Haga clic en la tarjeta a continuación para seguir la cuenta oficial de " CVer "
Mercancías secas pesadas AI/CV, entregadas por primera vez
Haga clic para ingresar —> [Video Comprensión y Transformador] Grupo de Intercambio
Reimpreso de: Xinzhiyuan | Editor: Eneas Tan somnoliento
【Introducción】 Los ex alumnos de la Universidad de Pekín trabajan juntos, ¡Meta lanza el primer modelo multimodal único de la historia! El modelo 7B derrotó a Diffusion y el problema del dibujo a mano perfecto se resolvió perfectamente.
¡Meta está aquí de nuevo!
Justo ahora, Meta lanzó un modelo multimodal basado en Transformer: CM3leon, que ha logrado avances absolutos en los campos de los gráficos de Vincent y la comprensión de imágenes, y puede llamarse el mejor de su tipo.
Además, esta combinación de múltiples modalidades en un solo modelo no tiene precedentes en los sistemas de IA divulgados anteriormente.

Obviamente, esta investigación de Meta define un nuevo estándar para la IA multimodal, lo que indica que el sistema de IA puede cambiar completamente libremente en tareas como comprender, editar y generar imágenes, videos y textos.
Mientras tanto, el lanzamiento de CM3leon marca oficialmente la primera vez que un modelo autorregresivo iguala el rendimiento de los principales modelos de difusión generativa en puntos de referencia clave.

Dirección del artículo: https://ai.meta.com/research/publications/scaling-autoregressive-multi-modal-models-pretraining-and-instruction-tuning/
Anteriormente, los modelos de tres estrellas que recibieron más atención en el campo de gráficos de Vincent fueron Stable Diffusion, DALL-E y Midjourney. La técnica del diagrama de Vinsen se basa básicamente en el modelo de difusión.
Pero el significado revolucionario de CM3leon es que utiliza una tecnología completamente diferente: un modelo autorregresivo basado en tokenizador.
Los resultados muestran que el modelo autorregresivo basado en el tokenizador no solo es más efectivo que el método basado en el modelo de difusión, y logra SOTA en el campo de los grafos vicencianos, sino que además requiere cinco veces menos cálculo de entrenamiento que el anterior método basado en Transformador. !

Prepárate, se acerca una ola de efectos geniales
Solo mirar los indicadores de rendimiento brutos no puede explicar nada.
Donde CM3leon realmente brilla es en el manejo de tareas de edición de imágenes e indicaciones más complejas.
Imágenes renderizadas con precisión con resultados sorprendentes
Por ejemplo, puede representar con precisión imágenes a partir de señales como "pequeño cactus en el Sahara con un sombrero de paja y gafas de sol de neón".

Cualquier aviso, edita las imágenes como quieras
CM3leon también tiene una capacidad única para editar imágenes existentes basadas en instrucciones de texto de forma libre, como cambiar el color del cielo o agregar objetos en ubicaciones específicas.
Las funciones anteriores superan con creces los efectos que pueden lograr modelos como DALL-E 2.

Modelo único multimodal sin precedentes
La arquitectura versátil de CM3leon le permite realizar una transición libre y fluida entre tareas de texto, imagen y composición.
Además de las capacidades de los diagramas de Vincent, CM3leon puede generar anotaciones para imágenes, responder preguntas sobre el contenido de la imagen e incluso crear imágenes a partir de descripciones textuales de cuadros delimitadores y mapas de segmentación.
Esta combinación de modalidades en un solo modelo no tiene precedentes en los sistemas de IA descritos anteriormente.
Pregunta: ¿Qué sostiene el perro? La modelo respondió: palo.
indicador: Describe la imagen dada en detalle. El modelo responde: En esta imagen, un perro sostiene un palo en su boca. Hay hierba en el suelo. La imagen tiene árboles en el fondo.

Dada la descripción del texto de la segmentación del cuadro delimitador de la imagen, que indica dónde se necesita un grupo o un espejo en la imagen, CM3leon puede generar la imagen correspondiente completamente de acuerdo con el aviso.

súper alta resolución
Se puede integrar una plataforma de súper resolución separada con la salida de CM3leon, lo que resulta en un aumento dramático en la resolución y el detalle.
Ingrese el mensaje "una pequeña isla circular en medio del lago, con bosques alrededor del lago, alto contraste"——

Resuelve el problema del pintor AI.
Incluso el antiguo problema de que la IA no podía dibujar manos fue resuelto fácilmente por CM3leon.

¿El modelo autorregresivo vence a Diffusion por primera vez?
En el campo de los diagramas de Vincent que se ha vuelto popular en los últimos años, Midjourney, DALL-E 2 y Stable Diffusion utilizan tecnología de difusión.
Si bien la técnica Diffusion produce resultados sorprendentes, es computacionalmente intensiva, lo que hace que sea computacionalmente intensiva, costosa de ejecutar y, a menudo, carece de la velocidad requerida para aplicaciones en tiempo real.
Curiosamente, OpenAI quería explorar la posibilidad de Transformer como generación de imágenes a través de un modelo llamado Image GPT hace unos años. Pero eventualmente abandonó la idea a favor de Diffusion.
El CM3leon adopta un enfoque completamente diferente. Como modelo basado en Transformer, aprovecha un mecanismo de atención para sopesar la relevancia de los datos de entrada (ya sea texto o imágenes).
Esta diferencia arquitectónica permite que CM3leon logre una velocidad de entrenamiento más rápida y una mejor paralelización, por lo que es más eficiente que los métodos tradicionales basados en difusión.
Con solo una TPU, CM3leon se entrena de manera eficiente en el conjunto de datos de imagen y logra una puntuación FID de 4,88 en el conjunto de datos MS-COCO, superando el modelo Parti de texto a imagen de Google.
Al mismo tiempo, la eficiencia de CM3leon es más de 5 veces mayor que la de la arquitectura similar de Transformer.
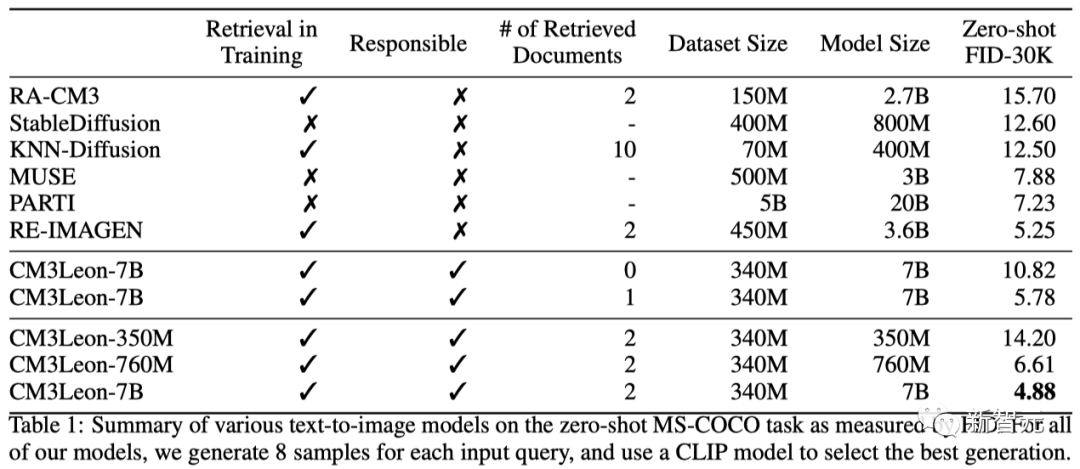
La razón por la que CM3leon tiene tanto éxito se puede atribuir a su arquitectura y método de entrenamiento únicos.
Una clave de su potente rendimiento es la técnica de ajuste fino supervisado (SFT).
SFT se ha utilizado anteriormente para entrenar modelos de generación de texto como ChatGPT con buenos resultados, pero Meta argumenta que también puede ser útil cuando se aplica a imágenes.
De hecho, el ajuste fino de las instrucciones mejoró el rendimiento de CM3Leon no solo en la generación de imágenes, sino también en la escritura de anotaciones de imágenes, lo que le permitió responder preguntas sobre imágenes y mejorar el rendimiento de las imágenes siguiendo instrucciones de texto como "Cambiar el color del cielo a azul brillante." ”) para editar la imagen.
CM3leon emplea solo una arquitectura de decodificador-transformador, similar a los modelos establecidos basados en texto, pero agrega la capacidad de procesar texto e imágenes.
El proceso de capacitación implica el aumento de la recuperación, así como el ajuste fino de las instrucciones en varias tareas de generación de imágenes y texto.
Mediante la aplicación de técnicas de ajuste fino supervisadas multimodales, Meta mejora significativamente el rendimiento de CM3leon en la anotación de imágenes, el control de calidad visual y la edición de texto.
Aunque CM3leon solo se entrena con 3 mil millones de tokens de texto, iguala o incluso supera los resultados de otros modelos entrenados con hasta 100 mil millones de tokens.
Como el primer modelo multimodal sintonizado de manera similar a los modelos de lenguaje de texto, Meta incorpora una etapa de preentrenamiento aumentada de recuperación a gran escala y una segunda etapa de ajuste fino supervisado (SFT) multitarea en CM3leon.
¿Cómo funciona CM3leon?
Con las capacidades de CM3leon, las herramientas de generación de imágenes pueden producir imágenes más consistentes que siguen mejor las señales de entrada.
La siguiente es una demostración de las capacidades de CM3leon en varias tareas, todas completadas por un solo modelo:
generación de texto a imagen
La edición de imágenes basadas en texto (por ejemplo, "cambiar el color del cielo a azul brillante") es un desafío porque requiere que el modelo comprenda tanto las instrucciones textuales como el contenido visual.
Especialmente cuando se trata de objetos complejos o cuando la sugerencia contiene múltiples restricciones que deben estar presentes en la salida.
A partir de un texto de aviso con una estructura altamente compositiva, CM3leon puede generar una imagen a seguir.

(1) Pequeño cactus con sombrero de paja y gafas de sol de neón en el desierto del Sahara
(2) Primer plano de una mano humana
(3) El personaje principal del mapache en el anime se prepara para participar en una batalla épica empuñando una katana.
(4) Una señal de alto en estilo de fantasía con las palabras "1991"
Edición de imágenes basada en texto
Dada una imagen y un mensaje de texto, CM3leon puede editar la imagen de acuerdo con las instrucciones del texto.
Debido a la generalidad del modelo CM3leon, esto se logra con el mismo modelo que las otras tareas, a diferencia de los modelos anteriores (como InstructPix2Pix) que solo se ajustaron para la edición de imágenes basadas en texto.

Al mismo tiempo, el modelo CM3leon también puede generar descripciones cortas o largas y responder preguntas sobre imágenes basadas en una serie de indicaciones diferentes.
Toma una castaña.
- pista:
Pregunta: ¿Qué tienen en común estos dos objetos?
Contexto: Elija la mejor respuesta.
Opciones: (A) Brillante (B) Salado
Respuesta: Pensemos paso a paso:
- Salida CM3Leon:
Piensa en cada objeto. Las patatas fritas son saladas. Los pretzels son salados. Entonces la respuesta es (B).

- pista:
Describir en detalle todos los objetos en una imagen dada.
- Salida CM3Leon:
Un cartel de la calle se asienta sobre un poste de metal. El logotipo es azul con texto en blanco. Hay una luz roja en el poste. El cielo es azul brillante. Hay coches aparcados en la calle. Hay árboles a ambos lados de la calle. Hay edificios a ambos lados de la calle.

Del mismo modo, CM3leon puede manejar fácilmente las siguientes "preguntas y respuestas con imágenes".
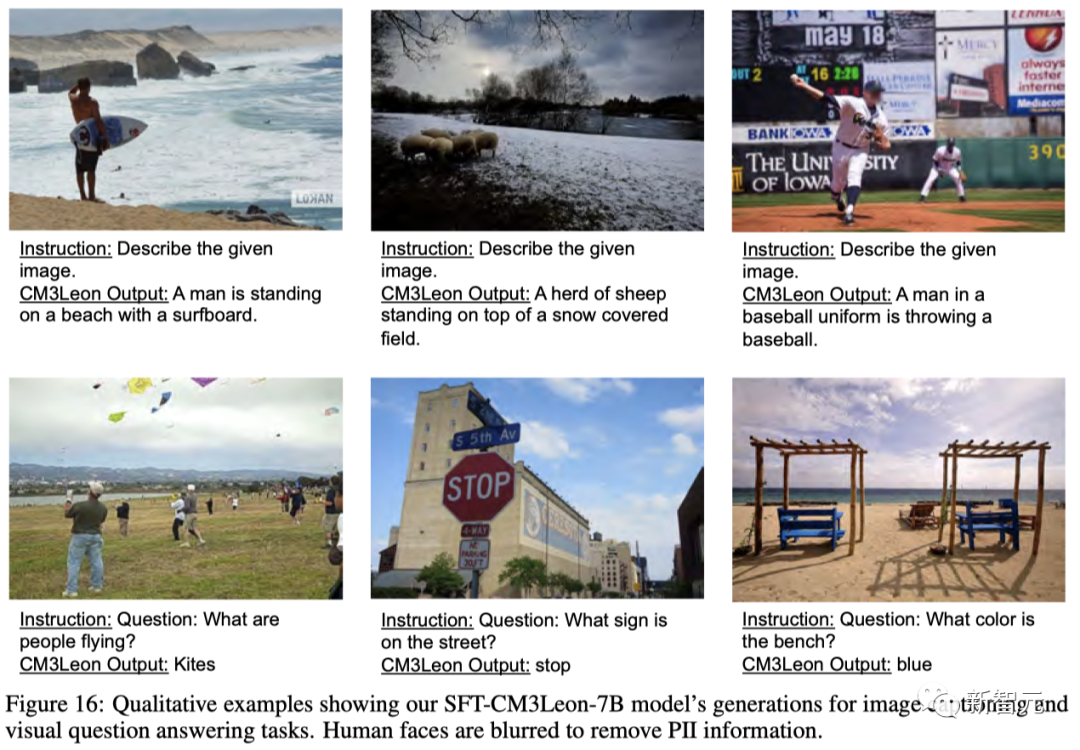
Para obtener más información sobre CM3leon, Meta evalúa empíricamente los modelos de instrucción ajustados en la generación de subtítulos de imagen y las tareas de respuesta de preguntas visuales, y los compara con los puntos de referencia anteriores de SOTA.
En comparación con Flamingo (100B) y OpenFlamingo (40B), los datos de texto del modelo CM3leon son significativamente menores (aproximadamente 3B tokens).
Pero en términos de descripción de imagen MS-COCO y respuesta a preguntas VQA2, CM3leon logró el mismo rendimiento que OpenFlamingo de muestra cero e incluso superó a Flamingo por casi 10 puntos porcentuales en la tarea VizWiz.
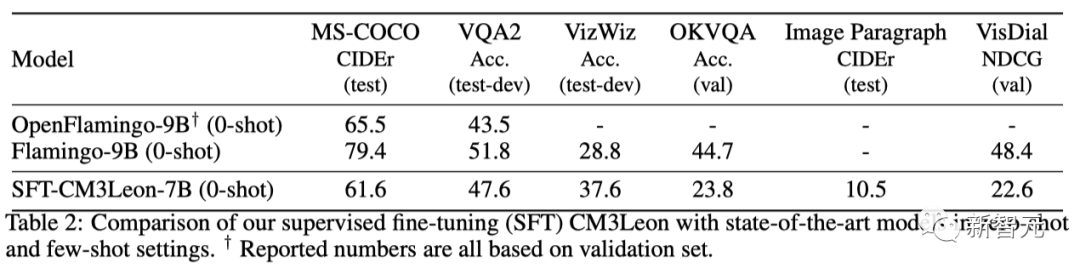
Edición de imágenes guiada por estructura
La edición de imágenes guiada por la estructura tiene como objetivo comprender e interpretar las instrucciones textuales proporcionadas junto con la información estructural o de diseño.
Esto permite que los modelos CM3leon creen compilaciones de imágenes visualmente consistentes y contextualmente apropiadas mientras se adhieren a las instrucciones estructurales o de diseño dadas.
En una imagen que contiene solo segmentaciones (sin categorías de texto), genere una imagen. La entrada aquí representa la imagen de la que se extrae la segmentación.

súper resolución
Además de esto, existe un truco común en el campo de la generación de imágenes: utilizar una etapa de súper resolución entrenada por separado para generar imágenes de mayor resolución a partir de la salida del modelo original.
Para este tipo de tarea de generación de texto a imagen, CM3leon también funciona muy bien.

(1) Una taza de café humeante con montañas al fondo, descansando en el camino
(2) Al atardecer, la hermosa y majestuosa carretera
(3) Una isla circular en el centro del lago rodeada de bosques
Y alguna generación de estilo "fantasía".

(1) Tortugas marinas nadando bajo el agua
(2) Los elefantes nadan bajo el agua
(2) Un rebaño de ovejas
Cómo construir CM3Leon
arquitectura
En términos de arquitectura, CM3Leon utiliza un transformador de solo decodificador similar a un modelo de texto maduro.
Pero la diferencia es que CM3Leon puede ingresar y generar texto e imágenes.
tren
Al adoptar la tecnología de mejora de recuperación de entrenamiento propuesta en el documento "Modelado de lenguaje multimodal aumentado por recuperación", Meta mejora en gran medida la eficiencia y la capacidad de control del modelo CM3Leon.
Al mismo tiempo, Meta también afinó el modelo CM3Leon en varias tareas de generación de imágenes y texto.
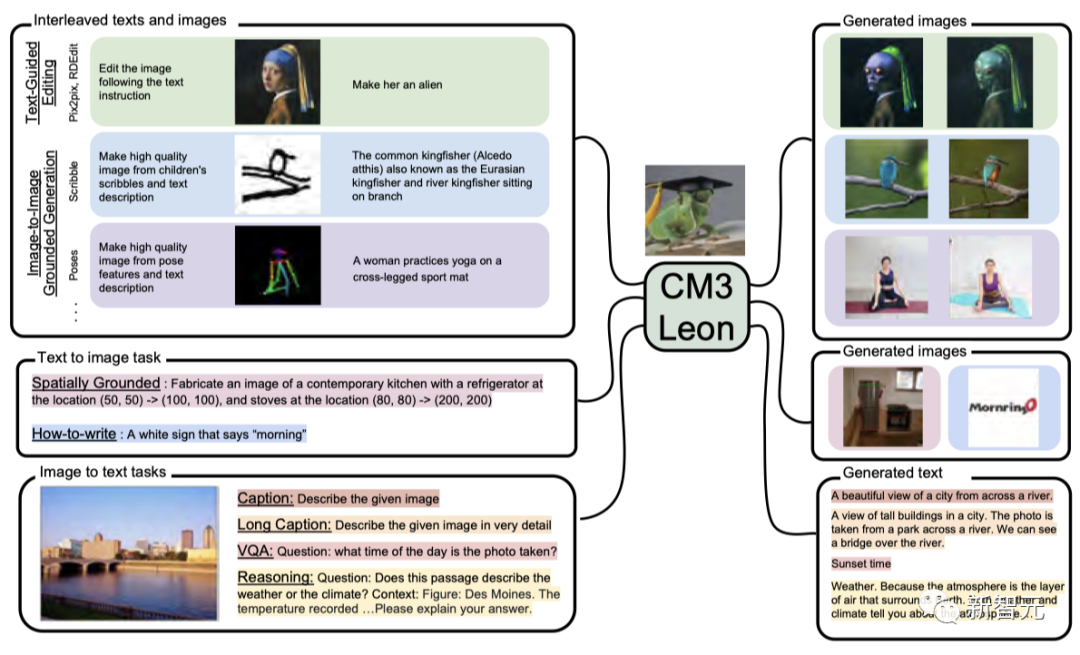
Izquierda: entradas comunes para varias tareas; derecha: salidas del modelo correspondiente.
Durante el entrenamiento, Meta concatena entradas y salidas del modelo y entrena con el mismo objetivo que en la etapa de preentrenamiento.
A medida que la industria de la IA continúa creciendo, los modelos generativos como CM3Leon se vuelven más complejos.
Estos modelos aprenden la relación entre la visión y el texto entrenando en millones de imágenes de ejemplo, pero también pueden reflejar sesgos presentes en los datos de entrenamiento.
Por lo tanto, Meta adopta el conjunto de datos con licencia para entrenar a CM3Leon.
Los resultados también demuestran que CM3Leon aún logra un desempeño sólido, aunque la distribución de los datos es bastante diferente de los modelos anteriores.
En este sentido, Meta espera que con el esfuerzo conjunto de todos se pueda construir un modelo más preciso, equitativo y equitativo.
Allanando el camino para los modelos de lenguaje multimodal
En general, Meta cree que el excelente desempeño de CM3Leon en varias tareas es un paso importante hacia la generación y comprensión de imágenes más realistas.
Y, en última instancia, dicho modelo puede ayudar a mejorar la creatividad y lograr mejores aplicaciones en el metaverso.
Sobre el Autor
Lili Yu, Bowen Shi y Ramakanth Pasunuru son coautores del artículo.
Entre ellos, Lili Yu obtuvo una licenciatura del Departamento de Física de la Universidad de Pekín y un doctorado en ingeniería eléctrica e informática del MIT.

Referencias:
https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
https://www.maginative.com/article/meta-revela-cm3leon-a-breakthrough-ai-model-for-advanced-text-to-image-generation-and-image-understanding/
https://techcrunch.com/2023/07/14/meta-generative-transformer-art-model/
Haga clic para ingresar —> [Video Comprensión y Transformador] Grupo de Intercambio
ICCV/CVPR 2023 Descarga de papel y código
Respuesta de antecedentes: CVPR2023, puede descargar la colección de documentos CVPR 2023 y codificar documentos de código abierto
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集视频理解和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-视频理解或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如视频理解或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号No es fácil de organizar, dale me gusta y mira![]()