OpenAI mantiene cerrada la arquitectura GPT-4 no por algún riesgo existencial para los humanos, sino porque lo que construyen es reproducible. De hecho, esperamos que empresas como Google, Meta, Anthropic, Inflection, Character, Tencent, ByteDance, Baidu, etc. tengan modelos tan capaces o incluso más potentes que GPT-4 a corto plazo.
No me malinterpreten, OpenAI tiene increíbles capacidades de ingeniería y lo que han construido es increíble, pero las soluciones que han encontrado no son mágicas. Esta es una solución elegante con muchas compensaciones complejas. La ampliación es solo una parte de la batalla. La ventaja competitiva más duradera de OpenAI es que tienen las aplicaciones más prácticas, el talento de ingeniería líder y pueden seguir superando a otras empresas con modelos futuros.
Hemos recopilado una gran cantidad de información sobre GPT-4 de múltiples fuentes y hoy queremos compartirla. Esto incluye la arquitectura del modelo, la infraestructura de entrenamiento, la infraestructura de inferencia, la cantidad de parámetros, la composición del conjunto de datos de entrenamiento, la cantidad de tokens, la cantidad de capas, las estrategias paralelas, la adaptación de la visión multimodal, el proceso de pensamiento detrás de las diferentes compensaciones de ingeniería, las técnicas únicas implementadas y cómo alivian algunos de los mayores cuellos de botella asociados con la inferencia en modelos enormes.
El aspecto más interesante de GPT-4 es comprender por qué tomaron ciertas decisiones arquitectónicas.
Además, describimos el costo de entrenar e inferir GPT-4 en el A100, y cómo escala con el H100 en arquitecturas de modelos de próxima generación.
Primero, veamos el enunciado del problema. De GPT-3 a 4, OpenAI espera expandirse 100 veces, pero el problema es el costo. Los modelos de transformadores densos no escalarán más. Dense Transformer es la arquitectura modelo utilizada por OpenAI GPT-3, Google PaLM, Meta LLAMA, TII Falcon, MosaicML MPT y otros modelos. Fácilmente podríamos nombrar más de 50 empresas que utilizan esta misma arquitectura para capacitar a los LLM. Es una buena arquitectura, pero tiene fallas para escalar.
Antes del lanzamiento de GPT-4, discutimos la relación entre los costos de capacitación y el próximo muro de ladrillos de IA. Allí, revelamos el enfoque de alto nivel de OpenAI para la arquitectura GPT-4 y el costo de capacitación de varios modelos existentes.
Durante los últimos seis meses, nos hemos dado cuenta de que los costos de capacitación son irrelevantes.
Claro, puede parecer una locura en la superficie, gastar decenas o incluso cientos de millones de dólares en tiempo de cómputo para entrenar un modelo, pero para estas empresas, ese es un gasto insignificante. Es realmente un gasto de capital fijo que siempre produce mejores resultados cuando se trata de escalar. El único factor limitante es escalar el cálculo a una escala de tiempo en la que los humanos puedan obtener comentarios y modificar la arquitectura.
En los próximos años, varias empresas como Google, Meta y OpenAI/Microsoft entrenarán modelos en supercomputadoras con un valor de más de 100 000 millones de dólares. Meta quema $ 16 mil millones al año en el "Metaverso", Google desperdicia $ 10 mil millones al año en varios proyectos, Amazon pierde más de $ 50 mil millones en Alexa, crypto desperdicia más de $ 100 mil millones en cosas sin valor.
Estas empresas y la sociedad en general pueden gastar y gastarán más de cien mil millones de dólares en la creación de supercomputadoras que puedan entrenar un único modelo gigantesco. Estos enormes modelos pueden convertirse en productos de varias maneras. Este trabajo se replicará en varios países y empresas. Esta es una nueva carrera espacial. A diferencia del desperdicio del pasado, la IA de hoy tiene un valor tangible que se obtendrá a corto plazo de los asistentes humanos y los agentes autónomos.
Un problema más importante al escalar la IA es la inferencia.
El objetivo es separar el cálculo de entrenamiento del cálculo de inferencia. Es por eso que la capacitación significativa está más allá de lo mejor de Chinchilla, independientemente del modelo que se implementará. Esta es la razón por la que se utiliza una arquitectura de modelo disperso; durante la inferencia, no es necesario activar todos los parámetros.
El verdadero desafío es que escalar estos modelos a usuarios y agentes es demasiado costoso. El costo de la inferencia es muchas veces mayor que el costo del entrenamiento. Este es el objetivo innovador de OpenAI en términos de arquitectura e infraestructura modelo.
La inferencia con modelos grandes es un problema multivariante, y para modelos densos, el tamaño del modelo es fatal. Discutimos los problemas relacionados con la computación perimetral en detalle aquí, pero la declaración del problema para el centro de datos es muy similar. En términos simples, los dispositivos nunca tendrán suficiente ancho de banda de memoria para lograr un nivel específico de rendimiento para modelos de lenguaje grandes. Incluso si el ancho de banda es suficiente, la utilización de los recursos informáticos de hardware en los dispositivos informáticos de borde será muy baja.
En el centro de datos, en la nube, la utilización es fundamental. La mitad de la razón por la que Nvidia es admirada por su software superior es porque a lo largo de la vida útil de la GPU, Nvidia actualiza continuamente el software de bajo nivel moviendo datos de manera más inteligente dentro del chip, entre chips y entre la memoria, para aumentar la utilización de FRACASOS.
En la mayoría de los casos de uso actuales, el objetivo de la inferencia LLM es ejecutarse como un asistente en tiempo real, lo que significa que debe lograr un rendimiento lo suficientemente alto para que los usuarios realmente lo utilicen. El ser humano promedio lee alrededor de 250 palabras por minuto, pero algunas personas llegan incluso a 1000 palabras por minuto. Esto significa que debe generar al menos 8,33 tokens por segundo, pero más cerca de 33,33 tokens por segundo para cubrir todos los casos.
Dados los requisitos de ancho de banda de la memoria, un modelo denso de megaparámetros es matemáticamente incapaz de lograr este tipo de rendimiento en los últimos servidores GPU Nvidia H100.
Cada token generado requiere que todos los parámetros se carguen desde la memoria al chip. El token generado luego se introduce en el aviso y se genera el siguiente token. Además, se requiere ancho de banda adicional para transmitir la caché KV para el mecanismo de atención.
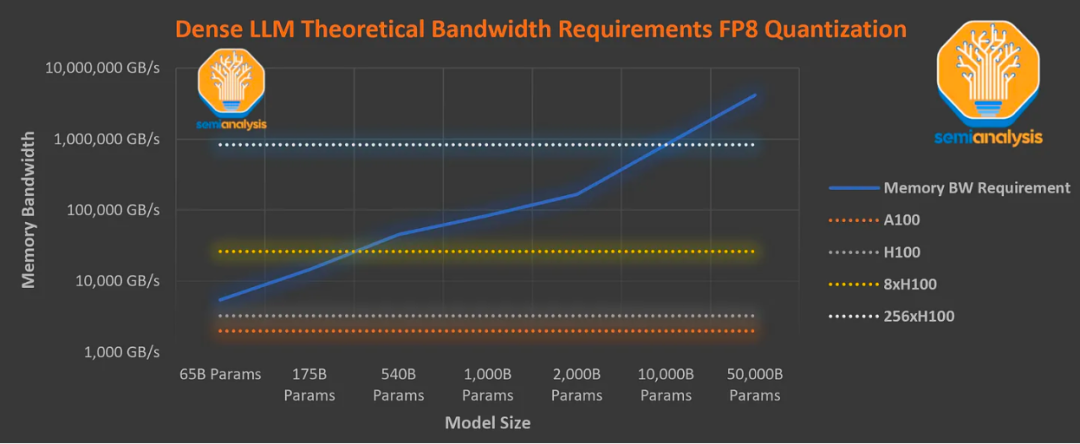
Este gráfico asume que la eficiencia es equivalente a las lecturas de parámetros debido a la incapacidad de fusionar cada operación, el ancho de banda de memoria requerido por el mecanismo de atención y la sobrecarga de hardware. De hecho, incluso con una biblioteca "optimizada" como la biblioteca FasterTransformer de Nvidia, la sobrecarga general es mayor.
El gráfico anterior muestra el ancho de banda de memoria requerido para inferir un LLM para lograr un rendimiento lo suficientemente alto para servir a un solo usuario. Muestra que incluso con 8 H100, no es posible servir un modelo denso de 1 megaparámetro a 33,33 tokens por segundo.
Además, la utilización de FLOPS con 8 H100 a 20 tokens por segundo sigue siendo inferior al 5 %, lo que genera costos de inferencia muy altos. De hecho, el sistema H100 actual basado en el paralelismo de tensores de 8 vías tiene un límite de inferencia de unos 300 000 millones de parámetros directos.
Sin embargo, OpenAI está utilizando el A100 para lograr la velocidad de lectura humana, utilizando más de 1 billón de parámetros de modelo y haciéndolo ampliamente disponible a un precio bajo de solo $ 0.06 por 1,000 tokens. Esto se debe a que es escaso, es decir, no se utilizan todos los parámetros.
Acerca de la arquitectura del modelo de GPT-4, la infraestructura de entrenamiento, la infraestructura de inferencia, la cantidad de parámetros, la composición del conjunto de datos de entrenamiento, la cantidad de tokens, la cantidad de capas, la estrategia paralela, el codificador visual multimodal, el proceso de pensamiento detrás de las diferentes compensaciones de ingeniería, la implementación de técnicas únicas y cómo alivian algunos de los mayores cuellos de botella asociados con la inferencia de modelos grandes.
#1 Arquitectura del modelo GPT-4
GPT-4 es más de 10 veces más grande que GPT-3. Hasta donde sabemos, tiene alrededor de 1,8 billones de parámetros, repartidos en 120 capas, mientras que GPT-3 tiene alrededor de 175 mil millones de parámetros.
OpenAI logró controlar el costo mediante el uso de un modelo Mixture of Experts (MoE). Si no está familiarizado con MoE, lea nuestro artículo de hace seis meses sobre la arquitectura generalizada de GPT-4 y los costos de capacitación.
Además, OpenAI utiliza 16 expertos en su modelo y los parámetros MLP de cada experto son alrededor de 111 mil millones. Hay 2 expertos en el enrutamiento de cada pase hacia adelante.
Si bien la literatura habla sobre algoritmos de enrutamiento avanzados para elegir a qué experto enrutar cada token, se dice que el algoritmo de enrutamiento del modelo GPT-4 actual de OpenAI es bastante simple.
Además, el mecanismo de atención comparte aproximadamente 55 mil millones de parámetros.
Cada pase de inferencia hacia adelante (que genera 1 token) solo usa alrededor de 280 mil millones de parámetros y 560 TFLOPS. Esto contrasta con los ~1,8 millones de parámetros y los 3700 TFLOPS necesarios por pase directo para un modelo puramente denso.
#2 Integración de datos
OpenAI entrenó a GPT-4 en alrededor de 13 billones de tokens. Esto tiene sentido considerando que CommonCrawl de RefinedWeb contiene alrededor de 5 megabytes de tokens de alta calidad. Como referencia, el modelo Chinchilla de Deepmind y el modelo PaLM de Google utilizaron alrededor de 1,4 mega tokens y 0,78 mega tokens respectivamente para el entrenamiento. Incluso se afirma que PaLM 2 se entrenó en alrededor de 5 billones de tokens.
Este conjunto de datos no contiene 13 billones de tokens únicos. Por el contrario, este conjunto de datos contiene varias épocas debido a la falta de tokens de alta calidad. Hay 2 épocas para datos de texto y 4 épocas para datos de código. Curiosamente, esta no es la mejor opción para Chinchilla, lo que demuestra que el modelo debe entrenarse con el doble de tokens. Esto demuestra la falta de tokens fáciles de obtener en la web. Hay 1000 veces más tokens de texto de alta calidad e incluso más tokens de audio y visuales, pero obtenerlos no es tan simple como raspar la web.
Tienen millones de líneas de instrucción ajustando datos de Scale Al e internamente, pero lamentablemente, no podemos encontrar muchos datos de aprendizaje de refuerzo en ellos.
La duración del contexto en la etapa de pre-entrenamiento es de 8k. La versión de longitud de token de 32k se ajusta con precisión sobre los 8k preentrenados.
El tamaño del lote se incrementó gradualmente durante varios días, pero al final, ¡OpenAI estaba usando un tamaño de lote de 60 millones! Por supuesto, dado que no todos los expertos ven todos los tokens, en realidad son solo 7,5 millones de tokens por lote por experto.
#3 Estrategias Paralelas
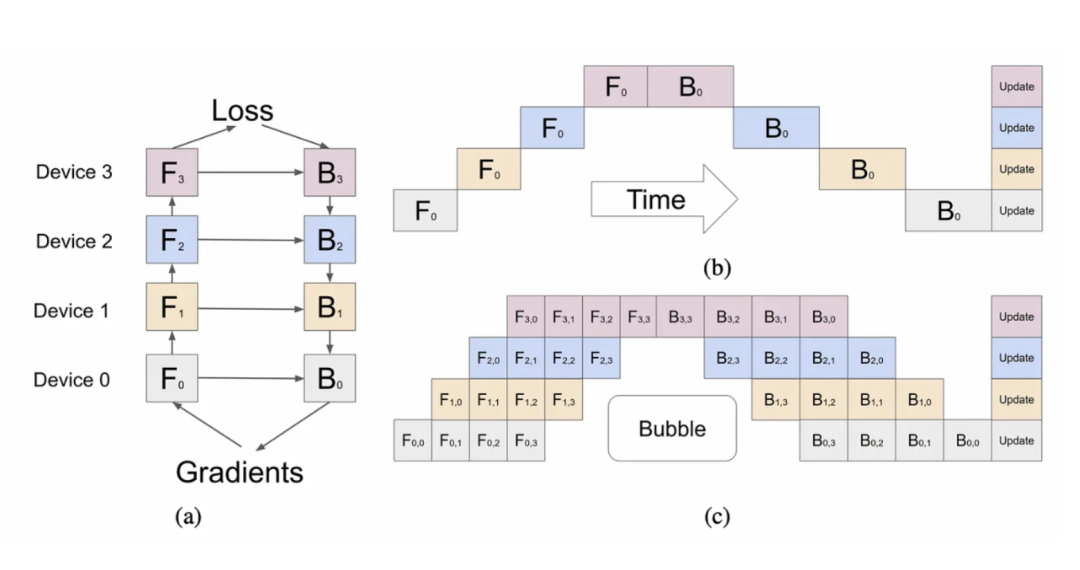
La estrategia de paralelización en todas las GPU A100 es muy importante. Usaron el paralelismo de tensor de 8 vías porque este es el límite de NVLink. Además, hemos escuchado que están usando canalizaciones de 15 vías en paralelo. Desde el punto de vista del tiempo de computación y la comunicación de datos, en teoría, la cantidad de canalizaciones paralelas es demasiado, pero si están limitadas por la capacidad de la memoria, entonces tiene sentido.
En canalización pura + paralelismo de tensor, cada GPU requiere alrededor de 30 GB (FP16) solo para parámetros. Una vez que agregue el caché KV y la sobrecarga, teóricamente tendría sentido si la mayoría de las GPU de OpenAI son A100 de 40 GB. Probablemente usaron ZeRo Phase 1. Probablemente usaron FSDP a nivel de bloque o paralelismo mixto de datos compartidos.
En cuanto a por qué no usaron el modelo completo de FSDP, podría deberse a la mayor sobrecarga de comunicación. Si bien la mayoría de los nodos de OpenAI tienen conexiones de red de alta velocidad entre ellos, no todos las tienen. Creemos que al menos algunos clústeres tienen un ancho de banda mucho menor entre clústeres que otros.
No entendemos cómo pueden evitar enormes burbujas por lote con un paralelismo de tubería tan alto. Lo más probable es que solo hayan cubierto los gastos generales.
#4 Costo de entrenamiento
OpenAI usó aproximadamente 25 000 chips A100 para entrenar en GPT-4, logrando una MFU (utilización media de funciones) de aproximadamente 32 % a 36 % durante un período de 90 a 100 días. Esta utilización extremadamente baja se debe en parte a la gran cantidad de fallas que requieren reinicios desde los puntos de control, siendo muy costosas las burbujas antes mencionadas.
Otra razón es que una reducción global en tantas GPU es muy costosa. Si nuestra conjetura es correcta, el clúster en realidad está formado por muchos clústeres más pequeños con conexiones de red muy delgadas entre ellos, es decir, conexiones sin bloqueo de 800G/1,6T entre diferentes partes del clúster, pero estas partes solo se pueden conectar a 200G/ Velocidad 400G.
Si tienen un chip A100 en la nube que cuesta alrededor de $ 1 por hora, solo ese entrenamiento cuesta alrededor de $ 63 millones. Esto no tiene en cuenta todos los experimentos, las ejecuciones de entrenamiento fallidas y otros costos, como la recopilación de datos, el aprendizaje por refuerzo y los costos de personal. Debido a estos factores, el costo real es mucho mayor. Además, significa que necesita que alguien compre el chip/la red/el centro de datos, cubra el gasto de capital y se lo arriende.
Actualmente, el entrenamiento previo se puede realizar en unos 55 días a 2 dólares la hora utilizando unos 8.192 chips H100, a un costo de unos 21,5 millones de dólares. Cabe señalar que creemos que 9 empresas tendrán más chips H100 para fines de este año. No todas estas empresas los usarán todos para una sola ejecución de capacitación, pero las que lo hagan tendrán modelos a una escala mucho mayor. Meta tendrá más de 100 000 chips H100 para fin de año, pero muchos de esos chips se distribuirán en sus centros de datos para la inferencia. Su clúster individual más grande seguirá teniendo más de 25 000 chips H100.
Para fines de este año, muchas empresas tendrán suficientes recursos informáticos para entrenar modelos en la escala de GPT-4.
# 5 Compensaciones de MoE
Durante la inferencia, MoE es una buena manera de reducir la cantidad de parámetros mientras aumenta la cantidad de parámetros durante la inferencia, lo cual es necesario para codificar más información por token de entrenamiento, porque es muy difícil obtener suficientes tarjetas de tokens de alta calidad. Si OpenAI realmente intentara lograr la optimización de Chinchilla, tendrían que usar el doble de la cantidad actual de tokens en el entrenamiento.
Aún así, OpenAI hace varias concesiones. Por ejemplo, durante la inferencia, MoE es muy difícil de manejar, porque no se usa cada parte del modelo en cada generación de token. Esto significa que algunas partes pueden estar inactivas mientras que otras se utilizan para atender a los usuarios. Esto tiene un gran impacto negativo en la utilización.
Los investigadores han demostrado que usar de 64 a 128 expertos tiene menos pérdidas que usar 16 expertos, pero eso es pura investigación. Hay varias razones para reducir el número de expertos. Una de las razones por las que OpenAI eligió a 16 expertos es porque más expertos tienen dificultades para generalizar sobre muchas tareas. También puede ser más difícil lograr la convergencia utilizando más expertos. En una carrera de entrenamiento tan grande, OpenAI optó por ser más conservador en la cantidad de expertos.
Además, reducir el número de expertos también ayuda a su infraestructura de inferencia. Hay varias compensaciones difíciles cuando se adoptan arquitecturas de inferencia mixta expertas. Antes de explorar las compensaciones que enfrentó OpenAI y las decisiones que tomaron, comenzamos con las compensaciones fundamentales del razonamiento LLM.
#6 Compensaciones de razonamiento
Por cierto, antes de comenzar, queremos señalar que todas las empresas LLM con las que hablamos pensaron que la biblioteca de inferencia FasterTransformer de Nvidia era bastante mala y que TensorRT era aún peor. La desventaja de no poder usar las plantillas de Nvidia y modificarlas significa que las personas necesitan crear sus propias soluciones desde cero. Si trabaja en Nvidia, después de leer este artículo, debe arreglar esto lo antes posible; de lo contrario, la opción predeterminada cambiará para abrir herramientas, por lo que se puede agregar soporte de hardware de terceros más fácilmente. Se acerca una gran ola de modelos. Si no hay una ventaja de software en la inferencia, y los núcleos aún deben escribirse a mano, entonces el MI300 de AMD y otro hardware tendrán un mercado más grande.
En la inferencia de modelos de lenguajes grandes, existen 3 compensaciones principales que ocurren entre el tamaño del lote (número de usuarios simultáneos atendidos) y el número de chips utilizados.
-
Latencia: el modelo debe responder con una latencia razonable. La gente no quiere esperar unos segundos antes de que la salida comience a fluir hacia la aplicación de chat. La precarga (tokens de entrada) y la decodificación (tokens de salida) tardan diferentes tiempos en procesarse.
-
Rendimiento: el modelo debe generar una cierta cantidad de tokens por segundo. Se requieren alrededor de 30 fichas por segundo para uso humano. Para varios otros usos, son aceptables rendimientos tanto más bajos como más altos.
-
Utilización: el hardware que ejecuta el modelo debe lograr una alta utilización; de lo contrario, el costo será prohibitivo. Si bien es posible lograr una mayor utilización agrupando más solicitudes de usuarios con mayor latencia y menor rendimiento, esto aumenta la dificultad.
El razonamiento de LLM se trata de equilibrar dos factores principales: el ancho de banda de la memoria y la computación. En los términos más simplificados, cada parámetro tiene que ser leído y asociado a él hay 2 FLOP. Como resultado, la proporción de la mayoría de los chips (por ejemplo, el chip H100 SXM tiene solo 3 TB/s de ancho de banda de memoria, pero 2000 TFLOPs/s de FP8) está completamente desequilibrada en la inferencia con un tamaño de lote de 1. Si solo se atiende a un usuario, con un tamaño de lote de 1, entonces para cada generación de token, el ancho de banda de memoria requerido domina el tiempo de inferencia. El tiempo de cálculo es casi cero. Para escalar de manera eficiente modelos de lenguaje grandes a varios usuarios, el tamaño del lote debe ser superior a 4. Múltiples usuarios comparten el costo de la lectura de parámetros. Por ejemplo, con un tamaño de lote de 256 o 512, hay 512 FLOP/s o 1024 FLOP/s por byte de lectura de memoria.
Esta relación está más cerca de la relación entre el ancho de banda de la memoria y FLOPS de H100. Esto ayuda a lograr una mayor utilización, pero a costa de una mayor latencia.
Mucha gente ve la capacidad de la memoria como un gran cuello de botella para la inferencia LLM, debido al hecho de que los modelos grandes requieren múltiples chips para la inferencia, y una mayor capacidad de memoria cabe en menos chips, pero en realidad, es mejor usar más chips de los necesarios. chips de capacidad para que la latencia sea menor, el rendimiento sea mayor y se puedan usar tamaños de lote más grandes para lograr una utilización cada vez mayor.
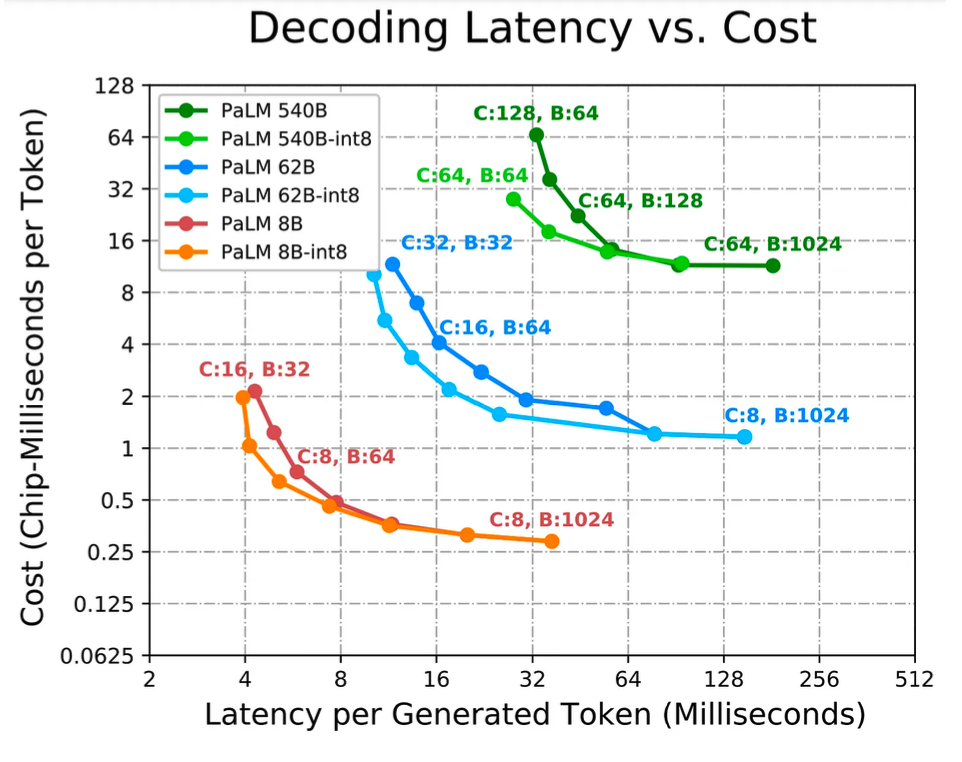
Google demuestra estas compensaciones en su artículo de inferencia de PaLM. Sin embargo, vale la pena señalar que esto es para un modelo denso como PaLM, no para un modelo disperso como GPT-4.
Si una aplicación requiere la latencia más baja, necesitamos aplicar más chips y dividir el modelo en tantas partes como sea posible. Los tamaños de lote más pequeños generalmente permiten una latencia más baja, pero los tamaños de lote más pequeños también dan como resultado una utilización más pobre, lo que resulta en un costo total más alto por token (en segundos de chip o dólares). Si una aplicación requiere inferencia fuera de línea y la latencia no es un problema, el objetivo principal es maximizar el rendimiento por chip (es decir, minimizar el costo total por token).
Aumentar el tamaño del lote es más eficiente porque los lotes más grandes generalmente logran una mejor utilización, pero ciertas estrategias de partición que no son eficientes para tamaños de lote pequeños se vuelven eficientes a medida que aumenta el tamaño del lote. Más chips y tamaños de lote más altos son más baratos porque aumentan la utilización, pero esto también introduce una tercera variable, el tiempo de red. Ciertos métodos de división de modelos entre chips son más eficientes en cuanto a latencia, pero se compensan con la utilización.
Tanto el tiempo de memoria como el tiempo de cálculo no atencional son proporcionales al tamaño del modelo e inversamente proporcionales al número de chips. Sin embargo, para un diseño de partición dado, el tiempo requerido para la comunicación entre chips disminuye más lentamente (o no se reduce en absoluto), por lo que se vuelve cada vez más importante a medida que aumenta la cantidad de chips, convirtiéndose en un cuello de botella cada vez más importante. Si bien hoy solo lo discutiremos brevemente, debe tenerse en cuenta que los requisitos de memoria de la caché KV aumentan drásticamente a medida que crece el tamaño del lote y la longitud de la secuencia. Si una aplicación necesita generar texto con contextos de atención más largos, el tiempo de inferencia aumentará significativamente.
Para un modelo 500B+ con atención de varios cabezales, la caché KV de atención se vuelve grande: para un tamaño de lote de 512 y una longitud de contexto de 2048, la caché KV alcanza los 3 TB en total, que es 3 veces el tamaño del parámetro del modelo. La memoria en el chip necesita cargar este caché KV desde la memoria fuera del chip a la memoria, y el núcleo de cómputo del chip está básicamente inactivo durante este período. Las longitudes de secuencia largas son particularmente malas para el ancho de banda de la memoria y la capacidad de la memoria. El GPT 3.5 turbo de longitud de secuencia de 16k de OpenAI y el GPT 4 de longitud de secuencia de 32k cuestan mucho más porque no pueden usar tamaños de lote más grandes debido a limitaciones de memoria.
Los tamaños de lote más bajos dan como resultado una menor utilización del hardware. Además, a medida que aumenta la longitud de la secuencia, la memoria caché KV también se vuelve más grande. La caché KV no se puede compartir entre usuarios, por lo que se requieren lecturas de memoria separadas, lo que reduce aún más el ancho de banda de la memoria.
#7 Inferencia de compensaciones e infraestructura para GPT-4
Todo lo anterior es difícil en la inferencia GPT-4, pero la arquitectura del modelo emplea una Mezcla de expertos (MoE), que presenta un nuevo conjunto de dificultades. Cada pase de reenvío generado por token se puede enrutar a un conjunto diferente de expertos. Esto plantea un problema con las compensaciones logradas entre el rendimiento, la latencia y la utilización en lotes de gran tamaño.
El GPT-4 de OpenAI tiene 16 expertos, 2 expertos en cada pase hacia adelante. Esto significa que si el tamaño de lote es 8, la lectura de parámetros de cada experto solo puede ser de tamaño de lote 1. Peor aún, tal vez un experto tenga un tamaño de lote de 8, mientras que otros podrían tener 4, 1 o 0. Cada vez que se genera un token, el algoritmo de enrutamiento envía un pase hacia adelante en una dirección diferente, lo que genera una latencia de token a token y una variación significativa en el tamaño del lote experto. La infraestructura de inferencia es una de las principales razones por las que OpenAI eligió un número menor de expertos. Si eligieran más expertos, el ancho de banda de la memoria sería más un cuello de botella para la inferencia.
OpenAI alcanza regularmente tamaños de lote de más de 4k en clústeres de inferencia, lo que significa que, incluso con un equilibrio de carga óptimo entre los expertos, el tamaño del lote de los expertos es de solo ~500. Esto requiere una gran cantidad de uso para lograrlo. Aprendimos que OpenAI ejecuta la inferencia en un grupo de 128 GPU. Tienen varios de estos clústeres en múltiples centros de datos y ubicaciones geográficas. La inferencia se realiza en paralelismo de tensor de 8 vías y paralelismo de tubería de 16 vías. Cada nodo que consta de 8 GPU tiene solo alrededor de 130B de parámetros, es decir, menos de 30 GB por GPU en modo FP16 y menos de 15 GB en modo FP8/int8. Esto permite que la inferencia se ejecute en el chip A100 de 40 GB, siempre que el tamaño de caché KV para todos los lotes no sea demasiado grande.
Una sola capa que contenga varios expertos no se dividiría en diferentes nodos, ya que esto haría que el tráfico de la red fuera demasiado irregular y sería demasiado costoso volver a calcular el caché KV entre cada generación de token. Para cualquier extensión futura del modelo MoE y el enrutamiento condicional, la mayor dificultad es cómo manejar el enrutamiento del caché KV.
El modelo tiene 120 capas, por lo que es trivial distribuirlo uniformemente en 15 nodos diferentes, pero dado que el primer nodo necesita cargar e incorporar datos, es significativo colocar menos capas en el nodo maestro del clúster de inferencia. Además, hemos escuchado algunos rumores sobre la decodificación especulativa del razonamiento, que discutiremos más adelante, pero no estamos seguros de creerlos. Esto también explicaría por qué los masternodes necesitan contener menos capas.
#8 Costo de inferencia de GPT-4
En comparación con el modelo Davinchi con parámetros 175B, GPT-4 es 3 veces más caro, aunque sus parámetros de avance solo aumentan 1,6 veces. Esto se debe principalmente a que GPT-4 requiere un clúster más grande y logra una menor utilización.
Consideramos que el costo por tokens de 1k es de 0,0049 centavos por 128 A100 para inferir longitudes de secuencia de 8k GPT-4 y 0,0021 centavos por tokens de 1k para 128 H100s para inferir longitudes de secuencia de 8k GPT-4.
Vale la pena señalar que asumimos una alta utilización y mantenemos un tamaño de lote alto. Esta podría ser una suposición incorrecta, ya que está claro que OpenAI a veces está muy infrautilizado. Experimentamos con varias técnicas nuevas asumiendo que OpenAI apaga el clúster durante los períodos mínimos y reprogramamos esos nodos para reanudar el entrenamiento en un modelo de prueba más pequeño desde un punto de control. Esto ayuda a reducir el costo de la inferencia. Si OpenAI no lo hubiera hecho, su utilización habría sido menor y nuestras estimaciones de costos se habrían más que duplicado.
#9 Atención multiconsulta
MQA es una técnica que están utilizando otras empresas, pero nos gustaría señalar que OpenAI también la está utilizando. Para resumir, con solo un encabezado requerido, la capacidad de memoria de la caché KV puede reducirse considerablemente. Aun así, GPT-4 con una longitud de secuencia de 32k ciertamente no puede ejecutarse en el chip A100 de 40 GB, y GPT-4 con una longitud de secuencia de 8k está limitado en el tamaño máximo del lote. Sin MQA, el tamaño máximo de lote de GPT-4 con una longitud de secuencia de 8k sería tan limitado que no sería económicamente viable.
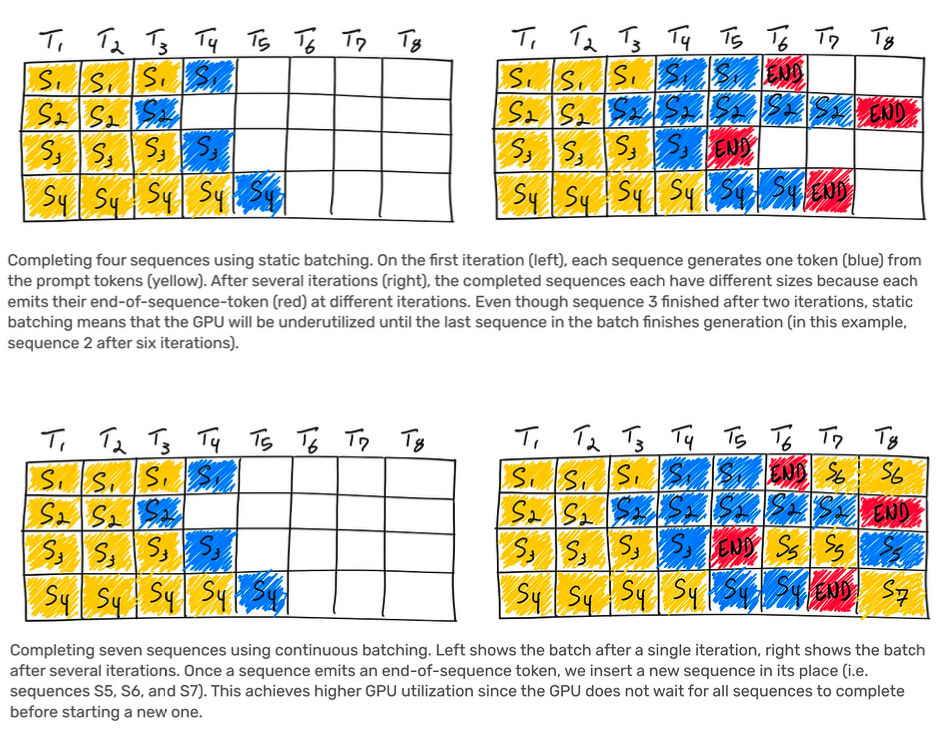
#10 Dosificación continua
OpenAI implementa tamaños de lote variables y procesamiento por lotes continuo. Esto permite una latencia máxima hasta cierto punto y optimiza los costos de inferencia. Si eres nuevo en el concepto, vale la pena leer este artículo de AnyScale.
#11 Acerca de las soluciones de adivinanzas
Hemos escuchado de algunas fuentes confiables que OpenAI usa la decodificación de conjeturas en su inferencia GPT-4. No estamos seguros de creerlo completamente. La variación general en la latencia de token a token y la diferencia cuando se realizan tareas de recuperación simples frente a tareas más complejas parece sugerir que esto es posible, pero hay demasiadas variables para estar seguros. Por si acaso, usaremos parte del texto de "Aceleración de la inferencia LLM mediante la decodificación de conjetura segmentada" aquí y modificaremos/agregaremos algunas aclaraciones.
Por lo general, hay dos fases para usar el LLM. La primera es la etapa de llenado previo, que pasa el texto de solicitud a través del modelo para generar la memoria caché KV y los logits (distribución de probabilidad de posibles salidas de token) para la primera salida. Por lo general, esta etapa es rápida, ya que todo el texto de la pista se puede procesar en paralelo.
La segunda etapa es la decodificación. Se selecciona un token de los logits de salida y se retroalimenta al modelo para generar los logits del siguiente token. Repita este proceso hasta que se genere la cantidad deseada de tokens. Debido a que la decodificación debe ocurrir de manera secuencial, con los pesos que se transmiten a través de la unidad de cómputo cada vez para generar un solo token, la intensidad aritmética de la segunda etapa (es decir, FLOP de cómputo/bytes de ancho de banda de memoria) cuando se ejecuta en mini lotes es muy baja.
Por lo tanto, la decodificación suele ser la parte más costosa de la generación autorregresiva. Es por eso que en las llamadas a la API de OpenAI, los tokens de entrada son mucho más baratos que los tokens de salida.
La idea básica de la decodificación de conjeturas es usar un modelo de borrador más pequeño y rápido para predecodificar múltiples tokens y luego alimentarlos al modelo de Oracle como un lote. Si el borrador del modelo es correcto sobre el token que predice, es decir, el modelo más grande está de acuerdo, entonces se pueden decodificar múltiples tokens en un lote, lo que ahorra un ancho de banda de memoria y tiempo considerables, por token.
Sin embargo, si el modelo más grande rechaza un token predicho por el modelo preliminar, el lote restante se descarta y el algoritmo vuelve naturalmente a la decodificación estándar token por token. La decodificación adivinatoria también puede ir acompañada de un esquema de muestreo de rechazo para tomar muestras de la distribución original. Tenga en cuenta que esto solo es útil en configuraciones de lotes pequeños donde el ancho de banda es el cuello de botella.
La decodificación adivinatoria compensa la computación y el ancho de banda. La decodificación conjetura es un objetivo de optimización del rendimiento por dos razones clave. En primer lugar, no degrada en absoluto la calidad del modelo. En segundo lugar, ofrece ventajas que generalmente no están relacionadas con otros métodos, ya que su desempeño proviene de convertir la ejecución secuencial en ejecución paralela.
El método de adivinación actual predice una sola secuencia para el lote. Sin embargo, esto no se escala bien con tamaños de lote grandes o alineación de modelo de borrador bajo. Intuitivamente, la probabilidad de que dos modelos coincidan en secuencias sucesivamente largas disminuye exponencialmente, lo que implica que la recompensa por adivinar la decodificación disminuye rápidamente a medida que aumenta la intensidad aritmética.
Creemos que si OpenAI usa la decodificación de conjeturas, probablemente solo la usen en secuencias de aproximadamente 4 tokens. Por cierto, toda la conspiración de GPT-4 para reducir la calidad probablemente se deba a que hicieron que el modelo de Oracle aceptara secuencias de menor probabilidad del modelo de decodificación de adivinanzas. Otra nota es que se ha especulado que Bard usó la decodificación de conjeturas porque Google esperó a que se completara la generación de la secuencia antes de enviar la secuencia completa al usuario, pero no creemos que esta especulación sea cierta.
#12 Sobre la multimodalidad visual
Las capacidades multimodales visuales son la parte menos impresionante de GPT-4, al menos en comparación con la investigación líder. Ciertamente, ninguna empresa ha comercializado aún la investigación sobre LLM multimodal.
Es un codificador visual independiente, separado del codificador de texto, pero con atención cruzada. Escuchamos que su arquitectura es similar a Flamingo. Esto agrega más parámetros además de los parámetros 1.8T de GPT-4. Después del entrenamiento previo de solo texto, también se ajusta en otros ~ 2 billones de tokens.
Para el modelo de visión, OpenAI esperaba entrenar desde cero, pero este método no estaba lo suficientemente maduro, por lo que decidieron comenzar con texto para mitigar el riesgo.
El próximo modelo, GPT-5, supuestamente será entrenado para la visión desde cero y podrá generar imágenes por sí mismo. Además, también será capaz de manejar audio.
Uno de los propósitos principales de esta capacidad de visión es permitir que los agentes autónomos lean páginas web y transcriban contenido de imágenes y videos. Algunos de los datos con los que entrenan son datos conjuntos (LaTeX/texto renderizados), capturas de pantalla de páginas web, videos de YouTube: marcos de muestra y ejecutan Whisper para obtener transcripciones.
Lo interesante de toda esta sobreoptimización para LLM es que el costo del modelo visual no es el mismo que el costo del modelo de texto. En el modelo de texto, como describimos en nuestro artículo "Amazon Cloud Crisis", el costo es muy bajo. Mientras que en el modelo de visión, el IO para la carga de datos es unas 150 veces mayor. Cada token tiene 600 bytes, no 4 para texto. Se está investigando mucho sobre la compresión de imágenes.
Esto es muy importante para los proveedores de hardware que están optimizando su hardware en función de los casos de uso y las proporciones de LLM en los próximos 2 o 3 años. Pueden encontrarse en un mundo donde cada modelo tiene poderosas capacidades visuales y de audio. Pueden encontrar que su esquema es desadaptativo. En general, es seguro que las arquitecturas evolucionarán a una etapa más allá de los actuales modelos densos y/o MoE simplificados basados en texto.