1. Introducción a Kafka
- Kafka es un sistema de mensajería distribuido de publicación y suscripción que puede procesar rápidamente flujos de datos de alto rendimiento y distribuir datos a múltiples consumidores en tiempo real. El sistema de mensajería de Kafka consta de varios intermediarios (servidores), que se pueden distribuir en varios centros de datos para proporcionar alta disponibilidad y tolerancia a fallas.
- La arquitectura básica de Kafka consta de productores, consumidores y temas. Los productores pueden publicar datos en temas específicos y los consumidores pueden suscribirse a estos temas y consumir datos de ellos. Al mismo tiempo, Kafka también admite el procesamiento y la conversión de flujos de datos, y la computación de flujos se puede realizar a través de la API de Kafka Streams en la canalización, como filtrado, conversión, agregación, etc.
- Kafka utiliza técnicas eficientes de almacenamiento y administración de datos que pueden manejar fácilmente volúmenes de datos de nivel TB. Sus ventajas incluyen alto rendimiento, baja latencia, escalabilidad, persistencia y tolerancia a fallas, entre otras.
- Kafka se usa ampliamente en aplicaciones de nivel empresarial, incluido el procesamiento de secuencias en tiempo real, la agregación de registros, la supervisión y el análisis de datos. Al mismo tiempo, Kafka también se puede integrar con otras herramientas de macrodatos, como Hadoop, Spark y Storm, para crear un ecosistema completo de procesamiento de datos.
1. El papel de MQ
MQ: MessageQueue, cola de mensajes. La cola es una estructura de datos FIFO primero en entrar, primero en salir. Los mensajes son datos pasados a través de procesos. Un sistema MQ típico enviará mensajes de los productores a MQ para ponerlos en cola y luego los entregará a los consumidores de mensajes en un orden determinado para su procesamiento.
El papel de MQ tiene principalmente los siguientes tres aspectos:
Recorte de pico de desacoplamiento asíncrono
2. Por qué usar Kafka
Un escenario de aplicación típico de agregación de registros:
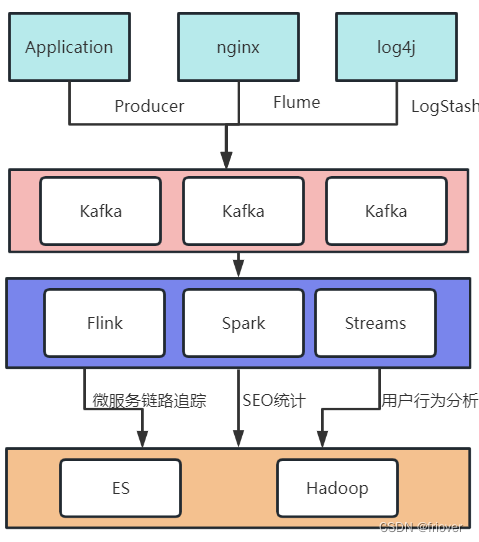
El escenario de negocio determina las características del producto.
1. El rendimiento de datos es muy grande: es necesario recopilar rápidamente registros masivos de varios canales
2. Alta tolerancia a fallas del clúster: permitir que una pequeña cantidad de nodos en el clúster se bloqueen
3. La función no necesita ser demasiado complicada: Kafka está diseñado con alto rendimiento, baja latencia y escalabilidad, centrándose en la entrega de mensajes en lugar del procesamiento de mensajes. Por lo tanto, Kafka no admite funciones avanzadas como colas de mensajes fallidos y mensajes secuenciales.
4. Se permite una pequeña cantidad de pérdida de datos: el propio Kafka optimiza constantemente los problemas de seguridad de los datos. En la actualidad, básicamente se puede considerar que Kafka no puede perder datos.
2. Habilidad rápida de Kafka
1. Ambiente experimental
Se prepararon tres máquinas virtuales 192.168.85.200~202, listas para construir un clúster de tres máquinas.
Las tres máquinas están preinstaladas con el sistema operativo CentOS7. Configure los nombres de las máquinas master, node1, node2 respectivamente.
vi /etc/hosts
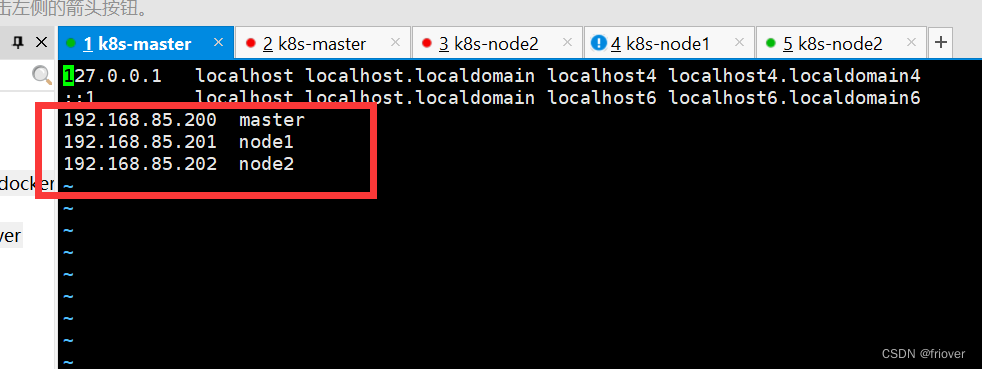
Luego, debe apagar el firewall (se recomienda apagarlo en el entorno experimental).
firewall-cmd --state 查看防火墙状态
systemctl stop firewalld.service 关闭防火墙
Luego, JAVA debe instalarse en las tres máquinas.
Descarga kafka y selecciona la última versión 3.2.0. Dirección de descarga: https://kafka.apache.org/downloads Seleccione kafka_2.13-3.4.0.tgz para descargar.
En cuanto a la versión de Kafka, la anterior 2.13 es la versión del lenguaje Scala utilizada para desarrollar Kafka, y la última 3.4.0 es la versión de la aplicación Kafka.
Scala es un lenguaje que se ejecuta en la máquina virtual JVM. En tiempo de ejecución, solo necesita instalar el JDK, y no importa qué versión de Scala elija. Pero si desea depurar el código fuente, debe seleccionar la versión de Scala correspondiente. Porque la versión del lenguaje Scala no es compatible con versiones anteriores.
Descargue Zookeeper, la dirección de descarga es https://zookeeper.apache.org/releases.html, la versión de Zookeeper no es obligatoria, aquí elegimos la versión más nueva 3.6.1.
El programa de instalación de kafka viene con Zookeeper, y puede ver el paquete jar del cliente de zookeeper en el directorio libs del paquete de instalación de kafka. Sin embargo, en circunstancias normales, para facilitar el mantenimiento de la aplicación, utilizaremos Zookeeper implementado por separado en lugar del Zookeeper que viene con Kafka.
Una vez completada la descarga, cargue los dos kits de herramientas en los tres servidores, descomprímalos y colóquelos en los directorios /app/kafka y /app/zookeeper respectivamente. Y configure la ruta del directorio bin en el directorio de implementación a la variable de entorno de ruta.
2. Experiencia de servicio independiente
El paquete de instalación de Kafka descargado no requiere ninguna configuración, puede hacer clic directamente para ejecutarlo. Este suele ser el primer paso para conocer a Kafka rápidamente.
- Zookeeper debe iniciarse antes de iniciar Kafka. **Aquí se usa el Zookeeper que viene con Kafka. El script de inicio está en el directorio bin.
#解压
tar -zxvf kafka_2.13-3.4.0.tgz
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
Puede ver en nohup.out que zookeeper se iniciará en el puerto 2181 de forma predeterminada. Vea un proceso QuorumPeerMain a través del comando jps para confirmar que el servicio se inició correctamente.
- Iniciar Kafka
nohup bin/kafka-server-start.sh config/server.properties &
Una vez que se complete el inicio, use el comando jps para ver un proceso kafka para confirmar que el servicio se inició correctamente. El servicio se iniciará en el puerto 9092 de forma predeterminada.
- El mecanismo de trabajo básico
de Kafka es que el remitente del mensaje puede enviar el mensaje al tema especificado en Kafka, y el consumidor del mensaje puede consumir el mensaje del tema especificado.
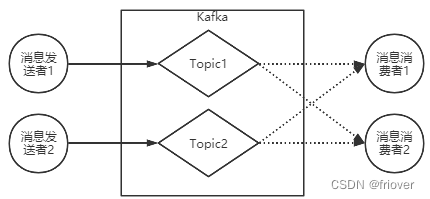
Primero, puede usar la secuencia de comandos del cliente proporcionada por Kafka para crear un tema
#创建Topic
bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092
#查看Topic
bin/kafka-topics.sh --describe --topic test --bootstrap-server localhost:9092
Luego, inicie un lado del remitente del mensaje. Envía un mensaje a un tema llamado prueba.
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Después de que aparezca el símbolo > en la línea de comando, ingrese algunos caracteres a voluntad. Ctrl+C Sale de la línea de comando. Esto completa la operación de envío de mensajes a Kafka.
A continuación, inicie un consumidor de mensajes para recibir mensajes del tema llamado prueba.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
Esto completa una interacción básica. Entre ellos, productores y consumidores no necesitan empezar al mismo tiempo. Se pueden intercambiar datos entre ellos, pero no dependen unos de otros. Sin productores, los consumidores aún pueden trabajar normalmente y, a la inversa, sin consumidores, los productores aún pueden trabajar normalmente. Esto también refleja el desacoplamiento entre productores y consumidores.
4. Otros patrones de consumo
Anteriormente, comenzamos un productor de mensajes y un consumidor de mensajes simples a través de los scripts de productor y consumidor proporcionados por kafka De hecho, kafka también proporciona una gran cantidad de métodos de consumo de mensajes.
Especificar el progreso del consumo
El consumidor de la consola iniciado por kafka-console.consumer.sh generará el contenido obtenido en la línea de comando. Si desea consumir el mensaje enviado anteriormente, puede especificarlo agregando el parámetro --from-begining.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test
Si necesita un consumo de mensajes más preciso, puede incluso especificar desde qué mensaje comenzar a consumir.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --partition 0 --offset 4 --topic test
Esto significa leer desde el cuarto mensaje en la Partición No. 0. Qué son Partición y Compensación, puede usar el siguiente comando para ver.
Consumo de grupo
Para cada consumidor, se puede especificar un grupo de consumidores. El mismo mensaje en Kafka solo puede ser consumido por un determinado consumidor en el mismo grupo de consumidores. Otros consumidores que no pertenecen al mismo grupo de consumidores también pueden consumir este mensaje.
En el script kafka-console-consumer.sh, el grupo de consumidores al que pertenece se puede especificar mediante –consumer-property group.id=testGroup. Por ejemplo, se pueden iniciar tres grupos de consumidores para verificar el mecanismo de consumo del grupo:
#Dos instancias de consumidores pertenecen al mismo grupo de consumidores
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGrroup --topic test
bin/kafka-console-consumer .sh --bootstrap-server localhost:9092
--consumer-property group.id=testGrroup --topic test
#Esta instancia de consumidor pertenece a un grupo de consumidores diferente bin/kafka-console-consumer.sh --bootstrap-server localhost: 9092 - -consumer-property group.id=testGrroup2 --topic test
Ver el desplazamiento del grupo de consumidores
A continuación, también puede utilizar kafka-consumer-groups.sh para observar la situación de los grupos de consumidores. Incluyendo su progreso de consumo.
查看消费者组的偏移量
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testGroup

3. Comprender el mecanismo de mensajería de Kakfa
A partir de experimentos anteriores, podemos ver que el remitente y el consumidor de mensajes de Kafka se comunican entre sí a través de un concepto lógico como Tema. Pero, de hecho, todos los mensajes se almacenan en una estructura de datos como Partición en el lado del servidor.
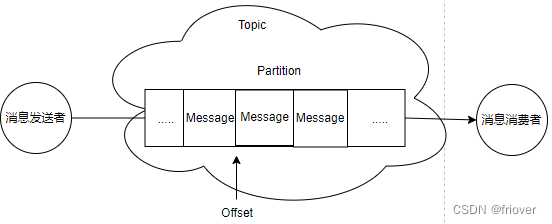
En el sistema técnico de Kafka, es necesario familiarizarse con los siguientes conceptos:
- Cliente Cliente: Incluye productores de mensajes y consumidores de mensajes.
- Grupo de consumidores: cada consumidor puede especificar un grupo de consumidores al que pertenece, y los consumidores del mismo grupo de consumidores juntos forman un grupo de consumidores lógico. Cada mensaje será consumido por múltiples grupos de consumidores interesados, pero dentro de cada grupo de consumidores, un mensaje solo se consumirá una vez.
- Server Broker: un servidor Kafka es un Broker.
- Topic: Este es un concepto lógico, se considera Topic a un grupo de mensajes con el mismo significado comercial. Los clientes producen o consumen temas que les interesan vinculando Tema.
- Partición Partición: el tema es solo un concepto lógico y la partición es el componente que realmente almacena los mensajes. Cada partición es una estructura de cola de cola. Todos los mensajes se almacenan en estas particiones de partición en orden FIFO primero en entrar, primero en salir.
4. Servicio de clúster de Kafka
¿Por qué usar un clúster?
En el servicio independiente, Kafka ya tiene un rendimiento muy alto. TPS puede alcanzar el nivel del millón. Sin embargo, cuando se usa en el trabajo real, Kafka construido en una sola máquina tendrá grandes limitaciones.
Por un lado: hay que guardar demasiados mensajes por separado. Kafka está diseñado para mensajes masivos. Habrá muchos mensajes bajo un tema y es difícil que sobrevivan los servicios independientes. Estos mensajes deben dividirse en diferentes particiones y distribuirse a múltiples agentes diferentes. De esta forma, cada Broker solo necesita guardar una parte de los datos. El número de estas particiones se denomina número de particiones.
Por otro lado: el servicio es inestable y los datos se pierden fácilmente. En el servicio independiente, si el servicio falla, los datos se perderán. Para garantizar la seguridad de los datos, es necesario configurar una o más copias de seguridad para cada partición para garantizar que los datos no se pierdan. En el modo de clúster de Kafka, cada partición tiene una o más copias de seguridad. Kafka utilizará un clúster unificado de Zookeeper como centro de elección para elegir un líder de nodo maestro para cada partición, y los otros nodos son seguidores de nodos esclavos. El nodo maestro es responsable de responder a solicitudes comerciales específicas de los clientes y guardar mensajes. El nodo esclavo es responsable de sincronizar los datos del nodo maestro. Cuando el nodo maestro falla, Kafka elegirá un nodo esclavo para que se convierta en el nuevo nodo maestro.
Por último: la información del agente en el clúster de Kafka, incluida la información de elección de partición, se almacenará en el clúster Zookeeper implementado adicionalmente, de modo que el clúster de Kafka no se interrumpa debido a la caída de algunos servicios del agente.
La arquitectura de clúster de Kafka es más o menos así:
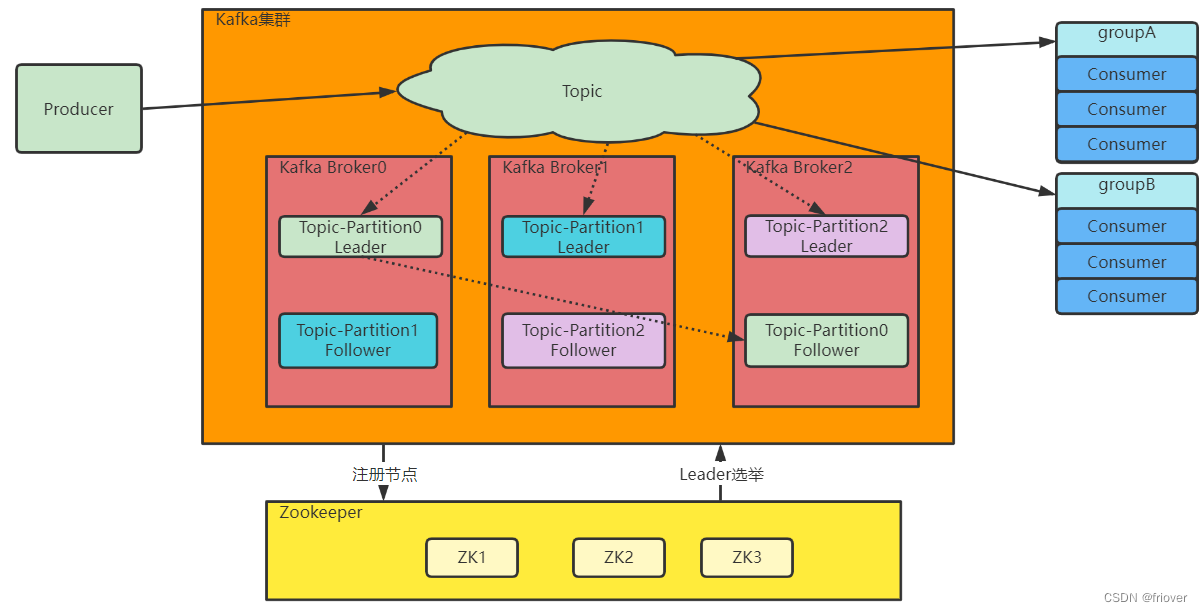
primero, implemente un clúster de Kafka basado en Zookeeper. Entre ellos, en la parte del centro de elección, Zookeeper es un mecanismo de elección con consenso mayoritario, que permite que falle una pequeña cantidad de nodos en el clúster. Por lo tanto, cuando se construye un clúster, los nodos con números impares, como 3, 5 y 7, generalmente se usan para maximizar la alta disponibilidad del clúster. En los experimentos posteriores, implementaremos Zookeeper y Kafka en los tres servidores.
1. Implemente el clúster de Zookeeper
Aquí, el Zookeeper descargado previamente se usa para implementar el clúster. Zookeeper es un mecanismo de elección por consenso mayoritario que permite que falle una minoría de nodos en el clúster. Por lo tanto, cuando se crea un clúster, generalmente se usa un número impar de nodos para maximizar la alta disponibilidad del clúster. En el proceso de implementación posterior, implementaremos Zookeeper en los tres servidores.
Aquí, el Zookeeper descargado previamente se usa para implementar el clúster. Zookeeper es un mecanismo de elección por consenso mayoritario que permite que falle una minoría de nodos en el clúster. Por lo tanto, cuando se crea un clúster, generalmente se usa un número impar de nodos para maximizar la alta disponibilidad del clúster. En el proceso de implementación posterior, implementaremos Zookeeper en los tres servidores.
Luego ingrese al directorio conf y modifique el archivo de configuración. En el directorio conf, se proporciona un archivo zoo_sample.cfg, que es un archivo de muestra. Solo necesitamos copiar este archivo a zoo.cfg (cp zoo_sample.cfg zoo.cfg), y modificar la configuración de claves en él. Entre ellos, los parámetros clave de modificación son los siguientes:
#Directorio de datos locales de Zookeeper, el valor predeterminado es /tmp/zookeeper. Este es el directorio temporal de Linux y se eliminará en cualquier momento.
dataDir=/app/zookeeper/data #
Puerto de servicio de Zookeeper
clientPort=2181
#Configuración de nodo de clúster
server.1=192.168.85.200:2888:3888
server.2=192.168.85.201:2888:3888
server.3=192.168.85.202: 2888 :3888
Entre ellos, clientPort 2181 es un puerto de servicio abierto a los clientes. Y cree myid en /app/zookeeper/data, correspondiente al servidor de zookeeper.*
En la parte de configuración del clúster, la x en server.x es el myid del nodo en el clúster. Este último puerto 2888 es el puerto utilizado para la transmisión de datos dentro del clúster. 3888 es el puerto utilizado para la elección dentro del clúster.
A continuación, distribuya todo el directorio de la aplicación Zookeeper a las otras dos máquinas. Puede iniciar el servicio Zookeeper en las tres máquinas.
bin/zkServer.sh --config conf inicio
Verifique el estado, el zoopper del servidor node2 es el líder del grupo
bin/zkServer.sh status

2. Implementar el clúster de Kafka
No es necesario elegir el servicio de Kafka, por lo que no se sugiere una cantidad impar de servicios.
La forma de implementar Kafka es similar a la de implementar Zookeeper, que consiste en descomprimir, configurar e iniciar servicios.
Primero descomprima Kafka en el directorio /app/kafka.
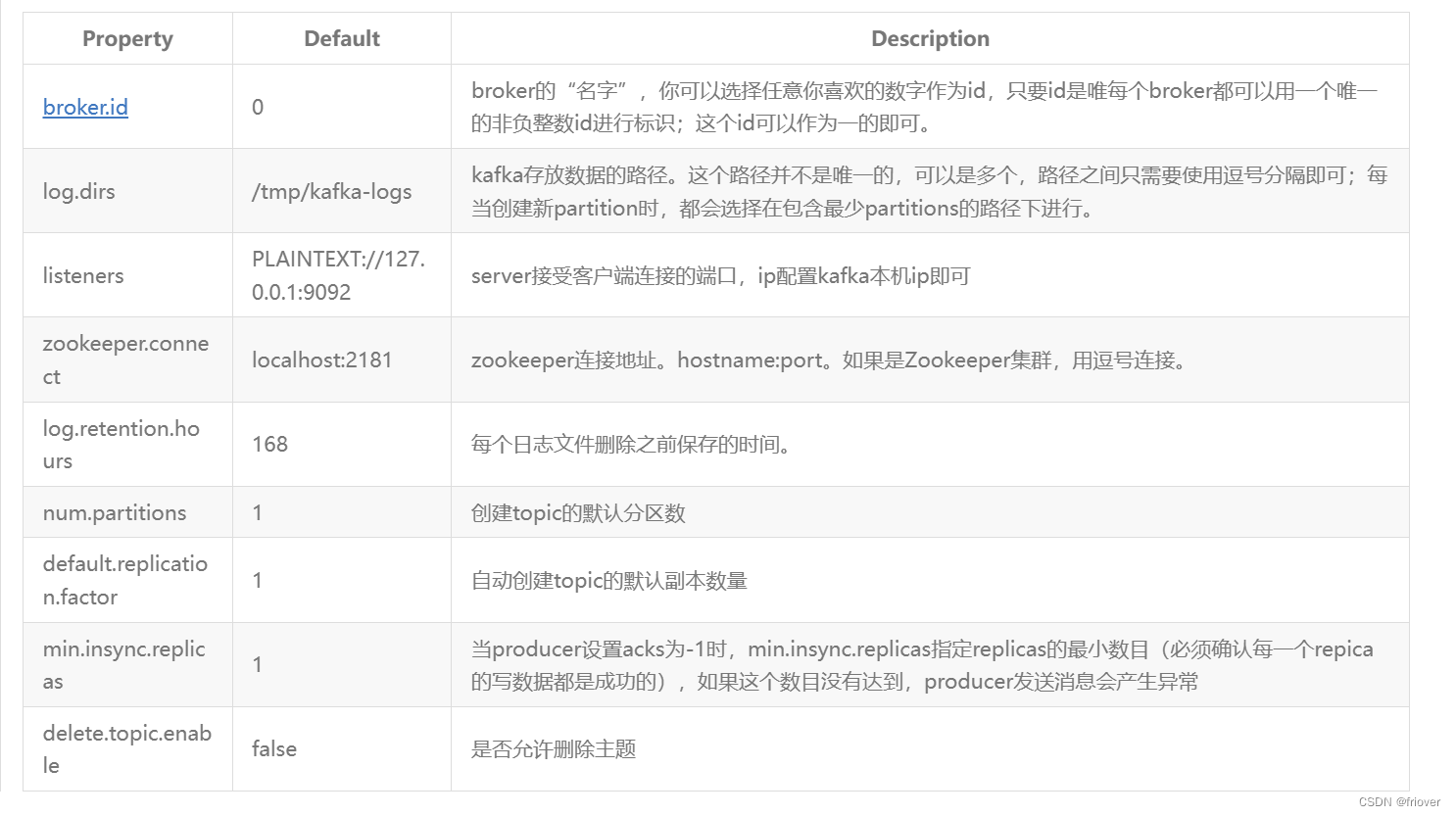
Luego ingrese al directorio de configuración y modifique server.properties. Hay muchos elementos de configuración en este archivo de configuración y, a continuación, se enumeran algunas configuraciones en las que se debe centrar la atención.
El número único global de #broker no se puede repetir, solo puede ser un número.
broker.id=0
#Dirección del archivo de datos. Se da el mismo valor predeterminado al directorio /tmp.
log.dirs=/app/kafka/logs
#El número predeterminado de particiones para cada tema
num.partitions=1 #
dirección del servicio zookeeper
zookeeper.connect=master:2181,node1:2181,node2:2181
El broker.id debe ser diferente en cada servidor. Al distribuir a otros servidores, preste atención a modificarlo.
Múltiples servicios de Kafka registrados en nodos en el mismo clúster de zookeeper formarán automáticamente un clúster.
Los comentarios en el archivo de configuración son muy detallados, puede prestarles atención. Las siguientes son las configuraciones centrales más importantes en el archivo server.properties
prueba de inicio
bin/kafka-server-start.sh -daemon config/server.properties
-daemon significa iniciar el servicio kafka en segundo plano, de modo que la ventana de comandos actual no esté ocupada.
El proceso de Kafka se puede ver a través del comando jps.
5. Comprender el tema, la partición y el intermediario del servidor
A continuación, puede comparar los servicios independientes anteriores para comprender rápidamente los temas principales, las particiones y los agentes del clúster de Kafka.
./kafka-topics.sh --bootstrap-server master:9092 --create --replication-factor 2 --partitions 4 --topic disTopic Created topic disTopic.
./kafka-topics.sh --bootstrap-server master:9092 --describe --topic disTopic

1. –create crea un clúster, puede especificar algunos parámetros complementarios. La mayoría de los parámetros pueden especificar valores predeterminados en el archivo de configuración.
- El parámetro partitons indica el número de particiones, y los mensajes bajo este tema se almacenarán en estas particiones diferentes. El disTopic creado en el ejemplo especifica cuatro particiones, lo que significa que los mensajes bajo este tema se dividirán en cuatro partes.
- El factor de replicación indica cuántas copias de seguridad tiene cada partición. El disTopic creado en el ejemplo especifica dos copias de seguridad para cada partición.
2. –describa la información de View Topic.
- El parámetro de partición enumera cuatro particiones, seguidas de números de partición para identificar estas particiones.
- Leader indica cuál es el nodo Leader en este grupo de particiones. El nodo líder es el nodo maestro responsable de responder a las solicitudes de los clientes. Se puede ver desde aquí que a cada Partición en Kafka se le asignará un Líder, lo que significa que cada Partición tiene diferentes nodos responsables de responder a las solicitudes de los clientes. De esta manera, las solicitudes del cliente se pueden distribuir tanto como sea posible.
- El parámetro Réplicas indica en qué agentes se asignan las copias de seguridad múltiples de esta partición. También conocido como RA. El 0, 1 y 2 aquí corresponden al broker.id especificado al configurar el clúster. Sin embargo, lo que las réplicas enumeran es solo una asignación lógica y no le importa si los datos se asignan realmente de acuerdo con esto. Incluso después de que algunos servicios de nodo estén inactivos, el ID del nodo seguirá apareciendo en Réplicas.
- El parámetro ISR indica la asignación real de la partición. Es un subconjunto de AR y solo enumera aquellos nodos de Broker que están actualmente activos y pueden sincronizar datos normalmente.
A continuación, también podemos comprobar la distribución de particiones en Tema. En Broker, la parte más relacionada con las noticias es Partition. Al configurar el clúster de Kafka anteriormente, se especificó un atributo log.dirs, que apuntaba a un directorio de registro en un servidor. Al ingresar a este directorio, puede ver el estado actual de los datos de cada Broker.

De todo el proceso, podemos ver que en Kafka, Topic es una unidad lógica de recopilación de datos. Los datos bajo el mismo tema en realidad se almacenan en la partición de partición, y la partición es la unidad física de almacenamiento de datos. Broker es el portador físico de Partition, y estas particiones de Partition se distribuirán a diferentes máquinas Broker de la manera más uniforme posible. El desplazamiento que se tocó antes es el desplazamiento de cada mensaje en la partición
¿Por qué Kafka diseña la relación entre Tema, Partición y Broker de esta manera?
1. El diseño de Kafka debe admitir cantidades masivas de datos, y una cantidad tan grande de datos no se puede almacenar en un solo corredor. Luego divídalo en varias particiones, y cada corredor solo almacena una parte de los datos. Esto amplía enormemente el rendimiento del clúster.
2. Cada partición retiene una parte de la copia del mensaje.Si se coloca en un Broker, es propensa a un único punto de falla. Por lo tanto, se diseña un nodo seguidor para que cada partición realice una copia de seguridad de los datos para garantizar la seguridad de los datos. Además, el diseño de Partición de copia de seguridad múltiple también mejora la concurrencia al leer mensajes.
3. Entre las múltiples Particiones de un mismo Tema, se generará una Partición como Líder. Esta Partición Líder será responsable de responder a las solicitudes de los clientes y distribuir los datos a otras Particiones.
6. Resumen del capítulo: la estructura general del clúster de Kafka
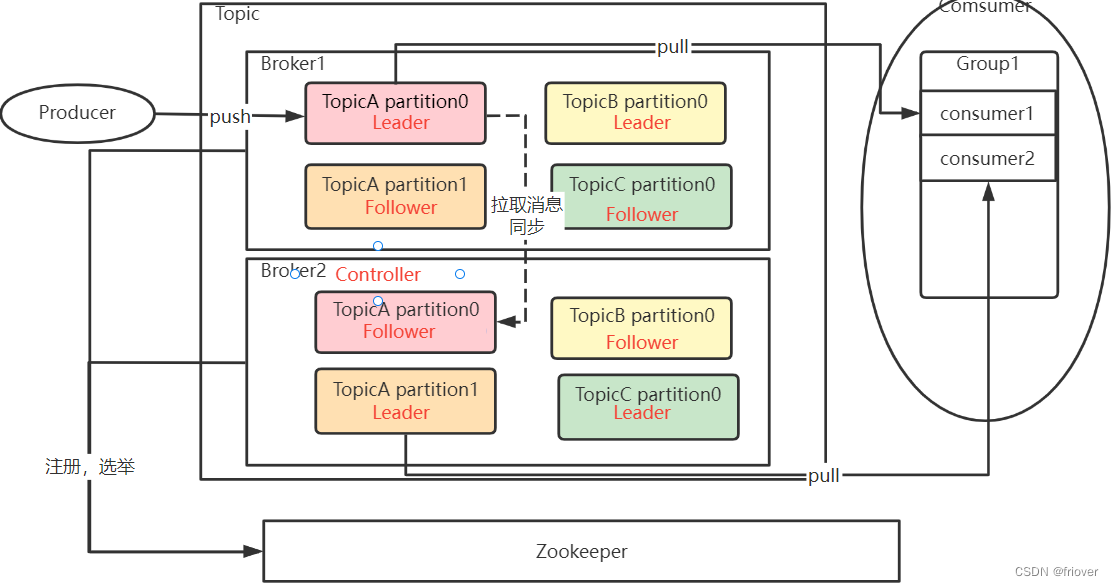
1. Tema es un concepto lógico. Productor y Consumidor realizan comunicación comercial a través de Tema.
2. Topic no almacena datos, y los datos bajo Topic se dividen en múltiples grupos de particiones, que se distribuyen de la manera más uniforme posible a cada corredor. Cada conjunto de particiones contiene mensajes para la siguiente parte del tema. Cada partición contiene una partición líder y varias particiones seguidoras para respaldo.La cantidad de particiones en cada grupo se denomina factor de réplica del factor de respaldo.
3. El Productor envía el mensaje a la Partición correspondiente, y luego el Consumidor usa el Desplazamiento compensado en la Partición para registrar el progreso del grupo de consumidores al que pertenece consume el mensaje en la Partición actual.
4. El mensaje enviado por el Productor a un Tema será enviado por Kafka a todos los grupos de consumidores suscritos al Tema para su procesamiento. Pero dentro de cada grupo de consumidores, solo una instancia de consumidor procesará este mensaje.
5. Finalmente, Kafka's Broker forma un clúster a través de Zookeeper. Luego, entre estos corredores, se debe elegir un corredor que actúe como controlador. La tarea principal de este Controller es ser responsable de la asignación de temas y la gestión del seguimiento. En nuestro grupo experimental, este controlador en realidad se genera a través de ZooKeeper.