Autor | Pai Pai Xing Editor | CVHub
Haga clic en la tarjeta a continuación para prestar atención a la cuenta pública " Automatic Driving Heart "
Productos secos ADAS Jumbo, puedes conseguirlo
Haga clic para ingresar → Grupo de intercambio técnico de Heart of Autopilot [Segmentación semántica]
Respuesta de fondo [Resumen de segmentación] ¡Obtenga materiales de aprendizaje súper completos, como segmentación semántica, segmentación de instancias, segmentación panorámica y segmentación supervisada débilmente!

Título: Segmente cualquier cosa en
PDF de alta calidad: https://arxiv.org/pdf/2306.01567v1.pdf
Código: https://github.com/SysCV/SAM-HQ
guía
SAM tiene una fuerte capacidad de disparo cero y sugerencias flexibles, aunque ha sido entrenado con 1100 millones de máscaras, su calidad de predicción de máscaras todavía es deficiente en muchos casos, especialmente cuando se trata de objetos estructuralmente complejos.
Con este fin, este documento propone HQ-SAM, que dota a SAM con la capacidad de segmentar con precisión cualquier objeto mientras mantiene el diseño original, la eficiencia y la capacidad de generalización de tiro cero de SAM. El diseño del autor reutiliza y conserva los pesos del modelo previamente entrenados de SAM, al tiempo que introduce solo parámetros y cálculos adicionales mínimos. Al mismo tiempo, también se diseña un token de salida de alta calidad que se puede aprender, que se inyecta en el decodificador de máscaras de SAM y es responsable de predecir máscaras de alta calidad. El método no solo lo aplica a las funciones del decodificador de máscara, sino que primero las fusiona con las funciones ViT iniciales y finales para mejorar los detalles. Para entrenar los parámetros de aprendizaje introducidos, este documento construye un conjunto de datos que contiene máscaras de grano fino de 44K. HQ-SAM se entrena solo en este conjunto de datos de máscara entrante de 44k, que tarda solo 4 horas en 8 GPU.
Finalmente, demostramos la efectividad de HQ-SAM en 9 conjuntos de datos de segmentación diferentes que cubren diferentes tareas posteriores, 7 de los cuales se evalúan en la transferencia de disparo cero.
introducción
La segmentación precisa de diversos objetos es fundamental para una variedad de aplicaciones de comprensión de escenas, incluida la edición de imágenes/videos, la percepción robótica y AR/VR. El modelo "Segment Anything Model" (SAM) está diseñado como un modelo de visión básico para la segmentación general de imágenes, que se entrena con miles de millones de etiquetas de máscara. El modelo SAM puede segmentar una serie de objetos, partes y estructuras visuales en varias escenas aceptando una sugerencia que contiene puntos, cuadros delimitadores o máscaras aproximadas. A pesar del impresionante rendimiento alcanzado por el modelo SAM, sus resultados de segmentación siguen siendo insuficientes en muchos casos, especialmente para tareas de anotación automática y edición de imagen/video, que tienen requisitos extremadamente altos para la precisión de las máscaras de imagen.
Por lo tanto, los autores proponen un nuevo modelo, HQ-SAM, que puede predecir máscaras de segmentación con una precisión extremadamente alta mientras mantiene la capacidad de disparo cero y la flexibilidad del modelo SAM original. Para mantener la eficiencia y el rendimiento de muestra cero, el autor realizó cambios menores en el modelo SAM, agregando solo menos del 0,5 % de los parámetros para mejorar sus capacidades de segmentación de alta calidad. Diseñan un token de salida HQ que se puede aprender que se alimenta al decodificador de máscara de SAM y se entrena para predecir máscaras de segmentación de alta calidad. Además, el token HQ-Output opera con un conjunto de características optimizadas para detalles de máscara precisos.
Para aprender una segmentación precisa, se requiere un conjunto de datos que contenga anotaciones de máscara precisas. Por lo tanto, los autores construyeron un nuevo conjunto de datos llamado HQSeg-44K, que contiene anotaciones de máscara de imagen de grano extremadamente fino de 44K que cubren más de 1000 categorías semánticas diferentes. Debido al pequeño tamaño del conjunto de datos y su arquitectura de conjunto mínima, HQ-SAM tarda solo 4 horas en entrenarse en 8 GPU RTX 3090.
Para verificar la efectividad de HQ-SAM, el autor realizó una gran cantidad de análisis experimentales cuantitativos y cualitativos. Compararon HQ-SAM con SAM en 9 conjuntos de datos de segmentación diferentes que cubrían diferentes tareas posteriores, 7 de los cuales emplearon el protocolo de transferencia de disparo cero. Evaluaciones rigurosas muestran que el HQ-SAM propuesto es capaz de generar máscaras de mayor calidad en comparación con SAM mientras mantiene la capacidad de disparo cero.
método
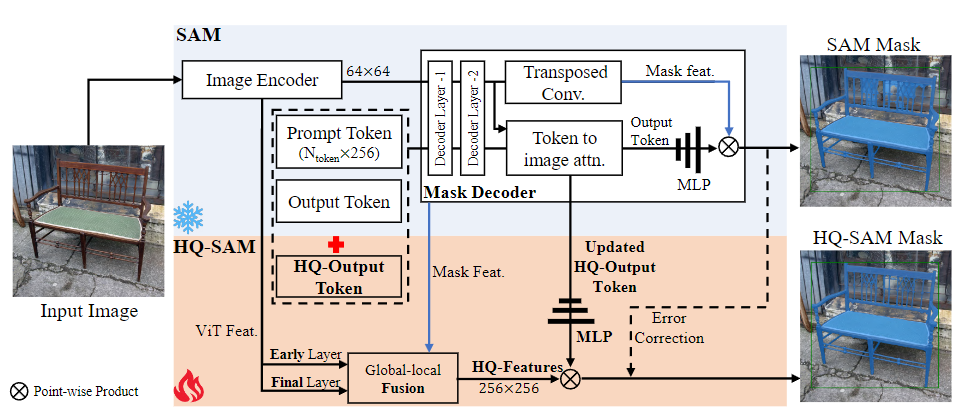
Para lograr una predicción de máscara de alta calidad, HQ-SAM introduce HQ-Output Token (token de salida de alta calidad) y una fusión de características global-local en SAM. Para mantener la capacidad de disparo cero de SAM, el token de salida HQ ligero multiplexa el decodificador de máscara de SAM y genera una nueva capa MLP (perceptrón multicapa) para realizar la misma función que las características HQ fusionadas (alta características de calidad) producto puntual. Durante el entrenamiento, los parámetros del modelo del SAM preentrenado son fijos y solo se pueden entrenar algunos parámetros que se pueden aprender en HQ-SAM.
Con el fin de mejorar el rendimiento del modelo SAM original en la tarea de segmentación de muestra cero, manteniendo sus características de muestra cero. HQ-SAM realiza dos cambios clave en el modelo SAM.
En primer lugar, el autor presenta un nuevo token de salida (token de salida de alta calidad) y una fusión de características global-local basada en el modelo SAM. HQ-Output Token puede guiar mejor la generación de máscaras de alta calidad, mientras que la fusión de características global-local puede extraer y fusionar características de diferentes etapas para enriquecer el contexto semántico global y los detalles de los límites locales de las características de la máscara.
La introducción de HQ-Output Token ha mejorado la capacidad de predicción de máscaras del modelo SAM. En el diseño del modelo SAM original, el decodificador de máscara utiliza un token de salida (similar a la consulta de objetos en DETR) para la predicción de máscara. En HQ-SAM, el autor presenta un nuevo token de salida HQ que se puede aprender y agrega una nueva capa de predicción de máscara para una predicción de máscara de alta calidad.
En segundo lugar, la fusión de características global-local mejora la calidad de la máscara al extraer y fusionar características de diferentes etapas del modelo SAM. Específicamente, los autores fusionaron las funciones de nivel inicial del codificador ViT del modelo SAM, las funciones globales de la última capa del codificador ViT y las funciones de máscara del decodificador de máscara del modelo SAM para generar nuevas funciones de alta calidad. (HQ -Características).

Entrenamiento y comparación de inferencias de SAM y HQ-SAM basados en ViT-L. HQ-SAM impone una carga computacional adicional insignificante a SAM, aumenta los parámetros del modelo en menos del 0,5 % y alcanza el 96 % de su velocidad original. SAM-L está capacitado para 180k iteraciones en 128 GPU A100. Basado en SAM-L, solo toma 4 horas entrenar HQ-SAM en 8 GPU RTX3090.
El proceso de entrenamiento e inferencia de HQ-SAM es eficiente en datos y computación. En la fase de entrenamiento, los autores fijan los parámetros del modelo SAM previamente entrenado y solo entrenan los parámetros de aprendizaje recientemente introducidos en HQ-SAM. En la etapa de inferencia, los autores siguieron el proceso de inferencia de SAM, pero utilizaron la predicción de máscara del token HQ-Output como una predicción de máscara de alta calidad.
En términos generales, en comparación con el modelo SAM original, HQ-SAM mejora la calidad de la segmentación y el proceso de capacitación es más eficiente. Solo se necesitan 4 horas para completar la capacitación en 8 GPU RTX3090. HQ-SAM también es muy liviano, con parámetros de modelo agregados insignificantes, uso de memoria GPU y tiempo de inferencia por imagen.
experimento

SAM se compara con la máscara predicha por nuestro HQ-SAM, y las señales de entrada son el mismo cuadro rojo o algunos puntos en el objeto. HQ-SAM produce resultados más detallados con límites muy precisos. En la columna más a la derecha, SAM malinterpretó la estructura delgada de la cuerda de la cometa y produjo una gran cantidad de errores con agujeros rotos en el mensaje del cuadro de entrada.
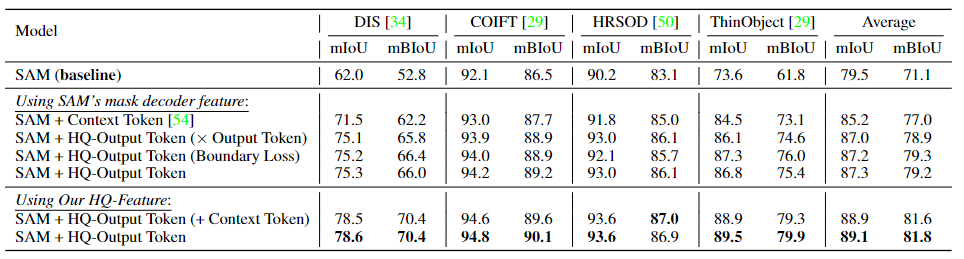
Experimentos de ablación de HQ-Output Token en cuatro conjuntos de datos de segmentación extremadamente detallados. Este documento utiliza las cajas convertidas a partir de sus máscaras GT (Ground Truth, true value) como entrada de solicitud de caja. De forma predeterminada, la máscara de predicción del token de salida HQ se entrena calculando la pérdida total de la máscara GT.
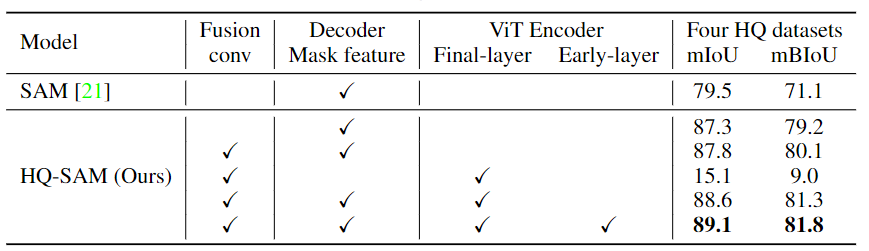
Experimentos de ablación en la fuente de HQ-Features. La capa temprana (early-layer) representa las características después del primer bloque de atención global del codificador ViT, mientras que la capa final (final-layer) representa la salida del último bloque ViT. Los cuatro conjuntos de datos HQ son DIS (conjunto de validación), ThinObject-5K (conjunto de prueba), COIFT y HR-SOD.
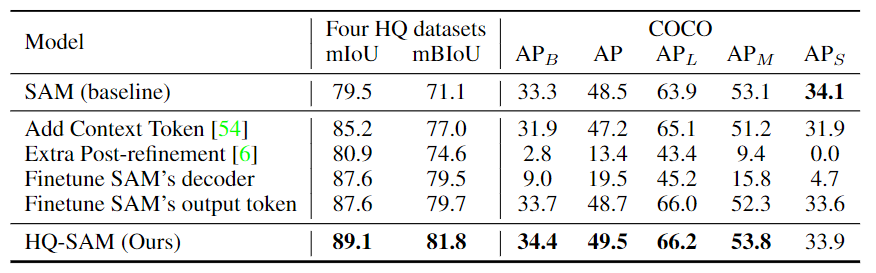
Comparación de ajuste fino del modelo o posprocesamiento adicional. Para el conjunto de datos de COCO, los autores utilizan FocalNet-DINO, un detector de objetos de última generación entrenado en el conjunto de datos de COCO, como generador de pistas de cuadro delimitador.
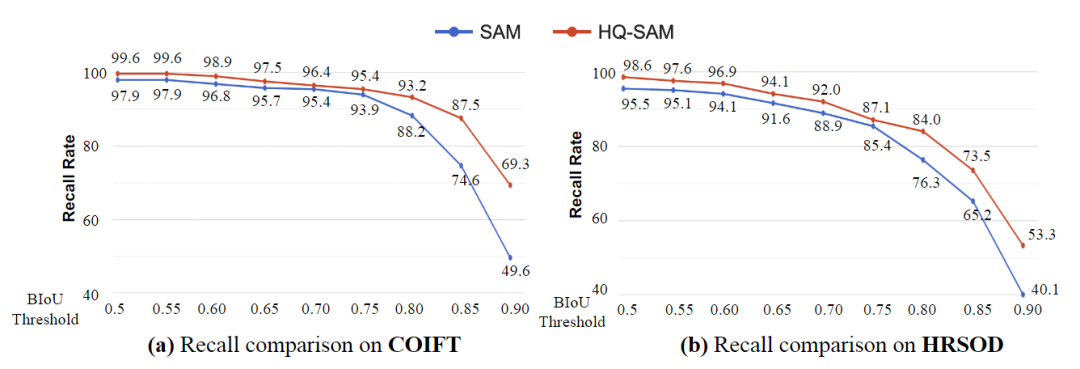
La figura anterior muestra la comparación de recuperación de COIFT y HRSOD bajo el protocolo de disparo cero, usando umbrales de BIoU de flexibles a estrictos. Los resultados muestran que la brecha de rendimiento entre SAM y HQ-SAM aumenta significativamente cuando el umbral varía de 0,5 a 0,9. Esto muestra que HQ-SAM tiene una ventaja en la predicción de máscaras de segmentación muy precisas, es decir, HQ-SAM puede realizar la segmentación de objetos con mayor precisión, especialmente bajo estrictos requisitos de umbral.

Comparación de resultados para la segmentación de instancias de mundo abierto sin disparo en el conjunto de datos UVO. Para generar sugerencias de límites, los autores utilizan el modelo FocalNet-DINO entrenado en el conjunto de datos COCO. donde el símbolo indica que se utiliza un umbral más estricto para definir la región límite.

Comparación de resultados de segmentación de tiro cero en el conjunto de prueba de referencia BIG de alta calidad. Para generar sugerencias de entrada, los autores utilizaron PSPNet para generar sugerencias de máscara gruesa. Los resultados de la segmentación de tiro cero se evalúan comparando diferentes tipos de señales de entrada.
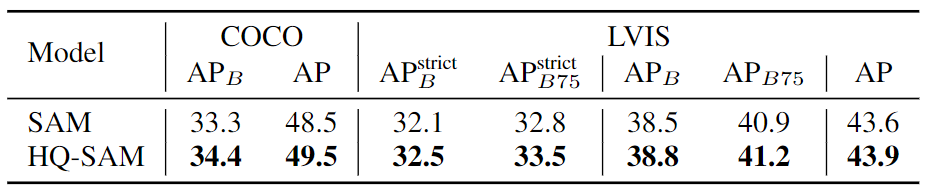
Comparación de resultados de segmentación de instancias de disparo cero en conjuntos de datos COCO y LVISv1. Para el conjunto de datos COCO, los autores usan el modelo FocalNet-DINO entrenado en COCO para la detección, mientras que para el conjunto de datos LVIS, usan ViTDet-H entrenado en el conjunto de datos LVIS como su generador de sugerencias de límites. En el modelo SAM, los autores usaron ViT-L como red troncal y usaron sugerencias de límites. Los autores mejoraron la calidad de la máscara de las regiones límite mientras mantenían la capacidad de segmentación de disparo cero del SAM original.

La figura anterior muestra la comparación de los resultados visuales de SAM y HQ-SAM en la configuración de transferencia de disparo cero, dado el mismo cuadro rojo o sugerencia de punto. Como se puede ver en los resultados, HQ-SAM produce resultados de conservación de detalles significativamente mayores y también corrige agujeros erróneos en la máscara. Por el contrario, HQ-SAM puede preservar mejor los detalles de los objetos y manejar los errores en las máscaras en la tarea de transferencia de disparo cero.
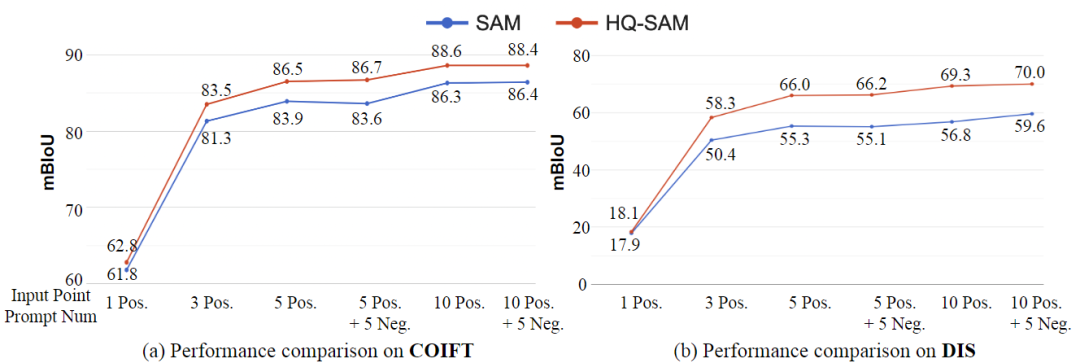
La figura anterior muestra la comparación de los resultados de la segmentación interactiva utilizando diferentes números de puntos de entrada en los conjuntos de validación COIFT (muestra cero) y DIS. Los resultados muestran que HQ-SAM supera consistentemente a SAM en varios puntos, y la mejora relativa es más pronunciada cuando la ambigüedad de la señal es pequeña. Esto muestra que HQ-SAM tiene un mejor rendimiento para diferentes números de puntos de entrada en la tarea de segmentación interactiva, especialmente en el caso de menos puntos de entrada y sugerencias poco claras, el efecto de mejora de HQ-SAM es más obvio.

La tabla anterior presenta los resultados de la comparación para la segmentación de instancias de video de disparo cero en el punto de referencia HQ-YTVIS. En esta comparación, los autores usaron un modelo Mask2Fromer basado en Swin-L, entrenado previamente en el conjunto de datos YTVIS como entrada para las señales del cuadro delimitador, y reutilizaron sus predicciones de asociación de objetos. Con este diseño, los autores evalúan y comparan los métodos de segmentación de instancias de video de disparo cero.
en conclusión
Este documento propone HQ-SAM, el primer modelo que logra una segmentación de disparo cero de alta calidad mediante la introducción de una sobrecarga insignificante en el SAM original, y explora cómo aprovechar y extender las segmentaciones base similares a SAM de manera eficiente en cuanto a datos y computacionalmente económica. Modelo. Los autores introducen un marcador de salida ligero de alta calidad en HQ-SAM para reemplazar el SAM original para la predicción de máscara de alta calidad. Después de entrenar con solo máscaras de alta precisión de 44K, HQ-SAM mejora significativamente la calidad de predicción de máscaras de SAM, que a su vez se entrenó con 1100 millones de máscaras. Los autores realizan evaluaciones de transferencia de disparo cero en siete puntos de referencia de segmentación que incluyen tareas de imagen y video, cubriendo una variedad de objetos y escenas.
(1) ¡El video curso está aquí!
El corazón de la conducción autónoma reúne fusión de visión de radar de ondas milimétricas, mapas de alta precisión, percepción BEV, calibración multisensor, despliegue de sensores, percepción cooperativa de conducción autónoma, segmentación semántica, simulación de conducción autónoma, percepción L4, planificación de decisiones, predicción de trayectoria , etc. Videos de aprendizaje en cada dirección, bienvenido a tomarlo usted mismo (escanee el código para ingresar al aprendizaje)

(Escanea el código para conocer el último video)
Sitio web oficial del vídeo: www.zdjszx.com
(2) La primera comunidad de aprendizaje de conducción autónoma en China
Una comunidad de comunicación de casi 1,000 personas y más de 20 rutas de aprendizaje de pila de tecnología de conducción autónoma, desea obtener más información sobre la percepción de conducción autónoma (clasificación, detección, segmentación, puntos clave, líneas de carril, detección de objetos 3D, Ocupación, fusión de sensores múltiples, seguimiento de objetos, estimación de flujo óptico, predicción de trayectoria), posicionamiento y mapeo de conducción automática (SLAM, mapa de alta precisión), planificación y control de conducción automática, soluciones técnicas de campo, implementación de implementación de modelos de IA, tendencias de la industria, publicaciones de trabajo, bienvenido a escanear el Código QR a continuación, Únase al planeta del conocimiento del corazón de la conducción autónoma, este es un lugar con productos secos reales, intercambie varios problemas para comenzar, estudiar, trabajar y cambiar de trabajo con los grandes en el campo, comparta papeles + códigos + videos diarios , esperamos el intercambio!

(3) [ Corazón de la conducción automatizada ] Grupo de intercambio de tecnología de pila completa
El corazón de la conducción autónoma es la primera comunidad de desarrolladores para la conducción autónoma, que se centra en la detección de objetos, la segmentación semántica, la segmentación panorámica, la segmentación de instancias, la detección de puntos clave, las líneas de carril, el seguimiento de objetos, la detección de objetos en 3D, la percepción de BEV, la fusión de sensores múltiples, SLAM, estimación de flujo de luz, estimación de profundidad, predicción de trayectoria, mapa de alta precisión, NeRF, control de planificación, implementación de modelos, prueba de simulación de conducción automática, administrador de productos, configuración de hardware, búsqueda de trabajo y comunicación de IA, etc.;

Agregue la invitación de Autobot Assistant Wechat para unirse al grupo
Observaciones: escuela/empresa + dirección + apodo