de la tabla de registro de navegación eliminada por el usuario de la biblioteca Mysql del sistema de registro de navegación al data mart a las 2:33 a. m. todos los días y escribe los datos eliminados en la tabla de registro de navegación eliminada por el usuario.
-
La tarea de cálculo de datos fuera de línea comienza todos los días a las 11:00 a. m. Primero extrae casi 60 días y 200 piezas de datos deduplicados por persona de la tabla de partición de PV del usuario, luego filtra y elimina los datos de acuerdo con la tabla de registros de navegación y eliminación del usuario, y calcula los nombres de usuario nuevos o eliminados del día y finalmente los almacena en la tabla de partición de datos fuera de línea.
-
La tarea de salida de datos sin conexión limpia y convierte los datos de navegación sin conexión incrementales de T+2 de la tabla de particiones de datos sin conexión a las 2:00 a. m. todos los días y envía los datos de navegación sin conexión en formato KV de los usuarios activos de T+2 al clúster de Hbase.
RustDesk 1.2: Usando Flutter para reescribir la versión de escritorio, apoyando a Wayland acusado de deepin V23 adaptándose con éxito a los lenguajes de programación WSL 8 con la mayor demanda en 2023: PHP es fuerte, la demanda de C/C++ se ralentiza ¿ React está experimentando el momento de Angular.js? El proyecto CentOS afirma estar "abierto a todos" Se lanzan oficialmente MySQL 8.1 y MySQL 8.0.34 Se lanza la versión estable de Rust 1.71.0Autor: Jingdong Retail Cao Zhifei
Fuente: Comunidad de desarrolladores de JD Cloud