El contenido del artículo "Prefacio" es aproximadamente una explicación del protocolo HTTP del protocolo de la capa de aplicación.
Programación de red "columna de pertenencia"
Página de inicio personal "Enlace de página de inicio"
"Autor" Sr. Maple Leaf (fy)
"Mr. Maple Leaf es un poco literario" "Compartir oraciones"
Como dice el refrán, no hay vuelta atrás cuando abres un arco, solo hay tres resultados: la flecha se rompe, la flecha cae y la flecha da en el blanco.
——Jiang Xiaoying "Su Dongpo: El amor más verdadero del mundo"

Tabla de contenido
1. Introducción al protocolo HTTP
HTTP(Hyper Text Transfer Protocol)El protocolo, también conocido como Protocolo de transferencia de hipertexto, es un protocolo de solicitud-respuesta que funciona en la capa de aplicación.
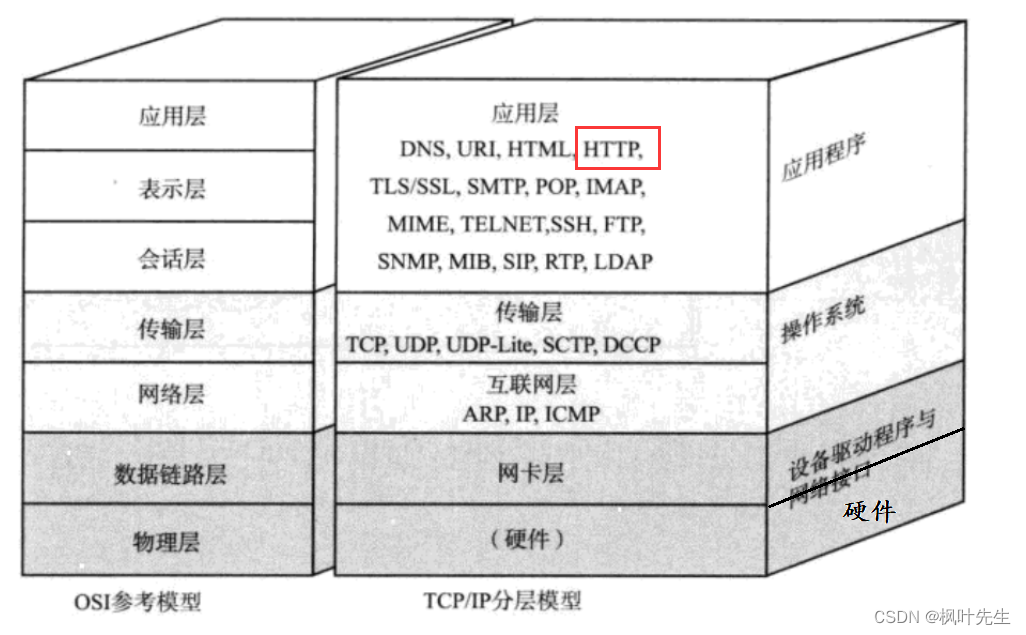
Aunque dijimos que el protocolo de la capa de aplicación puede ser personalizado por nosotros mismos, de hecho, algunos ingenieros excelentes ya han definido algunos protocolos listos para usar, y el protocolo de la capa de aplicación HTTP (Protocolo de transferencia de hipertexto) es uno de ellos para nuestra referencia directa.
Segundo, conozca la URL
Por lo general, lo que comúnmente llamamos "URL" en realidad significaURL
URL(Uniform Resource Lacator)Se llama localizador uniforme de recursos, que es lo que solemos llamar URL.
Una URL consta aproximadamente de las siguientes partes:

(1) Nombre del esquema de protocolo
http://Indicahttpel nombre del protocolo, indicando el protocolo que se necesita utilizar al realizar una solicitud.Los protocolos que solemos ver en Internet en nuestro día a día son: y, lo que queremoshttpexplicarhttpses quehttp协议elhttpsprotocolo se llama seguro protocolo de transmisión de datos, que será discutido en el siguiente capítulo.
(2) Información de inicio de sesión
usr:passIndica la información de autenticación de inicio de sesión, incluidos el nombre de usuario y la contraseña del usuario de inicio de sesión. Este campo ahora se omite para la mayoría de las URL.
(3) Dirección del servidor
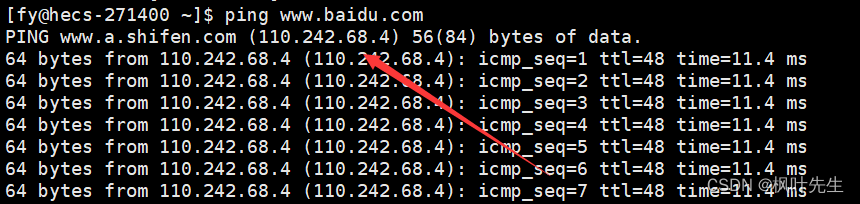
www.example.jpIndica la dirección del servidor, también conocida como nombre de dominio. Este nombre de dominio esIPuna dirección, que se utiliza para identificar un host único. Este nombre de dominio se resolverá enIPuna dirección, y el servidor de resolución de nombres de dominio completará la resolución del nombre de dominio.
En Linux, pingel nombre de dominio se puede resolver mediante el comando
(4) Número de puerto del servidor
80Indica el número de puerto del servidor,httpel número de puerto predeterminado del protocolo es80yhttpsel número de puerto predeterminado del protocolo es443.- En la URL, generalmente se omite el número de puerto del servidor, porque la correspondencia entre el servicio y el número de puerto es clara (el código ha sido escrito), por lo que no es necesario especificar el número de puerto correspondiente al protocolo al usar el
httpprotocolo
(5) Rutas de archivo jerárquicas
/dir/index.htmIndica la ruta donde se encuentra el recurso al que se va a acceder- El primero
/es el directorio raíz de la web, no el directorio raíz de Linux.El directorio raíz de la web puede ser cualquier directorio bajo Linux. - El propósito de acceder al servidor es obtener un determinado recurso en el servidor, el proceso del servidor correspondiente ya se puede encontrar a través del nombre de dominio y puerto anterior, lo que se debe hacer en este momento es indicar la ruta donde se encuentra el recurso .
httpUn protocolo es un protocolo para obtener recursos de un servidor remoto al local.
Todo lo que vemos en Internet es un recurso, como texto, audio, imágenes, páginas web, etc. Estos recursos (archivos) deben almacenarse en un determinado servidor. HTTPEl protocolo puede transmitir varios tipos de recursos de archivo, por lo que se denomina protocolo de transferencia de hipertexto en lugar de protocolo de transferencia de texto. Los tipos de recursos de archivo que se pueden transferir se reflejan en 超la palabra.
(6) cadena de consulta
uid=1Representa los parámetros proporcionados en el momento de la solicitud, &separados por símbolos
(7) Identificador de fragmento
ch1Representa el identificador de fragmento, que es un complemento parcial del recurso.
Tres, urlencode y urldecode
En la URL, los caracteres como /y ? etc. han sido interpretados como significados especiales por la URL. Por lo tanto, estos personajes no pueden aparecer aleatoriamente.
Por ejemplo, si estos caracteres especiales son obligatorios en un parámetro, primero se deben escapar los caracteres especiales.
Las reglas para escapar son las siguientes:
Convierta los caracteres que deben transcodificarse a 16进制, y luego, de derecha a izquierda, tome 4 dígitos (menos de 4 dígitos y procéselos directamente), haga un dígito por cada 2 dígitos, agréguelo al frente y codifíquelo %como%XY
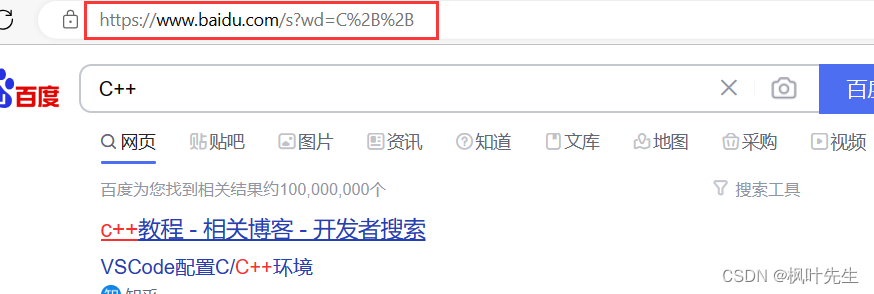
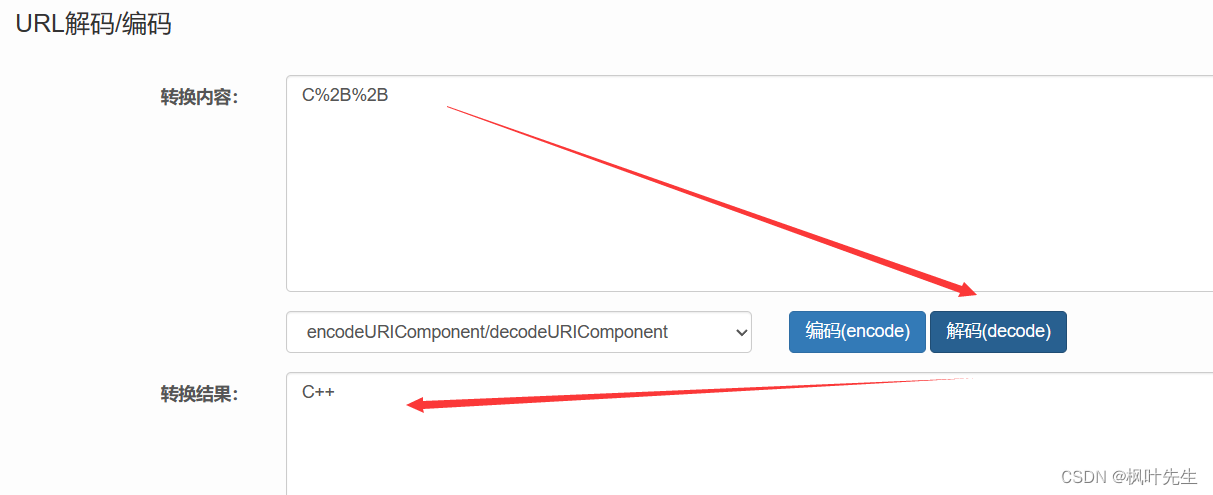
Por ejemplo, cuando buscamos algo en el navegador:
Por ejemplo, cuando buscamos C++, wdtodos los siguientes son nuestros parámetros de búsqueda ( wdel nombre del parámetro), +el signo más es un símbolo especial en la URL y +el valor después de convertir el carácter a hexadecimal es 0x2B, por lo que uno +será codificado en una %2B
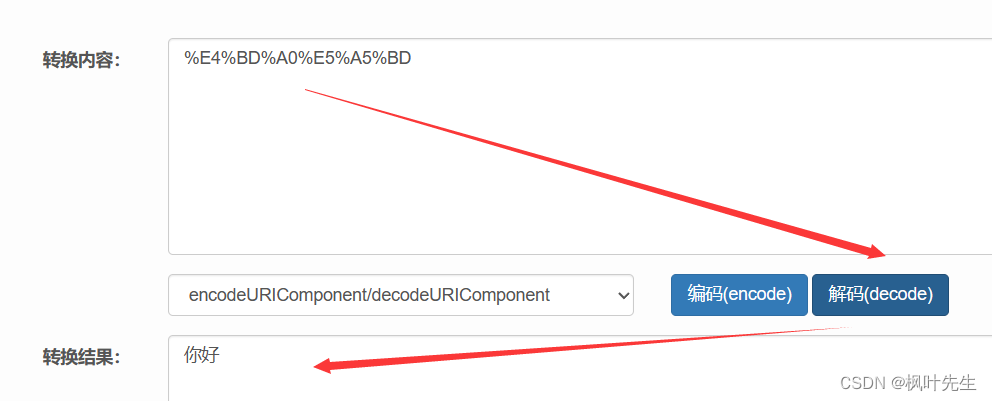
nota: los caracteres chinos y los caracteres especiales deben convertirse. Este proceso se convierte en URL. encode
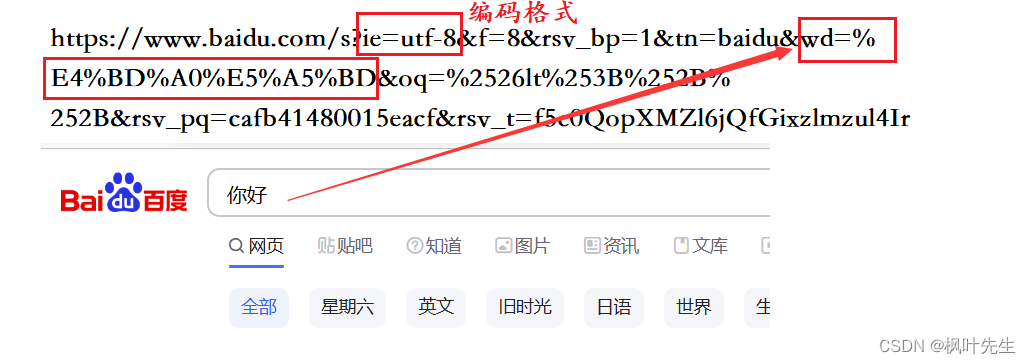
Cuando el servidor reciba nuestra solicitud, decodificará %xxlos símbolos especiales. Este proceso se llama URL decode. Cuando se usa C++para escribir el servidor, necesitamos hacer este trabajo (el código fuente está disponible en Internet, solo úselo directamente) Verifiquemos
el proceso de decodificación, solo busque una herramienta de decodificación de URL en línea en Internet y úsela
Cuarto, el formato de solicitud y respuesta del protocolo HTTP
HTTP es un servicio de capa de aplicación basado en solicitudes y respuestas. Como cliente, puede iniciar una solicitud al servidor . Después de que requestel servidor reciba esto , lo analizará para averiguar a qué recursos desea acceder, y luego el servidor construya una respuesta para completar esto. Una solicitud HTTP. Basado en este método de trabajo, se llama o modo, c significa , s significa , b significa que el navegador es el cliente del protocolo, lo que significa que no necesitamos escribir el cliente para usar el protocolo.requestrequestresponserequest&responsecsbsclientserverbrowserhttphttp
4.1 Formato de protocolo de solicitud HTTP
El formato del protocolo de solicitud HTTP es más o menos el siguiente:

Una solicitud HTTP consta de cuatro partes:
- Línea de solicitud: [método de solicitud]+[url]+[versión de http]+[\r\n]
- Encabezado de solicitud: los atributos de la solicitud, estos atributos se
name:valueenumeran en forma de + que terminan en [\r\n] - Línea en blanco: encontrar una línea en blanco (\r\n) indica el final del encabezado de la solicitud
- Cuerpo de la solicitud: el cuerpo de la solicitud puede ser una cadena vacía y el cuerpo de la solicitud puede estar vacío. Si el cuerpo de la solicitud existe, habrá uno en el encabezado de la solicitud
Content-Lengthpara identificar la longitud del cuerpo de la solicitud.
Aviso: http usa símbolos especiales (\r\n) para dividir el contenido
Las primeras tres partes generalmente se incluyen con el protocolo HTTP, y la última parte del cuerpo de la solicitud se puede omitir (cadena vacía). Una vez que se empaqueta la solicitud, se entrega directamente a la siguiente capa: la capa de transporte, que luego procesalo
4.2 Formato del protocolo de respuesta HTTP
El formato del protocolo de respuesta HTTP es más o menos el siguiente:

La respuesta HTTP consta de cuatro partes:
- Línea de estado: [versión http]+[código de estado]+[descripción del código de estado]]+[\r\n]
- Encabezado de respuesta: los atributos de la respuesta, estos atributos se
name:valueenumeran en forma de + que termina en [\r\n] - Línea vacía: encontrar una línea vacía (\r\n) indica el final del encabezado de respuesta
- Cuerpo de la respuesta: el cuerpo de la respuesta puede ser una cadena vacía y el cuerpo de la respuesta puede estar vacío. Si el cuerpo de la respuesta existe, habrá un atributo en el encabezado de la respuesta
Content-Lengthpara identificar la longitud del cuerpo de la respuesta.
Aviso: http está dividido por símbolos especiales (\r\n).
Las tres primeras partes del contenido generalmente las proporciona el protocolo HTTP. La última parte del cuerpo de la respuesta se puede omitir (cadena vacía). Después de empaquetar la solicitud, se entrega directamente a la siguiente capa: capa de transporte, que luego es procesada por la capa de transporte
4.3 Preguntas
¿Cómo garantizar que una solicitud y respuesta http se lean completamente en la capa de aplicación? ?
- Primero, para solicitudes y respuestas se puede leer línea por línea (cada línea tiene
\r\n) - Use
whileun bucle para leer una línea completa (para\r\ndividir) hasta que se lean todos los encabezados de solicitud o de respuesta, y se lea una línea en blanco para indicar que la lectura está completa - El siguiente paso es leer el texto, ¿cómo asegurar que se lea el texto? ? No hay símbolos especiales en el texto.
- Ya nos hemos asegurado de que se ha leído el encabezado de la solicitud o respuesta, y debe haber un campo en el encabezado:
Content-Length, que se utiliza para identificar la longitud del cuerpo de la respuesta o del cuerpo de la solicitud. - Para
Content-Lengthanalizar, obtenga la longitud del texto, de modo que pueda asegurarse de que el texto leído esté completo y pueda leerlo directamente de acuerdo con la longitud analizada
Esto asegura que una solicitud y respuesta http se lean completamente en la capa de aplicación.
¿Cómo se serializan y deserializan las solicitudes y respuestas http? ?
- La serialización y la deserialización
httpse implementan por sí mismas mediante el uso de caracteres especiales Siempre que los caracteres especiales se lean línea por línea, se puede obtener la cadena\r\ncompleta第一行 + 请求/响应报头 - El cuerpo no necesita ser serializado y deserializado, si es necesario, personalícelo usted mismo
Lo anterior es httpuna comprensión macro del protocolo, y el siguiente código está escrito para comprender httpel protocolo.
Cinco, código de prueba HTTP
5.1 Solicitudes HTTP
Escribamos un servidor TCP simple, lo que este servidor debe hacer es imprimir la solicitud HTTP enviada por el navegador.
httpServidor.hpp
#pragma once
#include <iostream>
#include <string>
#include <functional>
#include <strings.h>
#include <unistd.h>
#include <pthread.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include "protocol.hpp"
static const int gbacklog = 5;
using func_t = std::function<bool(const httpRequest &req, httpResponse &resp)>;
// 错误类型枚举
enum
{
UAGE_ERR = 1,
SOCKET_ERR,
BIND_ERR,
LISTEN_ERR
};
// 业务处理
void handlerHttp(int sockfd, func_t func)
{
char buffer[4096];
httpRequest req;
httpResponse resp;
size_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
req.inbuffer = buffer;
func(req, resp);
send(sockfd, resp.outbuffer.c_str(), resp.outbuffer.size(), 0);
}
}
class ThreadDate
{
public:
ThreadDate(int sockfd, func_t func) : _sockfd(sockfd), _func(func)
{
}
public:
int _sockfd;
func_t _func;
};
class httpServer
{
public:
httpServer(const uint16_t &port) : _listensock(-1), _port(port)
{
}
// 初始化服务器
void initServer()
{
// 1.创建套接字
_listensock = socket(AF_INET, SOCK_STREAM, 0);
if (_listensock == -1)
{
std::cout << "create socket error" << std::endl;
exit(SOCKET_ERR);
}
std::cout << "create socket success: " << _listensock << std::endl;
// 2.绑定端口
// 2.1 填充 sockaddr_in 结构体
struct sockaddr_in local;
bzero(&local, sizeof(local)); // 把 sockaddr_in结构体全部初始化为0
local.sin_family = AF_INET; // 未来通信采用的是网络通信
local.sin_port = htons(_port); // htons(_port)主机字节序转网络字节序
local.sin_addr.s_addr = INADDR_ANY; // INADDR_ANY 就是 0x00000000
// 2.2 绑定
int n = bind(_listensock, (struct sockaddr *)&local, sizeof(local)); // 需要强转,(struct sockaddr*)&local
if (n == -1)
{
std::cout << "bind socket error" << std::endl;
exit(BIND_ERR);
}
std::cout << "bind socket success" << std::endl;
// 3. 把_listensock套接字设置为监听状态
if (listen(_listensock, gbacklog) == -1)
{
std::cout << "listen socket error" << std::endl;
exit(LISTEN_ERR);
}
std::cout << "listen socket success" << std::endl;
}
// 启动服务器
void start(func_t func)
{
for (;;)
{
// 4. 获取新链接,accept从_listensock套接字里面获取新链接
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
// 这里的sockfd才是真正为客户端请求服务
int sockfd = accept(_listensock, (struct sockaddr *)&peer, &len);
if (sockfd < 0) // 获取新链接失败,但不会影响服务端运行
{
std::cout << "accept error, next!" << std::endl;
continue;
}
std::cout << "accept a new line success, sockfd: " << sockfd << std::endl;
// 5. 为sockfd提供服务,即为客户端提供服务
// 多线程版
pthread_t tid;
ThreadDate *td = new ThreadDate(sockfd, func);
pthread_create(&tid, nullptr, threadRoutine, td);
}
}
static void *threadRoutine(void *args)
{
pthread_detach(pthread_self()); // 线程分离
ThreadDate *td = static_cast<ThreadDate *>(args);
handlerHttp(td->_sockfd, td->_func); // 业务处理
close(td->_sockfd); // 必须关闭,由新线程关闭
delete td;
return nullptr;
}
~httpServer()
{
}
private:
int _listensock; // listen套接字,不是用来数据通信的,是用来监听链接到来
uint16_t _port; // 端口号
};
httpServidor.cc
#include "httpServer.hpp"
#include <memory>
// 使用手册
// ./httpServer port
static void Uage(std::string proc)
{
std::cout << "\nUage:\n\t" << proc << " local_port\n\n";
}
bool get(const httpRequest &req, httpResponse &resp)
{
std::cout << "----------------------http start----------------------" << std::endl;
std::cout << req.inbuffer;
std::cout << "----------------------http end ----------------------" << std::endl;
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
Uage(argv[0]);
exit(UAGE_ERR);
}
uint16_t port = atoi(argv[1]); // string to int
std::unique_ptr<httpServer> tsvr(new httpServer(port));
tsvr->initServer(); // 初始化服务器
tsvr->start(get); // 启动服务器
return 0;
}
protocolo.hpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
class httpRequest
{
public:
std::string inbuffer;
};
class httpResponse
{
public:
std::string outbuffer;
};
Después de ejecutar el programa del servidor y luego acceder a él con un navegador, nuestro servidor recibirá la solicitud HTTP del navegador y la imprimirá.
Dado que no hay nada en el código, solo se mostrará la siguiente información.
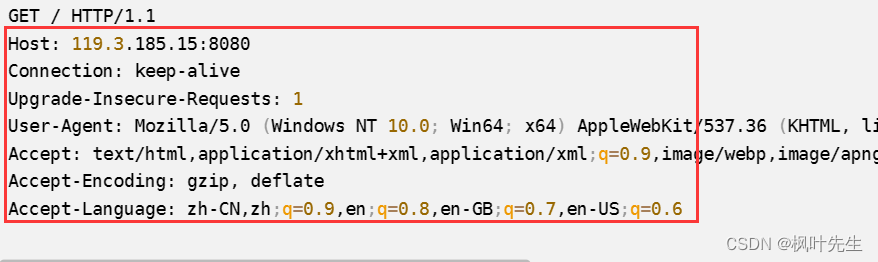
El servidor recibirá el solicitud del navegador Solicitudes HTTP entrantes e imprimirlas (aunque solo se visitó una vez, pero recibirá varias solicitudes HTTP, el comportamiento del navegador)

GET / HTTP/1.1
Host: 119.3.185.15:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
explicar:
- Dado que el navegador utiliza el protocolo HTTP de forma predeterminada cuando inicia una solicitud, podemos ingresar directamente la dirección de la red pública y el número de puerto del servidor sin especificar el protocolo HTTP al ingresar la URL en el cuadro de URL del navegador, como el
- La primera línea es la línea de estado:
GET / HTTP/1.1,GETque es el método de solicitud, que es el predeterminado del navegador, y la URL es\, debido a que no tenemos una solicitud específica, el navegador visitará\(directorio raíz web) de forma predeterminada, queHTTP/1.1es el número de versión de HTTP
El resto son encabezados de solicitud, todos los cuales son name: valuevarios atributos de solicitud que se muestran en forma de líneas.
También se imprimirá una línea en blanco. Como no hay cuerpo de solicitud, el valor predeterminado es una cadena vacía y no habrá información impresa. mostrado por
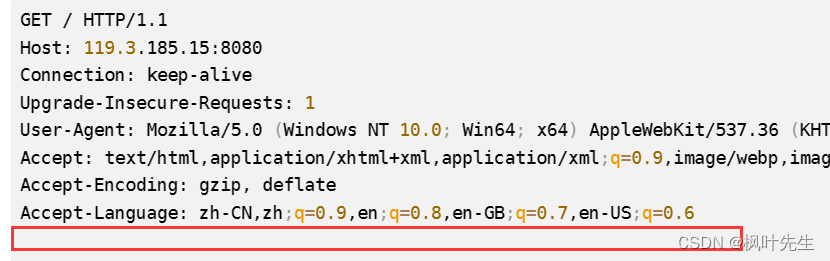
el cliente Información de la versión del host:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67
User-AgentEs para mostrar la información de la versión del host del cliente que inició la solicitud.
Por ejemplo, cuando buscamos algo para descargar, nos mostrará la descarga que coincide con nuestro propio sistema operativo por defecto. ¿Cómo sabe que queremos descargar? descargar la versión para computadora? ?
El motivo es que cuando iniciamos la solicitud, la solicitud ya lleva la información de la versión de nuestro sistema operativo , el resto
es decirle al servidor qué soporta actualmente mi cliente, como el formato de codificación, qué tipo de texto, etc.
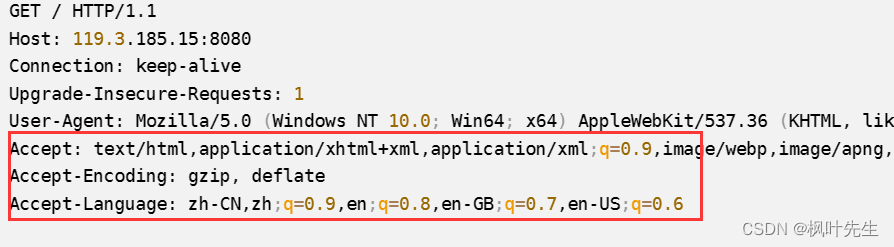
¿Cómo separar los encabezados HTTP de la carga útil?
- Para HTTP, la línea de estado y el encabezado de respuesta/solicitud son información de encabezado HTTP, y el cuerpo de respuesta/solicitud aquí es en realidad la carga útil HTTP.
- Si se lee una línea en blanco, significa que se ha leído el encabezado. La línea en blanco es la clave para separar el encabezado HTTP de la carga útil.
- Es decir, http usa símbolos especiales para separar los encabezados y las cargas útiles.
¿Por qué HTTP necesita una versión interactiva?
- La línea de solicitud en la solicitud HTTP y la línea de estado en la respuesta HTTP contienen información de la versión de http. . El cliente envía la solicitud HTTP, por lo que la solicitud HTTP indica la versión http del cliente, y el servidor envía la respuesta HTTP, por lo que la respuesta HTTP indica la versión http del servidor.
- Cuando el cliente y el servidor se comunican, intercambiarán las versiones http de ambas partes, principalmente por cuestiones de compatibilidad. Debido a que el servidor y el cliente pueden usar diferentes versiones de http, para permitir que los clientes de diferentes versiones disfruten de los servicios correspondientes, las partes de la comunicación deben realizar la negociación de la versión.
- Por ejemplo, una aplicación cuya versión es 1.0 se actualiza a 2.0 hoy (se proporcionan nuevas funciones, pero la versión anterior no). Algunos usuarios actualizan y otros optan por no actualizar. En este momento, habrá un problema de diferencias de versión. La versión anterior accede al servidor, pero no puede acceder a la nueva versión del servidor. Se debe permitir que la versión anterior acceda al servidor anterior. En este momento, la información de la versión de ambas partes debe intercambiarse, de modo que los clientes de diferentes versiones podrá disfrutar de los servicios correspondientes.
- Por lo tanto, para garantizar una buena compatibilidad, ambas partes deben intercambiar la información de su versión.
5.2 Respuesta HTTP
Simplemente agregue un pequeño código, observemos la respuesta HTTP
bool get(const httpRequest &req, httpResponse &resp)
{
std::cout << "----------------------http request start----------------------" << std::endl;
std::cout << req.inbuffer;
std::cout << "+++++++++++++++++++++++++++++" << std::endl;
std::cout << "request method: " << req.method << std::endl;
std::cout << "request url: " << req.url << std::endl;
std::cout << "request httpversion: " << req.httpversion << std::endl;
std::cout << "request path: " << req.path << std::endl;
std::cout << "request file suffix: " << req.suffix << std::endl;
std::cout << "request body size: " << req.size << "字节" << std::endl;
std::cout << "----------------------http request end ----------------------" << std::endl;
std::cout << "----------------------http response start ----------------------" << std::endl;
std::string respline = "HTTP/1.1 200 OK\r\n"; // 响应状态行
std::string respheader = Util::suffixToDesc(req.suffix);
std::string respblank = "\r\n"; // 响应空行
std::string respbody; // 响应正文
respbody.resize(req.size);
if (!Util::readFile(req.path, (char *)respbody.c_str(), req.size)) // 访问资源不存在,打开404html
{
struct stat st;
stat(html_404.c_str(), &st);
respbody.resize(st.st_size);
Util::readFile(html_404, (char *)respbody.c_str(), st.st_size); // 一定成功
}
resp.outbuffer = respline;
respheader += "Content-Length: ";
respheader += std::to_string(respbody.size());
respheader += respblank;
resp.outbuffer += respheader;
resp.outbuffer += respblank;
std::cout << resp.outbuffer;
resp.outbuffer += respbody;
std::cout << "----------------------http response end ----------------------" << std::endl;
return true;
}
No se publicará demasiado código, gitee enlace: enlace
El resultado de la operación, el servidor responde (cuando el navegador accede a nuestro servidor, el servidor responderá index.htmla este archivo al navegador, el index.htmlarchivo predeterminado es la página de inicio del sitio web visitado)
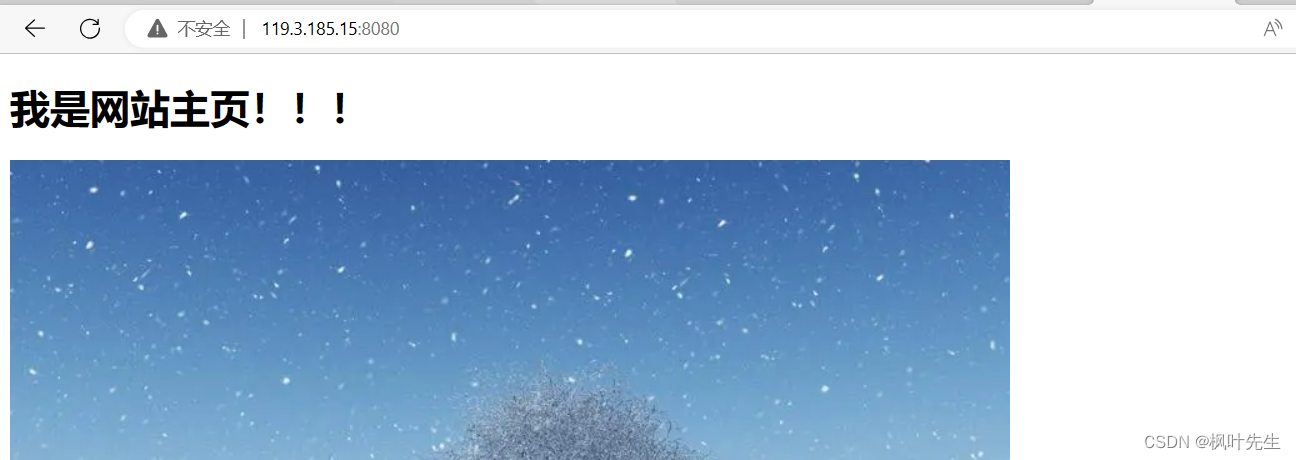
e imprime parte de la información de respuesta

Nota: Solo como ejemplo, al construir la respuesta HTTP, solo se agrega información de dos atributos al encabezado de respuesta, y hay mucha información de atributos en el encabezado de respuesta HTTP real.
Seis, método HTTP

Los métodos comunes de HTTP son los siguientes: (en la solicitud)
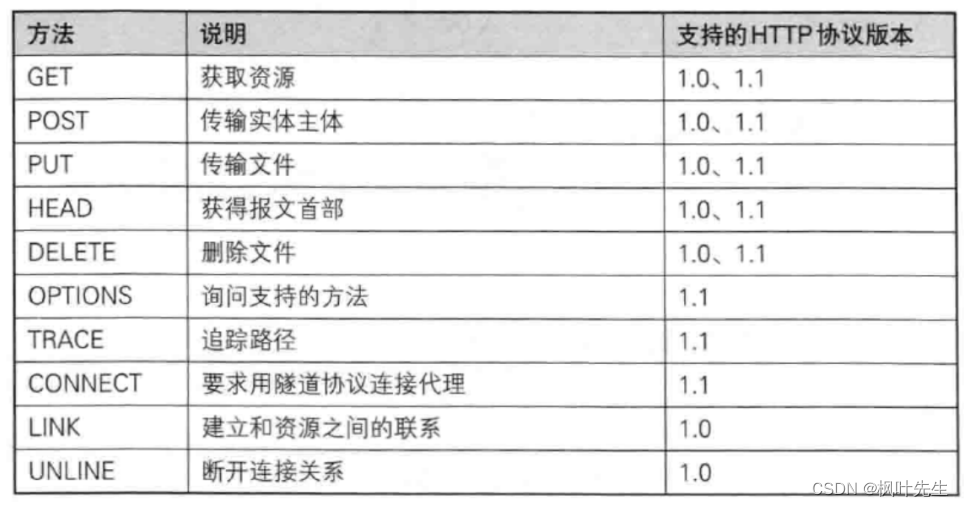
Los más utilizados son el método GET y el método POST
Al interactuar con los datos de front-end y back-end, la esencia es que el front-end formse envía a través del formulario y el navegador convertirá automáticamente el contenido del formulario en GET/POSTuna solicitud .
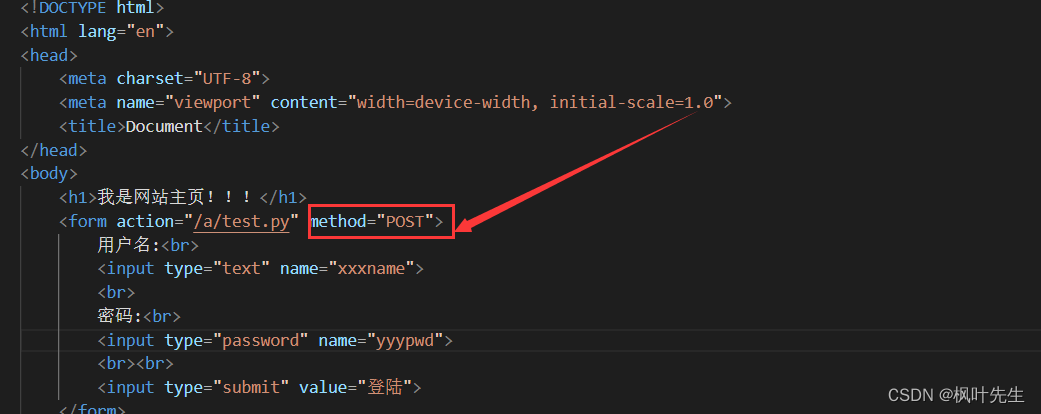
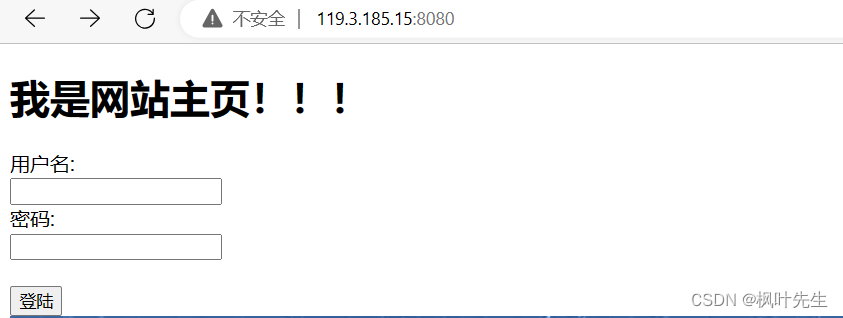
Por ejemplo, la página de envío del formulario de front-end

action="/a/test.py"significa que el formulario se envía al archivo de ruta especificado, method="GET"lo que significa acceso http El método es GET
iniciar el servidor, visitar el navegador

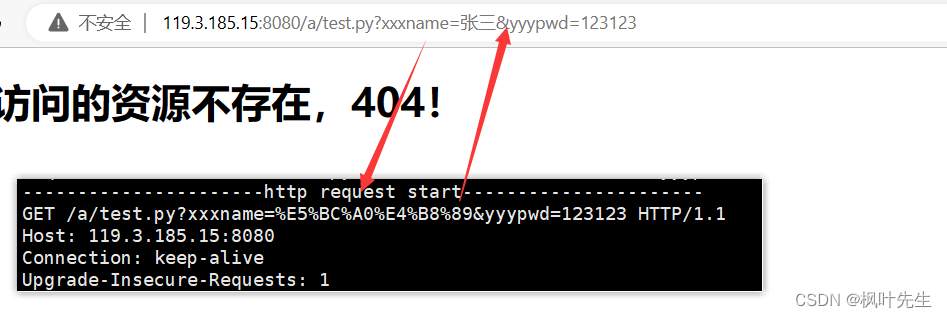
y enviar el contenido, como Zhang San, 123123,
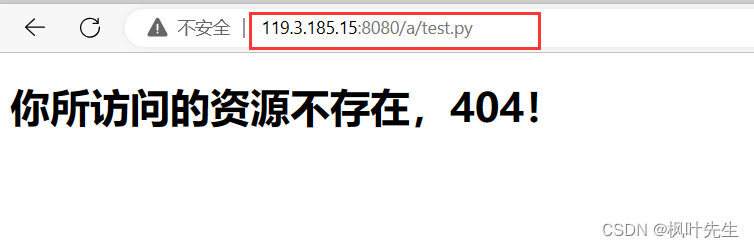
porque la página a la que se accedió /a/test.pyno existe, mostrar a 404la página (configurada por usted mismo)

para ver la información de la solicitud impresa por el servidor
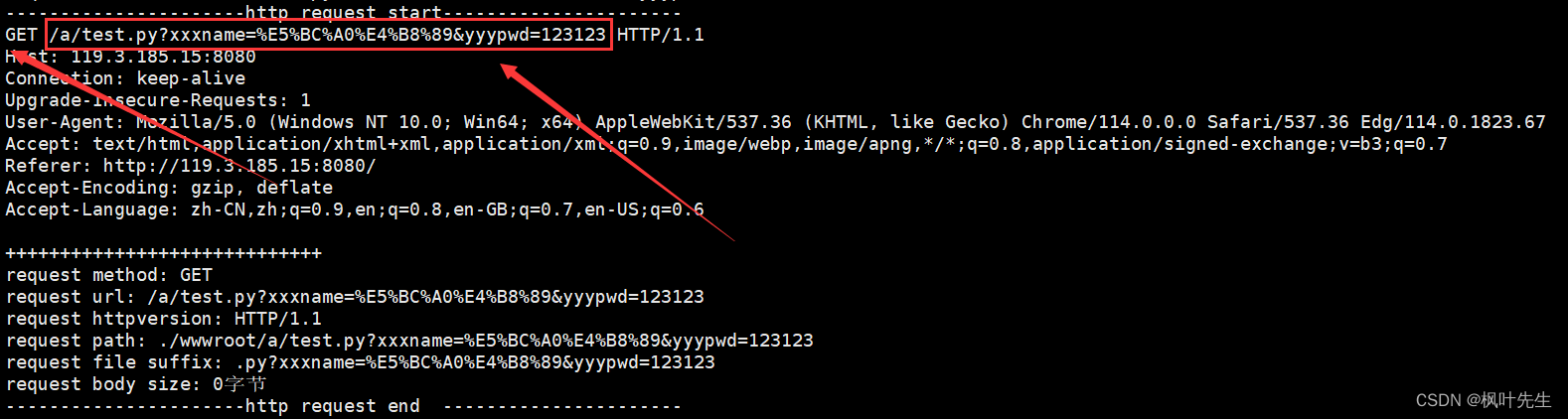
GETCuando el método envía parámetros, el envío de parámetros se empalmará con la parte posterior de la URL
/a/test.py?El frente es el recurso que queremos solicitar, y el reverso xxxname=%E5%BC%A0%E4%B8%89&yyypwd=123123es la información enviada por el formulario. También verá el contenido enviado en la barra de URL del navegador. Probemos
el POSTmétodo a continuación, modifique el
navegador HTML para acceder
al formulario de envío, y no lo verá en la barra de URL del navegador El contenido que enviamos, pero podemos ver los recursos a los que accedemos
Ver la información de solicitud impresa por el servidor
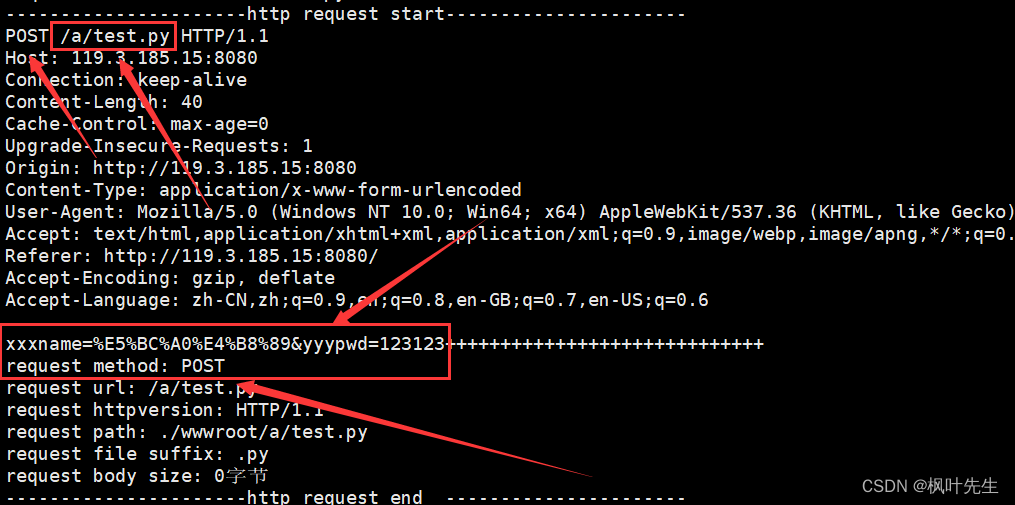
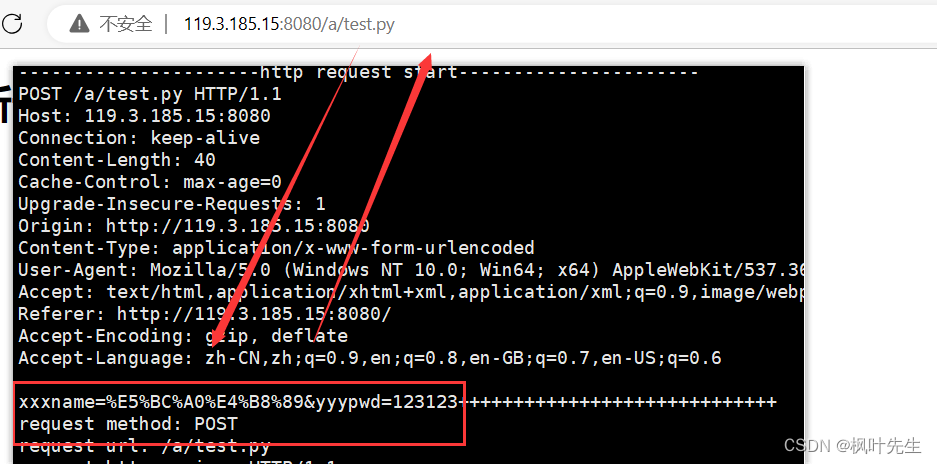
POSTEl método envía la información del formulario y los parámetros enviados se colocan en el cuerpo de la solicitud http
En la barra de URL del navegador, no veremos el contenido que enviamos, pero podemos ver los recursos que visitamos
Resumen:
GET/POSTla diferencia entre los métodos de solicitud http
GETEl parámetro de envío del método es pasar el parámetro a través de la URL, por ejemplo:http://ip:port/xxx/yyy?name=value&name2=value2...POSTEl parámetro de envío del método es enviar el parámetro a través del cuerpo de la solicitud httpPOSTEl método envía parámetros a través del cuerpo de la solicitud, que generalmente es invisible para los usuarios y mejor en privacidad.GETLos parámetros de envío del método son parámetros pasados a través de la URL, que cualquiera puede verGETEl método pasa el parámetro a través de la URL y el parámetro está destinado a no ser demasiado grande, mientras quePOSTel método pasa el parámetro a través del cuerpo y el cuerpo puede ser muy grande
Aviso: ¡Privacidad! = Seguridad, la seguridad HTTP no es buena, puede ser captada directamente por otros
Siete, código de estado HTTP
Los códigos de estado HTTP son los siguientes:
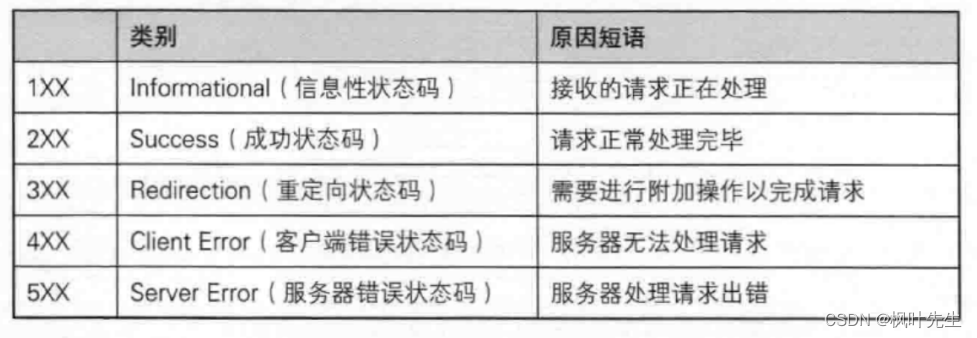
Nota: 1xx representa el código de estado que comienza con 1, el código de estado tiene tres dígitos, por ejemplo, 404 es
el código de estado más común, como200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
Hablemos de Redirección (código de estado de redirección)
La redirección es redirigir varias solicitudes de red a otras ubicaciones a través de varios métodos. En este momento, el servidor es equivalente a proporcionar un servicio de guía. La
redirección la realiza el cliente, y el servidor le dice al cliente que

redirija. Se puede dividir en redirección temporal. y redirección permanente El código de estado 301 indica una redirección permanente, mientras que los códigos de estado 302 y 307 indican una redirección temporal.
Movido permanentemente, redirigido permanentemente
- Permanente significa que los recursos a los que se accedió originalmente se han eliminado de forma permanente, y el cliente debe ser redirigido de acuerdo con el nuevo acceso URI
Redirección temporal
- Temporal significa que se puede acceder temporalmente a los recursos a los que se accede utilizando primero el URI de ubicación, pero los recursos antiguos aún están allí y es posible que no necesite redirigir la próxima vez que visite
- La redirección 302 puede tener secuestro de URL (secuestro de URL). Por ejemplo, los resultados de búsqueda siguen mostrando la URL A, pero el contenido de la página web utilizada es el contenido de su URL B. Esta situación se denomina secuestro de URL.
Para obtener más explicaciones sobre la redirección, enlace al artículo: Redirección
Aquí hay una demostración de redirección temporal
- El campo Ubicación es una información de atributo en el encabezado HTTP, que indica el sitio web de destino al que desea redirigir
Cambie el código de estado en la respuesta HTTP a 307 y luego continúe con la descripción del código de estado correspondiente. Además, debe agregar un campo de ubicación en el encabezado de respuesta HTTP. Esta ubicación es seguida por la página web a la que debe redirigir , como aquí Configurarlo como página de inicio de mi CSDN

En este momento, cuando el navegador acceda a nuestro servidor, saltará inmediatamente a la página de inicio de CSDN

El servidor responde imprimiendo información

Ocho, encabezado común HTTP
Los encabezados HTTP comunes son los siguientes:
Content-Type: tipo de datos (texto/html, etc.)Content-Length: la longitud del cuerpoHost: El cliente informa al servidor que el recurso solicitado está en qué puerto del host;User-Agent: declarar el sistema operativo del usuario y la información de la versión del navegador;Referer: Desde qué página se redirige la página actualLocation: Úselo con el código de estado 3xx para decirle al cliente dónde visitar a continuaciónCookie: Se utiliza para almacenar una pequeña cantidad de información en el lado del cliente. Normalmente se utiliza para implementar la función de sesión.
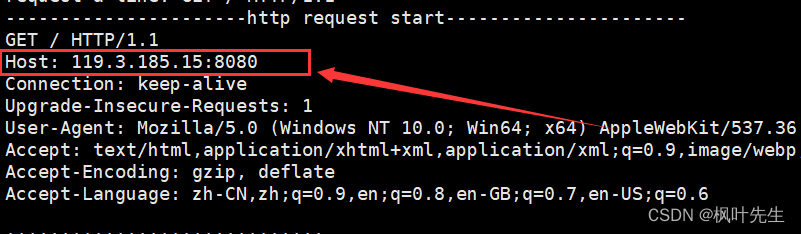
Anfitrión
HostEl campo indica la IP y el puerto del servicio al que el cliente quiere acceder, por ejemplo, cuando el navegador accede a nuestro servidor, el campo Host en la petición HTTP enviada por el navegador se rellena con nuestra IP y puerto.
Agente de usuario
Como se mencionó anteriormente, User-Agentrepresenta la información de la versión del sistema operativo y el navegador correspondiente al cliente.

Referirse
RefererRepresenta desde qué página estás saltando actualmente. RefererLa ventaja de grabar la página anterior es que es conveniente retroceder, y por otro lado, podemos saber la correlación entre nuestra página actual y la página anterior.
Keep-Alive (conexión larga)
Keep-Alive, también conocida como conexión larga, es una tecnología utilizada en el protocolo HTTP para mantener una conexión persistente entre el cliente y el servidor para reducir la demora y el consumo de recursos de cada solicitud
En el protocolo HTTP tradicional, cada vez que el cliente envía una solicitud, el servidor devolverá inmediatamente una respuesta y cerrará la conexión. Tal conexión se llama conexión corta. La conexión larga es que después de que se establece una conexión entre el cliente y el servidor, se pueden enviar múltiples solicitudes y se pueden recibir múltiples respuestas a través de la conexión. Las
ventajas de una conexión larga incluyen:
- Reducir la sobrecarga de establecimiento y desconexión de conexiones: en conexiones cortas, cada solicitud debe establecer y desconectar conexiones, mientras que las conexiones largas pueden reutilizar conexiones establecidas, reduciendo estas sobrecargas.
- Reducir el retraso: en conexiones cortas, cada solicitud necesita restablecer la conexión, mientras que las conexiones largas pueden evitar este retraso y mejorar la velocidad de respuesta.
- Reducir el consumo de recursos: en una conexión corta, cada solicitud necesita restablecer la conexión, y una conexión larga puede reducir el consumo de recursos del servidor
Por favor, tenga en cuenta: La conexión larga no es permanente. Tanto el servidor como el cliente pueden cerrar la conexión de forma activa. El valor correspondiente al campo
en la solicitud HTTP o el encabezado de respuesta significa que se admite la conexión larga. Hablemos de ello en detalle.ConnectKeep-Alive

Cookie和Session
Nueve, Cookie y Sesión
HTTP es en realidad un protocolo sin estado , no existe una relación entre cada solicitud/respuesta de HTTP, pero descubre que este no es el caso cuando usa un navegador.
Por ejemplo, cuando iniciamos sesión en un sitio web, como bilibili, después de iniciar sesión una vez, el estado de inicio de sesión puede permanecer durante mucho tiempo. Después de cerrar el sitio web de bilibili y volver a abrirlo, encontramos que la cuenta aún está iniciada, y no es necesario volver a iniciar sesión Cierra el navegador también
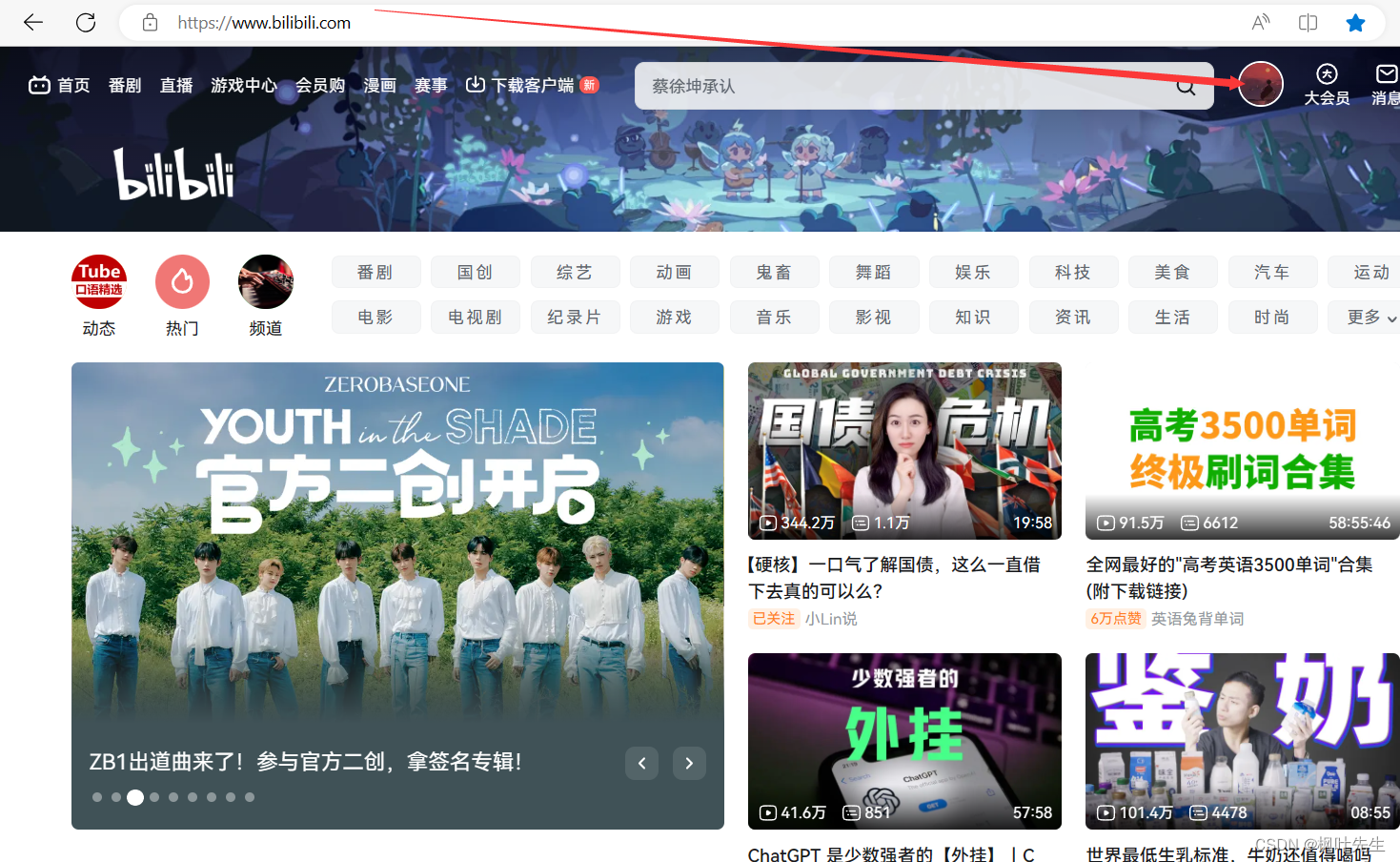
Esto se logra a través de
cookiey , esto se llama persistencia de sesiónsession
Aviso: Estrictamente hablando, la retención de la sesión no es una característica natural de http. Se encontró que la retención de la sesión es necesaria después de un uso posterior.
El protocolo http no tiene estado, pero los usuarios lo necesitan. Cuando el usuario realiza operaciones en la página web, es necesario visualizar una nueva página web. Si ocurre un salto de página, la nueva página no podrá identificar qué usuario es, y es necesario iniciar sesión nuevamente. Esto es obviamente inapropiado Por lo tanto, para el usuario
una vez que inicie sesión, puede visitar todo el sitio web de acuerdo con su propia identidad, lo que requiere la persistencia de la sesión
persistencia de sesión (forma antigua)
- Cuando el usuario visita el sitio web, el sitio web inducirá al usuario a iniciar sesión. Después de que el usuario inicie sesión, el navegador del cliente guardará el número de cuenta y la contraseña del usuario. En el futuro, siempre que el usuario visite el mismo sitio web, el el navegador empujará automáticamente el historial guardado información, autenticación
- El navegador guarda números de cuenta y contraseñas. Esta técnica se llama
cookie
Galleta
CookieEs un pequeño archivo de texto almacenado en el navegador del usuario, que se utiliza para almacenar información de autenticación de identidad del usuario, configuraciones personalizadas, etc. Cuando un usuario visita un sitio web, el servidor almacena cierta información y la envía al servidorCookieen futuras solicitudes.CookiecookieHay dos formas de guardar:cookie文件guardar ycookie内存guardar- Cierre el navegador y ábralo de nuevo, visite el sitio web en el que ha iniciado sesión anteriormente, si necesita volver a ingresar el número de cuenta y la contraseña, significa que la información de las cookies guardada en el navegador cuando inició sesión anteriormente está en el nivel de memoria
- Cierre el navegador o reinicie la computadora y ábralo nuevamente, visite el sitio web en el que inició sesión anteriormente, si no necesita volver a ingresar la cuenta y la contraseña, significa que la información de la cookie se guardó en el navegador cuando inició sesión antes está a nivel de archivo
Esto cookiese puede administrar en el navegador, cookieeliminar todo esto y todos los sitios web deben iniciar sesión nuevamente
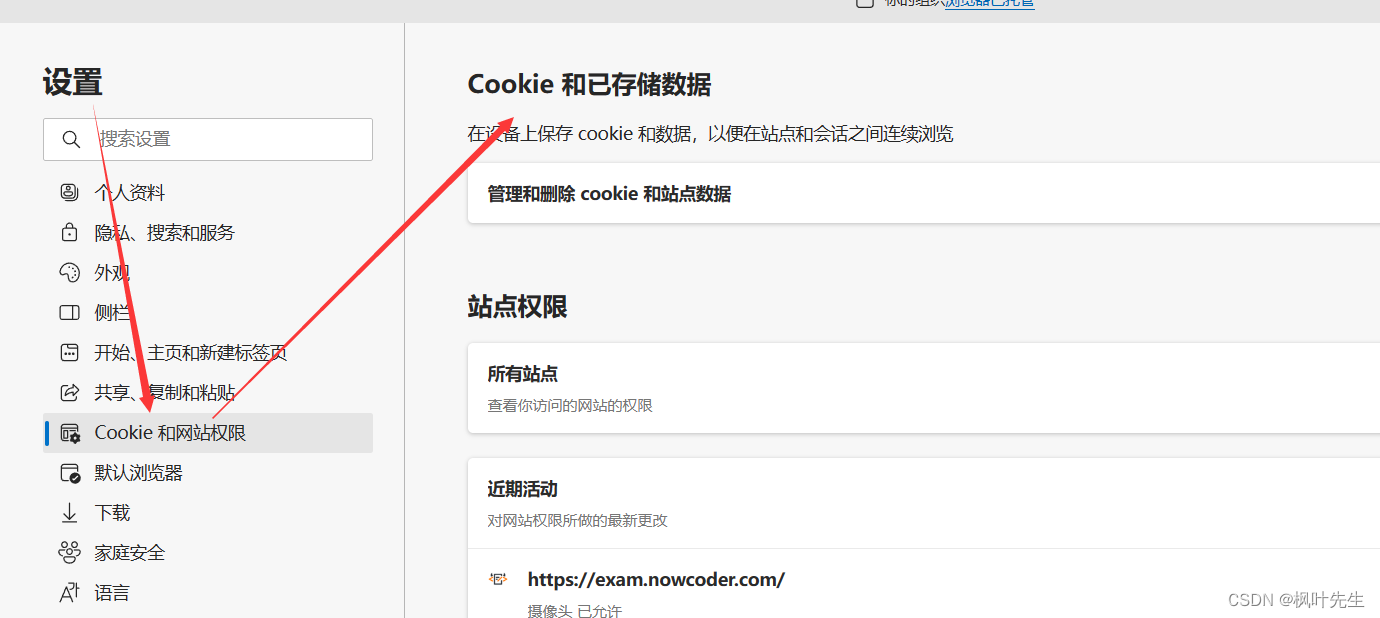
En el sitio web, después de iniciar sesión, también podemos ver el sitio web para cookie
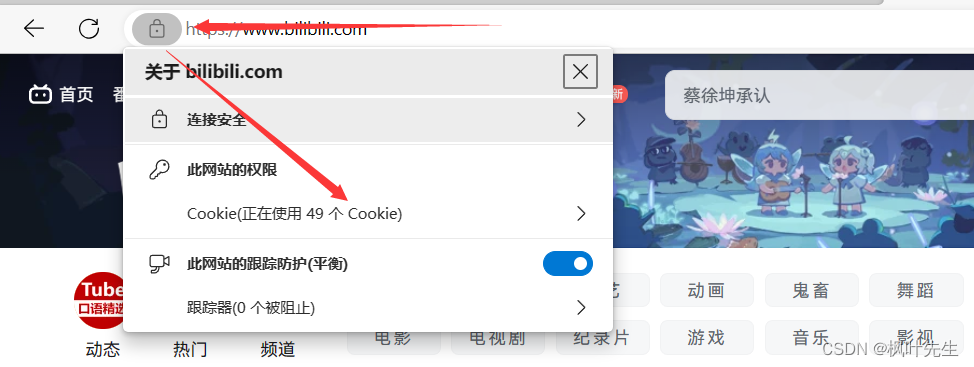
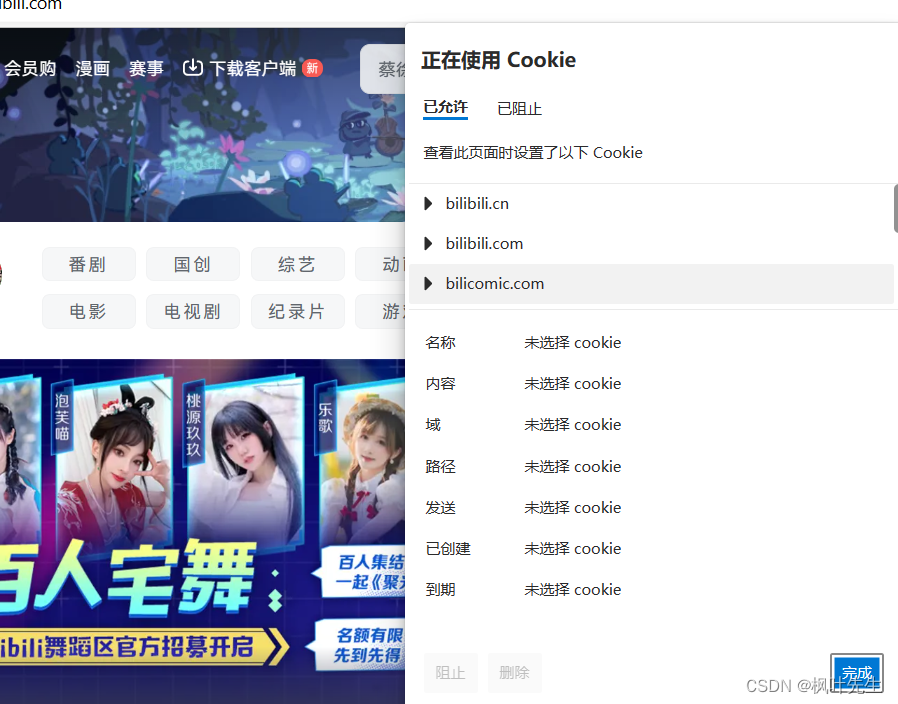
probarlo, cookieeliminar el sitio web, después de la eliminación, el usuario no ha iniciado sesión y necesita iniciar sesión de nuevo

cookieProblemas en uso
En circunstancias normales, no hay problema, si

la operación insegura del usuario está infectada con un virus, gusano, caballo de Troya, etc., la propia del usuario cookiese filtrará.
- Gusanos: cuyo objetivo es atacar directamente a los hosts de los usuarios (principalmente atacando la CPU, la memoria, etc.), provocando el agotamiento de los recursos del sistema.
- Virus del caballo de Troya: Los caballos de Troya son similares a los caballos de Troya de las antiguas leyendas, esconden a los soldados enemigos y salen de noche para destruirlos. El caballo de Troya no tiene como objetivo destruir la computadora, sino que está oculto en un programa aparentemente normal. Coopera con los piratas informáticos para cooperar con el interior y el exterior. El caballo de Troya tiene como objetivo robar información del usuario y controlar remotamente la computadora, y no atacar maliciosamente al host del usuario
cookieDespués de ser obtenido por alguien con malas intenciones, el hacker puede acceder directamente al servidor desde su propio navegador, y el servidor creerá erróneamente que el usuario está accediendo al servidor (gran daño a la sociedad)
Soluciónsession
sesión
sessionEs una tecnología de almacenamiento del lado del servidor para almacenar información de la sesión del usuario.- Cuando el usuario visita el sitio web por primera vez, el servidor creará una identificación única para el usuario
Session ID, almacenará la identificación en el navegador yCookiela enviará al navegador. El navegador enviará automáticamente esto al servidor en solicitudes posterioresSession ID. El servidorSession IDencuentra la información de la sesión correspondiente según el sessionSe almacena en el lado del servidor y cada usuario tiene unosession文件,session IDque es único en el servidor (una cadena)- El navegador del cliente no necesita almacenar la contraseña de la cuenta del usuario,
sessionIDsolo guárdela, es decir,sessionIDpóngalacookieen
SessionIDCuando iniciamos sesión en un sitio web por primera vez e ingresamos el número de cuenta y la contraseña , el servidor generará uno correspondiente después de que la autenticación del servidor sea SessionIDexitosa.Al
responder, el valor de ID de sesión generado se responderá al navegador. Después de que el navegador reciba la respuesta, extraerá automáticamente Session IDel valor y lo guardará en el cookiearchivo del navegador. Al acceder al servidor posteriormente, este se llevará automáticamente en la solicitud HTTP correspondiente Session ID.
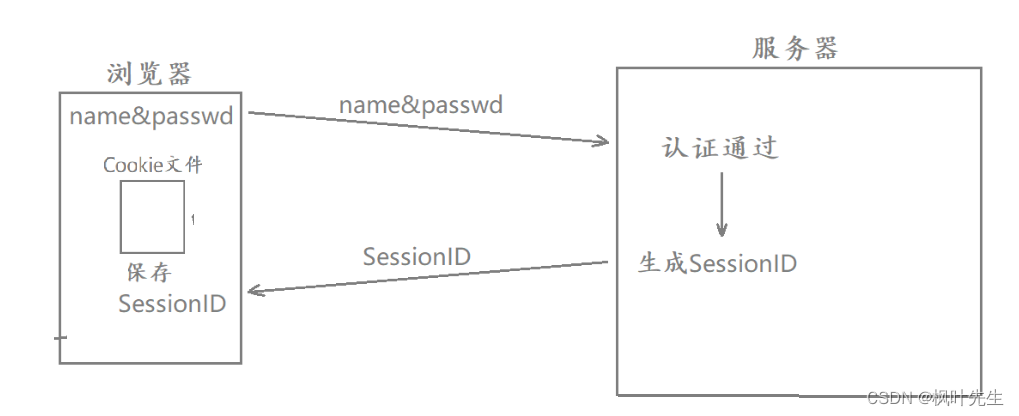
- En este momento, la fuga de información del usuario ha mejorado mucho, pero todavía hay problemas
- El pirata informático ha robado el archivo de sesión del usuario. El pirata informático puede acceder al servidor como el usuario, y el servidor creerá erróneamente que el usuario ilegal es un usuario normal. Esto no se puede resolver.
- En este momento, se utiliza cierta estrategia, como IP, para invalidarlo
session ID. Solo la persona con la contraseña puede iniciar sesión y el inicio de sesión vuelve a ser exitososession ID, lo que aliviasession IDel problema del robo hasta cierto punto (no se puede curado)
la seguridad es relativa
- Si bien no aborda realmente las preocupaciones de seguridad, este enfoque es relativamente seguro. No existe un concepto de seguridad absoluta en Internet. Cualquier seguridad es relativa. Incluso si cifra la información enviada a la red, puede ser descifrada por otros.
- Existe una regla en el campo de la seguridad: si el costo de descifrar una información es mucho mayor que los beneficios obtenidos después de descifrarla (lo que indica que hacer esto es una pérdida de dinero), entonces se puede decir que la información está segura .
Verifique a continuación, el cliente llevará la información de la cookie
- Cuando el navegador accede a nuestro servidor, si la respuesta HTTP del servidor al navegador contiene campos, entonces esta información
Set-Cookiese llevará cuando el navegador acceda al servidor nuevamente.cookie
j Simplemente modifique el código anterior, si hay demasiado código, no lo pegue, enlace: Código
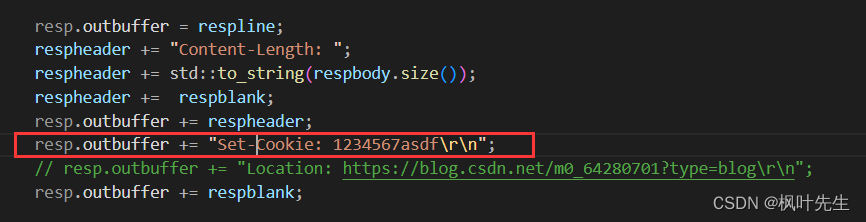
Agregue un campo al encabezado de respuesta del servidor Set-Cookiepara ver si el navegador traerá este Set-Cookiecampo cuando inicie la solicitud HTTP por segunda vez
Después de ejecutar el servidor, use un navegador para acceder a nuestro servidor, cookienosotros establecemos el valor 1234567asdf, en este momento, dicha cookie se escribe en el navegador,
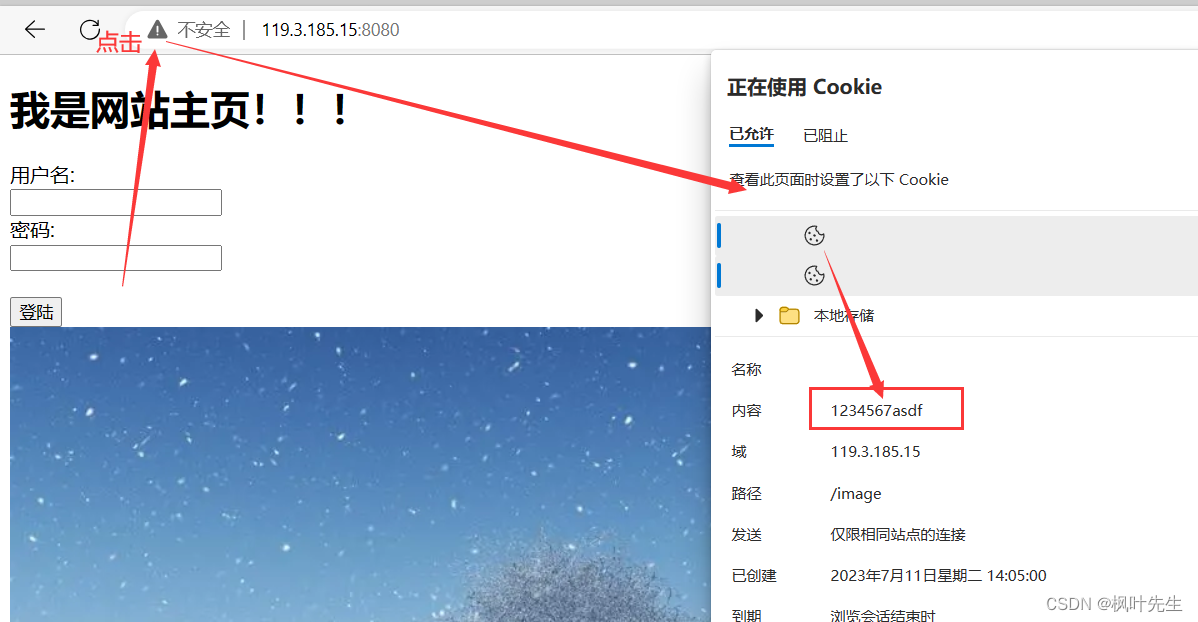
la segunda solicitud del cliente ya ha llevado la información de la cookie
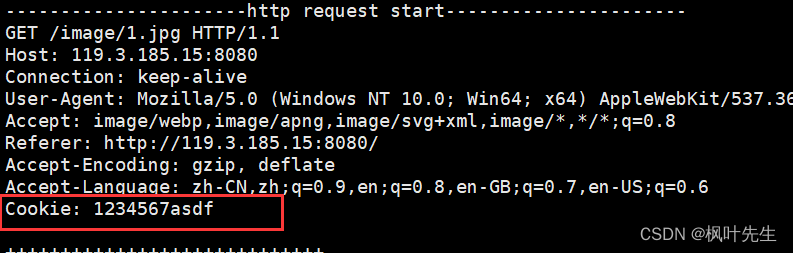
, después de eso, cada solicitud http transportará automáticamente todas las cookies que se han configurado para ayudar al servidor a realizar comportamientos de autenticación. Esta es la función de retención de sesión http
Recomendación de herramienta:
cartero: herramienta de depuración HTTP, simular el comportamiento del navegador
fiddler: herramienta de captura de paquetes, herramienta HTTP
--------------------- FIN --------- -- -----------
「 作者 」 枫叶先生
「 更新 」 2023.7.11
「 声明 」 余之才疏学浅,故所撰文疏漏难免,
或有谬误或不准确之处,敬请读者批评指正。