CACD is the abbreviation of Cant assign, Cache Dirty, a professional term of DELL EMC.
Before we start, let me introduce the concept of cache dirty. The simple language means that there is dirty data, and dirty data is of course data that cannot be used. Why is the data dirty? Let's start with the basic concept of storage.
In order to speed up the IO response speed of the host, all enterprise-level storage has the concepts of read cache and write cache. The write cache is a part of the memory space. All write operations are actually written to the write cache instead of directly It is written to the back-end disk. Of course, if the write cache is disabled, the data will be directly dropped to the disk, but the performance will be poor. The data in the cache is periodically written to the disk in batches according to a certain algorithm. That is, if the storage system is working normally, there will always be data written from the host stored in cache memory. If there is a problem with this part of the data, that is to say, from the host side, he has written the data to the storage, but the disk that actually stores the physical data has not written the data, and the data is in the cache due to various cause was destroyed. This leads to problems with data consistency on the physical disk. The data in these caches is also called dirty data. Because these data are written to the back-end storage disk, the data integrity is incorrect, and the storage does not allow these data to be written.
If there is a dirty cache, what will be the consequences? The most direct consequence is that the consistency of the customer's business data is lost and the data is incomplete. If you continue to use these data, you must do an integrity check, which is what we often say The fsck is up. In fact, from the definition of storage, data has already been lost, and data loss occurs, but it is just the amount of lost data.
Let's go back to the topic of this article. EMC's Clariion storage system is the storage of the CX, VNX and Unity series. If a dirty cache event occurs, what is the performance of the storage? The following discussion focuses on VNX as an example. CX is similar to Unity, but the processing methods are different. According to the distribution of dirty data in the storage, if there are several different pools on the customer storage, the LUN and POOL in the dirty pool will be offline, and of course the business will be suspended. As shown below:

Some LUNs are offline, while some LUNs are ready for this reason.
The POOLs corresponding to these LUNs are also in the offline state. If there is cache dirty, the service must be suspended, which is the so-called DU, and data unavailable.
The following is the key point, knock on the blackboard. Why does it cause cache dirty, and how to avoid this from happening? The most common are the following situations:
- The client shuts down by mistake.
The case of dirty cache is often encountered on the first day of work after the holiday. Why is this? Some customers turn off the storage because of the holiday, and then after going to work, the first thing is to turn it on. After turning it on, they say that the business is not connected up. In this case, without looking at the logs, it is highly likely that the cache is dirty. There is also the relocation of the computer room. Before the relocation, it was OK, but after moving to the new computer room, the startup will not work. In all likelihood, this situation is also cache dirty.
Why is the shutdown operation likely to cause cache dirty? Let's take a look at the power connection method of VNX. The following figure is the power connection diagram of VNX5300.
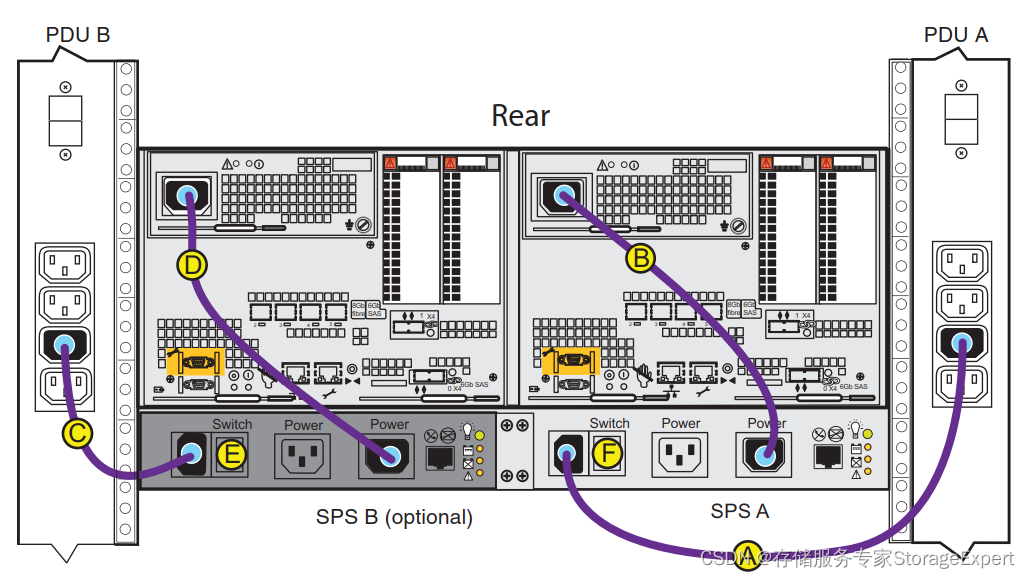
The PDU is directly connected to the SPS, which is the battery, and then comes out from the OUT of the battery to the power input of the controller.
Since there is no shutdown button on the early VNX graphical interface, the only way to shut down is to directly unplug the power. Sadly, the technicians who moved on site were ignorant and fearless engineers. Since it is called direct unplugging, then unplug it, directly unplug the four ABCD lines in the above picture at the same time, which is a sad reminder. The data in the memory is directly lost because there is no sps support. The correct shutdown and power-off sequence should be to unplug A and C first. At this time, the SPS continues to provide power protection for the two controllers, the system starts the vault, and the data in the memory is written to the back-end storage or vault area.
- The SPS or BBU battery failure did not attract attention.
Another category is that they don’t know the working principle of SPS. They always think that it doesn’t matter if the firmware is faulty, and it will not affect the normal operation of the system. Therefore, even if one SPS battery is broken, it is not necessary to replace it. Anyway, there is another SPS that is normal, and also No business problems were caused.
In some cases, if one SPS has an obvious failure, the other SPS also has an alarm but is not yet faulty. Even if the power is turned on and off in a normal order, it will cause cache loss and data loss.
- Misoperation when dealing with SP faults
This situation is also very common. Originally, the customer broke a controller, and then the service provider went to repair it for the customer. During the replacement process, some troubles were encountered, and the newly replaced controller could not start normally. In this case, it should be checked why it cannot start normally, but many engineers do not have the ability to check, so they use the 3R method (Reseat, Reboot, and Reinstall) to restart the entire machine. Due to the restart of the VNX controller It usually takes 10-15 minutes, or even longer. The on-site engineer saw that it hadn’t woken up for a long time, thought there was a problem, and then restarted sequentially. In fact, during the restart process, after going back and forth several times in this way, basically the probability of cache dirty is very high. In the end, the whole system hangs. Looking at the logs, cache loss occurs between several restarts.
Another situation is to replace a certain component in the controller, the common ones are the memory module, IO module, base module, etc. These FRU components need to be replaced after the controller is shut down. The device was pulled from normal power-on operation, then the faulty spare was replaced, and then plugged in to restart. I have encountered similar problems before, pointed out the problem to him, and said plausibly, I did this every time and nothing happened. Well, you NB. The normal workflow should be to temporarily close the write cache, then use the naviseccli command to shut down the SP, and finally complete the replacement. If the command will not be used, at least disable the write cache before doing the operation.
How to judge that the storage has encountered dirty cache instead of offline pool and LUN caused by other faults? For Unity and VNXe, both controllers are in service mode.
The easiest way is to check the event log of the sp. If you see something like "Can't Assign - Cache dirty ", it means 100% of the cache is dirty. Here's what it looks like in the spcollect log:
A 06/27/23 15:41:37 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:39 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:39 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:39 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:39 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
[ 9896 lines deleted ]
B 06/27/23 22:30:38 Bus1 Enc2 Dsk5 90a Can't Assign - Cache Dirty [ALU 3905] 0 6f00b9 f410041
B 06/27/23 22:30:38 Bus1 Enc3 Dsk3 90a Can't Assign - Cache Dirty [ALU 3924] 0 7000a6 f54004e
B 06/27/23 22:30:43 Bus1 Enc2 Dsk5 90a Can't Assign - Cache Dirty [ALU 3905] 0 6f00b9 f410041
B 06/27/23 22:30:43 Bus1 Enc3 Dsk3 90a Can't Assign - Cache Dirty [ALU 3924] 0 7000a6 f54004e
The last question is how to deal with it? This question is difficult to answer, and you can discuss it in add wechat at StorageExpert. EMC's Clarrion system is divided into many different products, and there are many version numbers, from the earliest CX R29, 30 to the VNX1 generation R31, R32, and then to the VNX2 generation R33, as well as VNXe and Unity. Depending on the OS version, the scenarios of customer cache loss are different, and the handling methods are also different. We wiped the buttocks of some customers because some engineers knew a clear cache method, thinking that all situations should be handled in this way, and the most serious thing is to completely clear the fast cache. In this way, no data can be recovered, and the general meeting can only announce that the data cannot be recovered, and all customer data is lost.
Finally, tap on the blackboard one by one. If you encounter serious problems related to data, if you don’t have a clear plan supported by logs, don’t make all kinds of unfounded attempts. This will only make things worse. It is very few.