Hola a todos, soy Weixue AI. Hoy les presentaré la inteligencia artificial (pytorch) para construir un modelo 17-pytorch para construir un modelo ReitnNet, cargar datos para el entrenamiento y la predicción del modelo, y RetinaNet es un modelo de aprendizaje profundo para la detección de objetivos. tareas Su objetivo es resolver el problema de muestras duras y clases desequilibradas en la detección de objetos. Es un método mejorado basado en un detector de una sola etapa, que logra una detección de objetos eficiente y precisa mediante la introducción de una función de pérdida y una estructura de red específicas.
La principal innovación de RetinaNet es utilizar una función de pérdida llamada Pérdida Focal para tratar el problema del desequilibrio de categorías durante el entrenamiento. En las tareas de detección de objetivos, las muestras negativas (es decir, los no objetivos) suelen ser mucho más que las muestras positivas (es decir, los objetivos), lo que conducirá a una capacidad de predicción excesiva del modelo para las muestras negativas y una capacidad de predicción débil para las muestras positivas. Focal Loss ajusta el peso de las muestras fáciles de clasificar para que el modelo preste más atención a las muestras que son difíciles de clasificar, aumentando así la atención a las muestras positivas y mejorando la precisión de la detección de objetivos.
Tabla de contenido
- introducción
- Principio del modelo RetinaNet
- Ejemplo de datos CSV
- carga de datos
- Uso del marco PyTorch para entrenar y predecir el modelo RetinaNet
- en conclusión
1. Introducción
En el campo del aprendizaje profundo, la detección de objetos es una dirección de investigación importante. RetinaNet es un modelo de detección de objetivos eficiente, que resuelve el problema del desequilibrio entre las categorías de primer plano y de fondo mediante la introducción de pérdida focal, logrando así resultados notables en las tareas de detección de objetivos. Este artículo presentará el principio del modelo RetinaNet en detalle y mostrará cómo usar el marco PyTorch para entrenar y predecir el modelo RetinaNet a través de un proyecto práctico.
2. Principio del modelo RetinaNet
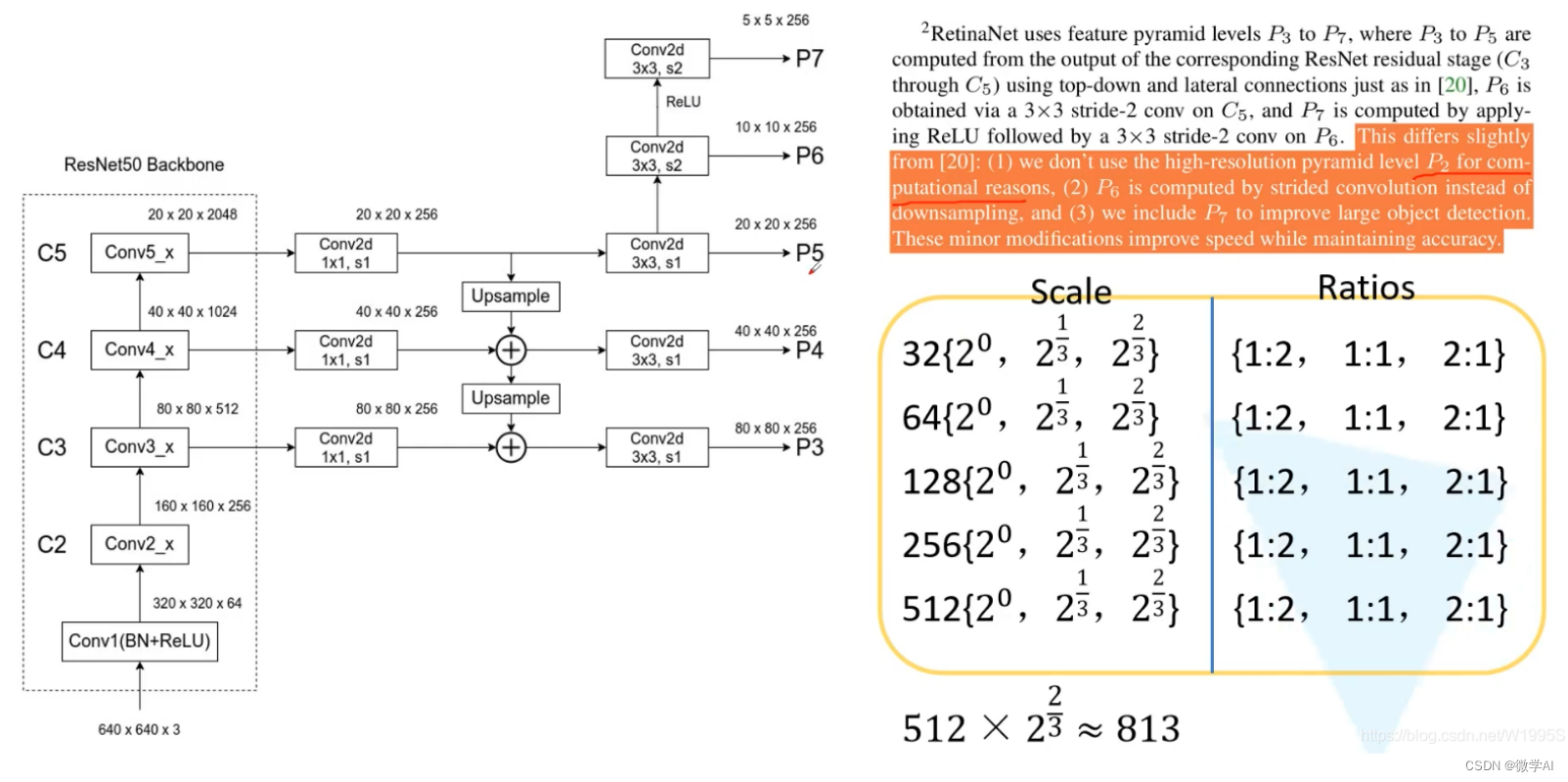
RetinaNet es un modelo de detección de objetos basado en el aprendizaje profundo, que consta de dos partes: Feature Pyramid Network (FPN) y subred de clasificación/regresión. El FPN se usa para extraer características de la imagen de entrada, mientras que la subred de clasificación/regresión se usa para predecir la categoría y la ubicación del objeto.
La innovación clave de RetinaNet es la introducción de una nueva función de pérdida: pérdida focal. En los modelos tradicionales de detección de objetos, dado que la cantidad de muestras de la categoría de fondo es mucho mayor que la de la categoría de primer plano, el modelo a menudo está dominado por una gran cantidad de muestras de fondo, lo que resulta en una disminución en el rendimiento de detección de la categoría de primer plano. . Focal Loss resuelve este problema dando más peso a las muestras que son difíciles de clasificar.
RetinaNet es un modelo de detección de objetivos basado en el aprendizaje profundo, y su principio matemático se puede expresar mediante la siguiente fórmula:
Primero, para una imagen de entrada, los mapas de características se extraen utilizando una red neuronal convolucional básica como ResNet. Supongamos que el tamaño del mapa de características es H × W × CH × W × CH×W×C , dondeHHHwaWW __W representa alto y ancho, respectivamente, y C representa el número de canales.
Luego, RetinaNet presenta una Feature Pyramid Network (FPN) para manejar objetos de diferentes tamaños mediante la generación de mapas de características con diferentes escalas en diferentes niveles. El mapa de características de cada nivel en FPN se puede expresar como P i P_iPAGyo, donde i representa el índice de la jerarquía. Cada P i P_iPAGyoEl tamaño es H i × W i × C i H_i×W_i×C_iHyo×Wyo×Cyo。
A continuación, RetinaNet presenta dos subredes paralelas: la subred de clasificación de objetos y la subred de regresión de cuadro delimitador.
La subred de clasificación de objetos divide cada P i P_i usando una capa convolucional de 1×1PAGyoEl mapa de funciones de se asigna a un mapa de funciones con canales K, donde KKK denota el número de categorías objetivo (incluido el fondo). Este mapa de características representa la probabilidad de que cada píxel pertenezca a una clase diferente. Luego, estas probabilidades se normalizan utilizando la función softmax para obtener las probabilidades finales de clasificación.
La subred de regresión del cuadro delimitador divide cada P i P_i usando una capa convolucional de 1×1PAGyoEl mapa de características de está asignado a un mapa de características con 4 canales. Este mapa de características representa la predicción de regresión de coordenadas de cada píxel correspondiente al cuadro delimitador del objeto.
3. Ejemplo de datos CSV
Los siguientes son algunos ejemplos de datos CSV, cada fila de datos contiene la ruta de la imagen, las coordenadas y la categoría del objetivo:
/path/to/image1.jpg,100,120,200,230,cat
/path/to/image1.jpg,300,400,500,600,dog
/path/to/image2.jpg,50,100,150,200,bird
/path/to/image3.jpg,100,120,200,230,cat
/path/to/image4.jpg,300,400,500,600,dog
/path/to/image5.jpg,50,100,150,200,bird
...
4. Carga de datos
Primero necesitamos cargar los datos CSV y convertirlos a un formato que el modelo pueda aceptar. Aquí está el código para la carga de datos:
import csv
import torch
from PIL import Image
class CSVDataset(torch.utils.data.Dataset):
def __init__(self, csv_file):
self.data = []
with open(csv_file, 'r') as f:
reader = csv.reader(f)
for row in reader:
img_path, x1, y1, x2, y2, class_name = row
self.data.append((img_path, (x1, y1, x2, y2), class_name))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img_path, bbox, class_name = self.data[idx]
img = Image.open(img_path).convert('RGB')
return img, bbox, class_name
5. Uso del marco PyTorch para entrenar y predecir el modelo RetinaNet
A continuación, usaremos el marco PyTorch para entrenar y predecir el modelo RetinaNet. Aquí está el código para el entrenamiento y la predicción:
import torch
from torch import nn
from torch.optim import Adam
from torchvision.models.detection import retinanet_resnet50_fpn
# 加载数据
dataset = CSVDataset('data.csv')
data_loader = torch.utils.data.DataLoader(dataset, batch_size=2, shuffle=True)
# 创建模型
model = retinanet_resnet50_fpn(pretrained=True)
model = model.cuda()
# 定义优化器和损失函数
optimizer = Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
# 训练模型
for epoch in range(10):
for imgs, bboxes, class_names in data_loader:
imgs = imgs.cuda()
bboxes = bboxes.cuda()
class_names = class_names.cuda()
# 前向传播
outputs = model(imgs)
# 计算损失
loss = criterion(outputs, class_names)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 10, loss.item()))
# 预测
model.eval()
with torch.no_grad():
for imgs, _, _ in data_loader:
imgs = imgs.cuda()
outputs = model(imgs)
print(outputs)
6. Conclusión
Este artículo presenta el principio del modelo RetinaNet en detalle y muestra cómo usar el marco PyTorch para entrenar y predecir el modelo RetinaNet a través de un proyecto práctico. El modelo RetinaNet resuelve el problema de las categorías de fondo y primer plano desequilibradas mediante la introducción de pérdida focal, logrando así resultados notables en las tareas de detección de objetivos. Espero que este artículo pueda ser útil para su estudio e investigación.