1. Tema
Lea y comprenda el código adjunto para lograr las siguientes tareas:
Para el conjunto de datos D = {(0.1, 2.8), (1.9, 0.6), (1.0, 2.0), (3.0, 2.5), (2.0, 2.5), (1.8, 3.0), (0.1, 0.1), (0.5 , 0.5), (1.5,0.5),(1.5, 1.5), (1.7, 0.1), (2.5, 0.2)}, la etiqueta correspondiente es L = {A, A, A, B, B, B, C, C , C, D, D, D}, dibuje respectivamente la división espacial (árbol kd) compuesta por k- vecinos más cercanos cuando k = 2 y 4 , y compare la relación entre la selección de k y la precisión de la predicción.
Código adjunto:
# -*- coding: utf-8 -*-
"""
【最近邻算法】通过计算预测点与测试样例点数据的欧式距离,找出待测数据与测试数据的最小欧式距离点,
并返回该测试点的类型,从而确定预测数据类型的算法。
Created on Thu Aug 15 23:18:35 2019
@author: CUP
"""
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']#SimHei是黑体的意思
plt.rcParams['axes.unicode_minus'] = False#avoid negtive symbol
import numpy as np
#%%
def NNclassify(input,dataSet,label):
dataSize = dataSet.shape[0]
####计算欧式距离
tarry=np.tile(input,(dataSize,1));#生成dataSet一样的矩阵,进行剪发运算
diff = tarry - dataSet
sqdiff = diff ** 2 #各参数平方(X²,Y²),得到距离
squareDist = np.sum(sqdiff,axis = 1)#行向量分别相加,从而得到新的一个行向量 X²,Y²相加,
dist = list(squareDist ** 0.5) #开方,得到欧式距离
return label[dist.index(np.min(dist))] #返回最近邻 //找到距离最小值,并得与之对应的类型
#%%
###通过KNN进行分类
def KNNclassify(input,dataSet,label,k):
dataSize = dataSet.shape[0]
####计算欧式距离
diff = np.tile(input,(dataSize,1)) - dataSet
sqdiff = diff ** 2
squareDist = np.sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量
dist = squareDist ** 0.5
##对距离进行排序
sortedDistIndex = np.argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标
classCount={}
for i in range(k):
voteLabel = label[sortedDistIndex[i]]
###对选取的K个样本所属的类别个数进行统计
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
###选取出现的类别次数最多的类别
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes
#%%
dataSet = np.array([[0.1,2.8],[1.9,0.6],[1.0,2.0],
[3.0,2.5],[2.0,2.5],[1.8,3.0],
[0.1,0.1],[0.5,0.5],[1.5,0.5],
[1.5,1.5],[1.7,0.1],[2.5,0.2],
])
labels = ['A','A','A','B','B','B','C','C','C','D','D','D']
#print("input = ",input)
input = np.array([1.9,0.5])
#
plt.figure(figsize=(5,5))
for i,j in enumerate(dataSet):
if labels[i] == 'A':
plt.scatter(j[0],j[1],marker ="^",c="blue",s=80)
elif labels[i] == 'B':
plt.scatter(j[0],j[1],marker ="D",c ="green",s=80)
elif labels[i] == 'C':
plt.scatter(j[0],j[1],marker ="o",c ="darkorange",s=80)
elif labels[i] == 'D':
plt.scatter(j[0],j[1],marker ="s",c ="purple",s=80)
plt.scatter(input[0],input[1],marker ="*",c ="red",s=200)
plt.axis('tight')
plt.show()
#plt.legend()
# 最近邻
output = NNclassify(input,dataSet,labels)
print('最近邻时结果')
print("class = ",output)
# K近邻
print('K近邻,k取不同值时结果')
for K in range(1,13): #交叉验证
output = KNNclassify(input,dataSet,labels,K)
print("K = ",K,"class = ",output)
dos, la respuesta
El resultado de ejecutar el código adjunto:
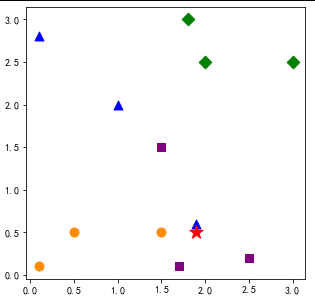
Cuando el vecino más cercano es el resultado
clase = A
K vecino, cuando k toma valores diferentes el resultado
K = 1 clase = A
K = 2 clase = A
K = 3 clase = A
K = 4 clase = D
K = 5 clase = D
K = 6 clase = D
K = 7 clase = D
K = 8 clase = C
K = 9 clase = C
K = 10 clase = C
K = 11 clase = C
K = 12 clase = A
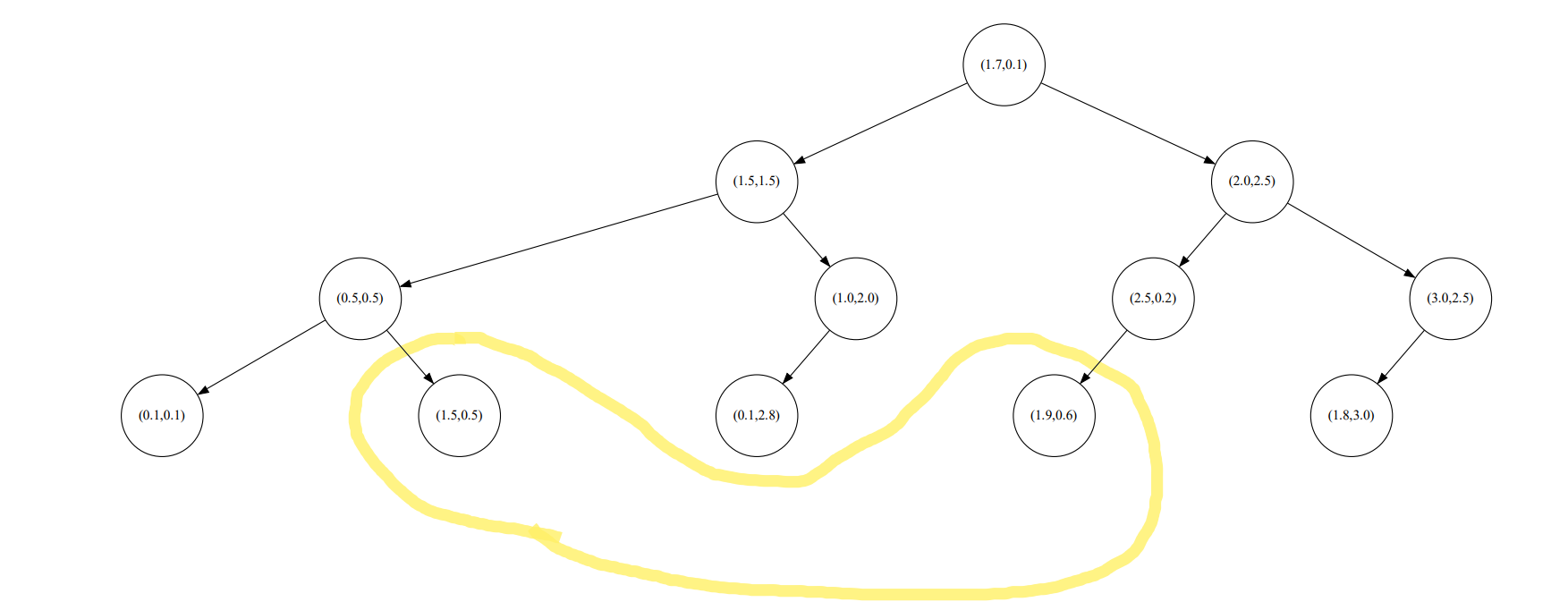
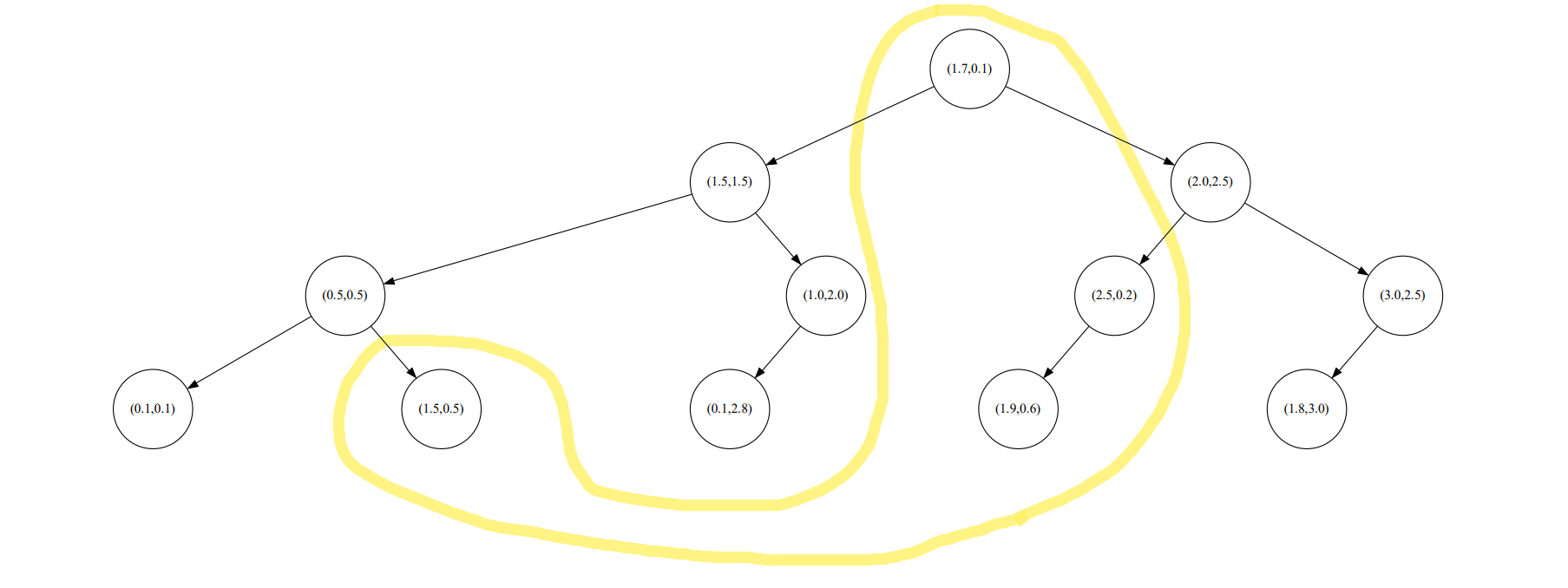
Se puede ver que cuando k=2, los puntos de entrada se dividen en A; cuando k=4, los puntos de entrada se dividen en D. A continuación, dibuje el diagrama kd y analice la relación.
El código para generar el diagrama de árbol kd:
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 2 11:32:18 2023
@author: 18705
"""
'''
画图二叉树代码
'''
import numpy as np
from graphviz import Digraph
from matplotlib import pyplot as plt
from matplotlib.pyplot import MultipleLocator
#data = [[2,3],[6, 4],[9, 6],[4, 7],[8, 1],[7, 2], [8,2], [10,4], [6,6]]
data = [[0.1,2.8],[1.9,0.6],[1.0,2.0],
[3.0,2.5],[2.0,2.5],[1.8,3.0],
[0.1,0.1],[0.5,0.5],[1.5,0.5],
[1.5,1.5],[1.7,0.1],[2.5,0.2],
]
data = np.array(data)
# 节点
class node:
def __init__(self, _data=None, _left=None, _right=None, _father=None, _dim=None, _index=None, _visiable=True):
self.data = _data
self.left = _left
self.right = _right
self.father = _father
self.dim = _dim
self.index = _index
self.visiable = _visiable
def getData(self):
s = "("
for i in range(self.data.size):
if i!=0:
s += ','
s+=str(self.data[i])
s += ")"
return s
def __str__(self):
if(self.visiable):
return str(self.index)
else:
return "_invis"+str(self.index)
dataIndex = 1
def drawKDTree(data, depth, k, dot):
# 根据数据生成KD树
dim = depth % k
length = data.shape[0]
if(length==0):
return None, dot
index = []
for i in range(length):
index.append([data[i][dim], i])
index.sort()
root = data[index[length//2][1]]
left = [data[index[i][1]] for i in range(length//2)]
left = np.array(left)
right = [data[index[i][1]] for i in range(length//2+1, length)]
right = np.array(right)
global dataIndex
root_node = node(_data=root, _dim=dim, _index=dataIndex)
dataIndex+=1
dot.node(str(root_node.index), root_node.getData())
root_node.left, dot=drawKDTree(left, depth+1, k, dot)
if(root_node.left==None):
pass
dot.node("_left"+str(root_node.index), root_node.getData(), style="invis")
dot.edge(str(root_node.index), "_left"+str(root_node.index), style="invis")
else:
dot.edge(str(root_node.index), str(root_node.left.index))
dot.node("_middle"+str(root_node.index), root_node.getData(), style="invis")
dot.edge(str(root_node.index), "_middle"+str(root_node.index), style="invis", weight="10")
root_node.right, dot=drawKDTree(right, depth+1, k, dot)
if(root_node.right==None):
pass
dot.node("_right"+str(root_node.index), root_node.getData(), style="invis")
dot.edge(str(root_node.index), "_right"+str(root_node.index), style="invis")
else:
dot.edge(str(root_node.index), str(root_node.right.index))
if(root_node.left):
root_node.left.father=root_node
if(root_node.right):
root_node.right.father=root_node
return root_node, dot
dot = Digraph(node_attr={'shape': 'circle'})
_, dot = drawKDTree(data, 0, 2, dot)
dot.view()
print(dot.source)
resultado:
División espacial de k-vecinos más cercanos cuando k=2
División espacial de k-vecinos más cercanos cuando k=4
Genere un árbol kd y analice y compare la relación entre la selección de k y la precisión de la predicción.
código:
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 2 12:50:48 2023
@author: 18705
"""
'''
kd树生成代码
'''
from scipy import spatial
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
X=np.array([[0.1,2.8],[1.9,0.6],[1.0,2.0],
[3.0,2.5],[2.0,2.5],[1.8,3.0],
[0.1,0.1],[0.5,0.5],[1.5,0.5],
[1.5,1.5],[1.7,0.1],[2.5,0.2],
])
labels = ['A','A','A','B','B','B','C','C','C','D','D','D']
testX=[[1.9,0.5]]
tree=spatial.KDTree(data=X)
dist,ind=tree.query(testX,k=2)
print("两个最近的邻居分别为")
for i in ind[0]:
print(X[i],labels[i])
print('最近的距离',dist)
print('\n')
dist1,ind1=tree.query(testX,k=4)
print("四个最近的邻居分别为")
for i in ind1[0]:
print(X[i],labels[i])
print('最近的距离',dist1)
knn2=KNeighborsClassifier(n_neighbors=2)
knn2.fit(X,labels)
score2=knn2.score(X,labels,sample_weight=None)
print('\n k=2时分类正确率:',score2)
knn4=KNeighborsClassifier(n_neighbors=4)
knn4.fit(X,labels)
score4=knn4.score(X,labels,sample_weight=None)
print('\n k=2时分类正确率:',score4)
xx=[i for i in range(1,10)]
all_score=[]
plt.figure()
for i in range(1,10):
knn=KNeighborsClassifier(n_neighbors=i)
knn.fit(X,labels)
score=knn.score(X,labels,sample_weight=None)
all_score.append(score)
plt.plot(i, score, color="#FF3B1D", marker='*')
plt.text(i+0.01, score+0.02,str(round(score, 2)))
plt.plot(xx,all_score,linestyle="-")
plt.title("K-预测准确率")
plt.xlabel("K")
plt.ylabel("预测准确率")
plt.show()resultado :
Cuando k=2, los dos vecinos más cercanos son:
[1.9 0.6] A
[1.5 0.5] C
La distancia más cercana [[0.1 0.4]]
Cuando k=4, los cuatro vecinos más cercanos son:
[1.9 0.6] A
[1.5 0.5] C
[1,7 0,1] D
[2,5 0,2]
La distancia más cercana de D [[0,1 0,4 0,4472136 0,67082039]]
Cuando k=2, la tasa de precisión de clasificación: 0,6666666666666666 Cuando
k=2, la tasa de precisión de clasificación: 0,8333333333333334
Puede obtener el mismo resultado que el código proporcionado por el profesor. Debido a que 0.6666<0.83333, al mismo tiempo, se puede concluir que cuanto mayor es k, mayor es la precisión de la predicción. ¿Pero es realmente el caso? Simplemente comparar la selección de dos k no puede obtener resultados extensos, por lo que volví a seleccionar k = 1:10, y los resultados de k y la precisión se muestran en la figura:
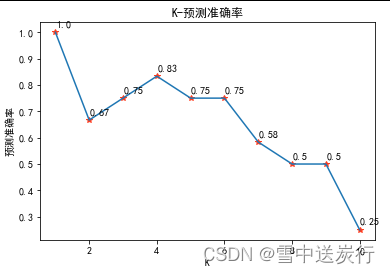
Se puede ver que los resultados del vecino más cercano no se consideran. A medida que aumenta k, la tasa de precisión aumenta primero y luego disminuye.