Prefacio:
En la comunidad de lectores (50+) del arquitecto Nien, de 40 años, muchos amigos no pueden recibir ofertas o no pueden recibir buenas ofertas .
Nien a menudo optimiza proyectos, optimiza currículos y extrae aspectos técnicos destacados para todos . En el proceso de guiar los currículos, la solución de problemas en línea y el ajuste de Java son una guía muy importante.
El problema es que muchos socios pequeños ni siquiera tienen un poco de experiencia en ajustes básicos y resolución de problemas en línea. Por supuesto, ni siquiera entienden escenarios de alta concurrencia. Ayer, en la comunidad de arquitectos de Nien, algunos amigos encontraron problemas en línea:
El paquete jar de springboot, el servicio está ahí, pero la solicitud no responde. Comprobado con arthas, la memoria y la CPU son normales, pero el conjunto de subprocesos de tomcat está lleno, ¿qué debo hacer?
Animación suspendida SpringBoot, ¿qué debo hacer?
Para los arquitectos y desarrolladores avanzados, el ajuste y la solución de problemas en línea son el contenido central y son la fuerza interna de la fuerza interna.
Combinando la experiencia arquitectónica senior y los casos de la industria, el equipo de Nien resolvió una serie de libros electrónicos en PDF de la " Biblia de sintonización de Java " , que incluye cinco partes planificadas para este artículo:
(1) Biblia de sintonización 1: competencia basada en cero en la medición de presión distribuida de Jmeter, práctica de medición de presión de más de 10 Wqps (completada)
(2) Tuning Bible 2: de 70 s a 20 ms, una práctica de optimización del rendimiento de 3500 veces, la solución está disponible para todos (completado)
(3) Tuning Bible 3: ¿Cómo hacer el ajuste mysql? 7 trucos mortales para ajustar SQL lento 100 veces, darse cuenta de su libertad de ajuste de Mysql (completado)
(4) Tuning Bible 4: animación suspendida SpringBoot, ¿cómo apagar el fuego ? (Este artículo)
(5) Tuning Bible 5: competencia basada en cero en las operaciones de ajuste de JVM para lograr la libertad de JVM (escritura)
(6) Tuning Bible 6: Competencia basada en cero en las operaciones de ajuste de Linux y Tomcat para lograr la libertad de ajuste de la infraestructura (por escrito)
Los artículos anteriores se publicarán en la cuenta oficial del círculo libre de tecnología en sucesión. El PDF completo "Java Tuning Bible" está disponible en Nien.
Directorio de artículos
-
- Prefacio:
- Animación suspendida SpringBoot online, un fenómeno de urgencia
- Las 10 posibles causas de la animación suspendida
- Método de análisis de cinco ejes de Nien
-
- El primer truco: comprobar el registro
- El segundo truco: comprobar los recursos del sistema
- El tercer hacha: verifique el punto muerto del subproceso JVM
- El cuarto truco: comprobar la pila de JVM
-
- Desbordamiento de memoria y pérdida de memoria:
- Solución de problemas de posibles causas de desbordamiento de memoria
- Cuatro escenarios de desbordamiento de memoria
- Solución de problemas de desbordamiento de memoria y fugas de memoria
- Tipo 1: fugas de memoria ligeras y análisis en línea de objetos grandes:
- Tipo 2: fugas de memoria pesadas y análisis en línea de objetos grandes:
- El quinto truco: comprobar la configuración del sistema operativo
- Caso en línea 1: OOM provoca animación suspendida
- Caso en línea 2: número insuficiente de subprocesos del sistema operativo conduce a animación suspendida
- Caso en línea 3: velocidad de procesamiento de solicitud lenta, lo que da como resultado una animación suspendida
- Caso en línea 4: la salida de registro a la consola conduce a una animación suspendida
- Caso en línea 5: animación suspendida en línea CLOSE_WAIT del lado del servidor
- Solución de animación suspendida del servicio en línea SpringBoot, la memoria de la CPU es normal
- Detección de animación suspendida SpringBoot y autorreparación
- Algunos consejos maduros finales
- referencias:
- Planificación de la iteración de la Biblia de afinación de Java
- El camino de realización de la libertad técnica PDF:
-
-
- Realice su libertad arquitectónica:
- Realice su libertad de respuesta:
- Realice su libertad de nube de primavera:
- Realice su libertad de Linux:
- Realice su libertad en línea:
- Realice su libertad de bloqueo distribuido:
- Realice su libertad componente rey:
- Realice las preguntas de su entrevista libremente:
-
Animación suspendida SpringBoot online, un fenómeno de urgencia
La aplicación SpringBoot será inaccesible. Hay 3 puntos de rendimiento específicos:
- Desempeño 1. No hay respuesta a la solicitud del cliente;
- Rendimiento 2. Al solicitar, no hay salida de registro;
- Rendimiento 3. El proceso SpringBoot está vivo
Desempeño 1. No hay respuesta a la solicitud del cliente;
Si hay una solicitud de front-end, se mostrará como pendiente.
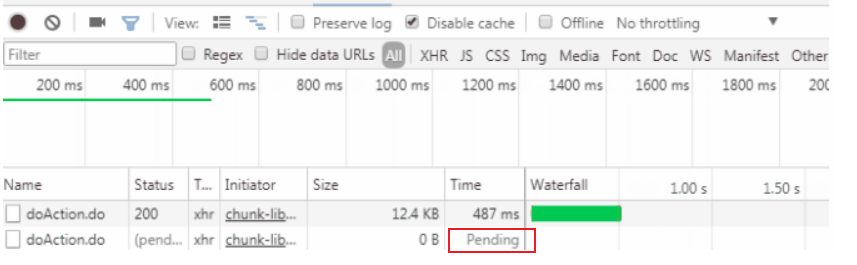
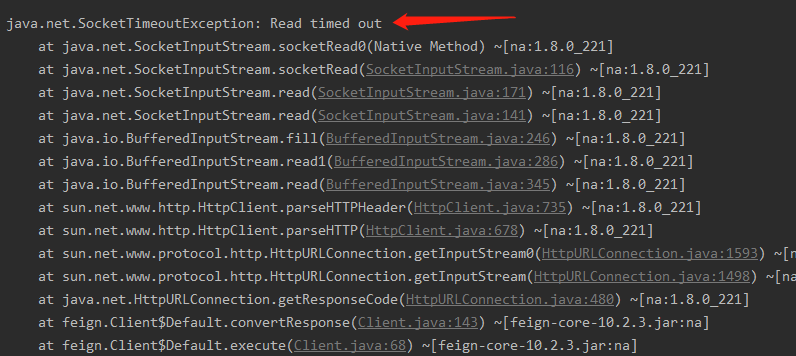
Si se trata de una llamada de cliente RPC, el rendimiento es que se agotó el tiempo de conexión
Rendimiento 2. Al solicitar, no hay salida de registro,
al verificar el registro comercial, se encuentra que el registro se ha detenido y no hay un registro de acceso más reciente.
Rendimiento 3. El proceso SpringBoot está vivo
Verifique el proceso a través de jps o ps, puede ver que el proceso de servicio existe;
Sentencia de animación suspendida:
Si existen las tres manifestaciones anteriores, básicamente se puede determinar que el proceso SpringBoot es una animación suspendida.
Las 10 posibles causas de la animación suspendida
- El subproceso java está interbloqueado o todos los subprocesos están bloqueados;
- La conexión en el grupo de conexiones de la base de datos está agotada, lo que genera una espera permanente al obtener la conexión de la base de datos;
- Hay una fuga de memoria que conduce a OutOfMemory, y el espacio de memoria insuficiente conduce a una falla continua en la asignación de espacio de memoria; la memoria disponible del servidor es suficiente, pero la memoria asignada a jvm está agotada, lo que es propenso a esta situación;
- El paquete jar se reemplazó durante la ejecución del programa de servicio, pero el servicio no se reinició.Este es un problema causado por no seguir las reglas;
- El espacio en disco está lleno, lo que hace que todos los lugares que necesitan escribir datos fallen;
el cliente recibe 500 y se agota el tiempo de conexión - El grupo de subprocesos está lleno y no se pueden asignar más subprocesos para procesar solicitudes, generalmente porque una gran cantidad de subprocesos están bloqueados en una determinada solicitud; la
conexión del cliente se agotó
Método de análisis de cinco ejes de Nien
Hay muchas situaciones que hacen que SpringBoot no pueda continuar con el procesamiento comercial, por lo que debe verificarse de muchas maneras.
- El primer truco: comprobar el registro
- El segundo truco: comprobar los recursos del sistema
- El tercer truco: verifique el interbloqueo del subproceso JVM
- El cuarto truco: comprobar la pila de JVM
- El quinto truco: comprobar la configuración del sistema operativo
El primer truco: comprobar el registro
Primero, verifique el estado de ejecución del servicio para determinar la razón superficial por la que no se puede manejar el negocio, ya sea la animación suspendida de SpringBoot o una excepción comercial.
Verifique el registro del proyecto para verificar si hay una situación de error obvia y trate con la situación de error.
- Verifique el registro de registro local
- O el registro distribuido de elk
Mensaje de error, muy importante. Generalmente, el 70% de los problemas pueden ser analizados.
Si hay varios nodos en servicio, el estado de un nodo se puede reservar para el análisis y la búsqueda de la causa de la falla, y los otros nodos pueden restaurar el servicio normal tan pronto como sea posible reiniciando el servicio;
El segundo truco: comprobar los recursos del sistema
Verifique la red, el disco, la CPU, etc. de la máquina donde se encuentra el servicio uno por uno.
Primero verifique los recursos de la CPU
paso 1: Averigüe los antecedentes familiares de los recursos de la CPU (¿cuántos núcleos de CPU hay?)
- Número de cpus físicas : el número de cpus realmente insertadas en la placa base, cuántas identificaciones físicas se pueden contar sin repetición (identificación física)
- Número de núcleos de CPU : el número de conjuntos de chips que pueden procesar datos en una sola CPU, como dual-core, quad-core, etc. (núcleos de CPU)
- Número lógico de CPU : en términos simples, permite que 1 núcleo en el procesador funcione en el sistema operativo como 2 núcleos.
De esta manera, los recursos de ejecución disponibles para el sistema operativo se duplican y el rendimiento general del sistema mejora considerablemente.En este momento, CPU lógica = número de CPU físicas x número de núcleos por núcleo x2.
La cantidad total de núcleos = la cantidad de CPU físicas × la cantidad de núcleos de cada CPU física.
La cantidad total de CPU lógicas = la cantidad de CPU físicas × la cantidad de núcleos de cada CPU física × la cantidad de hiperprocesos.
Así que es de doble núcleo.
# 查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
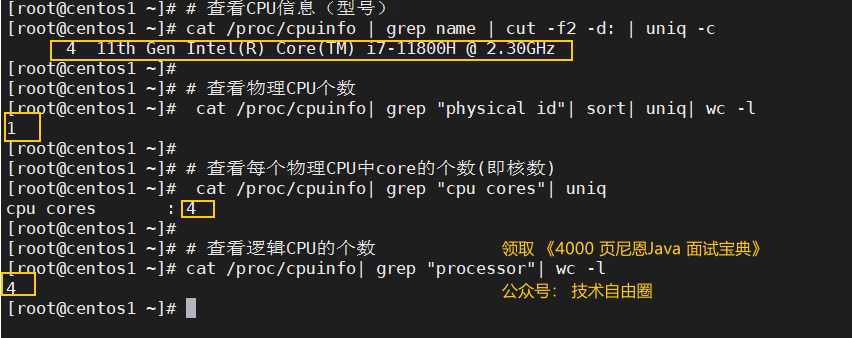
Hay una fórmula anterior: número total de CPU lógicas = número de CPU físicas x número de núcleos por CPU física x número de hiperprocesos.
Hay otro indicador para esto: el número de hiperprocesos. Luego verifique si centos7 está hiperproceso.
cat /proc/cpuinfo | grep -e "cpu cores" -e "siblings" | sort | uniq

Calcular si el hyperthreading está habilitado
- CPU lógica > CPU física x número de núcleos de CPU (con hyperthreading habilitado)
- CPU lógica = CPU física x número de núcleos de CPU (hyperthreading no está habilitado o no es compatible con hyperthreading)
- Si la cantidad de núcleos de CPU es la misma que la cantidad de hermanos, el hiperproceso no está habilitado; de lo contrario, el hiperproceso está habilitado.
A juzgar por los resultados de la ejecución anterior, la máquina virtual de Nin no tiene habilitado el hyperthreading.
La CPU utilizada por la máquina virtual de Nien tiene 1 * 4 = 4 núcleos, y cada núcleo tiene 1 hiperproceso, por lo que hay 4 núcleos de CPU lógicos.
paso 2: compruebe el uso de todos los núcleos de la CPU
Ver todo el uso de la CPU.
mpstat -P ALL 1
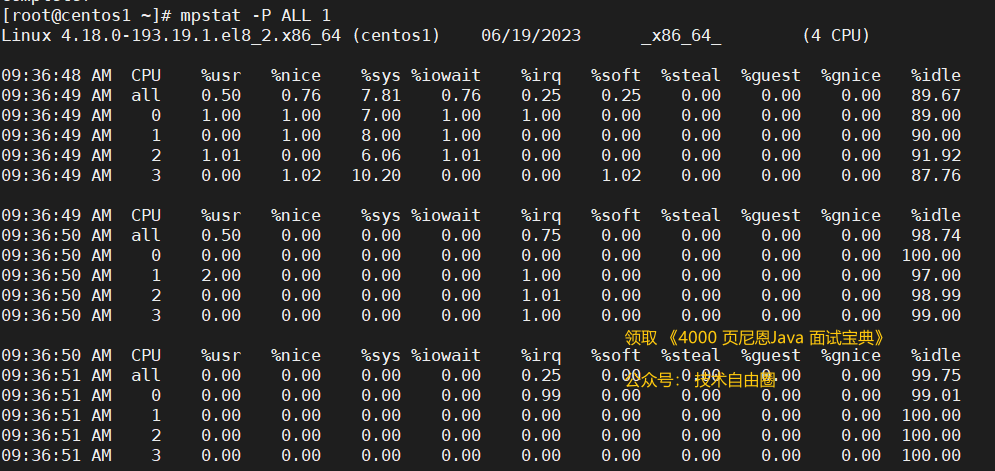
%dileEs la proporción de CPU inactiva%iowait%Washington%iowait%Representa el porcentaje de tiempo de CPU en espera de E/S
Incluso si la CPU no está llena.
Si la CPU está muy llena, verifique el uso de la CPU del proceso
Comprobar el uso de la CPU del proceso
topComando para ver el uso de CPU del proceso
top
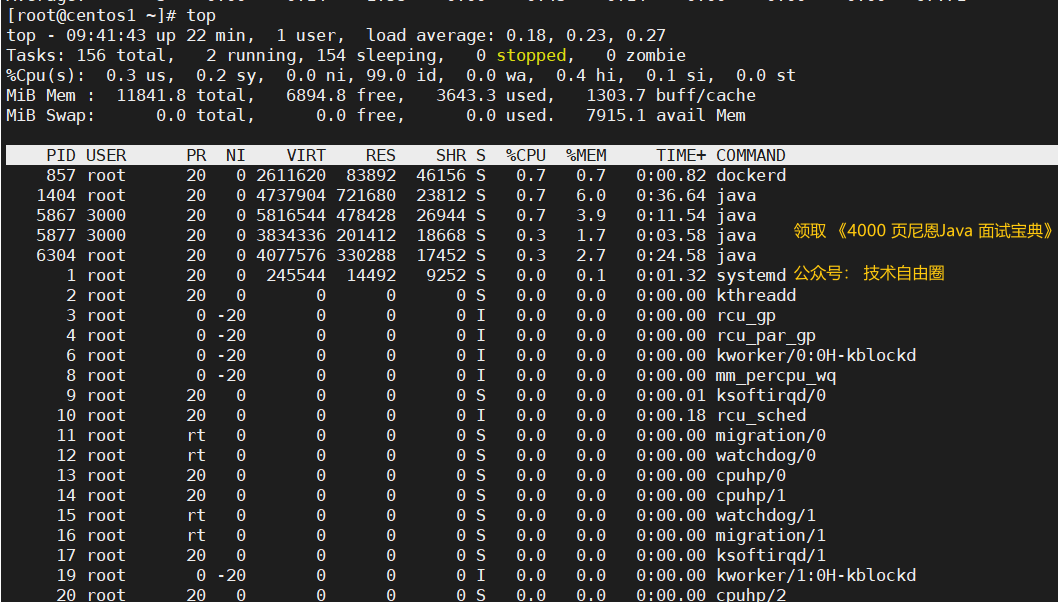
ps aux|sort -nr -k3|head -10Comando para ver el uso de CPU del proceso
ps aux|sort -nr -k3|head -10

Es fácil encontrar procesos que consumen mucha CPU. Luego analice más.
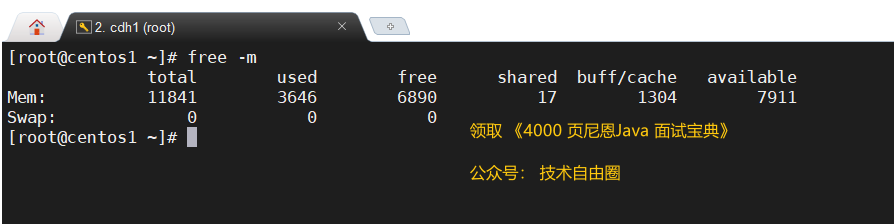
Luego, verifique los recursos de memoria
free -mMire el uso total de la memoria . Determine si la memoria está llena.
Muestra la información de la memoria, en megabytes, la información de salida es la siguiente:
$free -m
topComando, también verifique el uso de memoria a nivel de proceso
top
paso 3: comprobar IO
Determine si el IO está lleno.
comando iostat para verificar IO
iostat puede proporcionarnos abundantes datos de estado de IO
parámetros del comando iostat
iostat [选项] [<时间间隔>] [<次数>]
-c: 显示CPU使用情况
-d: 显示磁盘使用情况
-N: 显示磁盘阵列(LVM) 信息
-n: 显示NFS 使用情况
-k: 以 KB 为单位显示
-m: 以 M 为单位显示
-t: 报告每秒向终端读取和写入的字符数和CPU的信息
-V: 显示版本信息
-x: 显示详细信息
-p:[磁盘] 显示磁盘和分区的情况
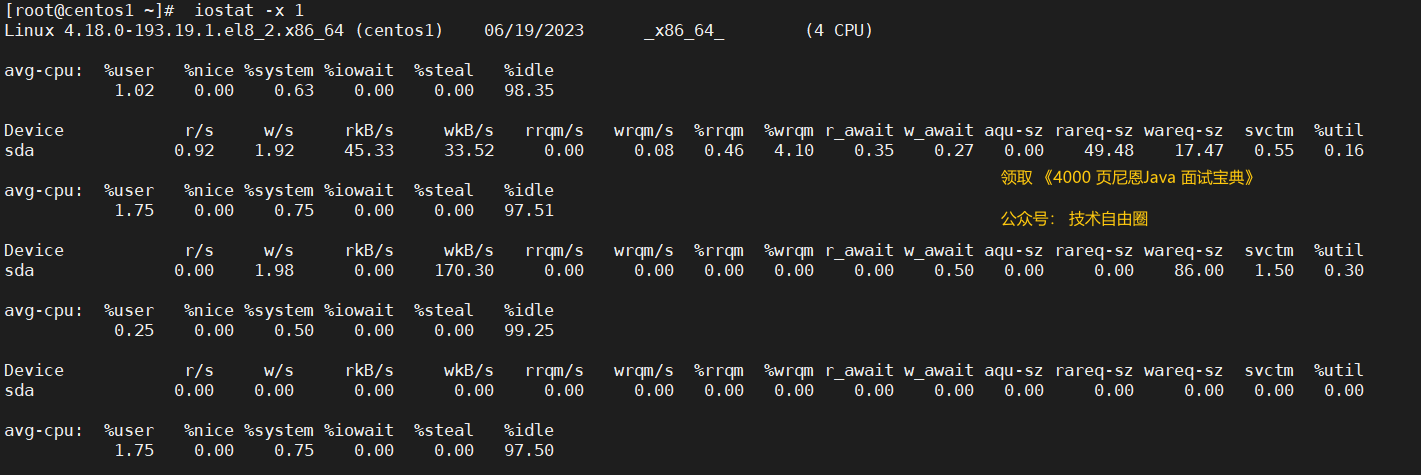
Estadísticas de uso de la CPU: uso del proceso del usuario, uso del sistema, tasa de inactividad, etc., y la suma de los siguientes indicadores es 1
%user: El porcentaje de tiempo que la CPU está en modo de usuario.%nice: El porcentaje de tiempo que la CPU está en modo usuario con un valor NICE.%system: El porcentaje de tiempo que la CPU está en modo sistema.%iowait: El porcentaje de tiempo que la CPU espera a que se complete la entrada y la salida. Si el valor de %iowait es demasiado alto, significa que hay un cuello de botella de E/S en el disco duro.%steal: Porcentaje de tiempo de espera no intencional para una CPU virtual mientras el hipervisor mantiene otro procesador virtual.%idle: porcentaje de tiempo de inactividad de la CPU. Un valor de %inactivo alto significa que la CPU está relativamente inactiva. Si el valor de %inactivo es alto pero el sistema responde lentamente, es posible que la CPU esté esperando para asignar memoria. En este momento, se debe aumentar la capacidad de la memoria. Si el valor de %idle es continuamente inferior a 10, entonces la capacidad de procesamiento de la CPU del sistema es relativamente baja, lo que indica que el recurso que más necesita ser resuelto en el sistema es la CPU.
Estadísticas de E/S del dispositivo de bloque: la cantidad de datos leídos y escritos por segundo, la cantidad total de datos leídos y escritos, etc.
Indicadores de lectura:
r/s: El número de dispositivos de E/S de lectura completados por segundo. Es decir, rio/s, lo que puede explicar muchas E/S aleatorias.rkB/s: Leer K bytes por segundo. Es la mitad de rsect/s porque cada sector tiene un tamaño de 512 bytes.rrqm/s: el número de operaciones de lectura combinadas por segundo. es decir, fusionar/s%rrqm: el porcentaje de solicitudes de lectura que se fusionaron antes de enviarse al dispositivo.r_await: El tiempo promedio requerido para cada operación de lectura. Concéntrese en él. Para HDD, si es superior a 20 ms, puede haber demasiadas solicitudes, lo que resultará en una cola, ya que una búsqueda normal es de solo 10 ms.rareq-sz: El tamaño promedio de las solicitudes de lectura enviadas al dispositivo (en k)
Escribir índice:
w/s: El número de dispositivos de E/S de escritura completados por segundo. es decir, wio/swkB/s: El número de K bytes escritos por segundo. Es la mitad de wsect/s.wrqm/s: el número de operaciones de combinación de escritura por segundo. es decir, wmerge/s%wrqm: el porcentaje de solicitudes de escritura que se fusionaron antes de enviarse al dispositivo.w_await: El tiempo promedio (en milisegundos) de cada solicitud de escritura. Esto incluye el tiempo que las solicitudes pasaron en la cola y el tiempo que tomó ejecutarlas. Es importante tener en cuenta que para HDD, si es superior a 20 ms, puede haber demasiadas solicitudes, lo que genera colas, porque una búsqueda normal es de solo 10 ms.wareq-sz: El tamaño promedio de las solicitudes de escritura enviadas al dispositivo (en k).
Indicadores de caída:
d/s: el número de solicitudes de descarte completadas por el dispositivo por segundo (después de la fusión).dkB/s: El número de kB descartados del dispositivo por segundodrqm/s: el número de solicitudes de descarte de fusión en cola en el dispositivo por segundo%drqm: el porcentaje de solicitudes de descarte que se fusionaron antes de enviarse al dispositivo.d_await: tiempo promedio en milisegundos para emitir una solicitud de descarte para un dispositivo que se va a reparar. Esto incluye el tiempo dedicado a las solicitudes en la cola y el tiempo dedicado a atender las solicitudes.dareq-sz: tamaño medio (en kilobytes) de las solicitudes de descarte enviadas al dispositivo.
Otros indicadores:
aqu-sz: La longitud promedio de la cola de solicitudes realizadas al dispositivo. Nota: En versiones anteriores, este campo se llamaba avgqu-sz. Este indicador es alto y debe prestarse atención. Puede haber demasiados IO y debe esperar.%util: ¿Qué porcentaje del tiempo en un segundo se usa para operaciones de E/S, es decir, el porcentaje de CPU consumido por io y el porcentaje de tiempo transcurrido para enviar solicitudes de E/S al dispositivo (la tasa de utilización de ancho de banda del dispositivo). La saturación de dispositivos ocurre cuando este valor se acerca al 100 % de los dispositivos que atienden solicitudes en serie. Pero para dispositivos que procesan solicitudes en paralelo, como arreglos RAID y SSD modernos, este número no refleja sus limitaciones de rendimiento. Un indicador alto indica que IO es básicamente el cuello de botella, pero un indicador bajo no significa necesariamente que IO no sea el cuello de botella. Generalmente, si el %util es superior al 70%, la presión de E/S será relativamente alta.
Al mismo tiempo, puede combinar vmstat para ver el parámetro b (la cantidad de procesos que esperan recursos) y el parámetro wa (el porcentaje de tiempo de CPU ocupado por la espera de E/S y la presión de E/S es alta cuando es superior al 30%)
E/S de disco de proceso de consulta iotop
iotopes una herramienta superior que muestra la actividad del disco en tiempo real.
iotopSupervisa la salida de información de uso de E/S del kernel de Linux y muestra el uso de E/S actual de un proceso o subproceso en el sistema.
iotopes una herramienta similar topque muestra la actividad del disco en tiempo real.
iotopSupervisa la salida de información de uso de E/S del kernel de Linux y muestra el uso de E/S actual de un proceso o subproceso en el sistema.
Muestra el ancho de banda de E/S de lectura y escritura por proceso/subproceso. También muestra el porcentaje de tiempo que pasan los subprocesos/procesos esperando el intercambio y esperando la E/S.
Total DISK READLos valores de y Total DISK WRITErepresentan el ancho de banda total de lectura y escritura entre los procesos y los subprocesos del kernel, por un lado, y el subsistema del dispositivo de bloqueo del kernel, por el otro.
Actual DISK READLos valores de y Actual DISK WRITErepresentan el ancho de banda de E/S del disco real correspondiente al subsistema del dispositivo de bloque del kernel y el hardware subyacente (HDD, SSD, etc.).
iotopUso de parámetros de comando
-o, --only只显示正在产生I/O的进程或线程。除了传参,可以在运行过程中按o生效。
-b, --batch非交互模式,一般用来记录日志。
-n NUM, --iter=NUM设置监测的次数,默认无限。在非交互模式下很有用。
-d SEC, --delay=SEC设置每次监测的间隔,默认1秒,接受非整形数据例如1.1。
-p PID, --pid=PID指定监测的进程/线程。
-u USER, --user=USER指定监测某个用户产生的I/O。
-P, --processes仅显示进程,默认iotop显示所有线程。
-a, --accumulated显示累积的I/O,而不是带宽。
-k, --kilobytes使用kB单位,而不是对人友好的单位。在非交互模式下,脚本编程有用。
-t, --time 加上时间戳,非交互非模式。
-q, --quiet 禁止头几行,非交互模式。有三种指定方式。
-q 只在第一次监测时显示列名
-qq 永远不显示列名。
-qqq 永远不显示I/O汇总。
Teclas interactivas, similar al comando superior, iotop también admite las siguientes teclas interactivas.
left和right方向键:改变排序。
r:反向排序。
o:切换至选项--only。
p:切换至--processes选项。
a:切换至--accumulated选项。
q:退出。
i:改变线程的优先级。
Ejemplo de comando:
#时间刷新间隔2秒,输出5次
iotop -d 2 -n 5
#非交互式,输出pid为 1404 的进程信息,这里示例1404 为nginx进程
iotop -botq -p 1404
Puede ver la tasa de lectura del disco y la tasa de escritura

Ver el estado de E/S de cada disco.
kB_read/s: La cantidad de datos leídos del dispositivo (unidad expresada) por segundo;kB_wrtn/s: la cantidad de datos escritos en el dispositivo (unidad expresada) por segundo;kB_read: la cantidad total de datos leídos;kB_wrtn: La cantidad total de datos escritos; estas unidades son Kilobytes.
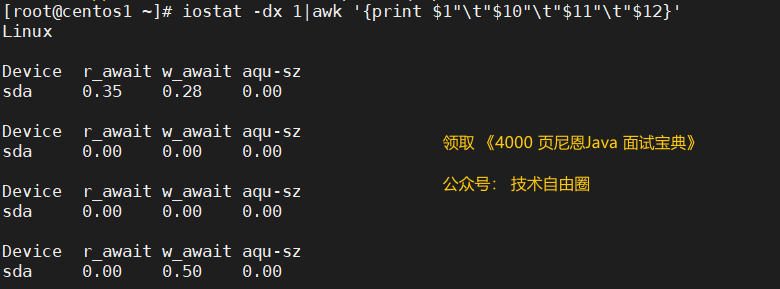
Consulte la espera y la utilidad de cada disco.
iostat -dx 1|awk '{print $1"\t"$10"\t"$11"\t"$12}'
paso 4: Comprobar la red
El uso de la red también es una métrica importante para monitorear.
Cuando el ancho de banda es insuficiente, el tiempo de respuesta de la solicitud aumentará considerablemente.
Para evitar la presión de simultaneidad repentina, debe asegurarse de que el uso de ancho de banda del servidor esté por encima del 80 %.
Cabe señalar aquí que la tarjeta de red física limita el ancho de banda máximo que puede utilizar el servidor.
Use nload para ver la red
Primero necesita instalar nload, tome centos como ejemplo
yum install nload -y
Una vez completada la instalación, ejecutamos directamentenload
nload

Después de ingresar nloadel comando, el uso de la red se muestra en la figura anterior.
En el que, el uso de la red se divide en datos que fluyen hacia la tarjeta de red y datos que fluyen hacia afuera de la tarjeta de red.
- Entrante La velocidad de red correspondiente al ancho de banda descendente de la tarjeta de red entrante,
- Saliente Los datos que salen de la tarjeta de red corresponden a la velocidad de red del ancho de banda ascendente.
Si la "velocidad actual de la red" está cerca de la "velocidad máxima de la red", significa que el uso del ancho de banda está cerca del 100%.
Descripción del indicador:
- Actual: velocidad actual de Internet
- Promedio: velocidad promedio de Internet
- Min: velocidad mínima de internet
- Max: velocidad máxima de la red
- TTL: tráfico total
Use iftop para ver la red
Si aún no está satisfecho, puede usar iftop
Use el comando iftop, use yum install iftop -y en el sistema CentOS para instalar
La interfaz del comando iftop es la siguiente:
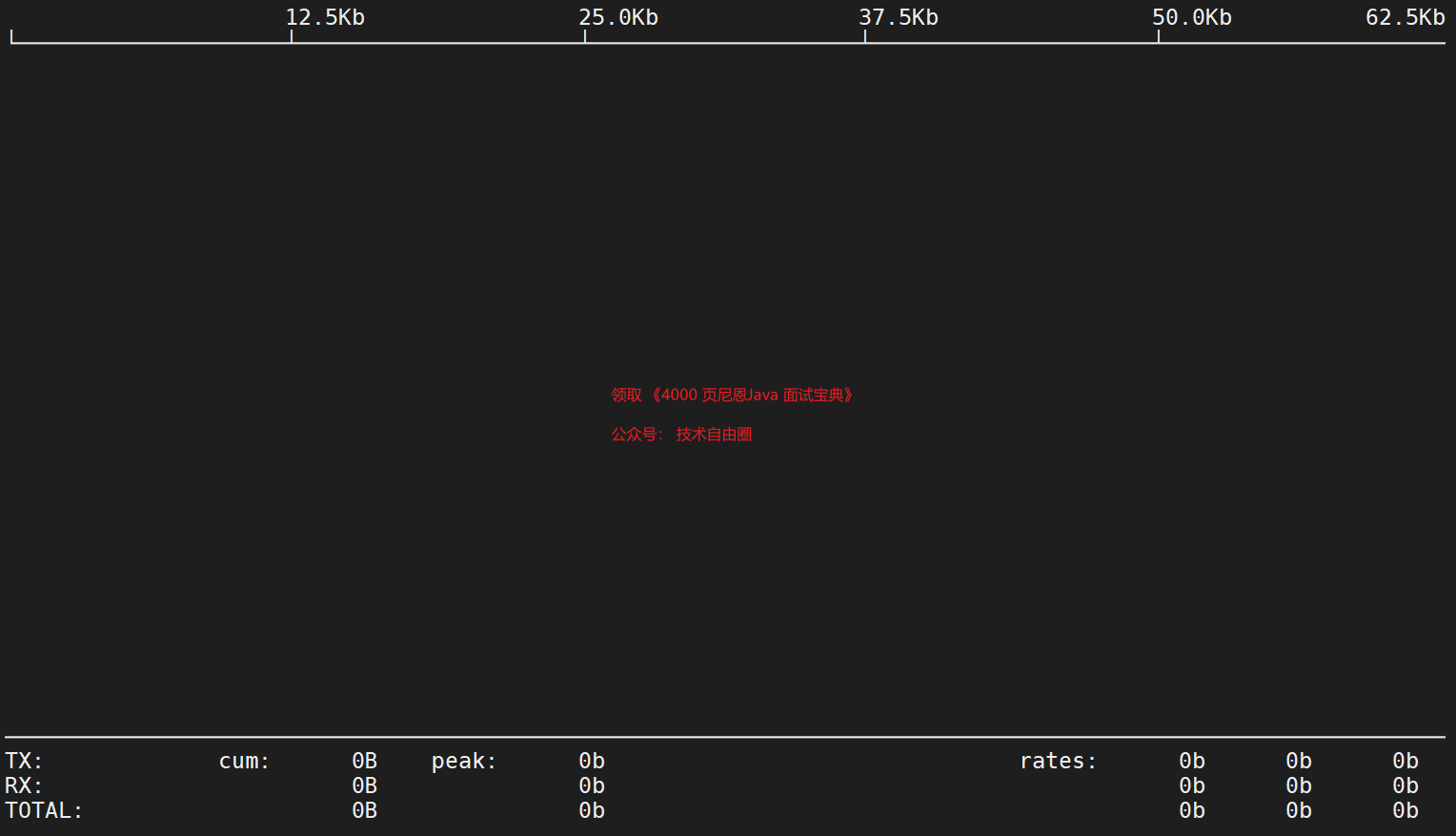
iftop -P(Puede mostrar dinámicamente todas las conexiones con tráfico, incluido el análisis de puertos)
-i: especifica la tarjeta de red que se va a monitorear
-n: muestra la información del host de salida a través de IP, sin análisis inverso de DNS
-B: salida en bytes Muestra el tráfico de la tarjeta de red, el valor predeterminado es bits
-p: ejecuta iftop en modo promiscuo, en este momento iftop se puede usar como rastreador de red
-N: solo muestra el número de puerto de conexión, no muestra el nombre del servicio correspondiente al puerto
-P: muestra host y información del puerto, este parámetro es muy útil
-F: muestra el tráfico entrante y saliente de la tarjeta de red de un segmento de red específico
-m: establece el valor máximo de la escala de flujo superior en la interfaz de salida iftop, y se muestra la escala de flujo en cinco grandes segmentos
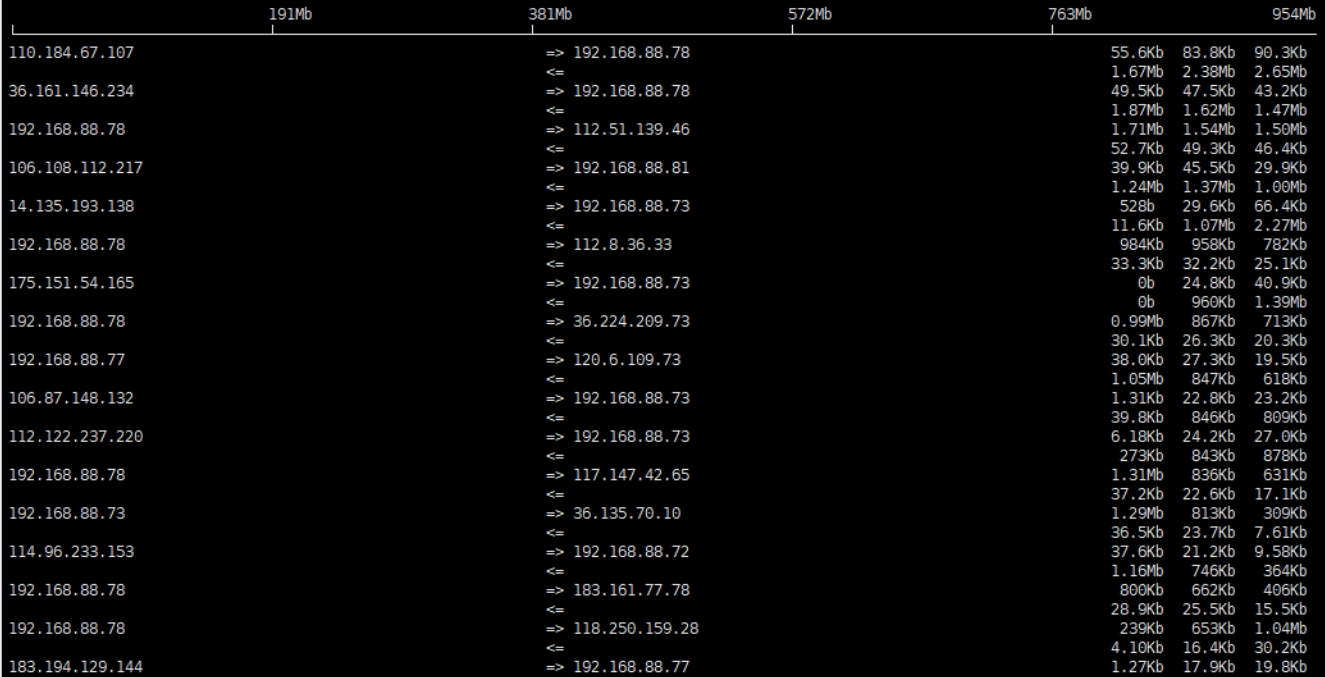
El rango de escala similar a una escala se muestra en la interfaz, que se utiliza como escala para la barra larga que muestra el gráfico de flujo.
#"TX":从网卡发出的流量
#"RX":网卡接收流量
#"TOTAL":网卡发送接收总流量
#"cum":iftop开始运行到当前时间点的总流量
#"peak":网卡流量峰值
#"rates":分别表示最近2s、10s、40s 的平均流量
Parámetros interactivos de iftop:
参数 含义
P 暂停/继续 (Display unpaused/paused )
h 帮助/显示(help / Display)
b 平均流量刻度条开关 (Bars on/off)
B 2s、10s、40s内的平均流量 (Bars show 2s/10s/40s average)
T 显示/隐藏每个连接的总流量( show / hide cumulative totals)
j/k 上移/下滚(通vi hjkl 左上下右)
l 过滤 (screen filter > IP、主机名或端口支持模糊查询 ctrl+删除键回退)
L 对数尺度、计算尺; 直线标度、线性标尺 (logarithmic scale && linear scale)==加个进度条比例不同
q 退出(quit)
n DNS解析开关(DNS resolution off/on)主要看hosts 文件有无
s/d 显示源/目的主机信息 show/hide source/dest host
S/D 显示源/目的端口信息 port display dest/source或on
t 仅显示接收流量。received traffic only , 仅显示发送流量 sent traffic only,接收发送同时显示 two line per host 接收发送合并显示 one line per host
N 端口号及对应服务名称切换,只识别通用端口修改后不显示服务。port resolution on/off
p 全量显示/关闭端口信息 (port display off/on)
1/2/3 根据近2 秒、10 秒、40 秒的平均网络流量排序 sort by col 1/2/3
< 根据源ip/主机名排序 (sort by source)
> 根据目的地址ip或主机名排序 (sort by dest)
o 冻结当前连接显示 order frozen/unfrozen
El tercer hacha: verifique el punto muerto del subproceso JVM
Concéntrese en analizar si el hilo está bloqueado en una posición determinada
Al jstack -F pidencontrar interbloqueos de subprocesos, exportar pilas de subprocesos y luego ver el estado del subproceso;
1. Ver el estado del hilo en el proceso de servicio
top -H -p pid
top -H -p 1293
或
ps -mp pid -o THREAD,tid,time
ps -mp 1293 -o THREAD,tid,time
2. Ver el subproceso de excepción del sistema hexadecimal
printf “%x\n” nid
3. Ver la información de la pila de subprocesos de excepción
jstack pid | grep number
例如:
jstack 1293 | grep 100
jmap -histo 1293|head -100
exportar a archivo
jstack -l PID >> a.log
4. Analizar el punto muerto del subproceso
Consejo de Nien: cómo analizar el punto muerto del subproceso, los pasos de la operación son relativamente engorrosos. Para obtener más información, consulte el vídeo "Tuning Bible".
Después de que el pdf "Tuning Bible" esté terminado, el video de apoyo se lanzará pronto
El cuarto truco: comprobar la pila de JVM
- Si hay suficiente espacio libre en la memoria, se puede determinar que no se debe a una memoria insuficiente;
- Si el registro de recolección de basura es normal, incluida la generación joven y la generación anterior, se puede determinar básicamente que no se debe a una memoria insuficiente;
- Al verificar las instancias del objeto y el espacio ocupado en la memoria, si no hay una situación particularmente grande, se puede determinar básicamente que no se debe a una memoria insuficiente;
- Se ha descartado la causa de la memoria insuficiente y es posible que haya ocurrido una fuga de memoria, y se requiere una investigación de fuga de memoria;
Por lo tanto, el núcleo es verificar el desbordamiento de memoria y las fugas de memoria.
Desbordamiento de memoria y pérdida de memoria:
- Desbordamiento de memoria: la solicitud de espacio de memoria supera el espacio máximo de memoria del montón.
- Fuga de memoria: De hecho, incluye el desbordamiento de memoria. El espacio de la memoria del montón está ocupado por objetos inútiles y no se libera a tiempo, lo que resulta en la ocupación de la memoria y, finalmente, en las fugas de memoria.
Solución de problemas de posibles causas de desbordamiento de memoria
El desbordamiento de memoria es causado por demasiados objetos sin referencia (basura) que hacen que la JVM no se recicle a tiempo, lo que provoca un desbordamiento de memoria. Si ocurre este fenómeno, se puede realizar la solución de problemas de código:
(1) Si las clases y las variables de referencia en la aplicación utilizan demasiado la modificación estática, como Staitc públicos Estudiantes;
Es mejor usar solo tipos básicos o cadenas para usar decoración estática en los atributos de la clase . Tales como: public static int i = 0 public static String str;
(2) Si se usa una gran cantidad de recursividad o recursividad infinita en la aplicación (se usan muchos objetos nuevos en la recursividad )
(3) Si se usa una gran cantidad de bucles o bucles infinitos en la aplicación (se usa una gran cantidad de objetos recién creados en el bucle)
(4) Compruebe si el método de consulta de todos los registros de la base de datos se utiliza en la aplicación. Es decir, el método de consulta de todos a la vez , si la cantidad de datos supera los 100.000, puede causar un desbordamiento de memoria . Por lo tanto, se debe utilizar "consulta de paginación" al realizar consultas.
(5) Verifique si hay arreglos, listas y mapas que almacenen referencias de objetos en lugar de objetos , porque estas referencias evitarán que se liberen los objetos correspondientes y se almacenarán en la memoria en grandes cantidades.
(6) Compruebe si se utiliza la operación de "+ para cadenas no literales" .
Debido a que el contenido de la clase String es inmutable, se generarán nuevos objetos cada vez que ejecute "+". Si hay demasiados objetos String nuevos, habrá demasiados objetos String nuevos, lo que provocará que la JVM no se recicle. en el tiempo y causar desbordamiento de memoria .
Cuatro escenarios de desbordamiento de memoria
- Desbordamiento de pila (StackOverflowError)
- Desbordamiento de almacenamiento dinámico (OutOfMemoryError: espacio de almacenamiento dinámico de Java)
- Desbordamiento de generación permanente (OutOfMemoryError: espacio PermGen)
- desbordamiento directo de memoria
1. Desbordamiento de montón
Si no hay memoria de almacenamiento dinámico que se pueda asignar al crear un objeto, la JVM generará una excepción de espacio de almacenamiento dinámico OutOfMemoryError: java .
Ejemplo de desbordamiento de montón:
/**
* VM Args: -Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError
*/
public static void main(String[] args) {
List<byte[]> list = new ArrayList<>();
int i=0;
while(true){
list.add(new byte[5*1024*1024]);
System.out.println("分配次数:"+(++i));
}
}
resultado de la operación:
分配次数:1
分配次数:2
分配次数:3
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid2464.hprof ...
Heap dump file created [16991068 bytes in 0.047 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.ghs.test.OOMTest.main(OOMTest.java:16)
Adjunto: el archivo de volcado se generará en el directorio raíz del proyecto
En el ejemplo anterior, podemos ver que se produjo un desbordamiento de memoria durante la cuarta asignación de memoria.
Dos, desbordamiento de pila
Cuando el espacio de la pila es insuficiente, se deben manejar las siguientes dos situaciones:
- Si la profundidad de pila solicitada por el subproceso es mayor que la profundidad máxima permitida por la máquina virtual, se generará un StackOverflowError
- La máquina virtual no puede solicitar suficiente espacio de memoria al expandir la profundidad de la pila y se generará un OutOfMemberError
Archivo adjunto: la mayoría de las pilas de máquinas virtuales actuales son dinámicamente escalables.
Aquí hay un caso
public class StackSOFTest {
int depth = 0;
public void sofMethod(){
depth ++ ;
sofMethod();
}
public static void main(String[] args) {
StackSOFTest test = null;
try {
test = new StackSOFTest();
test.sofMethod();
} finally {
System.out.println("递归次数:"+test.depth);
}
}
}
Resultados de la:
递归次数:982
Exception in thread "main" java.lang.StackOverflowError
at com.ghs.test.StackSOFTest.sofMethod(StackSOFTest.java:8)
at com.ghs.test.StackSOFTest.sofMethod(StackSOFTest.java:9)
at com.ghs.test.StackSOFTest.sofMethod(StackSOFTest.java:9)
……后续堆栈信息省略
3. Desbordamiento del área de método
El área de métodos almacena la información relevante de la clase y luego manipula directamente el código de bytes con la ayuda de CGLib para generar una gran cantidad de clases dinámicas.
public class MethodAreaOOMTest {
public static void main(String[] args) {
int i=0;
try {
while(true){
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
return proxy.invokeSuper(obj, args);
}
});
enhancer.create();
i++;
}
} finally{
System.out.println("运行次数:"+i);
}
}
static class OOMObject{
}
}
resultado de la operación:
运行次数:56
Exception in thread "main"
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "main"
Cuarto, desbordamiento de memoria directo
DirectMemory se puede especificar mediante -XX:MaxDirectMemorySize,
Si no se especifica, el valor predeterminado es el mismo que el valor máximo del montón de Java (especificado por -Xmx).
¿Cómo simular el desbordamiento directo de la memoria? NIO usará memoria directa, puede simularla a través de NIO,
En el siguiente ejemplo, NIO se omite y UnSafe se usa directamente para asignar memoria directa.
public class DirectMemoryOOMTest {
/**
* VM Args:-Xms20m -Xmx20m -XX:MaxDirectMemorySize=10m
* @param args
*/
public static void main(String[] args) {
int i=0;
try {
Field field = Unsafe.class.getDeclaredFields()[0];
field.setAccessible(true);
Unsafe unsafe = (Unsafe) field.get(null);
while(true){
unsafe.allocateMemory(1024*1024);
i++;
}
} catch (Exception e) {
e.printStackTrace();
}finally {
System.out.println("分配次数:"+i);
}
}
}
resultado de la operación:
Exception in thread "main" java.lang.OutOfMemoryError
at sun.misc.Unsafe.allocateMemory(Native Method)
at com.ghs.test.DirectMemoryOOMTest.main(DirectMemoryOOMTest.java:20)
分配次数:27953
Resumen de desbordamiento de memoria:
- Desbordamiento de memoria de pila : la profundidad de pila requerida por el programa es demasiado grande.
- Desbordamiento de memoria del montón : Distinguir entre fugas de memoria y capacidad de memoria insuficiente. La fuga depende de cómo GC Root haga referencia al objeto y, si es insuficiente, aumente los parámetros -Xms y -Xmx.
- Desbordamiento de generación permanente : los objetos de clase no se liberan, los objetos de clase ocupan demasiada información y hay demasiados objetos de clase.
- Desbordamiento de memoria directa : en qué parte del sistema se usará la memoria directa.
Solución de problemas de desbordamiento de memoria y fugas de memoria
Probablemente se utilizarán las siguientes herramientas
1. Verifique el uso de la memoria y la recolección de basura a través de jstat, y verifique si el uso de la memoria y la recolección de basura son anormales;
jstat es una herramienta de línea de comandos proporcionada en JDK, que se utiliza principalmente para imprimir estadísticas relacionadas con los datos de rendimiento de JVM.
Incluye principalmente los siguientes aspectos: datos de recolección de basura (GC), datos relacionados con la compilación (Compilación), información de carga de clases (Cargador de clases)
La mayor ventaja de jstat es que puede capturar estos datos en tiempo real mientras se ejecuta la JVM.
Usando jstack, podemos generar una instantánea de subprocesos de la máquina virtual en el momento actual, incluida una colección de pilas de métodos que ejecuta cada subproceso en la máquina virtual, que se utiliza para localizar la causa de pausas a largo plazo en subprocesos, como como interbloqueos, bucles infinitos y recursos externos a largo plazo.
2. Verifique la asignación de memoria a través de jmap -heap para ver si el espacio de memoria está lleno, lo que resulta en la incapacidad de asignar suficiente espacio de memoria;
A veces, solo mirar las instantáneas de los hilos no es suficiente.
Es necesario seguir observando la instancia del objeto, en este momento podemos usar el comando jmap.
Jmap se puede utilizar para ver la información de la memoria, el número de instancias y el tamaño de la memoria ocupada.
jmap -histo[:live] imprime el número de instancias de cada clase, el uso de la memoria y la información del nombre completo de la clase.
Nota: El prefijo "*" se agregará al comienzo del nombre de la clase interna de la VM. Si se agrega live al subparámetro, solo se contará la cantidad de objetos en vivo.
3. Para verificar el motivo de la recolección de basura a través de gclog, debe especificar registrar el registro de recolección de basura cuando se inicia el servicio;
4. Búsqueda en línea de Arthas
Pasos aproximados:
paso 1: jps para obtener la identificación del proceso
- Utilícelo
jpspara averiguar el ID exclusivo de este proceso en la máquina virtual local, ya que este LVMID se necesita en el proceso de solución de problemas posterior para determinar qué proceso de máquina virtual se debe supervisar. - El formato del comando es:
jps [ options ] [ hostid ]
comúnmente jps -lusado
paso 2: jstat ver estadísticas de GC
- Ver el porcentaje del espacio total de la estación utilizado.
- Formato de comando:
jstat [ option vmid [interval[s|ms] [count]] ]
ejemplo
jstat -gcutil 20954 1000
- gcutil se refiere a: el porcentaje del espacio total de la estación espacial utilizada.
- 20954 se refiere a: pid
- 1000 significa: consulta una vez cada 1000 milisegundos y sigue comprobando.

El área Eden de nueva generación (E, significa Eden) utiliza el 97,14% del espacio,
Las dos áreas de Superviviente (S0, S1, que representan a Survivor0, Survivor1) son 64,38 % y 0 % respectivamente,
La vejez (O, significa Viejo) utiliza el 29,07%.
Minor GC (YGC, en representación de Young GC) ha ocurrido 32 veces desde que se ejecutó el programa, con un tiempo total de 1.016 segundos.
El GC completo (FGC, GC completo) ocurre 3 veces y el tiempo total de GC completo es de 0,4 segundos.
El tiempo total consumido (GCT, GC Time) es de 1,416 segundos.
paso 3: Análisis de fugas de memoria y objetos grandes
Normalmente hay dos métodos de análisis:
- Tipo 1: análisis en línea ligero:
Paso 1: jmap Ver los N objetos principales que ocupan la mayoría de los recursos en el proceso,
Paso 2: saber qué objeto consume memoria, y luego no es difícil localizar el código.
- Tipo 2: análisis fuera de línea pesado:
Utilice la "herramienta de creación de imágenes de memoria de Java: jmap" para generar una instantánea de volcado de pila (comúnmente llamada headdump o archivo de volcado).
Vuelque el montón y luego use MAT y otras herramientas para el análisis, pero lleva mucho tiempo volcar el montón, y el archivo es enorme, y luego arrástrelo desde el servidor a la herramienta de importación local.
Tipo 1: fugas de memoria ligeras y análisis en línea de objetos grandes:
Paso 1: jmap Ver los N objetos principales que ocupan la mayoría de los recursos en el proceso,
formato de comando jmap:jmap [ option ] vmid
Utilice el comando de la siguiente manera:jmap -histo:live 1293
jmap Ver los 20 objetos principales que ocupan la mayor parte de los recursos en el proceso,
jmap -histo pid|head -N
例如:
jmap -histo 1293|head -20
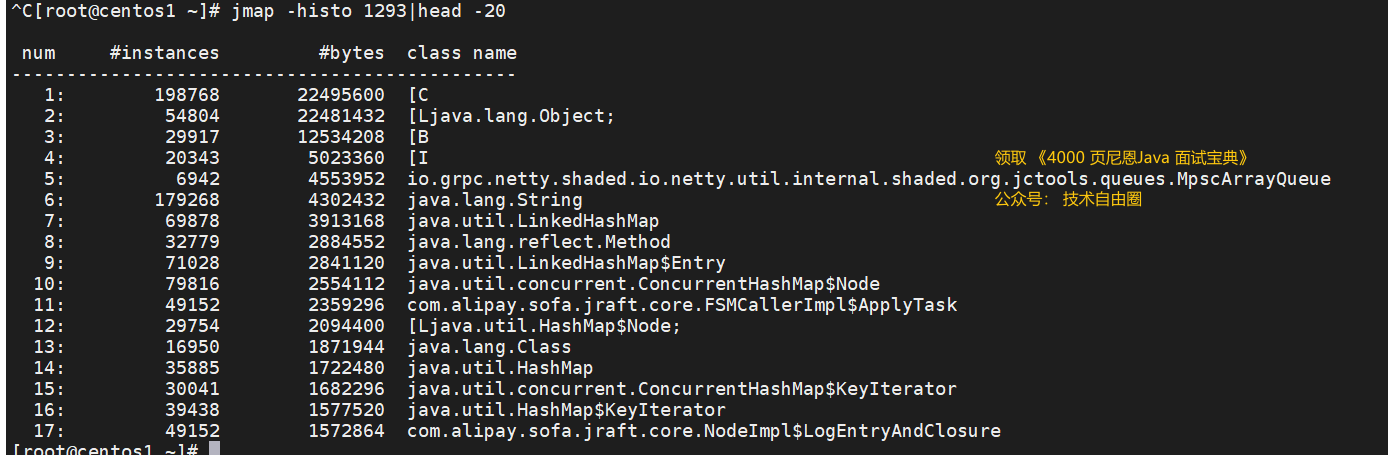
Habrá grandes objetos de clases en su propio proyecto, y la cuarta columna es el nombre de la clase.
Paso 2: use Arthas para ubicar el código donde se encuentra el objeto grande
Arthas es una herramienta de diagnóstico de JavaAlibaba que se abrió en septiembre de 2018 . Soporte , utilizando el modo interactivo de la línea de comandos, proporcionando incompletitud automática, que puede localizar y diagnosticar convenientemente problemas de ejecución del programa en línea. Al momento de escribir este artículo, se han cosechado más de 17000.JDK6+TabStar
La documentación oficial de Arthas es muy detallada. Este artículo también se refiere al contenido de la documentación oficial. Al mismo tiempo, no solo hay comentarios de problemas en el Githubproyecto de código abierto, sino también una gran cantidad de casos de uso, que también pueden utilizarse como referencia de aprendizaje.Issues
Dirección de código abierto: https://github.com/alibaba/arthas
Documentación oficial: https://alibaba.github.io/arthas
Gracias a las poderosas y ricas funciones de Arthas , lo que Arthas puede hacer está más allá de la imaginación.
Los siguientes son solo algunos escenarios de uso comunes, y usted mismo puede explorar más escenarios de uso después de familiarizarse con Arthas .
- ¿Existe una visión global de la salud del sistema?
- ¿Por qué se aumenta de nuevo la CPU?¿Dónde está ocupada la CPU?
- ¿Hay varios subprocesos que se ejecutan en interbloqueo? ¿Hay un bloqueo?
- El programa tarda mucho en ejecutarse. ¿Dónde tarda mucho tiempo? ¿Cómo monitorearlo?
- ¿De qué paquete jar se carga esta clase? ¿Por qué se informan varios tipos de excepciones relacionadas?
- ¿Por qué no se ejecuta el código que cambié? ¿Será que no me comprometí? ¿Bifurcación incorrecta?
- Si encuentra un problema y no puede depurar en línea, ¿puede volver a publicarlo agregando un registro?
- ¿Hay alguna forma de monitorear el estado de ejecución en tiempo real de la JVM?
Aquí hay algunos comandos comunes de Arthas ,
| Orden | introducir |
|---|---|
| panel | Panel de datos en vivo para el sistema actual |
| hilo | Ver la información de la pila de subprocesos de la JVM actual |
| mirar | Método Ejecución Datos Observación |
| rastro | La ruta de la llamada interna del método y la salida del tiempo dedicado a cada nodo en la ruta del método |
| pila | Salida de la ruta de llamada donde se llama al método actual |
| tt | El túnel de tiempo-espacio de los datos de ejecución del método, registra los parámetros de entrada y devuelve información de cada llamada del método especificado, y puede observar estas llamadas en diferentes momentos |
| monitor | Supervisión de ejecución de métodos |
| jvm | Ver información actual de JVM |
| opción vmo | Ver y actualizar parámetros relacionados con el diagnóstico de JVM |
| Carolina del Sur | Ver la información de la clase cargada por la JVM |
| SM | Ver la información del método de la clase cargada |
| Jad | Descompilar el código fuente de la clase cargada especificada |
| cargador de clases | Ver árbol de herencia del cargador de clases, URL, información de carga de clases |
| volcado de pila | Función de volcado de pila similar al comando jmap |
Consejo de Nien: cómo usar Arthas para localizar el código del objeto grande, los pasos de la operación son relativamente engorrosos.
Cómo usar Arthas para ubicar el código de ubicación del objeto grande, consulte el video "Tuning Bible" para obtener más detalles.
Después de que el pdf "Tuning Bible" esté terminado, el video de apoyo se lanzará pronto
Tipo 2: fugas de memoria pesadas y análisis en línea de objetos grandes:
Use jmap o información de volcado para analizar usando herramientas Mat o JProfiler o JVisualVM
jmap -dump:live,format=b,file=/dump.bin pid
例如:
jmap -dump:live,format=b,file=/dump.bin 1293
Consejo de Nien: Cómo usar JVisualVM para analizar y ubicar el código del objeto grande después de exportar usando jmap, los pasos de la operación también son relativamente engorrosos.
Cómo usar jmap y JVisualVM para analizar y ubicar el código del objeto grande, vea el video "Tuning Bible" para obtener más detalles.
Después de que el pdf "Tuning Bible" esté terminado, el video de apoyo se lanzará pronto
El quinto truco: comprobar la configuración del sistema operativo
- Límite en el número de identificadores de archivos
- Límites en el número de mapas de memoria
- Límite de hilo
etc.
Caso en línea 1: OOM provoca animación suspendida
Este es un caso de Internet, el texto original es el siguiente:
https://blog.csdn.net/weixin_42130396/article/details/126020231
Fenómeno
En un accidente de producción, el subproceso OOM se debió a la consulta de demasiados datos de la base de datos a la vez: excepción de espacio de almacenamiento dinámico de Java
**Preste atención a la escala de datos:** Datos de 15 W de la tabla de datos, memoria de montón JVM 2G
**La situación en línea es:** Cuando se produce el hilo OOM, el proceso de Java no se cuelga inmediatamente.
El problema es que a menudo decimos: cuando ocurre OOM, el programa se cuelga. La situación aquí es: se produjo OOM y la JVM no se colgó.
Nota especial: la JVM no se bloquea necesariamente cuando se produce OOM
Nin escribió un artículo detallado que presenta:
Lado de Meituan: después de OOM, ¿salirá definitivamente la JVM? ¿Por qué?
escena del accidente
El monitoreo encontró que uno de los servicios en línea se colgó , el proceso aún estaba allí y springboot murió en una animación suspendida.
Inicie sesión en el registro de consultas del servidor y encontró java.lang.OutOfMemoryError: se excedió el límite de sobrecarga de GC,
El error significa: jvm pasa mucho tiempo haciendo gc, pero no hay efecto de reciclaje (creando muchos objetos grandes y no reciclando basura).
En el registro de excepciones, se puede ver que la causa de OOM es causada por la llamada de hibernación a repository.findAll()

identificar el problema
Exporte el archivo hprof al local y use jvisualvm que viene con jdk para el análisis.
Veamos qué es grande primero.
Todavía está exportando el archivo hprof al local y usando jvisualvm que viene con jdk para el análisis. Esta vez, no tengo tanta suerte. Puedo encontrar pistas útiles haciendo clic y saltando a "Ver el hilo que causó el error de excepción OutOfMemoryError". , así que veamos qué es grande.

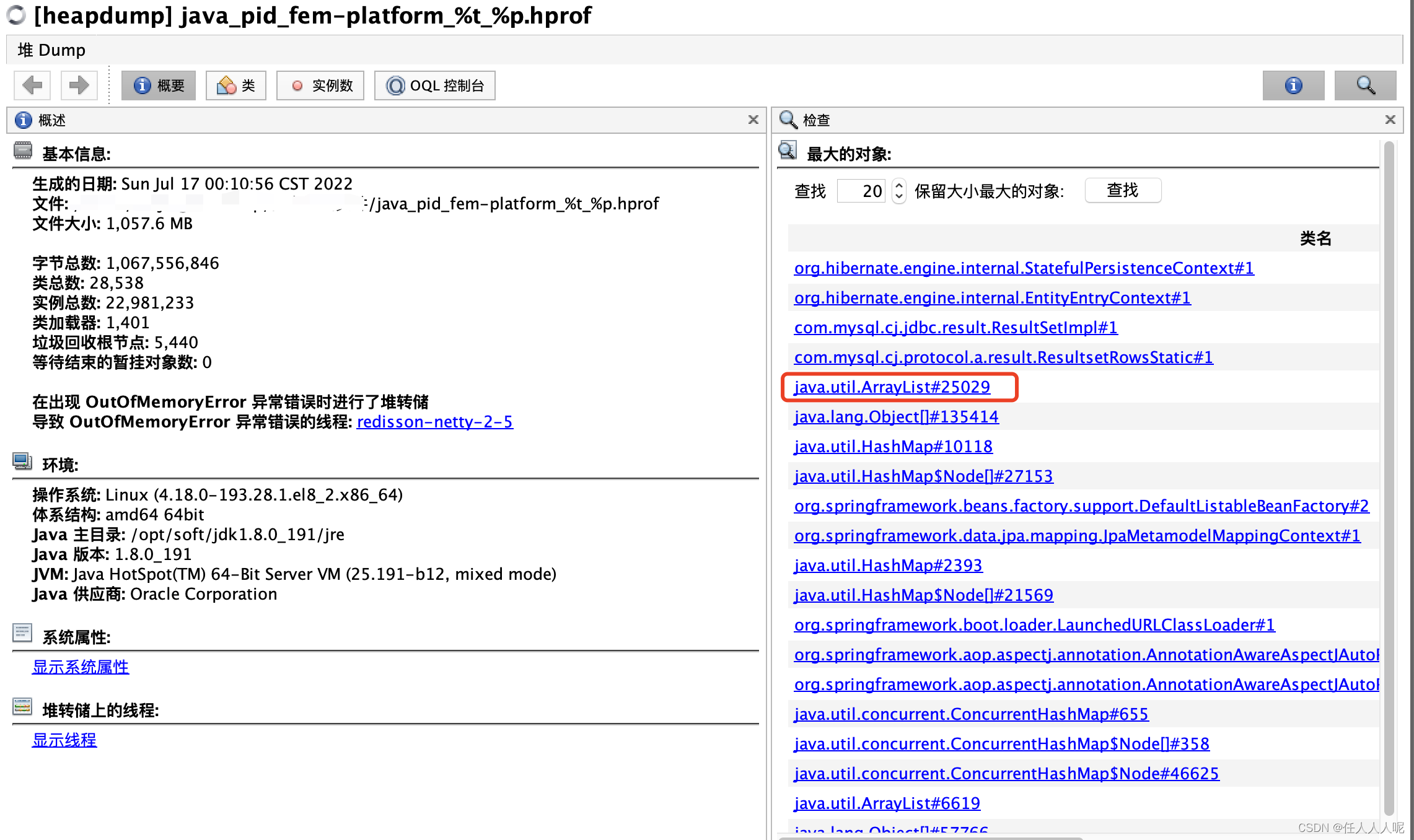
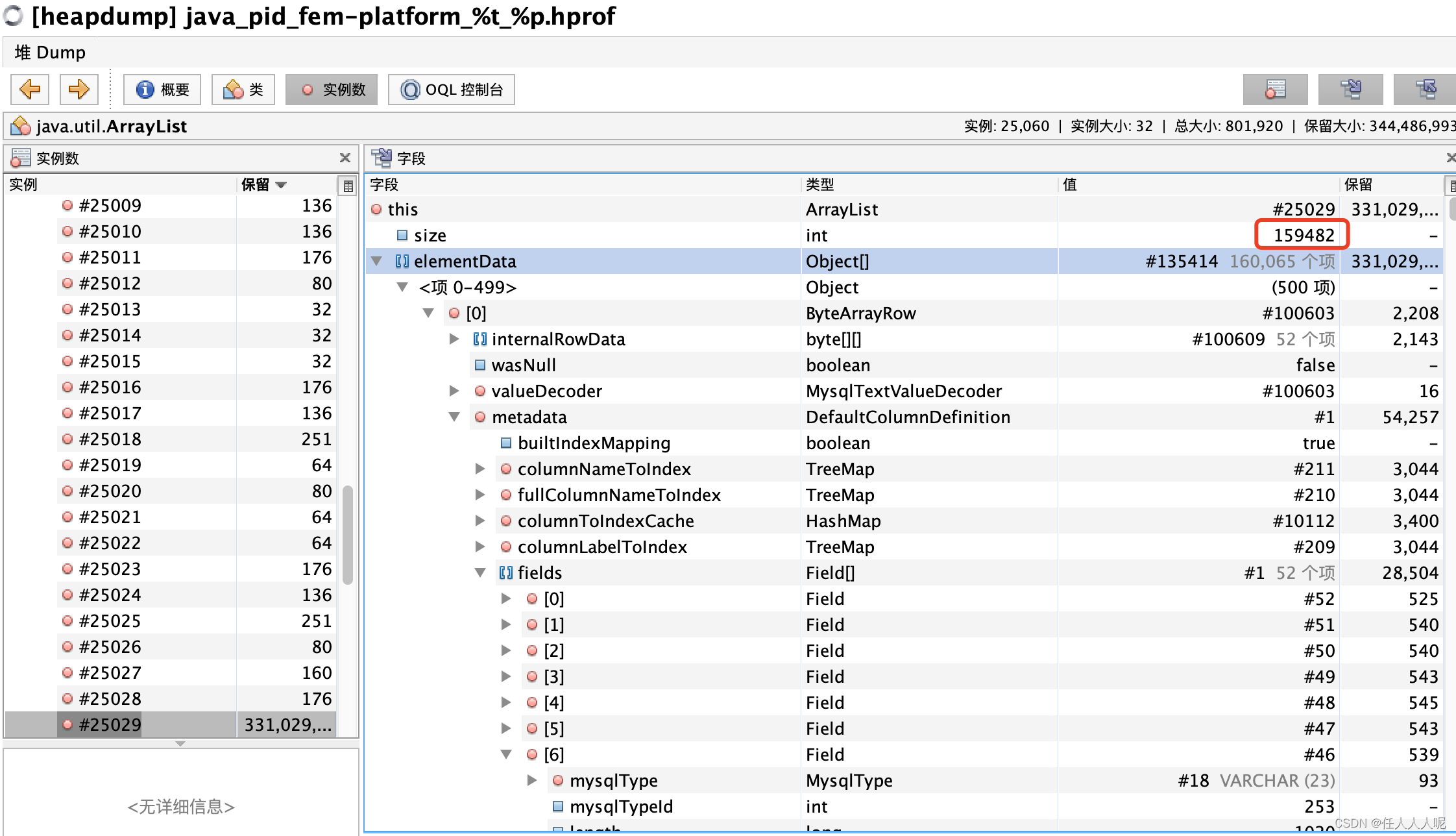
Puede ver que list.size en realidad tiene 159482. Expanda para ver qué objetos están almacenados en esta lista.
Expanda y vea los metadatos——>fields——>fullName (o tableName y columnName) para ver si hay tablas y campos familiares que puedan ubicar todos los datos de la tabla que se consulta

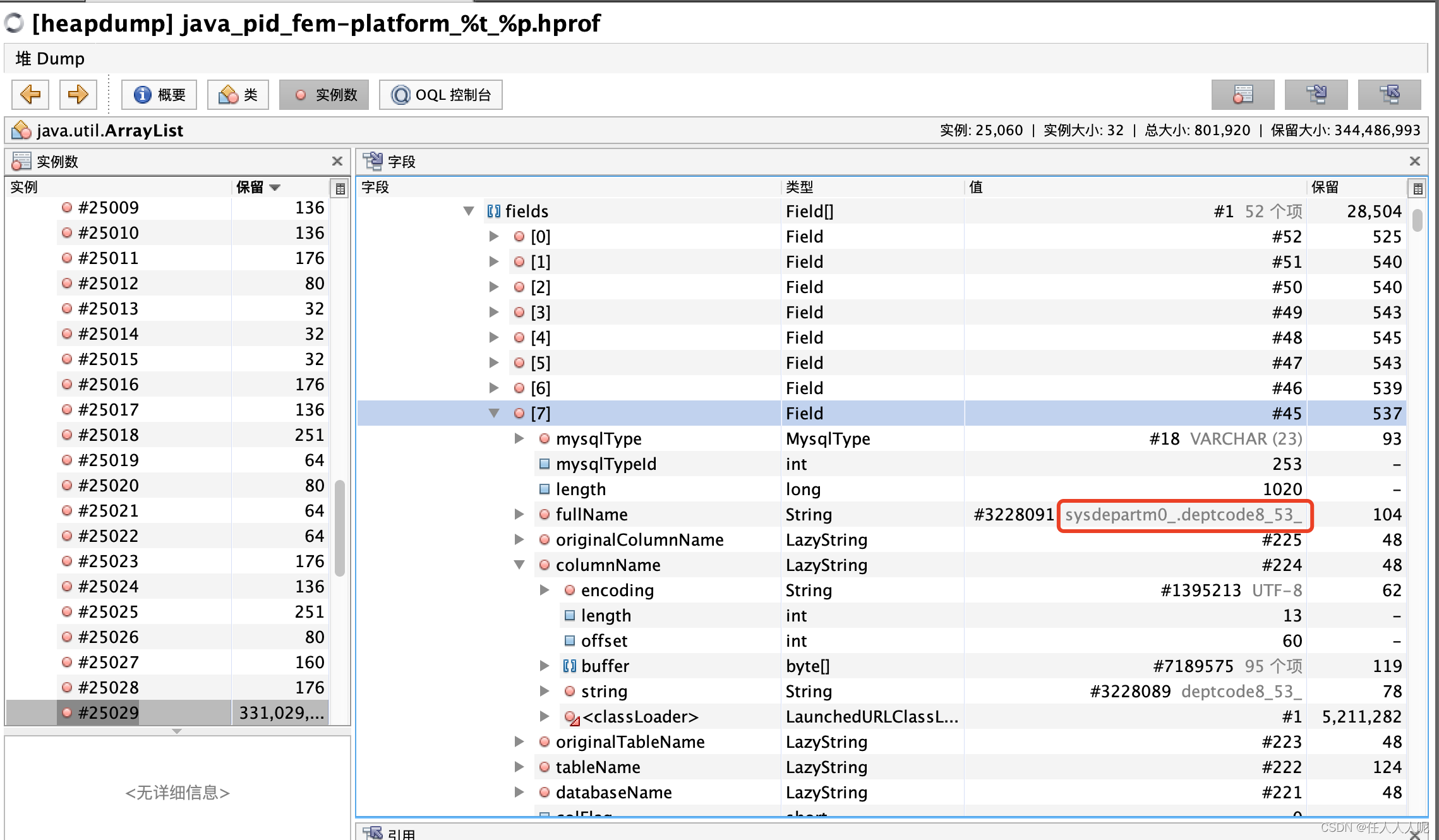
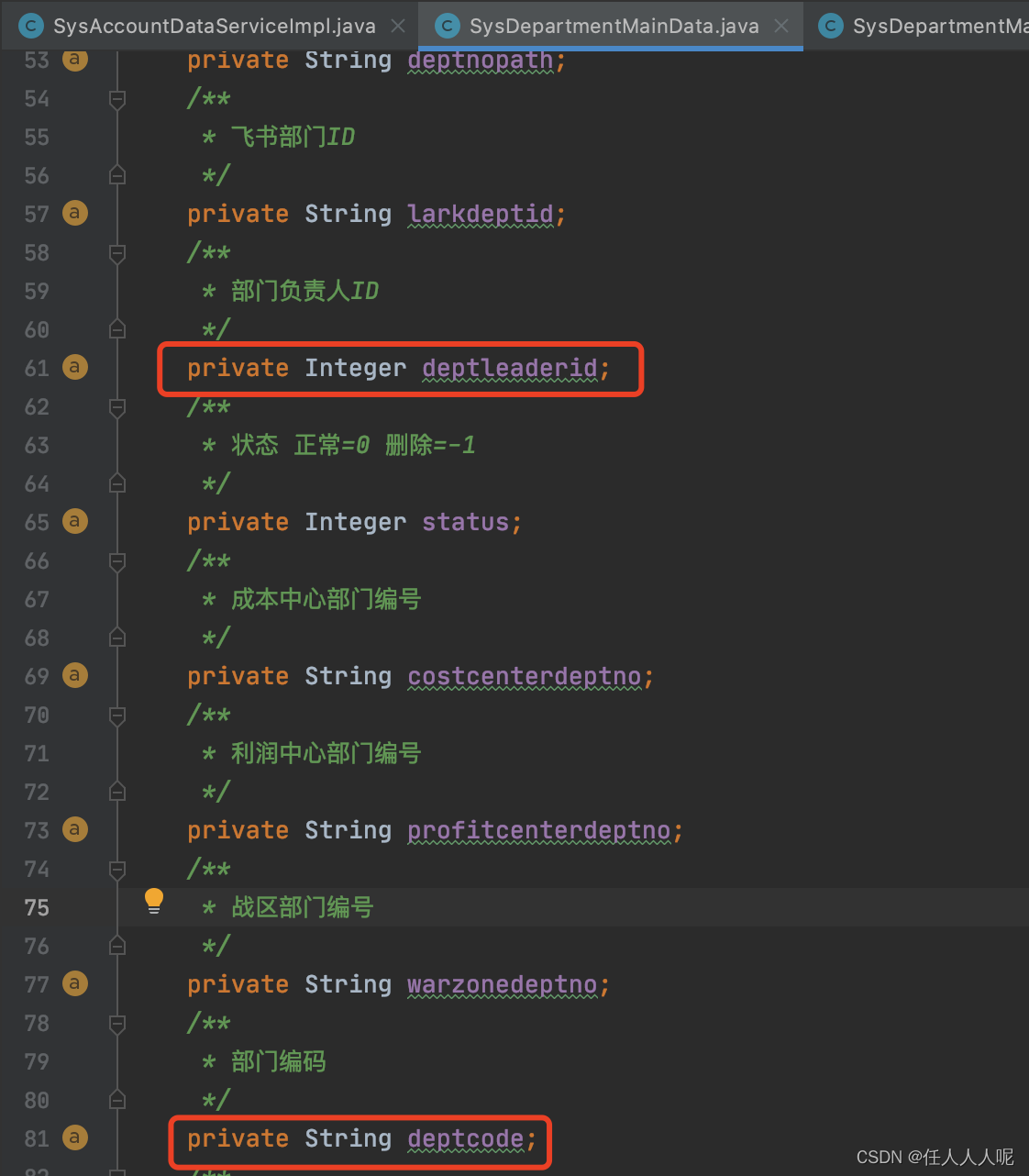
Hasta ahora, se ha descubierto que jpa ha consultado todos los datos en la tabla de departamentos.
Combinado con las tareas programadas ejecutadas en este momento, finalmente se encuentra la ubicación del código:
List<SysDepartmentMainData> departments = departmentMainDataRepository.findAll();
Pero aquí viene la pregunta, ¿cómo puede haber más de 150.000 datos departamentales?
La tabla de departamentos en este proyecto es una tarea programada. La tabla se borra todos los días y luego los datos maestros de la empresa se sincronizan para cubrir toda la información del departamento.
Este método agrega transacciones, por lo que no habrá ninguna situación en la que no haya datos en la tabla después de borrar la tabla pero falle la llamada a la interfaz de datos principal.
Solo hay más de 4000 tablas de departamentos para ver los datos maestros de la empresa, entonces, ¿cómo llegaron los 150 000?
Luego tenemos que mirar la lógica del código de la tabla de almacenamiento y encontramos el problema, la siguiente es la causa del problema y la solución final
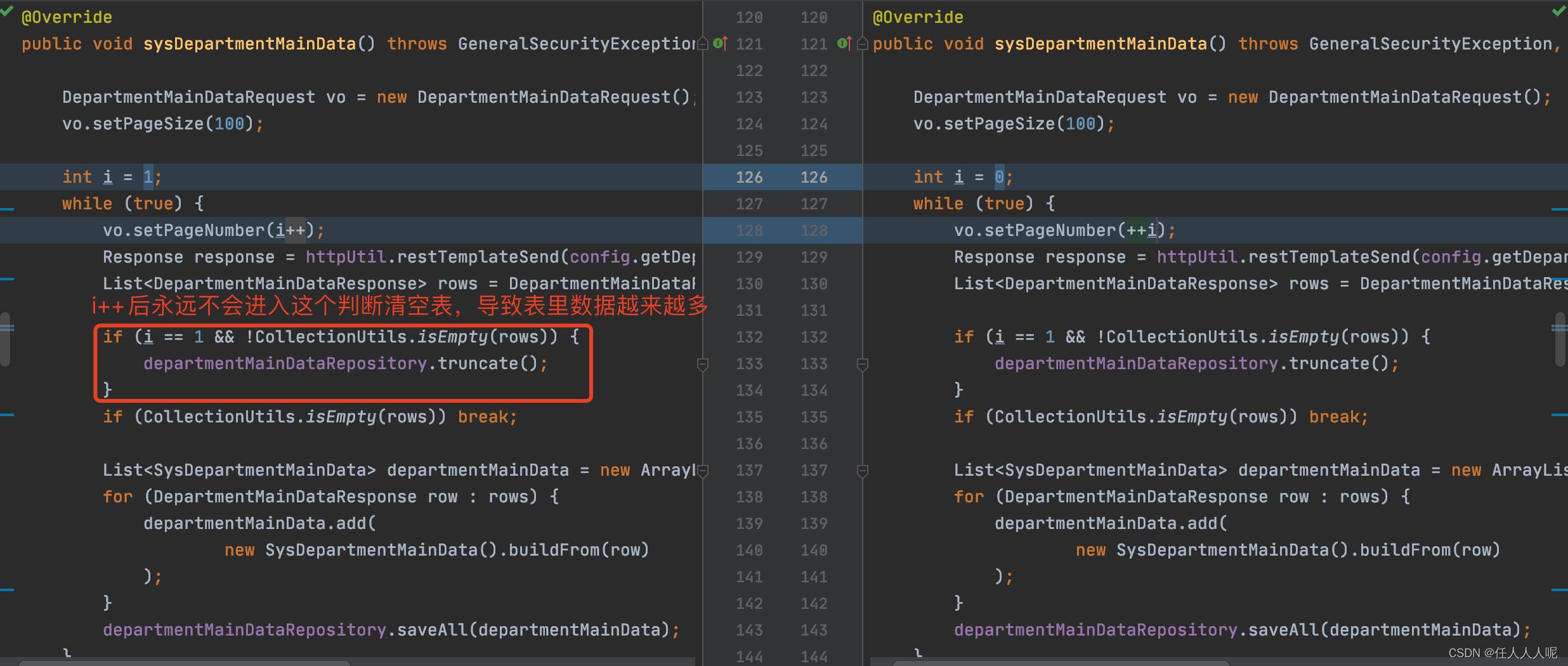
Caso en línea 2: número insuficiente de subprocesos del sistema operativo conduce a animación suspendida
Fenómeno
El monitoreo encontró que uno de los servicios en línea se colgó , el proceso aún estaba allí y springboot murió en una animación suspendida.
Sin embargo, el sistema operativo es normal.
cpu, memoria, io, etc. son todos normales
Proceso de solución de problemas
A. Consulta de estado de la memoria
jstat -gcutil pid

ningún problema.
B. Exportación de instantáneas de memoria
sudo -u wwwroot `jmap -dump:live,format=b,file=heap001 pid`
Cuando el comando anterior no se puede exportar, ejecute la siguiente declaración
sudo -u wwwroot `jmap -F -dump:live,format=b,file=heap001 pid`
ningún problema.
C. Exportación de información de pila
sudo -u wwwroot `jstack pid > aaa.txt `
sudo -u wwwroot `jstack pid > aaa.txt `
D. Ver información de la memoria
free

ningún problema.
E. vista ilimitada
Preste atención a las diferentes situaciones de los usuarios.

tiene un problema.
no hay suficientes hilos
Solución
1. Borrar caché de página
echo 3 > /proc/sys/vm/drop_caches
2. ajuste de configuración ulimit
El fenómeno de la configuración irrazonable es:
1. No se puede ingresar al programa
2. Ningún registro anormal
3. La cantidad de subprocesos y la cantidad de conexiones a la base de datos no son muchas.
4. El proceso del programa es normal.
1、查看命令:ulimit -a
2、修改vim /etc/security/limits.conf,添加或修改配置(可能之前已经存在),添加完成后关闭putty并重新连接通过ulimit -a查看是否生效
* soft nproc 35535
* hard nproc 65535
* soft nofile 35535
* hard nofile 65535
3、如果上述修改无法生效,尝试查看或修改vim /etc/security/limits.d/20-nproc.conf,内容同上
4、如果2、3均无法生效,联系运维排查无法生效问题
Caso en línea 3: velocidad de procesamiento de solicitud lenta, lo que da como resultado una animación suspendida
Descripción de fondo:
Mientras el proyecto se está ejecutando, de repente no puede manejar nuevas solicitudes.
Los tps que vienen son decenas de miles, y todas las máquinas de repente se vuelven 0, ¡lo que tiene un gran impacto en los negocios en línea!
Por lo tanto, verifique inmediatamente el estado de ejecución del servicio, pero aún se está ejecutando, por lo que se puede considerar que SpringBoot tiene una animación suspendida.
Proceso de solución de problemas:
Paso 1: Ver registros, recursos del sistema y memoria jvm
ningún problema
El segundo paso es comprobar el estado del puerto correspondiente al servicio.
Use el netstat -anp |grepnúmero de puerto de comando para ver la situación detallada del puerto,
A continuación, hay información como el tipo de protocolo, ip + puerto de origen, estado del protocolo tcp, etc. Aquí, nos enfocamos principalmente en la cantidad de conexiones del protocolo tcp y el estado correspondiente de cada conexión.
netstat -an |grep 80
tcp4 0 0 192.168.31.24.51380 120.253.255.102.443 ESTABLISHED
tcp4 0 0 192.168.31.24.50935 192.30.71.80.443 ESTABLISHED
tcp4 31 0 192.168.31.24.50863 3.80.20.154.443 CLOSE_WAIT
tcp6 0 0 fe80::b7ca:330b:.1028 fe80::5059:ee74:.1025 ESTABLISHED
tcp6 0 0 fe80::b7ca:330b:.1024 fe80::5059:ee74:.1024 ESTABLISHED
También es posible determinar el número y el estado de las conexiones de puerto tcp actuales mediante códigos de estado tcp específicos de grep.
netstat -an |grep 80 |grep CLOSE_WAIT
netstat -an |grep 80 |grep CLOSE_WAIT
tcp4 31 0 192.168.31.24.50863 3.80.20.154.443 CLOSE_WAIT
tcp4 31 0 192.168.31.24.50855 3.80.20.154.443 CLOSE_WAIT
tcp4 31 0 192.168.31.24.50854 3.80.20.154.443 CLOSE_WAIT
tcp4 31 0 192.168.31.24.50853 3.80.20.154.443 CLOSE_WAIT
tcp4 31 0 192.168.31.24.50852 3.80.20.154.443 CLOSE_WAIT
Además, también se puede utilizar ss -lnr |grep 80para determinar el número de Send-Q y Recv-Q del puerto correspondiente.
También puede reflejar si el tcp del puerto correspondiente está bloqueado.
En el tercer paso, la cola de conexión TCP está llena, lo que provoca la suspensión de la animación.
De acuerdo con la situación tcp del puerto de servicio en el paso anterior, se determina que el problema final es que la cola de conexión TCP del puerto está llena porque la conexión tcp no se libera correctamente y las solicitudes posteriores no pueden ingresar a la cola de conexión, ¡haciendo que Tomcat se congele!
Finalmente, después de identificar el problema, diríjase al servicio para encontrar la causa.
Puede ser que la solicitud http correspondiente no responda, o debido a que la velocidad de procesamiento del servicio está muy por debajo de la cantidad de solicitudes, la cola de conexión se llena lentamente durante la operación.
solución:
- Cuando se encuentre con una situación de este tipo, primero puede intentar reiniciar el servicio y puede continuar admitiendo el servicio. Después de un cierto período de tiempo, el servicio entrará en animación suspendida; al mismo tiempo, apague la parte frontal del negocio para reducir o incluso cerrar el número de solicitudes. Minimizar las pérdidas comerciales.
- Restaurar la versión. Generalmente, la aparición de problemas se debe al lanzamiento de nuevos servicios. Restaurar primero la versión sin problemas.
- Identifique la causa del problema y resuélvalo de manera específica.
Caso en línea 4: la salida de registro a la consola conduce a una animación suspendida
La siguiente es una descarga de archivo atascada, la esencia sigue siendo un caso de animación suspendida en línea:
Problema: descarga de archivos atascada
En un clúster de descarga de archivos grandes (más de 100 instancias), un usuario nos notificó un día:
你们下载一个文件咋下载了一整天都没下载下来
Según los logs y archivos descargados, no es que el archivo de descarga sea lento, sino que el programa está atascado, es decir, animación suspendida.
Proceso de análisis
- Analice el registro, rastree el programa y descubra que no hay nada malo con el código, y el registro no puede decir por qué
jstack -l pidseguimiento de pila, información de pila dada en parte
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.131-b11 mixed mode):
"Attach Listener" #186 daemon prio=9 os_prio=0 tid=0x00007fbf98001000 nid=0x28e8 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
Locked ownable synchronizers:
- None
"pool-47-thread-4" #185 prio=5 os_prio=0 tid=0x00007fbf4c44c800 nid=0x2b76 runnable [0x00007fbf348e3000]
java.lang.Thread.State: RUNNABLE
at java.io.FileOutputStream.writeBytes(Native Method)
at java.io.FileOutputStream.write(FileOutputStream.java:326)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:122)
- locked <0x0000000080223058> (a java.io.BufferedOutputStream)
at java.io.PrintStream.write(PrintStream.java:480)
- locked <0x0000000080223038> (a java.io.PrintStream)
at java.io.FilterOutputStream.write(FilterOutputStream.java:97)
at ch.qos.logback.core.joran.spi.ConsoleTarget$1.write(ConsoleTarget.java:37)
at ch.qos.logback.core.encoder.LayoutWrappingEncoder.doEncode(LayoutWrappingEncoder.java:131)
at ch.qos.logback.core.OutputStreamAppender.writeOut(OutputStreamAppender.java:187)
at ch.qos.logback.core.OutputStreamAppender.subAppend(OutputStreamAppender.java:212)
at ch.qos.logback.core.OutputStreamAppender.append(OutputStreamAppender.java:100)
at ch.qos.logback.core.UnsynchronizedAppenderBase.doAppend(UnsynchronizedAppenderBase.java:84)
at ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:48)
at ch.qos.logback.classic.Logger.appendLoopOnAppenders(Logger.java:270)
at ch.qos.logback.classic.Logger.callAppenders(Logger.java:257)
at ch.qos.logback.classic.Logger.buildLoggingEventAndAppend(Logger.java:421)
at ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus(Logger.java:383)
at ch.qos.logback.classic.Logger.info(Logger.java:591)
at com.baidu.adb.client.download.AbstractPartitionDownloader$Worker.run(AbstractPartitionDownloader.java:99)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- <0x0000000587fa71f0> (a java.util.concurrent.ThreadPoolExecutor$Worker)
- <0x000000008021cbe8> (a java.util.concurrent.locks.ReentrantLock$FairSync)
"pool-47-thread-3" #184 prio=5 os_prio=0 tid=0x00007fbf4c44b800 nid=0x2b74 waiting on condition [0x00007fbf35af5000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x000000008021cbe8> (a java.util.concurrent.locks.ReentrantLock$FairSync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
....
Como se puede ver en la información de la pila, pool-47-thread-4 está en RUNNABLE y ha adquirido 2 bloqueos
Locked ownable synchronizers:
- <0x0000000587fa71f0> (a java.util.concurrent.ThreadPoolExecutor$Worker)
- <0x000000008021cbe8> (a java.util.concurrent.locks.ReentrantLock$FairSync)
El estado de pool-47-thread-3 y pool-47-thread-2 es ESPERANDO, y ambos están en estado de condición de espera, y ambos están esperando 0x000000008021cbe8, que es un interbloqueo .
Mire la información de la pila de pool-47-thread-4 nuevamente, at ch.qos.logback.core.joran.spi.ConsoleTarget$1.write(ConsoleTarget.java:37)es decir, el inicio de sesión no ha liberado el bloqueo y está en el agregador de la consola
Verifique el archivo de inicio de sesión, hay un agregador en el registrador que es consola

solución
Si el subproceso de trabajo de inicio de sesión no puede completarse, debe ser porque su cola de bloqueo está llena.
El subproceso de trabajo está esperando para depositar su entrada de registro y, debido a que el subproceso está esperando, sabemos que liberó el bloqueo en la cola, pero aún mantiene el bloqueo en el flujo de impresión.
El subproceso de escritura de la consola está bloqueado al intentar adquirir un bloqueo en el flujo de impresión, por lo que están bloqueados.
La solución mínima para evitar cambios en el código es cambiar el agregador de la consola por uno que no necesite adquirir un bloqueo en el flujo de impresión.
en conclusión:
El programa ha impreso la salida de información en el terminal, pero después de ejecutarse en segundo plano, la información no se puede enviar al terminal.
Después de imprimir demasiada información, el búfer está lleno y el programa deja de ejecutarse, lo que provoca la suspensión de la animación.
Solución:
- El programa que se ejecuta en segundo plano no imprime información de salida en el terminal
Dado que el programa usa log4j, la salida de configuración de la Consola en la configuración log4j.xml está bloqueada - Use nohup para agregar la información de impresión al archivo nohup.out, lo que generará un archivo grande con el tiempo.
Caso en línea 5: animación suspendida en línea CLOSE_WAIT del lado del servidor
El siguiente es un caso real de animación suspendida en línea:
Un proyecto de arranque de primavera proporciona servicios de interfaz de descanso de forma externa, pero se producirán 500 tiempos de espera de conexión cada tres a cinco veces.
identificar el problema
Después de excluir los escenarios de memoria, CPU y disco lleno, accidentalmente descubrí que esta máquina tiene una gran cantidad de conexiones de red CLOSE_WAIT.
Observe la situación CLOSE_WAIT y cuente el número de conexiones close_wait
lsof -i:8091 |grep "CLOSE_WAIT" |wc -l
El número de CLOSE_WAIT conexiones es 67 y sigue creciendo.
¿Por qué hay una gran cantidad de CLOSE_WAIT estados? Tenemos que introducir las cuatro manos agitadas durante el proceso de desconexión del enchufe.
Dado que las conexiones TCP son full-duplex, cada dirección debe cerrarse por separado. Suponga que el comando de terminación lo inicia el cliente.

Cuando el extremo del cliente transfiere datos o necesita desconectarse:
- El cliente envía un mensaje FIN al servidor. (El número de serie es M)
1.1 Indica que llamando a la API de cierre (socket), el Cliente terminará la conexión del Cliente al Servidor.
1.2 significa que el Cliente ya no enviará datos al Servidor. (Pero el Servidor puede continuar enviando al Cliente)
1.3 El estado del Cliente cambia a FIN_WAIT_1 - Después de recibir el FIN, el servidor envía un mensaje ACK al cliente. (el número de serie es M+1)
2.1 El estado del servidor cambia a CLOSE_WAIT
2.2 El estado del cliente cambia a FIN_WAIT_2 después de recibir ACK con el número de serie (M+1) - El lado del servidor también envía un mensaje FIN al lado del cliente. (El número de serie es N)
3.1 significa que el servidor también finaliza la conexión con el cliente en esta dirección.
3.2 Llamando a la API close(socket).
3.3 El estado del servidor cambia a LAST_ACK - Después de que el cliente recibe el mensaje FIN, también envía un mensaje ACK al servidor. (Número de serie N+1)
4.1 El estado del cliente cambia a TIME_WAIT - El lado del servidor recibe el ACK con el número de secuencia (N+1)
5.1 El estado del servidor pasa a ser CERRADO. - Después de traer 2MSL,
el estado del Cliente 6.1 también cambia a CERRADO. - En este punto, se cierra una conexión TCP completa.
Dos preguntas básicas:
- P: ¿Cuándo aparece CLOSE_WAIT de Sever?
R: Después de que el Servidor reciba el mensaje FIN del Cliente. - P: ¿Cuándo pasa el estado CLOSE_WAIT al siguiente estado?
R: Después de que el Servidor envíe un mensaje FIN al Cliente.
Volviendo a la pregunta anterior: ¿Por qué hay una gran cantidad de estados CLOSE_WAIT?
Si el servidor no ha enviado un mensaje FIN al cliente (llamando a la API close()), siempre existirá este CLOSE_WAIT.
Análisis de la razón :
De lo anterior podemos ver que aparece CLOSE_WAIT, lo que indica que el servidor no inició la operación close(), que es básicamente un problema con el programa del servidor del usuario; por lo general, el servidor espera a que el cliente acceda, si el cliente sale y solicitudes para cerrar la conexión, el servidor cierra conscientemente () la conexión correspondiente. Pero el servidor no ha tenido tiempo de cerrar conscientemente (), y la diferencia de tiempo entre el servidor que devuelve el acuse de recibo, el estado de conexión del servidor es close_wait.
Por lo general, esta diferencia de tiempo es muy corta, no lo suficiente como para evitar que toda la aplicación responda al mundo exterior, a menos que, en un caso, la concurrencia alcance el límite de solicitudes de procesamiento de tomcat en un momento determinado y, al mismo tiempo, toda la el grupo de subprocesos para procesar solicitudes está completamente ocupado y espera a que se cierre.
La aplicación SpringBoot en línea justo arriba básicamente se ajusta a este escenario.
Solución de problemas
La idea de solución de problemas es consultar la información del hilo a través de jstack para ver dónde está bloqueado http
jps
jstack $PID > stack.txt
Primero encuentre el pid del proceso y luego exporte la información del hilo a través del comando jstack.
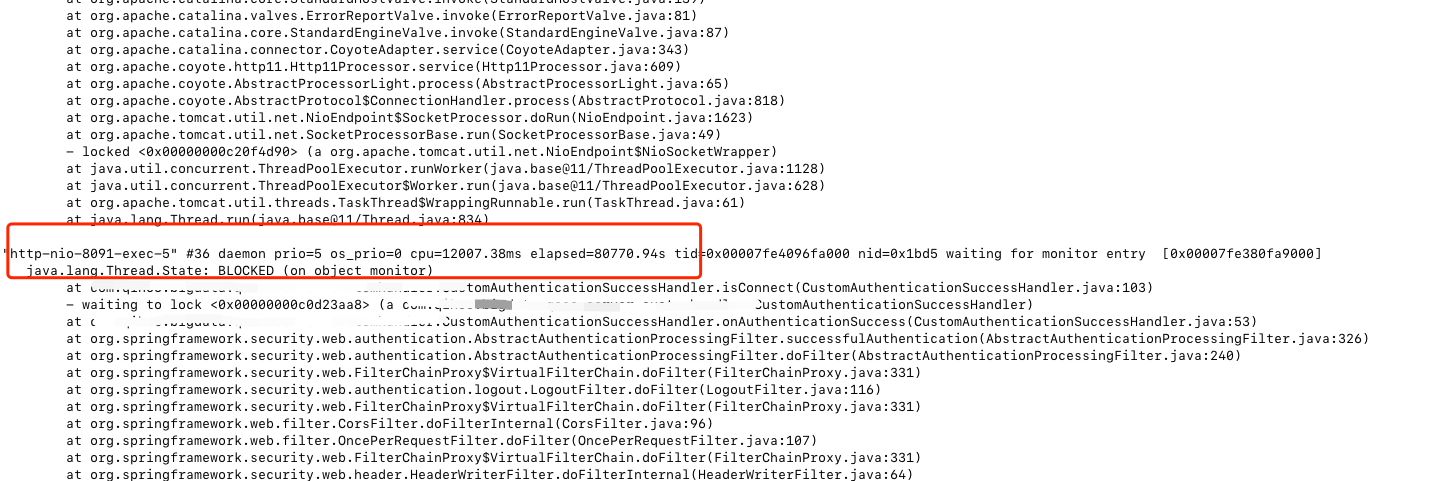
En stack.txt, busque BLOCKED y descubra que una gran cantidad de subprocesos están bloqueados.
文件内容查找:
grep BLOCKED stack.txt
'
Buscar hilos de nio BLOQUEADOS
# -C 3 展示匹配内容及后面3行
grep "BLOCKED" -C 3 | grep "http-nio-exec" stack.txt

http-nio-xx-exec-Es el nombre del subproceso que Tomcat procesa la solicitud.Se puede ver que la mayoría de los subprocesos están bloqueados. Esta es la causa raíz de la animación suspendida.
También puede ver la información de la pila en la información del hilo, que nos indica claramente en qué línea de código se produjo el bloqueo.
Seguimiento del código Efectivamente, el código solicita dos direcciones http a las que ya no se puede acceder normalmente.
Después de modificar el código, libérelo en el entorno de desarrollo, continúe observando la situación CLOSE_WAIT y cuente el número de conexiones close_wait
lsof -i:8091 |grep "CLOSE_WAIT" |wc -l
Fue 67 antes de la revisión y sigue creciendo.
Después de la modificación, se convierte en 0.
ok, el problema de close_wait en línea ha sido resuelto. La animación suspendida de SpringBoot también se ha resuelto.
Solución de animación suspendida del servicio en línea SpringBoot, la memoria de la CPU es normal
Solución de problemas
La regla anterior es que varios nodos del mismo servicio no responden en un entorno de clúster. Si no se resuelve a tiempo, puede formar un efecto de avalancha.
Verifique primero el registro del servicio para ver si hay un error, y verifique el estado de la CPU y la memoria del servicio de manera cortés y habitual.
Revisa primero, si no hay ningún error reportado en el servicio. Si la CPU o la memoria son anormales, siga los pasos a continuación para solucionar el problema.
Solución de problemas
1. Recopilación y análisis de información
Debido a que el monitoreo del estado del servicio no responde, la CPU y la memoria son normales, verifique la información de la pila directamente para ver qué están haciendo los subprocesos.
jstack -l PID >> a.log
En la salida de Jstack, el estado del subproceso de Java es principalmente el siguiente:
Subproceso RUNNABLE en ejecución o E/S en espera
El subproceso BLOQUEADO está esperando el bloqueo del monitor (palabra clave sincronizada)
TIMED_WAITING El subproceso está esperando para activarse, pero se ha establecido un límite de tiempo
ESPERANDO hilo está esperando infinitamente para despertar
Se encuentra que todos están ESPERANDO subprocesos.
"http-nio-8888-exec-6666" #8833 daemon prio=5 os_prio=0 tid=0x00001f2f0016e100 nid=0x667d waiting on condition [0x00002f1de3c5200]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000007156a29c8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at com.alibaba.druid.pool.DruidDataSource.takeLast(DruidDataSource.java:1897)
at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1458)
....
at org.apache.ibatis.executor.CachingExecutor.query(CachingExecutor.java:109)
at com.github.pagehelper.PageInterceptor.intercept(PageInterceptor.java:143)
at org.apache.ibatis.plugin.Plugin.invoke(Plugin.java:61)
at com.sun.proxy.$Proxy571.query(Unknown Source)
2. Localice información clave y rastree el código fuente
La información clave es la siguiente:
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at com.alibaba.druid.pool.DruidDataSource.takeLast(DruidDataSource.java:1897)
Método DruidDataSource.takeLast
DruidConnectionHolder takeLast() throws InterruptedException, SQLException {
try {
while (poolingCount == 0) {
emptySignal(); // send signal to CreateThread create connection
if (failFast && isFailContinuous()) {
throw new DataSourceNotAvailableException(createError);
}
notEmptyWaitThreadCount++;
if (notEmptyWaitThreadCount > notEmptyWaitThreadPeak) {
notEmptyWaitThreadPeak = notEmptyWaitThreadCount;
}
try {
// 数据库的连接都没有释放且被占用,连接池中无可用连接,导致请求被阻塞
notEmpty.await(); // signal by recycle or creator
} finally {
notEmptyWaitThreadCount--;
}
notEmptyWaitCount++;
if (!enable) {
connectErrorCountUpdater.incrementAndGet(this);
throw new DataSourceDisableException();
}
}
} catch (InterruptedException ie) {
...
}
...
return last;
}
El código central en el código fuente es el siguiente:
// 数据库的连接都没有释放且被占用,连接池中无可用连接,导致请求被阻塞
notEmpty.await(); // signal by recycle or creator
Al obtener una conexión del grupo de conexiones de Druid, si la conexión en el grupo no se ha liberado y está ocupada, no hay ninguna conexión disponible en el grupo de conexiones, lo que hace que se bloquee la solicitud.
Localice el código del problema junto con el informe de errores de registro. Debido a un error que informa que la conexión disponible no se libera normalmente, la espera se ha bloqueado.
El código del problema es el siguiente:
try {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
mapper.insetList(list);
sqlSession.flushStatements();
} catch (Exception e) {
e.printStackTrace();
}
Recurrencia del problema
Reproduzca en el entorno multiactivo de acuerdo con la información anterior. La verificación de monitoreo no responde porque los subprocesos están llenos y esperando.
El hilo de Tomcat está lleno:
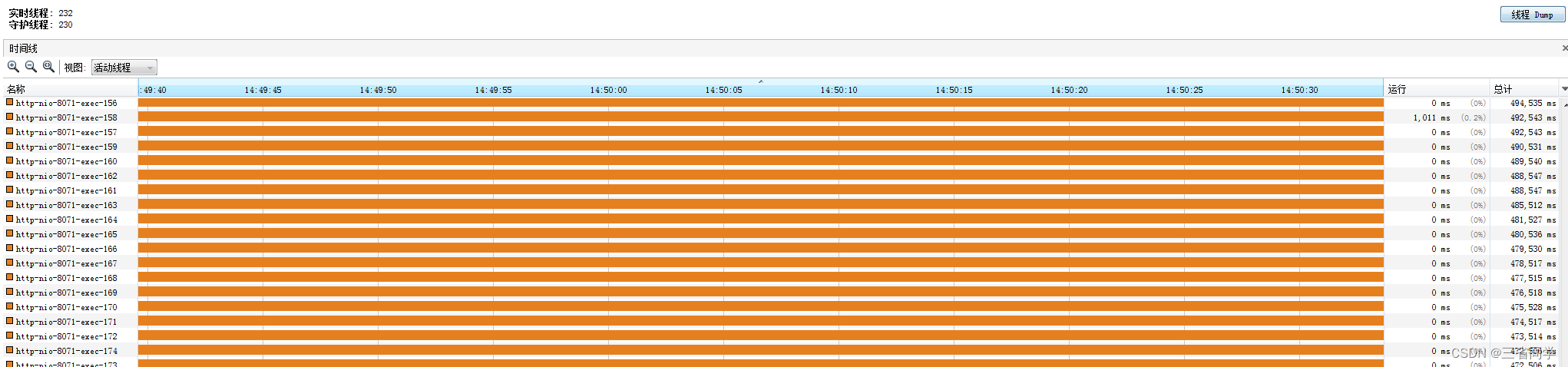
Parámetros predeterminados de Tomcat:
El número máximo de subprocesos de trabajo, el valor predeterminado es 200.
server.tomcat.max-threads=200
El número máximo de conexiones predeterminado es 10000
server.tomcat.max-connections=10000
Longitud de la cola de espera, el valor predeterminado es 100.
servidor.tomcat.accept-count=100Número mínimo de subprocesos inactivos en funcionamiento, predeterminado 10.
server.tomcat.min-repuesto-hilos=100
Los parámetros predeterminados del grupo de conexiones de Druid son los siguientes:
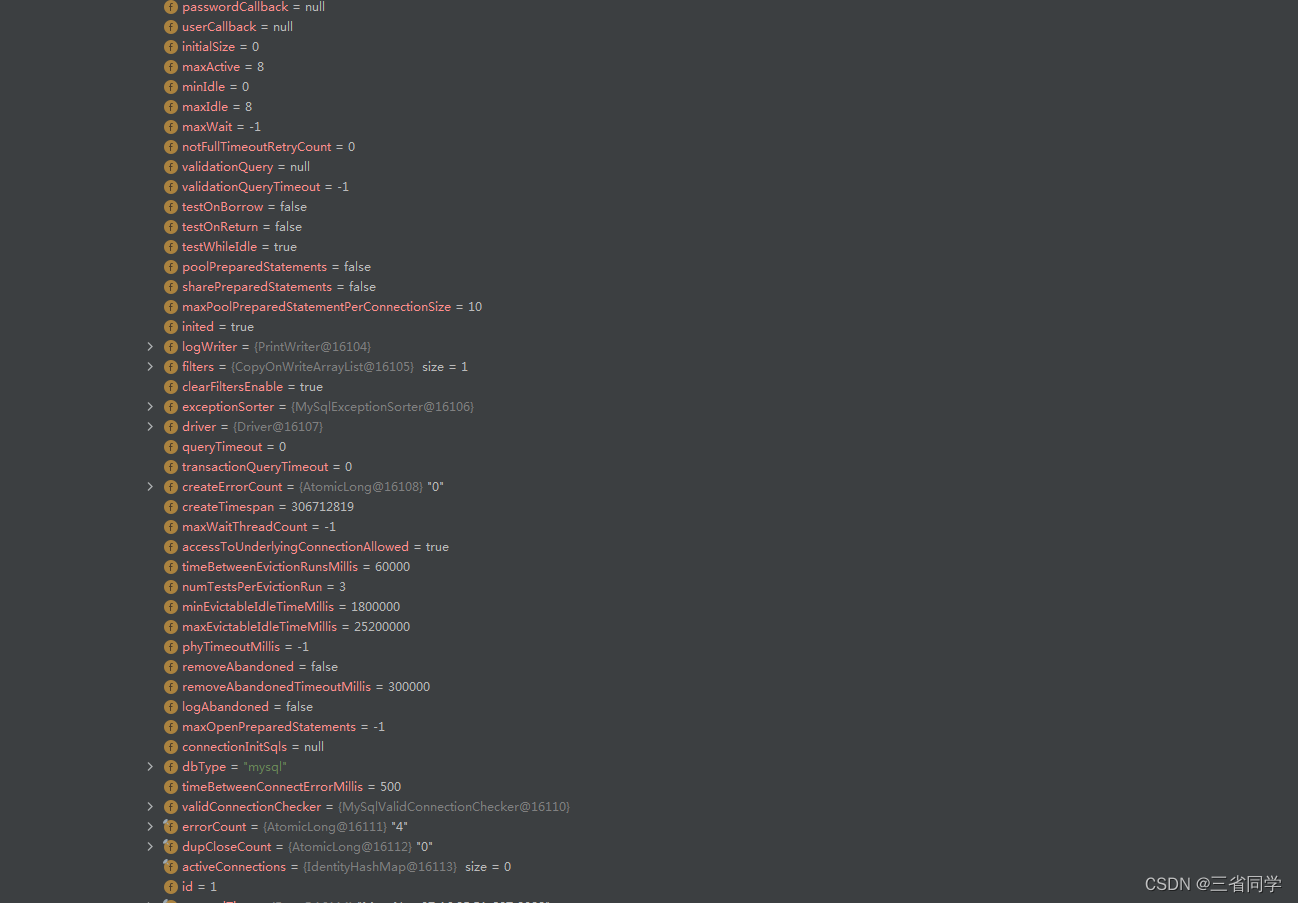
Los parámetros de configuración del grupo de conexiones de Druid son los siguientes:
| Atributos | ilustrar | valor sugerido |
|---|---|---|
| nombre de usuario | Nombre de usuario para iniciar sesión en la base de datos | |
| contraseña | Contraseña de usuario para iniciar sesión en la base de datos | |
| tamaño inicial | El valor predeterminado es 0, cuántas conexiones se inicializan en el grupo de conexiones al iniciar el programa | 10-50 es suficiente |
| maxActivo | El valor predeterminado es 8, el número máximo de sesiones activas admitidas en el grupo de conexiones | |
| espera máxima | Predeterminado -1, cuando el programa solicita una conexión del grupo de conexiones, si se excede el valor de maxWait, se considera que la solicitud ha fallado, es decir, no hay ninguna conexión disponible en el grupo de conexiones y la unidad es milisegundos. Cuando se establece -1, significa espera infinita | 100 |
| minEvictableIdleTimeMills | Después de que el tiempo de inactividad de una conexión en el grupo alcance N milisegundos, el grupo de conexiones reciclará la conexión cuando verifique la conexión inactiva la próxima vez, que debería ser menor que la configuración de tiempo de espera del firewall net.netfilter.nf_conntrack_tcp_timeout_establecido | Ver la descripción |
| timeBetweenEvictionRunsMillis | Frecuencia de verificación de conexiones inactivas, en milisegundos, entero no positivo significa que no se verifica | |
| mantener viva | Si el programa no tiene una conexión cercana y el tiempo de inactividad excede minEvictableIdleTimeMillis, se ejecutará el SQL especificado por validationQuery para garantizar que el grupo no elimine la conexión del programa, y su rango no exceda la cantidad de conexiones especificadas por minIdle | verdadero |
| mininactivo | El valor predeterminado es 8. Al reciclar conexiones inactivas, se garantizarán al menos conexiones minIdle. | Igual que tamaño inicial |
| eliminarAbandonado | Después de que el programa obtenga la conexión del grupo, debe cerrarse después de N segundos, de lo contrario, Druid reciclará la conexión a la fuerza, sin importar si la conexión está activa o inactiva, para evitar que el proceso ocupe la conexión sin cerrarse. | falso, se establece en verdadero cuando se encuentra que el programa no ha cerrado la conexión normalmente |
| eliminarAbandonedTimeout | Establezca el límite de tiempo para que el druida recicle la conexión a la fuerza. Cuando el programa pase del grupo a la conexión, después de que se exceda este valor, el druida reciclará a la fuerza la conexión, en segundos. | Debe ser mayor que el tiempo máximo de funcionamiento del negocio. |
| registroAbandonado | Cuando el druida recicla a la fuerza la conexión, ya sea para registrar el seguimiento de la pila en el registro | verdadero |
| prueba mientras está inactivo | Cuando un programa solicita una conexión, si el grupo primero verifica si la conexión es válida al asignar la conexión. (eficiente) | verdadero |
| consulta de validación | instrucción SQL para verificar si la conexión en el grupo todavía está disponible, drui se conectará a la base de datos para ejecutar el SQL, si regresa normalmente, significa que la conexión está disponible, de lo contrario significa que la conexión no está disponible | |
| testOnBorrow | 程序申请连接时,进行连接有效性检查(低效,影响性能) | false |
| testOnReturn | 程序返还连接时,进行连接有效性检查(低效,影响性能) | false |
| poolPreparedStatements | 缓存通过以下两个方法发起的SQL: public PreparedStatement prepareStatement(String sql) public PreparedStatement prepareStatement(String sql,int resultSetType, int resultSetConcurrency) | true |
| maxPoolPrepareStatementPerConnectionSize | 每个连接最多缓存多少个SQL | 20 |
| filters | 这里配置的是插件,常用的插件有:监控统计: filter:stat 日志监控: filter:log4j 或者 slf4j 防御SQL注入: filter:wall | stat,wall,slf4j |
| connectProperties | 连接属性。比如设置一些连接池统计方面的配置。 druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 比如设置一些数据库连接属性 |
解决
1、Druid连接池的配置超时参数
spring:
redis:
host: localhost
port: 6379
password:
datasource:
druid:
stat-view-servlet:
enabled: true
loginUsername: admin
loginPassword: 123456
dynamic:
druid:
initial-size: 10
min-idle: 5
maxActive: 100
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
filters: stat,slf4j,wall
connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000
2、异常及时关闭连接
发生异常,及时关闭连接
try {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
mapper.insetList(list);
sqlSession.flushStatements();
} catch (Exception e) {
e.printStackTrace();
sqlSession.close(); //异常及时关闭连接
}
SpringBoot假死检测与自愈
- 首先,配置 当SpringBoot发生oom时自动退出
- 其次,配置进行假死检测与自愈
当SpringBoot发生oom时自动退出
在使用springboot开发应用时遇到一个问题,当springboot发生内存溢出时,springboot并没有自动退出,因为当发生oom时springboot对oom异常进行了管理(oom异常也可以被try catch捕获)
解决方法:在启动jar包时加入命令行参数
XX:+CrashOnOutOfMemoryError
当发生内存溢出时jvm会自动退出,并且在当前程序目录下生成error文件日志,里面包括是哪个线程引起的oom,当前内存使用情况等。
配置进行假死检测与自愈
为了防止这个问题,临时采取定期检查该站点url的方式判断tomcat的运行情况。
写一个shell脚本:当取得到健康检查url状态码不是200时,强制重启SpringBoot。
#!/bin/bash
n=`curl -I -s |grep "200 OK" |wc -l`
if [ $n -ne 1 ]
then
source /etc/profile
/usr/local/app/bin/deploy.sh stop
/usr/local/app/bin/deploy.sh start
fi
用crond每隔一段时间执行一次上面的假死检测与自愈脚本。
最后的 一些成熟的建议
给出一些实战经验,让工作中更加从容:
- 调优参数务必加上
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=,发生OOM让JVM自动dump出内存,方便后续分析问题解决问题 - 堆内存不要设置的特别大,因为你设置的特别大,发生OOM时生成的dump文件就特别大,不好分析。建议不超过8G。
- 想主动dump出JVM的内存,有挺多方式,但不管哪种方式,主动dump内存会引发STW,请择时操作。即通过arthas提供的命令heapdump主动dump出JVM的内存,这个操作会引发FGC,背后是STW,操作时请选择好时机,不然老板可能提刀来见。
- 我提供的代码务必拉下来跑跑,找下感觉。最好是自己也去写一份与我提供的不同的,加深理解,加深印象。
JVM相关的启动参数
-XX:+HeapDumpOnOutOfMemoryError
从字面就可以很容易的理解,在发生OutOfMemoryError异常时,进行堆的Dump,这样就可以获取异常时的内存快照了。
-XX:HeapDumpPath=/usr/local/heap-dump/
这个也很好理解,就是配置HeapDump的路径,
方便我们管理,这里我们配置为/usr/local/heap-dump/,当然你也可以根据自己的需要,定义为其他的目录。
参考文献:
https://www.cnblogs.com/etangyushan/p/6909437.html
https://blog.csdn.net/longxy520/article/details/84752660
https://blog.csdn.net/nmyphp/article/details/115544822
https://blog.csdn.net/web15285868498/article/details/124347503
https://blog.csdn.net/u011983531/article/details/63250882
https://www.iteye.com/blog/bijian1013-2271600
https://zhuanlan.zhihu.com/p/269892810
https://blog.csdn.net/qq_35764295/article/details/127753003
《Java 调优圣经》迭代计划
尼恩团队的所有文章和PDF电子书,都是 持续迭代的模式, 最新版本永远是最全的。
尼恩团队结合资深架构经验和行业案例,给大家梳理一个系列的**《Java 调优圣经》PDF** 电子书,包括本文在内规划的五个部分:
(1) 调优圣经1:零基础精通Jmeter分布式压测,10Wqps+压测实操 (已经完成)
(2) 调优圣经2:从70s到20ms,一次3500倍性能优化实战,方案人人可用 (已经完成)
(3) 调优圣经3:如何做mysql调优?绝命7招让慢SQL调优100倍,实现你的Mysql调优自由 (已经完成)
(4) 调优圣经4:SpringBoot假死,十万火急,怎么救火? (本文)
(5) 调优圣经5:零基础精通JVM调优实操,实现JVM自由 (写作中)
(6) 调优圣经6:零基础精通Linux、Tomcatl调优实操,实现基础设施调优自由 (写作中)
以上的多篇文章,后续将陆续在 技术自由圈 公众号发布。 完整的《Java 调优圣经》PDF,可以找尼恩获取。
技术自由的实现路径 PDF:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
" Enciclopedia de comandos de Linux: 2W más palabras, una vez para lograr la libertad de Linux "
Realice su libertad en línea:
" Explicación detallada del protocolo TCP (el más completo de la historia) "
Realice su libertad de bloqueo distribuido:
" Redis Distributed Lock (Ilustración - Segundo Entendimiento - El Más Completo de la Historia) "
" Bloqueo distribuido de Zookeeper - Diagrama - Segundo entendimiento "
Realice su libertad componente rey:
" Rey de la cola: principios disruptivos, arquitectura y penetración del código fuente "
" El rey del caché: el uso de la cafeína (el más completo de la historia) "
" Java Agent probe, bytecode mejorado ByteBuddy (el más completo de la historia) "
Realice las preguntas de su entrevista libremente:
4000 páginas de "Nin's Java Interview Collection" 40 temas
Vaya a la siguiente cuenta oficial de "Technical Freedom Circle" para obtener la actualización del archivo PDF de las notas de arquitectura de Nien y las preguntas de la entrevista↓↓↓