Detección de conteo de sentadillas/dominadas
prefacio
1. ¿Qué es mediapipe?
MediaPipe es un marco para crear canalizaciones de aprendizaje automático para procesar datos de series temporales, como video y audio. Este marco multiplataforma funciona en escritorio/servidor, Android, iOS y dispositivos integrados como Raspberry Pi y Jetson Nano. Mediapipe es compatible con muchas funciones de IA de uso común. Aquí hay algunos ejemplos de uso común:
Detección de rostros FaceMesh: reconstruya la
malla 3D del rostro humano a partir de la imagen/video, que se puede usar para renderizado AR Seguimiento de gestos: se pueden marcar las coordenadas 3D de 21 puntos clave Estimación de la pose del cuerpo humano: se pueden marcar las coordenadas 3D de 33 puntos clave se le dará coloración del cabello: el cabello se puede detectar y colorear en el mapa
Este artículo explicará el uso de la clasificación de posturas en mediapipe para lograr la detección del conteo de sentadillas/dominadas
2. ¿Qué es BlazePose?
Una de las aplicaciones que BlazePose puede habilitar es fitness. Más específicamente: clasificación de poses y conteo de repeticiones. En esta sección, brindaremos una guía básica sobre cómo crear un clasificador de poses personalizado con la ayuda de Colabs, envolviéndolo en una simple demostración de actividad física en la aplicación ML Kit Quickstart. Las flexiones y las sentadillas se utilizan con fines de demostración como los ejercicios más comunes.
3. Algoritmo KNN
El algoritmo de adyacencia, o el algoritmo de clasificación K-Nearest Neighbor (kNN, k-NearestNeighbor) es uno de los métodos de clasificación más simples en la minería de datos. Llamados K-vecinos más cercanos, significa los vecinos más cercanos del vecino más cercano k, lo que significa que cada muestra puede ser representada por sus vecinos más cercanos a k. El algoritmo K-Nearest Neighbor Algorithm (KNN) es simple y eficiente. Tiene una amplia gama de aplicaciones en clasificación, regresión, reconocimiento de patrones, etc.
4. Entorno de software
Este proyecto se desarrolla en el entorno de desarrollo de notebook jupyter y se ejecuta en una PC python3.7 con una cámara en el sistema operativo win10. La versión de mediapipe es 0.8.10,
expliqué la configuración del entorno en mi blog anterior. haga clic para entrar
5. Documentos de referencia
https://google.github.io/mediapipe/solutions/pose_classification.html
1. Implementación del código
from matplotlib import pyplot as plt
import os
def show_image(img, figsize=(10, 10)):
"""Shows output PIL image."""
plt.figure(figsize=figsize)
plt.imshow(img)
plt.show()
#人体姿态编码
class FullBodyPoseEmbedder(object):
"""Converts 3D pose landmarks into 3D embedding."""
def __init__(self, torso_size_multiplier=2.5):
# Multiplier to apply to the torso to get minimal body size.
self._torso_size_multiplier = torso_size_multiplier
# Names of the landmarks as they appear in the prediction.
self._landmark_names = [
'nose',
'left_eye_inner', 'left_eye', 'left_eye_outer',
'right_eye_inner', 'right_eye', 'right_eye_outer',
'left_ear', 'right_ear',
'mouth_left', 'mouth_right',
'left_shoulder', 'right_shoulder',
'left_elbow', 'right_elbow',
'left_wrist', 'right_wrist',
'left_pinky_1', 'right_pinky_1',
'left_index_1', 'right_index_1',
'left_thumb_2', 'right_thumb_2',
'left_hip', 'right_hip',
'left_knee', 'right_knee',
'left_ankle', 'right_ankle',
'left_heel', 'right_heel',
'left_foot_index', 'right_foot_index',
]
def __call__(self, landmarks):
"""Normalizes pose landmarks and converts to embedding
Args:
landmarks - NumPy array with 3D landmarks of shape (N, 3).
Result:
Numpy array with pose embedding of shape (M, 3) where `M` is the number of
pairwise distances defined in `_get_pose_distance_embedding`.
"""
assert landmarks.shape[0] == len(self._landmark_names), 'Unexpected number of landmarks: {}'.format(
landmarks.shape[0])
# Get pose landmarks.
landmarks = np.copy(landmarks)
# Normalize landmarks.
landmarks = self._normalize_pose_landmarks(landmarks)
# Get embedding.
embedding = self._get_pose_distance_embedding(landmarks)
return embedding
def _normalize_pose_landmarks(self, landmarks):
"""Normalizes landmarks translation and scale."""
landmarks = np.copy(landmarks)
# Normalize translation.
pose_center = self._get_pose_center(landmarks)
landmarks -= pose_center
# Normalize scale.
pose_size = self._get_pose_size(landmarks, self._torso_size_multiplier)
landmarks /= pose_size
# Multiplication by 100 is not required, but makes it eaasier to debug.
landmarks *= 100
return landmarks
def _get_pose_center(self, landmarks):
"""Calculates pose center as point between hips."""
left_hip = landmarks[self._landmark_names.index('left_hip')]
right_hip = landmarks[self._landmark_names.index('right_hip')]
center = (left_hip + right_hip) * 0.5
return center
def _get_pose_size(self, landmarks, torso_size_multiplier):
"""Calculates pose size.
It is the maximum of two values:
* Torso size multiplied by `torso_size_multiplier`
* Maximum distance from pose center to any pose landmark
"""
# This approach uses only 2D landmarks to compute pose size.
landmarks = landmarks[:, :2]
# Hips center.
left_hip = landmarks[self._landmark_names.index('left_hip')]
right_hip = landmarks[self._landmark_names.index('right_hip')]
hips = (left_hip + right_hip) * 0.5
# Shoulders center.
left_shoulder = landmarks[self._landmark_names.index('left_shoulder')]
right_shoulder = landmarks[self._landmark_names.index('right_shoulder')]
shoulders = (left_shoulder + right_shoulder) * 0.5
# Torso size as the minimum body size.
torso_size = np.linalg.norm(shoulders - hips)
# Max dist to pose center.
pose_center = self._get_pose_center(landmarks)
max_dist = np.max(np.linalg.norm(landmarks - pose_center, axis=1))
return max(torso_size * torso_size_multiplier, max_dist)
def _get_pose_distance_embedding(self, landmarks):
"""Converts pose landmarks into 3D embedding.
We use several pairwise 3D distances to form pose embedding. All distances
include X and Y components with sign. We differnt types of pairs to cover
different pose classes. Feel free to remove some or add new.
Args:
landmarks - NumPy array with 3D landmarks of shape (N, 3).
Result:
Numpy array with pose embedding of shape (M, 3) where `M` is the number of
pairwise distances.
"""
embedding = np.array([
# One joint.
self._get_distance(
self._get_average_by_names(landmarks, 'left_hip', 'right_hip'),
self._get_average_by_names(landmarks, 'left_shoulder', 'right_shoulder')),
self._get_distance_by_names(landmarks, 'left_shoulder', 'left_elbow'),
self._get_distance_by_names(landmarks, 'right_shoulder', 'right_elbow'),
self._get_distance_by_names(landmarks, 'left_elbow', 'left_wrist'),
self._get_distance_by_names(landmarks, 'right_elbow', 'right_wrist'),
self._get_distance_by_names(landmarks, 'left_hip', 'left_knee'),
self._get_distance_by_names(landmarks, 'right_hip', 'right_knee'),
self._get_distance_by_names(landmarks, 'left_knee', 'left_ankle'),
self._get_distance_by_names(landmarks, 'right_knee', 'right_ankle'),
# Two joints.
self._get_distance_by_names(landmarks, 'left_shoulder', 'left_wrist'),
self._get_distance_by_names(landmarks, 'right_shoulder', 'right_wrist'),
self._get_distance_by_names(landmarks, 'left_hip', 'left_ankle'),
self._get_distance_by_names(landmarks, 'right_hip', 'right_ankle'),
# Four joints.
self._get_distance_by_names(landmarks, 'left_hip', 'left_wrist'),
self._get_distance_by_names(landmarks, 'right_hip', 'right_wrist'),
# Five joints.
self._get_distance_by_names(landmarks, 'left_shoulder', 'left_ankle'),
self._get_distance_by_names(landmarks, 'right_shoulder', 'right_ankle'),
self._get_distance_by_names(landmarks, 'left_hip', 'left_wrist'),
self._get_distance_by_names(landmarks, 'right_hip', 'right_wrist'),
# Cross body.
self._get_distance_by_names(landmarks, 'left_elbow', 'right_elbow'),
self._get_distance_by_names(landmarks, 'left_knee', 'right_knee'),
self._get_distance_by_names(landmarks, 'left_wrist', 'right_wrist'),
self._get_distance_by_names(landmarks, 'left_ankle', 'right_ankle'),
# Body bent direction.
# self._get_distance(
# self._get_average_by_names(landmarks, 'left_wrist', 'left_ankle'),
# landmarks[self._landmark_names.index('left_hip')]),
# self._get_distance(
# self._get_average_by_names(landmarks, 'right_wrist', 'right_ankle'),
# landmarks[self._landmark_names.index('right_hip')]),
])
return embedding
def _get_average_by_names(self, landmarks, name_from, name_to):
lmk_from = landmarks[self._landmark_names.index(name_from)]
lmk_to = landmarks[self._landmark_names.index(name_to)]
return (lmk_from + lmk_to) * 0.5
def _get_distance_by_names(self, landmarks, name_from, name_to):
lmk_from = landmarks[self._landmark_names.index(name_from)]
lmk_to = landmarks[self._landmark_names.index(name_to)]
return self._get_distance(lmk_from, lmk_to)
def _get_distance(self, lmk_from, lmk_to):
return lmk_to - lmk_from
Clasificación de la pose humana
class PoseSample(object):
def __init__(self, name, landmarks, class_name, embedding):
self.name = name
self.landmarks = landmarks
self.class_name = class_name
self.embedding = embedding
class PoseSampleOutlier(object):
def __init__(self, sample, detected_class, all_classes):
self.sample = sample
self.detected_class = detected_class
self.all_classes = all_classes
import csv
import numpy as np
import os
class PoseClassifier(object):
"""Classifies pose landmarks."""
def __init__(self,
pose_samples_folder,
pose_embedder,
file_extension='csv',
file_separator=',',
n_landmarks=33,
n_dimensions=3,
top_n_by_max_distance=30,
top_n_by_mean_distance=10,
axes_weights=(1., 1., 0.2)):
self._pose_embedder = pose_embedder
self._n_landmarks = n_landmarks
self._n_dimensions = n_dimensions
self._top_n_by_max_distance = top_n_by_max_distance
self._top_n_by_mean_distance = top_n_by_mean_distance
self._axes_weights = axes_weights
self._pose_samples = self._load_pose_samples(pose_samples_folder,
file_extension,
file_separator,
n_landmarks,
n_dimensions,
pose_embedder)
def _load_pose_samples(self,
pose_samples_folder,
file_extension,
file_separator,
n_landmarks,
n_dimensions,
pose_embedder):
"""Loads pose samples from a given folder.
Required folder structure:
neutral_standing.csv
pushups_down.csv
pushups_up.csv
squats_down.csv
...
Required CSV structure:
sample_00001,x1,y1,z1,x2,y2,z2,....
sample_00002,x1,y1,z1,x2,y2,z2,....
...
"""
# Each file in the folder represents one pose class.
file_names = [name for name in os.listdir(pose_samples_folder) if name.endswith(file_extension)]
pose_samples = []
for file_name in file_names:
# Use file name as pose class name.
class_name = file_name[:-(len(file_extension) + 1)]
# Parse CSV.
with open(os.path.join(pose_samples_folder, file_name)) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=file_separator)
for row in csv_reader:
assert len(row) == n_landmarks * n_dimensions + 1, 'Wrong number of values: {}'.format(len(row))
landmarks = np.array(row[1:], np.float32).reshape([n_landmarks, n_dimensions])
pose_samples.append(PoseSample(
name=row[0],
landmarks=landmarks,
class_name=class_name,
embedding=pose_embedder(landmarks),
))
return pose_samples
def find_pose_sample_outliers(self):
"""Classifies each sample against the entire database."""
# Find outliers in target poses
outliers = []
for sample in self._pose_samples:
# Find nearest poses for the target one.
pose_landmarks = sample.landmarks.copy()
pose_classification = self.__call__(pose_landmarks)
class_names = [class_name for class_name, count in pose_classification.items() if count == max(pose_classification.values())]
# Sample is an outlier if nearest poses have different class or more than
# one pose class is detected as nearest.
if sample.class_name not in class_names or len(class_names) != 1:
outliers.append(PoseSampleOutlier(sample,class_names, pose_classification))
return outliers
def __call__(self, pose_landmarks):
"""Classifies given pose.
Classification is done in two stages:
* First we pick top-N samples by MAX distance. It allows to remove samples
that are almost the same as given pose, but has few joints bent in the
other direction.
* Then we pick top-N samples by MEAN distance. After outliers are removed
on a previous step, we can pick samples that are closes on average.
Args:
pose_landmarks: NumPy array with 3D landmarks of shape (N, 3).
Returns:
Dictionary with count of nearest pose samples from the database. Sample:
{
'pushups_down': 8,
'pushups_up': 2,
}
"""
# Check that provided and target poses have the same shape.
assert pose_landmarks.shape == (self._n_landmarks, self._n_dimensions), 'Unexpected shape: {}'.format(pose_landmarks.shape)
# Get given pose embedding.
pose_embedding = self._pose_embedder(pose_landmarks)
flipped_pose_embedding = self._pose_embedder(pose_landmarks * np.array([-1, 1, 1]))
# Filter by max distance.
#
# That helps to remove outliers - poses that are almost the same as the
# given one, but has one joint bent into another direction and actually
# represnt a different pose class.
max_dist_heap = []
for sample_idx, sample in enumerate(self._pose_samples):
max_dist = min(
np.max(np.abs(sample.embedding - pose_embedding) * self._axes_weights),
np.max(np.abs(sample.embedding - flipped_pose_embedding) * self._axes_weights),
)
max_dist_heap.append([max_dist, sample_idx])
max_dist_heap = sorted(max_dist_heap, key=lambda x: x[0])
max_dist_heap = max_dist_heap[:self._top_n_by_max_distance]
# Filter by mean distance.
#
# After removing outliers we can find the nearest pose by mean distance.
mean_dist_heap = []
for _, sample_idx in max_dist_heap:
sample = self._pose_samples[sample_idx]
mean_dist = min(
np.mean(np.abs(sample.embedding - pose_embedding) * self._axes_weights),
np.mean(np.abs(sample.embedding - flipped_pose_embedding) * self._axes_weights),
)
mean_dist_heap.append([mean_dist, sample_idx])
mean_dist_heap = sorted(mean_dist_heap, key=lambda x: x[0])
mean_dist_heap = mean_dist_heap[:self._top_n_by_mean_distance]
# Collect results into map: (class_name -> n_samples)
class_names = [self._pose_samples[sample_idx].class_name for _, sample_idx in mean_dist_heap]
result = {
class_name: class_names.count(class_name) for class_name in set(class_names)}
return result
Los resultados de la clasificación de poses son fluidos
#指数移动平均,使图像平滑
class EMADictSmoothing(object):
"""Smoothes pose classification."""
def __init__(self, window_size=10, alpha=0.2):
self._window_size = window_size
self._alpha = alpha
self._data_in_window = []
def __call__(self, data):
"""Smoothes given pose classification.
Smoothing is done by computing Exponential Moving Average for every pose
class observed in the given time window. Missed pose classes arre replaced
with 0.
Args:
data: Dictionary with pose classification. Sample:
{
'pushups_down': 8,
'pushups_up': 2,
}
Result:
Dictionary in the same format but with smoothed and float instead of
integer values. Sample:
{
'pushups_down': 8.3,
'pushups_up': 1.7,
}
"""
# Add new data to the beginning of the window for simpler code.
self._data_in_window.insert(0, data)
self._data_in_window = self._data_in_window[:self._window_size]
# Get all keys.
keys = set([key for data in self._data_in_window for key, _ in data.items()])
# Get smoothed values.
smoothed_data = dict()
for key in keys:
factor = 1.0
top_sum = 0.0
bottom_sum = 0.0
for data in self._data_in_window:
value = data[key] if key in data else 0.0
top_sum += factor * value
bottom_sum += factor
# Update factor.
factor *= (1.0 - self._alpha)
smoothed_data[key] = top_sum / bottom_sum
return smoothed_data
Contador de acciones, puede modificar los umbrales superior e inferior en enter_threshold=6, exit_threshold=4 definidos a continuación
class RepetitionCounter(object):
"""Counts number of repetitions of given target pose class."""
def __init__(self, class_name, enter_threshold=6, exit_threshold=4):
self._class_name = class_name
# If pose counter passes given threshold, then we enter the pose.
self._enter_threshold = enter_threshold
self._exit_threshold = exit_threshold
# Either we are in given pose or not.
self._pose_entered = False
# Number of times we exited the pose.
self._n_repeats = 0
@property
def n_repeats(self):
return self._n_repeats
def __call__(self, pose_classification):
"""Counts number of repetitions happend until given frame.
We use two thresholds. First you need to go above the higher one to enter
the pose, and then you need to go below the lower one to exit it. Difference
between the thresholds makes it stable to prediction jittering (which will
cause wrong counts in case of having only one threshold).
Args:
pose_classification: Pose classification dictionary on current frame.
Sample:
{
'pushups_down': 8.3,
'pushups_up': 1.7,
}
Returns:
Integer counter of repetitions.
"""
# Get pose confidence.
pose_confidence = 0.0
if self._class_name in pose_classification:
pose_confidence = pose_classification[self._class_name]
# On the very first frame or if we were out of the pose, just check if we
# entered it on this frame and update the state.
if not self._pose_entered:
self._pose_entered = pose_confidence > self._enter_threshold
return self._n_repeats
# If we were in the pose and are exiting it, then increase the counter and
# update the state.
if pose_confidence < self._exit_threshold:
self._n_repeats += 1
self._pose_entered = False
return self._n_repeats
módulo de visualización
import io
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
import requests
class PoseClassificationVisualizer(object):
"""Keeps track of claassifcations for every frame and renders them."""
def __init__(self,
class_name,
plot_location_x=0.05,
plot_location_y=0.05,
plot_max_width=0.4,
plot_max_height=0.4,
plot_figsize=(9, 4),
plot_x_max=None,
plot_y_max=None,
counter_location_x=0.85,
counter_location_y=0.05,
counter_font_path='https://github.com/googlefonts/roboto/blob/main/src/hinted/Roboto-Regular.ttf?raw=true',
counter_font_color='red',
counter_font_size=0.15):
self._class_name = class_name
self._plot_location_x = plot_location_x
self._plot_location_y = plot_location_y
self._plot_max_width = plot_max_width
self._plot_max_height = plot_max_height
self._plot_figsize = plot_figsize
self._plot_x_max = plot_x_max
self._plot_y_max = plot_y_max
self._counter_location_x = counter_location_x
self._counter_location_y = counter_location_y
self._counter_font_path = counter_font_path
self._counter_font_color = counter_font_color
self._counter_font_size = counter_font_size
self._counter_font = None
self._pose_classification_history = []
self._pose_classification_filtered_history = []
def __call__(self,
frame,
pose_classification,
pose_classification_filtered,
repetitions_count):
"""Renders pose classifcation and counter until given frame."""
# Extend classification history.
self._pose_classification_history.append(pose_classification)
self._pose_classification_filtered_history.append(pose_classification_filtered)
# Output frame with classification plot and counter.
output_img = Image.fromarray(frame)
output_width = output_img.size[0]
output_height = output_img.size[1]
# Draw the plot.
img = self._plot_classification_history(output_width, output_height)
img.thumbnail((int(output_width * self._plot_max_width),
int(output_height * self._plot_max_height)),
Image.ANTIALIAS)
output_img.paste(img,
(int(output_width * self._plot_location_x),
int(output_height * self._plot_location_y)))
# Draw the count.
output_img_draw = ImageDraw.Draw(output_img)
if self._counter_font is None:
font_size = int(output_height * self._counter_font_size)
font_request = requests.get(self._counter_font_path, allow_redirects=True)
self._counter_font = ImageFont.truetype(io.BytesIO(font_request.content), size=font_size)
output_img_draw.text((output_width * self._counter_location_x,
output_height * self._counter_location_y),
str(repetitions_count),
font=self._counter_font,
fill=self._counter_font_color)
return output_img
def _plot_classification_history(self, output_width, output_height):
fig = plt.figure(figsize=self._plot_figsize)
for classification_history in [self._pose_classification_history,
self._pose_classification_filtered_history]:
y = []
for classification in classification_history:
if classification is None:
y.append(None)
elif self._class_name in classification:
y.append(classification[self._class_name])
else:
y.append(0)
plt.plot(y, linewidth=7)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Frame')
plt.ylabel('Confidence')
plt.title('Classification history for `{}`'.format(self._class_name))
#plt.legend(loc='upper right')
if self._plot_y_max is not None:
plt.ylim(top=self._plot_y_max)
if self._plot_x_max is not None:
plt.xlim(right=self._plot_x_max)
# Convert plot to image.
buf = io.BytesIO()
dpi = min(
output_width * self._plot_max_width / float(self._plot_figsize[0]),
output_height * self._plot_max_height / float(self._plot_figsize[1]))
fig.savefig(buf, dpi=dpi)
buf.seek(0)
img = Image.open(buf)
plt.close()
return img
Extraiga las coordenadas del punto clave del conjunto de entrenamiento. En el documento de Google mediapipe, con open(csv_out_path, 'w') como csv_out_file: habrá problemas en el tiempo de ejecución. Consulte el método de otro blogger. Cambie todo con open(csv_out_path
) , 'w', newline='') como csv_out_file:
Se ha modificado el siguiente código
import cv2
from matplotlib import pyplot as plt
import numpy as np
import os
from PIL import Image
import sys
import tqdm
from mediapipe.python.solutions import drawing_utils as mp_drawing
from mediapipe.python.solutions import pose as mp_pose
class BootstrapHelper(object):
"""Helps to bootstrap images and filter pose samples for classification."""
def __init__(self,
images_in_folder,
images_out_folder,
csvs_out_folder):
self._images_in_folder = images_in_folder
self._images_out_folder = images_out_folder
self._csvs_out_folder = csvs_out_folder
# Get list of pose classes and print image statistics.
self._pose_class_names = sorted([n for n in os.listdir(self._images_in_folder) if not n.startswith('.')])
def bootstrap(self, per_pose_class_limit=None):
"""Bootstraps images in a given folder.
Required image in folder (same use for image out folder):
pushups_up/
image_001.jpg
image_002.jpg
...
pushups_down/
image_001.jpg
image_002.jpg
...
...
Produced CSVs out folder:
pushups_up.csv
pushups_down.csv
Produced CSV structure with pose 3D landmarks:
sample_00001,x1,y1,z1,x2,y2,z2,....
sample_00002,x1,y1,z1,x2,y2,z2,....
"""
# Create output folder for CVSs.
if not os.path.exists(self._csvs_out_folder):
os.makedirs(self._csvs_out_folder)
for pose_class_name in self._pose_class_names:
print('Bootstrapping ', pose_class_name, file=sys.stderr)
# Paths for the pose class.
images_in_folder = os.path.join(self._images_in_folder, pose_class_name)
images_out_folder = os.path.join(self._images_out_folder, pose_class_name)
csv_out_path = os.path.join(self._csvs_out_folder, pose_class_name + '.csv')
if not os.path.exists(images_out_folder):
os.makedirs(images_out_folder)
with open(csv_out_path, 'w', newline='') as csv_out_file:
csv_out_writer = csv.writer(csv_out_file, delimiter=',', quoting=csv.QUOTE_MINIMAL)
# Get list of images.
image_names = sorted([n for n in os.listdir(images_in_folder) if not n.startswith('.')])
if per_pose_class_limit is not None:
image_names = image_names[:per_pose_class_limit]
# Bootstrap every image.
for image_name in tqdm.tqdm(image_names):
# Load image.
input_frame = cv2.imread(os.path.join(images_in_folder, image_name))
input_frame = cv2.cvtColor(input_frame, cv2.COLOR_BGR2RGB)
# Initialize fresh pose tracker and run it.
with mp_pose.Pose() as pose_tracker:
result = pose_tracker.process(image=input_frame)
pose_landmarks = result.pose_landmarks
# Save image with pose prediction (if pose was detected).
output_frame = input_frame.copy()
if pose_landmarks is not None:
mp_drawing.draw_landmarks(
image=output_frame,
landmark_list=pose_landmarks,
connections=mp_pose.POSE_CONNECTIONS)
output_frame = cv2.cvtColor(output_frame, cv2.COLOR_RGB2BGR)
cv2.imwrite(os.path.join(images_out_folder, image_name), output_frame)
# Save landmarks if pose was detected.
if pose_landmarks is not None:
# Get landmarks.
frame_height, frame_width = output_frame.shape[0], output_frame.shape[1]
pose_landmarks = np.array(
[[lmk.x * frame_width, lmk.y * frame_height, lmk.z * frame_width]
for lmk in pose_landmarks.landmark],
dtype=np.float32)
assert pose_landmarks.shape == (33, 3), 'Unexpected landmarks shape: {}'.format(pose_landmarks.shape)
csv_out_writer.writerow([image_name] + pose_landmarks.flatten().astype(np.str).tolist())
# Draw XZ projection and concatenate with the image.
projection_xz = self._draw_xz_projection(
output_frame=output_frame, pose_landmarks=pose_landmarks)
output_frame = np.concatenate((output_frame, projection_xz), axis=1)
def _draw_xz_projection(self, output_frame, pose_landmarks, r=0.5, color='red'):
frame_height, frame_width = output_frame.shape[0], output_frame.shape[1]
img = Image.new('RGB', (frame_width, frame_height), color='white')
if pose_landmarks is None:
return np.asarray(img)
# Scale radius according to the image width.
r *= frame_width * 0.01
draw = ImageDraw.Draw(img)
for idx_1, idx_2 in mp_pose.POSE_CONNECTIONS:
# Flip Z and move hips center to the center of the image.
x1, y1, z1 = pose_landmarks[idx_1] * [1, 1, -1] + [0, 0, frame_height * 0.5]
x2, y2, z2 = pose_landmarks[idx_2] * [1, 1, -1] + [0, 0, frame_height * 0.5]
draw.ellipse([x1 - r, z1 - r, x1 + r, z1 + r], fill=color)
draw.ellipse([x2 - r, z2 - r, x2 + r, z2 + r], fill=color)
draw.line([x1, z1, x2, z2], width=int(r), fill=color)
return np.asarray(img)
def align_images_and_csvs(self, print_removed_items=False):
"""Makes sure that image folders and CSVs have the same sample.
Leaves only intersetion of samples in both image folders and CSVs.
"""
for pose_class_name in self._pose_class_names:
# Paths for the pose class.
images_out_folder = os.path.join(self._images_out_folder, pose_class_name)
csv_out_path = os.path.join(self._csvs_out_folder, pose_class_name + '.csv')
# Read CSV into memory.
rows = []
with open(csv_out_path, newline='') as csv_out_file:
csv_out_reader = csv.reader(csv_out_file, delimiter=',')
for row in csv_out_reader:
rows.append(row)
# Image names left in CSV.
image_names_in_csv = []
# Re-write the CSV removing lines without corresponding images.
with open(csv_out_path, 'w', newline='') as csv_out_file:
csv_out_writer = csv.writer(csv_out_file, delimiter=',', quoting=csv.QUOTE_MINIMAL)
for row in rows:
image_name = row[0]
image_path = os.path.join(images_out_folder, image_name)
if os.path.exists(image_path):
image_names_in_csv.append(image_name)
csv_out_writer.writerow(row)
elif print_removed_items:
print('Removed image from CSV: ', image_path)
# Remove images without corresponding line in CSV.
for image_name in os.listdir(images_out_folder):
if image_name not in image_names_in_csv:
image_path = os.path.join(images_out_folder, image_name)
os.remove(image_path)
if print_removed_items:
print('Removed image from folder: ', image_path)
def analyze_outliers(self, outliers):
"""Classifies each sample agains all other to find outliers.
If sample is classified differrrently than the original class - it sould
either be deleted or more similar samples should be aadded.
"""
for outlier in outliers:
image_path = os.path.join(self._images_out_folder, outlier.sample.class_name, outlier.sample.name)
print('Outlier')
print(' sample path = ', image_path)
print(' sample class = ', outlier.sample.class_name)
print(' detected class = ', outlier.detected_class)
print(' all classes = ', outlier.all_classes)
img = cv2.imread(image_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
show_image(img, figsize=(20, 20))
def remove_outliers(self, outliers):
"""Removes outliers from the image folders."""
for outlier in outliers:
image_path = os.path.join(self._images_out_folder, outlier.sample.class_name, outlier.sample.name)
os.remove(image_path)
def print_images_in_statistics(self):
"""Prints statistics from the input image folder."""
self._print_images_statistics(self._images_in_folder, self._pose_class_names)
def print_images_out_statistics(self):
"""Prints statistics from the output image folder."""
self._print_images_statistics(self._images_out_folder, self._pose_class_names)
def _print_images_statistics(self, images_folder, pose_class_names):
print('Number of images per pose class:')
for pose_class_name in pose_class_names:
n_images = len([
n for n in os.listdir(os.path.join(images_folder, pose_class_name))
if not n.startswith('.')])
print(' {}: {}'.format(pose_class_name, n_images))
Cargue el conjunto de datos y la imagen debe repetir el estado terminal para la clase de pose deseada.
1. Si desea clasificar las flexiones, proporcione las dimensiones para dos categorías: cuando la persona está arriba y cuando la persona está abajo.
En segundo lugar, cada clase debe tener alrededor de decenas o cientos de muestras que cubran diferentes ángulos de cámara, condiciones ambientales, formas corporales y cambios de movimiento para construir un buen clasificador.
El formato del conjunto de datos se muestra en la figura.

2. Posibles problemas
1. Problema de fuente
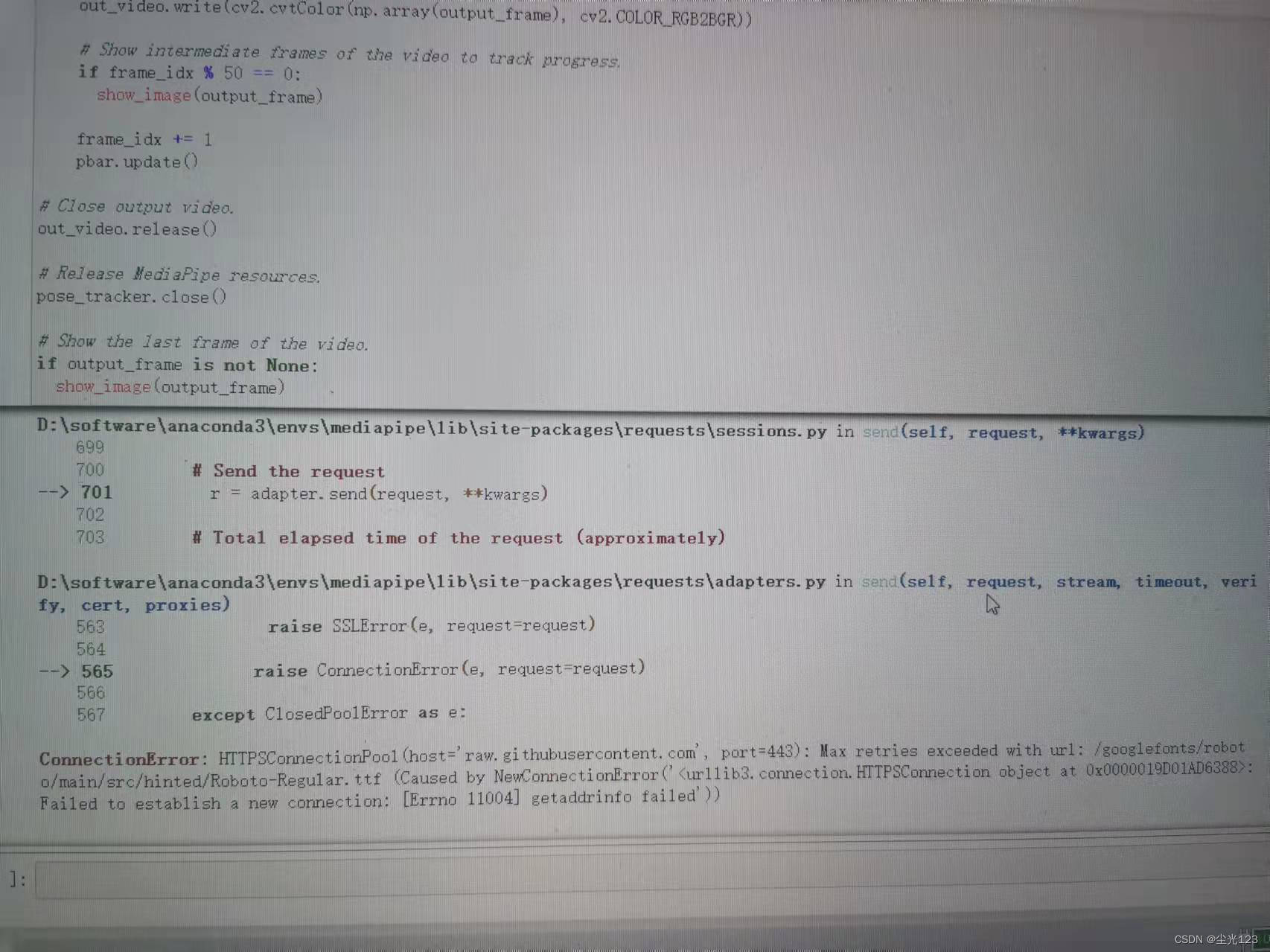
En el módulo de visualización, la fuente se descarga desde 'https://github.com/googlefonts/roboto/blob/main/src/hinted/Roboto-Regular.ttf?raw=true', pero el acceso doméstico generalmente se agota. puede llamar a la fuente local en su lugar.
Dos, upper_body_only=Falso
upper_body_only: el valor predeterminado es falso, ya sea para detectar solo los puntos de referencia de la parte superior del cuerpo. Hay un total de 33 puntos de referencia para poses humanas y 25 para poses de la parte superior del cuerpo. En el documento provisto por Google, es mp_pose.Pose(upper_body_only=False). Puede haber problemas durante el tiempo de ejecución. Simplemente elimine upper_body_only=False entre paréntesis y cámbielo a mp_pose.Pose(). El código en el texto ha sido modificado.
Ejemplo, plt.legend(loc='arriba a la derecha')

El plt.legend(loc='upper right') en el módulo de visualización informará un error, simplemente coméntelo y el código en el texto se ha comentado.
Cuatro, problema class_name
Al especificar la ruta de video, class_name debe ser consistente con el nombre correspondiente en el conjunto de datos, como class_name='pushups_down'
4. El efecto final
El efecto final se muestra en la siguiente figura. Este proyecto puede detectar flexiones, sentadillas y dominadas.

V. Resumen
El blog de mediapipe anterior explicaba las diversas detecciones de cuerpo humano de mediapipe. Esta vez, el blog ha realizado la detección de conteo de pull-up/squat. El código oficial completo está en https://mediapipe.page.link/pose_classification_extended. Es mejor para verlo mirar.