0 Prefacio
En los capítulos anteriores, hemos explicado el uso básico de la versión independiente de solr, pero en la producción real, para garantizar una alta disponibilidad y un alto rendimiento, generalmente usamos el modo de clúster, por lo que a continuación continuamos explicando la construcción. y operaciones básicas del clúster solr
1. Modo de grupo
1.1 Fragmentación
Antes de explicar el modo de clúster de solr, primero debemos entender el concepto de "fragmentación".
Cuando el nodo se expande de un nodo a varios, también surgen problemas de sincronización y almacenamiento de datos.Si los datos simplemente se almacenan en un determinado nodo, no se puede lograr el propósito de alta disponibilidad.Si los datos se almacenan en cada nodo Almacenamiento, entonces conducirá a la pérdida de espacio, por lo que aparece el concepto de fragmentación.
El llamado sharding consiste en dividir los datos en varias partes, cada parte es un fragmento, y luego almacenar estos fragmentos en diferentes nodos para lograr la expansión del almacenamiento.Al mismo tiempo, debido a que diferentes datos se almacenan en diferentes nodos, de hecho también mejora el rendimiento de las consultas.
Y estos fragmentos también se dividen en fragmentos primarios y fragmentos de réplica. Los fragmentos primarios son datos diferentes, y los fragmentos de réplica son las copias de seguridad de los fragmentos primarios. Luego, estos fragmentos se distribuyen a diferentes nodos, de modo que tanto el almacenamiento de datos realizado como la copia de seguridad de datos
Para lograr una alta disponibilidad, se requiere que los mismos fragmentos primarios y secundarios no puedan estar en el mismo nodo; de lo contrario, cuando un nodo se bloquea, los fragmentos secundarios también se bloquean.
1.2 Gobernanza de nodos
Cuando hay más nodos, la coordinación de llamadas entre nodos se convierte en un problema. Solr no tiene su propia gestión de servicios, por lo que necesita introducir componentes de terceros. Generalmente, usamos zookeeper como un centro de registro para gestionar la programación de servicios.
Al mismo tiempo, para garantizar la alta disponibilidad del centro de registro, nuestro cuidador del zoológico también debe implementarse en modo clúster. Algunos estudiantes pueden tener dudas, zk se implementa en modo de clúster, entonces, quién coordinará los múltiples nodos de zk, por supuesto, es el propio zk, y su modo de clúster tiene su propia función de administración de servicios.
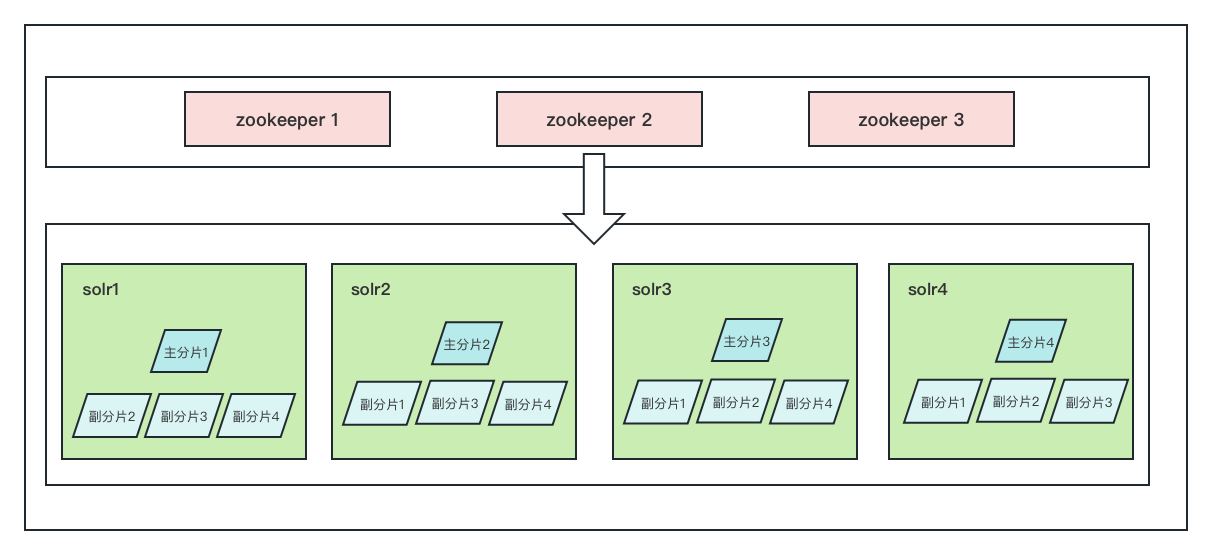
1.3 Arquitectura de implementación
Con los conceptos básicos anteriores, clasifiquemos la arquitectura del clúster solr que se implementará.
En primer lugar, la cantidad mínima de nodos maestros en el modo de clúster es 3. Aquí, para simular el entorno en línea, se construyen 4 fragmentos maestros y cada fragmento maestro tiene fragmentos de réplica 3. Yo uso 4 nodos, y usted puede consulte el entorno del servidor para obtener más detalles. para seleccionar el número de nodos, pero no menos de 3
En segundo lugar, zookeeper construye un clúster, la cantidad mínima de nodos es 3, por lo que la arquitectura de implementación se muestra en la figura a continuación.
2. Construir
2.1 Crear un grupo de cuidadores del zoológico
El clúster de cuidadores del zoológico se puede crear en otro artículo: cree un clúster de cuidadores del zoológico y configúrelo para que se inicie automáticamente
Pero tenga en cuenta que debido a que uso la versión solr 8.2.0, se selecciona la versión correspondiente de zookeeper 3.4.14, y puede haber problemas de conexión si la versión no corresponde. resultará en un errorTimeoutException: Could not connect to ZooKeeper
2.2 Construir un clúster solr
1. Hemos construido un solo nodo solr antes y copiado el nodo 3 veces a los otros 3 servidores
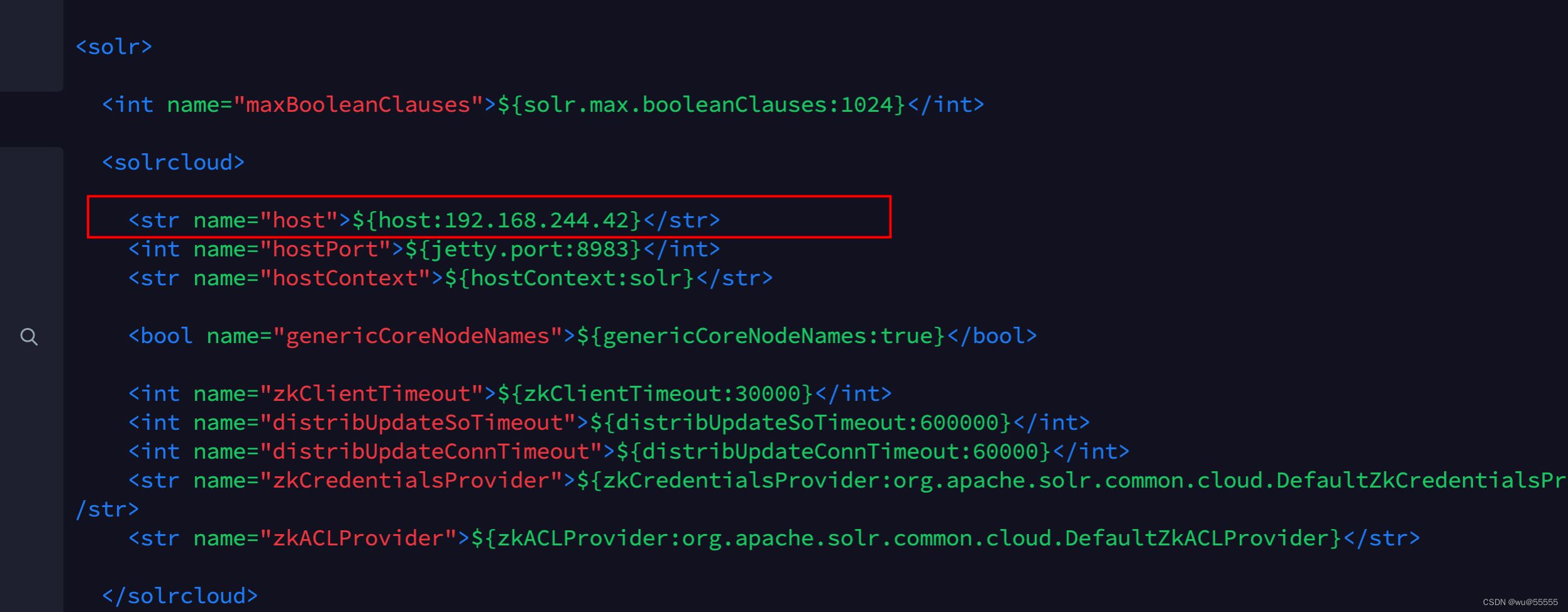
2. Modificar el archivo de configuración de solrsolr.xml
vim server/solr/solr.xml
Contenido, ajústelo a la ip del servidor solr del servidor, si el puerto está ajustado, puede modificarlo directamente
3. Modifique el archivo de script de inicio solr.in.shy configure la dirección zk
vim bin/solr.in.sh
contenido
ZK_HOST="192.168.244.42:2181,192.168.244.43:2181,192.168.244.44:2181"
# Set the ZooKeeper client timeout (for SolrCloud mode)
ZK_CLIENT_TIMEOUT="15000"
4. En los otros 3 nodos, ajuste los 2 pasos anteriores sincrónicamente
5. Reinicie los cuatro nodos solr
# 如下启动指令是单独配置的,参考专栏第一篇文章
service solr restart
¡Poder acceder a solr-admin normalmente demuestra que la implementación del clúster es exitosa!
Si se encuentra un error aquíSolrException: ruok is not executed because it is not in the whitelist. Check 4lw.commands.whitelist setting in zookeeper configuration file
Esto se debe a que si desea usar el comando de cuatro palabras de zk de manera simple y conveniente sin iniciar sesión en el cliente zk, por ejemplo, ruok es un comando para verificar si zk se inició, debe agregar una lista blanca de comandos permitidos por zk
conf/zoo.cfgAgregue un elemento de configuración en el archivo de configuración de zookeeper 4lw.commands.whitelist=stat,ruok,conf,isro, configure la instrucción de cuatro palabras especificada para que se llame de forma remota, si está configurado, *significa que se permite llamar a todas las instrucciones
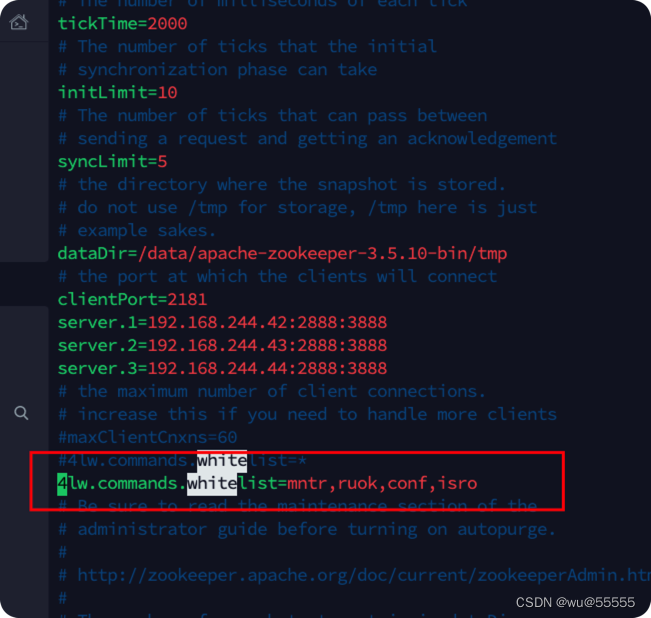
Después de la configuración, reinicie zk, solr, si es un clúster, recuerde modificar cada nodo zk
Comience normalmente, puede Cloudverificar el estado de los nodos del clúster en el menú
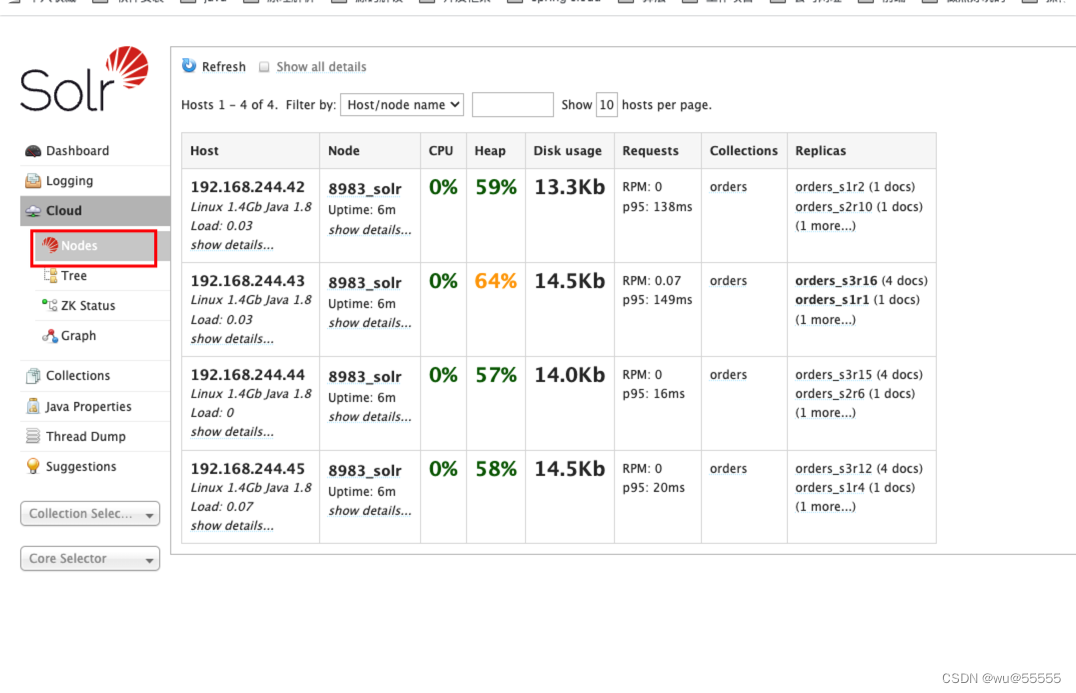
6. Debido a que zookeeper se usa para administrar el clúster, debemos cargar los archivos de configuración relevantes de solr en zookeeper y usar zookeeper como centro de configuración.
Primero cargue el archivo de configuración del núcleo de pedidos que creamos en el solr independiente a uno de los nodos de solr
scp -r orders [email protected]:/data/solr-8.2.0/server/solr
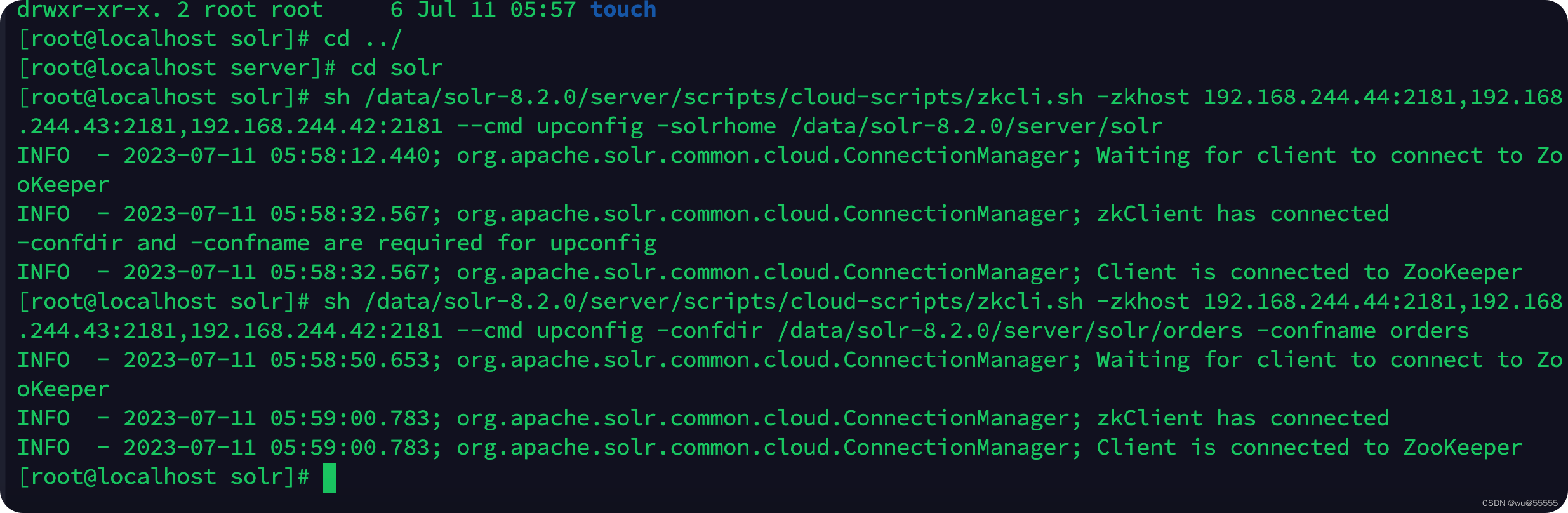
7. Mientras carga a zk, solr nos proporciona un archivo de scriptserver/scripts/cloud-scripts/zkcli.sh
El principal será solr.xmlel archivo de configuración bajo el núcleo (índice) managed-schema,solrconfig.xml
Ejecutar en cualquier nodo solr:
# 设置solr配置文件路径
sh /data/solr-8.2.0/server/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.244.44:2181,192.168.244.43:2181,192.168.244.42:2181 --cmd upconfig -solrhome /data/solr-8.2.0/server/solr
# 上传核心配置文件目录
sh /data/solr-8.2.0/server/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.244.44:2181,192.168.244.43:2181,192.168.244.42:2181 --cmd upconfig -confdir /data/solr-8.2.0/server/solr/orders -confname orders
Si necesita cargar otros archivos de configuración del núcleo (índice) en el futuro, solo necesita ejecutar las siguientes instrucciones
sh /data/solr-8.2.0/server/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.244.44:2181,192.168.244.43:2181,192.168.244.42:2181 --cmd upconfig -confdir /data/solr-8.2.0/server/solr/collection_name -confname collection_name
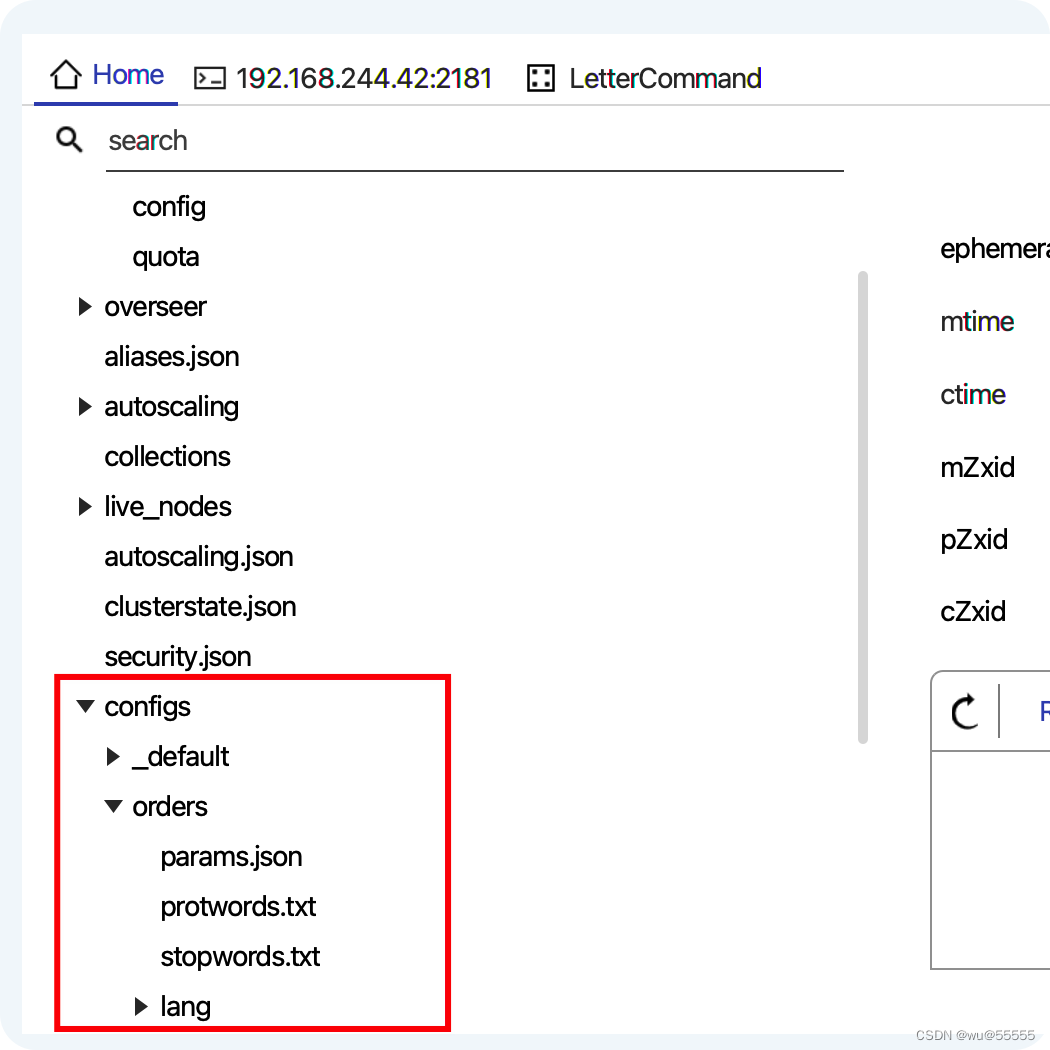
Conéctese a zk, y también puede encontrar los datos correspondientes. La conexión aquí es prettyZoouna herramienta. Si no sabe cómo instalarla, puede consultar mi blog anterior:
Instale las herramientas de visualización de zookeeper PrettyZoo, ZooKeeperAssistant
8. Inicie sesión en cualquier administrador de solr, agregue un núcleo, el nombre es consistente con el que se cargó antes orders, y debido a que tenemos 4 nodos, generalmente establezca la cantidad de fragmentos primarios para que sea la misma que la cantidad de nodos, y no puede supere la cantidad de nodos, los mismos fragmentos primarios y secundarios No en un nodo, entonces hay 4 fragmentos primarios en total, y cada fragmento primario tiene 3 fragmentos de réplica
Debido a que el nodo solr predeterminado maxShardsPerNodees 1, es decir, a cada nodo solo se le permite crear 1 fragmento (fragmento principal o fragmento secundario), lo que obviamente no cumple con nuestra arquitectura mencionada anteriormente, y cada nodo necesita crear 1 fragmento principal y 3 copia Sharding, por lo que un nodo necesita crear 4 fragmentos, luego debemos maxShardsPerNodeajustarnos a 4
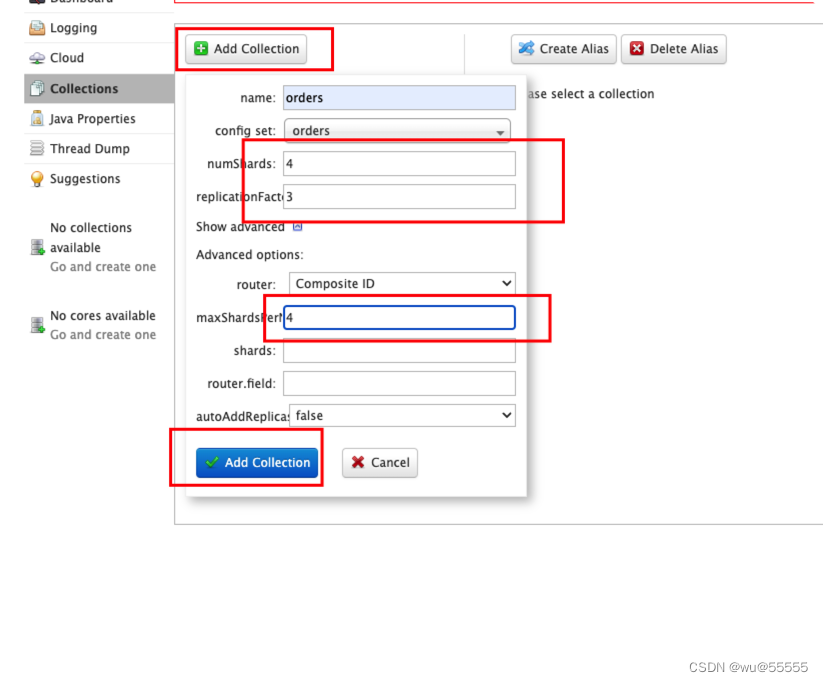
El núcleo creado después de guardar se sincronizará con otros nodos
CollectionsLa fragmentación se puede ver en
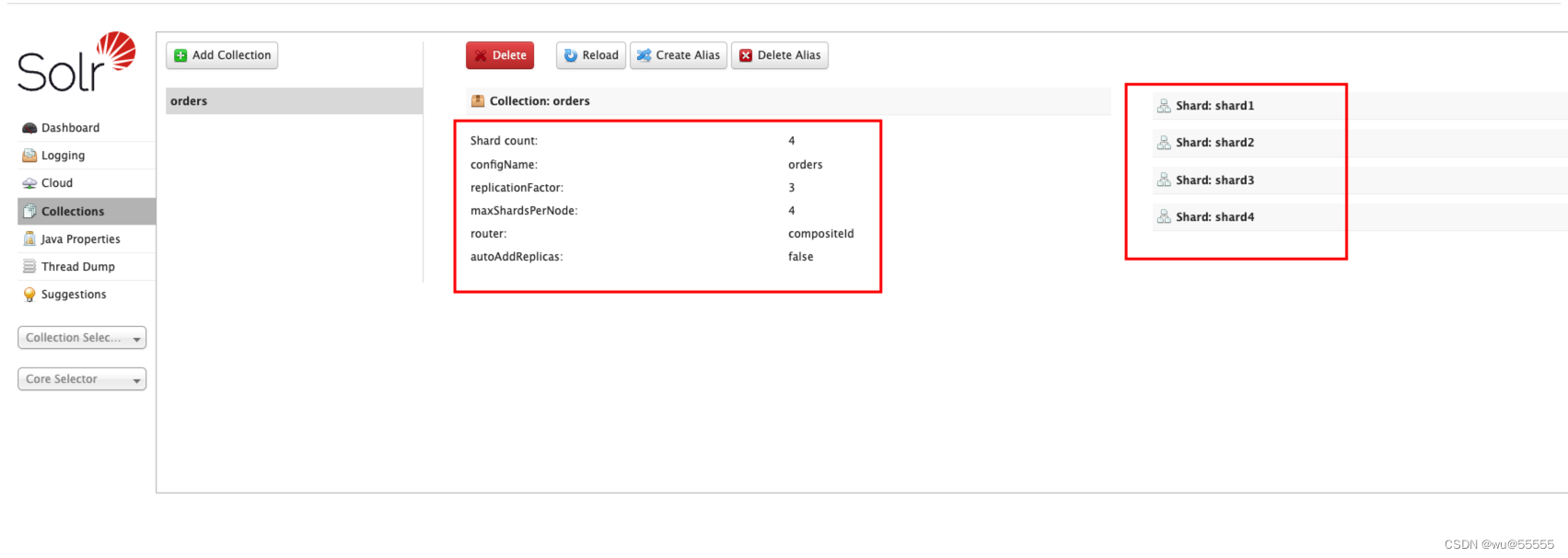
9. Realice una sincronización completa. Si no está familiarizado con las operaciones de sincronización, puede consultar los artículos anteriores en la columna
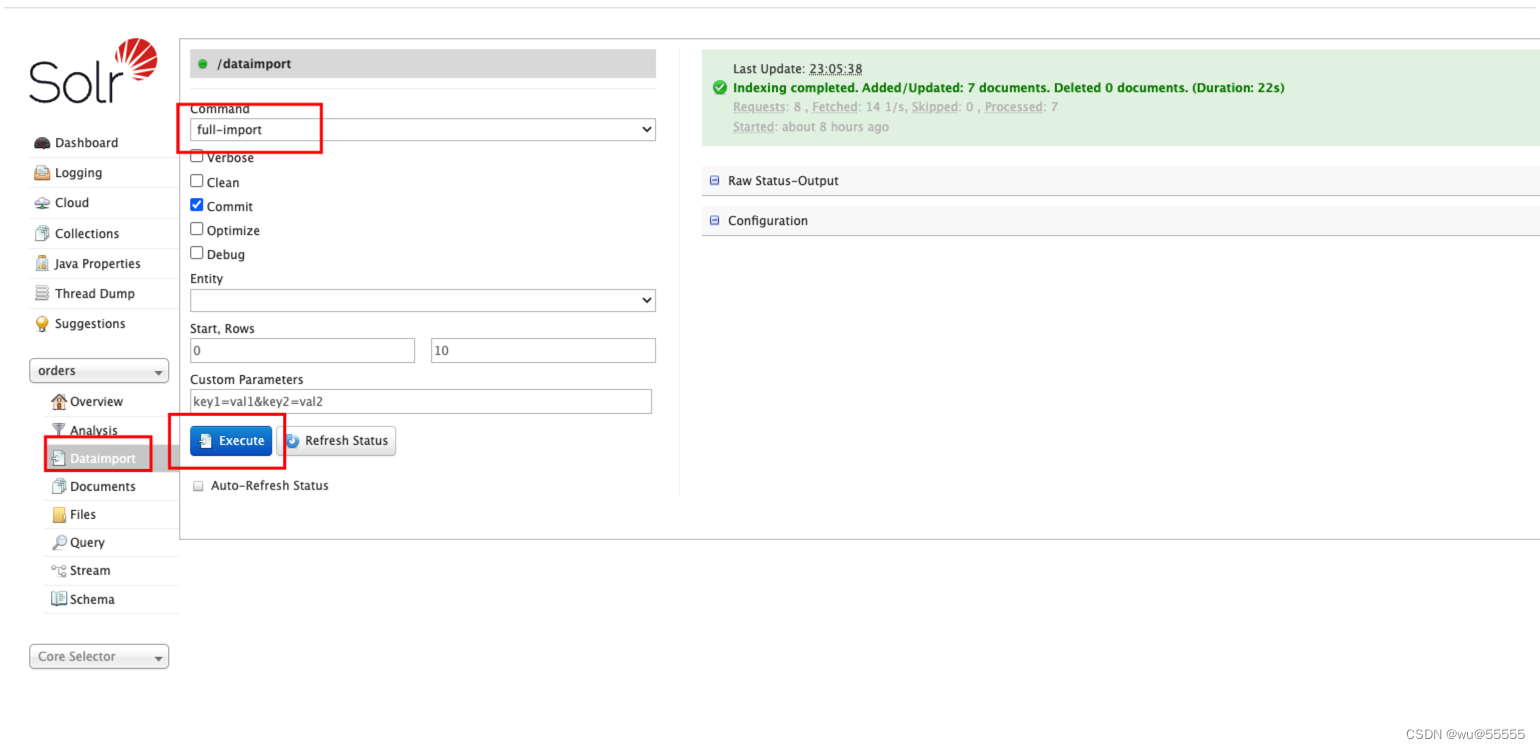
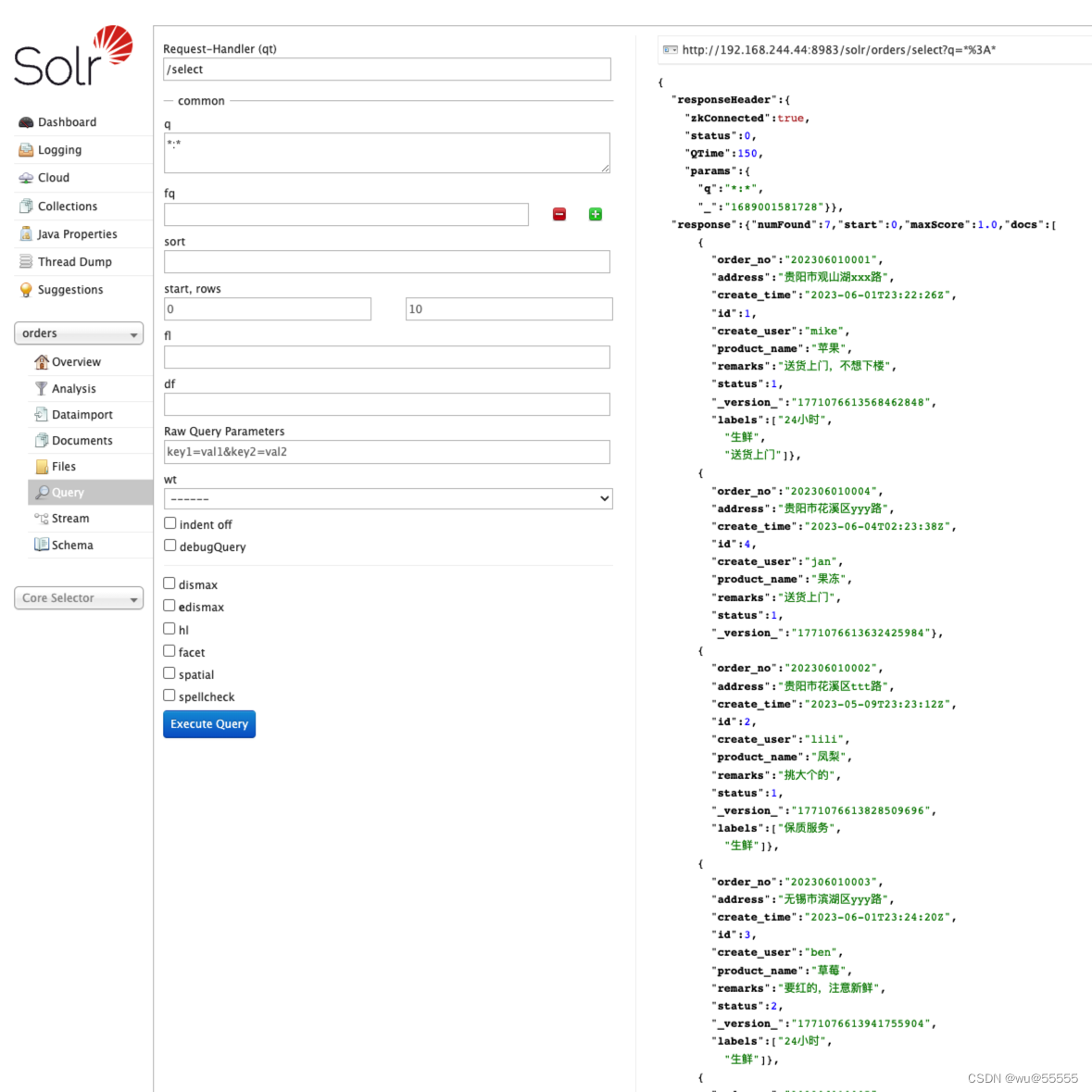
10. Consulte datos y descubra que la consulta de datos es exitosa
Resumir
Desde entonces, hemos explicado la construcción del clúster solr, la creación del núcleo y la sincronización de datos. Al mismo tiempo, lo que se debe cambiar es el código cuando nuestro cliente se conecta. Se debe ajustar al modo clúster, es decir. , para conectarse a través de zk