Tabla de contenido
Comprensión personal del proceso de formación de SRCNN
2. Preguntas frecuentes sobre el experimento y algunas interpretaciones
1. Uso de la función DataLoader en torch.utils.data.dataloader
2. ¿La razón y el método de conversión del espacio de color de la imagen SRCNN?
3. La diferencia entre model.parameters() y model.state_dict()
4. ¿Cómo usar la función .item()?
5. ¿Pasos finales del proceso de prueba?
6. El uso y definición de argparse
7. El uso de unsqueeze y squeeze
1. Uso sin apretar: agregue una dimensión entre el índice de dimensión original i de la matriz
2. Uso de compresión: Exprime la dimensión cuyo número de función es 1 en los datos del tensor
8. Comprensión de Python si __name__ == '__main__'.
9. ¿Pasos de conjuntos de datos personalizados?
3. Interpretación de la parte del Código
prepare.py (haga conjuntos de datos de capacitación y verificación personalizados en formato h5)
train.py (entrena el modelo SRCNN para obtener los parámetros óptimos)
utils.py (caja de herramientas)
4. Visualización de resultados experimentales
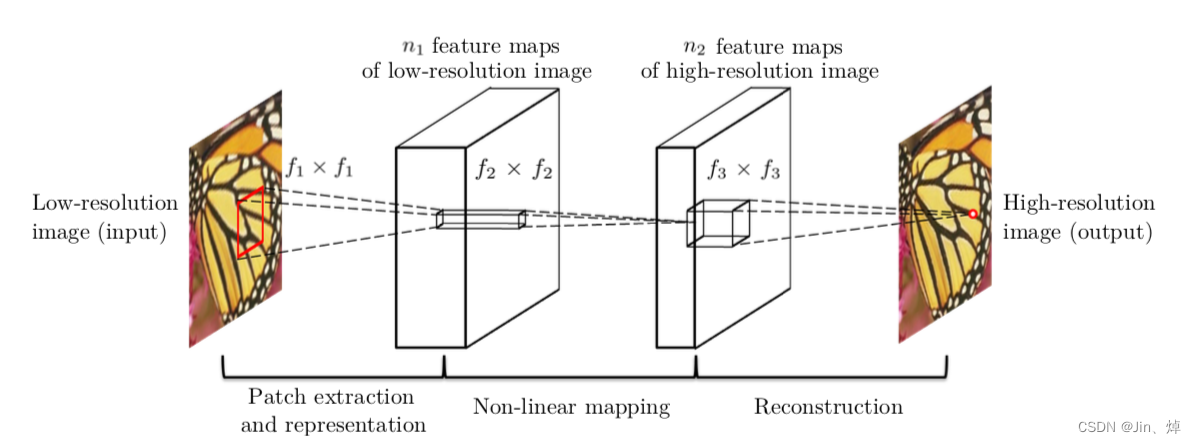
1. Introducción a SRCNN
La superresolución es el proceso de ampliar imágenes de baja resolución (LR, baja resolución) a alta resolución (HR, alta resolución).
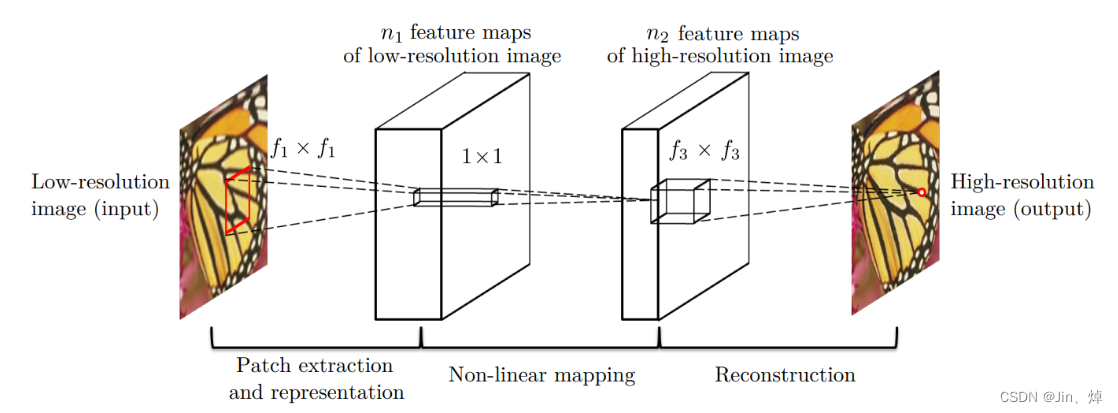
Capa de extracción de características de la imagen: extraiga las características de la imagen Y a través de CNN y guárdelas en el vector. Use una capa de CNN y ReLU para convertir la imagen Y en una pila de vectores, es decir, un mapa de características.
![]()
Capa de mapeo no lineal: realice aún más el mapeo no lineal en las características extraídas, aumente la profundidad de la red y aumente la complejidad de la red.
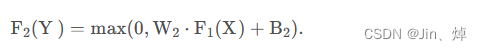
Capa de reconstrucción: Combina los parches obtenidos previamente para producir la imagen final de alta resolución.
![]()
Procedimiento experimental
- Ingrese la imagen LR X, después de la interpolación bicúbica, se amplía al tamaño objetivo (como ampliado a 2 veces, 3 veces, 4 veces) y se obtiene Y, que es la imagen de baja resolución (Imagen de baja resolución)
- Ajuste de mapas no lineales a través de redes convolucionales de tres capas
- Resultado de la imagen HR de salida F (Y)
anotación:
- Y: La imagen obtenida al preprocesar la imagen de entrada (interpolación bicúbica), todavía consideramos a Y como una imagen de baja resolución, pero su tamaño es mayor que la imagen de entrada.
- F (Y): la imagen de salida final de la red, nuestro objetivo es aprender esta función F (⋅) optimizando la pérdida entre F (Y) y Ground-Truth.
- X: Imagen de alta resolución, es decir, Ground-Truth, que tiene el mismo tamaño que Y.
- Las imágenes se convierten al espacio de color YCbCr, aunque la red solo utiliza el canal de luminancia (Y). La salida de la red luego combina los canales CbCr interpolados para generar la imagen de color final. Elegimos este paso porque no nos interesan los cambios de color (información almacenada en el canal CbCr) sino solo su brillo (canal Y); la razón fundamental es que la visión humana es más sensible a los cambios de brillo que a las diferencias de color.
proceso de entrenamiento
Referencia de la imagen: Súper resolución: SRCNN_Super-resolución srcnn_Da Laohu's Blog Tonight-CSDN Blog
1. Reducir la resolución:

2. Corta la imagen, hay repetición entre los parches.

3. Entrene el modelo y aprenda la relación de mapeo de baja resolución → a → alta resolución


función de pérdida
Número de pérdida: MES (error cuadrático medio), una razón importante para elegir MSE como función de pérdida es que el formato de MSE es muy similar a nuestro índice de evaluación de distorsión de imagen PSNR
F(Y;θ) : la imagen de súper resolución obtenida X : la imagen original de alta resolución

Función de activación: Relu
PSRN: Peak Signal-to-Noise Ratio, que es un estándar objetivo para evaluar imágenes, tiene limitaciones y generalmente se usa para un proyecto de ingeniería entre la señal máxima y el ruido de fondo.
Comparación de fórmulas MSE y PSNR:
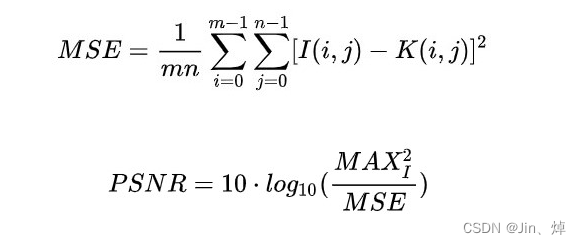

El MSE aquí es el error cuadrático medio entre la imagen original (habla) y la imagen procesada (habla).
SSIM (otro parámetro para medir resultados)

Comprensión personal del proceso de formación de SRCNN
1. Construya el conjunto de entrenamiento, que contiene imágenes de baja resolución e imágenes de alta resolución. Las imágenes deben convertirse de imágenes RGB a imágenes YCBCR, y las imágenes se dividen en pequeños bloques para el almacenamiento. Las imágenes de alta resolución están antes reduce la resolución de la imagen, la imagen de baja resolución se reduce y la imagen aumenta la resolución.
2. Construya el modelo SRCNN, que es un modelo de convolución de tres capas, y establezca MES como la función de pérdida, porque MES es similar al cálculo del índice objetivo PSNR de la imagen de evaluación, es decir, para maximizar PSNR. Establezca el resto de los parámetros comunes de la red neuronal (tasa de aprendizaje, tamaño de lote, número de épocas, etc.).
3. Entrenar el modelo SRCNN, es decir, aprender la relación de mapeo de imágenes de baja resolución a imágenes de alta resolución. De acuerdo con diferentes valores de PSRN de diferentes parámetros, se conservan los parámetros del modelo correspondientes al valor máximo de PSNR.
2. Preguntas frecuentes sobre el experimento y algunas interpretaciones
1. Uso de la función DataLoader en torch.utils.data.dataloader
Al consultar los datos y mirar los ejemplos de código, el significado de los parámetros de la función DataLoader() es el siguiente:
1.dataset (Conjunto de datos): decidir dónde o dónde leer los datos;
2. batch_size (python:int, opcional): el tamaño del conjunto de datos procesado cada vez (el valor predeterminado es 1)
3. barajar (bool, opcional): si cada época está desordenada (predeterminado: falso);
4. num_workers (python:int, opcional): cuántos procesos leen datos (el valor predeterminado es 0);
5. pin_memory (bool, opcional): si es True, los datos se colocarán en la GPU (el valor predeterminado es falso)
6. drop_last (bool, opcional): cuando el número de muestras no se puede dividir por el tamaño del lote, descartar el último lote de datos (predeterminado: falso)
Por ejemplo: shuffle(bool, opcional) indica que el tipo de parámetro entrante es de tipo bool, y el parámetro shuffle es un parámetro opcional.
2. ¿La razón y el método de conversión del espacio de color de la imagen SRCNN?
La razón de elegir YCbCr: Porque lo que nos interesa no es el cambio de color (información almacenada en el canal CbCr) sino únicamente su brillo (canal Y); la razón fundamental es que la visión humana es más sensible a los cambios de brillo que a la diferencia de color .
La diferencia entre Y solamente y YCbCr:
①Solo Y: el método de línea de base, que es una red de un solo canal (c=1), solo se entrena en el brillo. Los canales Cb y Cr se extienden por interpolación bicúbica. ②YCbCr: Entrenamiento en tres canales del espacio YCbCr
Hay tres funciones de conversión en el código:
1. convert_rgb_to_y(img)
2. convert_rgb_to_ycbcr(img)
3. convert_ycbcr_to_rgb(img)
YCBCR: Y representa el brillo y la concentración del color, también llamada escala de grises. (Las imágenes en escala de grises también se pueden obtener extrayendo el componente Y a través de la conversión RGB YCBCR)
Cb: Indica el desplazamiento de la densidad azul del color, es decir, la diferencia entre la parte azul de la señal de entrada RGB y el valor de brillo de la señal RGB.
Cr: Indica el desplazamiento de la densidad roja del color, es decir, la diferencia entre la parte roja de la señal de entrada RGB y el valor de brillo de la señal RGB.
Fórmula de conversión:
1. RGB a YCBCR
Y=0,257*R+0,564*G+0,098*B+16
Cb=-0.148*R-0.291*G+0.439*B+12
Cr=0,439*R-0,368*G-0,071*B+128
2. YCBCR a RGB
R=1,164*(Y-16)+1,596*(Cr-128)
G=1,164*(Y-16)-0,392*(Cb-128)-0,813*(Cr-128)
B=1,164*(Y-16)+2,017*(Cb-128)
3. La diferencia entre model.parameters() y model.state_dict()
Diferencia: el método model.parameters() devuelve un generador generador, cada elemento es un parámetro desde el principio hasta el final, los parámetros no tienen un nombre de clave correspondiente, es un generador compuesto de parámetros puros y state_dict es un diccionario que contiene Se ha introducido una clave.
4. ¿Cómo usar la función .item()?
t.item() convierte una variable de Tensor en un escalar de Python (int float, etc.), donde t es una variable de Tensor, que solo puede ser un escalar, y el dtype convertido es consistente con el dtype de Tensor.
5. ¿Pasos finales del proceso de prueba?
1. Establecer parámetros (pesos entrenados, imágenes, aumento)
2. Cree el modelo SRCNN y asigne parámetros óptimos al modelo
3. Interpolar la imagen para obtener una imagen de baja resolución.
4. Entrene en el espacio de color y de las imágenes de baja resolución Lr
5. Calcule el valor PSNR y la salida
6. Convertir a imagen y salida
6. El uso y definición de argparse
El módulo argparse es el módulo incorporado de Python para opciones de elementos de comando y análisis de parámetros. El módulo argparse facilita la escritura de interfaces de línea de comandos fáciles de usar y ayuda a los programadores a definir parámetros para modelos.
definir pasos
- Importar el paquete argparse -- importar argparse
- Cree un objeto de analizador de línea de comando: cree un objeto ArgumentParser ()
- Agregue argumentos de línea de comandos al analizador: llame al método add_argument() para agregar argumentos
- Análisis de argumentos de la línea de comando: utilice parse_args() para analizar los argumentos agregados
7. Uso de unsqueeze y squeeze
1. Uso sin apretar: agregue una dimensión entre el índice de dimensión original i de la matriz
x = t.Tensor([[3, 4], [2, 7], [6, 9]]) # 3*2
y1 = x.unsqueeze(0) # 1*3*2
print(y1.size())
y2 = x.unsqueeze(1) # 3*1*2
print(y2.size())
y3 = x.unsqueeze(2) # 3*2*1
print(y3.size())
2. Uso de compresión: Exprime la dimensión cuyo número de función es 1 en los datos del tensor
x = t.ones(1,1,2,3,1)
y1 = x.squeeze(0) # 1*2*3*1
print(y1.size())
y2 = x.squeeze(1) # 1*2*3*1
print(y2.size())
y3 = x.squeeze() # 2*3
print(y3.size())
8. Comprensión de Python si __name__ == '__main__'.
Este fragmento de código solo se ejecuta cuando se ejecuta el script y no se ejecutará cuando se importe a otros scripts. Cuando el archivo se ejecuta directamente como script, el valor de __name__ en este momento es: main, y cuando se referenciado por otros archivos, es el propio archivo.
9. ¿Pasos de conjuntos de datos personalizados?
El conjunto de datos de entrenamiento se puede generar manualmente y la ampliación se establece a escala. Teniendo en cuenta que los datos originales pueden no ser divisibles por escala, es necesario volver a planificar el tamaño de la imagen, establecer el tamaño de la imagen a través de la interpolación bicúbica y luego guárdelo como un archivo h5 para el entrenamiento.La generación del conjunto de datos se divide en tres pasos:
- Lea el directorio donde se encuentra la carpeta de imágenes
- Convierta todas las imágenes a imágenes RGB
- Cambie el tamaño de la imagen original a través de la interpolación bicúbica para que pueda ser divisible por escala y utilícela como datos de imagen de alta resolución HR
- Comprimir HR por interpolación bicúbica por tiempos de escala, como los datos originales de imágenes de baja resolución
- La imagen de baja resolución se amplía en tiempos de escala a través de la interpolación bicúbica, que es igual a la dimensión de la imagen HR, y se utiliza como datos de imagen de baja resolución LR
- Convierta imágenes de baja resolución e imágenes de alta resolución en imágenes YCBCR y entrene el canal y.
- Extraiga parches de imágenes de alta y baja resolución para entrenar la relación de mapeo entre imágenes de baja resolución e imágenes de alta resolución.
Finalmente, los datos de entrenamiento se pueden dividir en bloques y empaquetar a través de h5py.De manera similar, el archivo del conjunto de prueba se puede generar de acuerdo con las operaciones anteriores.
3. Interpretación de la parte del Código
modelo.py
from torch import nn
class SRCNN(nn.Module): #搭建SRCNN 3层卷积模型,Conve2d(输入层数,输出层数,卷积核大小,步长,填充层)
def __init__(self, num_channels=1):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 64, kernel_size=9, padding=9 // 2)
self.conv2 = nn.Conv2d(64, 32, kernel_size=5, padding=5 // 2)
self.conv3 = nn.Conv2d(32, num_channels, kernel_size=5, padding=5 // 2)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.conv3(x)
return xdataset.py
formato de archivo h5py

import h5py # 一个h5py文件是 “dataset” 和 “group” 二合一的容器。
import numpy as np
from torch.utils.data import Dataset
'''为这些数据创建一个读取类,以便torch中的DataLoader调用,而DataLoader中的内容则是Dataset,
所以新建的读取类需要继承Dataset,并实现其__getitem__和__len__这两个成员方法。
'''
class TrainDataset(Dataset): # 构建训练数据集,通过np.expand_dims将h5文件中的lr(低分辨率图像)和hr(高分辨率图像)组合为训练集
def __init__(self, h5_file):
super(TrainDataset, self).__init__()
self.h5_file = h5_file
def __getitem__(self, idx): #通过np.expand_dims方法得到组合的新数据
with h5py.File(self.h5_file, 'r') as f:
return np.expand_dims(f['lr'][idx] / 255., 0), np.expand_dims(f['hr'][idx] / 255., 0)
def __len__(self): #得到数据大小
with h5py.File(self.h5_file, 'r') as f:
return len(f['lr'])
# 与TrainDataset类似
class EvalDataset(Dataset): # 构建测试数据集,通过np.expand_dims将h5文件中的lr(低分辨率图像)和hr(高分辨率图像)组合为验证集
def __init__(self, h5_file):
super(EvalDataset, self).__init__()
self.h5_file = h5_file
def __getitem__(self, idx):
with h5py.File(self.h5_file, 'r') as f:
return np.expand_dims(f['lr'][str(idx)][:, :] / 255., 0), np.expand_dims(f['hr'][str(idx)][:, :] / 255., 0)
def __len__(self):
with h5py.File(self.h5_file, 'r') as f:
return len(f['lr'])prepare.py (haga conjuntos de datos de capacitación y verificación personalizados en formato h5)
import argparse
import glob
import h5py
import numpy as np
import PIL.Image as pil_image
from utils import convert_rgb_to_y
'''
训练数据集可手动生成,设放大倍数为scale,考虑到原始数据未必会被scale整除,所以要重新规划一下图像尺寸,所以训练数据集的生成分为三步:
1.将原始图像通过双三次插值重设尺寸,使之可被scale整除,作为高分辨图像数据HR
2.将HR通过双三次插值压缩scale倍,为低分辨图像的原始数据
3.将低分辨图像通过双三次插值放大scale倍,与HR图像维度相等,作为低分辨图像数据LR
最后,可通过h5py将训练数据分块并打包
'''
# 生成训练集
def train(args):
"""
def是python的关键字,用来定义函数。这里通过def定义名为train的函数,函数的参数为args,args这个参数通过外部命令行传入output
的路径,通过h5py.File()方法的w模式--创建文件自己自写,已经存在的文件会被覆盖,文件的路径是通过args.output_path来传入
"""
h5_file = h5py.File(args.output_path, 'w')
# #用于存储低分辨率和高分辨率的patch
lr_patches = []
hr_patches = []
for image_path in sorted(glob.glob('{}/*'.format(args.images_dir))):
'''
这部分代码的目的就是搜索指定文件夹下的文件并排序,for这一句包含了几个知识点:
1.{}.format():-->格式化输出函数,从args.images_dir路径中格式化输出路径
2.glob.glob():-->返回所有匹配的文件路径列表,将1得到的路径中的所有文件返回
3.sorted():-->排序,将2得到的所有文件按照某种顺序返回,,默认是升序
4.for x in *: -->循换输出
'''
#将照片转换为RGB通道
hr = pil_image.open(image_path).convert('RGB')
'''
1. *.open(): 是PIL图像库的函数,用来从image_path中加载图像
2. *.convert(): 是PIL图像库的函数, 用来转换图像的模式
'''
#取放大倍数的倍数, width, height为可被scale整除的训练数据尺寸
hr_width = (hr.width // args.scale) * args.scale
hr_height = (hr.height // args.scale) * args.scale
#图像大小调整,得到高分辨率图像Hr
hr = hr.resize((hr_width, hr_height), resample=pil_image.BICUBIC)
#低分辨率图像缩小
lr = hr.resize((hr_width // args.scale, hr_height // args.scale), resample=pil_image.BICUBIC)
#低分辨率图像放大,得到低分辨率图像Lr
lr = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
#转换为浮点并取ycrcb中的y通道
hr = np.array(hr).astype(np.float32)
lr = np.array(lr).astype(np.float32)
hr = convert_rgb_to_y(hr)
lr = convert_rgb_to_y(lr)
'''
np.array():将列表list或元组tuple转换为ndarray数组
astype():转换数组的数据类型
convert_rgb_to_y():将图像从RGB格式转换为Y通道格式的图片
假设原始输入图像为(321,481,3)-->依次为高,宽,通道数
1.先把图像转为可放缩的scale大小的图片,之后hr的图像尺寸为(320,480,3)
2.对hr图像进行双三次上采样放大操作
3.将hr//scale进行双三次上采样放大操作之后×scale得到lr
4.接着进行通道数转换和类型转换
'''
# 将数据分割
for i in range(0, lr.shape[0] - args.patch_size + 1, args.stride):
for j in range(0, lr.shape[1] - args.patch_size + 1, args.stride):
'''
图像的shape是宽度、高度和通道数,shape[0]是指图像的高度=320;shape[1]是图像的宽度=480; shape[2]是指图像的通道数
'''
lr_patches.append(lr[i:i + args.patch_size, j:j + args.patch_size])
hr_patches.append(hr[i:i + args.patch_size, j:j + args.patch_size])
lr_patches = np.array(lr_patches)
hr_patches = np.array(hr_patches)
#创建数据集,把得到的数据转化为数组类型
h5_file.create_dataset('lr', data=lr_patches)
h5_file.create_dataset('hr', data=hr_patches)
h5_file.close()
#下同,生成测试集
def eval(args):
h5_file = h5py.File(args.output_path, 'w')
lr_group = h5_file.create_group('lr')
hr_group = h5_file.create_group('hr')
for i, image_path in enumerate(sorted(glob.glob('{}/*'.format(args.images_dir)))):
hr = pil_image.open(image_path).convert('RGB')
hr_width = (hr.width // args.scale) * args.scale
hr_height = (hr.height // args.scale) * args.scale
hr = hr.resize((hr_width, hr_height), resample=pil_image.BICUBIC)
lr = hr.resize((hr_width // args.scale, hr_height // args.scale), resample=pil_image.BICUBIC)
lr = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
hr = np.array(hr).astype(np.float32)
lr = np.array(lr).astype(np.float32)
hr = convert_rgb_to_y(hr)
lr = convert_rgb_to_y(lr)
lr_group.create_dataset(str(i), data=lr)
hr_group.create_dataset(str(i), data=hr)
h5_file.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--images-dir', type=str, required=True)
parser.add_argument('--output-path', type=str, required=True)
parser.add_argument('--patch-size', type=int, default=32)
parser.add_argument('--stride', type=int, default=14)
parser.add_argument('--scale', type=int, default=4)
parser.add_argument('--eval', action='store_true') #store_flase就是存储一个bool值true,也就是说在该参数在被激活时它会输出store存储的值true。
args = parser.parse_args()
#决定使用哪个函数来生成h5文件,因为有俩个不同的函数train和eval生成对应的h5文件。
if not args.eval:
train(args)
else:
eval(args)
train.py (entrena el modelo SRCNN para obtener los parámetros óptimos)
import argparse
import os
import copy
import numpy as np
from torch import Tensor
import torch
from torch import nn
import torch.optim as optim
# gpu加速库
import torch.backends.cudnn as cudnn
from torch.utils.data.dataloader import DataLoader
# 进度条
from tqdm import tqdm
from models import SRCNN
from datasets import TrainDataset, EvalDataset
from utils import AverageMeter, calc_psnr
##需要修改的参数
# epoch.pth
# losslog
# psnrlog
# best.pth
'''
python train.py --train-file "path_to_train_file" \
--eval-file "path_to_eval_file" \
--outputs-dir "path_to_outputs_file" \
--scale 3 \
--lr 1e-4 \
--batch-size 16 \
--num-epochs 400 \
--num-workers 0 \
--seed 123
'''
if __name__ == '__main__':
# 初始参数设定
parser = argparse.ArgumentParser() # argparse是python用于解析命令行参数和选项的标准模块
parser.add_argument('--train-file', type=str, required=True,) # 训练 h5文件目录
parser.add_argument('--eval-file', type=str, required=True) # 测试 h5文件目录
parser.add_argument('--outputs-dir', type=str, required=True) #模型 .pth保存目录
parser.add_argument('--scale', type=int, default=3) # 放大倍数
parser.add_argument('--lr', type=float, default=1e-4) #学习率
parser.add_argument('--batch-size', type=int, default=16) # 一次处理的图片大小
parser.add_argument('--num-workers', type=int, default=0) # 线程数
parser.add_argument('--num-epochs', type=int, default=400) #训练次数
parser.add_argument('--seed', type=int, default=123) # 随机种子
args = parser.parse_args()
# 输出放入固定文件夹里
args.outputs_dir = os.path.join(args.outputs_dir, 'x{}'.format(args.scale))
# 没有该文件夹就新建一个文件夹
if not os.path.exists(args.outputs_dir):
os.makedirs(args.outputs_dir)
# benckmark模式,加速计算,但寻找最优配置,计算的前馈结果会有差异
cudnn.benchmark = True
# gpu或者cpu模式,取决于当前cpu是否可用
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 每次程序运行生成的随机数固定
torch.manual_seed(args.seed)
# 构建SRCNN模型,并且放到device上训练
model = SRCNN().to(device)
# 恢复训练,从之前结束的那个地方开始
# model.load_state_dict(torch.load('outputs/x3/epoch_173.pth'))
# 设置损失函数为MSE
criterion = nn.MSELoss()
# 优化函数Adam,lr代表学习率,
optimizer = optim.Adam([
{'params': model.conv1.parameters()},
{'params': model.conv2.parameters()},
{'params': model.conv3.parameters(), 'lr': args.lr * 0.1}
], lr=args.lr)
# 预处理训练集
train_dataset = TrainDataset(args.train_file)
train_dataloader = DataLoader(
# 数据
dataset=train_dataset,
# 分块
batch_size=args.batch_size,
# 数据集数据洗牌,打乱后取batch
shuffle=True,
# 工作进程,像是虚拟存储器中的页表机制
num_workers=args.num_workers,
# 锁页内存,不换出内存,生成的Tensor数据是属于内存中的锁页内存区
pin_memory=True,
# 不取余,丢弃不足batchSize大小的图像
drop_last=True)
# 预处理验证集
eval_dataset = EvalDataset(args.eval_file)
eval_dataloader = DataLoader(dataset=eval_dataset, batch_size=1)
# 拷贝权重
best_weights = copy.deepcopy(model.state_dict())
best_epoch = 0
best_psnr = 0.0
# 画图用
lossLog = []
psnrLog = []
# 恢复训练
# for epoch in range(args.num_epochs):
for epoch in range(1, args.num_epochs + 1):
# for epoch in range(174, 400):
# 模型训练入口
model.train()
# 变量更新,计算epoch平均损失
epoch_losses = AverageMeter()
# 进度条,就是不要不足batchsize的部分
with tqdm(total=(len(train_dataset) - len(train_dataset) % args.batch_size)) as t:
# t.set_description('epoch:{}/{}'.format(epoch, args.num_epochs - 1))
t.set_description('epoch:{}/{}'.format(epoch, args.num_epochs))
# 每个batch计算一次
for data in train_dataloader:
# 对应datastes.py中的__getItem__,分别为lr,hr图像
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
# 送入模型训练
preds = model(inputs)
# 获得损失
loss = criterion(preds, labels)
# 显示损失值与长度
epoch_losses.update(loss.item(), len(inputs))
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 进度条更新
t.set_postfix(loss='{:.6f}'.format(epoch_losses.avg))
t.update(len(inputs))
# 记录lossLog 方面画图
lossLog.append(np.array(epoch_losses.avg))
# 可以在前面加上路径
np.savetxt("lossLog.txt", lossLog)
# 保存模型
torch.save(model.state_dict(), os.path.join(args.outputs_dir, 'epoch_{}.pth'.format(epoch)))
# 是否更新当前最好参数
model.eval()
epoch_psnr = AverageMeter()
for data in eval_dataloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
# 验证不用求导
with torch.no_grad():
preds = model(inputs).clamp(0.0, 1.0)
epoch_psnr.update(calc_psnr(preds, labels), len(inputs))
print('eval psnr: {:.2f}'.format(epoch_psnr.avg))
# 记录psnr
psnrLog.append(Tensor.cpu(epoch_psnr.avg))
np.savetxt('psnrLog.txt', psnrLog)
# 找到更好的权重参数,更新
if epoch_psnr.avg > best_psnr:
best_epoch = epoch
best_psnr = epoch_psnr.avg
best_weights = copy.deepcopy(model.state_dict())
print('best epoch: {}, psnr: {:.2f}'.format(best_epoch, best_psnr))
torch.save(best_weights, os.path.join(args.outputs_dir, 'best.pth'))
print('best epoch: {}, psnr: {:.2f}'.format(best_epoch, best_psnr))
torch.save(best_weights, os.path.join(args.outputs_dir, 'best.pth'))
utils.py (caja de herramientas)
import torch
import numpy as np
"""
只操作y通道
因为我们感兴趣的不是颜色变化(存储在 CbCr 通道中的信息)而只是其亮度(Y 通道);
根本原因在于相较于色差,人类视觉对亮度变化更为敏感。
"""
def convert_rgb_to_y(img):
if type(img) == np.ndarray:
return 16. + (64.738 * img[:, :, 0] + 129.057 * img[:, :, 1] + 25.064 * img[:, :, 2]) / 256.
elif type(img) == torch.Tensor:
if len(img.shape) == 4:
img = img.squeeze(0)
return 16. + (64.738 * img[0, :, :] + 129.057 * img[1, :, :] + 25.064 * img[2, :, :]) / 256.
else:
raise Exception('Unknown Type', type(img))
"""
RGB转YCBCR
Y=0.257*R+0.564*G+0.098*B+16
Cb=-0.148*R-0.291*G+0.439*B+128
Cr=0.439*R-0.368*G-0.071*B+128
"""
def convert_rgb_to_ycbcr(img):
if type(img) == np.ndarray:
y = 16. + (64.738 * img[:, :, 0] + 129.057 * img[:, :, 1] + 25.064 * img[:, :, 2]) / 256.
cb = 128. + (-37.945 * img[:, :, 0] - 74.494 * img[:, :, 1] + 112.439 * img[:, :, 2]) / 256.
cr = 128. + (112.439 * img[:, :, 0] - 94.154 * img[:, :, 1] - 18.285 * img[:, :, 2]) / 256.
return np.array([y, cb, cr]).transpose([1, 2, 0])
elif type(img) == torch.Tensor:
if len(img.shape) == 4:
img = img.squeeze(0)
y = 16. + (64.738 * img[0, :, :] + 129.057 * img[1, :, :] + 25.064 * img[2, :, :]) / 256.
cb = 128. + (-37.945 * img[0, :, :] - 74.494 * img[1, :, :] + 112.439 * img[2, :, :]) / 256.
cr = 128. + (112.439 * img[0, :, :] - 94.154 * img[1, :, :] - 18.285 * img[2, :, :]) / 256.
return torch.cat([y, cb, cr], 0).permute(1, 2, 0)
else:
raise Exception('Unknown Type', type(img))
"""
YCBCR转RGB
R=1.164*(Y-16)+1.596*(Cr-128)
G=1.164*(Y-16)-0.392*(Cb-128)-0.813*(Cr-128)
B=1.164*(Y-16)+2.017*(Cb-128)
"""
def convert_ycbcr_to_rgb(img):
if type(img) == np.ndarray:
r = 298.082 * img[:, :, 0] / 256. + 408.583 * img[:, :, 2] / 256. - 222.921
g = 298.082 * img[:, :, 0] / 256. - 100.291 * img[:, :, 1] / 256. - 208.120 * img[:, :, 2] / 256. + 135.576
b = 298.082 * img[:, :, 0] / 256. + 516.412 * img[:, :, 1] / 256. - 276.836
return np.array([r, g, b]).transpose([1, 2, 0])
elif type(img) == torch.Tensor:
if len(img.shape) == 4:
img = img.squeeze(0)
r = 298.082 * img[0, :, :] / 256. + 408.583 * img[2, :, :] / 256. - 222.921
g = 298.082 * img[0, :, :] / 256. - 100.291 * img[1, :, :] / 256. - 208.120 * img[2, :, :] / 256. + 135.576
b = 298.082 * img[0, :, :] / 256. + 516.412 * img[1, :, :] / 256. - 276.836
return torch.cat([r, g, b], 0).permute(1, 2, 0)
else:
raise Exception('Unknown Type', type(img))
# PSNR 计算
def calc_psnr(img1, img2):
return 10. * torch.log10(1. / torch.mean((img1 - img2) ** 2))
# 计算 平均数,求和,长度
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
prueba.py
import argparse
import torch
import torch.backends.cudnn as cudnn
import numpy as np
import PIL.Image as pil_image
from models import SRCNN
from utils import convert_rgb_to_ycbcr, convert_ycbcr_to_rgb, calc_psnr
if __name__ == '__main__':
# 设置权重参数目录,处理图像目录,放大倍数
parser = argparse.ArgumentParser()
parser.add_argument('--weights-file', default='outputs/x3/best.pth', type=str)
parser.add_argument('--image-file', default='img/butterfly_GT.bmp', type=str)
parser.add_argument('--scale', type=int, default=3)
args = parser.parse_args()
# Benchmark模式会提升计算速度
cudnn.benchmark = True
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = SRCNN().to(device) # 新建一个模型
state_dict = model.state_dict() # 通过 model.state_dict()得到模型有哪些 parameters and persistent buffers
# torch.load('tensors.pth', map_location=lambda storage, loc: storage) 使用函数将所有张量加载到CPU(适用在GPU训练的模型在CPU上加载)
for n, p in torch.load(args.weights_file, map_location=lambda storage, loc: storage).items(): # 载入最好的模型参数
if n in state_dict.keys():
state_dict[n].copy_(p)
else:
raise KeyError(n)
model.eval() # 切换为测试模式 ,取消dropout
image = pil_image.open(args.image_file).convert('RGB') # 将图片转为RGB类型
# 经过一个插值操作,首先将原始图片重设尺寸,使之可以被放大倍数scale整除
# 得到低分辨率图像Lr,即三次插值后的图像,同时保存输出
image_width = (image.width // args.scale) * args.scale
image_height = (image.height // args.scale) * args.scale
image = image.resize((image_width, image_height), resample=pil_image.BICUBIC)
image = image.resize((image.width // args.scale, image.height // args.scale), resample=pil_image.BICUBIC)
image = image.resize((image.width * args.scale, image.height * args.scale), resample=pil_image.BICUBIC)
image.save(args.image_file.replace('.', '_bicubic_x{}.'.format(args.scale)))
# 将图像转化为数组类型,同时图像转为ycbcr类型
image = np.array(image).astype(np.float32)
ycbcr = convert_rgb_to_ycbcr(image)
# 得到 ycbcr中的 y 通道
y = ycbcr[..., 0]
y /= 255. # 归一化处理
y = torch.from_numpy(y).to(device) #把数组转换成张量,且二者共享内存,对张量进行修改比如重新赋值,那么原始数组也会相应发生改变,并且将参数放到device上
y = y.unsqueeze(0).unsqueeze(0) # 增加两个维度
# 令reqires_grad自动设为False,关闭自动求导
# clamp将inputs归一化为0到1区间
with torch.no_grad():
preds = model(y).clamp(0.0, 1.0)
psnr = calc_psnr(y, preds) # 计算y通道的psnr值
print('PSNR: {:.2f}'.format(psnr)) # 格式化输出PSNR值
# 1.mul函数类似矩阵.*,即每个元素×255
# 2. *.cpu().numpy() 将数据的处理设备从其他设备(如gpu拿到cpu上),不会改变变量类型,转换后仍然是Tensor变量,同时将Tensor转化为ndarray
# 3. *.squeeze(0).squeeze(0)数据的维度进行压缩
preds = preds.mul(255.0).cpu().numpy().squeeze(0).squeeze(0) #得到的是经过模型处理,取值在[0,255]的y通道图像
# 将img的数据格式由(channels,imagesize,imagesize)转化为(imagesize,imagesize,channels),进行格式的转换后方可进行显示。
output = np.array([preds, ycbcr[..., 1], ycbcr[..., 2]]).transpose([1, 2, 0])
output = np.clip(convert_ycbcr_to_rgb(output), 0.0, 255.0).astype(np.uint8) # 将图像格式从ycbcr转为rgb,限制取值范围[0,255],同时矩阵元素类型为uint8类型
output = pil_image.fromarray(output) # array转换成image,即将矩阵转为图像
output.save(args.image_file.replace('.', '_srcnn_x{}.'.format(args.scale))) # 对图像进行保存
4. Visualización de resultados experimentales



original bicúbico_x3 SRCNN_x3
SRCNN:PSNR: 27,61



original bicúbico_x3 SRCNN_x3
SRCNN:PSNR: 29.17
Portal de dirección del proyecto GitHub: SRCNN_Pytorch