Resumen
La detección de obstáculos es clave para una conducción autónoma segura y eficiente. Para ello, proponemos NVRadarNet, una red neuronal profunda (DNN) para detectar obstáculos dinámicos y espacios libres utilizando sensores de radar automotriz. La red aprovecha los datos acumulados en el tiempo de múltiples sensores de radar para detectar obstáculos dinámicos y calcular su orientación en una Vista de pájaro (BEV) de arriba hacia abajo. La red también retrocede el espacio libre manejable para detectar obstáculos no clasificados. Nuestro DNN es el primero de su tipo en explotar señales de radar escasas, realizando detección de obstáculos y espacio libre en tiempo real solo a partir de datos de radar. La red se ha aplicado con éxito a la percepción de vehículos autónomos en escenarios reales de conducción autónoma. La red se ejecuta más rápido que en tiempo real en una GPU integrada y muestra una buena generalización en todas las regiones geográficas.
1. Introducción
La capacidad de detectar obstáculos dinámicos y estacionarios (por ejemplo, automóviles, camiones, peatones, bicicletas, peligros) es fundamental para los vehículos autónomos. Esto es especialmente importante en entornos semiurbanos y urbanos con mucha oclusión y escenas complejas de varias formas.
Los métodos de percepción anteriores se basan en gran medida en la utilización de cámaras [1][2][3] o LiDAR [4][5][6][7] para detectar obstáculos. Estos métodos tienen algunas desventajas: no son confiables en oclusiones severas, los sensores pueden ser muy costosos, no son confiables en condiciones climáticas adversas [8] o de noche. Los métodos tradicionales de detección de obstáculos basados en radar funcionan bien cuando detectan objetos en movimiento con buenas propiedades reflectantes, pero a menudo tienen dificultades para estimar el tamaño y la orientación del objeto, y suelen fallar por completo cuando detectan objetos estacionarios u objetos con poca reflectividad de radar.
En este artículo, proponemos una red neuronal profunda (DNN) que puede detectar obstáculos móviles y estacionarios, calcular su orientación y tamaño, y detectar espacios libres transitables a partir de datos de radar. Empleamos una vista de pájaro de arriba hacia abajo (BEV) en carreteras y escenas urbanas, mientras usamos radares automotrices estándar. Nuestro enfoque se basa únicamente en la detección de picos de radar [9][10], ya que el firmware del radar automotriz solo proporciona estos datos. Por el contrario, otros métodos [11][12] requieren costosas operaciones de transformada rápida de Fourier en las secciones transversales del cubo de datos de radar sin procesar, que no están disponibles en la mayoría de los sensores automotrices comerciales.
Nuestro método de aprendizaje profundo puede distinguir con precisión entre obstáculos estacionarios (como automóviles) y ruido de fondo estacionario. Esto es importante cuando te desplazas por un entorno urbano abarrotado. Además, nuestro método nos permite hacer una regresión de las dimensiones y orientaciones de estos obstáculos, que los métodos clásicos no pueden proporcionar. Nuestro DNN puede incluso detectar obstáculos con baja reflectividad como peatones. Finalmente, nuestro método proporciona un mapa de probabilidad de ocupación para etiquetar obstáculos no clasificados y retroceder espacios libres transitables.
Hemos probado nuestro NVRadarNet DNN en vehículos que ejecutan GPU integradas NVIDIA DRIVE AGX. Nuestro DNN se ejecuta más rápido que en tiempo real a 1,5 ms de extremo a extremo y le da al planificador tiempo suficiente para reaccionar de manera segura.
Nuestras contribuciones son las siguientes:
• NVRadarNet: la primera red neuronal profunda multinivel que puede detectar objetos estacionarios y en movimiento de extremo a extremo sin procesamiento posterior en una vista de pájaro (BEV) de arriba hacia abajo, utilizando solo detecciones máximas de radares automotrices;
• Un método novedoso de detección de espacio libre de conducción semisupervisada que utiliza únicamente la detección de picos de radar;
• Arquitectura DNN que se ejecuta 1,5 ms más rápido que en tiempo real de un extremo a otro en una GPU integrada.
2. Trabajo previo
Detección de obstáculos . La percepción de obstáculos rápida y eficiente es un componente central de los vehículos autónomos. Los sensores de radar automotrices proporcionan una forma rentable de obtener información rica en posición y velocidad en 3D y se usan ampliamente en la mayoría de los vehículos modernos. Varios artículos recientes han investigado el uso de conjuntos de datos de radar densos para realizar la detección de obstáculos [11][12]. Sin embargo, estos métodos requieren un alto ancho de banda de entrada/salida para adquirir datos tan ricos. Esto los hace inadecuados para autos verdaderamente autónomos. Por lo tanto, en las aplicaciones de radar automotriz, la mayoría de los enfoques clásicos utilizan la detección de picos de posprocesamiento del cubo de datos para realizar la clasificación y la detección de cuadrícula de ocupación [13][14][15]. Otros se dieron cuenta de que la detección de picos de radar se puede ver como una nube de puntos 3D escasa y, por lo tanto, se puede usar para la fusión de sensores con puntos LiDAR 3D en un enfoque similar a los DNN LiDAR [4][16][17][5][18 ]. Hay intentos de mejorar la detección de obstáculos 3D de la cámara fusionando el radar, como [19].
Detección de espacio libre . [20] y [21] intentaron una estimación del espacio libre manejable basada en radar.
Nuestro DNN realiza una detección multiclase de obstáculos dinámicos y estáticos y segmenta el espacio libre transitable utilizando solo la detección de picos de radar. Nuestra arquitectura DNN es liviana y se ejecuta de extremo a extremo más rápido que en tiempo real en 1,5 ms en una GPU integrada (NVIDIA DRIVE AGX). Ha demostrado su solidez en la conducción en el mundo real y se ha probado en más de 10 000 kilómetros de carreteras y caminos urbanos como parte de nuestra pila autónoma. Hasta el momento, no tenemos conocimiento de ninguna detección de picos de radar solo DNN que pueda realizar todas estas tareas y operar de manera eficiente en vehículos autónomos.
3. Método
A : generación de entrada
La entrada a nuestra red es una proyección ortográfica BEV de arriba hacia abajo de los picos de detección de radar acumulados alrededor de nuestro vehículo ego, que se coloca en el centro de esta vista de pájaro (BEV) de arriba hacia abajo, mirando hacia la derecha.
Para calcular esta entrada, primero acumulamos detecciones de picos de radar de todos los sensores de radar en el vehículo (8 radares que cubren un campo de visión de 360 grados) y luego las transformamos en nuestro sistema de coordenadas de la plataforma del vehículo ego. Para aumentar la densidad de la señal, también acumulamos estos tiempos máximos de detección por encima de 0,5 s. Cada punto de datos tiene una marca de tiempo relativa para indicar su edad, similar a [16]. A continuación, realizamos una compensación de movimiento del ego en las detecciones acumuladas hasta la última posición conocida del vehículo. Propagamos puntos antiguos con el ego-movimiento conocido del vehículo para estimar su posición en el momento de la inferencia DNN (hora actual).
A continuación, proyectamos cada detección acumulada en una cuadrícula BEV de arriba hacia abajo con la cuantificación espacial deseada, creando un tensor de entrada para nuestro DNN. Establecemos la resolución de entrada en 800 × 800 píxeles con un rango de ±100 metros en cada dirección, lo que da como resultado una resolución de 25 cm por píxel. Cada píxel BEV válido (con datos) obtiene un conjunto de características en su canal de profundidad, calculado promediando las características de la señal sin procesar de las detecciones de radar que aterrizaron en ese píxel. Nuestra entrada final para el tiempo t es un tensor It ∈ R(h×w×5), donde h = 800 y w = 800 son la altura y el ancho de la vista de arriba hacia abajo. Las 5 características del radar en el canal de profundidad son: Doppler, Elevación, Sección transversal del radar (RCS), Acimut y promedio de las marcas de tiempo de detección relativas. Normalizamos estos valores al rango [0,1] utilizando los valores máximos y mínimos proporcionados por la especificación de hardware para la estabilidad del entrenamiento. El tensor resultante se utiliza como entrada a la red.
B: transferencia de etiquetas
Utilizamos etiquetas de cuadro delimitador anotadas por humanos basadas en lidar como la realidad básica para entrenar un radar-DNN. Estas etiquetas se crearon para los datos lidar de la misma escena donde entrenamos el radar DNN. Dado lo escasa que es la firma del radar, sería casi imposible para un ser humano distinguir vehículos usando solo puntos de radar, incluso en una vista BEV de arriba hacia abajo. Por lo tanto, confiamos en LiDAR para etiquetar los datos de entrenamiento. Capturamos datos de radar y lidar en diferentes frecuencias y seleccionamos la más cercana para su procesamiento. Luego creamos una proyección BEV de arriba hacia abajo de la escena LIDAR para que los humanos anoten objetos con etiquetas de cuadro delimitador y espacios libres con polilíneas. Para cada cuadro LiDAR BEV etiquetado, calculamos la imagen acumulativa de BEV de radar más cercana a través del método de preprocesamiento anterior y luego transferimos las etiquetas a la vista de arriba hacia abajo de RADAR. Limpiamos aún más la verdad del terreno eliminando cualquier etiqueta de vehículo que contenga menos de 4 detecciones de radar, lo que se demuestra empíricamente que mejora la precisión de la red. Finalmente, eliminamos las detecciones con RCS por debajo de −40 dBm, ya que determinamos empíricamente que introducen más ruido que señal. Como se muestra en la Figura 1.
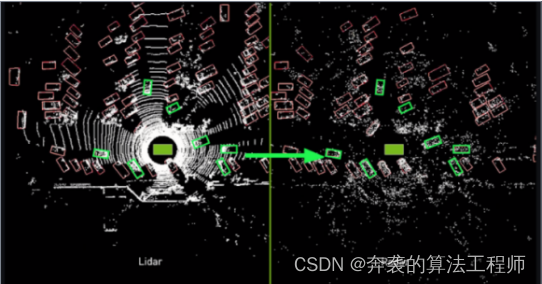
Figura 1 Pasar etiquetas de cuadro delimitador de automóvil del dominio LiDAR al dominio RADAR
C: Generación de etiquetas de espacio libre
Los objetivos de espacio libre se generan utilizando nubes de puntos LiDAR sin procesar. En primer lugar, la nube de puntos se preprocesa para identificar y eliminar puntos que pertenecen a la propia superficie transitable mediante la estimación del ángulo de pendiente de la superficie a partir de líneas de exploración LIDAR adyacentes; luego, superponemos las etiquetas de espacio libre LIDAR obtenidas manualmente para limpiar aún más esta estimación. A continuación, trazar un conjunto de rayos desde el origen del vehículo del ego hasta varios ángulos nos permite deducir qué regiones son:
• Ser observado y libre.
• Observar y ocupar.
•No me di cuenta.
• Observación parcial.
Finalmente, superponemos etiquetas de obstáculos 3D existentes en la ocupación generada automáticamente. Marcamos explícitamente los obstáculos como observados y ocupados. Consulte la figura 2.

Figura 2 Representación visual de objetivos en el espacio libre: los objetos observados y libres son negros, los objetos observados y ocupados son blancos, los objetos no observados son gris claro y los objetos parcialmente observados son gris oscuro
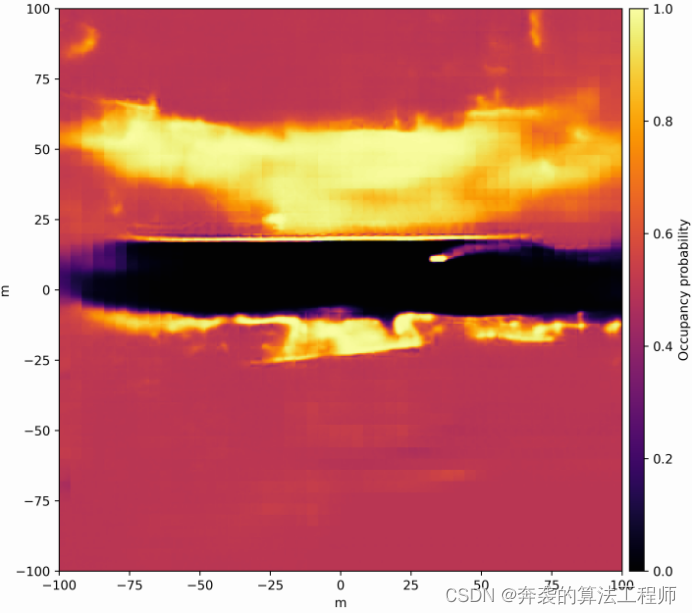
Figura 3. Mapa de probabilidad de ocupación densa inferido que muestra un gradiente de probabilidades de oscuro bajo a alto (más alto) en rojo a amarillo.
D: conjunto de datos
Nuestro modelo se entrena en un conjunto de datos interno diverso que consta de más de 300 000 marcos de entrenamiento y más de 70 000 marcos de validación extraídos de cientos de horas de conducción de muestras en múltiples regiones geográficas. El conjunto de datos incluye una combinación de datos urbanos y de carreteras y contiene lecturas simultáneas de lidar, radar e IMU. Las etiquetas tienen anotaciones humanas e incluyen vehículos, ciclistas, peatones y espacios libres transitables.
E: estructura de la red
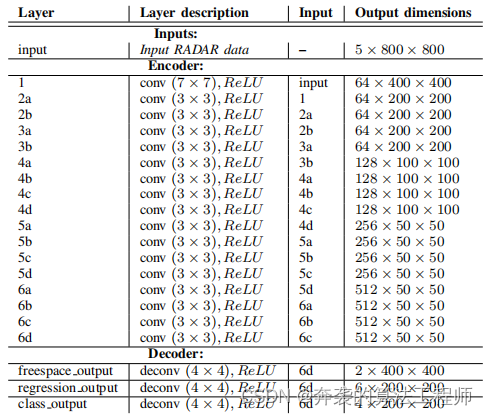
Usamos una arquitectura DNN similar a Feature Pyramid Network [22]. Nuestro DNN incluye componentes codificadores y decodificadores, y varios cabezales para predecir diferentes opciones de salida/reproducción. Consulte la Figura 4 para ver la estructura de alto nivel y la Tabla 1 para obtener detalles.
Nuestro codificador comienza con una capa convolucional 2D con 64 filtros, stride 2 y kernels 7 × 7. A esto le siguen 4 bloques, cada uno con 4 capas, cada uno de los cuales aumenta el número de filtros en dos mientras divide la resolución a la mitad. Cada capa del bloque consta de una convolución 2D con normalización por lotes y activación de ReLU.
El decodificador consta de una convolución transpuesta 2D con núcleos de paso 4 y 4 × 4 para cada cabeza. También experimentamos con el uso de dos circunvoluciones 2D transpuestas con una conexión de salto en el medio. El tensor de salida resultante es 1/4 de la resolución espacial de la entrada.
Usamos los siguientes encabezados en la red:
• El encabezado de división de clases predice tensores multicanal, un canal por clase. Cada valor contiene una puntuación de confianza que indica que un píxel dado pertenece a la clase correspondiente a su canal.
• El cabezal de regresión de la instancia predice el cuadro delimitador orientado de un objeto usando información de nr (nr = 6) canales de cada píxel predicho. El vector de elementos nr contiene: [δx, δy, w0, l0, sen θ, cos θ], donde (δx, δy) apunta al centroide del objeto correspondiente, w0 × l0 es la dimensión del objeto y θ es la orientación BEV de arriba hacia abajo.
• El cabezal del modelo de sensor inverso (ISM) calcula un mapa de probabilidad de ocupación para cada celda de la cuadrícula [20].

Figura 4 Arquitectura de red. Nuestra red utiliza CNN como codificador y decodificador con conexiones de salto. La red tiene tres cabezas: una cabeza de clasificación (que genera probabilidades de detección), una cabeza de regresión de forma (que genera parámetros de cuadro delimitador) y una cabeza de segmentación de espacio libre.
Tabla 1 Estructura de red de NVRadarNet
F: función de pérdida
Nuestras pérdidas incluyen la pérdida de entropía cruzada estándar para el encabezado de clasificación con mayor énfasis en la clase minoritaria, una pérdida L1 para la regresión del cuadro delimitador y una pérdida del modelo de sensor inverso para la detección de espacio libre [20].
Combinamos estas pérdidas utilizando el aprendizaje bayesiano de pesos, siguiendo el enfoque descrito en [23], modelando los pesos para cada tarea como una incertidumbre homocedástica dependiente de la tarea. Este enfoque nos permite entrenar de manera conjunta y eficiente estas tres tareas diferentes sin comprometer la precisión general del modelo.
La función de pérdida global se define como:
 (1)
(1)
donde K es el número de tareas/cabezas, Li es la pérdida de la tarea i, ![]() δi es el parámetro de varianza logarítmica aprendida para cada tarea y uw es el valor medio de los pesos de wi.
δi es el parámetro de varianza logarítmica aprendida para cada tarea y uw es el valor medio de los pesos de wi.
G: Detección de obstáculos de extremo a extremo
Para evitar el agrupamiento con costosas supresiones no máximas (NMS) o posprocesamiento (por ejemplo, DBSCAN), empleamos un enfoque de extremo a extremo mediante la clasificación de píxeles individuales por obstáculo, inspirado en OneNet [24].
Primero, calculamos la pérdida L1 para el cabezal de regresión y la pérdida de clasificación a nivel de píxel para el cabezal de clasificación. A continuación, para cada obstáculo objetivo, seleccionamos el píxel de primer plano con la menor pérdida total entre (ClassWeight * ClassLossPerPixel) + RegressionLossPerPixel. Luego, este píxel se selecciona para el cálculo de pérdida final, mientras que el resto de los píxeles de primer plano se ignoran. Luego, la pérdida de píxeles de fondo se explota selectivamente mediante minería negativa dura. Finalmente, realizamos la normalización por lotes dividiendo la cantidad total de pérdida de entropía cruzada por la cantidad de píxeles positivos seleccionados en el proceso anterior. Solo calcule la pérdida de regresión para los píxeles positivos seleccionados.
En el momento de la inferencia, simplemente seleccionamos todos los píxeles candidatos por encima de un cierto umbral en el encabezado de clasificación para cada clase. La dimensión de la barrera se toma directamente del encabezado de regresión para cada candidato de umbral correspondiente.
Mediante el uso de esta técnica, nuestra red puede generar directamente los obstáculos finales sin un costoso procesamiento posterior.
H: convertir la salida del encabezado ISM en un mapa de distancia radial
Las aplicaciones de vehículos autónomos suelen representar regiones de espacio libre transitables por sus contornos delimitadores. En esta sección, describimos cómo convertir contornos de límites en mapas de distancia radial (RDM), si es necesario. En la vista BEV de arriba hacia abajo del automóvil autónomo, RDM ![]() especifica un conjunto de direcciones angulares φf para la distancia df entre un punto de referencia en el automóvil autónomo y el límite del espacio libre transitable. Para calcular RDM, primero volvemos a muestrear el mapa de probabilidad de ocupación densa (salida DNN) en un sistema de coordenadas polares centrado en un punto de referencia. Al emplear el modo de interpolación del vecino más cercano, el proceso de remuestreo se puede expresar como una operación de indexación. Esto asigna el valor de cada píxel (φf,df) representado por la polaridad como el valor de un solo píxel del mapa de probabilidad de ocupación densa pronosticado. Dado que este mapeo solo depende del tamaño del mapa de ocupación y
especifica un conjunto de direcciones angulares φf para la distancia df entre un punto de referencia en el automóvil autónomo y el límite del espacio libre transitable. Para calcular RDM, primero volvemos a muestrear el mapa de probabilidad de ocupación densa (salida DNN) en un sistema de coordenadas polares centrado en un punto de referencia. Al emplear el modo de interpolación del vecino más cercano, el proceso de remuestreo se puede expresar como una operación de indexación. Esto asigna el valor de cada píxel (φf,df) representado por la polaridad como el valor de un solo píxel del mapa de probabilidad de ocupación densa pronosticado. Dado que este mapeo solo depende del tamaño del mapa de ocupación y ![]() la ubicación de los puntos de referencia, todos los índices requeridos pueden calcularse fuera de línea y almacenarse en tablas de búsqueda. La figura 5 es un mapa de probabilidad de ocupación. La Figura 3 muestra el remuestreo en coordenadas polares. Después del remuestreo, la distancia df para cada dirección angular φf se determina encontrando el primer píxel a lo largo de cada eje angular donde la probabilidad de ocupación alcanza algún umbral pocc. La Figura 6 muestra la representación RDM del límite del espacio libre manejable derivado por el programa del mapa de probabilidad de ocupación densa que se muestra en la Figura 3.
la ubicación de los puntos de referencia, todos los índices requeridos pueden calcularse fuera de línea y almacenarse en tablas de búsqueda. La figura 5 es un mapa de probabilidad de ocupación. La Figura 3 muestra el remuestreo en coordenadas polares. Después del remuestreo, la distancia df para cada dirección angular φf se determina encontrando el primer píxel a lo largo de cada eje angular donde la probabilidad de ocupación alcanza algún umbral pocc. La Figura 6 muestra la representación RDM del límite del espacio libre manejable derivado por el programa del mapa de probabilidad de ocupación densa que se muestra en la Figura 3.
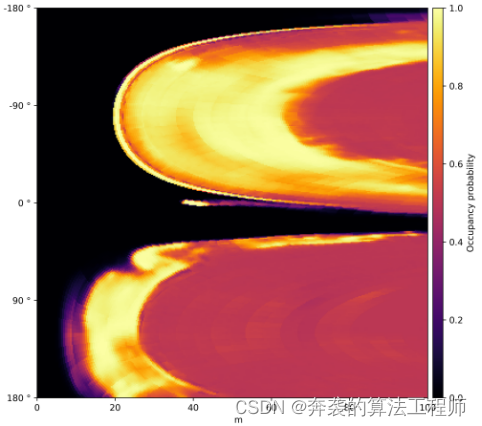
El mapa de ocupación densa pronosticado en la Figura 5 se vuelve a muestrear a un sistema de coordenadas polares centrado en el punto de referencia ![]() . La probabilidad se indica de rojo (baja) a amarillo (alta).
. La probabilidad se indica de rojo (baja) a amarillo (alta).
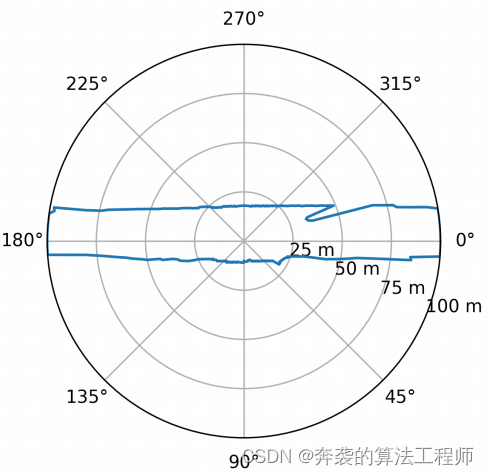
Figura 6. Representación del mapa de distancia radial de los límites del espacio libre transitable extraídos de los mapas de probabilidad de ocupación densa pronosticados.
4. Experimenta
A. Experimentos de conjuntos de datos internos
Actualmente, hay conjuntos de datos limitados, puntos de referencia y DNN publicados dedicados a la detección de obstáculos y espacios libres basada en radar, lo que dificulta la evaluación. Consulte la Tabla 2 para obtener una lista de los métodos disponibles y sus propiedades. El trabajo más cercano [17][5][19][18] utiliza la fusión de sensores y no comparte públicamente solo los resultados del radar. Por lo tanto, según nuestro leal saber y entender, estamos estableciendo líneas de base para la detección de obstáculos, la clasificación y la regresión en el espacio libre utilizando solo picos de radar. La detección de peatones y ciclistas es un gran desafío debido a la escasez de señales de radar.
Evaluamos nuestro DNN en el conjunto de datos RADAR de NVIDIA y el conjunto de datos público de nuScenes. También comparamos nuestro DNN con otros trabajos publicados tanto como sea posible y enumeramos todos los resultados en esta sección.
Para nuestro conjunto de datos interno de NVIDIA Radar, utilizamos los datos de prueba mencionados en la Sección III-D para la evaluación. Tenga en cuenta que incluso si se filtran los cuadros delimitadores de la verdad del terreno que contienen muy pocas detecciones de picos de radar (como se describe en la Sección III-B), todavía terminaremos con etiquetas de verdad del terreno ruidosas. Por ejemplo, en muchos casos, los vehículos están tapados por otros vehículos, por lo que los etiquetadores humanos no pueden crear una buena verdad del terreno solo a partir de los datos LIDAR. En este caso, el RADAR aún arroja resultados válidos, con algunos obstáculos clasificados correctamente por nuestro DNN, pero marcados como falsos positivos en el momento de la evaluación debido a deficiencias en la verdad del terreno. Esto reduce nuestra precisión. Además, el sensor lidar está montado más alto en el vehículo (techo) que el sensor de radar (parachoques), por lo que el lidar puede ver algunos obstáculos y el radar tiene una visibilidad limitada, lo que genera etiquetas y datos de radar ruidosos. Esto puede dar lugar a falsos negativos y reducir nuestra memoria.
Nuestros resultados en la tarea de detección de objetos se muestran en las Tablas III, IV. Las métricas para la tarea de detección de espacio libre (Tabla V) se calculan por separado para regiones de espacio libre y RDM de espacio libre. Las regiones de espacio libre se definen por probabilidades de ocupación po < 0,4.
B. Rendimiento del conjunto de datos de NuScenes
Evaluamos aún más nuestro método en el conjunto de datos público de nuScenes [25]. Este conjunto de datos contiene datos de sensores de 1 lidar y 5 radares. Sin embargo, los sensores en este conjunto de datos son de una generación anterior, lo que dificulta las comparaciones directas. El sensor lidar utilizado para la recopilación de datos de nuScenes contiene solo 32 haces, en comparación con los 128 haces de nuestro conjunto de datos interno. La escasez adicional en este conjunto de datos degrada la calidad de nuestros objetivos de espacio libre generados automáticamente. Del mismo modo, el radar Continental ARS 408-21 utilizado en el conjunto de datos nuScenes produjo significativamente menos detecciones que el sensor de radar Continental ARS430 de nueva generación que usamos en nuestro conjunto de datos interno. No obstante, demostramos resultados respetables, especialmente a corta distancia. Ver Tabla 6, Tabla 7 y Tabla 8 para más detalles.
Además, comparamos nuestra precisión de detección de espacio libre NVRadarNet DNN con el método publicado en [21], que también brinda resultados en el conjunto de datos nuScenes. Sin embargo, este método opera en una cuadrícula que cubre el área frente al vehículo ego hasta 86 m con 10 m a cada lado y, a diferencia de nuestro método, no retrocede ni clasifica las barreras. Para esta comparación, evaluamos en las mismas regiones de la imagen mientras transformamos las probabilidades de ocupación previstas en las siguientes tres clases: ocupada, libre y no observada.
• Ocupación: pocc > 0,65
• Libre: pocc < 0,35
• No observado: 0,35 <= pocc <= 0,65
Los resultados se muestran en la Tabla 9. Nuestro DNN supera a otros métodos en la regresión de espacio ocupado (mejores resultados en negrita) y funciona de manera similar en otras tareas.
C. Razonamiento de redes neuronales profundas de NVRadarNet
Nuestro NVRadarNet DNN se puede entrenar con cuantificación INT8 en modo de precisión mixta sin perder precisión. Exportamos la red usando NVIDIA TensorRT y la cronometramos en la GPU integrada de NVIDIA DRIVE AGX que se usa en autos sin conductor. Nuestro DNN puede lograr una inferencia de extremo a extremo de 1,5 ms para las tres cabezas. Procesamos todo el radar envolvente, realizamos la detección de obstáculos y la segmentación del espacio libre mucho más rápido que las GPU integradas en tiempo real. Es difícil encontrar otros tiempos de inferencia de redes neuronales profundas de RADAR en la literatura para una comparación directa. Solo encontramos que [11] es un orden de magnitud más lento.
Tabla 2 Métodos de detección de radar relacionados. Nuestro método (en negrita) utiliza solo datos de radar, admite detección de objetos y espacio libre y proporciona resultados públicos.

Tabla 3 Precisión de detección de obstáculos de nuestra DNN en el conjunto de datos interno de NVIDIA, ordenados por categoría y rango.

Tabla 4. Precisión de detección de obstáculos de nuestra DNN en el conjunto de datos interno de NVIDIA, ordenados por categoría.

Tabla 5. Precisión de regresión de espacio libre de nuestro DNN en el conjunto de datos interno de NVIDIA.

Tabla 6 Precisión de detección de obstáculos de nuestra DNN en el conjunto de datos de nuScenes, ordenados por categoría y rango.
Tabla 7. Precisión de detección de obstáculos de nuestra DNN en el conjunto de datos de nuScenes, ordenados por categoría.

Tabla 8 Precisión de regresión de espacio libre de nuestro DNN en el conjunto de datos de nuScenes.

Tabla 9 Comparación con occancynet [21] en el conjunto de datos de nuScenes. El texto en negrita funciona mejor.

5. Conclusión
En este trabajo, proponemos la red neuronal profunda NVRadarNet, una red neuronal profunda en tiempo real para detectar obstáculos y espacios libres transitables a partir de datos de radar sin procesar proporcionados por radares automotrices comunes. Comparamos el DNN con el conjunto de datos interno de NVIDIA y el conjunto de datos público de nuScenes y presentamos resultados de precisión. Nuestro DNN se ejecuta más rápido que en tiempo real con un tiempo de inferencia de extremo a extremo de 1,5 milisegundos en la GPU integrada de NVIDIA DRIVE AGX. Hasta ahora, no hemos encontrado ninguna otra red de radar que pueda realizar tanto la detección de obstáculos como la regresión del espacio libre mientras se ejecuta más rápido que en tiempo real en la computadora integrada del automóvil.
gracias
Nos gustaría agradecer a Sriya Sarathy, Tilman Wekel y Stan Birchfield por sus contribuciones técnicas. También nos gustaría agradecer a David Nister, Sangmin Oh y Minwoo Park por su apoyo.
Enlace original