Durante mucho tiempo dudé si destacar el asunto de leer el código y escribirlo como un tweet. Después de todo, al leer el código, todo el mundo puede leerlo. Además, la cantidad de código que leí y escribí personalmente no es suficiente para guiar a todos a leer el código. Pero el autor aún decidió escribir un poco audazmente: es establecer un estándar para leer código para mí en el futuro y escribir algunos métodos que no se han practicado antes para su referencia. Si es inapropiado, por favor avise.
Para aquellos que se involucran en el aprendizaje profundo, los dos elementos imprescindibles en la vida diaria son leer códigos además de leer documentos . Para el método de lectura de documentos, consulte el artículo anterior, pero cómo leer y qué habilidades se usan para leer, todos tienen opiniones diferentes, por lo que no diré mucho aquí. Leer código es algo similar a leer documentos y leer libros, después de todo, todos están en la naturaleza de la lectura. Pero, de nuevo, leer código es muy diferente a leer papel.El código es un proceso de implementación de modelos y algoritmos en el papel, y es un proceso que requiere que su pensamiento esté en línea todo el tiempo. Y debido a que lo que leemos es el código del proyecto de aprendizaje profundo , no un libro enorme como el código del kernel de Linux, la naturaleza del código es algo diferente.
El código de un proyecto de aprendizaje profundo mencionado por el autor aquí debe leerse de diferentes maneras, desde una demostración de prueba con unos pocos cientos de líneas hasta un proyecto de código abierto con decenas de millones de líneas. La siguiente figura muestra la comparación entre el código del proyecto Mask R-CNN y el código fuente de PyTorch:
Se puede ver que Mask R-CNN es un marco de segmentación de instancias clásico, y se puede decir que su volumen de código es bastante satisfactorio. El volumen de código de 3k casi se puede gastar unos días después de que terminemos de leer el documento. Sin embargo, el código fuente de PyTorch no es tan amigable para la mayoría de las personas. La cantidad de código es de 750k, y el código C++ subyacente representa hasta la mitad de todo el proyecto. En lo que respecta a la investigación de aprendizaje profundo, puede ser llamado un nivel gigante. . Esta cantidad de código es como un principiante que obtiene una copia de PRML y, a menudo, le dedica mucha energía y luego no sucede nada. Por lo tanto, para estos dos tipos de códigos de proyecto, el método de lectura definitivamente será diferente.
Debido a que el propósito, la escena y el objeto de nuestra lectura de código son diferentes, el autor discutirá con usted cómo leer el código de un proyecto de aprendizaje profundo desde tres aspectos.
Algunas formas comunes de leer código
Algunas formas generales de leer el código primero. Este punto no se limita al código del proyecto de aprendizaje profundo, cualquier proyecto, la lectura de código en cualquier idioma es aplicable. Nuestra lectura diaria de código no es más que dos herramientas. Una es descargar el código al local, abrir IDLE y leer tranquilamente en IDLE:
Lectura directa del lado web de GitHub
Lea directamente en el lado web de GitHub, pero GitHub no establece el directorio de lectura a la izquierda como el editor. Cada vez que ingresa un archivo de código, debe salir para ingresar otro archivo, y la experiencia del usuario es extremadamente pobre. Por supuesto, nada de esto es un problema. Chrome nos proporciona complementos auxiliares de lectura como Octotree, que se pueden buscar e instalar directamente en la extensión de Chrome.
Después de la instalación, podemos tener la experiencia de leer el código IDLE directamente en el lado web:
Puede ver que hay una barra de directorio similar a IDLE en el lado izquierdo de la página, lo que nos facilita enormemente ver y leer el código del proyecto. Este es el nivel de herramienta en el método general, veamos algunas reglas básicas de lectura. Con las herramientas IDLE y Octotree, nuestro primer punto debe ser mirar detenidamente el directorio del código para tener una comprensión general de la estructura del código y la distribución de todo el proyecto. Para el aprendizaje profundo, los módulos en el directorio suelen ser relativamente fijos, como el directorio de modelos El código para la construcción y el entrenamiento del modelo se coloca en el directorio conifg, algunos archivos de configuración del modelo se colocan en el directorio conifg y la información de datos utilizada por el proyecto se coloca en el directorio de datos. La estructura de directorios del proyecto de segmentación semántica es la siguiente:
Una vez que esté familiarizado con la estructura del código del proyecto de aprendizaje profundo, naturalmente se familiarizará con él después de leer mucho, y la eficiencia de lectura también aumentará más adelante.
El segundo método general es encontrar rápidamente el documento Léame . En términos generales, el documento Léame en el directorio raíz contiene el método de uso de este código, que contiene información clave que puede permitirle comprender rápidamente el proyecto. En términos generales, el autor en el archivo Léame de un proyecto de código abierto describirá cómo usar el código y cómo implementarlo. La siguiente imagen es el documento Léame de DenseNet:
Para proyectos a gran escala, puede haber documentos Léame en cada subdirectorio. Esta es la parte que debemos leer detenidamente. El autor pone toda la información clave en él. Independientemente de esto, leer el archivo Léame por primera vez es un paso necesario y un método general para comprender el proyecto.
El tercer método general es cómo leer específicamente. Es decir, tenemos que determinar una línea principal de lectura . Este punto es un método general para los códigos de proyectos de aprendizaje profundo. Para un proyecto de aprendizaje profundo, los puntos más importantes que generalmente queremos entender no son más que datos, modelos y cómo entrenarlos. Si desea ver rápidamente los resultados de las pruebas de este proyecto de código abierto, simplemente lea el archivo Léame para ver cómo usarlo. Si el autor de este proyecto propone un nuevo marco de modelo, como bert, y desea conocer los detalles de su marco de modelo, ubique directamente el archivo .py con la palabra modelo en el directorio de modelos y comience a leer. O desea ver cómo se entrena este proyecto, qué trucos de entrenamiento se usan, cómo se inicializan sus parámetros, qué tan grande es el tamaño del lote, cómo se ajusta la tasa de aprendizaje durante el proceso de entrenamiento, etc., así que no diré much , ubique directamente el archivo .py con train. Los tres archivos de entrenamiento de fast-rcnn se muestran en la siguiente figura.
Según el propósito, ya sea la línea principal del modelo o el tren, definitivamente otras ramas estarán involucradas en el proceso de lectura, como otras ramas como datos y configuración. Mejora continuamente tu comprensión de las ramas durante el proceso de lectura principal y, con el tiempo, digerirás un proyecto completo.
Los anteriores son algunos métodos generales para leer códigos de proyectos de aprendizaje profundo. Hablemos de la lectura de código de los dos escenarios en detalle. Después de todo, todos prestan atención al propósito al hacer las cosas y, a menudo, hacen algo con un propósito fuerte, y la eficiencia es generalmente particularmente alta.
La primera escena es cuando todos encuentran problemas mientras investigan y realizan proyectos . No sé cómo resolver este problema y cuando Google no puede encontrar un método adecuado directamente. En este momento, esperamos buscar en GitHub. Por ejemplo, queremos saber cómo ponderar la función de pérdida cuando los datos están extremadamente desequilibrados, o cómo encontrar el mejor umbral de clasificación para la predicción del modelo para problemas de etiquetas múltiples, etc. Es probable que todos estos problemas se encuentren cuando estamos haciendo proyectos reales. En este caso, si puede encontrar una solución para un escenario similar en GitHub, creo que se actualizará instantáneamente.
El siguiente proyecto de clasificación de etiquetas múltiples de CNN basado en keras utiliza matthews_corrcoef para determinar el mejor umbral de predicción de clasificación para la optimización del umbral de clasificación de etiquetas múltiples. En cuanto a lo que es matthews_corrcoef, estos son los lugares que necesita aprender y absorber en el proceso de resolución de problemas. En resumen, leer a propósito el código de un determinado proyecto a menudo es solo leer un determinado bloque o incluso unas pocas líneas clave. El número no es grande y puede resolver su problema.
El segundo escenario es leer código para la superación personal . El llamado refinamiento personal es la clave para una persona con una gran cantidad de tiempo disponible de estudio e investigación personal, un alto grado de autodisciplina y una fuerte capacidad de aprendizaje para dar un salto en la capacidad. **Aunque el autor acude ocasionalmente a GitHub para leer algunos códigos, está lejos de ser suficiente para alcanzar el nivel de superación personal. Por ejemplo, el código fuente PyTorch 750k anterior, con una cantidad de código tan grande, la estrategia de lectura debe ser la idea de divide y vencerás, cerco disperso y destrucción individual. Descomponiendo el proyecto, estableciendo planes y objetivos de lectura, todavía es posible completarlo con una super ejecución. Esto no es algo que haga la gente común, pero creo que aquellos que pueden mejorar en el campo del aprendizaje profundo no serán personas comunes.
¿Qué debo hacer si el código descargado no se ejecuta?
El código descargado rara vez se ejecuta por primera vez, y la mayoría de ellos informarán errores debido a problemas como el entorno local y la versión del paquete. En este momento, una forma es verificar si su propia versión se ajusta al entorno proporcionado por el código fuente uno por uno, la segunda forma es preguntar directamente al autor o buscar directamente en los problemas de código existentes.Algunos códigos fuente clásicos tienen ya ha sido publicado Los predecesores propusieron los hoyos y las soluciones que pisaron. Ambos son más problemáticos.
La reciente popularidad de chatgpt y gpt4 facilita la corrección de errores. Por ejemplo, el siguiente ejemplo, creo que todos están familiarizados con él, GPT4 no solo da una solución, sino que también explica por qué ocurre este error.
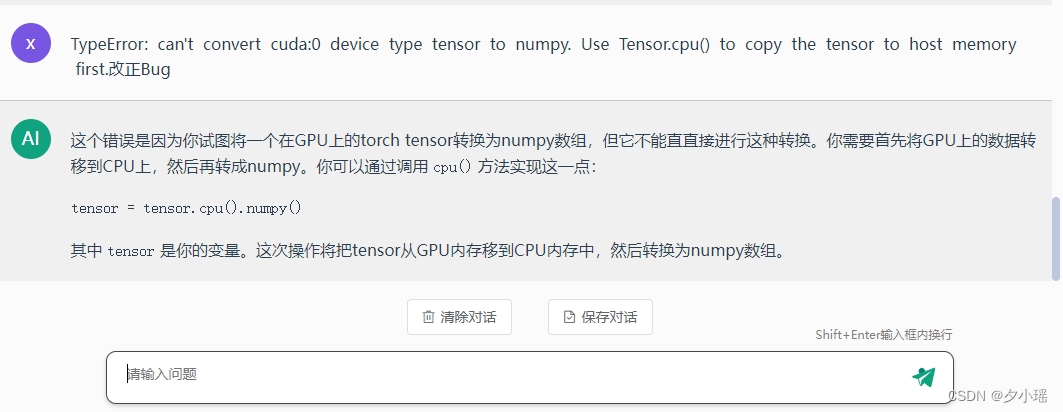
GPT-4 es un gran modelo de lenguaje autorregresivo que puede comprender y generar lenguaje humano, incluso lenguaje de programación de computadoras, aprendiendo una gran cantidad de datos de entrenamiento. Su rendimiento en la corrección de errores de código se debe principalmente al entrenamiento del modelo en una gran cantidad de bases de código y documentos relacionados. Si está interesado, puede usar https://gpt4test.com para probarlo. Puede probarlo en China, no es necesario cruzar el muro y el sitio es estable. Para errores más complejos, puede usar el siguiente aviso para hacer preguntas sobre gpt:
Basado en el siguiente código (código de copia), hay un error (error de copia), ayúdame a corregirlo según el código original
GPT no solo puede descubrir la causa del error, sino también proporcionar el código modificado, que se puede copiar y usar directamente. Creo que después de probarlo, programará gradualmente para gpt. ¡Es realmente fragante!
Es cierto que ya sea leyendo libros de texto, leyendo documentos o leyendo códigos mencionados en este artículo, estos son en sí mismos un proceso de mejora de la capacidad de aprendizaje personal y adquisición de conocimientos. Para nosotros, que estamos comprometidos con el aprendizaje profundo, hay un sinfín de documentos sobre arxiv y códigos en GitHub. La clave es seguir aprendiendo y ser un aprendiz de por vida .
Con el fin de ayudarlo a leer mejor los documentos y comprender la información de vanguardia, hemos compilado un producto seco de núcleo duro: el primer manual completo de inteligencia artificial de la industria , que contiene hasta 3,000 páginas, que cubren el desarrollo de tecnología de modelo de lenguaje grande, las últimas tendencias y aplicaciones de la tecnología AIGC, la tecnología de aprendizaje profundo y otras direcciones de IA.
La cuenta pública de WeChat sigue "Xi Xiaoyao Technology Talk" y responde "789" para descargar materiales.![[imagen]](https://img-blog.csdnimg.cn/dd8812ed0c7b414880fe1a79e6db956e.png)