
Figura 1. Descripción general de nuestro conjunto de datos RADIal. RADIal incluye 3 sensores (cámara, escáner láser, radar HD) con GPS y rastreo CAN del vehículo; 25k muestras simultáneas en formato raw. (a) Imagen de la cámara, nube de puntos de láser de proyección roja, marca azul índigo nube de puntos de radar, marca naranja vehículo, marca verde espacio de conducción libre; (b) marca de cuadro delimitador de banda de espectro de potencia de radar; marca de vista de pájaro (c) espacio de conducción libre Marcado , el cuadro delimitador naranja marca el vehículo, el azul índigo marca la nube de puntos del radar y el rojo marca la nube de puntos del láser; el sistema de coordenadas cartesianas (d) el mapa de alcance y azimut superpone la nube de puntos del radar y la nube de puntos del láser; ( e) el rojo marca el track del GPS, y el verde la reconstrucción del track del kilometraje.
Resumen
Los sensores de radar, con su solidez frente a condiciones climáticas adversas y su capacidad para medir la velocidad, han sido parte del panorama automotriz durante más de 20 años. En los últimos años, los avances en el radar de imágenes de alta definición (HD) han llevado la resolución angular por debajo de 1 grado, acercándose así al rendimiento del escaneo láser. Sin embargo, la cantidad de datos proporcionados por el radar de alta definición y el costo computacional de estimar la posición angular siguen siendo un desafío. En este documento, proponemos un nuevo modelo de detección de radar de alta definición, FFT-RadNet, que elimina la sobrecarga de calcular el tensor 3D de rango-acimut-Doppler, en lugar de aprender el ángulo de recuperación. FFTRadNet está capacitado para detectar vehículos y segmentar el espacio de conducción libre. En ambas tareas, compite con los modelos basados en radar de última generación y requiere menos computación y memoria. Además, recopilamos y anotamos 2 horas de datos sin procesar de sensores de grado automotriz sincronizados (cámaras, láseres, radar HD) en diferentes entornos (calles de la ciudad, autopistas, caminos rurales). Este conjunto de datos único, llamado "Radar, LiDAR, et al", está disponible en https://github.com/valeoai/RADIal.
1. Introducción
Los radares automotrices han estado en producción desde finales de los 90. Son el sensor de referencia más asequible para el control de crucero adaptativo, la detección de puntos ciegos y el frenado automático de emergencia. Sin embargo, su pobre resolución angular dificulta su aplicación en sistemas de conducción autónoma. En la práctica, tales sistemas requieren un alto nivel de seguridad y robustez, que normalmente se puede lograr a través de mecanismos redundantes. Si bien la detección se mejora al fusionar varias modalidades, la combinación general solo funcionará si cada sensor logra un rendimiento suficiente y comparable. Han surgido radares de imágenes de alta definición (HD) para cumplir con estos requisitos. Estos nuevos sensores logran una alta resolución angular tanto en azimut como en elevación (posiciones angulares horizontales y verticales) mediante el uso de conjuntos de antenas virtuales densos. y producir nubes de puntos más densas.
Con el rápido desarrollo del aprendizaje profundo y la disponibilidad de conjuntos de datos de conducción pública como [4,6,12], las capacidades de percepción de los sistemas de conducción basados en la visión (detección de objetos, estructuras, marcadores y señales, estimación de la profundidad, predicción de otros usuarios de la carretera La capacidad de hacer ejercicio) mejora significativamente. Estos avances se extendieron rápidamente a los sensores de profundidad, como los escáneres láser (LiDAR), con la ayuda de arquitecturas específicas para procesar nubes de puntos 3D [19, 42].
Tabla 1. Conjuntos de datos de conducción disponibles públicamente con radar. Los conjuntos de datos son "pequeños" (<15k cuadros), "grandes" (>130k cuadros) o "medianos" (algo intermedio). El radar está disponible en baja definición (LD), alta definición (HD) o escaneo (S) y sus datos se publican en diferentes formatos, incluidas diferentes canalizaciones de procesamiento de señales: señal de convertidor analógico a digital (ADC), tensor Doppler acimutal (RAD). , Vista de acimut (RA), Vista Doppler (RD), Nube de puntos (PC). La presencia de información Doppler depende del sensor de radar. Otras modalidades de sensor incluyen cámara (C), lidar (L) y odometría (O). RADIal es el único conjunto de datos que proporciona radar de alta definición, combinando cámaras, lidar y odometría, al tiempo que aborda tareas de detección y segmentación de espacio libre.

Sorprendentemente, el procesamiento de señales de radar es mucho más lento para adoptar el aprendizaje profundo en este caso en comparación con otros sensores. Esto puede deberse a la complejidad, la naturaleza y la falta de conjuntos de datos públicos de los datos. De hecho, las contribuciones clave recientes en el campo de la percepción de vehículos basada en radar se produjeron con el lanzamiento del conjunto de datos. Curiosamente, el trabajo más reciente explota la representación de rango-azimut (RA) de datos de radar (ya sea en coordenadas polares o cartesianas). Similar a una vista de pájaro (consulte la Figura 1d), esta representación es fácil de interpretar y permite un aumento de datos simple a través de la traducción y la rotación. Sin embargo, una desventaja apenas mencionada es que la generación de mapas de radar RA incurre en un enorme costo de procesamiento (decenas de GOPS, consulte la Sección 6.5), lo que perjudica su viabilidad en hardware integrado. Si bien los radares de alta definición más nuevos ofrecen una mejor resolución, exacerban este problema de complejidad computacional.
Debido a las buenas capacidades del radar HD, nuestro trabajo se centra en este problema para mejorar su practicidad. En particular, proponemos: (1) FFT-RadNet, una arquitectura profunda optimizada para procesar datos de radar de alta definición a un costo reducido, para dos tareas de percepción diferentes, a saber, detección de vehículos y segmentación de espacio libre; (2) comparación de varios análisis empíricos de representación de señales de radar en términos de rendimiento, complejidad y huella de memoria; (3) RADIal, el primer conjunto de datos de radar sin procesar de alta definición que incluye varios otros sensores de grado automotriz, como se muestra en la Tabla 1.
El documento está organizado de la siguiente manera: las secciones 2 y 3 analizan los antecedentes del radar y el trabajo relacionado; las secciones 4 y 5 presentan FFT-RadNet y RADIal; los experimentos se informan en la sección 6 y concluyen en la sección 7.
2. Fondo de radar
El radar generalmente consta de un conjunto de antenas de transmisión y recepción. El transmisor emite ondas electromagnéticas que los objetos del entorno reflejan de vuelta al receptor. En un producto estándar en la industria automotriz [3,13], un radar de onda continua modulada en frecuencia (FMCW) emite una serie de señales moduladas en frecuencia llamadas chirips. La diferencia de frecuencia entre transmisión y recepción se debe principalmente a la distancia radial de los obstáculos. Por lo tanto, esta distancia se extrae mediante la transformada rápida de Fourier (rangeFFT) a lo largo de la secuencia chirp. Una segunda FFT (Doppler-FFT) a lo largo del eje del tiempo extrae la diferencia de fase, que captura la velocidad radial del reflector. La combinación de estas 2 FFT proporciona un espectro Doppler de rango (RD) para cada antena receptora (Rx), y todas las Rx se almacenan en un tensor RD. El ángulo de llegada (AoA) se puede estimar utilizando múltiples Rx. Debido a la pequeña distancia entre las antenas Rx, se puede observar una diferencia de fase de la señal recibida. Una práctica común es aplicar una tercera FFT (angle-FFT) a lo largo del eje del canal para estimar este AoA.
La capacidad de un radar para distinguir entre dos objetivos con el mismo alcance y velocidad pero diferentes ángulos se conoce como resolución angular. Es proporcional a la apertura de la antena, que es la distancia entre la primera antena y la última antena. Los métodos de entrada múltiple y salida múltiple (MIMO) [9] se usan comúnmente para aumentar la resolución angular sin aumentar la apertura física: cada antena de transmisión adicional (Tx) aumenta la resolución angular en un factor de 2. El sistema MIMO representa el número de canales Tx y Rx de NTx y NRx respectivamente, y se establece una matriz virtual Doppler de secuencia modal ADC RAD RA o RD PC de tipo radar de antena NTx·NRx. Para evitar la interferencia de las señales transmitidas, el transmisor transmite simultáneamente la misma señal pero con un ligero cambio de fase ∆ϕ entre dos antenas consecutivas. La desventaja de este enfoque es que cada característica del reflector aparece NTx veces en el espectro RD, intercalando los datos.
Para convertir AoA en un ángulo válido, se debe calibrar el sensor. Otra opción para la tercera FFT es correlacionar el espectro RD con la matriz de calibración en el dominio complejo para estimar ángulos (acimut y altitud). Para un solo punto del tensor RD, la complejidad de esta operación es O(NTxNTxNRxBABE), donde BA y BE son el número de bins discretos en azimut y elevación respectivamente en la matriz de calibración. Para una representación 4D de rango-azimut-elevación-Doppler, esto debe hacerse para cada punto del tensor RD.
En resumen, para el radar integrado de alta definición, los métodos tradicionales de procesamiento de señales son demasiado grandes en términos de requisitos informáticos y recursos de memoria para aplicar. Por lo tanto, para los sistemas de asistencia al conductor, es un desafío aumentar la resolución angular del radar mientras se controla el costo de procesamiento.
3. Trabajo relacionado
conjunto de datos de radar. El radar tradicional ofrece una buena compensación entre costo y rendimiento. Si bien proporcionan un alcance y una velocidad precisos, tienen una resolución azimutal baja, lo que genera ambigüedad al aislar objetos cercanos. Los conjuntos de datos recientes incluyen representaciones de radar procesadas, como todo el tensor Doppler de rango-acimut (RAD) [31, 43] o una sola vista de rango-azimut (RA) de este tensor [1, 17, 27, 38, 41] o Rango Doppler (RD) [27]. Estas representaciones requieren un gran ancho de banda para la transmisión y un gran almacenamiento de memoria. Por lo tanto, los conjuntos de datos que contienen varios patrones de muestra, como nuScenes [4], solo proporcionan nubes de puntos de radar, una representación más clara. Sin embargo, es una representación de procesamiento limitada y está sesgada hacia la canalización de procesamiento de señales. Varios otros conjuntos de datos utilizan un radar de exploración de 360◦ [1, 17, 38]. Sin embargo, su resolución angular es tan limitada como la de un radar convencional y no proporciona información Doppler.
Como se mencionó anteriormente, los radares de alta definición recientes han logrado con éxito resoluciones de azimut por debajo de este grado utilizando grandes conjuntos de antenas virtuales. El conjunto de datos de Zendar [27] proporciona vistas de rango-Doppler y rango-azimut para este radar. Los conjuntos de datos de Astyx [24] y RadarScenes [36] contienen datos de radar de alta resolución procesados como nubes de puntos.
Hasta donde sabemos, no hay conjuntos de datos de radar de alta definición de código abierto que proporcionen datos sin procesar que combinen cámaras y lidar en varios entornos de conducción, y nuestro conjunto de datos está llenando este vacío. La Tabla 1 resume las características de los conjuntos de datos de conducción de radar disponibles públicamente.
Detección de objetivos por radar. El radar de baja definición (LD) se ha utilizado en muchos escenarios de aplicación, como reconocimiento de gestos [10], detección de objetos o personas dentro de puertas [15] y vigilancia aérea [26]. Para aplicaciones automotrices, se elige una sola vista del tensor RAD como entrada a una arquitectura de red neuronal específica para detectar firmas de objetos en la vista considerada, ya sea RA [8, 40] o RD [28]. A diferencia de [44], que utiliza vistas de radar para localizar objetos en las imágenes de la cámara, [2] propone un enfoque en dos etapas para estimar el azimut de los objetos detectados utilizando solo vistas de RD.
Las arquitecturas específicas están diseñadas para ingerir vistas agregadas de tensores RAD para detectar objetos en vistas RA [11, 23]. También se ha considerado el tensor completo, tanto para la detección de objetos en vistas RA y RD [43] como para la localización de objetos en imágenes de cámara [32].
Debido al preprocesamiento aplicado, las nubes de puntos de radar contienen menos información que las vistas RAD. Sin embargo, [7, 35] utilizó el radar LR para la detección de objetos 2D y [25] mostró que las nubes de puntos de radar de alta definición pueden superar a LiDAR en esta tarea.
Ninguno de estos trabajos menciona el costo de preprocesamiento de generar tensores RAD o nubes de puntos, que se dan por sentado. De hecho, el radar de alta definición no se puede utilizar con los métodos antes mencionados, ya que no es adecuado ni siquiera para los dispositivos integrados de automóviles más grandes. Por ejemplo, aplicando [11] al radar HD, los datos de entrada para cada marca de tiempo ocuparán 450 MB, y solo una altura (usando [11]) requiere 4,5 10^10 FLOPS2. Hasta donde sabemos, no existe ningún trabajo previo sobre la detección de objetos de extremo a extremo que pueda escalar con datos de radar de alta definición sin procesar.
Segmentación Semántica Radar. La segmentación semántica en representaciones de radar se ha investigado menos debido a la falta de conjuntos de datos anotados. Las vistas RA han sido el tema de investigación de la segmentación multiclase [16] y de espacio libre [29]. Todo el tensor RAD se considera para la segmentación de vistas múltiples en [30]. La segmentación de la nube de puntos de radar también se ha explorado para estimar las cuadrículas de ocupación de vista aérea, ya sea para radares LD [22, 39] o HD [33, 34, 37].
Además, ninguno de estos métodos escala a datos de radar de alta definición sin procesar, por ejemplo, para realizar la segmentación de espacio libre. Además, no hay trabajo sobre la segmentación espacial de conducción libre o la segmentación semántica utilizando solo vistas RD de señales de radar de alta definición. Además, actualmente no existe un modelo multitarea capaz de realizar simultáneamente la detección de objetos de radar y la segmentación semántica. A continuación, detallamos nuestro enfoque, con memoria y complejidad reducidas , para realizar la detección de vehículos y la segmentación del espacio de conducción libre utilizando señales de radar HD sin procesar.
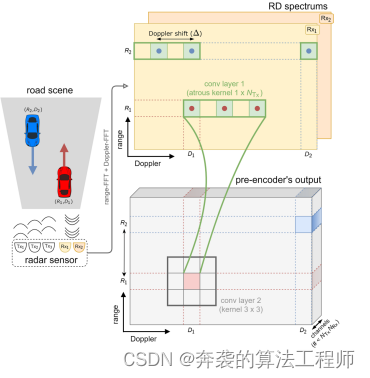
Figura 2. Precodificador MIMO entrenable. Considerando tres transmisores (NTx = 3) y dos receptores (NRx = 2), la firma de un objeto es visible en el espectro RD para tiempos NTx. Este precodificador utiliza convoluciones de Allah para organizar y comprimir firmas en menos canales de salida que NTx NRx.
4. Arquitectura FFT-RadNet
Nuestro enfoque se basa en las restricciones automotrices: se deben usar sensores de grado automotriz, mientras que solo hay recursos limitados de procesamiento/memoria disponibles en el hardware integrado. En este caso, el espectro RD es la única representación viable de la representación del radar HD. En base a esto, proponemos una arquitectura multitarea compatible con los requisitos anteriores, que consta de cinco bloques (ver Figura 3):
• Un precodificador reorganiza y comprime tensores RD en una representación significativa y compacta;
• Codificador Shared Feature Pyramid Network (FPN) que combina información semántica de baja resolución con detalles de alta resolución;
• Un decodificador de rango-ángulo que construye representaciones latentes de rango-acimut a partir de pirámides de características;
• El cabezal de detección ubica el vehículo en coordenadas distancia-azimut;
• Cabezal de segmentación para predicción de espacio de viaje libre.
4.1 Precodificador MIMO
Como se describe en la Sección 2, la configuración MIMO proporciona a cada receptor un espectro RD complejo. Esto da como resultado un tensor 3D complejo (BR, BD, NRx), donde BR y BD son el número de unidades discretas para rango y Doppler, respectivamente. Es importante comprender cómo aparece en los datos un objeto reflectante dado (como un automóvil en el frente). R representa la distancia radial real del objeto al radar, y D representa su velocidad radial relativa por el efecto Doppler. Para cada receptor, su señal se mostrará NTx veces, una para cada transmisor. Más específicamente, las medidas se realizarán en la posición Doppler de rango (R, (D+k∆)[Dmax])k=1···NTx, donde ∆ es el desplazamiento Doppler (por el desplazamiento de fase ∆φ inducido), Dmax es el Doppler máximo que se puede medir. El valor Doppler medido es módulo este máximo.
Esta complejidad de la señal requiere un reordenamiento del tensor RD, lo que facilita la posterior utilización de la información MIMO (para recuperar ángulos) manteniendo el volumen de datos bajo control. Con este fin, proponemos un nuevo precodificador entrenable que realiza una reorganización tan compacta de los tensores de entrada (Fig. 2). Para manejar mejor su estructura específica a lo largo del eje Doppler, primero usamos una capa convolucional de Atrous correctamente definida que recopila información de Tx y Rx en la ubicación correcta. Para un canal de entrada, el tamaño de su kernel es 1×NTx, por lo que se define por el número de antenas Tx, y su expansión es δ = ∆BD / Dmax, que es el número de contenedores Doppler correspondientes al cambio de frecuencia Doppler. ∆. El número de canales de entrada es el número de NRx de la antena Rx. La segunda capa convolucional (usando un kernel 3×3) aprende cómo combinar estos canales y comprimir la señal. El precodificador de dos capas se entrena de extremo a extremo con el resto de la arquitectura propuesta.
4.2.Precodificador FPN
El aprendizaje de características multiescala con estructura piramidal es un método común en la detección de objetos [20] y la segmentación semántica [45]. Nuestra arquitectura FPN utiliza 4 bloques que constan de 3, 6, 6 y 3 capas residuales [14] respectivamente. Los mapas de características de estos bloques residuales forman una pirámide de características. Los codificadores clásicos se optimizan teniendo en cuenta la naturaleza de los datos mientras controlan la complejidad de los datos. De hecho, la dimensión del canal se elige como máximo para codificar el acimut en todo el rango de distancias (es decir, alta resolución y campo de visión estrecho a distancias largas, resolución baja y campo de visión amplio a distancias cortas). Para evitar la pérdida de características de objetos pequeños (por lo general, unos pocos píxeles en el espectro RD), el codificador FPN realiza una reducción de muestreo de 2 × 2 en cada bloque, lo que da como resultado una reducción de 16 veces en el tamaño del tensor tanto en altura como en ancho. Por razones similares, para evitar la superposición entre Tx adyacentes, utiliza un kernel de convolución de 3×3.
4.3 Decodificador distancia-ángulo
El objetivo del decodificador distancia-ángulo es extender el mapa de características de entrada a una representación de mayor resolución. Esta escala generalmente se logra mediante múltiples capas de deconvolución cuyas salidas se combinan con mapas de características anteriores para preservar los detalles espaciales. En nuestro caso, esta representación es inusual debido a la física de los ejes: las dimensiones del tensor de entrada corresponden a rango, Doppler y azimut, respectivamente, mientras que los mapas de características que se enviarán a los jefes de tareas posteriores deben corresponder a Expresado en distancia-azimut. Por lo tanto, intercambiamos los ejes Doppler y azimutal para que coincidan con el orden final de los ejes y luego actualizamos los mapas de características. Sin embargo, el eje de distancia es más pequeño en tamaño que el eje de acimut porque después de cada bloque restante, el eje de distancia es diezmado por un factor de 2 mientras que el eje de acimut (anteriormente el eje del canal) aumenta. Antes de estas operaciones, aplicamos una convolución 1×1 en el mapa de características del codificador al decodificador. Cambia el tamaño del canal de acimut a su tamaño final antes de cambiar los ejes. La capa de deconvolución solo agrega el eje de distancia, produciendo un mapa de características concatenado con el mapa de características de la capa de pirámide anterior. Se aplica un bloque final que consta de dos capas Conv-BatchNorm-ReLU para generar la representación latente de orientación de rango final.
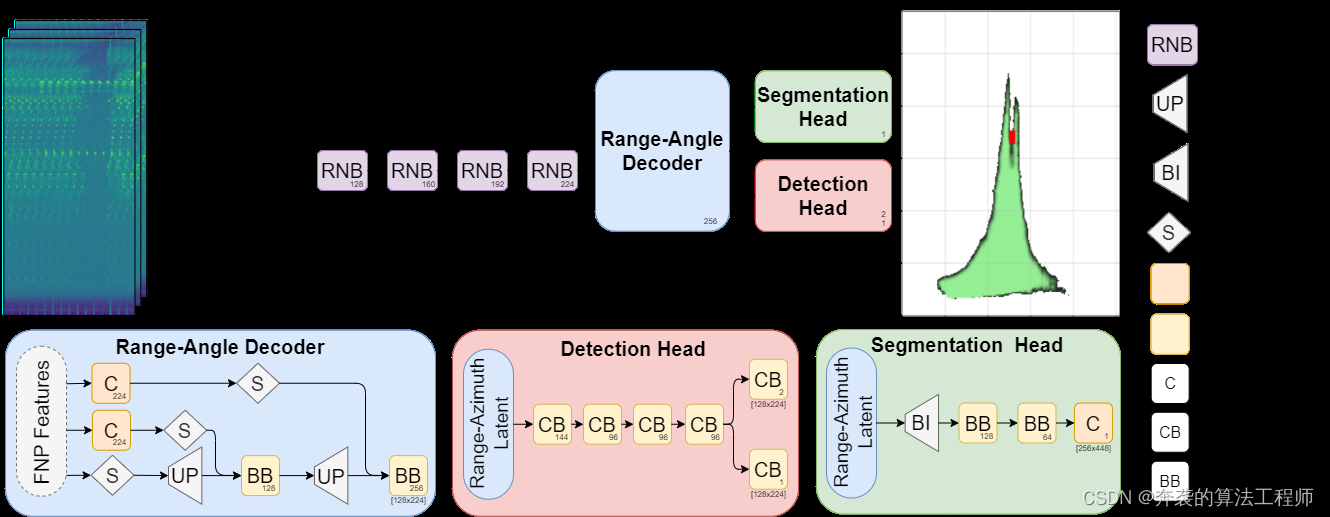
Figura 3: Descripción general de FFT-RadNet. FFT-RadNet es una arquitectura multitarea ligera. No utiliza mapas RA ni tensores RAD, lo que requeriría un preprocesamiento costoso. En su lugar, utiliza un espectro Doppler de rango complejo que contiene toda la información de rango, azimut y elevación. Estos datos son desentrelazados y comprimidos por un precodificador MIMO. El codificador FPN extrae una pirámide de características, que se convierte en una representación de rango-acimut latente mediante un decodificador de rango-ángulo. Sobre esta base, el cabezal multitarea finalmente realiza la detección del vehículo y la predicción del espacio de circulación libre.
4.4 Aprendizaje multitarea
tareas de detección. El cabezal de detección está inspirado en Pixor [42], un modelo de una etapa eficiente y escalable. Toma la representación latente de RA como entrada y la procesa usando la primera secuencia común de cuatro capas Conv-BatchNorm con 144, 96, 96 y 96 filtros respectivamente. Luego divida las ramas en las rutas de clasificación y regresión. La parte de clasificación es una capa convolucional con activación sigmoidea que predice un mapa de probabilidad. Esta salida corresponde a una clasificación binaria de si cada "píxel" está ocupado por un vehículo o no. Para reducir la complejidad computacional, predice un mapa RA aproximado donde cada celda tiene una resolución de 0,8 m en rango y 0,8◦ en azimut (es decir, 1/4 y 1/8 de la resolución nativa respectivamente en distancia y orientación). Este tamaño de celda es suficiente para separar dos objetos adyacentes. Luego, la parte de regresión predice con precisión el valor de distancia y azimut correspondiente al objeto medido. Con este fin, una capa convolucional única de 3 × 3 genera dos mapas de características, que responden a los valores finales de rango y azimut.
Este cabezal de detección dual entrena una pérdida multitarea que incluye una pérdida focal aplicada a todas las ubicaciones para la clasificación y una pérdida "L1 suavizada" para la regresión aplicada solo a las detecciones positivas (consulte [42] para obtener detalles sobre estas pérdidas). Sea x el ejemplo de entrenamiento, ![]() la verdad fundamental para la clasificación y
la verdad fundamental para la clasificación y ![]() la verdad fundamental para la regresión de correlación. El cabezal de detección de FFT-RadNet predice un mapa de detección
la verdad fundamental para la regresión de correlación. El cabezal de detección de FFT-RadNet predice un mapa de detección ![]() y el mapa de regresión asociado
y el mapa de regresión asociado ![]() . Su pérdida de entrenamiento es la siguiente:
. Su pérdida de entrenamiento es la siguiente:
![]() ,(1)
,(1)
donde β > 0 es un hiperparámetro de equilibrio.
Dividir tareas. La tarea de segmentación espacial de ejecución libre se formula como una clasificación binaria a nivel de píxel. La resolución de la máscara de segmentación es de 0,4 m de alcance y 0,2◦ de acimut. Corresponde a la mitad del rango nativo y la resolución de azimut, considerando solo la mitad del campo de visión de azimut completo (en [-45◦, 45◦]). Las representaciones latentes de RA son procesadas por dos conjuntos consecutivos de bloques Conv-BatchNorm-ReLu, generando 128 y 64 mapas de características, respectivamente. La convolución 1×1 final genera un mapa de características 2D, seguido de activaciones sigmoideas para estimar la probabilidad de que cada ubicación sea manejable. Sea x el ejemplo de entrenamiento,![]() su punto de acceso real y
su punto de acceso real y![]() el mapa de detección suave predicho. Aprendizaje de tareas de segmentación usando pérdida de entropía cruzada binaria:
el mapa de detección suave predicho. Aprendizaje de tareas de segmentación usando pérdida de entropía cruzada binaria:
![]() , (2)
, (2)
Aquí, ![]() .
.
Capacitación integral multitarea. Todo el modelo FFT-RadNet se entrena minimizando una combinación de pérdidas previas de detección y segmentación:
![]() , (3)
, (3)
Parámetros que involucran precodificador MIMO, codificador FPN, decodificador RA y dos cabezales; λ es un hiperparámetro positivo que equilibra estas dos tareas.
5. Conjunto de datos RADIales
Como se muestra en la Tabla 1, los conjuntos de datos disponibles públicamente no proporcionan señales de radar sin procesar, ni radar LD ni radar HD. Por lo tanto, construimos un nuevo conjunto de datos RADIal, que puede estudiar el radar de alta definición automotriz. Dado que RADIal incluye 3 modos de sensor: cámara, radar y escáner láser, también debería permitir a las personas investigar la fusión del radar HD con otros sensores más clásicos. Consulte el Apéndice A para conocer las especificaciones detalladas del kit de sensor utilizado. Todos los sensores tienen calificación de grado automotriz, excepto la cámara. Además de esto, también se proporcionan la posición GPS del vehículo y el bus CAN completo (incluido el odómetro). Las señales del sensor se registran simultáneamente en formato sin procesar sin ningún procesamiento previo de la señal. En el caso del radar HD, la señal sin procesar es el ADC. A partir de los datos ADC, se pueden generar todas las representaciones de radar convencionales: tensores Doppler de rango-azimut, vistas de rango-azimut y Doppler de rango o nubes de puntos.
RADIal contiene 91 clips con una duración de aproximadamente 1-4 minutos y un total de 2 horas. Esto equivale a alrededor de 25k cuadros simultáneos en total, de los cuales 8252 cuadros fueron etiquetados para 9550 vehículos (ver Apéndice A para más detalles). La anotación del vehículo consta de un cuadro 2D en el plano de la imagen junto con la distancia real del suelo y el valor Doppler (velocidad radial relativa) al sensor. La representación espectral RD de las señales de radar no tiene sentido para el ojo humano, por lo que es difícil lograr la anotación de las señales de radar.
Las etiquetas de detección de vehículos primero se generan automáticamente con la supervisión de cámaras y escáneres láser. Las propuestas de objetos se extraen de las cámaras utilizando un modelo RetinaNet [21]. Estas propuestas luego se validan cuando el radar y el lidar acuerdan la ubicación del objetivo en sus respectivas nubes de puntos. Finalmente, se produce la verificación humana, ya sea rechazando o validando la etiqueta. La anotación de espacio libre se realiza de forma completamente automática para las imágenes de la cámara. DeepLabV3+ [5] entrenado previamente en Cityscape, ajustado con dos clases (espacio libre y ocupado) en una pequeña parte anotada manualmente del conjunto de datos. El modelo segmenta cada cuadro de video y la máscara de segmentación resultante se proyecta desde el sistema de coordenadas de la cámara al sistema de coordenadas del radar con calibraciones conocidas. Finalmente, el cuadro delimitador ya disponible del vehículo se resta de la máscara de espacio libre. La calidad de las máscaras de segmentación es limitada debido al enfoque automatizado que empleamos y la proyección imprecisa de la cámara al mundo real.
6. Experimenta
6.1 Detalles de la capacitación
La arquitectura propuesta ha sido entrenada en el conjunto de datos RADIal utilizando solo espectros RD como entrada. El espectro RD consta de números complejos, y superponemos las partes real e imaginaria a lo largo del eje del canal antes de pasarlo al precodificador MIMO. El conjunto de datos se divide en conjuntos de entrenamiento, validación y prueba (aproximadamente el 70 %, 15 % y 15 % del conjunto de datos) para que los fotogramas de la misma secuencia no aparezcan en diferentes conjuntos. Dividimos manualmente el conjunto de datos de prueba en casos "difíciles" y "fáciles". Los casos difíciles son principalmente aquellos en los que la señal del radar se ve interferida, por ejemplo, por otros radares, efectos de lóbulo lateral significativos o reflejos significativos de superficies metálicas.
La arquitectura FFT-RadNet se entrena utilizando la pérdida multitarea detallada en la Sección 4.4, y los siguientes hiperparámetros se establecen empíricamente: λ = 100, β = 100 y γ = 2. El proceso de entrenamiento utiliza el optimizador de Adam [18] en 100 épocas con una tasa de aprendizaje inicial de 10 − 4 y un decaimiento de 0,9 cada 10 épocas.
6.2 Línea de base
La arquitectura propuesta ha sido comparada con contribuciones recientes de la comunidad de radares. La mayoría de los métodos de la competencia presentados en la Sección 3 están diseñados para radar LD y no pueden escalar con datos de radar HD debido a limitaciones de memoria. En su lugar, se eligen líneas base con una complejidad similar en términos de representación de entrada (distancia-acimut o nube de puntos) para una comparación justa. Genere representaciones de entrada (RD, RA o nubes de puntos) para todos los conjuntos de entrenamiento, validación y prueba utilizando canalizaciones de procesamiento de señales convencionales.
Detección de objetos con nubes de puntos. Después de voxelizar la nube de puntos del radar con el método Pixor[42], [0 m, 103 m]×[−40 m, 40 m]×[−2,5 m, 2,0 m], y después de muestrear a 0,1 m en cada dirección , se detecta el vehículo. Por lo tanto, el tamaño de esta cuadrícula 3D de entrada es 1030×800×45. Pixor es una arquitectura ligera diseñada para tiempo real. Sin embargo, su representación de entrada produce 96 MB de datos, lo cual es un desafío para los dispositivos integrados.
Tensor RA para detección de objetos. Como se describe en la Sección 3, algunos métodos [11, 23] usan vistas de tensores RAD como entrada. Sin embargo, el uso de la memoria es demasiado grande para los datos de radar de alta resolución. [23] mostró que se puede lograr un mejor rendimiento de detección de objetos utilizando solo la vista RA, por lo que comparamos nuestro método con la arquitectura Pixor sin el módulo de voxelización. Toma la representación RADIal RA como entrada con un tamaño de 512×896, un valor de rango de [0m, 103m] y un acimut de [−90◦, 90◦].
Segmentación del espacio libre. Elegimos PolarNet [29] para evaluar nuestro método. Es una arquitectura liviana diseñada para manejar el mapeo RA y predecir el espacio libre. Lo re-implementamos de acuerdo a nuestro entendimiento.
 Tabla 2: Rendimiento de detección de objetos por agrupación en el equipo de prueba RADIal . Comparación entre Pixor entrenado con representación de nube de puntos ('PC') o rango-acimut ('RA') y FFT-RadNet que solo requiere rango-Doppler ('RD') como entrada. Para un umbral de IOU del 50 %, nuestro método logra un rendimiento general similar o mejor que la línea de base en términos de precisión promedio ("AP") y recuperación promedio ("AR"). También logra una precisión de rango ('R') y ángulo ('A') similar o mejor, lo que demuestra que aprende con éxito una canalización de procesamiento de señales que estima AoA con significativamente menos operaciones, como se muestra en la Tabla 4.
Tabla 2: Rendimiento de detección de objetos por agrupación en el equipo de prueba RADIal . Comparación entre Pixor entrenado con representación de nube de puntos ('PC') o rango-acimut ('RA') y FFT-RadNet que solo requiere rango-Doppler ('RD') como entrada. Para un umbral de IOU del 50 %, nuestro método logra un rendimiento general similar o mejor que la línea de base en términos de precisión promedio ("AP") y recuperación promedio ("AR"). También logra una precisión de rango ('R') y ángulo ('A') similar o mejor, lo que demuestra que aprende con éxito una canalización de procesamiento de señales que estima AoA con significativamente menos operaciones, como se muestra en la Tabla 4.
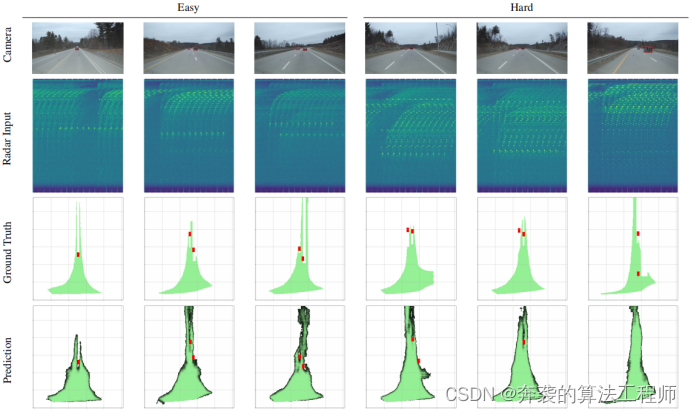
Figura 4: Resultados cualitativos de detección de objetos y segmentación de espacio libre en muestras fáciles y duras . La vista de la cámara (primera fila) se muestra solo como referencia visual; el espectro RD (segunda fila) es la única entrada para el modelo; la realidad del terreno (tercera fila) y las predicciones (cuarta fila) se muestran para ambas tareas. Tenga en cuenta que puede haber errores de proyección de la cámara al espacio de conducción libre del mundo real debido a los cambios de inclinación del vehículo.
6.3 Escala de evaluación
Para la detección de objetos, se utilizan la precisión promedio (AP) y la recuperación promedio (AR) para considerar un umbral de intersección sobre unión (IoU) del 50 %. Para la segmentación semántica, la métrica IoU media (mIoU) se utiliza en una tarea de clasificación binaria (inactiva u ocupada). La métrica se calcula en el rango reducido [0m, 50m], ya que los límites del pavimento son apenas visibles más allá de esta distancia.
6.4 Análisis de desempeño
Detección de objetivos. El rendimiento de la detección de objetos se muestra en la Tabla 2. Observamos que FFT-RadNet que utiliza Range-Doppler como entrada supera la línea de base de Pixor, mientras que el uso de PC como entrada (Pixor-PC) supera ligeramente a la costosa línea de base de Pixor-RA. La precisión de posicionamiento, tanto en distancia como en acimut, es similar, o incluso mejor en ángulo, en comparación con Pixor-RA. Estos resultados demuestran que nuestro método aprende con éxito los acimutes de los datos. Desde el punto de vista de la fabricación, tenga en cuenta que esto abre oportunidades para el ahorro de costes, ya que la calibración del sensor al final de la línea ya no es necesaria en el marco propuesto. En el conjunto de prueba simple, FFT-RadNet proporciona +1,6 % AP y +3,6 % AR en comparación con Pixor-RA. Sin embargo, en la prueba dura, Pixor-RA se desempeña mejor. El enfoque de RA no tiene muchas dificultades para manejar muestras duras, ya que los datos se procesan previamente a través de una canalización de procesamiento de señales que ya aborda algunos de estos casos. Por el contrario, el rendimiento utilizando la entrada de nube de puntos es mucho menor. De hecho, la tasa de recuperación es baja debido al número limitado de puntos a largas distancias.
Segmentación libre del espacio de conducción. El rendimiento de la segmentación del espacio de conducción libre se muestra en la Tabla 3. Observamos que el IoU promedio de FFT-RadNet es significativamente más alto que el de PolarNet en un 13,4 %. Esto se debe en parte a la falta de información de elevación en los mapas RA, que está presente en los espectros RD.

Tabla 3: Rendimiento de la segmentación del espacio de conducción libre. FFT-RadNet aproxima con éxito la información angular en los datos de radar y logra un mejor rendimiento que PolarNet. Tenga en cuenta que FFT-RadNet logra este rendimiento mientras realiza la detección de objetos, ya que nuestro modelo es multitarea.
6.5 Análisis de complejidad
FFT-RadNet está diseñado ante todo para deshacerse de las cadenas de procesamiento de señales que transforman los datos de ADC en nubes de puntos dispersas o representaciones más densas (RA o RAD) sin comprometer la riqueza de la señal. Dado que los datos de entrada aún son bastante grandes, diseñamos un modelo compacto para limitar la complejidad en términos del número de operaciones, como compensación entre el rendimiento y la precisión de rango/ángulo. Además, la capa del precodificador comprime significativamente los datos de entrada. Los investigadores realizaron estudios de ablación para determinar el equilibrio óptimo entre el tamaño del mapa de características y el rendimiento del modelo (consulte el Apéndice B para obtener más detalles).
Como se muestra en la Tabla 4, FFT-RadNet es el único método que no requiere la estimación de AoA. Como se describe en la Sección 2, la capa del precodificador comprime la señal MIMO que contiene toda la información para recuperar el acimut y la elevación. El AoA del método de nube de puntos genera coordenadas 3D para una nube dispersa de alrededor de 1000 puntos en promedio, lo que resulta en una carga computacional de 8GFLOPS antes de aplicar Pixor para la detección de objetos. Para producir tensores RA o RAD, AoA se ejecuta en un solo contenedor del mapa RD, pero solo se considera un paso. Por lo tanto, dicho modelo no puede estimar la altura de objetos como puentes o carga perdida (objetos bajos). Para un lanzamiento, la complejidad es de aproximadamente 45 GFLOPS, pero aumentará a 495 GLPOPS para los 11 lanzamientos. Hemos demostrado que FFT-RadNet puede reducir estos costos de procesamiento sin comprometer la calidad de la estimación.
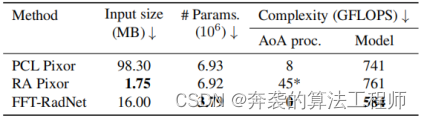
Tabla 4: Análisis de complejidad. El método logra un equilibrio óptimo entre el tamaño de la entrada, el número de parámetros del modelo y la complejidad computacional. Tenga en cuenta que el procesamiento AoA del método RA Pixor (*) solo considera un solo tono, de lo contrario, sería tan alto como 496 GFLOPS para todo el tono BE = 11.
7. Conclusión
Presentamos FFT-RadNet, una nueva arquitectura entrenable para procesar y analizar señales de radar de alta definición. Demostramos que reduce efectivamente el costoso preprocesamiento requerido para estimar las representaciones RA o RAD. En cambio, detecta y estima las ubicaciones de los objetos mientras segmenta directamente el espacio de conducción libre de los espectros de RD. FFT-RadNet supera ligeramente a los métodos basados en RA al tiempo que reduce los requisitos de procesamiento. Los experimentos se realizan en el conjunto de datos RADIal, que es parte del trabajo y contiene secuencias de señales de sensores de grado automotriz (radar de alta definición, cámaras y escáneres láser). Los datos del sensor síncrono se proporcionan en formato sin procesar, por lo que se pueden evaluar varias representaciones y se pueden realizar más estudios, posiblemente con enfoques basados en la fusión.
A. Detalles del conjunto de datos RADIal
Especificaciones de los sensores. Centrado en el conjunto de datos RADIal, nuestro radar HD consta de NRx = 16 antenas de recepción y NTx = 12 antenas de transmisión, para un total de NRx NTx = 192 antenas virtuales. Este conjunto de antenas virtuales puede lograr una alta resolución de azimut al estimar el ángulo de elevación de los objetos. Dado que las señales de radar son difíciles de anotar para los anotadores y los profesionales, se proporciona un escáner láser de grado automotriz (LiDAR) de 16 capas y una cámara RGB de 5 megapíxeles. La cámara se coloca debajo del espejo interior detrás del parabrisas, mientras que el radar y el lidar se montan en el medio de la rejilla de ventilación delantera, uno encima del otro. Los tres sensores tienen líneas de visión horizontales paralelas, apuntando en la dirección de conducción. Sus parámetros externos se proporcionan con el conjunto de datos. RADIal también proporciona seguimiento simultáneo de GPS y CAN, lo que brinda acceso a la ubicación georreferenciada del vehículo, así como a su información de conducción, como la velocidad, el ángulo del volante y la velocidad de guiñada. Consulte la Tabla 5 para conocer las especificaciones del sensor.

Tabla 5: Especificaciones del kit de sensor RADIal. Informe las características clave de HD Radar, LiDAR y Camera. Sus señales de sincronización son compensadas por información GPS y CAN.
Conjunto de datos RADIales. RADIal contiene 91 clips que van de 1 a 4 minutos de duración, para un total de 2 horas. Las secuencias se dividen en conducción en carretera, campo y ciudad. La distribución de secuencias se muestra en la Figura 5. Cada secuencia contiene señales de sensor sin procesar, grabadas a su frecuencia de cuadro nativa. Se proporciona una biblioteca de Python para leer y sincronizar datos. Hay aproximadamente 25000 fotogramas sincronizados con los tres sensores, de los cuales 8252 fotogramas marcan un total de 9550 coches.
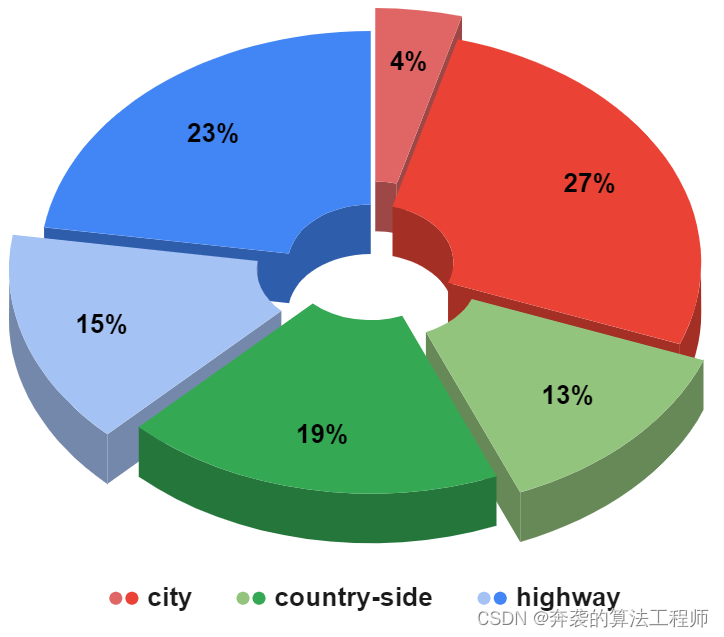 Figura 5: Escala de tipo de escena en RADIal. El conjunto de datos contiene un total de 91 secuencias, capturadas en calles de la ciudad, carreteras o caminos rurales, con un total de 25k cuadros sincronizados (color oscuro), de los cuales 8252 están etiquetados (color claro).
Figura 5: Escala de tipo de escena en RADIal. El conjunto de datos contiene un total de 91 secuencias, capturadas en calles de la ciudad, carreteras o caminos rurales, con un total de 25k cuadros sincronizados (color oscuro), de los cuales 8252 están etiquetados (color claro).
B. Experimento de ablación del precodificador MIMO
El papel del precodificador MIMO es desintercalar los espectros Doppler de rango y transformarlos en una representación compacta que, a través del aprendizaje, todavía permite la predicción del acimut y otra información en el reflector. La entrada al precodificador MIMO consta de espectros Doppler de rango NRx = 16 complejos, uno para cada Rx. Las partes real e imaginaria se superponen, dando como resultado un tensor de entrada de tamaño total BR×BD×2NRx, que es 512×256×32. El estudio de ablación consiste en evaluar el rendimiento del cabezal del detector FFT-RadNet mientras se reduce la salida de volumen de funciones del precodificador MIMO. El número máximo de canales de salida es el número de antenas virtuales con señales complejas (reales e imaginarias), es decir, NTx 2 NRx = 384. Variamos el número de canales de salida de un mínimo de 24 a este máximo y calculamos el rendimiento de detección en el conjunto de validación. Los resultados del estudio de ablación se muestran en la Figura 6. Medimos el rendimiento de detección con la puntuación f1, definida clásicamente como puntuación f1 = AP AR/AP+AR, que agrega la precisión promedio (AP) y el recuerdo promedio (AR) en una sola métrica. Observamos que el mejor rendimiento se alcanza en 192 canales de salida, por lo tanto, la mitad del tamaño máximo de salida. Esta salida comprimida es la que captura la mayor cantidad de información de rango y orientación del espectro Doppler de rango de entrada para tareas de detección y segmentación.

Figura 6: Ablación del precodificador MIMO. El efecto de la cantidad de canales de salida del precodificador en la huella de memoria y el rendimiento del cabezal de detección.
C. Comparación de láser de radar
El conjunto de datos RADIal está diseñado para recopilar información de varias tecnologías de sensores. Para los sistemas críticos para la seguridad, como los vehículos autónomos, creemos que la redundancia en todos los niveles del sistema a partir de la capa de detección es fundamental para garantizar un funcionamiento seguro. En un sistema de conducción autónomo completo, la combinación de radar con cámaras y lidar mejorará la robustez general. De hecho, LiDAR proporciona una localización 3D precisa de objetos en distancia y ángulo, incluso de noche, mientras que las cámaras brindan información semántica y geométrica rica sobre la escena con buena luz . Sin embargo, ambos tipos de sensores están sujetos a condiciones climáticas adversas que pueden degradar en gran medida su rendimiento. El radar es más confiable en condiciones climáticas adversas, puede proporcionar estimaciones precisas de la distancia y la velocidad de los objetos, y es particularmente adecuado para las limitaciones de costo y tamaño de las aplicaciones automotrices .
Como referencia, informamos el rendimiento obtenido en la dirección radial para el radar de imágenes (usando FFT-RadNet) y el sensor lidar (usando Pixor) por separado en la Tabla 6. El primero se desempeñó de manera similar en AP y más bajo en AR que el último, pero aún así fue bueno. Este ya es un resultado notable, debido a las ventajas prácticas de la tecnología de radar, que mencionamos anteriormente. Además, esta diferencia en el rendimiento podría explicarse por la forma en que se creó el conjunto de datos RADIal. Detección/segmentación 2D de la cámara fusionada con información LiDAR 3D, obtención semiautomática de la realidad del terreno. Por lo tanto, la evaluación puede estar sesgada hacia el procesamiento de la entrada LIDAR.
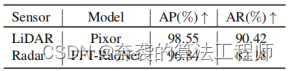
Tabla 6: Resultados de detección de vehículos para radar HD solo y LiDAR solo. Rendimiento de precisión promedio (AP) y recuperación promedio (AR) en el equipo de prueba RADIal. FFT-RadNet toma el espectro Doppler de rango como entrada y Pixor es la nube de puntos LiDAR.
Debido a la naturaleza del proceso de anotación y a los reflejos de trayectos múltiples del radar, muchas secuencias de escenas complejas en entornos urbanos o densos que ocurren en RADIal no se anotan. En la Fig. 7, comparamos cualitativamente la detección de vehículos en esta escena compleja cuando se usa un radar HD o LiDAR. Observamos que el radar HD equipado con FFT-RadNet puede detectar vehículos en situaciones complejas, incluidos vehículos más allá de la primera fila, donde ni las cámaras ni LiDAR funcionan bien.

Figura 7: Ejemplos de detección de vehículos usando radar HD o lidar en escenas complejas. Comparación entre Pixor entrenado con nubes de puntos lidar (columna "Pixor LiDAR", recuadros verdes) y nuestra FFT-RadNet propuesta que solo requiere Doppler de rango como entrada ("FFT-RadNet", recuadros rojos). Tenga en cuenta que la detección de radar no se limita a los vehículos de la primera fila, pero se pueden ver los vehículos de la segunda fila. Además, FFT-RadNet proporciona la velocidad relativa del vehículo a través de mediciones Doppler.