Haga clic en la tarjeta a continuación para seguir la cuenta oficial de " CVer "
Mercancías secas pesadas AI/CV, entregadas por primera vez
Haga clic para ingresar —>【Transformador】Grupo de intercambio de WeChat
Los peces y las ovejas se envían desde el Templo Aufei
y se reproducen desde: Qubit (QbitAI)
¡La nueva arquitectura del gran modelo de Microsoft desafía oficialmente a Transformer !
El título del artículo dice brillantemente:
Retentive Network (RetNet): El sucesor de Transformer en el campo de los modelos grandes.

Red retentiva: un sucesor de Transformer para modelos de lenguaje grandes
Código: https://github.com/microsoft/unilm
Papel: https://arxiv.org/abs/2307.08621
El documento propone un nuevo mecanismo de Retención para reemplazar la Atención. Los investigadores del Instituto de Investigación de Microsoft Asia y la Universidad de Tsinghua no negaron su "ambición" y dijeron con valentía:
RetNet logra buenos resultados de escalado, capacitación paralela, implementación de bajo costo e inferencia eficiente.
Estas características hacen de esta infraestructura un poderoso sucesor del Transformador en el modelo de lenguaje grande.
Los datos experimentales también muestran que en las tareas de modelado del lenguaje:
RetNet puede lograr una perplejidad comparable a la de Transformer
Inferencia 8,4 veces más rápida
70% de reducción en el uso de memoria
Tiene buena escalabilidad
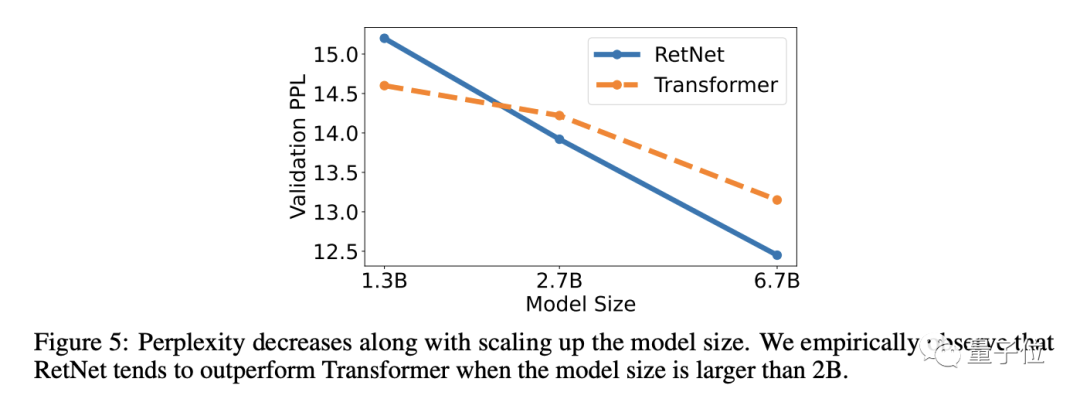
Y cuando el tamaño del modelo es mayor que cierta escala, RetNet funcionará mejor que Transformer.
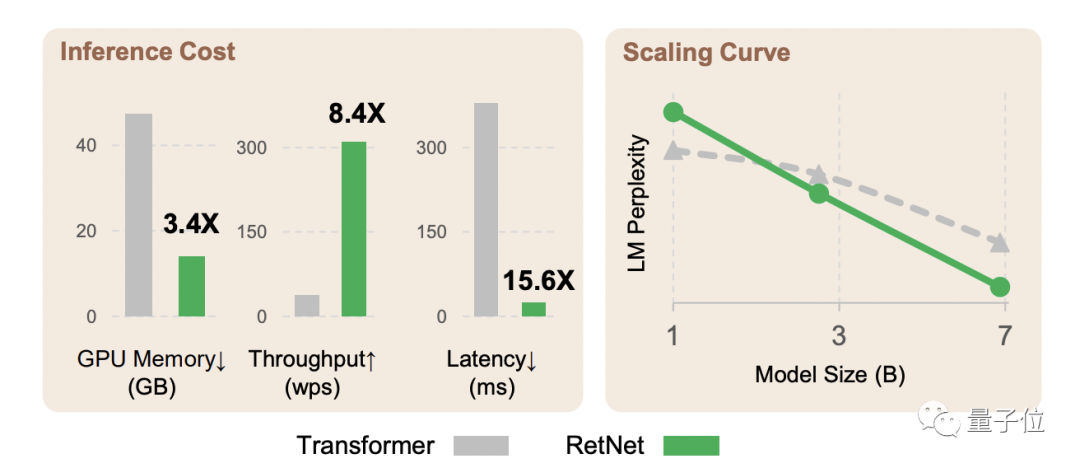
Transformador realmente "sucesor tiene un modelo"? Para más detalles, veamos juntos.
Resuelve el "triángulo imposible"
La importancia de Transformer en grandes modelos de lenguaje está fuera de toda duda. Ya sea la serie GPT de OpenAI, PaLM de Google o LLaMA de Meta, todos están basados en Transformer.
Pero Transformer no es perfecto: su mecanismo de procesamiento paralelo es a costa de un razonamiento ineficiente , y la complejidad de cada paso es O(N); Transformer es un modelo intensivo en memoria, y cuanto más larga es la secuencia, más memoria ocupa .
Antes de eso, no es que todos no pensaran en seguir mejorando Transformer. Sin embargo, las principales direcciones de investigación se descuidan un poco:
La atención lineal puede reducir el costo del razonamiento, pero el rendimiento es deficiente;
Las redes neuronales recurrentes no se pueden entrenar en paralelo.
En otras palabras, hay un "triángulo imposible" frente a estas arquitecturas de redes neuronales. Las tres esquinas representan: entrenamiento en paralelo, razonamiento de bajo costo y buena escalabilidad.
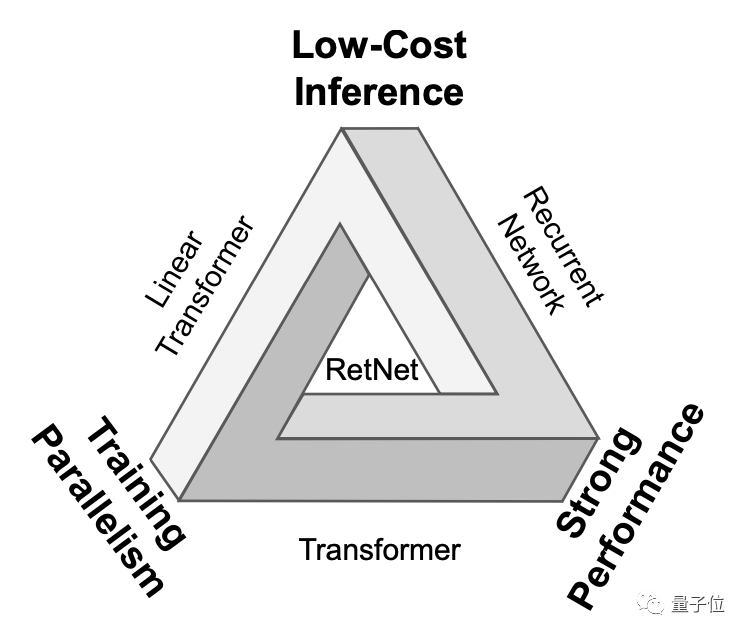
Lo que los investigadores de RetNet quieren hacer es hacer posible lo imposible.
Específicamente, sobre la base de Transformer, RetNet utiliza un mecanismo de retención de múltiples escalas para reemplazar el mecanismo de autoatención estándar .
En comparación con el mecanismo de autoatención estándar, el mecanismo de retención tiene varias características:
Se introduce un término de decaimiento exponencial dependiente de la posición para reemplazar softmax, que simplifica el cálculo y conserva la información del paso anterior en forma de decaimiento.
Introduzca un espacio numérico complejo para expresar información de posición, reemplace la codificación de posición absoluta o relativa y convierta fácilmente a forma recursiva.
Además, el mecanismo de retención utiliza tasas de descomposición de varias escalas, lo que aumenta la expresividad del modelo y utiliza la invariancia de escala de GroupNorm para mejorar la precisión numérica de la capa de retención.
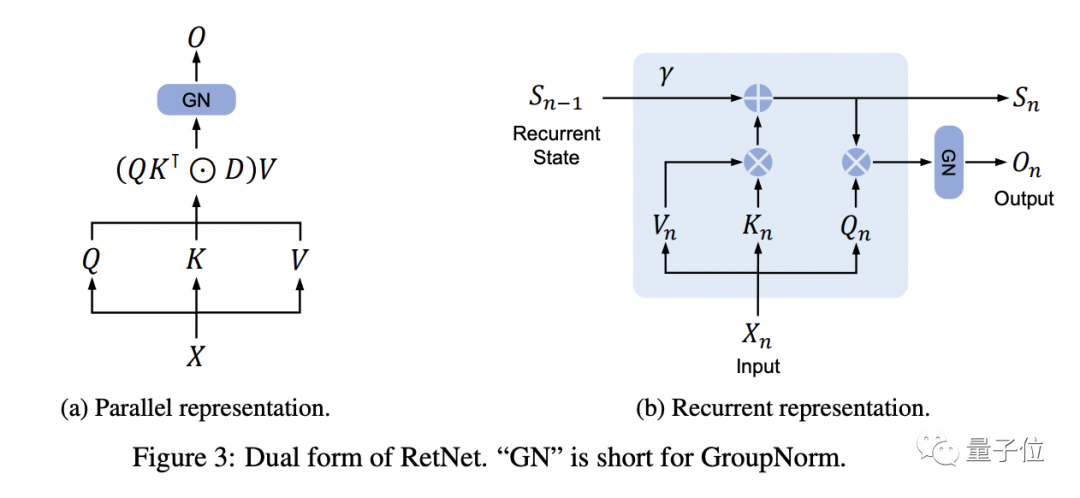
△ Representación dual de RetNet
Cada bloque RetNet contiene dos módulos: un módulo de conservación multiescala (MSR) y un módulo de red de avance (FFN).
El mecanismo de retención admite la representación de secuencias en tres formas:
paralelo
recursión
La recursión de bloques, es decir, una forma híbrida de representación paralela y representación recursiva, divide la secuencia de entrada en bloques, realiza cálculos de acuerdo con la representación paralela dentro de los bloques y sigue la representación recursiva entre bloques.
Entre ellos, la representación en paralelo permite que RetNet utilice de manera eficiente la GPU para el entrenamiento en paralelo como Transformer.
La representación recursiva logra la complejidad de inferencia O(1), reduciendo el uso de memoria y la latencia.
La recursividad fragmentada puede manejar secuencias largas de manera más eficiente.
De esta forma, RetNet hace posible el "triángulo imposible". Los siguientes son los resultados de la comparación de RetNet y otras infraestructuras:
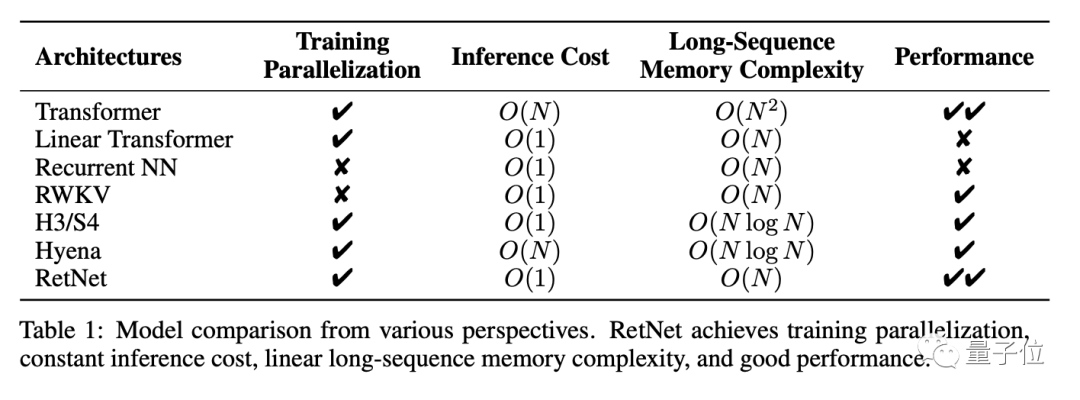
Los resultados experimentales de las tareas de modelado del lenguaje demuestran aún más la eficacia de RetNet.
Los resultados muestran que RetNet puede lograr una perplejidad similar a Transformer (PPL, un indicador para evaluar la calidad del modelo de lenguaje, cuanto más pequeño mejor).
Al mismo tiempo, cuando los parámetros del modelo son 7 mil millones y la longitud de la secuencia de entrada es 8k, la velocidad de inferencia de RetNet puede alcanzar 8,4 veces la de Transformer y el uso de memoria se reduce en un 70% .
Durante el proceso de entrenamiento, RetNet también funciona mejor que el Transformer+FlashAttention estándar en términos de ahorro de memoria y efectos de aceleración, alcanzando 25-50% y 7 veces respectivamente .
Vale la pena mencionar que el costo de inferencia de RetNet es independiente de la longitud de la secuencia y la latencia de inferencia es insensible al tamaño del lote, lo que permite un alto rendimiento.
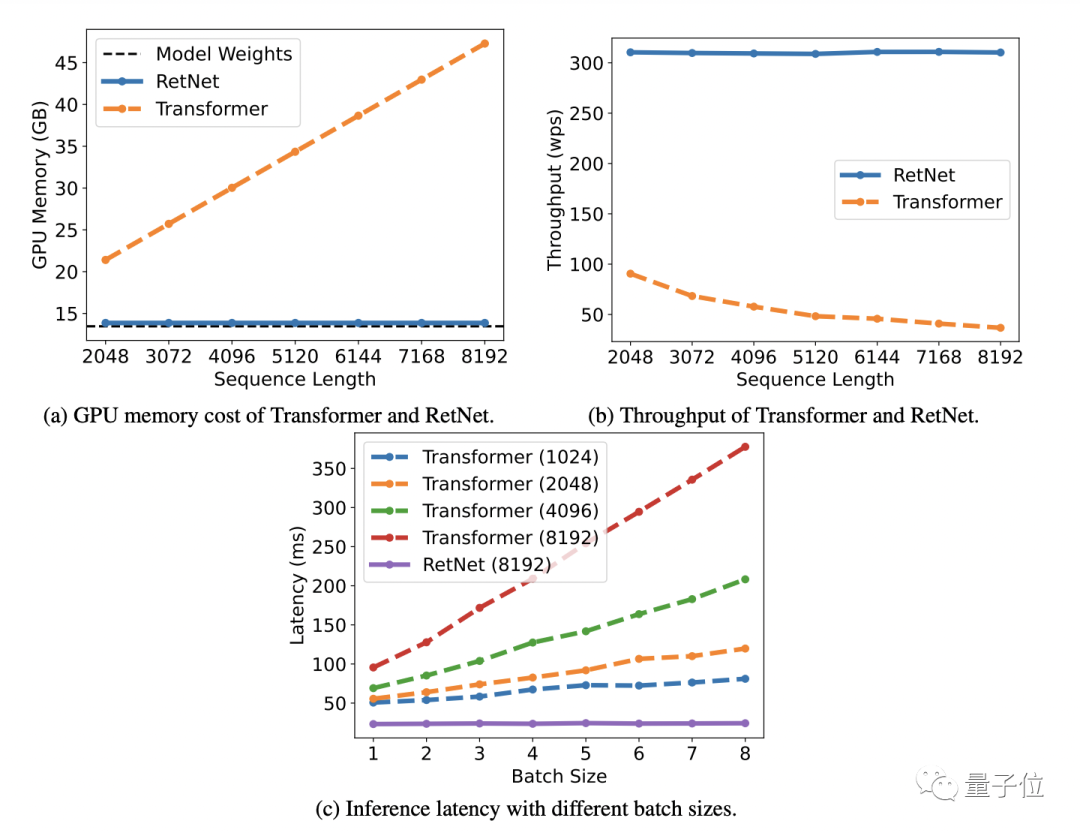
Además, cuando el tamaño del parámetro del modelo es superior a 2 mil millones, RetNet funcionará mejor que Transformer.
equipo de investigación
El equipo de investigación de RetNet es del Instituto de Investigación de Microsoft Asia y la Universidad de Tsinghua.
Juntos como Sun Yutao y Dong Li.
Sun Yutao, estudiante universitario en el Departamento de Ciencias de la Computación de la Universidad de Tsinghua, actualmente es pasante en el Instituto de Investigación de Microsoft Asia.
Dong Li es investigador en el Instituto de Investigación de Microsoft Asia. También es uno de los autores del artículo "Transformador que puede recordar mil millones de tokens" que ha llamado mucho la atención.
El autor correspondiente del artículo de RetNet es Wei Furu. Es un socio de investigación global del Instituto de Investigación de Microsoft Asia, y el Transformador de mil millones de tokens también pertenece a su equipo de investigación.
Dirección en papel:
https://arxiv.org/abs/2307.08621
Haga clic para ingresar —>【Computer Vision】WeChat Exchange Group
ICCV/CVPR 2023 Descarga de papel y código
Respuesta de antecedentes: CVPR2023, puede descargar la colección de documentos CVPR 2023 y codificar documentos de código abierto
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号No es fácil de organizar, dale me gusta y mira![]()