
¿Cómo romper el cuello de botella de la inteligencia artificial (IA) contemporánea? Diferentes eruditos tienen diferentes puntos de vista.
En términos generales, se puede resumir en dos categorías: una son los estudiantes supervisados, que abogan por mejorar el aprendizaje supervisado mejorando la calidad de las etiquetas de datos. Los representantes incluyen a Wu Enda, quien inició la revolución de la "IA centrada en datos", y Rev Lebaredian, quien abogó por el diseño de "datos sintéticos con todas las etiquetas".
En segundo lugar, los académicos no supervisados, como Yann LeCun, defienden que la próxima generación de sistemas de IA ya no dependerá de conjuntos de datos cuidadosamente etiquetados.
Recientemente, Yann LeCun explicó en profundidad sus ideas de aprendizaje autosupervisado en el blog oficial de meta AI (anteriormente Facebook) y en una entrevista con IEEE. Él cree que si AI quiere romper el cuello de botella actual, debe dejar que la máquina aprenda. el modelo mundial para llenar los vacíos. información, predecir lo que sucederá y predecir el impacto de las acciones.

No fue una idea revolucionaria, pero fue un acto revolucionario. Como mencionó LeCun en muchos discursos: Esta revolución no será supervisada (LA REVOLUCIÓN NO SERÁ SUPERVISADA). En concreto, esta revolución se refleja en el pensamiento de dos cuestiones:
Primero, ¿qué paradigma de aprendizaje deberíamos usar para entrenar el modelo mundial?
En segundo lugar, ¿qué arquitectura debería usar el modelo mundial?
Al mismo tiempo, también mencionó que las limitaciones del aprendizaje supervisado a veces se confunden con las limitaciones del aprendizaje profundo, y estas limitaciones pueden superarse mediante el aprendizaje autosupervisado.
El siguiente es el pensamiento de LeCun sobre la autosupervisión y el diseño del modelo mundial. El contenido proviene de meta AI e IEEE. AI Technology Review se ha compilado sin cambiar el significado original.
La IA puede aprender modelos del mundo
LeCun mencionó que los humanos y los animales pueden aprender el conocimiento del mundo a través de la observación, la interacción simple y sin supervisión, por lo que se puede suponer que las habilidades potenciales contenidas en esto forman la base del sentido común. Este sentido común permite a los humanos completar tareas en entornos desconocidos, como un conductor joven que nunca ha conducido un automóvil en la nieve, pero sabe que si el automóvil se conduce con demasiada fuerza, las llantas patinarán.
Ya hace décadas, algunos académicos estudiaron cómo los humanos, los animales e incluso los sistemas inteligentes "aprovechan" el modelo mundial para aprender por sí mismos. Por lo tanto, la IA actual también se enfrenta a un rediseño de los paradigmas y arquitecturas de aprendizaje, lo que permite que las máquinas aprendan modelos del mundo de forma autosupervisada y luego utilicen estos modelos para la predicción, el razonamiento y la planificación.
Los modelos mundiales deben incorporar perspectivas de diferentes disciplinas, incluidas, entre otras, la ciencia cognitiva, la neurociencia de sistemas, el control óptimo, el aprendizaje por refuerzo y la inteligencia artificial "tradicional". Deben combinarse con nuevos conceptos en el aprendizaje automático, como el aprendizaje autosupervisado y las arquitecturas de integración conjunta.
Nueva arquitectura de IA: arquitectura de inteligencia autónoma
Sobre la base de la idea del modelo mundial mencionada anteriormente, LeCun propone una agencia inteligente autónoma, que consta de seis módulos independientes, y asume que cada uno es diferenciable: algunas funciones objetivas se pueden calcular fácilmente, y las estimaciones de gradiente correspondientes, y el gradiente información propagada a los módulos aguas arriba.
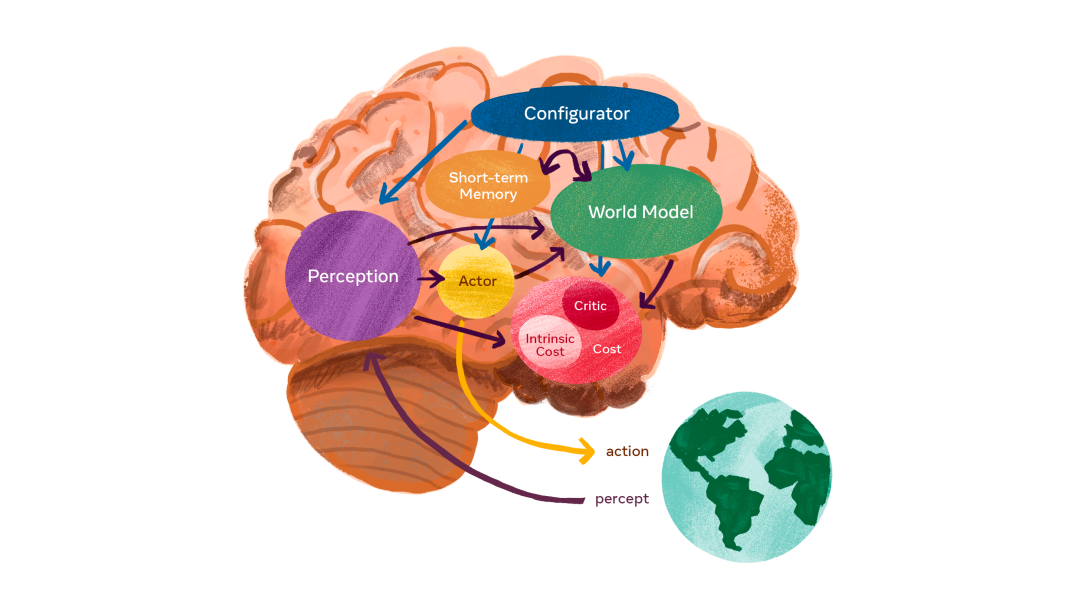
Arquitectura del sistema autónomo e inteligente: el configurador es el núcleo y recibe información de otros módulos.
-
El papel del configurador es el control. Dada una tarea a realizar, preconfigura módulos de percepción, modelos mundiales ajustando parámetros, calcula costos y agrega actores.
-
El módulo de percepción es capaz de recibir información y estimar el mundo real. Para una tarea específica, solo una pequeña fracción del estado del mundo percibido es relevante y útil. El configurador alimenta el módulo de percepción, que extrae información relevante para la tarea de la percepción.
-
El módulo del modelo mundial es la parte más compleja y cumple una doble función. 1. Estimar la información faltante que el módulo de percepción no puede obtener 2. Predecir razonablemente el estado futuro del mundo, incluida la evolución natural del mundo y el impacto de las acciones de los participantes. Un modelo mundial es un simulador del mundo real, y dado que el mundo está lleno de incertidumbres, el modelo debe poder manejar múltiples predicciones posibles. Ejemplo intuitivo: un conductor que se acerca a una intersección puede reducir la velocidad de su automóvil para evitar que otro vehículo que se acerque a la intersección no se detenga en una señal de alto.
-
El módulo de costes se utiliza para calcular la inadecuación del agente previsto. Consta de dos partes: costo intrínseco, que no es entrenable, pero puede calcular la "incomodidad" en tiempo real: daño del agente, violación del comportamiento codificado, etc.; crítico, que es un módulo entrenable que predice el valor futuro de el costo intrínseco.
LeCun dijo: El módulo de costos es donde se encuentran los impulsores de comportamiento básicos y las motivaciones intrínsecas. Así, se tendrá en cuenta el coste intrínseco: no derrochar energía, y el consumo específico de la tarea. El módulo de costos es separable y el gradiente del costo se puede propagar hacia atrás a través de otros módulos para la planificación, el razonamiento o el aprendizaje.
-
El módulo del participante proporciona recomendaciones para la acción. El módulo actor puede encontrar una secuencia óptima de acciones que minimice el costo futuro estimado y generar la primera acción en la secuencia óptima, de manera similar al control óptimo clásico.
-
El módulo de memoria a corto plazo puede registrar la situación actual, predecir el estado del mundo y el costo asociado.
Arquitectura modelo mundial y entrenamiento autosupervisado
En el corazón de la arquitectura del modelo mundial está la predicción.
Un desafío clave en la construcción de un modelo mundial es cómo hacer que el modelo represente múltiples predicciones ambiguas. El mundo real no es del todo predecible: una situación dada puede evolucionar de muchas maneras, y muchos detalles relevantes para la situación son irrelevantes para la tarea en cuestión. Por ejemplo, es posible que necesite predecir lo que harán los automóviles a mi alrededor mientras conduzco, pero no necesito predecir la posición detallada de las hojas individuales en los árboles cerca de la carretera. Entonces, ¿cómo aprende el modelo mundial una representación abstracta del mundo real, retiene detalles importantes, ignora detalles irrelevantes y hace predicciones en el espacio de representaciones abstractas?
Un elemento clave de la solución es la arquitectura predictiva de integración conjunta (JEPA). JEPA captura las dependencias entre dos entradas (x e y). Por ejemplo, x podría ser un video e y podría ser el próximo video. Las entradas x e y se alimentan a codificadores entrenables que extraen sus representaciones abstractas, a saber, sx y sy. El módulo predictor está capacitado para predecir sy a partir de sx. Un predictor puede usar la variable latente z para representar información que está presente en sy pero no en sx. JEPA trata la incertidumbre en las predicciones de dos maneras: (1) el codificador puede optar por descartar información difícil de predecir sobre y; (2) cuando la variable latente z varía en un conjunto, causará un conjunto de predicciones plausibles en cambiar.
Entonces, ¿cómo entrenamos JEPA?
Hasta ahora, el único método que han utilizado los investigadores es el "contraste", que consiste en mostrar ejemplos de x e y compatibles, y muchos ejemplos de x e y incompatibles. Pero esto es poco práctico cuando la representación es un estado de alta dimensión.
Otra estrategia de formación ha surgido en los últimos dos años: los métodos de regularización. Cuando se aplica a la formación JEPA, el método utiliza cuatro criterios:
-
hacer que la representación de x sea lo más informativa posible sobre x
-
hacer que la representación de y sea lo más informativa posible sobre y
-
hacer que la representación de y sea máximamente predecible a partir de la representación de x
-
Hacer que el predictor use la menor cantidad posible de información variable latente para representar la incertidumbre en el pronóstico
Estos criterios se pueden transformar en funciones de costos diferenciables de varias maneras. Un método es el método VICReg, a saber, varianza/variable (Varianza), invarianza (Invarianza), regularización de covarianza (Regularización de covarianza). En VICReg, el contenido de información representado por x e y se maximiza manteniendo la varianza de sus componentes por encima de un umbral y haciendo que estos componentes sean lo más independientes posible entre sí. Al mismo tiempo, el modelo intenta hacer predecible la representación de y a partir de la representación de x. Además, el contenido de información de las variables latentes se minimiza haciéndolas discretas, de baja dimensión, escasas o ruidosas.

La belleza de JEPA es que produce naturalmente una representación abstracta de la información de entrada, elimina detalles irrelevantes y puede realizar predicciones. Esto permite que los JEPA se apilen uno encima del otro para aprender representaciones con un mayor nivel de abstracción, lo que permite predicciones a largo plazo.
Por ejemplo, una escena podría describirse a un alto nivel como "el chef está haciendo crepes". Predice que el cocinero traerá la harina, la leche y los huevos, mezclará los ingredientes, echará la masa en la sartén, freirá la masa, dará la vuelta a la crepe y repetirá el proceso una y otra vez. En un nivel más bajo de expresión, la escena podría ser verter una cucharada de masa y batirla uniformemente y extenderla alrededor de la sartén. La trayectoria precisa de la mano del chef que dura cada milisegundo. En trayectorias manuales de bajo nivel, nuestro modelo mundial solo puede hacer predicciones precisas a corto plazo. Pero a un nivel más alto de abstracción, puede hacer predicciones a largo plazo.
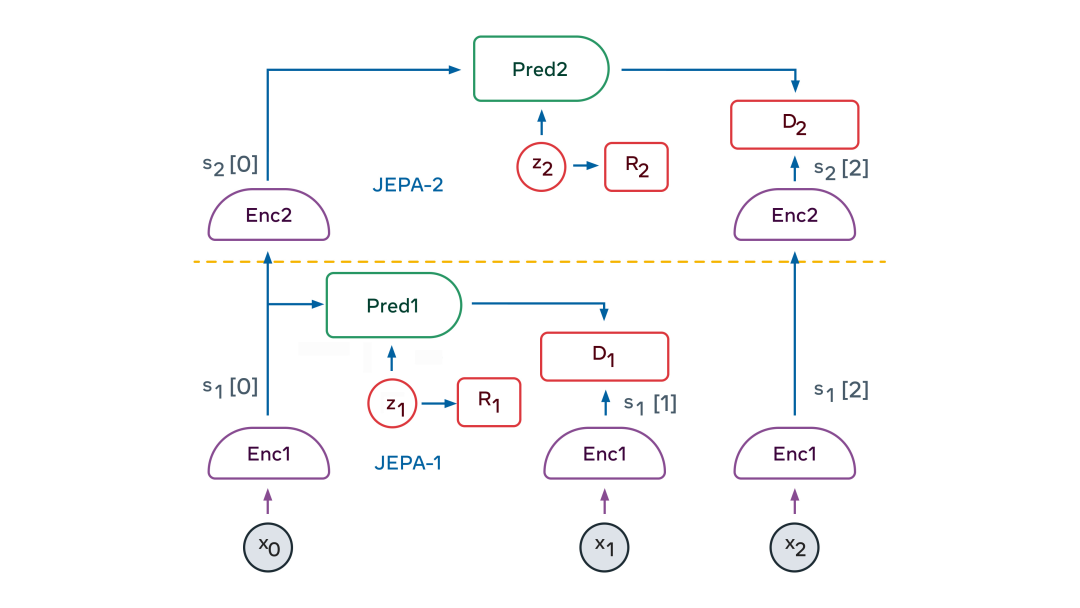
JEPA jerárquico se puede utilizar para realizar predicciones en múltiples niveles de abstracción y en múltiples escalas de tiempo. El método de entrenamiento es principalmente a través de la observación pasiva y rara vez a través de la interacción.
En los primeros meses de vida, los bebés aprenden cómo funciona el mundo principalmente mediante la observación. Aprendió que el mundo es tridimensional, que algunos objetos se colocarán frente a otros y que cuando un objeto se ocluye, todavía existe. Eventualmente, alrededor de los 9 meses de edad, los bebés aprenden física intuitiva, por ejemplo, que los objetos sin soporte caen debido a la gravedad.
La visión de JEPA en capas es que puede aprender cómo funciona el mundo viendo videos e interactuando con el medio ambiente. Al entrenarse para predecir lo que sucederá en un video, puede generar una representación jerárquica del mundo. Al tomar acciones en el mundo y observar los resultados, el modelo del mundo aprenderá a predecir las consecuencias de sus acciones y, por lo tanto, podrá razonar y planificar.
Trama "Sentido-Acto"
Al entrenar JEPA jerárquica como un modelo mundial, un agente (robot) puede realizar una planificación jerárquica de acciones complejas, descomponiendo tareas complejas en una serie de subtareas menos complejas y menos abstractas, hasta el efector (efector) acciones de bajo nivel.
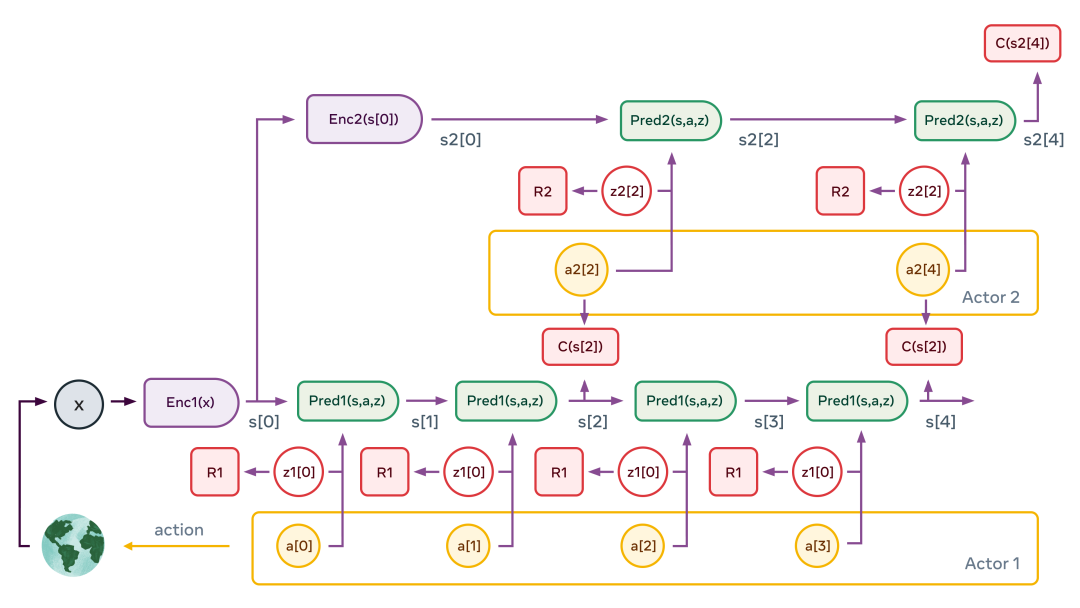
Un gráfico típico de percepción-acción es el anterior. La figura ilustra el caso de una jerarquía de dos niveles. El módulo de percepción extrae una representación jerárquica del estado mundial (s1[0]=Enc1(x) y s2[0]=Enc2(s[0]) en la figura). Luego, el predictor secundario se aplica varias veces para predecir el estado futuro dada la secuencia de acciones abstractas propuestas por el actor secundario. El actor optimiza la secuencia de acción secundaria para minimizar el costo total (C(s2[4]) en la figura).
Este proceso es similar al modelo de control predictivo en control óptimo. Repita el proceso para varias gráficas de variables latentes de segundo nivel, que pueden generar diferentes escenarios de alto nivel. Las acciones de alto nivel resultantes no constituyen acciones reales, sino que simplemente definen restricciones que la secuencia de estados de bajo nivel debe satisfacer (por ejemplo, ¿los ingredientes están mezclados correctamente?). Forman subobjetivos. Todo el proceso se repite en las capas inferiores: ejecute los predictores de la capa inferior, optimice las secuencias de acción de la capa inferior para minimizar el costo intermedio de la capa superior y repita el proceso para múltiples gráficos de las variables latentes de la capa inferior. Una vez que se completa el proceso, el agente envía la primera acción de bajo nivel al efector y se puede repetir todo el episodio.
Si logramos construir un modelo de este tipo, entonces todos los módulos son diferenciables, por lo que todo el proceso de optimización de movimiento se puede realizar utilizando métodos basados en gradientes.
Acercando la IA a la inteligencia a nivel humano
La visión de LeCun necesita ser explorada más profundamente y hay muchos desafíos abrumadores por delante. Uno de los desafíos más interesantes y difíciles fue instanciar la arquitectura y los detalles de entrenamiento para el modelo mundial. Incluso podríamos decir que entrenar un modelo del mundo es el principal reto sobre el que la inteligencia artificial realmente puede avanzar en las próximas décadas.
Pero quedan muchos otros aspectos de la arquitectura por definir, incluido cómo entrenar exactamente a un crítico (el papel de una red de críticos es medir qué tan bueno es un actor en un estado determinado), cómo construir y entrenar un configurador y cómo usar la memoria a corto plazo para realizar un seguimiento del estado del mundo y almacenar la historia del estado y las acciones del mundo, y usar el costo intrínseco para ajustar la crítica.
LeCun y otros investigadores de Meta AI esperan explorarlos en los próximos meses y años, intercambiando ideas y aprendizajes con otros en el campo. Crear máquinas que puedan aprender y comprender tan eficientemente como los humanos es un esfuerzo científico a largo plazo, y el éxito no está garantizado. Pero creemos que la investigación fundamental continuará profundizando nuestra comprensión de las mentes y las máquinas, y conducirá a muchos más avances en IA que beneficiarán a la humanidad.
Yann LeCun: la IA no necesita supervisión humana
IEEE Spectrum: Ha dicho que las limitaciones del aprendizaje supervisado a veces se confunden con las limitaciones intrínsecas del aprendizaje profundo, entonces, ¿qué limitaciones se pueden superar con el aprendizaje autosupervisado?
Yann LeCun : El aprendizaje supervisado funciona bien en algunos campos estructuralmente estables. En estos dominios, puede recopilar una gran cantidad de datos etiquetados y puede ver durante la implementación que estos tipos de entradas no son muy diferentes de los tipos de entradas utilizadas durante el entrenamiento. Es difícil recopilar grandes cantidades de datos etiquetados que sean relativamente imparciales. No estoy hablando necesariamente de sesgo social, estoy diciendo que el sistema no debería usar las correlaciones en los datos. Un ejemplo muy famoso es cuando estás entrenando un sistema que reconoce vacas, y estás entrenando con vacas en el pasto, el sistema usará el pasto como fondo para las vacas. Dada otra vaca en la playa, podría ser más difícil de detectar.
El aprendizaje autosupervisado (SSL) nos permite entrenar sistemas para aprender buenas representaciones de entrada de manera independiente de la tarea. Debido a que el entrenamiento SSL usa datos sin etiquetar, podemos usar conjuntos de entrenamiento muy grandes y dejar que el sistema aprenda representaciones más sólidas y completas de las entradas. Luego, requiere solo una pequeña cantidad de datos etiquetados para lograr un buen desempeño en las tareas supervisadas. Esto reduce en gran medida la cantidad de datos etiquetados típicos del aprendizaje puramente supervisado y hace que el sistema sea más resistente a las entradas que difieren de las muestras de entrenamiento etiquetadas. A veces, también reduce la sensibilidad del sistema al sesgo de datos, una mejora de la que compartiremos más información de la investigación en las próximas semanas.
Lo que está sucediendo ahora en los sistemas de IA reales es que nos estamos moviendo a arquitecturas más grandes que usan SSL para entrenar previamente en grandes cantidades de datos sin etiquetar. Estos pueden ser utilizados para diversas tareas. Por ejemplo, Meta AI ahora tiene un sistema de traducción de idiomas que puede manejar cientos de idiomas. ¡Esa es una sola red neuronal! También disponemos de un sistema de reconocimiento de voz multilingüe. Estos sistemas pueden manejar idiomas con pocos datos, y mucho menos datos anotados.
Espectro IEEE: Otros pioneros de la industria dicen que el camino a seguir para la IA es mejorar el aprendizaje supervisado a través de un mejor etiquetado de datos. Andrew Ng me habló recientemente sobre IA centrada en datos , y Rev Lebaredian de NVIDIA me habló sobre datos sintéticos con todas las etiquetas. ¿Hay desacuerdos en el campo sobre el camino a seguir?
LeCun : No creo que haya una división filosófica. El pre-entrenamiento SSL es una práctica bastante estándar en PNL. Mostró grandes mejoras de rendimiento en el reconocimiento de voz y comenzó a ser cada vez más útil para la visión. Sin embargo, todavía hay muchas aplicaciones sin explotar del aprendizaje supervisado "clásico", por lo que, por supuesto, se deben usar datos sintéticos y aprendizaje supervisado siempre que sea posible. También se dice que Nvidia está desarrollando activamente SSL.
A mediados de la década de 2000, Geoff Hinton, Yoshua Bengio y yo estábamos convencidos de que la única forma en que podíamos entrenar redes neuronales muy grandes y profundas era a través del aprendizaje autosupervisado (o no supervisado). También fue entonces cuando Andrew Ng se interesó en el aprendizaje profundo. Su trabajo en ese momento también se centró en lo que ahora llamamos autosupervisión.
IEEE Spectrum: ¿Cómo conduce el aprendizaje autosupervisado a sistemas de IA de sentido común? ¿Hasta dónde puede el sentido común llevar los sistemas de IA a la inteligencia a nivel humano?
LeCun : Creo que la IA hará grandes avances una vez que descubramos cómo hacer que las máquinas aprendan cómo funciona el mundo de la manera en que lo hacen los humanos y los animales: principalmente observando y actuando en base a esa observación. Entendemos cómo funciona el mundo porque hemos aprendido un modelo interno del mundo que nos permite completar la información que falta, predecir lo que sucederá y predecir el impacto de nuestras acciones. Nuestros modelos del mundo nos permiten percibir, interpretar, razonar, planificar y actuar.
Pero, ¿cómo aprende una máquina un modelo del mundo? Esto se reduce a dos preguntas: ¿qué paradigma de aprendizaje debemos usar para entrenar el modelo mundial? ¿Qué arquitectura debería usar el modelo mundial?
Para la primera pregunta, mi respuesta es SSL (aprendizaje autosupervisado). Un ejemplo sería hacer que una máquina vea un video, pause el video y luego haga que la máquina aprenda una representación de lo que sucederá a continuación en el video. Al hacerlo, las máquinas pueden aprender una gran cantidad de conocimientos previos sobre cómo funciona el mundo, quizás de manera similar a cómo aprenden los bebés y los animales durante las primeras semanas y meses de vida.
Para la segunda pregunta, mi respuesta es un nuevo tipo de macroarquitectura profunda, a la que llamo Arquitectura de predicción de incrustación conjunta jerárquica (H-JEPA). Explicado brevemente, en lugar de predecir fotogramas futuros de un videoclip, JEPA aprende una representación abstracta del videoclip y el futuro del clip para que este último pueda predecirse fácilmente en función de la comprensión del primero. Esto se puede lograr utilizando algunos desarrollos recientes en métodos SSL sin contraste, en particular uno propuesto recientemente por mis colegas y por mí llamado "VICReg".
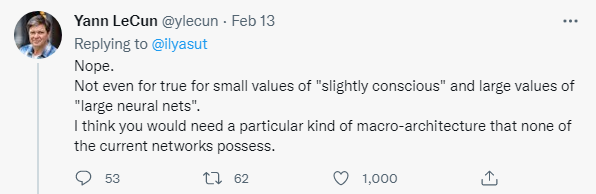
IEEE Spectrum: Hace unas semanas, usted respondió a un tuit de Ilya Sutskever de OpenAI en el que especulaba que las grandes redes neuronales actuales podrían ser conscientes. Su respuesta es un rotundo "no". En tu opinión, ¿qué se necesita para construir una red neuronal consciente? ¿Cómo sería ese sistema?
LeCun : En primer lugar, la conciencia es un concepto muy vago. Algunos filósofos, neurocientíficos y científicos cognitivos piensan que es solo una ilusión, y yo estoy bastante cerca de eso.
Pero tengo una conjetura sobre qué causa la ilusión de la conciencia. Mi hipótesis es que tenemos un único "motor" modelo mundial en nuestra corteza prefrontal. El modelo mundial se puede configurar de acuerdo con la situación actual. Somos el timonel del velero, nuestro modelo mundial simula las corrientes de aire y agua alrededor de nuestro barco. Construimos una mesa de madera; nuestro modelo del mundo imaginaba los resultados de cortar madera y ensamblarla, y así sucesivamente.
Necesitamos un módulo en nuestro cerebro, al que llamo un "configurador", que nos establece metas y submetas, configura nuestro modelo mundial para simular la situación actual y activa nuestro sistema de percepción para extraer información relevante y descartar la información sobrante. . La existencia de un configurador supervisor puede ser responsable de nuestra ilusión de conciencia. Pero aquí está lo gracioso: necesitamos este configurador porque solo tenemos un motor de modelo mundial. Si nuestros cerebros fueran lo suficientemente grandes como para acomodar muchos modelos del mundo, no necesitaríamos la conciencia. Entonces, en este sentido, ¡la conciencia es el resultado de las limitaciones de nuestro cerebro!
IEEE Spectrum: ¿Qué papel puede jugar el aprendizaje autosupervisado en la construcción del Metaverso?
LeCun : El aprendizaje profundo tiene muchas aplicaciones específicas en el mundo virtual, como el seguimiento de movimiento para gafas VR y gafas AR, captura y resintetización de movimientos corporales y expresiones faciales, y más.
Hay muchas oportunidades para nuevas herramientas creativas impulsadas por IA en el metaverso, lo que permite a todos crear cosas nuevas en mundos virtuales y reales. Pero Metaverse también tiene una aplicación de "IA pura": asistentes virtuales de IA. Deberíamos tener asistentes virtuales de IA que puedan ayudarnos en nuestra vida diaria, responder cualquier pregunta que tengamos y ayudarnos a lidiar con la avalancha de información que nos bombardea todos los días. Para hacer esto, necesitamos que nuestros sistemas de IA tengan cierta comprensión de cómo funciona el mundo (ya sea físico o virtual), cierta capacidad de razonar y planificar, y cierto nivel de sentido común. En resumen, debemos descubrir cómo construir sistemas de IA autónomos que puedan aprender como los humanos. Toma tiempo. Pero Meta lleva mucho tiempo en este camino.
Link de referencia:
1.https://ai.facebook.com/blog/yann-lecun-advances-in-ai-research
2.https://spectrum.ieee.org/yann-lecun-ai
El editor ha recopilado información sobre inteligencia artificial, incluidas bibliotecas de recursos como procesamiento de imágenes opencv\procesamiento de lenguaje natural, fundamentos matemáticos de aprendizaje automático, libros electrónicos de lectura obligatoria y colecciones de artículos. Estudiantes universitarios que desean aprender inteligencia artificial o cambiar a Las industrias que pagan bien también están muy interesadas. Práctico, gratuito sin ninguna rutina,
Agregue mi falda [ 966367816 ] para descargar, o escanee el código + vx para recibir recursos internos, banco de preguntas de inteligencia artificial, esquema de estudio de preguntas de entrevista de Dachang, esquema de curso de autoaprendizaje y juerga de datos de inteligencia artificial de 500G gratis ~
