
Autor | Guangdong Liu, responsable de Apache SeaTunnel
fondo
Actualmente, las soluciones de búsqueda de libros existentes, como las que utilizan las bibliotecas públicas, dependen en gran medida de la coincidencia de palabras clave en lugar de una comprensión semántica del contenido real de los títulos de los libros. Por lo tanto, los resultados de la búsqueda no podrán satisfacer muy bien nuestras necesidades, e incluso ser bastante diferentes de los resultados que esperamos. Esto se debe a que no es suficiente confiar únicamente en la coincidencia de palabras clave, ya que no puede lograr la comprensión semántica y, por lo tanto, no puede comprender la intención real del buscador.
Entonces, ¿hay una mejor manera de realizar búsquedas de libros de manera más precisa y eficiente? ¡La respuesta es sí! En este artículo, presentaré cómo usar Apache SeaTunnel, Milvus y OpenAI para realizar una búsqueda de similitud para lograr una comprensión semántica del título completo del libro, lo que hace que los resultados de la búsqueda sean más precisos.
El uso de un modelo entrenado para representar datos de entrada se conoce como búsqueda semántica, y este enfoque se puede extender a una variedad de diferentes casos de uso basados en texto, incluida la detección de anomalías y la búsqueda de documentos. Por lo tanto, la tecnología presentada en este documento puede generar avances e impactos significativos en el campo de la búsqueda de libros.
A continuación, permítanme presentar brevemente algunos conceptos relacionados con este artículo y las herramientas/plataformas utilizadas, para que todos puedan comprender mejor este artículo.
¿Qué es Apache SeaTunnel?
Apache SeaTunnel es una plataforma informática y de gestión de datos distribuidos de código abierto y alto rendimiento. Es un proyecto de alto nivel respaldado por Apache Foundation, capaz de procesar cantidades masivas de datos, proporcionar consultas y cálculos de datos en tiempo real y admitir múltiples fuentes y formatos de datos. El objetivo de SeaTunnel es proporcionar una plataforma de gestión e integración de datos escalable y orientada a la empresa para satisfacer diversas necesidades de procesamiento de datos a gran escala.
¿Qué es Milvus?
Milvus es un motor de búsqueda de vectores similares de código abierto, que admite el almacenamiento, la recuperación y la búsqueda de similitud de vectores masivos. Es una solución de alto rendimiento y bajo costo para datos vectoriales a gran escala. Milvus se puede utilizar en varios escenarios, como el sistema de recomendación, la búsqueda de imágenes, la recomendación de música y el procesamiento del lenguaje natural.
¿Qué es OpenAI?
ChatGPT es un sistema de generación de diálogos basado en el modelo GPT (Generative Pre-trained Transformer), desarrollado por OpenAI. El sistema utiliza principalmente procesamiento de lenguaje natural, aprendizaje profundo y otras tecnologías para generar texto en lenguaje natural similar al diálogo humano. ChatGPT tiene una amplia gama de aplicaciones y se puede utilizar para desarrollar aplicaciones como servicio al cliente inteligente, robots de chat y asistentes inteligentes, y también se puede utilizar para la investigación y el desarrollo de modelos de lenguaje. En los últimos años, ChatGPT se ha convertido en uno de los focos de investigación en el campo del procesamiento del lenguaje natural.
¿Qué es LLM (modelo de lenguaje grande)?
Large Language Model (Modelo de lenguaje grande) es un modelo de procesamiento de lenguaje natural basado en tecnología de aprendizaje profundo, que puede analizar y comprender un texto determinado y generar contenido de texto relevante. Los modelos de lenguaje grande generalmente usan redes neuronales profundas para aprender las reglas sintácticas y semánticas del lenguaje natural y convertir datos de texto en representaciones vectoriales en espacios vectoriales continuos. Durante el proceso de entrenamiento, el modelo de lenguaje grande utiliza una gran cantidad de datos de texto para aprender patrones de lenguaje y leyes estadísticas, de modo que se pueda generar contenido de texto de alta calidad, como artículos, noticias, diálogos, etc. Los campos de aplicación de los grandes modelos de lenguaje son muy amplios, incluyendo traducción automática, generación de texto, sistema de respuesta a preguntas, reconocimiento de voz, etc. En la actualidad, muchos marcos de aprendizaje profundo de código abierto proporcionan la implementación de grandes modelos de lenguaje, como TensorFlow, PyTorch, etc.
tutorial
¡Aquí viene el punto! Mostraré cómo usar Apache SeaTunnel, la API de incrustación de OpenAI con nuestra base de datos vectorial para buscar semánticamente títulos de libros completos.
pasos de preparación
Antes del experimento, debemos ir al sitio web oficial para obtener un token de OpenAI y luego implementar un entorno experimental de Milvus . También necesitamos preparar los datos que se utilizarán para este ejemplo. Puedes descargar los datos desde aquí.
Importe datos a Milvus a través de SeaTunnel Primero, coloque book.csv en /tmp/milvus_test/book, luego configure la tarea como milvus.conf y colóquela en config. Consulte la Guía de inicio rápido .
env {
# You can set engine configuration here
execution.parallelism = 1
job.mode = "BATCH"
checkpoint.interval = 5000
#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
}
source {
# This is a example source plugin **only for test and demonstrate the feature source plugin**
LocalFile {
schema {
fields {
bookID = string
title_1 = string
title_2 = string
}
}
path = "/tmp/milvus_test/book"
file_format_type = "csv"
}
}
transform {
}
sink {
Milvus {
milvus_host = localhost
milvus_port = 19530
username = root
password = Milvus
collection_name = title_db
openai_engine = text-embedding-ada-002
openai_api_key = sk-xxxx
embeddings_fields = title_2
}
}Ejecute el siguiente comando:
./bin/SeaTunnel.sh --config ./config/milvus.conf -e localVea los datos en la base de datos y podrá ver que los datos se han escrito en ella.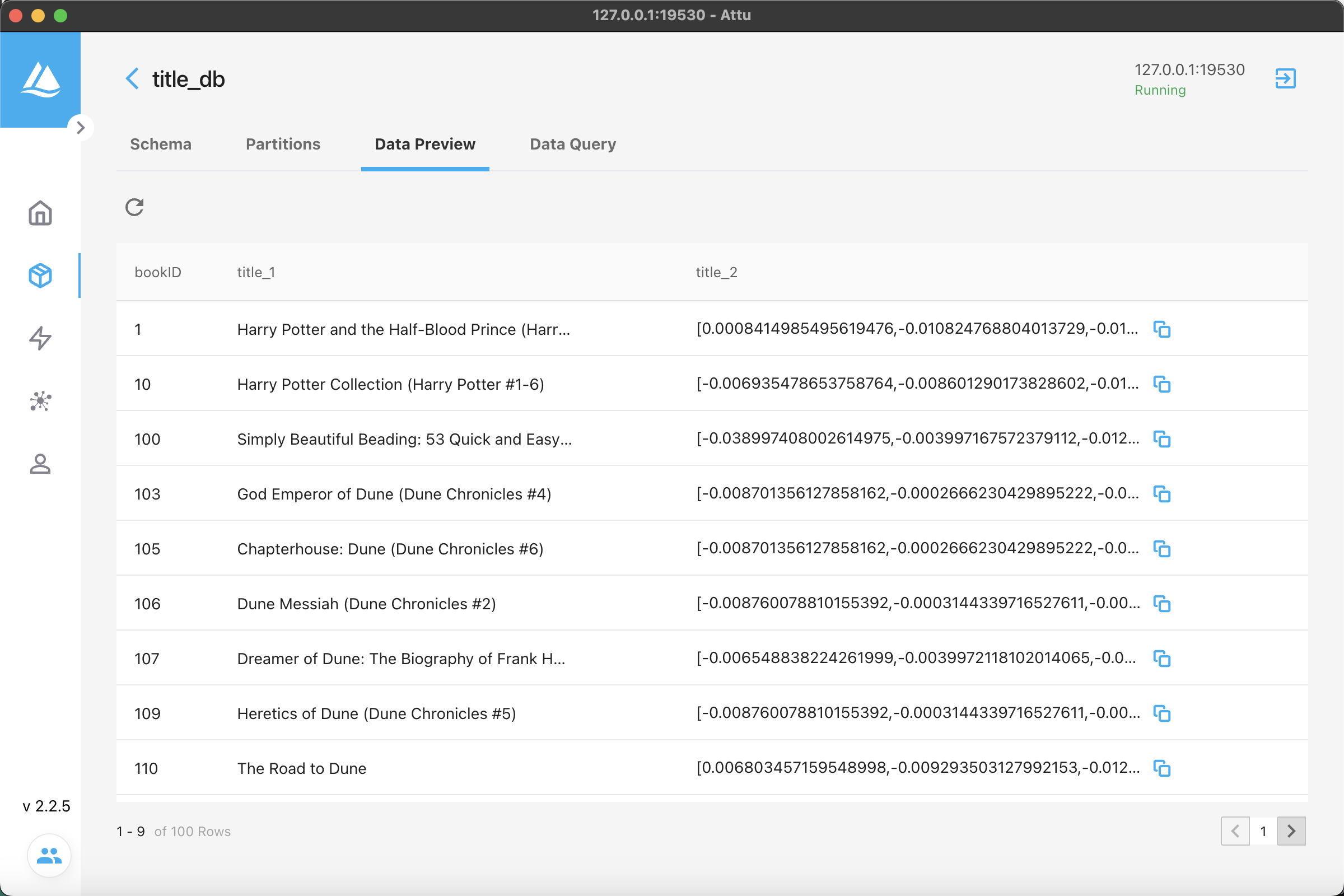
Luego use el siguiente código para buscar títulos de libros semánticamente:
import json
import random
import openai
import time
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
COLLECTION_NAME = 'title_db' # Collection name
DIMENSION = 1536 # Embeddings size
COUNT = 100 # How many titles to embed and insert.
MILVUS_HOST = 'localhost' # Milvus server URI
MILVUS_PORT = '19530'
OPENAI_ENGINE = 'text-embedding-ada-002' # Which engine to use
openai.api_key = 'sk-******' # Use your own Open AI API Key here
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
collection = Collection(name=COLLECTION_NAME)
collection.load()
def embed(text):
return openai.Embedding.create(
input=text,
engine=OPENAI_ENGINE)["data"][0]["embedding"]
def search(text):
# Search parameters for the index
search_params={
"metric_type": "L2"
}
results=collection.search(
data=[embed(text)], # Embeded search value
anns_field="title_2", # Search across embeddings
param=search_params,
limit=5, # Limit to five results per search
output_fields=['title_1'] # Include title field in result
)
ret=[]
for hit in results[0]:
row=[]
row.extend([hit.id, hit.score, hit.entity.get('title_1')]) # Get the id, distance, and title for the results
ret.append(row)
return ret
search_terms=['self-improvement', 'landscape']
for x in search_terms:
print('Search term:', x)
for result in search(x):
print(result)
print()Los resultados de la búsqueda son los siguientes:
Search term: self-improvement
[96, 0.4079835116863251, "The Dance of Intimacy: A Woman's Guide to Courageous Acts of Change in Key Relationships"]
[56, 0.41880303621292114, 'Nicomachean Ethics']
[76, 0.4309804439544678, 'Possession']
[19, 0.43588975071907043, 'Vanity Fair']
[7, 0.4423919916152954, 'Knowledge Is Power (The Amazing Days of Abby Hayes: #15)']
Search term: landscape
[9, 0.3023473024368286, 'The Lay of the Land']
[1, 0.3906732499599457, 'The Angry Hills']
[78, 0.392495334148407, 'Cloud Atlas']
[95, 0.39346450567245483, 'Alien']
[94, 0.399422287940979, 'The Known World']Si seguimos el método antiguo - búsqueda por palabra clave, el título del libro debe contener palabras clave como superación personal y mejora; pero si proporcionamos un modelo grande para la comprensión semántica, podemos recuperar títulos que satisfagan mejor nuestras necesidades. Por ejemplo, en el ejemplo anterior, la palabra clave que buscamos fue superación personal (autosuperación), y los títulos de los libros mostrados fueron "Dance of Relationship: The Art of Getting Together Intimately and Independently", "Nicomachean Ethics". , etc. Contiene palabras clave relevantes, pero obviamente está más en línea con nuestros requisitos. Se puede ver que podemos usar Apache SeaTunnel, Milvus y OpenAI para lograr una búsqueda más precisa de la similitud de los títulos de los libros a través del método de modelos de lenguaje grandes, que ha traído importantes avances tecnológicos en el campo de la búsqueda de libros y también ha proporcionado información valiosa. para la comprensión semántica Espero que pueda servirte de inspiración.
enlaces relacionados
- https://seatunnel.apache.org/
- https://openai.com/
- https://milvus.io/
¡ Este artículo está respaldado por la tecnología de código abierto de Beluga !