Tabla de contenido
2.CAB (Bloque de atención de canal)
6.SAM (Módulo de Atención Supervisada)
7.ORSNet (Subred de resolución original)
1. Introducción
Dirección en papel: https://arxiv.org/pdf/2102.02808.pdf
Dirección del código: http://github.com/swz30/MPRNet
Las tareas de restauración de imágenes requieren un equilibrio complejo entre los detalles espaciales y las características contextuales de alto nivel. Entonces, los autores diseñan un modelo de varias etapas que primero usa una arquitectura de codificador-decodificador para aprender características contextuales y luego las combina con una rama de alta resolución que conserva la información local.
Por ejemplo, quiero volver a pintar una imagen de una serpiente, el códec es responsable de extraer características contextuales de alto nivel, diciéndole al modelo que "pinte" escamas en la serpiente, no plumas u otras cosas; entonces la rama de alta resolución es responsable de refinar el patrón de escamas.
Hay muchos detalles en MPRNet, pero la principal innovación es "multietapas". El modelo tiene tres etapas. Las dos primeras etapas son subredes de códecs, que se utilizan para aprender características contextuales de campos receptivos más grandes. La última etapa es Ramas de alta resolución para construir las texturas deseadas en la imagen de salida final. El autor asigna tres tareas a los proyectos Deblurring, Denoising y Deraining. La columna vertebral de los tres proyectos es la misma, pero la escala de parámetros es diferente (Deblurring>Denoising>Deraining). Tomemos el Deblurring más grande como ejemplo para presentar.
2. Cómo usar
El proyecto MPRNet se divide en tres subproyectos: Deblurring, Denoising y Deraining. El autor no utiliza bibliotecas extrañas ni habilidades de programación avanzadas. Es muy adecuado para la investigación y el aprendizaje. El método de uso también es muy simple y las habilidades se pueden explicar en pocas palabras.
1. Razonamiento
(1) Descargue el modelo preentrenado: el modelo preentrenado existe en la carpeta pretrained_models de tres subproyectos, y la dirección de descarga está en el README.md de cada carpeta pretrained_models. Tiene que estar científicamente en línea. Pongo en el disco de red:
Enlace: https://pan.baidu.com/s/1sxfidMvlU_pIeO5zD1tKZg Código de extracción: faye
(2) Prepare la imagen de prueba: coloque la imagen degradada en el directorio samples/input/
(3) Ejecutar demo.py
# 执行Deblurring
python demo.py --task Deblurring
# 执行Denoising
python demo.py --task Denoising
# 执行Deraining
python demo.py --task Deraining(4) Los resultados se colocan en el directorio samples/output/.
2. Entrenamiento
(1) Descargue el conjunto de datos de acuerdo con la dirección en el archivo README.md en la carpeta Conjunto de datos.
(2) Compruebe si es necesario modificar training.yml, principalmente la dirección del conjunto de datos final.
(3) Entrenamiento de ejecución
python train.py3. Estructura MPRNet
Presentaré la estructura del modelo de acuerdo con la implementación del código oficial. La división de algunos módulos importantes puede ser diferente del documento, pero la estructura general es la misma.
1. Estructura general
El diagrama de estructura oficial proporcionado por MPRNet es el siguiente:
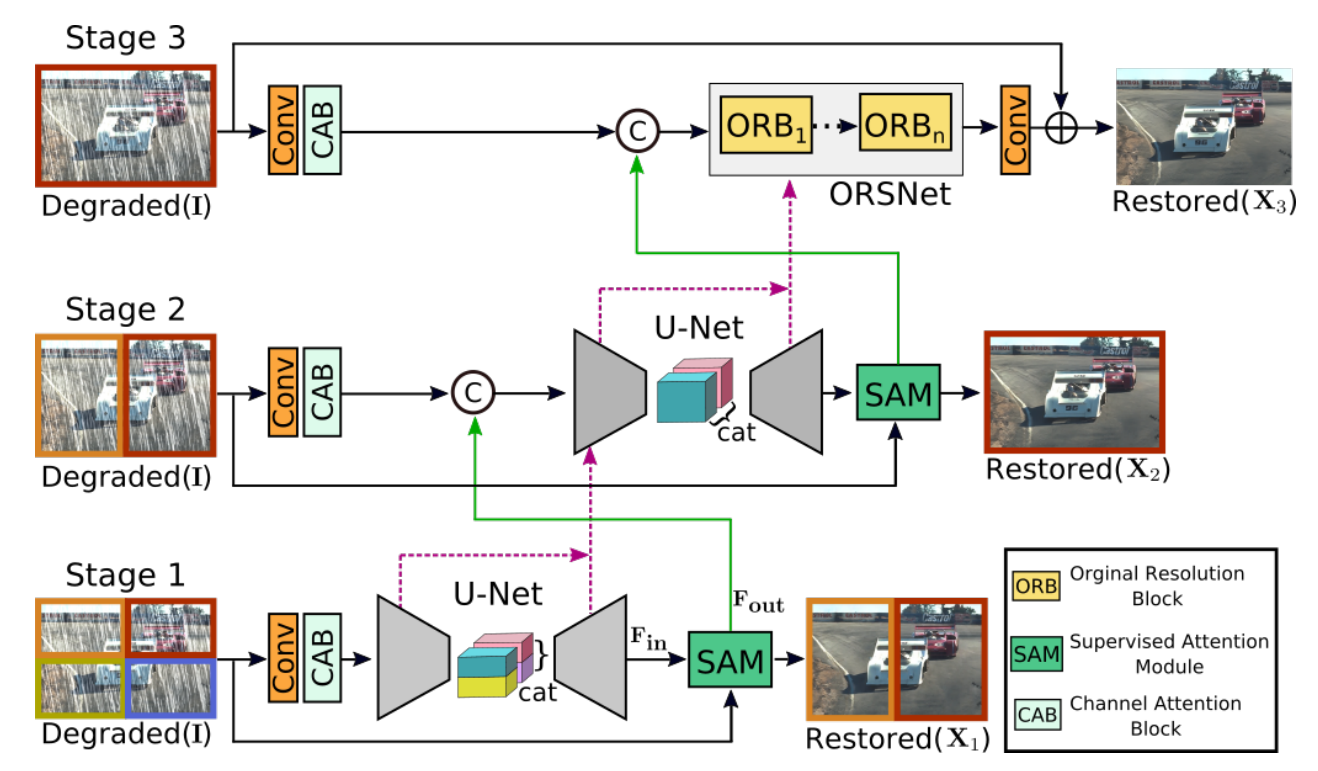
Figura 1
En general, esta figura resume la estructura de MPRNet, pero no se muestran muchos detalles Al leer el código, daré una introducción más detallada a la estructura del modelo. En la siguiente figura, ingrese uniform 512x512, tomamos Deblurring como ejemplo y batch_size=1.
El diagrama general de la estructura es el siguiente:
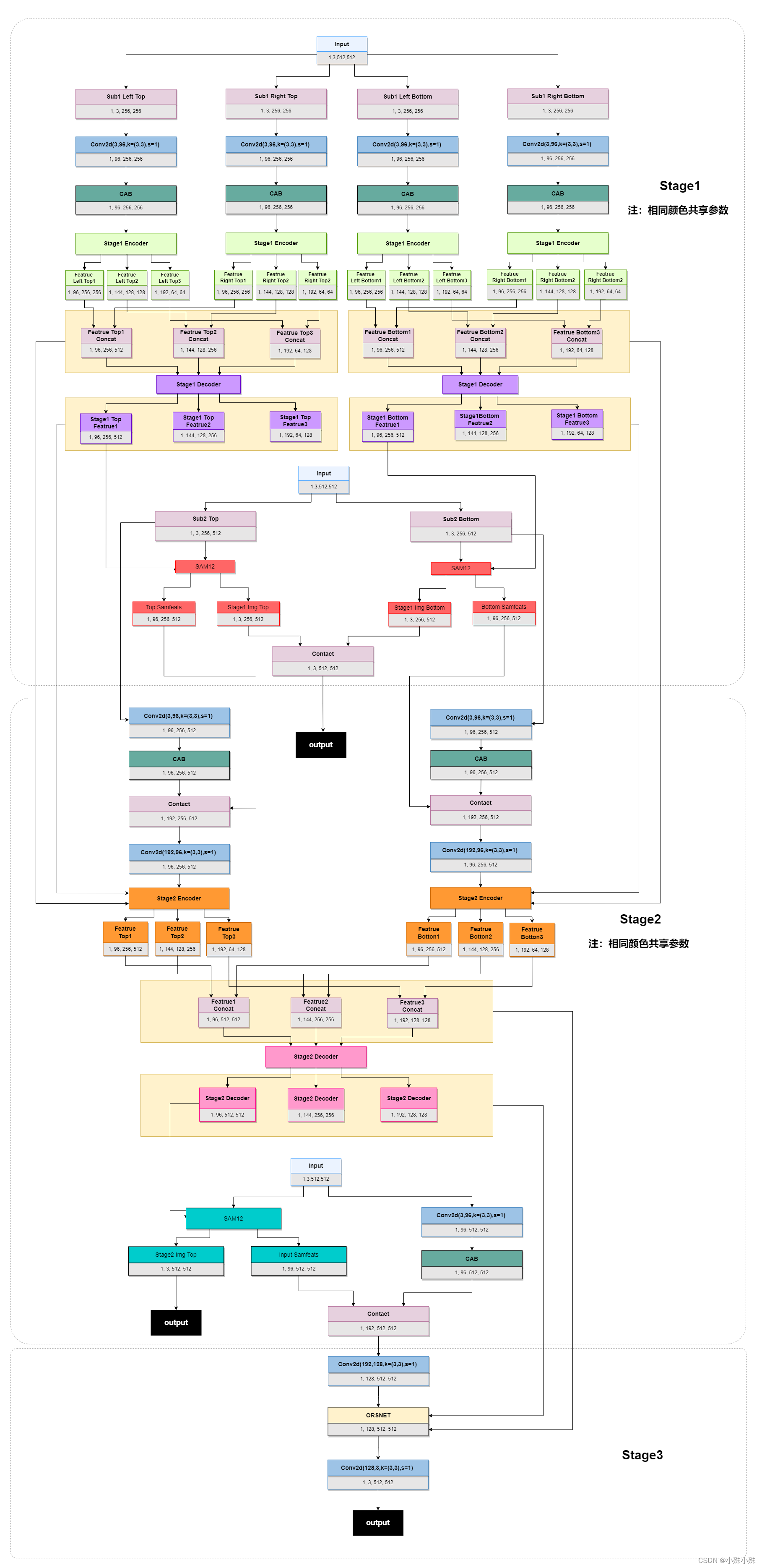
Figura 2
Las tres entradas en la figura son imágenes originales. Todo el modelo tiene tres etapas. El proceso general es el siguiente:
1.1 La imagen de entrada se divide en cuatro partes por el método de múltiples parches, dividida en superior izquierda, superior derecha, inferior izquierda e inferior derecha;
1.2 Cada parche se somete a una convolución de 3x3 para expandir la dimensión, con el fin de extraer información de funciones más rica más adelante;
1.3 Después de CAB (Channel Attention Block), use el mecanismo de atención para extraer características en cada dimensión;
1.4 Codificador, que codifica características de imagen de tres escalas, extrae características de contexto de múltiples escalas y también extrae características semánticas más profundas;
1.5 Fusionar características profundas, fusionar las características de la misma escala de cuatro lotes en dos escalas a la izquierda y a la derecha, y enviarlas a Decoder;
1.6 Decodificador, extrayendo las características de cada escala después de la fusión;
1.7 La imagen de entrada se divide en dos partes por el método de múltiples parches, dividida en izquierda y derecha;
1.8 Envíe los lotes izquierdo y derecho y los mapas de características a gran escala generados por el decodificador Stage1 a SAM (módulo de atención supervisada).Durante el entrenamiento, SAM puede usar GT para proporcionar señales de control útiles para el proceso de recuperación de la etapa actual;
1.9 La salida de SAM se divide en dos partes, una parte son las características de la imagen original de la segunda entrada, que continuará el siguiente proceso; la otra parte se usa para la salida Stage1 durante el entrenamiento, y GT se puede usar para hacer el modelo converger más rápido y mejor.
2.0 Después del canal de expansión de convolución de Stage2 y la operación CAB, las funciones antes y después del decodificador en Stage1 se envían al codificador de Stage2.
2.2 Después de un decodificador similar a Stage1, también se generan dos partes de salida, una parte continúa a Stage3, y la otra parte se emite y GT se calcula como una pérdida;
3.1 La entrada de imagen original de Stage3 ya no está segmentada, el propósito es usar la información de contexto completa para restaurar los detalles de la imagen.
3.2 Convolucionar la imagen original para escalar;
3.3 Envíe las características antes y después del decodificador en Stage2 a ORSNet ( Subred de resolución original ) de Stage 3. ORSNet no utiliza ninguna operación de reducción de muestreo y genera características espacialmente ricas de alta resolución.
3.4 Finalmente, después de una convolución, la dimensión se reduce a 3 y la salida.
Código:
#位置:MPRNet.py
class MPRNet(nn.Module):
def __init__(self, in_c=3, out_c=3, n_feat=96, scale_unetfeats=48, scale_orsnetfeats=32, num_cab=8, kernel_size=3, reduction=4, bias=False):
super(MPRNet, self).__init__()
act=nn.PReLU()
self.shallow_feat1 = nn.Sequential(conv(in_c, n_feat, kernel_size, bias=bias), CAB(n_feat,kernel_size, reduction, bias=bias, act=act))
self.shallow_feat2 = nn.Sequential(conv(in_c, n_feat, kernel_size, bias=bias), CAB(n_feat,kernel_size, reduction, bias=bias, act=act))
self.shallow_feat3 = nn.Sequential(conv(in_c, n_feat, kernel_size, bias=bias), CAB(n_feat,kernel_size, reduction, bias=bias, act=act))
# Cross Stage Feature Fusion (CSFF)
self.stage1_encoder = Encoder(n_feat, kernel_size, reduction, act, bias, scale_unetfeats, csff=False)
self.stage1_decoder = Decoder(n_feat, kernel_size, reduction, act, bias, scale_unetfeats)
self.stage2_encoder = Encoder(n_feat, kernel_size, reduction, act, bias, scale_unetfeats, csff=True)
self.stage2_decoder = Decoder(n_feat, kernel_size, reduction, act, bias, scale_unetfeats)
self.stage3_orsnet = ORSNet(n_feat, scale_orsnetfeats, kernel_size, reduction, act, bias, scale_unetfeats, num_cab)
self.sam12 = SAM(n_feat, kernel_size=1, bias=bias)
self.sam23 = SAM(n_feat, kernel_size=1, bias=bias)
self.concat12 = conv(n_feat*2, n_feat, kernel_size, bias=bias)
self.concat23 = conv(n_feat*2, n_feat+scale_orsnetfeats, kernel_size, bias=bias)
self.tail = conv(n_feat+scale_orsnetfeats, out_c, kernel_size, bias=bias)
def forward(self, x3_img):
# Original-resolution Image for Stage 3
H = x3_img.size(2)
W = x3_img.size(3)
# Multi-Patch Hierarchy: Split Image into four non-overlapping patches
# Two Patches for Stage 2
x2top_img = x3_img[:,:,0:int(H/2),:]
x2bot_img = x3_img[:,:,int(H/2):H,:]
# Four Patches for Stage 1
x1ltop_img = x2top_img[:,:,:,0:int(W/2)]
x1rtop_img = x2top_img[:,:,:,int(W/2):W]
x1lbot_img = x2bot_img[:,:,:,0:int(W/2)]
x1rbot_img = x2bot_img[:,:,:,int(W/2):W]
##-------------------------------------------
##-------------- Stage 1---------------------
##-------------------------------------------
## Compute Shallow Features
x1ltop = self.shallow_feat1(x1ltop_img)
x1rtop = self.shallow_feat1(x1rtop_img)
x1lbot = self.shallow_feat1(x1lbot_img)
x1rbot = self.shallow_feat1(x1rbot_img)
## Process features of all 4 patches with Encoder of Stage 1
feat1_ltop = self.stage1_encoder(x1ltop)
feat1_rtop = self.stage1_encoder(x1rtop)
feat1_lbot = self.stage1_encoder(x1lbot)
feat1_rbot = self.stage1_encoder(x1rbot)
## Concat deep features
feat1_top = [torch.cat((k,v), 3) for k,v in zip(feat1_ltop,feat1_rtop)]
feat1_bot = [torch.cat((k,v), 3) for k,v in zip(feat1_lbot,feat1_rbot)]
## Pass features through Decoder of Stage 1
res1_top = self.stage1_decoder(feat1_top)
res1_bot = self.stage1_decoder(feat1_bot)
## Apply Supervised Attention Module (SAM)
x2top_samfeats, stage1_img_top = self.sam12(res1_top[0], x2top_img)
x2bot_samfeats, stage1_img_bot = self.sam12(res1_bot[0], x2bot_img)
## Output image at Stage 1
stage1_img = torch.cat([stage1_img_top, stage1_img_bot],2)
##-------------------------------------------
##-------------- Stage 2---------------------
##-------------------------------------------
## Compute Shallow Features
x2top = self.shallow_feat2(x2top_img)
x2bot = self.shallow_feat2(x2bot_img)
## Concatenate SAM features of Stage 1 with shallow features of Stage 2
x2top_cat = self.concat12(torch.cat([x2top, x2top_samfeats], 1))
x2bot_cat = self.concat12(torch.cat([x2bot, x2bot_samfeats], 1))
## Process features of both patches with Encoder of Stage 2
feat2_top = self.stage2_encoder(x2top_cat, feat1_top, res1_top)
feat2_bot = self.stage2_encoder(x2bot_cat, feat1_bot, res1_bot)
## Concat deep features
feat2 = [torch.cat((k,v), 2) for k,v in zip(feat2_top,feat2_bot)]
## Pass features through Decoder of Stage 2
res2 = self.stage2_decoder(feat2)
## Apply SAM
x3_samfeats, stage2_img = self.sam23(res2[0], x3_img)
##-------------------------------------------
##-------------- Stage 3---------------------
##-------------------------------------------
## Compute Shallow Features
x3 = self.shallow_feat3(x3_img)
## Concatenate SAM features of Stage 2 with shallow features of Stage 3
x3_cat = self.concat23(torch.cat([x3, x3_samfeats], 1))
x3_cat = self.stage3_orsnet(x3_cat, feat2, res2)
stage3_img = self.tail(x3_cat)
return [stage3_img+x3_img, stage2_img, stage1_img]Todavía hay algunos detalles del módulo que no se muestran en la figura, que presentaré en detalle a continuación.
2.CAB ( Bloque de atención de canal )
Como su nombre lo indica, CAB utiliza el mecanismo de atención para extraer las características de cada canal, y la forma de los mapas de características de salida y entrada permanece sin cambios. El diagrama de estructura es el siguiente:
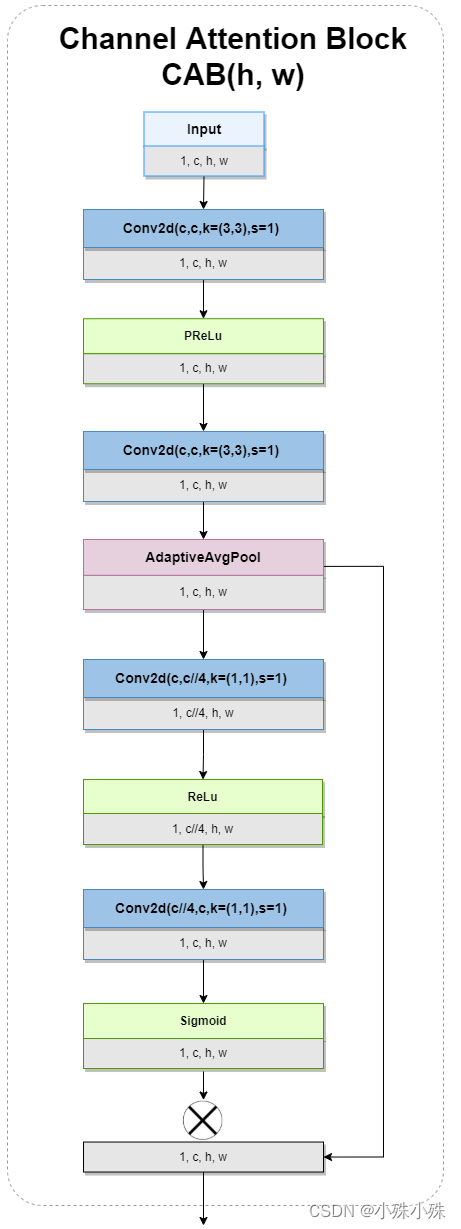
imagen 3
Se puede ver que después de dos convoluciones y GAP, se obtiene un mapa de probabilidad (es decir, el borde residual), y después de dos convoluciones y Sigmoid se multiplican por el mapa de probabilidad, se realiza un mecanismo de atención de canal.
Código:
# 位置MPRNet.py
## Channel Attention Layer
class CALayer(nn.Module):
def __init__(self, channel, reduction=16, bias=False):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=bias),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=bias),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
##########################################################################
## Channel Attention Block (CAB)
class CAB(nn.Module):
def __init__(self, n_feat, kernel_size, reduction, bias, act):
super(CAB, self).__init__()
modules_body = []
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias))
modules_body.append(act)
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias))
self.CA = CALayer(n_feat, reduction, bias=bias)
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res = self.CA(res)
res += x
return res3. Codificador Stage1
Existen algunas diferencias entre Stage1 y el codificador de Stage1, por lo que se presentan por separado. Stage1 Encoder tiene una entrada y tres salidas de diferentes escalas, para extraer las características de las tres escalas y prepararse para el siguiente proceso de fusión de escalas; hay múltiples estructuras CAB, que pueden extraer mejor las características del canal; pases de reducción de muestreo La implementación cruda de Downsample tiene la siguiente estructura:
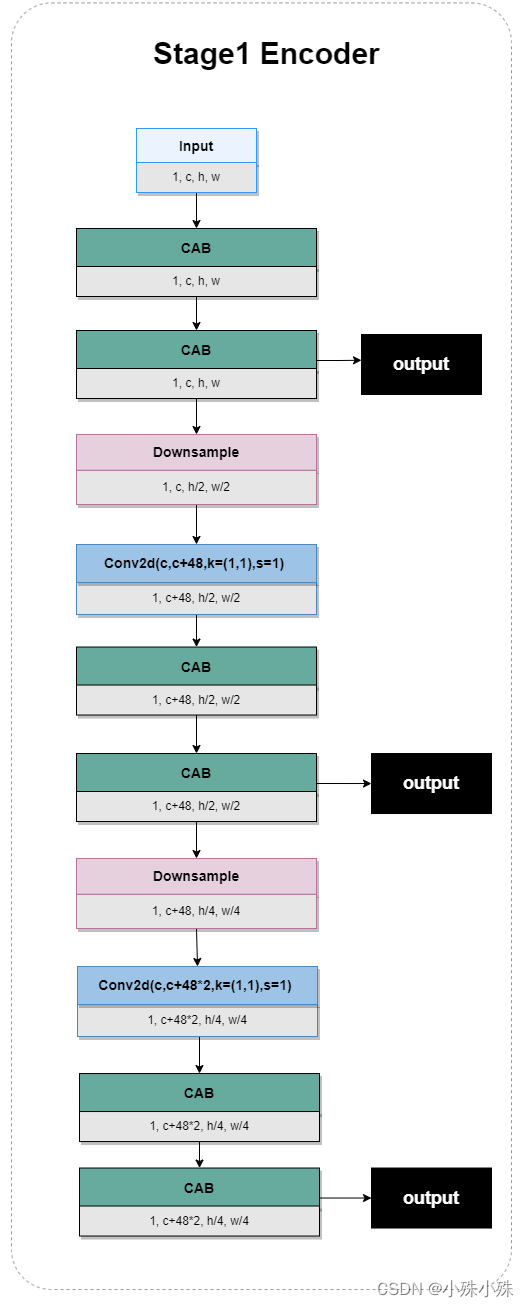
Figura 4
Código:
# 位置MPRNet.py
class Encoder(nn.Module):
def __init__(self, n_feat, kernel_size, reduction, act, bias, scale_unetfeats, csff):
super(Encoder, self).__init__()
self.encoder_level1 = [CAB(n_feat, kernel_size, reduction, bias=bias, act=act) for _ in range(2)]
self.encoder_level2 = [CAB(n_feat+scale_unetfeats, kernel_size, reduction, bias=bias, act=act) for _ in range(2)]
self.encoder_level3 = [CAB(n_feat+(scale_unetfeats*2), kernel_size, reduction, bias=bias, act=act) for _ in range(2)]
self.encoder_level1 = nn.Sequential(*self.encoder_level1)
self.encoder_level2 = nn.Sequential(*self.encoder_level2)
self.encoder_level3 = nn.Sequential(*self.encoder_level3)
self.down12 = DownSample(n_feat, scale_unetfeats)
self.down23 = DownSample(n_feat+scale_unetfeats, scale_unetfeats)
# Cross Stage Feature Fusion (CSFF)
if csff:
self.csff_enc1 = nn.Conv2d(n_feat, n_feat, kernel_size=1, bias=bias)
self.csff_enc2 = nn.Conv2d(n_feat+scale_unetfeats, n_feat+scale_unetfeats, kernel_size=1, bias=bias)
self.csff_enc3 = nn.Conv2d(n_feat+(scale_unetfeats*2), n_feat+(scale_unetfeats*2), kernel_size=1, bias=bias)
self.csff_dec1 = nn.Conv2d(n_feat, n_feat, kernel_size=1, bias=bias)
self.csff_dec2 = nn.Conv2d(n_feat+scale_unetfeats, n_feat+scale_unetfeats, kernel_size=1, bias=bias)
self.csff_dec3 = nn.Conv2d(n_feat+(scale_unetfeats*2), n_feat+(scale_unetfeats*2), kernel_size=1, bias=bias)
def forward(self, x, encoder_outs=None, decoder_outs=None):
enc1 = self.encoder_level1(x)
if (encoder_outs is not None) and (decoder_outs is not None):
enc1 = enc1 + self.csff_enc1(encoder_outs[0]) + self.csff_dec1(decoder_outs[0])
x = self.down12(enc1)
enc2 = self.encoder_level2(x)
if (encoder_outs is not None) and (decoder_outs is not None):
enc2 = enc2 + self.csff_enc2(encoder_outs[1]) + self.csff_dec2(decoder_outs[1])
x = self.down23(enc2)
enc3 = self.encoder_level3(x)
if (encoder_outs is not None) and (decoder_outs is not None):
enc3 = enc3 + self.csff_enc3(encoder_outs[2]) + self.csff_dec3(decoder_outs[2])
return [enc1, enc2, enc3]4. Codificador Stage2
El Codificador Stage2 tiene tres entradas, que son la salida de la capa anterior y las características antes y después del Decodificador en Stage1. El proceso principal (es decir, la columna vertical de la izquierda) es el mismo que el codificador Stage1. Se agregaron dos entradas, cada entrada se divide en tres escalas, cada escala pasa a través de una capa convolucional, y luego el mapa de características de la misma escala se usa para la fusión de características, la salida, la estructura es la siguiente:
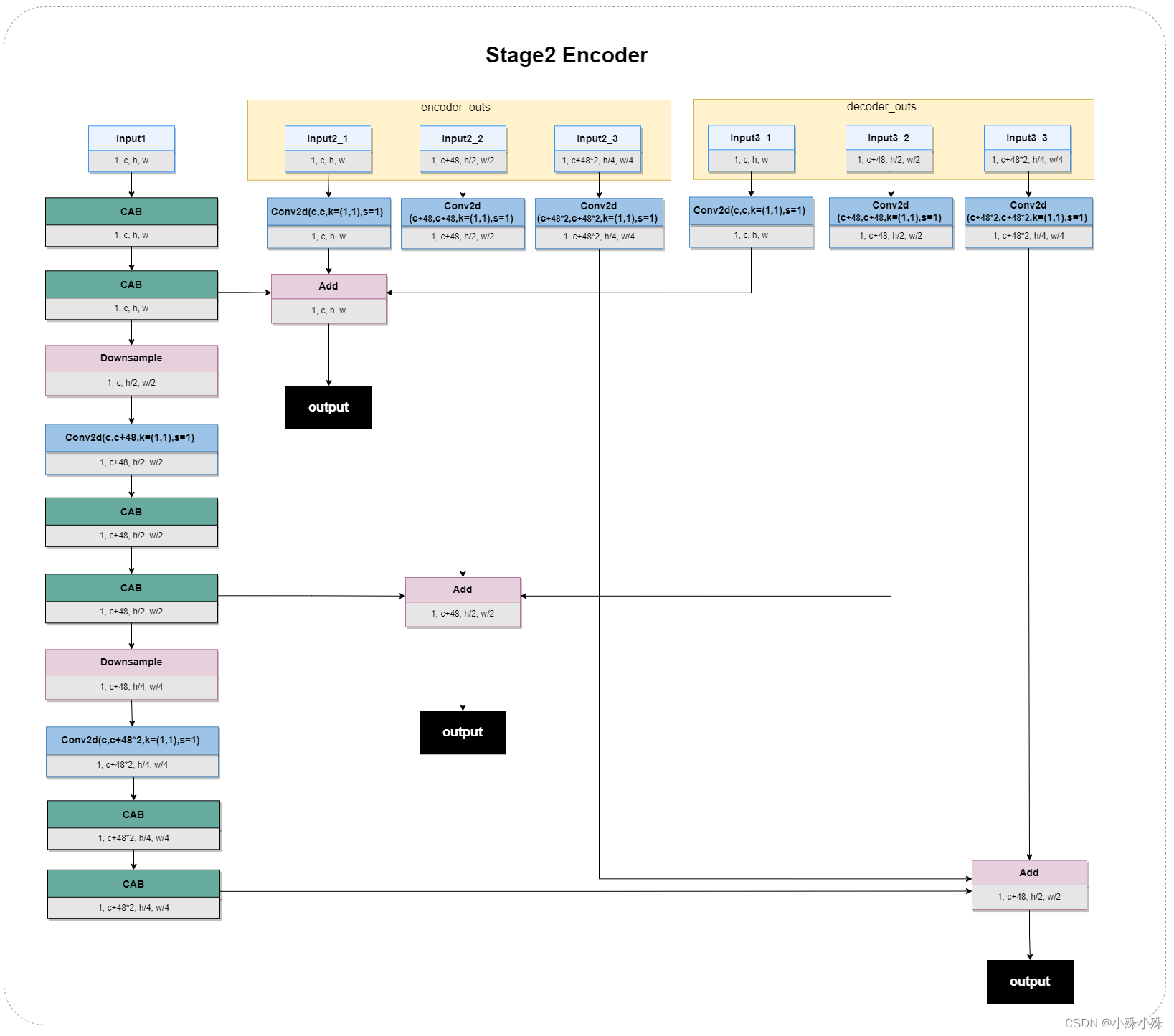
Figura 5
5. Decodificador
La estructura del decodificador de las dos etapas es la misma, por lo que juntas hay tres entradas con diferentes escalas; las características se extraen a través de CAB; las características a pequeña escala se amplían mediante muestreo ascendente y los canales se reducen a través de la convolución; los mapas de características a pequeña escala La forma finalmente se convierte en la misma que a gran escala, y la fusión de características se realiza a través del borde residual.La estructura es la siguiente:
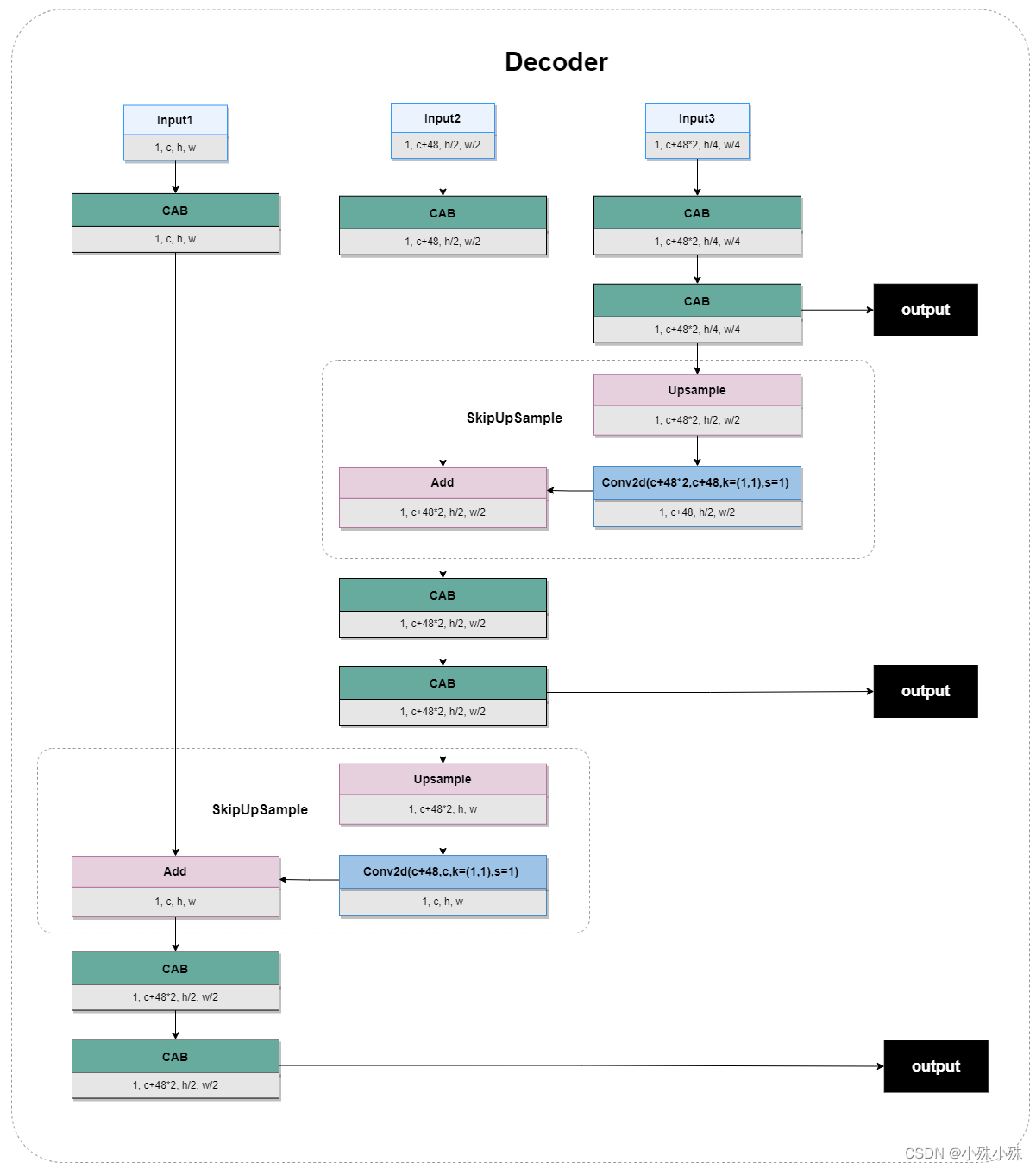
Figura 6
Código:
# 位置:MPRNet.py
class Decoder(nn.Module):
def __init__(self, n_feat, kernel_size, reduction, act, bias, scale_unetfeats):
super(Decoder, self).__init__()
self.decoder_level1 = [CAB(n_feat, kernel_size, reduction, bias=bias, act=act) for _ in range(2)]
self.decoder_level2 = [CAB(n_feat+scale_unetfeats, kernel_size, reduction, bias=bias, act=act) for _ in range(2)]
self.decoder_level3 = [CAB(n_feat+(scale_unetfeats*2), kernel_size, reduction, bias=bias, act=act) for _ in range(2)]
self.decoder_level1 = nn.Sequential(*self.decoder_level1)
self.decoder_level2 = nn.Sequential(*self.decoder_level2)
self.decoder_level3 = nn.Sequential(*self.decoder_level3)
self.skip_attn1 = CAB(n_feat, kernel_size, reduction, bias=bias, act=act)
self.skip_attn2 = CAB(n_feat+scale_unetfeats, kernel_size, reduction, bias=bias, act=act)
self.up21 = SkipUpSample(n_feat, scale_unetfeats)
self.up32 = SkipUpSample(n_feat+scale_unetfeats, scale_unetfeats)
def forward(self, outs):
enc1, enc2, enc3 = outs
dec3 = self.decoder_level3(enc3)
x = self.up32(dec3, self.skip_attn2(enc2))
dec2 = self.decoder_level2(x)
x = self.up21(dec2, self.skip_attn1(enc1))
dec1 = self.decoder_level1(x)
return [dec1,dec2,dec3]6.SAM (Módulo de Atención Supervisada)
SAM aparece entre dos etapas y tiene dos entradas. Las características de la capa superior y la imagen original se usan como entrada, lo que mejora el rendimiento de la extracción de características. Como módulo de atención supervisada, SAM usa el mapa de atención para filtrar fuertemente la información útil entre etapas. características. Hay dos salidas, una es el mapa de funciones después del mecanismo de atención, que proporciona funciones para el siguiente proceso; la otra es la función de imagen de 3 canales, para la salida de la fase de entrenamiento, la estructura es la siguiente:
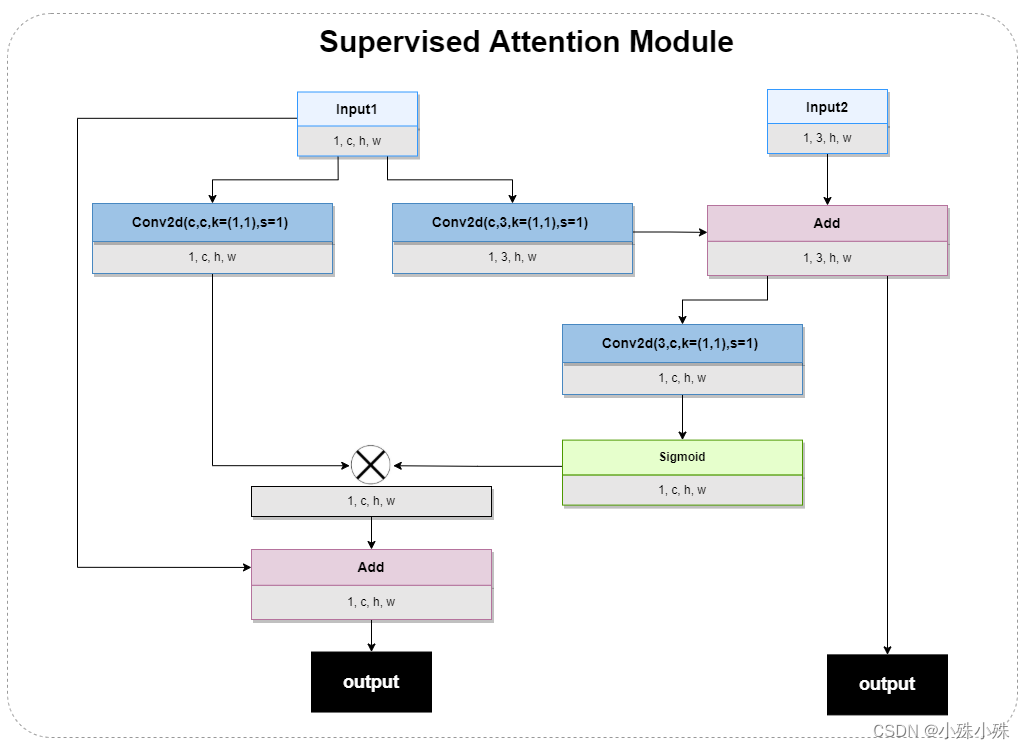
Figura 7
Ubicación del código:
# 位置MPRNet.py
## Supervised Attention Module
class SAM(nn.Module):
def __init__(self, n_feat, kernel_size, bias):
super(SAM, self).__init__()
self.conv1 = conv(n_feat, n_feat, kernel_size, bias=bias)
self.conv2 = conv(n_feat, 3, kernel_size, bias=bias)
self.conv3 = conv(3, n_feat, kernel_size, bias=bias)
def forward(self, x, x_img):
x1 = self.conv1(x)
img = self.conv2(x) + x_img
x2 = torch.sigmoid(self.conv3(img))
x1 = x1*x2
x1 = x1+x
return x1, img7. ORSNet (Subred de resolución original)
Para preservar los detalles de la imagen de entrada, el modelo introduce la subred de resolución original (ORSNet: Subred de resolución original) en la última etapa. ORSNet no utiliza ninguna operación de reducción de resolución y genera funciones de alta resolución espacialmente ricas. Consta de múltiples bloques de resolución nativa (BRB) y es la etapa final del modelo, estructurado de la siguiente manera:

Figura 8
Se puede ver que hay tres entradas, que son la salida de la capa anterior y las características antes y después del Decodificador en Stage2. Las dos últimas entradas, cada entrada se divide en tres escalas, el número de canales de las tres escalas primero se convierte en 96 y luego en 128; el tamaño de la escala pequeña se vuelve igual al de la escala grande, y finalmente la función de fusión es realizado Antes de pasar por el módulo ORB (Bloque de resolución original).
ORB consta de una serie de CABs y un gran borde residual, la estructura es la siguiente:

Figura 9
Código:
# 位置MPRNet.py
## Original Resolution Block (ORB)
class ORB(nn.Module):
def __init__(self, n_feat, kernel_size, reduction, act, bias, num_cab):
super(ORB, self).__init__()
modules_body = []
modules_body = [CAB(n_feat, kernel_size, reduction, bias=bias, act=act) for _ in range(num_cab)]
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x
return res
##########################################################################
class ORSNet(nn.Module):
def __init__(self, n_feat, scale_orsnetfeats, kernel_size, reduction, act, bias, scale_unetfeats, num_cab):
super(ORSNet, self).__init__()
self.orb1 = ORB(n_feat+scale_orsnetfeats, kernel_size, reduction, act, bias, num_cab)
self.orb2 = ORB(n_feat+scale_orsnetfeats, kernel_size, reduction, act, bias, num_cab)
self.orb3 = ORB(n_feat+scale_orsnetfeats, kernel_size, reduction, act, bias, num_cab)
self.up_enc1 = UpSample(n_feat, scale_unetfeats)
self.up_dec1 = UpSample(n_feat, scale_unetfeats)
self.up_enc2 = nn.Sequential(UpSample(n_feat+scale_unetfeats, scale_unetfeats), UpSample(n_feat, scale_unetfeats))
self.up_dec2 = nn.Sequential(UpSample(n_feat+scale_unetfeats, scale_unetfeats), UpSample(n_feat, scale_unetfeats))
self.conv_enc1 = nn.Conv2d(n_feat, n_feat+scale_orsnetfeats, kernel_size=1, bias=bias)
self.conv_enc2 = nn.Conv2d(n_feat, n_feat+scale_orsnetfeats, kernel_size=1, bias=bias)
self.conv_enc3 = nn.Conv2d(n_feat, n_feat+scale_orsnetfeats, kernel_size=1, bias=bias)
self.conv_dec1 = nn.Conv2d(n_feat, n_feat+scale_orsnetfeats, kernel_size=1, bias=bias)
self.conv_dec2 = nn.Conv2d(n_feat, n_feat+scale_orsnetfeats, kernel_size=1, bias=bias)
self.conv_dec3 = nn.Conv2d(n_feat, n_feat+scale_orsnetfeats, kernel_size=1, bias=bias)
def forward(self, x, encoder_outs, decoder_outs):
x = self.orb1(x)
x = x + self.conv_enc1(encoder_outs[0]) + self.conv_dec1(decoder_outs[0])
x = self.orb2(x)
x = x + self.conv_enc2(self.up_enc1(encoder_outs[1])) + self.conv_dec2(self.up_dec1(decoder_outs[1]))
x = self.orb3(x)
x = x + self.conv_enc3(self.up_enc2(encoder_outs[2])) + self.conv_dec3(self.up_dec2(decoder_outs[2]))
return x4. Función de pérdida
MPRNet utiliza principalmente dos funciones de pérdida CharbonnierLoss y EdgeLoss, la fórmula es la siguiente:
La acumulación se debe a que hay salidas en las tres etapas de entrenamiento, y se requiere un GT para calcular la pérdida (como se muestra en las tres salidas de la Figura 2); el modelo no predice directamente la imagen restaurada, pero predice la imagen residual , agregando entrada degradada
La imagen
obtiene:
Las dos tareas de Deblurring y Deraining, CharbonnierLoss y EdgeLoss, hicieron una suma ponderada, con una relación de 1:0.05, solo se usó CharbonnierLoss, siento que es porque el ruido que se usa aquí es el ruido de una cierta distribución (en gaussiana). distribución, distribución de Poisson), no causará diferencias de borde drásticas, por lo que Denoising no usa EdgeLoss.
Las dos pérdidas se describen brevemente a continuación.
1.Pérdida de carbonero
La fórmula es la siguiente:
CharbonnierLoss es cercano a cero debido a la existencia de una constante, el gradiente no se volverá cero, evitando la desaparición del gradiente. La curva de la función se aproxima a la pérdida L1, en comparación con la pérdida L2, no es sensible a los valores atípicos y evita aumentar excesivamente el error.
Código:
# 位置losses.py
class CharbonnierLoss(nn.Module):
"""Charbonnier Loss (L1)"""
def __init__(self, eps=1e-3):
super(CharbonnierLoss, self).__init__()
self.eps = eps
def forward(self, x, y):
diff = x - y
# loss = torch.sum(torch.sqrt(diff * diff + self.eps))
loss = torch.mean(torch.sqrt((diff * diff) + (self.eps*self.eps)))
return loss2.Pérdida de borde
La pérdida de L1 o L2 se enfoca en la situación general y no tiene en cuenta la influencia de algunas características sobresalientes.La estructura sobresaliente y la información de textura están altamente relacionadas con la percepción subjetiva humana y no se pueden ignorar.
La pérdida del borde considera principalmente la diferencia en la parte de la textura, que puede considerar la información de la estructura de la textura de alta frecuencia y mejorar el rendimiento de los detalles de la imagen generada. La publicidad es la siguiente:
Representa la función kernel en la detección de bordes de Laplacian, lo que significa detección de bordes. Las otras partes de la fórmula son similares a CharbonnierLoss.
Código:
# 位置losses.py
class EdgeLoss(nn.Module):
def __init__(self):
super(EdgeLoss, self).__init__()
k = torch.Tensor([[.05, .25, .4, .25, .05]])
self.kernel = torch.matmul(k.t(),k).unsqueeze(0).repeat(3,1,1,1)
if torch.cuda.is_available():
self.kernel = self.kernel.cuda()
self.loss = CharbonnierLoss()
def conv_gauss(self, img):
n_channels, _, kw, kh = self.kernel.shape
img = F.pad(img, (kw//2, kh//2, kw//2, kh//2), mode='replicate')
return F.conv2d(img, self.kernel, groups=n_channels)
def laplacian_kernel(self, current):
filtered = self.conv_gauss(current) # filter
down = filtered[:,:,::2,::2] # downsample
new_filter = torch.zeros_like(filtered)
new_filter[:,:,::2,::2] = down*4 # upsample
filtered = self.conv_gauss(new_filter) # filter
diff = current - filtered
return diff
def forward(self, x, y):
loss = self.loss(self.laplacian_kernel(x), self.laplacian_kernel(y))
return loss
El contenido principal de MPRNet se presenta aquí, principalmente la innovación de la columna vertebral, las otras partes son bastante satisfactorias y no se pierde la atención.