Mejora de la función de búsqueda de código binario basada en DNN con verificación de equivalencia de bajo costo [TSE 2023]
Huaijin Wang , Pingchuan Ma , Yuanyuan Yuan , Zhibo Liu , Shuai Wang Departamento de Informática e Ingeniería, HKUST, Clear Water Bay, Kowloon, Hong Kong
Qiyi Tang , Sen Nie y Shi Wu Tencent Security Keen Lab
La función de búsqueda de código binario es la base fundamental de varias aplicaciones de ingeniería de software y seguridad, incluida la clasificación de muestras maliciosas, la detección de códigos clonados, la auditoría de vulnerabilidades, etc. Identificar funciones de ensamblaje lógicamente similares sigue siendo un desafío. información del programa, como gráficos de flujo de control y gráficos de flujo de datos extraídos por técnicas de análisis de programas o redes neuronales profundas.Sin embargo, las técnicas basadas en DNN capturan vocabulario de código binario, estructura de control o información de nivel de flujo de datos para el aprendizaje de representación, que generalmente son demasiado Áspero, no puede representar con precisión las funciones del programa. Además, puede exhibir poca robustez en varias configuraciones desafiantes, como la optimización del compilador y la ofuscación. Este documento propone un método para mejorar la búsqueda de funciones de código binario basado en dnn. Una solución general para la clasificación top-k candidatos en . La idea clave es idear una verificación de equivalencia completa y de bajo costo que exponga rápidamente las desviaciones funcionales entre la función objetivo y sus funciones de coincidencia top-k. lista k, y las funciones que pasan la verificación se pueden revisar para progresar en las funciones candidatas top-k de manera intencional. Los autores diseñan una verificación de equivalencia práctica y eficiente, denominada BinUSE, ejecución simbólica con restricciones insuficientes
ejecución simbólica, USE). USE es una variante de la ejecución simbólica que mejora la disponibilidad al iniciar la ejecución simbólica directamente desde el punto de entrada de la función y relajar las restricciones sobre los parámetros de la función. Escalabilidad. Elimina la carga causada por la explosión de rutas y las restricciones de sobrecarga. BinUSE tiene como objetivo proporcionar verificación de equivalencia a nivel de función de ensamblaje, mejorando la búsqueda de código binario basada en dnn al reducir los falsos positivos a un costo más bajo.La evaluación muestra que BinUSE puede mejorar universal y efectivamente cuatro búsquedas de código binario basadas en dnn de última generación herramientas frente a los desafíos planteados por diferentes compiladores, optimizaciones, ofuscaciones y arquitecturas.
Conclusión: BinUSE utiliza una ejecución simbólica sin restricciones para realizar verificaciones de equivalencia en funciones binarias buscadas por DNN, lo que reduce los falsos positivos para mejorar los resultados de la búsqueda.
introducción
Con el vigoroso desarrollo de la tecnología de aprendizaje automático y su amplia aplicación en tareas posteriores como la incrustación de software [6], [7], la mayoría de las herramientas de búsqueda de código binario contemporáneas tienen como objetivo entrenar un modelo de aprendizaje automático para capturar la similitud del código binario [8], [ 9], [10], [11] En particular, los avances recientes en redes neuronales profundas (DNN) y el aprendizaje de representaciones han hecho posible entrenar modelos DNN para aprender representaciones de código óptimas que pueden distinguir funciones de ensamblaje similares [12] , [13], [14], [15], [16], [17]. Para aprender representaciones de código, los modelos DNN se entrenan usando vocabulario (ligero), estructuras de control o características de nivel de flujo de datos. Tales representaciones, aunque fáciles extraer, puede no preservar la semántica del programa en gran medida. Las características ligeras generalmente no son resistentes a desafíos como la optimización del compilador o la ofuscación, lo que hace que el código ensamblador semánticamente similar se vea bastante diferente. Por lo tanto, el modelo DNN puede exhibir una menor discriminabilidad y menos robustez, lo que lleva a una gran cantidad de falsos positivos en los k principales candidatos que recupera.Este documento tiene como objetivo utilizar principios
efectivos y métodos eficientes para mejorar la búsqueda de funciones de código binario.Dada la función objetivo ft f_tFty la biblioteca de funciones RP, utilizando verificaciones de equivalencia de bajo costo para identificar rápidamente ft f_t en RPFtLas funciones semánticamente desviadas se eliminan de las funciones candidatas de clasificación top-k recuperadas. Por lo tanto, se puede reconsiderar si incluir las funciones que pasan la inspección en las funciones candidatas de top-k recuperadas. Para herramientas de búsqueda de funciones binarias basadas en dnn. los resultados de la ponderación se muestran en la Tabla 1.
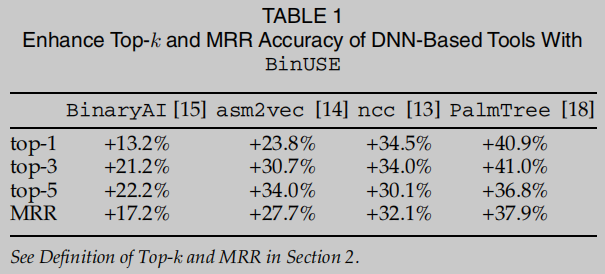
Este trabajo proporciona mejoras efectivas a cuatro herramientas SOTA DNN, a pesar de que estas herramientas utilizan diferentes modelos de redes neuronales y métodos de aprendizaje.Para diseñar un método de prueba de equivalencia de función de ensamblaje práctico y de bajo costo, este documento adopta técnicas de resolución de restricciones y ejecución simbólica sin restricciones. [19] para construir y verificar la relación de entrada-salida de las funciones de ensamblaje. En comparación con la ejecución simbólica estándar, USE tiene como objetivo realizar un razonamiento simbólico flexible y rápido directamente desde el punto de entrada de la función, omitiendo los prefijos de ruta caros a las funciones de destino. Optimizado el estándar esquema de uso BinUSE como una utilidad, especialmente para verificar la equivalencia de funciones de ensamblaje BinUSE inicia un recorrido USE desde el punto de entrada de la función, recorriendo cada ruta hasta llegar a la primera El punto de llamada de función externa representa un nodo crítico y rico en información en el CFG. Luego, BinUSE usa la fórmula simbólica ingresada por el punto de llamada externo para formar restricciones simbólicas en cada ruta y recopila restricciones de símbolo coincidentes para hacer coincidir dos funciones.
Contribuciones
(1) A nivel conceptual, se propone un nuevo enfoque para mejorar la función de búsqueda de código binario basada en dnn con baja precisión.Este artículo no diseña una nueva dnn (en principio, es difícil capturar la semántica con precisión), pero diseña una Una verificación de equivalencia de bajo costo para marcar y eliminar funciones de ensamblaje que se desvían semánticamente de la función objetivo
(2) A nivel técnico, se propone un método de verificación de equivalencia para reducir aún más su costo mediante la optimización del esquema de uso estándar. está diseñado específicamente para funciones de ensamblaje, teniendo en cuenta varios desafíos técnicos y oportunidades de optimización, como recopilar restricciones de símbolos en sitios de llamadas externos accesibles por puntos de entrada de funciones para reducir la complejidad (3) Resultados experimentales Se muestra que la prueba de equivalencia diseñada es general
y eficaz, y puede mejorar la herramienta de búsqueda de función binaria basada en dnn a un costo menor.Bajo varias condiciones desafiantes, incluida la coincidencia de función de equivalencia general y la búsqueda CVE, la prueba de equivalencia muestra un rendimiento excelente
conocimiento preliminar
Formulación y Métricas
El trabajo de búsqueda de funciones conscientes de la semántica existente recibe la función de ensamblaje de destino ft f_tFty una biblioteca de funciones RP RPRP , el buscador obtendrá las k funciones con mayor similitud semántica comoft f_tFtEl resultado del reconocimiento es Top-K. El índice para medir la precisión de top-K se calcula mediante la siguiente fórmula:
1 N × ∑ i = 1 npk ( fi ) \frac{1}{N} \times \sum_{ i=1 }^n p_k\left(f_i\right)norte1×yo = 1∑npagk( fyo)
donde N es el número total de funciones en el programa. Simplemente comprenda el significado de esta fórmula y coloque de forma iterativa el binarioB en 1 Bin_1B i n1La función fi f_i enFyoComo función objetivo, consultar con B en 2 Bin_2B i n2El conjunto de funciones compuesto por todas las funciones en RP RPRP , deja que coincida correctamentecon fi f_iFyoLa función de es fi ′ f_i'Fi′′, 当fi ′ f_i 'Fi′′pk ( fi ) = 1 p_k(f_i) = 1 en los k principales candidatospagk( fyo)=1 , de lo contrario es 0.
Otro indicador de uso común se llama puntaje de rango recíproco medio (MMR)
MRR = 1 ∣ Q ∣ ∑ i = 1 ∣ Q ∣ 1 rank i \mathrm{MRR}=\frac {1}{| Q|} \sum_{i=1}^{|Q|} \frac{1}{\operatorname{rango}_i}MRR=∣ Q ∣1yo = 1∑∣ Q ∣rangoyo1
donde ∣ Q ∣ |Q|∣ Q ∣ es el número total de consultas,ranki rank_ir un kyoes el número de secuencia del resultado correcto en los k principales candidatos en una consulta, por ejemplo, el resultado correcto ocupa el cuarto lugar en los k principales, luego ranki = 4 rank_i = 4r un kyo=4 , cuanto mayor sea el índice MMR, mejor será el efecto.
Comprobación de equivalencia
Además del popular aprendizaje de representación basado en DNN, otra dirección de investigación es realizar verificaciones de equivalencia de código, usando relaciones de entrada-salida del programa obtenidas mediante ejecución simbólica. Dada una fórmula simbólica que representa las relaciones de entrada-salida del código binario, luego use la resolución de restricciones. El compilador verifica la equivalencia de fórmulas simbólicas. La verificación de equivalencia es resistente a configuraciones desafiantes como optimizaciones y ofuscaciones del compilador, ya que estas configuraciones no deberían cambiar las relaciones de entrada y salida del programa. Un ejemplo

Los dos fragmentos de código anteriores pueden ser equivalentes a las siguientes dos declaraciones, luego la verificación de equivalencia puede verificar a = m ∧ p ≠ sa=m \wedge p \neq sa=metro∧pag=Si la restricción se cumple en el dominio de entrada, si todas las entradas no satisfacen esta condición de restricción, entonces se dice que los dos fragmentos de código son estrictamente equivalentes.
LimitacionesLa técnica propuesta proporciona una prueba estricta de la equivalencia del programa. Sin embargo, la ejecución simbólica y la resolución de restricciones son menos escalables debido a la explosión de rutas, el razonamiento sobre restricciones complejas y los desafíos específicos del dominio del análisis binario.Hasta ahora, los métodos basados en comprobaciones de equivalencia se han utilizado principalmente para comparaciones de seguimiento de ejecución o bloques básicos.Clasificación binariaDos errores estándar para la comprobación de
equivalencia: falso positivo (FP) y falso negativo (FN), el primero es que las funciones de diferentes funciones se consideran equivalentes, y el segundo es que las funciones que son equivalentes se consideran no equivalentes. Aunque las verificaciones de equivalencia no se pueden usar directamente para calcular top-k precisión, pero las verificaciones de equivalencia habilitadas por USE se pueden usar para eliminar falsas alarmas de los modelos DNN.
Ejecución simbólica con restricciones insuficientes
Se propone la ejecución simbólica sin restricciones para realizar la inspección de fragmentos de código arbitrarios, reduciendo la complejidad de la ejecución simbólica en principio y sistema. Para ilustrar las diferencias técnicas de alto nivel entre SE y USE (en términos de cobertura de ruta), la Fig. 2a presenta una Analice el caso del programa de decodificación de mensajes e identifique un error en decoding_msg. La función principal usa receive_msg para recibir el mensaje codificado y ejecuta el proceso de decodificación en una declaración de bucle. Luego, el mensaje decodificado se pasa a la función decoding_msg, uno de los errores (etiquetados como error en la línea 15 en la Figura 2a) está oculto en la rama if. SE puede verse obstaculizado al analizar este caso simple debido al alto uso de recursos computacionales y las restricciones prolongadas. USE de una manera basada en principios Complejidad reducida. lograr errores, USE analiza directamente decoding_msg. La ruta resultante se muestra en la Figura 2c, para el mensaje decodificado msg 22 msg_{22}m s g22No se imponen restricciones complejas y se pueden introducir restricciones que son más fáciles de resolver El análisis más costoso de todo el programa se puede posponer hasta que se necesite.
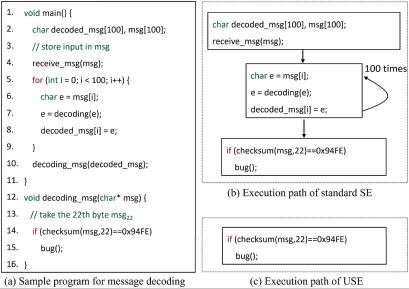
Limitaciones USO Al relajar las restricciones en la entrada, es posible encontrar soluciones satisfactorias que en realidad no son válidas cuando se considera el prefijo de la ruta desde el fragmento de código principal al de destino. los fragmentos fallan en la verificación de equivalencia En general, USE proporciona en principio una verificación de equivalencia completa, válida pero poco sólida, lo que posiblemente conduzca a falsos negativos que a menudo no son deseables.
motivación
Los métodos basados en DNN aprenden representaciones de código a partir de vocabularios, estructuras de control o hechos de flujo de datos.Un modelo DNN bien entrenado convierte muestras binarias de entrada (o instrucciones de máquina) en vectores numéricos, donde dos programas similares deberían tener una distancia de coseno más cercana. Los métodos aprenden principalmente características de control y datos "difusos" y livianos, que tienen una alta flexibilidad y escalabilidad, y facilitan el análisis de muestras binarias a gran escala. Sin embargo, el vocabulario aprendido, el control o las características de datos no necesariamente representan funciones con precisión. En resumen , creemos que las representaciones de incrustación aprendidas tienen principalmente los siguientes dos defectos: (1) Discriminación baja: los modelos DNN pueden tratar funciones lógicamente diferentes como similares. Por lo tanto, la Discriminación baja da como resultado más resultados de coincidencia de FP informados; (2) Robustez baja: Robustez se refiere a la resistencia bajo varias condiciones imperfectas cuando se ejecuta software o algoritmos. La baja robustez significa que el modelo DNN puede tener dificultades para hacer coincidir funciones que comparten la misma lógica pero son sintácticamente diferentes. En general, la baja robustez da como resultado informes de más resultados de coincidencia de FN.
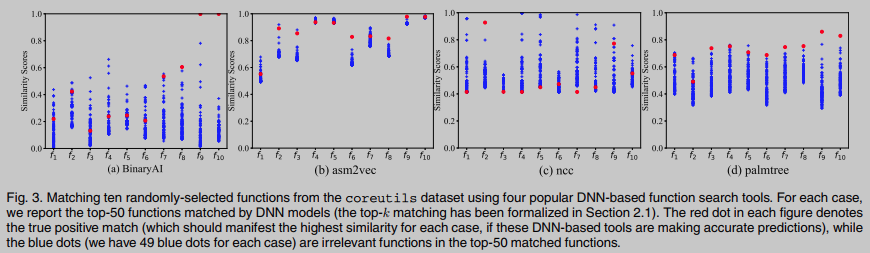
La Figura 3 muestra los resultados de la comparación, donde los puntos rojos representan las puntuaciones de similitud entre las funciones de ensamblaje compiladas a partir de la misma función fuente, y los puntos azules representan las puntuaciones de similitud entre otras funciones. Idealmente, las puntuaciones de similitud altas de los puntos rojos muestran la solidez del modelo DNN a la optimización del compilador: las funciones de ensamblaje compiladas desde la misma función fuente tienen la misma semántica a pesar de exhibir diferentes formas de sintaxis. Por lo tanto, cuando los puntos azules están bien separados, refleja la Distinguibilidad, lo que significa que las funciones de ensamblaje compiladas desde diferentes fuentes funciones muestran enormes diferencias en la vista del modelo DNN.
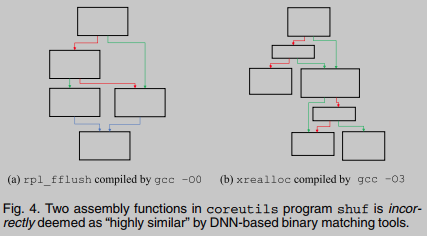
La figura 4 da una predicción incorrecta: dos funciones de ensamblaje compiladas a partir de diferentes códigos fuente se consideran erróneamente "similares". Esto puede deberse a la similitud del "gráfico de flujo de contexto" extraído por ncc, que no puede reflejar la desviación de la función.
Reseña del programa
La búsqueda moderna de código binario basada en DNN aprende la representación del código a partir de características de granularidad gruesa, que tiene baja discriminabilidad y baja robustez. Por lo tanto, generalmente las funciones de coincidencia top-k tienen puntajes de similitud similares, mientras que las coincidencias pueden no tener una similitud lo suficientemente alta debido a configuraciones desafiantes como optimizaciones del compilador u ofuscación. Nuestro estudio preliminar verificó manualmente los resultados de coincidencia top-k de estos modelos DNN, y sospechamos que una simple verificación de equivalencia puede reducir efectivamente los FP. Por ejemplo, podemos dar la función objetivo F t PieFtProporcione la misma entrada que las funciones en top-k y compare sus salidas para ver si son diferentes.
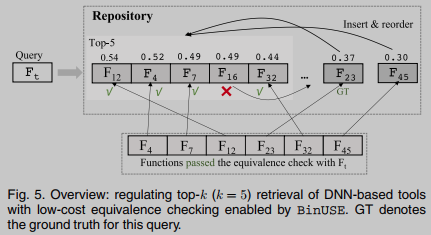
La Figura 5 muestra una descripción general de nuestro flujo de trabajo para aumentar la recuperación de top-k con herramientas basadas en DNN. En resumen, este estudio tiene como objetivo proporcionar una verificación de equivalencia de bajo costo que tenga sentido si dos funciones de ensamblaje son idénticas. Juicio verdadero/falso. De esta manera, podemos condicionar los resultados de búsqueda de herramientas basadas en dnn al reducir los FP en la recuperación de top-k.Por ejemplo, los muchos "puntos azules" en el ejemplo motivador (Fig. 3) se pueden resolver simplemente ejecutando con Ingrese dos funciones y compare la equivalencia de sus salidas para determinar que son diferentes de la función objetivo. Con esta verificación de equivalencia de bajo costo, estos FP se pueden eliminar fácilmente de la recuperación de top-k. Verifique que la equivalencia del software
sea costoso en general, por lo que como compensación práctica aceptamos verificaciones de equivalencia de precisión relativamente baja en el sentido de que dos funciones que pasan la verificación pueden ser diferentes. puede conducir a sinergias reales, lo que lleva a un servicio más rápido y una mayor precisión.
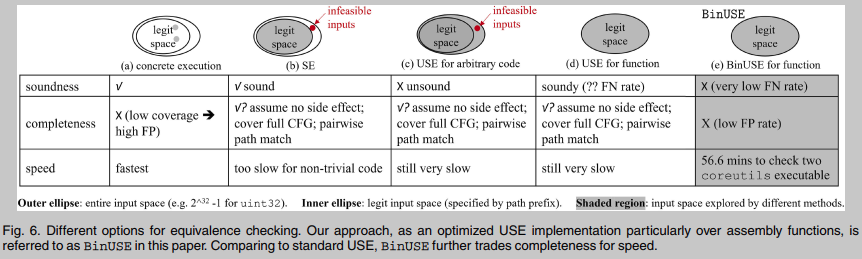
1 Las verificaciones de equivalencia específicas de la ejecución utilizan valores muestreados aleatoriamente como entrada y comparan las salidas de ejecuciones específicas. Este enfoque puede cubrir solo un pequeño espacio de entrada y, al tratar diferentes funciones como equivalentes, puede generar FP altos. El contexto de ejecución apropiado cuando se ejecuta directamente el código ensamblador es un problema muy desafiante.2
Las comprobaciones de equivalencia basadas en la ejecución simbólica modelan con precisión las restricciones de entrada y construyen comprobaciones de equivalencia dentro del espacio de entrada legal. Por lo tanto, debería ser preciso. Sin embargo, la escalabilidad de SE es baja, y su ejecución difícilmente puede alcanzar funciones ocultas en la cadena de llamadas.3
Comprobación de equivalencia basada en ejecución simbólica sin restricciones USE puede iniciar símbolos en puntos de programa arbitrarios Inferencia, mejora SE estándar al omitir prefijos de ruta costosos.Los prefijos de ruta se ignoran, lo que indica que USE no puede modelar las restricciones en la entrada del fragmento de código de destino. Por lo tanto, USE sobreexplora el espacio de entrada completo. USE puede realizar una verificación de equivalencia completa pero no confiable, porque puede encontrar contraejemplos fuera del espacio de entrada legal, violando así las restricciones de verificación de equivalencia.
4 Comprobación de equivalencia funcional basada en ejecución simbólica sin restricciones Aunque existen dificultades generales para resolver problemas no confiables, nuestras observaciones del software del mundo real llevaron a una suposición clave en este estudio: que las funciones en programas reales siguen el principio de programación defensiva [35], [36 ], [37], que establece que ninguna función en particular debe hacer suposiciones sobre su entrada (por ejemplo, el puntero pasado por la persona que llama puede no ser válido), es decir, la entrada de la función puede ser cualquier valor en el espacio de entrada. Esta suposición brinda una oportunidad única para proporcionar una verificación de equivalencia "confiable", especialmente para funciones, porque al analizar funciones en software real, el espacio de entrada legal debe alinearse con el espacio de entrada completo que puede explorar USE. es adoptado por conjuntos de programas populares (por ejemplo, coreutils, binutils) y los programadores de software complejo del mundo real como OpenSSL y Wireshark lo siguen.
5 La comprobación de equivalencia de función basada en BinUSE intercambia integridad por velocidad para optimizar aún más el método USE estándar. BinUSE calcula la fórmula simbólica ingresada por el sitio de llamada externo para formar restricciones simbólicas para cada ruta. Para hacer coincidir dos funciones, BinUSE explora el signo de coincidencia restricciones recopiladas para cada ruta en . BinUSE no está completo. Sin embargo, según los resultados empíricos, la tasa promedio de FN es muy baja. Además, BinUSE puede realizar comprobaciones de bajo costo en varias configuraciones desafiantes (por ejemplo, arquitectura cruzada). dos ejecutables coreutils se pueden realizar en 56,6 minutos de CPU (25 segundos por par de funciones en promedio), incluidas todas las tareas de resolución de restricciones y ejecución simbólica.
Diseño de papelera
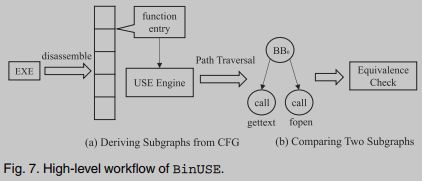
Dado un ejecutable de entrada, BinUSE primero realiza ingeniería inversa para recuperar la información de la función de ensamblaje. Luego, inicia USE ruta por ruta, comenzando desde el punto de entrada de cada función de ensamblaje, donde cada ruta atraviesa antes de llegar al primer punto de llamada externo. El resultado será generar un subgrafo en el que cada nodo de hoja corresponde a un sitio de llamada externo. Para comparar las dos funciones de ensamblaje, verificamos la equivalencia semántica de las entradas del sitio de llamada externo y las restricciones de ruta al iniciar la resolución de restricciones, para comparar sus subgrafos derivados (ver más abajo para detalles).
El análisis hipotético inverso es a nivel de función y no supone la presencia de símbolos de programa o información de depuración. Siempre que se identifiquen las funciones que se van a utilizar, los binarios despojados se pueden procesar sin dificultad. Nuestro análisis también es plataforma neutral; evaluamos tres configuraciones de arquitectura cruzada para arquitecturas x86 de 64 bits, x86 de 32 bits y ARM.También se evalúan diferentes compiladores (gcc y clang), niveles de optimización y métodos comunes de ofuscación.
Base
El enfoque de referencia es realizar un análisis estándar dentro del procedimiento a partir del punto de entrada de la función e iterar a través de cada ruta de ejecución. Los símbolos libres se crean cada vez que se realizan cargas a partir de datos desconocidos, incluidos los parámetros de la función, los datos globales y otras regiones de la memoria. Luego , recopilamos fórmulas simbólicas de salida para registros de CPU y memoria en los puntos de salida de la ruta para construir relaciones de entrada-salida.
Generación de subgráficos desde CFG
Teniendo en cuenta la dificultad de explorar completamente el CFG de una función, primero extraemos un subgrafo. El subgrafo debe conservar las características representativas del CFG correspondiente y reducir razonablemente la complejidad del análisis. BinUSE está diseñado para atravesar los puntos de entrada de cada función de ensamblaje Cada ejecución comienza la ruta. Cuando se encuentra un bucle, como una solución común, desenrollamos el bucle. Al analizar una ruta de ejecución, BinUSE inserta recursivamente cada sitio de llamada en la ruta. BinUSE Deténgase en un sitio de llamada externo. De acuerdo con el SE estándar, creamos símbolos para representar valores almacenados en registros o ubicaciones de memoria. Cuando nos encontramos con un sitio de llamada externo, recopilamos fórmulas simbólicas para la entrada de cada llamada de función, con Formas como la "salida" de esta ruta. También registramos restricciones de ruta como requisitos previos para llegar a sitios de llamadas externas.
Comparando dos subgrafos

La figura anterior muestra la comparación de dos funciones de ensamblaje ft, fs f_t, f_sFt,Fssubgrafo G t , G s G_t, G_sGRAMOt,GRAMOsproceso Compara iterativamente cada sitio de llamada hasta que encontramos que G t G_tGRAMOtSitios de llamadas externas en G s G_sGRAMOsPermutaciones equivalentes por pares de sitios de llamadas externas en . Tenga en cuenta que solo se permite G t G_tGRAMOtUn subconjunto de sitios de llamada en G s G_sGRAMOsOtro subconjunto de sitios de llamadas en . La razón es que las optimizaciones del compilador a veces pueden eliminar las llamadas a funciones de la biblioteca C, por lo que permitir que un subconjunto de llamadas a la biblioteca coincida con otro subconjunto de llamadas a la biblioteca no obstaculiza G t G_tGRAMOtcon G s G_s altamente optimizadoGRAMOsPor el contrario, si no se encuentra ninguna permutación, las dos funciones se consideran iguales. Aunque en G t G_tGRAMOty G s G_sGRAMOsLa comparación de sitios de llamadas en pares puede introducir muchas permutaciones, pero las comprobaciones de equivalencia de peso pesado solo se realizan cuando dos sitios de llamadas apuntan a la misma función externa.
Sustitución de llamadas a la biblioteca C Cuando algunos de los parámetros de entrada de una llamada a la biblioteca C son constantes, el compilador puede reemplazar esta llamada a la biblioteca C con otra. Además, el compilador puede ocasionalmente reemplazar una llamada a la biblioteca C común con una versión más segura. Por ejemplo, usando En __printf_chklugar printf, se detecta un desbordamiento de pila antes de calcular el resultado.
La coincidencia de sitios de llamada de biblioteca se considera un paso crítico en la verificación de equivalencia, para lo cual recopilamos manualmente las siguientes listas. BinUSE trata las llamadas de biblioteca en cada lista como idénticas. Por ejemplo, además de comparar dos sitios de llamada de printf, consideramos y es lo printf callsitemismo __printf_chk. Esta lista contiene todos los posibles reemplazos de la biblioteca C que se encuentran en nuestros casos de prueba, que incluyen suites de prueba Linux coreutilsy binutilsuna base de datos CVE, que incluye vulnerabilidades de software complejo como OpenSSL, Wireshark, bash y la función ffmpeg.

Calcule la puntuación de coincidencia cuantitativa asumiendo G t G_tGRAMOtHay n rutas en (cada ruta termina en un sitio de llamada externo), y se determinan p rutas cuyos sitios de llamada externos están en G s G_sGRAMOsUn sitio de llamada semánticamente equivalente en , que indica que la función del ensamblador ft f_tFty fs f_sFsSe calcula un puntaje de confianza considerado equivalente como p/n. Este puntaje de confianza se utilizará al calibrar los resultados del modelo DNN. Al analizar el ejecutable de coreutils, el 87.9 % de los casos tuvo un puntaje de confianza de 1.0, lo cual se muestra que en la mayoría de los casos, G f G_fGRAMOfTodos los caminos en G s G_sGRAMOsfósforo.
Comparación de dos sitios de llamada
Aunque la investigación anterior ha demostrado que IDA-Pro no tiene soporte suficiente para la recuperación de información de funciones [43], en la base de datos FLIRT de IDA-Pro [44], se ha mantenido bien la información de funciones de la biblioteca C estándar. Por lo tanto, usando IDA-Pro (versión 7.3) garantiza en gran medida un análisis confiable de sitios de llamadas externas. Sin embargo, si el ejecutable contiene algunas llamadas de biblioteca definidas por el usuario (o definidas por terceros), FLIRT no puede manejarlas. Restaurar dicha información necesita inferir la cantidad de parámetros de función; El último progreso de la recuperación de información del prototipo de función puede consultar [43], [45], [46] Dado un sitio de llamada que contiene N parámetros, de acuerdo con la convención de llamada en la arquitectura correspondiente Extrae N fórmulas simbólicas.
Permutación de parámetros de llamadas Para verificar dos sitios de llamadas, buscamos permutaciones de parámetros de funciones que coincidan por pares. En lugar de simplemente comparar el i-ésimo parámetro de los dos sitios de llamadas, adoptamos un diseño más conservador y comparamos las permutaciones coincidentes entre parámetros. Para ejemplo En la figura siguiente, filenamet filename_tnombre de archivo _ _ _tcan y nombres de archivo filename_snombre de archivo _ _ _sPartido, también puede ser con modos mode_smodo _ _ _s; modet mode_tmodo _ _ _tcan y nombres de archivo filename_snombre de archivo _ _ _sPartido, también puede ser con modos mode_smodo _ _ _sCoincidencia: este diseño hace que la verificación de equivalencia sea más conservadora, resistente a las optimizaciones del compilador y a posibles confusiones, pero puede introducir FP.

Además, funciones con diferente número de parámetro también pueden ser equivalentes, por ejemplo, gettextcuando dgettexteste último domainnamees un valor constante, los dos son equivalentes.

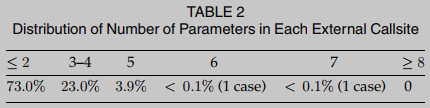
Para abordar este obstáculo, BinUSE está diseñado para ser resistente a una variedad de software del mundo real. Las observaciones empíricas muestran que este método de permutación no incurre en una sobrecarga excesiva, ya que casi todo el software de uso común tiene un número limitado de parámetros de función. Para justificar aún más esta decisión de diseño, presentamos la distribución del número de parámetros para todos los sitios de llamadas externas encontrados en los casos de prueba en la Tabla 2. A partir de estos resultados empíricos se puede observar que la mayoría de los sitios de llamadas externas tienen menos o igual a 2 parámetros, casi todos los sitios de llamadas externas tienen parámetros menores o iguales a 5. Por lo tanto, creemos que nuestra decisión de diseño de arreglo de parámetros no agrega un costo significativo, pero puede ayudar a que el diseño general de BinUSE sea más conservador y sólido.
Comprobación de equivalencia de parámetros Sea PC t , PC s PC_t, PC_sPC _t,PC _sSon las restricciones de ruta desde el punto de entrada de la función de ensamblaje de destino hasta el punto de llamada, Argti , A rgsj Arg^i_t, Arg^j_sA r gtyo,A r gsjson el i-ésimo parámetro de la función t y el j-ésimo parámetro de la función s, respectivamente.
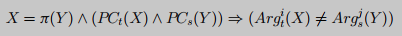
donde X = [ x 0 , x 1 , . . . , xm ] X = [x_0, x_1, ..., x_m]X=[ X0,X1,... ,Xm] representa la lista de símbolos utilizada por los parámetros y restricciones de ruta de la función t,Y = [ y 0 , y 1 , . . . , yn ] Y = [y_0, y_1, ..., y_n]Y=[ años0,y1,... ,yn] es la lista de símbolos utilizada por los parámetros y las restricciones de ruta de la función S. La siguiente figura es para comprobar si hay un tipoπ ( Y ) \pi(Y)π ( Y )在PC t ( X ) ∧ PC s ( Y ) PC_t(X) \cuña PC_s(Y)PC _t( X )∧PC _sHacer coincidir X bajo la condición de ( Y ) hace que las restricciones anteriores sean insatisfactorias. Si no existe tal arreglo, entoncesA rgti , A rgsj Arg^i_t, Arg^j_sA r gtyo,A r gsjser equivalente.

Este diseño hace que BinUSE sea más robusto y confiable (menos FN) incluso frente a arquitecturas cruzadas, compiladores cruzados, confusión, etc. Relación FN. Excepto Además de la permutación, en este paso, las constantes que representan las direcciones de memoria en la fórmula simbólica también se normalizan. Adoptamos un método directo para determinar las constantes que representan las direcciones de memoria. Primero, al ejecutar USE ruta por ruta, siempre que como la observación Una constante se usa para construir la dirección base del puntero de código, que marcamos como una dirección de memoria.En segundo lugar, hacemos una suposición compartida por muchos desensambladores estáticos avanzados [47], [48], [49], como que una constante se tratará como una dirección de memoria si apunta a una sección de datos o texto de un ejecutable en formato ELF.
Al verificar las restricciones anteriores, establecemos el tiempo de espera del solucionador usado Z3 [50] en N segundos. Si el SMT solver produce un unsat, o no puede encontrar una solución sat dentro de N segundos, los dos argumentos de la llamada a la función se consideran equivalentes. Para nuestra implementación actual, N se establece en 15 segundos. Establecer un tiempo de espera puede dar como resultado que los parámetros no sean iguales ( Sin embargo, establecer un tiempo de espera no introduce FN, lo que puede acelerar el análisis de muestras binarias grandes.
Mejoramiento
Si bien las estrategias transversales presentadas en esta sección pueden cubrir la mayoría de los casos prácticos, es posible que haya algunos casos extremos que obstaculicen nuestro análisis. En particular, es posible que no haya sitios de llamadas externas en la ruta de ejecución. En este caso, simplemente no salteamos esto. análisis de ruta y, en su lugar, recopile las restricciones de ruta PC desde el punto de entrada de la función hasta llegar a la instrucción de retorno (ret) al final de la ruta de ejecución. Sin embargo, si no se pueden construir condiciones de ruta mientras se recorre esta ruta, omita la comparación de esta ruta. En general, cada instrucción de retorno ret se tratará como un "sitio de llamada externo" especial sin parámetros. Para determinar si dos rutas sin sitios de llamada externos pueden coincidir, usamos las siguientes restricciones para verificar que estén relacionadas . t PC_tPC _ty PC PC_sPC _s.
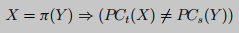
Esta optimización extenderá el subgrafo generado durante el recorrido simbólico con nodos adicionales que representan restricciones de ruta recopiladas de rutas de ejecución sin sitios de llamadas externas. Luego, para comparar con la función de ensamblaje ft f_tFty fs f_sFsLos dos subgrafos formados derivados G t G_tGRAMOty G s G_sGRAMOs, aún comparamos G t G_tGRAMOty G s G_sGRAMOsNodos que representan sitios de llamadas externas en , también comparación cruzada G t G_tGRAMOty G s G_sGRAMOsUn nodo en una ruta que no representa un sitio de llamada externo.
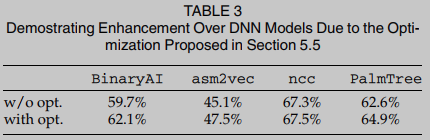
Las precisiones top-1 de las cuatro mejoras del modelo DNN evaluadas se comparan en la Tabla 3. Después de usar las optimizaciones propuestas en esta sección, BinUSE puede mejorar aún más la precisión de los modelos DNN en aproximadamente un 2,45 % en promedio.
IMPULSANDO LAS HERRAMIENTAS BASADAS EN DNN
En términos simples, cuando los modelos basados en BinUSE y DNN llegan a un consenso: fs ∈ P dnn ∧ fs ∈ P use f_s \in P_{dnn} \wedge f_s \in P_{use}Fs∈PAGd nn∧Fs∈PAGtú sabes, luego considere fs f_sFsSimilar a la función objetivo, el algoritmo 1 proporciona el algoritmo mejorado, P es el resultado final de la predicción y los elementos se componen de dos tuplas, la primera es la puntuación de confianza de BinUSE, la segunda es la puntuación de confianza de DNN, ordenadas según el BinUSE más alto Clasifique en orden descendente por peso Finalmente, devuelva los resultados de búsqueda de la función top-k.

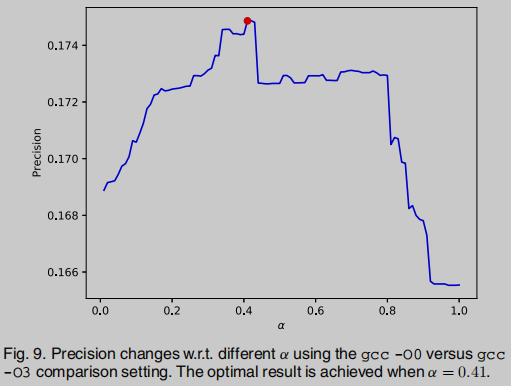
Donde el umbral α \alphaα se selecciona por experimento,α \alphaSi α es demasiado alto, creerá demasiado que BinUSE generará más FP. Si es demasiado bajo, el efecto de optimización será insuficiente. El mejor efecto es 0.41, así que elijaα = 0.41 \alpha = 0.41a=0.41

experimento
Implementación
Basándonos en el marco de análisis binario angr[51], implementamos BinUSE con alrededor de 5500 líneas de código Python. Al conectarse con el popular ecosistema angr y actualizar el código ensamblador al lenguaje intermedio VEX independiente de la plataforma, BinUSE puede manejar archivos ejecutables. Además , un amplio conjunto de herramientas de análisis (por ejemplo, ejecución simbólica) ya se proporciona en angr, por lo que ahorra el esfuerzo de construirlo desde cero.
Configuración de evaluación
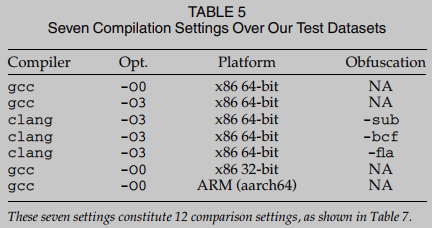
Conjuntos de datos y configuraciones de compilación BinUSE se evaluó utilizando el conjunto de datos coreutils de Linux. El conjunto de datos Coreutils contiene 106 programas. Los programas se compilaron con siete configuraciones diferentes (consulte la Tabla 5). Usamos gcc 7.5.0 y clang 4.0.1 para compilar los programas. Compilamos programas sin optimización (-O0) y optimización máxima (-O3). Para facilitar las comparaciones entre arquitecturas, compilamos binarios en tres arquitecturas diferentes, x86 de 32 bits, x86 de 64 bits y ARM. Un ejecutable coreutils compilado con la opción -O3 tiene un promedio de funciones 103.7. En otras palabras, dado un par de ejecutables coreutils, BinUSE necesita comparar funciones de ensamblaje 103.7 * 103.7. Además, BinUSE se compara utilizando la prueba de conjunto de datos binutils de Linux. El conjunto de datos Binutils contiene programas 112. Cada ejecutable binutils tiene un promedio de funciones 1765.0.
Utilizamos BinUSE para mejorar cuatro herramientas de búsqueda de función de código binario basadas en ADN de última generación: BinaryAI [15], asm2vec [14], PalmTree [18] y ncc [13].
Una nota sobre la selección de conjuntos de datos de entrenamiento. Usamos código binario simple para entrenar estos modelos DNN, y los modelos DNN entrenados se evalúan en función de su robustez en configuraciones de compilador cruzado, optimización cruzada, arquitectura cruzada y ofuscación.
Rendimiento de BinUSE
La Tabla 7 informa el rendimiento de BinUSE en un total de 12 configuraciones de comparación en el conjunto de datos de coreutils. La mayoría de las comparaciones requieren configuraciones desafiantes de compilador cruzado, optimización cruzada y arquitectura cruzada. Por ejemplo, la última comparación en la Tabla 7 muestra un Muy difícil configuración, es arquitectura cruzada (ARM vs x86 64bit), compilador cruzado (gcc vs clang), optimizado cruzado (-O0 vs -O3), también aplica ofuscación de aplanamiento de flujo de control (-fla), cambios extensos en el control estructura de flujo
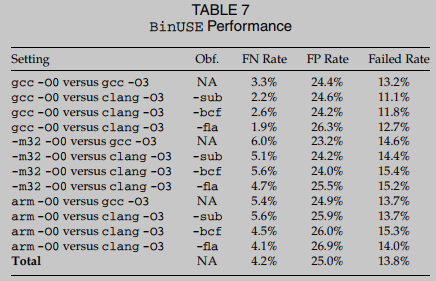
La tabla 7 muestra que BinUSE falla en la detección de más funciones compiladas con ofuscación de aplanamiento de flujo de control-fla. Esta ofuscación convierte CFG en declaración de cambio C y une bloques básicos con nodos de despacho. Los punteros de código a menudo se encuentran en el despachador. Se usan en nodos para dirigir transferencias de control. lo que conduce a una mayor probabilidad de falla al materializar punteros de código simbólico.
Tiempo de procesamiento
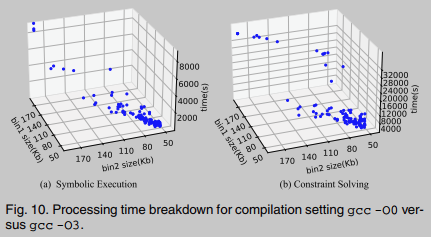
La Figura 10 muestra el desglose del tiempo de procesamiento para gcc -O0 en comparación con gcc -O3. En las Figuras 10a y 10b, respectivamente, informamos que el tiempo de procesamiento para ejecutar la ejecución simbólica y resolver restricciones es lineal en el tamaño de . Esto es intuitivo: grande Los ejecutables tienen más funciones, lo que prolonga el tiempo de ejecución simbólico de BinUSE. De manera similar, los ejecutables grandes pueden contener restricciones simbólicas más complejas, lo que prolonga la resolución de El tiempo requerido para las restricciones simbólicas. Sin embargo, se puede ver que la mayoría de las muestras de código binario pueden analizar ejecución en 2000 segundos de CPU y resolución de restricciones en 4000 segundos de CPU.
Comparación de modelos DNN
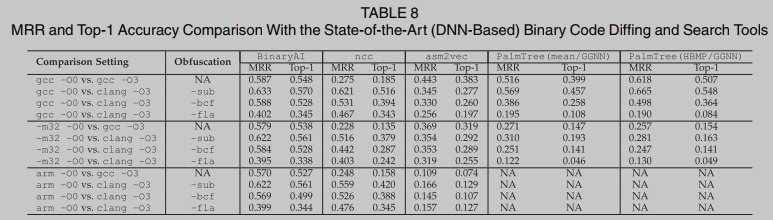
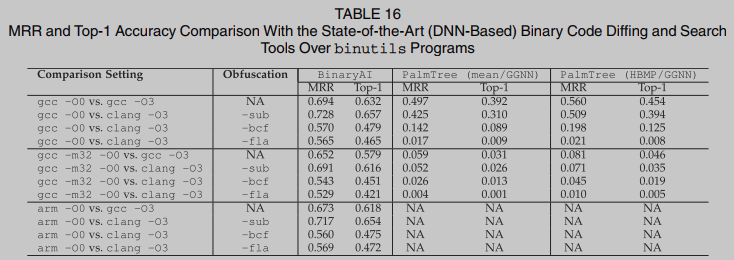
Se ejecutaron cuatro herramientas de búsqueda de funciones binarias basadas en dnn: BinaryAI, asm2vec, ncc y PalmTree en las 12 configuraciones de comparación. PalmTree no puede manejar ejecutables en la plataforma ARM; por lo tanto, omitimos los cálculos correspondientes. La Tabla 8 resume los resultados de rendimiento. BinaryAI supera Todos los modelos en todas las configuraciones diferentes. Aunque las configuraciones de arquitectura cruzada plantean desafíos importantes, BinaryAI parece ser más resistente a los cambios de arquitectura cruzada debido a su microaprendizaje en el código independiente de la plataforma. La ofuscación, especialmente el aplanamiento del flujo de control (-fla), principalmente y socava constantemente la precisión del top 1. Encontramos mucha ingeniería inversa al elevar el código binario a LLVM IR como entrada al error de ingeniería ncc. El refuerzo binario RetDec lanza una excepción al procesar ciertos binarios. En este caso, solo el top-1 de binarios procesados con éxito (los binarios compilados con clang -O3 tienen alrededor del 40% de los casos restantes). No pudimos recuperar la alta precisión informada en el documento de asm2vec: enfatizamos que tanto la ingeniería de software como las comunidades de seguridad han señalado problemas similares Nuestra evaluación muestra una precisión top-1 de asm2vec del 38,3%, aunque inferior a la precisión informada en su tasa de papel, pero es muy consistente con los resultados de estudios recientes [16], [68], [69].
Mejora del modelo DNN
Para medir la mejora de los métodos basados en DNN utilizando BinUSE, tratamos de responder dos preguntas: 1) RQ1: ¿Puede BinUSE mejorar diferentes herramientas de búsqueda de función de código binario basadas en DNN? y 2) RQ2: ¿Puede BinUSE mejorar BinaryAI en diferentes configuraciones? RQ2, nos enfocamos en BinaryAI porque superó significativamente a los otros tres modelos. Además, además de mejorar los métodos basados en dnn, también exploramos RQ3: ¿BinaryAI es lo suficientemente general como para mejorar las herramientas de diferenciación binaria convencional a nivel de estructura basadas en programas para obtener información? RQ3, probamos una popular herramienta de diferenciación binaria, FuncSimSearch[70], desarrollada y mantenida por Project Zero de Google.
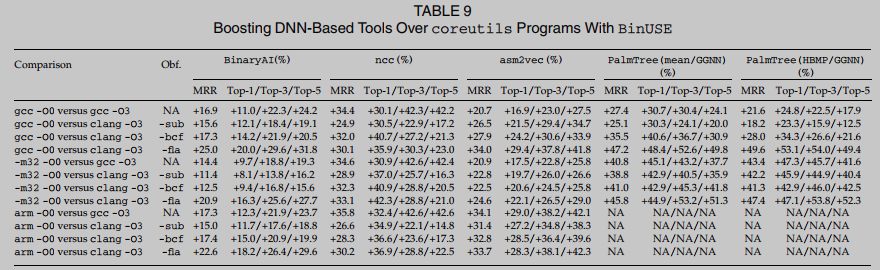
RQ1. La Tabla 9 presenta los resultados de la evaluación en diferentes configuraciones. Medimos consistentemente las mejoras principales 1, 3 principales y 5 principales. La Tabla 9 muestra que el uso de BinUSE puede mejorar significativamente todos los métodos basados en DNN. Los modelos DNN generalmente comienzan desde granulado, que no son resistentes a diversas configuraciones desafiantes y, por lo tanto, generan falsas alarmas muy altas. BinUSE tiene como objetivo abordar sus limitaciones clave de manera consistente.
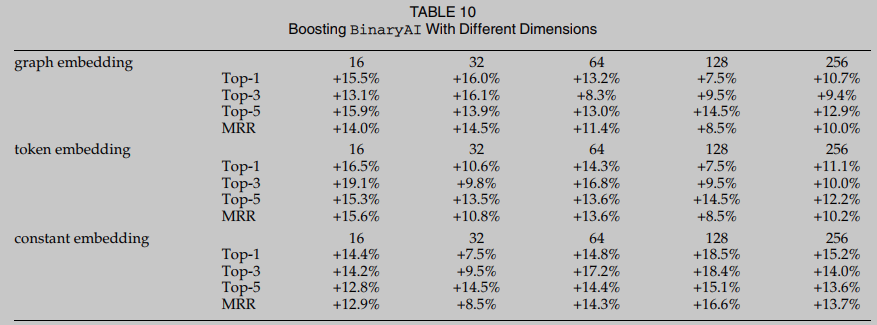
RQ2. Para responder a RQ2, investigamos tres hiperparámetros clave para el aprendizaje de representación relacionado con la incrustación de dimensiones vectoriales. En general, diferentes dimensiones afectan principalmente la precisión del modelo: las incrustaciones más largas pueden transmitir información sutil sobre los datos de entrada, las incrustaciones más pequeñas pueden no ser capaces de representar la semántica. bien. Sin embargo, los vectores más largos significan que el entrenamiento del modelo enfrenta más desafíos y puede destruir potencialmente la solidez del modelo. BinaryAI contiene tres dimensiones de incrustación hiperparámetros relacionados, respectivamente, dimensión de incrustación de token, dimensión de incrustación constante y dimensión de incrustación de gráficos. La Tabla 10 informa que para todos hiperparámetros, a pesar de las diferentes dimensiones de incrustación, BinUSE mejora constantemente la precisión. En general, esta evaluación revela que se realiza una observación intuitiva: a pesar de los cambios en la configuración del modelo, la verificación de equivalencia siempre puede resolver las falsas alarmas altas, otro aspecto importante que muestra la generalización de BinUSE.
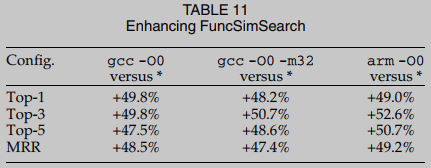
RQ3: Este estudio se centra principalmente en la búsqueda de función de código binario basada en DNN, porque los métodos basados en DNN exhiben una alta precisión y superan en gran medida a los algoritmos tradicionales basados en la estructura del programa, como el isomorfismo de gráficos [71] Sin embargo, es fácil ver que BinUSE no es limitado a mejorar los métodos basados en dnn. En principio, argumentamos que la diferenciación binaria basada en la estructura del programa a menudo produce predicciones de baja discriminabilidad y baja robustez. Nuestro argumento está empíricamente validado por una herramienta avanzada de diferenciación binaria, FuncSimSearch, que calcula las puntuaciones de Simhash en el flujo de control. gráficos para determinar de manera eficiente la distancia de las funciones de ensamblaje. Los resultados de la evaluación se muestran en la Tabla 11. En comparación con los métodos contemporáneos basados en dnn. En comparación con FuncSimSearch, los resultados de FuncSimSearch son mucho peores. Por lo tanto, BinUSE puede mejorar la precisión de todas las configuraciones de evaluación para en gran medida. La precisión relativamente baja de FuncSimSearch también se señala en el documento de asm2vec. En general,
las evaluaciones muestran consistentemente que BinUSE puede mejorar las altas falsas alarmas producidas por herramientas populares basadas en estructuras (DNN) de una manera general, eficiente y manera única Por lo tanto, recomendamos combinar la búsqueda de código binario con BinUSE para lograr efectos sinérgicos en el uso de producción.
Búsqueda de funciones vulnerables
Se inicia un estudio de caso aplicando BinUSE para extender la tarea de búsqueda de vulnerabilidades a un conjunto de datos de vulnerabilidad pública. Esta aplicación simula un escenario de uso de seguridad común: dada una función de ensamblaje f de un fragmento ejecutable sospechoso, buscamos en la base de datos de funciones D con vulnerabilidades conocidas, y determinar si f puede coincidir con alguna función en D. En este paso, usamos cuatro configuraciones de ofuscación -sub, -bcf, -fla y -hybrid, respectivamente, para convertir f en D a Los ejemplos se compilan en Dasm, a base de datos de funciones del ensamblador. Tenga en cuenta que la configuración híbrida (llamada -hybrid) combina los tres métodos de ofuscación durante la compilación. También habilitamos la optimización completa -O3 al compilar cada programa de ejemplo y función de destino. En resumen, dada una función de ensamblaje altamente optimizada (-O3) con una vulnerabilidad conocida, recuperamos su función coincidente de Dasm y verificamos si su función coincidente correcta con la misma vulnerabilidad existe entre los 1 candidatos principales en la función.
En este paso, medimos asm2vec, BinaryAI y dos versiones de PalmTree. Omitimos evaluar ncc porque descubrimos que el refuerzo binario que emplea falla en demasiados casos cuando se trata de este software complejo del mundo real. Informamos en la Tabla 12. , Los resultados de la evaluación para cada configuración se informan en 13, 14 y 15. asm2vec parece tener problemas con OpenSSL y Wireshark porque ambos programas son muy complejos Para las tres versiones de OpenSSL y Wireshark, asm2vec ocupa un lugar más bajo para la coincidencia real Mucho más Por ejemplo, asm2vec clasifica la vulnerabilidad Heartbleed en OpenSSL (ver) como una coincidencia real. Esto significa que un usuario puede necesitar comparar manualmente al menos 17 copias del programa en Dasm para confirmar la vulnerabilidad Heartbleed en una entrada sospechosa. Por el contrario , BinUSE puede hacer coincidir con éxito la entrada sospechosa con la vulnerabilidad Heartbleed top 1 en Dasm. Asm2vec también es mucho menos preciso al analizar otro notorio CVE ws-snmp. Descubrimos que la vulnerabilidad contiene un CFG grande, que puede dificultar la incrustación a nivel de gráfico de asm2vec Cálculo basado en caminata aleatoria En resumen, con la ayuda de BinUSE, asm2vec puede poner la función frágil real en el top-1.
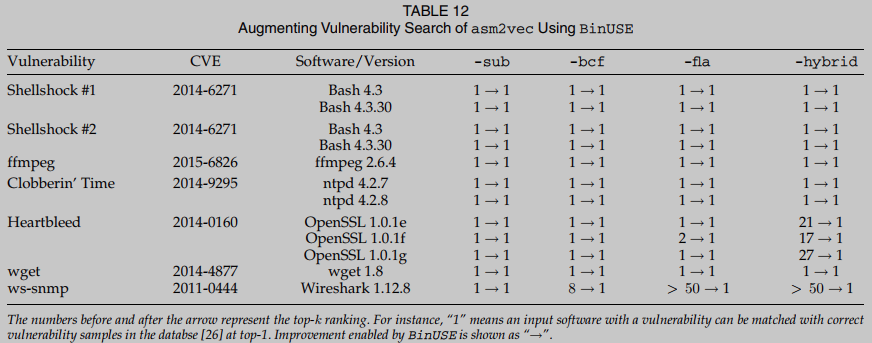
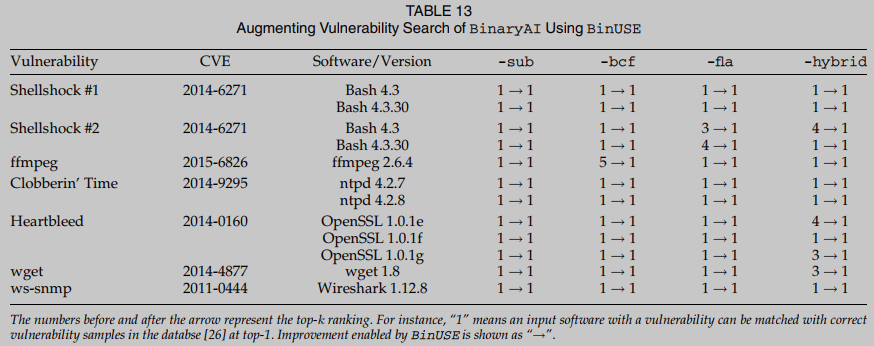

En resumen, las evaluaciones en esta sección revelan resultados muy alentadores cuando se usa BinUSE para analizar aplicaciones reales con fines de seguridad. Los cálculos en esta sección demuestran la efectividad de considerar información detallada del sitio de llamadas cuando se realiza la comparación de funciones.
Extensión de BinUSE
pies piesFtcon cada función f ∈ RP f \in RPF∈Comparar RP aún es costoso. En esta sección, investigaremos posibles extensiones de BinUSE; nuestro objetivo es reducir el costo comparando preferentemente las funciones top-k devueltas por el modelo DNN. Por ejemplo, k = 100, una vez que el modelo DNN Determinado con la función objetivoft f_tFtCombinando las 100 funciones principales, BinUSE compara estas 100 funciones de clasificación con ft f_tFtRealiza comparaciones, reordena y ajusta sus rankings. De esta forma, las comparaciones de BinUSE se reducen del tamaño de los RPs a solo 100, reduciendo el costo al analizar programas dual utils. Sin embargo, dado que BinUSE solo accede y reordena los rankings del modelo DNN. Para el primeras 100 funciones de ensamblaje, la precisión mejorada de top-k (donde k = 100) está limitada por la precisión de top 100 del modelo DNN. En otras palabras, si el modelo DNN de destino es menos preciso, incluso top-100, la posibilidad de mejora También muy pequeña.
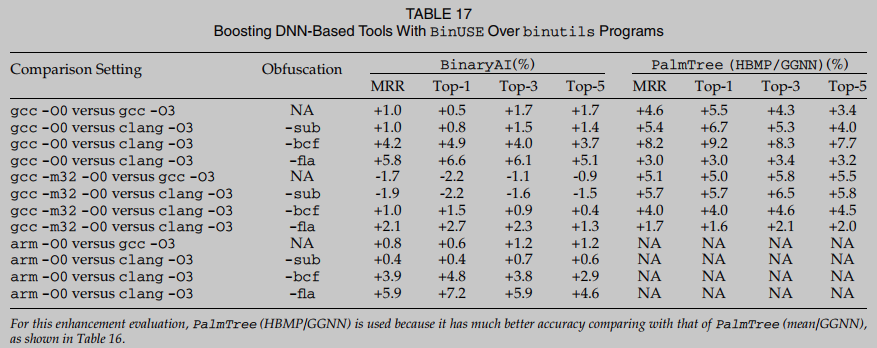
Las mejoras a BinaryAI y PalmTree se informan en la Tabla 17. En esta tabla, evaluamos 12 configuraciones de comparación. En comparación con BinaryAI, BinUSE mejora PalmTree en un grado mayor. Esto se debe principalmente al rendimiento de PalmTree en el caso de prueba de utilidades duales. La precisión de es relativamente bajo, lo que deja más oportunidades de mejora. Por otro lado, en comparación con la evaluación en el conjunto de datos coreutils, el efecto de mejora de BinUSE es bajo. Además de la dificultad general de analizar la función binutils, para esta evaluación de tiempo, BinUSE solo analiza las primeras 100 funciones devueltas por las herramientas basadas en dnn. Según nuestras observaciones, algunas coincidencias reales ni siquiera se encuentran dentro de las primeras 100 funciones. Para explorar más a fondo los grados más altos de mejora de la precisión, los usuarios pueden considerar aprovechar The top-150 o top-200 funciones devueltas por las herramientas de dnn.
Resumir
Referencias
[6] U. Alon, M. Zilberstein, O. Levy y E. Yahav, "Code2Vec: Aprendizaje de representaciones distribuidas de código", en Proc. Programa ACM. Lang., 2019, págs. 1–29.
[7] U. Alon, S. Brody, O. Levy y E. Yahav, "code2seq: Generación de secuencias a partir de representaciones estructuradas de código", 2018, arXiv:1808.01400.
[8] F. Zuo, X. Li, P. Young, L. Luo, Q. Zeng y Z. Zhang, "La traducción automática neuronal inspiró la comparación de similitud de código binario más allá de los pares de funciones", en Proc. Neto. Distribuir sist. Seguro Symp., 2019.
[9] S. Eschweiler, K. Yakdan y E. Gerhards-Padilla, "discovRE: identificación eficiente de errores en la arquitectura cruzada en código binario", en Netw. Distribuir sist. Seguro Síntoma, 2016.
[10] J. Gao, X. Yang, Y. Fu, Y. Jiang y J. Sun, "VulSeeker: un buscador de vulnerabilidades basado en el aprendizaje semántico para binarios multiplataforma", en Proc. 33° ACM/IEEE internacional. Conf. Software automatizado Ing., 2018, págs. 896–899.
[11] S. Luan, D. Yang, K. Sen y S. Chandra, "Aroma: recomendación de código a través de la búsqueda de código estructural", 2018. [En línea]. Disponible: http://arxiv.org/abs/1812.01158
[12] X. Xu, C. Liu, Q. Feng, H. Yin, L. Song y D. Song, “Neural network-based graph inbedding for cross -detección de similitud de código binario de plataforma”, en Proc. Conferencia ACM SIGSAC. computar común Secur., 2017, págs. 363–376.
[13] T. Ben-Nun, AS Jakobovits y T. Hoefler, "Comprensión del código neuronal: una representación aprendible de la semántica del código", en Proc. 32 Int. Conf. Información neuronal Proceso. Syst., 2018, págs. 3589–3601.
[14] SHH Ding, BCM Fung y P. Charland, "Asm2Vec: Aumento de la solidez de la representación estática para la búsqueda de clones binarios contra la ofuscación del código y la optimización del compilador", en Proc. Simposio IEEE Seguro Privacidad, 2019, págs. 472–489.
[15] Z. Yu, R. Cao, Q. Tang, S. Nie, J. Huang y S. Wu, "El orden importa: redes neuronales conscientes de la semántica para la detección de similitud de código binario", en Proc. Conferencia AAAI Artefacto Intel., 2020, págs. 1145–1152.
[16] Y. Duan, X. Li, J. Wang y H. Yin, "DEEPBINDIFF: aprendizaje de representaciones de código de todo el programa para diferenciación binaria", en Proc. 27 Anu. Neto. Distribuir sist. Seguro Symp., 2020.
[17] B. Liu et al., "diff: Detección de similitud de código binario de versión cruzada con DNN", en Proc. 33° IEEE/ACM Int. Conf. Software automatizado Ing., 2018, págs. 667–678.
[18] X. Li, Q. Yu y H. Yin, "PalmTree: aprendizaje de un modelo de lenguaje ensamblador para la incorporación de instrucciones", en Proc. Conferencia ACM SIGSAC. computar común Secur., 2021, pp. 3236–3251
[35] CAR Hoare, “¿Cómo se volvió tan confiable el software sin pruebas?”, en Proc. En t. Síntoma Métodos formales Eur., 1996, págs. 1–17.
[36] E. Gunnerson, “Programación defensiva”, en A Programmer's Introduction to C#, Nueva York, NY, EE. UU.: Apress, 2001. [37] M. Stueben, “Programación defensiva”, en Good Habits
for Great Coding, New York, NY, EE. UU.: Apress, 2018.
[43] T. Bao, J. Burket, M. Woo, R. Turner y D. Brumley, "ByteWeight: Aprender a reconocer funciones en código binario", en Proc. 23 USENIX Secur. Symp., 2014, págs. 845–860.
[44] Tecnología rápida de identificación y reconocimiento de bibliotecas, 2021. [En línea]. Disponible: https://www.hex-rays.com/products/ida/tech/flirt/
[45] ECR Shin, D. Song y R. Moazzezi, "Reconociendo funciones en binarios con redes neuronales", en Proc. 24ª Conferencia USENIX. Seguro Symp., 2015, págs. 611–626.
[46] Y. Lin y D. Gao, "Cuando la recuperación de la firma de la función se encuentra con la optimización del compilador", en Proc. Simposio IEEE Seguro Privacidad, 2021, págs. 36–52.
[51] Y. Shoshitaishvili et al., "SOK: (Estado de) el arte de la guerra: Técnicas ofensivas en análisis binario", en Proc. Simposio IEEE Seguro Privacidad, 2016, págs. 138–157.
[68] Y. Hu, H. Wang, Y. Zhang, B. Li y D. Gu, "Un enfoque híbrido basado en la semántica sobre la comparación de similitud de código binario", IEEE Trans. suave Ing., vol. 47, núm. 6, págs. 1241–1258, junio de 2021.
[69] J. Jiang et al., "Similitud de archivos binarios en niveles de optimización y ofuscación", en Proc. EUR. Síntoma Res. computar Secur., 2020, págs. 295–315.
[70] FunctionSimSearch, 2021. [En línea]. Disponible: https://github.com/googleprojectzero/functionsimsearch
[71] H. Flake, "Comparación estructural de objetos ejecutables", en Proc. En t. Evaluación de la vulnerabilidad del software malicioso de intrusiones de detección del taller de GI, 2004, págs. 161–174.
Perspectivas
Autores
(1) Mejorar el efecto de entrenamiento del modelo DNN a través de diferentes opciones de optimización y programas binarios confusos (similar al artículo sobre la liberación de energía (2
) El efecto de reproducción de ncc es mucho menor que el del artículo
(3) Granularidad fina debe tenerse en cuenta al realizar el emparejamiento de funciones Información del punto de llamada
(4) Los últimos avances en tecnología de inteligencia artificial explicable (XAI) han sido capaces de identificar los códigos más influyentes en la toma de decisiones del modelo DNN. fragmentos de código c1 y c2, que son los principales responsables del modelo DNN La decisión de hacer coincidir las funciones de ensamblaje f1 y f2. BinUSE se puede iniciar en el c1 y c2 marcados para verificar su equivalencia semántica. Los fragmentos de código influyentes pueden reducir el costo de inspección, pero el desafío es cómo distinguir los límites de los fragmentos de código influyentes y las restricciones de ruta para mantener los fragmentos de código.
Mine
(1) Para experimentos de trabajo de arquitectura única, se pueden abandonar las pruebas de arquitectura cruzada. Por ejemplo, palmtree solo realiza experimentos en x86
(2) Se pueden descartar ejemplos de fallas de actualización de retdec y solo se conservan muestras exitosas para experimentos
(3 ) ¿Usar el mecanismo de autoatención para identificar fragmentos de código de alto impacto para ajustar automáticamente los pesos computacionales para incrustaciones de código?