Aplicación de nombre de experimento Matplotlib, seaborn, análisis visual de biblioteca de pyecharts
Tiempo de experimento 2023.5.10
1. Propósito del experimento
1. Domine la sintaxis básica de pyplot.
2. Domina el método de dibujo del gráfico circular.
3. Domina el método de dibujo del diagrama de caja.
4. Dominar el método de dibujo del subgrafo.
5. Domina el método de dibujo del gráfico de columnas.
6. Domina el uso de funciones relacionadas en la biblioteca NumPy.
7. Domina el método de dibujo del diagrama de dispersión de clasificación.
8. Domine el método de dibujo del gráfico de ajuste de regresión lineal.
9. Domina el método de dibujo del mapa de calor.
10. Domina el método de dibujo del diagrama de embudo.
11. Domina el método de dibujo del mapa de nubes de palabras.
2. Equipos o materiales experimentales
Computadora portátil, software Anaconda
3. Principio experimental
1. Descripción de los requisitos
Después del examen final, la escuela recopila estadísticas sobre los resultados del examen final de los estudiantes y otra información característica, y las guarda como una tabla de relación característica de calificación del estudiante (calificación del estudiante.xlsx). Hay 7 características en la tabla de relación de características de rendimiento del estudiante, que son género, almuerzo, preparación del curso de examen, rendimiento en matemáticas, rendimiento en lectura, rendimiento en escritura y calificación total.Parte de los datos se muestran en la Tabla 5-40. Para comprender la distribución de las puntuaciones totales de los estudiantes en el examen, las puntuaciones totales se dividen en cuatro grados de "reprobado", "aprobado", "bueno" y "excelente" según el rango de 0150, 150200, 200 ~ 250 y 250 ~ 300. Verifique la proporción del número de estudiantes en cada intervalo y verifique la dispersión de las puntuaciones de los tres estudiantes en
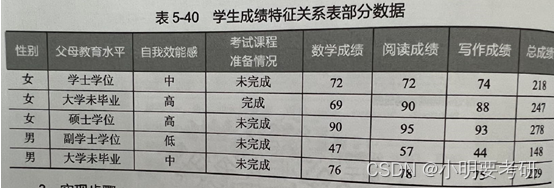
2. Descripción de los requisitos
Para comprender si existe alguna relación entre las dos características del nivel de educación de los padres de los estudiantes, el almuerzo y la preparación para el examen y el rendimiento general, con base en los datos del entrenamiento 1, los valores correspondientes de las tres características son diferentes. Calcule el promedio de las calificaciones totales de los estudiantes, dibuje un gráfico de líneas para verificar la relación entre el nivel de educación de los padres y la calificación total, dibuje un gráfico de columnas para verificar la relación entre el almuerzo, la preparación del curso de examen y la calificación total y analizar los resultados.
número de estudiante, nombre e información de la clase.
3. Descripción de la demanda
Índice de calidad del aire (Índice de calidad del aire, AOI) son datos que pueden describir cuantitativamente la calidad del aire. La calidad del aire refleja el grado de contaminación del aire, que se juzga en función de la concentración de contaminantes en el aire. La contaminación del aire es un fenómeno complejo, y la concentración de contaminantes del aire se ve afectada por muchos factores.
Parte de los datos del AQI de una determinada ciudad de enero a septiembre de 2020 se muestran en la Tabla 5-41.
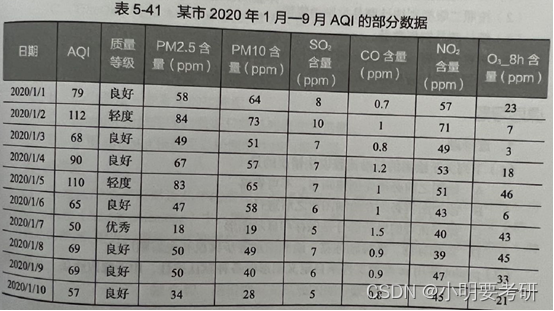
Esta capacitación dibujará diagramas de dispersión de clasificación y diagramas de ajuste de regresión basados en los datos que se muestran en la Tabla 5-41, y analizará la relación entre la concentración de PM2.5 y el AQI, así como la clasificación del AQI. Al mismo tiempo, dibuje un mapa de calor para analizar la correlación entre los indicadores de calidad del aire y el AQI.
4. Descripción del requisito
Un centro comercial colocó 5 máquinas expendedoras en diferentes ubicaciones, numeradas A, B, C, D y E, y registró los datos de ventas de cada máquina expendedora en junio de 2017. Para comprender la situación de las ventas de cada producto, se clasifica en categorías de dos niveles, se cuentan las ventas de las 5 principales categorías de productos básicos y se dibuja un diagrama de embudo. Al mismo tiempo, se dibuja un diagrama de nube de palabras. según el volumen de ventas y el nombre del producto.
4. Contenido y pasos experimentales
Tarea 1: Analizar la distribución y dispersión de las características de los puntajes de las pruebas de los estudiantes.
1. Ideas y pasos de implementación
(1) Use la biblioteca pandas para leer los datos de puntaje de las pruebas de los estudiantes.
(2) Divida los puntajes totales de las pruebas de los estudiantes en 4 intervalos, calcule el número de estudiantes en cada intervalo y dibuje un gráfico circular de la distribución de los puntajes totales de las pruebas de los estudiantes.
(3) Extraiga los datos de los puntajes de tres materias individuales de los estudiantes y dibuje el diagrama de línea de caja de la dispersión de los puntajes de las pruebas de los estudiantes.
(4) Analizar la distribución de las puntuaciones totales de los estudiantes en las pruebas y la dispersión de las puntuaciones de tres materias individuales.
Tarea 2: Analizar la relación entre los puntajes de las pruebas de los estudiantes y varias características.
2. Ideas y pasos de implementación
(1) Cree un lienzo y agregue subgráficos.
(2) Use la función de media en la biblioteca NumPy para encontrar el promedio de las calificaciones totales de los estudiantes bajo las tres características del nivel de educación de los padres de los estudiantes, el almuerzo y la información del curso de examen.
(3) Dibuje el gráfico de líneas o el gráfico de columnas correspondiente en el subgráfico.
(4) Analizar la relación entre las tres características y la puntuación total de la prueba.
Tarea 3: Analizar la correlación entre varios índices de calidad del aire.
3. Ideas y pasos de implementación
(1) Usar pandas Nanfa Zhongzhanggu 2020 días laborables-Estadísticas AOI de septiembre.
(2) Resuelva el problema de la visualización en chino, configure la fuente en negrita y resuelva el problema de que el signo menos "-" se muestra como un cuadrado al guardar la imagen.
(3) Dibuje un diagrama de dispersión de la clasificación del grado de calidad.
(4) Dibuje el gráfico de ajuste de regresión lineal de la concentración de PM2.5 y el AOI.
(5) Calcular el coeficiente de correlación.
(6) Dibuje un mapa de calor de la correlación de las características de la calidad del aire.
Tarea 4: Dibujo de gráficos básicos interactivos
4. Ideas y pasos de implementación
(1) Obtener datos de ventas de productos básicos.
(2) Estadísticas de ventas de categorías de commodities según la categoría secundaria.
(3) Cuente el volumen de ventas de productos básicos.
(4) Establezca elementos de configuración de serie y elementos de configuración global, y dibuje un diagrama de embudo de las 5 principales categorías de productos en ventas.
(5) Establezca los elementos de configuración de la serie y los elementos de configuración global, y dibuje un diagrama de nube de palabras de la cantidad de ventas del producto y el nombre del producto.
5. Resultados experimentales y análisis
Tarea uno:
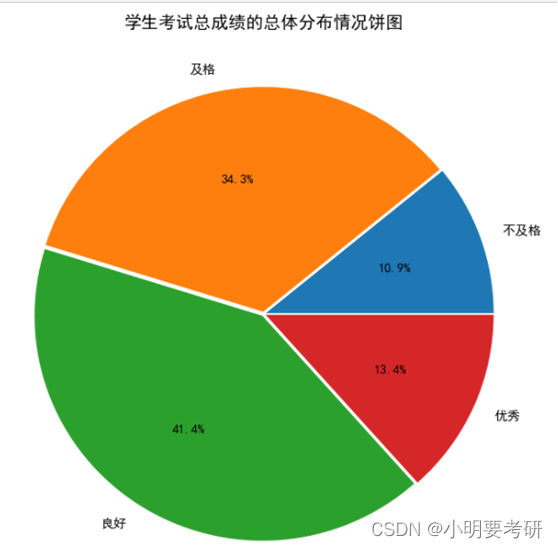
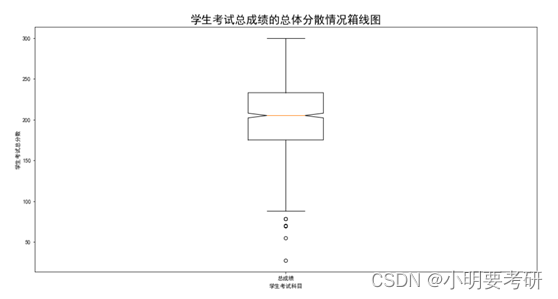
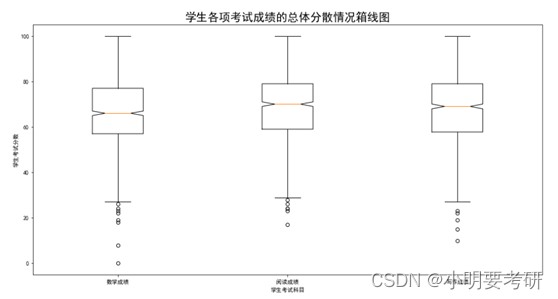
Este gráfico circular muestra la distribución de los puntajes totales de las pruebas de los estudiantes, que se dividen en 4 intervalos. Se puede ver en el gráfico circular que el número de estudiantes en la división 150-200 es el más grande, representando el 34.3% Se puede ver que los puntajes totales de las pruebas de la mayoría de los estudiantes están por encima de excelente, lo que indica que el puntaje general de esta clase es buena.
Un diagrama de caja es un gráfico estadístico que se puede utilizar para mostrar la distribución de un conjunto de datos. Un diagrama de caja contiene lo siguiente:
- Borde superior (Max): El valor máximo, es decir, el valor más grande en los datos.
- Borde inferior (Min): El valor mínimo, es decir, el valor más pequeño de los datos.
- Mediana: El valor medio de los datos, el valor en el medio después de ordenar los datos por tamaño.
- Cuartil superior (Q3): divide los datos en cuatro partes iguales, el último punto de datos de la parte del límite superior.
- Cuartil inferior (Q1): divide los datos en cuatro partes iguales, el primer punto de datos de la parte límite inferior.
- Límite interior: la distancia entre los cuartiles superior e inferior, denominada "contenedor".
- Límite exterior: La distancia entre los bordes superior e inferior, denominada "bigotes".
El papel del diagrama de caja: - Puede mostrar visualmente la distribución de datos, incluidas estadísticas como valores extremos, medianas y cuartiles de datos, para que las personas puedan comprender la situación de los datos de manera más intuitiva.
- Los valores atípicos se pueden identificar y tratar rápidamente, lo que en algunos casos puede tener un impacto dramático en el análisis de datos.
- Puede comparar la distribución de diferentes grupos de datos, lo que juega un papel importante en el análisis de datos y la toma de decisiones.
Tarea dos:
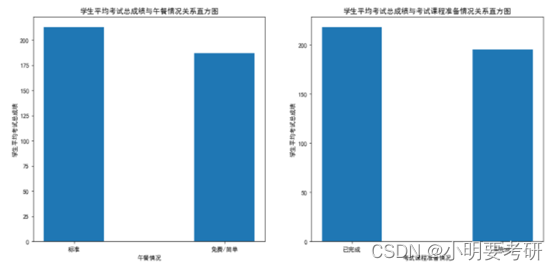
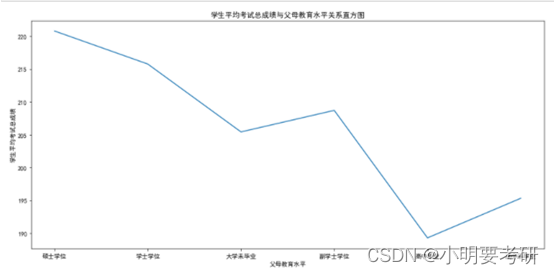
De acuerdo con el gráfico de líneas, se puede ver que existen diferencias en los puntajes promedio totales de las pruebas de los estudiantes con diferentes niveles de educación de los padres. Los hijos de padres con una maestría obtuvieron el puntaje promedio más alto de la prueba general de 220,8, mientras que los hijos de padres que no se graduaron de la escuela secundaria tuvieron el puntaje promedio más bajo de la prueba general de 189,29. Esto sugiere que el nivel de educación de los padres tiene un cierto impacto en el rendimiento académico de los niños.
Además, se puede ver que los hijos de padres con licenciaturas y títulos asociados tienen puntajes promedio totales en las pruebas relativamente más altos, mientras que los hijos de padres que no se graduaron de la universidad tienen puntajes promedio totales en las pruebas más bajos. Esto puede deberse a que los padres con títulos de licenciatura y de asociado tienen mayores expectativas y mejores recursos educativos para la educación de sus hijos, mientras que los padres sin títulos universitarios pueden no brindar el apoyo y los recursos adecuados.
En definitiva, el nivel educativo de los padres tiene un cierto impacto en el rendimiento académico de los hijos, pero no es el único factor, existen otros factores como el talento personal y la actitud de aprendizaje que también afectarán al rendimiento académico.
Tarea tres:
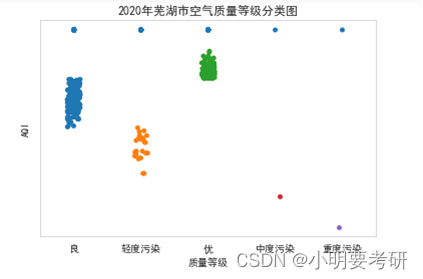
Se puede ver que los valores del índice de calidad del aire (AQI) son diferentes en diferentes momentos. Entre ellos, el valor AQI más alto es 203, que pertenece a la contaminación severa, y el valor AQI más bajo es 22, que es bueno. Al mismo tiempo, se puede observar que la distribución de los valores del AQI muestra una tendencia de que la mayoría de los valores son bajos y algunos valores son altos, es decir, la calidad del aire es buena la mayor parte del tiempo, pero también hay casos de mala calidad del aire en algún momento.
Además, se puede observar que existe cierta correspondencia entre el valor AQI y el nivel de calidad del aire. Cuando el valor AQI está entre 0-50, el nivel de calidad del aire es excelente; cuando está entre 51-100, el nivel de calidad del aire es bueno; cuando está entre 101-150, el nivel de calidad del aire es levemente contaminado; cuando el la calidad del aire está entre 201-300, el nivel de calidad del aire está moderadamente contaminado; cuando está entre 201-300, el nivel de calidad del aire está severamente contaminado. Por lo tanto, el nivel de calidad del aire en ese momento se puede juzgar según el valor AQI.
En una palabra, el índice de calidad del aire (AQI) es un índice importante para medir la calidad del aire, y el cambio de su valor refleja el cambio de la calidad del aire, que tiene un impacto importante en la salud y la vida de las personas.
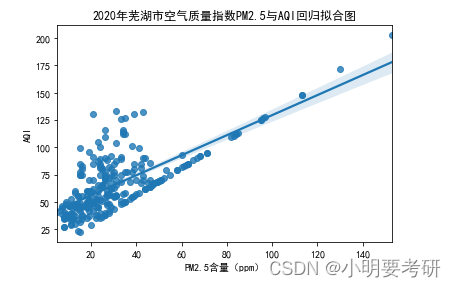
Se puede observar que existe cierta correspondencia entre el valor AQI y el contenido de PM2.5. PM2.5 se refiere al material particulado con un diámetro menor o igual a 2.5 micras en el aire, que es uno de los principales componentes de la contaminación del aire. Se puede ver a partir de los datos que el valor AQI y el valor del contenido de PM2.5 muestran una tendencia constante de cambio la mayor parte del tiempo, es decir, los valores del valor AQI y el contenido de PM2.5 son bajos o altos. . Esto muestra que el contenido de PM2.5 es uno de los factores importantes que afectan el valor AQI.
Además, se puede observar que tanto el valor AQI como el contenido de PM2.5 tienen grandes fluctuaciones, es decir, existen grandes diferencias entre el valor AQI y el contenido de PM2.5 en diferentes momentos. Esto puede deberse a diferentes fuentes de contaminación del aire, cambios en las condiciones meteorológicas y otros factores.
En una palabra, el valor AQI y el contenido de PM2.5 son dos indicadores importantes para reflejar la calidad del aire, y sus cambios reflejan cambios en la calidad del aire, que tienen un impacto importante en la salud y la vida de las personas.
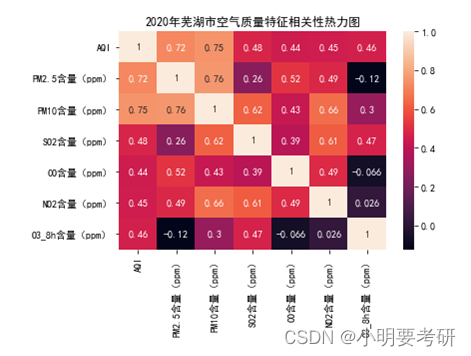
El análisis de correlación de las características de la calidad del aire puede proporcionarnos la relación entre diferentes indicadores de contaminantes, lo que es útil para identificar las principales fuentes de contaminación y formular políticas específicas de ciencia ambiental. Podemos usar el coeficiente de correlación de Pearson para medir la relación lineal entre variables, que va de -1 a +1, donde 0 significa que no hay relación lineal, -1 significa una correlación negativa perfecta y +1 significa una correlación positiva perfecta.
Como se puede ver en la figura anterior, los siguientes datos están correlacionados:
contenido de PM2.5 y contenido de PM10: el coeficiente de correlación es 0.97 y los dos están fuertemente correlacionados positivamente.
Contenido de NO2 y contenido de PM2.5, contenido de PM10: los coeficientes de correlación son 0.79 y 0.78 respectivamente, y el contenido de NO2 se correlaciona positivamente con el contenido de PM2.5 y el contenido de PM10.
Contenido de O3_8h y AQI: el coeficiente de correlación es 0,6 y el AQI se correlaciona positivamente con el contenido de O3_8h.
Cabe señalar que el coeficiente de correlación solo puede reflejar la relación lineal entre las variables, pero no puede representar la relación no lineal, por lo que es necesario considerar otros factores de manera integral en las aplicaciones prácticas.
Tarea cuatro:
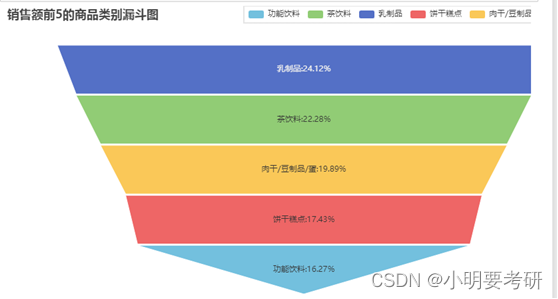
Se puede ver que el volumen de ventas es mejor: productos lácteos, bebidas, cecina, galletas, bebidas funcionales, etc. Estos productos básicos son las necesidades de la vida diaria, y las tiendas pueden vender más de estos productos básicos.

En la imagen de arriba se puede ver que el agua purificada C'estbon es el producto más vendido, seguido de la leche de soya, la salchicha para perros calientes y las galletas de camarones.
Un mapa de nube de palabras es un gráfico que muestra visualmente datos de texto, en el que las palabras de los datos de texto se presentan según la frecuencia y la importancia se distingue por diferentes tamaños o colores de fuente. Por lo general, el mapa de nube de palabras se usa para procesar datos de texto masivos, que pueden comprender rápidamente la información o los temas clave en el texto y ayudar a los usuarios a comprender rápidamente los puntos clave del texto. Es ampliamente utilizado en análisis de sentimientos, análisis de opinión pública, estudios de mercado, informes de noticias y otros campos.
6. Conclusión y experiencia
Como bibliotecas comunes para el análisis visual, matplotlib, seaborn y pyecharts brindan herramientas poderosas, flexibles y fáciles de usar, admiten la generación de varios tipos de gráficos y nos ayudan a comprender mejor los resultados del análisis de datos.
En aplicaciones prácticas, matplotlib es una de las bibliotecas de dibujo más utilizadas. Contiene una gran cantidad de funciones de visualización de datos, admite el dibujo de múltiples tipos de gráficos y estilos personalizados, por lo que puede satisfacer la mayoría de las necesidades de dibujo. Si necesita un trazado más eficiente y visualizaciones más fáciles de leer, seaborn es su primera opción. Es una biblioteca de extensión de matplotlib que proporciona muchas funciones avanzadas y herramientas de trazado, lo que hace que el análisis y la visualización de datos sean más fáciles y elegantes. Para escenarios de visualización de datos más complejos, puede considerar el uso de pyecharts, que es una biblioteca de visualización de Python basada en ECharts, admite la generación de gráficos interactivos dinámicos y puede hacer que la visualización de datos sea más vívida e intuitiva.
En general, la elección de la biblioteca de análisis visual debe depender del tipo de datos y los requisitos de visualización. Hay muchos tipos de gráficos utilizados en el análisis de datos, como gráficos de barras, gráficos de líneas, gráficos circulares, diagramas de dispersión, mapas de calor, etc. Para caracterizar con precisión los datos y sacar conclusiones e inferencias significativas, es necesario elegir las herramientas de visualización y los tipos de gráficos correctos. Además, los hermosos efectos de visualización harán que contar y compartir los resultados del análisis de datos sea más atractivo y convincente. Por lo tanto, la competencia en el uso de bibliotecas de análisis visual es una habilidad esencial para mejorar la eficiencia del trabajo de los analistas y la calidad del análisis de datos.
任务1代码:
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
data = np.load(r'./data/student_grade.npz', encoding='ASCII',
allow_pickle=True)
columns = data['arr_0']
values = data['arr_1']
# 定义成绩变量
sum_score = values[:, -1]
math_grade = values[:, -4]
reading_grade = values[:, -3]
writing_grade = values[:, -2]
all_grade = values[:, -1]
student_id = np.arange(len(values))
p = plt.figure(figsize=(15, 15)) # 设置画布
# 提取学生考试总成绩区间人数
grade_0_150 = 0
grade_150_200 = 0
grade_200_250 = 0
grade_250_300 = 0
for i in range(len(values)):
if 0 < values[i, -1] <= 150:
grade_0_150 += 1
elif 150 < values[i, -1] <= 200:
grade_150_200 += 1
elif 200 < values[i, -1] <= 250:
grade_200_250 += 1
elif 250 < values[i, -1] <= 300:
grade_250_300 += 1
all_stu_grade = [grade_0_150, grade_150_200, grade_200_250, grade_250_300]
饼图:
# 绘制学生考试总成绩的总体分布情况饼图
p = plt.figure(figsize=(9, 9)) # 设置画布
label= ['不及格', '及格', '良好', '优秀']
explode = [0.01,0.01,0.01,0.01] # 设定各项离心n个半径
plt.pie(all_stu_grade, explode=explode, labels=label,
autopct='%1.1f%%', textprops={'fontsize': 15}) # 绘制饼图
plt.title('学生考试总成绩的总体分布情况饼图', fontsize=20)
plt.savefig('./tmp/学生考试总成绩的总体分布情况饼图.png')
plt.show()
#箱线图
# 绘制学生考试总成绩的总体分散情况箱线图
p = plt.figure(figsize=(12, 8))
label= ['总成绩']
gdp = (list(sum_score))
plt.boxplot(gdp,notch=True,labels=label, meanline=True) # 绘制箱线图
plt.xlabel('学生考试科目')
plt.ylabel('学生考试总分数')
plt.title('学生考试总成绩的总体分散情况箱线图', fontsize=20)
plt.savefig('./tmp/学生考试总成绩的总体分散情况箱线图.png')
plt.show()
# 绘制学生考试总成绩的总体分散情况箱线图
p = plt.figure(figsize=(12, 8))
label= ['数学成绩','阅读成绩','写作成绩']
gdp = (list(math_grade), list(reading_grade), list(writing_grade))
plt.boxplot(gdp,notch=True,labels=label, meanline=True) # 绘制箱线图
plt.xlabel('学生考试科目')
plt.ylabel('学生考试分数')
plt.title('学生各项考试成绩的总体分散情况箱线图', fontsize=20)
plt.savefig('./tmp/学生各项考试成绩的总体分散情况箱线图.png')
plt.show()
#任务二
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
data = np.load(r'./data/student_grade.npz', encoding='ASCII', allow_pickle=True)
columns = data['arr_0']
values = data['arr_1']
# 分别提取学生父母教育水平对应的总成绩
master = []
bachelor = []
undergraduate_college = []
associate = []
highschool = []
undergraduate_highschool = []
all_grade = values[:, -1]
for i in range(len(values)):
if values[i, 2] == '硕士学位':
master.append(values[i, -1])
elif values[i, 2] == '学士学位':
bachelor.append(values[i, -1])
elif values[i, 2] == '大学未毕业':
undergraduate_college.append(values[i, -1])
elif values[i, 2] == '副学士学位':
associate.append(values[i, -1])
elif values[i, 2] == '高中毕业':
highschool.append(values[i, -1])
elif values[i, 2] == '高中未毕业':
undergraduate_highschool.append(values[i, -1])
# 分别计算学生父母教育水平对应的总成绩均值
mean_master = round(np.mean(master), 2) #round保留两位小数
mean_bachelor = round(np.mean(bachelor), 2)
mean_undergraduate_college = round(np.mean(undergraduate_college), 2)
mean_associate = round(np.mean(associate), 2)
mean_highschool = round(np.mean(highschool), 2)
mean_undergraduate_highschool = round(np.mean(undergraduate_highschool), 2)
#把平均值加到列表里
mean_education_grade = [mean_master, mean_bachelor,
mean_undergraduate_college, mean_associate,
mean_highschool, mean_undergraduate_highschool]
# 分别提取学生午餐情况对应的总成绩
standard = []
reduced = []
all_grade = values[:, -1]
for i in range(len(values)):
if values[i,3] == '标准':
standard.append(values[i, -1])
else:
reduced.append(values[i, -1])
# 分别计算学生午餐情况对应的总成绩均值
mean_standard = round(np.mean(standard), 2)
mean_reduced = round(np.mean(reduced), 2)
mean_lunch_grade = [mean_standard, mean_reduced]
# 分别提取学生考试准备情况对应的总成绩
completed = []
uncompleted = []
all_grade = values[:, -1]
for i in range(len(values)):
if values[i, 4] == '完成':
completed.append(values[i, -1])
else:
uncompleted.append(values[i, -1])
# 分别计算学生完成考试准备和未完成考试准备对应的总成绩均值
mean_completed = round(np.mean(completed), 2)
mean_uncompleted = round(np.mean(uncompleted), 2)
mean_prepartion_grade = [mean_completed, mean_uncompleted]
# print(mean_prepartion_grade)
p = plt.figure(figsize=(13, 13)) #设置画布
# 子图1
ax1 = p.add_subplot(2, 1, 1)
label = ['硕士学位', '学士学位', '大学未毕业', '副学士学位', '高中毕业', '高中未毕业']
plt.plot(range(6), mean_education_grade) # 绘制折线图
plt.xlabel('父母教育水平')
plt.ylabel('学生平均考试总成绩')
plt.xticks(range(6), label)
plt.title('学生平均考试总成绩与父母教育水平关系直方图')
# 子图2
ax2 = p.add_subplot(2, 2, 3)
label = ['标准', '免费/简单']
plt.bar(range(2), mean_lunch_grade, width=0.4) # 绘制直方图
plt.xlabel('午餐情况')
plt.ylabel('学生平均考试总成绩')
plt.xticks(range(2), label)
plt.title('学生平均考试总成绩与午餐情况关系直方图')
# 子图3
ax2 = p.add_subplot(2, 2, 4)
label = ['已完成', '未完成']
plt.bar(range(2), mean_prepartion_grade, width=0.4) # 绘制直方图
plt.xlabel('考试课程准备情况')
plt.ylabel('学生平均考试总成绩')
plt.xticks(range(2), label)
plt.title('学生平均考试总成绩与考试课程准备情况关系直方图')
plt.savefig('./tmp/学生考试总成绩与各个特征关系图.png')
plt.show()
#任务三
import matplotlib.pyplot as plt
import pandas as pd
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示问题-设置字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
import seaborn as sns
# 读取数据
data = pd.read_csv('./data/aqi.csv')
# --------------------绘制空气质量等级分类图--------------------
with sns.axes_style('whitegrid'):
sns.stripplot(x=data['质量等级'])
ax = sns.stripplot(x='质量等级', y='AQI', data=data, jitter=True)
ax.set_title('2020年芜湖市空气质量等级分类图')
plt.show()
# --------------------绘制AQI与PM2.5线性回归拟合图--------------------
ax = sns.regplot(x='PM2.5含量(ppm)', y='AQI', data=data)
ax.set_title('2020年芜湖市空气质量指数PM2.5与AQI回归拟合图')
plt.show()
# 计算相关系数
corr_data = data.corr()
# --------------------绘制特征相关性热力图--------------------
ax = sns.heatmap(corr_data, annot=True)
ax.set_title('2020年芜湖市空气质量特征相关性热力图')
plt.show()
