Нажмите на карточку ниже , чтобы обратить внимание на публичный аккаунт « Automatic Driving Heart ».
Сухие товары ADAS Jumbo, вы можете получить их
Сегодня Сердце автономного вождения поделится с вами последними достижениями в области обнаружения линий полосы движения, превзойдя BEV-LaneNet! Наш метод получает 2D- и 3D-предсказания дорожек, применяя функции дорожек к просмотру изображения и функциям BEV соответственно. Если у вас есть связанные работы, чтобы поделиться, пожалуйста, свяжитесь с нами в конце статьи!
>>Нажмите, чтобы войти→ Группа технического обмена в основе автоматического вождения [обнаружение полосы движения]
Редактор | Сердце автопилота

Точное определение линий полосы движения в трехмерном пространстве имеет решающее значение для автономного вождения. Существующие методы обычно сначала преобразуют функции вида изображения в вид с высоты птичьего полета (BEV) с помощью отображения обратной перспективы (IPM), а затем определяют линии дорожек на основе функций BEV. Однако IPM игнорирует изменения высоты дороги, что приводит к неточным переходам между видами. Кроме того, два независимых этапа процесса могут привести к кумулятивным ошибкам и увеличению сложности. Чтобы устранить эти ограничения, мы предлагаем эффективный преобразователь для трехмерного обнаружения дорожек. В отличие от ванильного преобразователя, модель включает факторизованный механизм перекрестного внимания для одновременного изучения представлений дорожек и BEV. Этот механизм разлагает перекрестное внимание между изображениями и функциями BEV на взаимное внимание между изображениями и функциями дорожек и взаимное внимание между полосами и функциями BEV, оба из которых контролируются линиями дорожек GT.
Наш метод получает 2D- и 3D-предсказания дорожек, применяя функции дорожек к просмотру изображения и функциям BEV соответственно. Это позволяет выполнять более точные преобразования представлений, чем методы на основе IPM, поскольку преобразования представлений изучаются на основе данных с контролируемым перекрестным вниманием. Кроме того, перекрестное внимание между функциями полосы движения и BEV позволяет им настраивать друг друга для более точного обнаружения полос движения, чем два отдельных этапа. Наконец, разложенное перекрестное внимание более эффективно, чем исходное перекрестное внимание, и результаты экспериментов на OpenLane и ONCE-3DLanes демонстрируют современную производительность нашего метода!
Недостатки нынешних основных методов в этой области
Обнаружение полосы движения является ключевым компонентом вспомогательных и автономных систем вождения, поскольку оно позволяет выполнять ряд последующих задач, таких как планирование маршрута, помощь в удержании полосы движения и построение карты высокой четкости (HD). В последние годы алгоритмы обнаружения полос на основе глубокого обучения достигли впечатляющих результатов в пространстве 2D-изображений, однако в практических приложениях линии дорожек обычно необходимо представлять в 3D-пространстве или с высоты птичьего полета (BEV). Это особенно полезно для задач, связанных с взаимодействием с окружающей средой, таких как планирование и контроль.
Типичный конвейер 3D-обнаружения дорожек заключается в том, чтобы сначала обнаружить линии дорожек в представлении изображения, а затем спроецировать их в BEV. Проецирование обычно достигается с помощью карты обратной перспективы (IPM), предполагающей плоскую поверхность дороги, однако, как показано на рисунке 1, поскольку изменение высоты дороги игнорируется, IPM приведет к расхождению проецируемых линий полосы движения в случае подъема или спуска. или сходятся. Чтобы решить эту проблему, SALAD предсказывает истинную глубину линии дорожки и положение просмотра ее изображения, а затем проецирует ее в трехмерное пространство, используя входную/выходную проекцию камеры, однако оценка глубины не является точной на определенном расстоянии, что влияет на качество изображения. точность проекции!
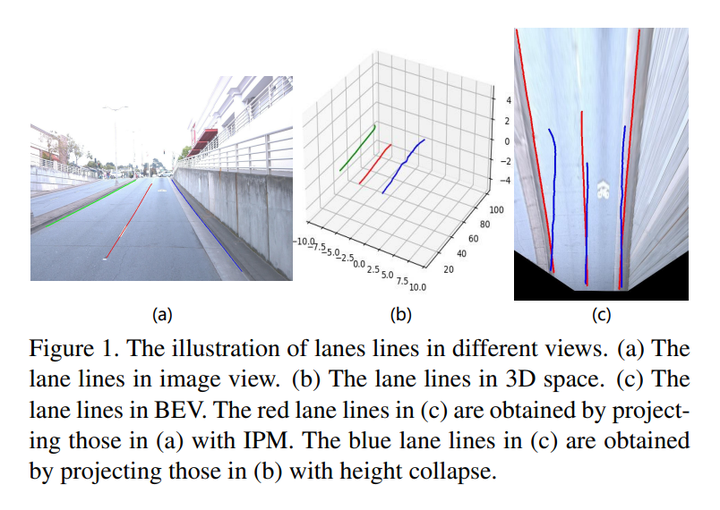
Современные методы, как правило, предсказывают трехмерную структуру линий дорожек непосредственно из BEV, они сначала преобразуют карты характеристик изображения в BEV с помощью IPM, а затем обнаруживают линии дорожек на основе карт характеристик BEV. Однако, как показано на рис. 1(c), из-за плоского допущения IPM наземные 3D-линии полосы движения (синие линии) не совпадают с элементами полосы движения BEV (красные линии) при столкновении с неровными дорогами. Чтобы решить эту проблему, некоторые методы представляют виртуальные виды сверху вниз, сначала проецируя наземные 3D-линии полосы движения на плоскость изображения, а затем проецируя их на ровную плоскость дороги с помощью IPM (красные линии на рисунке, параграф 1 (c). 3D-трассировки в формате . Затем эти методы предсказывают истинную высоту линии дорожки и ее положение в виртуальном виде сверху и, наконец, проецируют ее в трехмерное пространство посредством геометрического преобразования. Однако точность прогнозируемой высоты значительно влияет на преобразованное положение BEV, что влияет на надежность модели, и, кроме того, разделение преобразования вида и обнаружения полосы движения приводит к кумулятивной ошибке и увеличению сложности.
Чтобы преодолеть эти ограничения существующих методов, в документе предлагается эффективный переносчик для обнаружения трехмерных дорожек.Наша модель включает факторизованный механизм внимания для одновременного изучения представлений полос и BEV под наблюдением. Этот механизм разлагает перекрестное внимание между изображениями и элементами BEV на взаимное внимание между изображениями и элементами дорожек и взаимное внимание между BEV и элементами дорожек. полученные путем применения функций полосы движения к изображению и функциям BEV соответственно!
Чтобы достичь этого, динамические ядра генерируются для каждой линии дорожки в соответствии с особенностями дорожки, а затем представление изображения и карта признаков BEV свертываются с этими ядрами, и соответственно получаются представление изображения и карта смещения BEV. Карта смещений предсказывает смещение каждого пикселя до ближайшей точки дорожки в 2D- и 3D-пространстве, которое обрабатывается с использованием алгоритма голосования для получения окончательных точек 2D- и 3D-дорожки соответственно. Поскольку перевод представлений изучается на основе данных с контролируемым перекрестным вниманием, он более точен, чем перевод представлений на основе IPM. Кроме того, функции полосы движения и BEV могут быть динамически согласованы друг с другом посредством перекрестного внимания, что приводит к более точному обнаружению полосы движения, чем два отдельных этапа. Наше факторизованное перекрестное внимание более эффективно, чем стандартное перекрестное внимание между просмотрами изображений и функциями BEV. Эксперименты на двух эталонных наборах данных, включая OpenLane и ONCE-3Lanes, демонстрируют эффективность и действенность нашего метода.
Трехмерные линии дорожек и метод трансформатора
Трехмерное обнаружение полосы движения может быть реализовано в виде изображения. Некоторые методы сначала обнаруживают 2D-линии дорожек в виде изображения, а затем проецируют их на вид с высоты птичьего полета. Были предложены различные методы для решения проблемы обнаружения 2D-полос, включая методы на основе привязки, на основе параметров и на основе сегментации. Что касается проекции линии полосы движения, в некоторых методах используется отображение обратной перспективы (IPM), что приводит к тому, что проецируемые линии полосы движения расходятся или сходятся при столкновении с неровными дорогами, возникающими в результате плоскостного предположения.
Чтобы решить эту проблему, SALAD предсказывает истинную глубину линии дорожки и положение ее изображения, а затем проецирует ее в BEV с проекцией входа/выхода камеры. Однако оценка глубины неточна на определенном расстоянии, что влияет на точность проекции, а другие методы напрямую предсказывают трехмерную структуру линий дорожек из изображения. Например, CurveFormer применяет преобразователь для прогнозирования параметров 3D-кривых линий дорожек непосредственно из объектов изображения, а Anchor3DLane проецирует якоря дорожек, определенные в 3D-пространстве, на карты объектов изображения и извлекает их функции для классификации и регрессии. из-за ограничений низкого разрешения функций удаленного просмотра изображений!
Трехмерное обнаружение линии полосы движения при BEV
Другой способ обнаружения трехмерных дорожек состоит в том, чтобы сначала преобразовать карту объектов представления изображения в BEV, а затем обнаружить линии дорожек на основе карты признаков BEV, где преобразование представления обычно основано на IPM. Например, некоторые методы используют сеть пространственного преобразования (STN) для преобразования представления, где сетка дискретизации STN создается с помощью IPM. PersFormer использует деформируемый преобразователь для преобразования вида, где опорная точка декодера преобразователя генерируется IPM!
Однако из-за плоскостного допущения IPM наземные 3D-линии полосы движения не совпадают с основными функциями полосы движения BEV при столкновении с неровными дорогами. Чтобы решить эту проблему, некоторые методы представляют наземные 3D-линии дорог в виртуальном виде сверху, сначала проецируя наземные 3D-линии дорожек на плоскость изображения, а затем используя IPM для проецирования результата на плоскую поверхность. земля. Реальная высота линии полосы движения и ее положение в виртуальном виде сверху прогнозируются, а затем проецируются в трехмерное пространство путем геометрического преобразования. Однако точность прогнозируемой высоты может существенно повлиять на преобразованное местоположение BEV и, следовательно, на надежность модели. BEV LaneDet применяет многослойный персептрон (MLP) для лучшего преобразования представления, однако размер его параметров очень велик!
внимание в трансформаторе
Механизм внимания в преобразователе требует попарного вычисления подобия между запросами и ключами, что усложняется при большом количестве запросов и ключей. Чтобы решить эту проблему, некоторые методы фокусируются только на подмножестве ключевых слов для каждого запроса, а не на всем наборе при вычислении матрицы внимания. CCNet предлагает модуль внимания, который собирает контекстную информацию только для всех пикселей на своем перекрестном пути, а Deformable DETR предлагает модуль внимания, который фокусируется только на одном пикселе, отобранном вокруг изученной контрольной точки, небольшое количество ключевых точек. Swin-Transformer предлагает модуль сдвинутого окна, который ограничивает собственное внимание неперекрывающимися локальными окнами, а также позволяет использовать соединения между окнами, а другие методы применяют приближения низкого ранга для ускорения вычисления матриц внимания. Nystromformer использует метод Нистрома для восстановления исходной матрицы внимания, что сокращает объем вычислений. Nystromformer использует случайно выбранные функции для разложения низкого ранга, в то время как наш метод разлагает исходную матрицу внимания на две части низкого ранга в соответствии с запросом полосы, и каждая часть может контролироваться GT, что больше подходит для задачи обнаружения полосы 3D, существующие аппроксимации трансформатора обычно жертвуют некоторой точностью, в то время как наш метод обеспечивает лучшую производительность, чем исходный трансформатор!
введение метода
В этой статье предлагается эффективный преобразователь для сквозного обнаружения трехмерных дорожек, сначала представлена общая структура, а затем подробно описывается каждый компонент, включая эффективный модуль преобразователя, головку обнаружения канала и бинарное согласование потерь! Общая структура показана на рис. 2, которая начинается с магистрали CNN для извлечения карт признаков представления изображения из входного изображения. Затем эффективный модуль-трансформер изучает характеристики полосы движения и вида с высоты птичьего полета (BEV) из характеристик изображения, используя факторизованный механизм перекрестного внимания. Функции просмотра изображений и BEV добавляют позиционные вложения с соответствующими позиционными кодировщиками. Затем головка обнаружения дорожки использует характеристики дорожки для создания набора динамических ядерных и целевых показателей для каждой дорожки. Затем эти ядра используются для свертки карт представления изображения и карт объектов BEV для создания карт представления изображения и карт смещения BEV соответственно. Эти два набора карт смещения обрабатываются с помощью алгоритма голосования для получения окончательных точек 2D- и 3D-дорожки соответственно, а для обучения модели вычисляются двудольные потери соответствия между 2D/3D-прогнозами и наземной истиной.
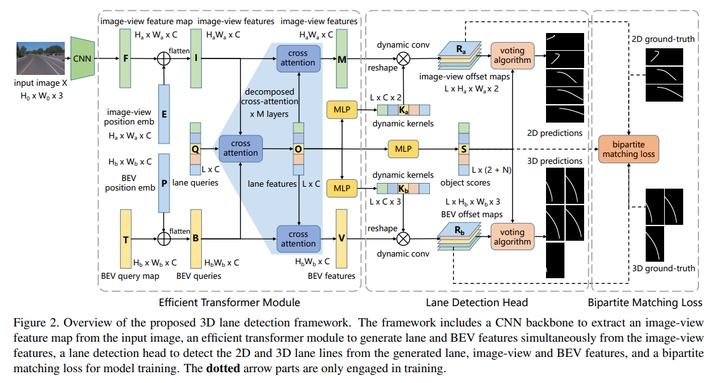
Эффективный трансформаторный модуль
Как показано на рис. 2, при наличии входного изображения X∈R^{H_0×W_0×3} мы сначала используем магистраль CNN для извлечения карты признаков представления изображения F∈R^{H_a×W_a×C}, где Ha , Wa и C — высота, ширина и канал F соответственно. Карта признаков F добавляется с позиционными вложениями E ∈ R^{H_a×W_a×C}, сгенерированными кодировщиком положения (как описано в разделе 3.3), а затем сглаживается до последовательности I ∈ R^{H_a×W_a×C}. . Инициализируется карта запросов BEV T ∈ R^{H_b×W_b×C} с изучаемыми параметрами, которая также добавляет еще одно сгенерированное кодировщиком положения вложение позиции P ∈ R^{H_b×W_b×C}. Затем она сглаживается в последовательность B ∈ R^{H_b×W_b×C}.
После получения функций просмотра изображений и запросов BEV инициализируется набор запросов дорожек Q ∈ {R^{L×C}} с параметрами, которые можно обучить, представляющие L различных прототипов линий дорожек. Затем функция дорожки O ∈ {R ^ {L × C}} изучается из функции просмотра перекрестного внимания I и запроса BEV B, пусть O_i ∈ R ^ C обозначает, что i-я функция дорожки соответствует i- th переулок запрос Qi, и Oi может получить его:
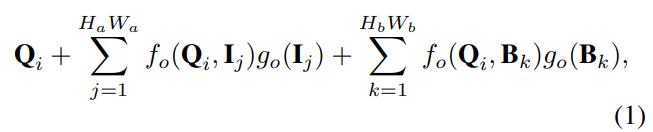
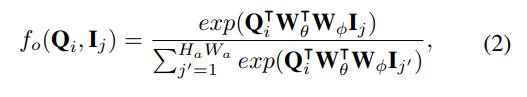
Затем функция BEV V строится в соответствии с характеристикой полосы движения O, и внимание к перекрестку выглядит следующим образом:
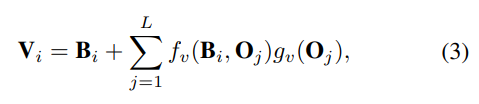
где gv( ) и fv( , ) имеют ту же форму, что и go( ), fo( , .) в уравнении соответственно, за исключением их обучаемых весовых матриц. Таким образом, исходное перекрестное внимание между функцией V BEV и функцией просмотра изображения I, показанное на рис. 3, разлагается на перекрестное внимание между функцией I просмотра изображения и функцией O полосы движения, а также перекрестное внимание между функцией O полосы движения и функцией V BEV. Перекресток внимание!
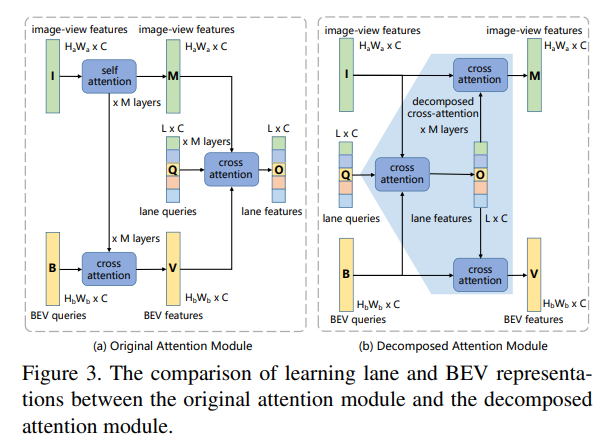
По сравнению с исходным перекрестным вниманием разложенное перекрестное внимание дает три преимущества. Во-первых, он обеспечивает лучшее преобразование вида за счет контроля разложенного перекрестного внимания на 2D- и 3D-линиях наземной дорожки. 2D- и 3D-предсказания дорожек получаются путем применения признаков O дорожек к функциям просмотра изображения I и функциям BEV V соответственно. Во-вторых, динамическая регулировка между характеристикой полосы движения O и характеристикой V BEV осуществляется за счет перекрестного внимания, что повышает точность трехмерного обнаружения полосы движения. В-третьих, это значительно сокращает объем вычислений и повышает эффективность работы в реальном времени!
Точно так же функции просмотра изображения I обновляются функциями объекта O с перекрестным вниманием следующим образом:
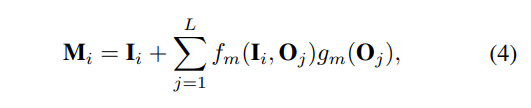
По сравнению с исходным собственным вниманием, разложенное собственное внимание обеспечивает динамическую настройку между функциями полосы O и функциями просмотра изображения I посредством перекрестного внимания, тем самым повышая точность обнаружения 2D-полосы. Кроме того, поскольку обе функции изображения M и функции BEV V созданы из функций объекта O, их можно лучше совместить друг с другом!
Встраивание позиции
Для встраивания E положения просмотра изображения в пространстве камеры сначала строится трехмерная координатная сетка G, где D — количество дискретных интервалов глубины. Каждая точка в G может быть выражена как pj = (uj×dj, vj×dj, dj, 1), где (uj, vj) — соответствующая координата пикселя на карте характеристик представления изображения F, а dj — соответствующее значение глубины. . Затем сетка G преобразуется в сетку G′ в трехмерном пространстве следующим образом:

Предсказать распределение высоты Z ∈ R^{H^b×W^b×Z} по T, указав вероятность того, что каждый пиксель принадлежит каждому элементу высоты, а затем получить положение, встраивающее P, следующим образом:
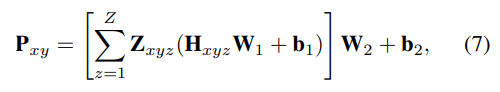
Головка обнаружения полосы движения
Во-первых, два многослойных персептрона (MLP) применяются к дорожке O для создания двух наборов динамических ядер K_a∈R^{L×C×2} и K_b∈R^{R×C×3} соответственно. Затем K_a и K_b применяются для свертки функции M просмотра изображения и функции V BEV для получения карты смещения представления изображения R_a∈R^{L×Ha×Wa×2} и карты смещения BEV R_b∈R^{L×Hb ×Вб×3}. Ra предсказывает горизонтальное и вертикальное смещения каждого пикселя в представлении изображения до ближайшей к нему точки дорожки; Rb предсказывает смещение каждого пикселя в направлениях x и y до ближайшей точки дорожки в BEV, а также фактическую высоту точка переулка!
Затем к характеристикам дорожки O применяется другой MLP для получения целевых показателей S ∈ R^{L×(2+N)}, включая фон, передний план и вероятности для N классов дорожки. Затем карты смещения изображения Ra и BEV обрабатывают карту смещения Rb с помощью алгоритма голосования, чтобы получить 2D- и 3D-точки дорожек соответственно. Процесс Rb показан в алгоритме 1 (аналогичен Ra, за исключением того, что z и r удалены), алгоритм голосования голосует за предсказанные точки дорожки всех пикселей, а затем выбирает те точки, чьи голоса превышают пороговое значение ширины дорожки w для формируют прогнозируемую линию полосы движения и, наконец, сохраняют в качестве выходных данных только предсказанные линии полосы движения, вероятность переднего плана которых превышает порог объекта t.

Потеря двудольного сопоставления

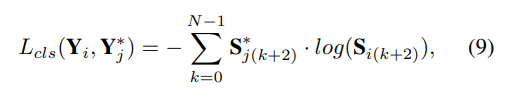
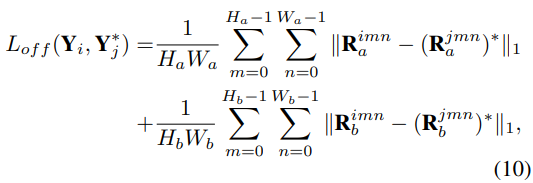
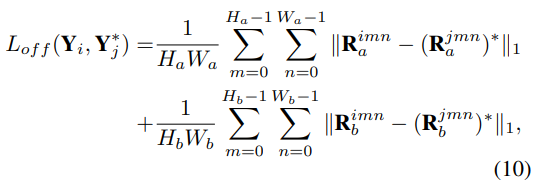
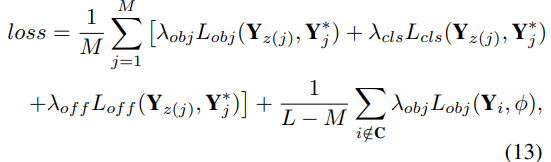
Результаты эксперимента
Эксперименты проводятся на двух тестах обнаружения 3D-полос: OpenLane и ONCE-3DLanes, OpenLane содержит 160 000 и 40 000 изображений для обучающего и проверочного наборов соответственно! Набор проверки включает шесть различных сценариев, включая кривые, пересечения, ночное время, экстремальные погодные условия, слияние и разделение, а также движение вверх и вниз. Он аннотирует 14 категорий полос, включая край дороги, двойную желтую сплошную полосу и т. д. ONCE-3D Lane содержит изображения 200K, 3K и 8K для обучения, проверки и тестирования соответственно, охватывая различное время утреннего, дневного, дневного и ночного сегментов, включая солнечные, облачные и дождливые погодные условия, а также центральные районы, пригороды, дороги, мосты и туннели.
Регрессия с F-показателем, точностью сопоставления дорожек для классификации и редактированием расстояния для сопоставления прогнозов с наземной истиной, где полосы прогнозируются только в том случае, если 75% y-позиций находятся в пределах поточечного расстояния, меньшего, чем максимально допустимое расстояние 1,5 метра Только тогда он считается истинным переулком. Для дорожек ONCE-3D используется двухэтапная оценочная метрика для измерения сходства между предсказанными дорожками и дорожками GT. Сначала используйте традиционный метод IoU для сопоставления дорожки в виде сверху. Если IoU больше порогового значения (0,3), используйте одностороннее расстояние снятия фаски для расчета ошибки сопоставления кривой. Если расстояние снятия фаски меньше порогового значения (0,3 метра), то спрогнозированная полоса считается реальной полосой движения.
Используются ResNet-18, ResNet-34, EfficientNet (-B7), а предварительно обученные веса ImageNet используются в качестве основы CNN. Входные изображения дополняются случайными горизонтальными переворотами и случайными поворотами, а их размер изменяется до 368×480. Пространственное разрешение карты признаков BEV составляет 50 × 32, представляя пространство BEV с диапазоном [-10, 10] × [3, 103] метров по направлениям x и y соответственно. Размер карты смещения BEV изменяется до 400 × 256 для окончательного прогноза. AdamW оптимизирован, бета равны 0,9 и 0,999, а уменьшение веса равно 1e−4. Размер bs установлен на 16, и мы обучаем модель на 50 эпох.
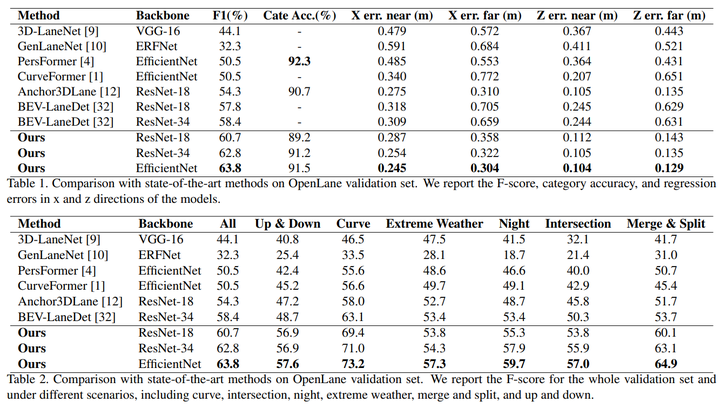
Производительность набора данных OpenLane, результаты сравнения на OpenLane показаны в таблице 1. Используя ResNet18 в качестве основы, наш метод достигает F-показателя 60,7, что на 10,2, 6,4 и 2,9 выше, чем у PersFormer, Anchor3DLane и BEV LaneDet соответственно. Самые низкие ошибки прогнозирования также получаются в направлениях x, y и z, как показано в таблице 2, и наш метод достигает наилучшей производительности во всех шести сценариях, демонстрируя свою надежность. Например, для сценариев «вверх и вниз», «кривая», «пересечение» и «слияние и разделение» с использованием ResNet-34 в качестве основы F-показатель на 8,2, 7,9, 5,6 и 9,4 выше, чем у BEV LaneDet. , соответственно. На рис. 5 показаны результаты качественного сравнения OpenLane, включая сценарии подъема, спуска, поворота и разветвления, и результаты сравнения показывают, что полосы движения на неровных дорогах и полосы движения со сложной топологией могут обрабатываться хорошо.
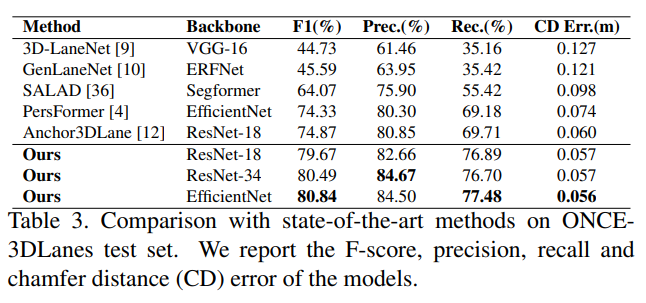
Производительность набора данных ONCE-3DLanes и результаты сравнения полос ONCE-3D показаны в таблице 3. Используя ResNet-18 в качестве основы, наш метод получил F-оценку 79,67, что на 15,60 балла выше, чем у SALAD, PersFormer. и Anchor3DLane соответственно.При оценке 5,34 и 4,80 также достигается наименьшая ошибка CD, что свидетельствует о хорошей точности предложенного метода.

Влияние декомпозиции внимания, в статье сравниваются результаты предложенной декомпозиции внимания и внимания на основе IPM. Внимание на основе IPM используется в PersFormer для преобразования представления, где IPM используется для вычисления контрольной точки преобразователя. Как показано в Таблице 4, исходное внимание работает немного лучше, чем внимание, основанное на IPM, а разложенное внимание получает на 3,3 и 2,3 более высокие баллы F1, чем исходное внимание на OpenLane и ONCE-3Lanes соответственно. Это связано с тем, что декомпозированное внимание обеспечивает более точные переходы между видами с помощью 2D и 3D GT для наблюдения за перекрестным вниманием между изображениями и функциями дорожек, а также за взаимным вниманием между функциями дорожек и BEV, и, кроме того, повышает точность трехмерных дорожек. обнаружение путем динамической настройки между полосой движения и функциями BEV!

ссылка
[1] Эффективный преобразователь для одновременного изучения BEV и представлений дорожек при 3D-обнаружении дорожек.
(1) Видеокурс здесь!
Сердце автономного вождения объединяет слияние радиолокационного зрения миллиметрового диапазона, высокоточные карты, восприятие BEV, калибровку датчиков, развертывание датчиков, совместное восприятие автономного вождения, семантическую сегментацию, моделирование автономного вождения, восприятие L4, планирование решений, прогнозирование траектории и т. д. , Направленное обучающее видео, добро пожаловать, чтобы взять его самостоятельно (отсканируйте код, чтобы войти в обучение)

(Сканируйте код, чтобы узнать последнее видео)
Официальный сайт видео: www.zdjszx.com
(2) Первое сообщество по обучению автономному вождению в Китае.
Коммуникационное сообщество, насчитывающее около 1000 человек, и более 20 обучающих маршрутов по технологии автономного вождения, хотят узнать больше о восприятии автономного вождения (классификация, обнаружение, сегментация, ключевые точки, линии полосы движения, обнаружение трехмерных объектов, присутствие, объединение нескольких датчиков, отслеживание объектов, оценка оптического потока, прогнозирование траектории), автоматическое позиционирование и картирование вождения (SLAM, высокоточная карта), автоматическое планирование и управление вождением, полевые технические решения, внедрение модели ИИ, отраслевые тенденции, выпуски вакансий, добро пожаловать на сканирование QR-код ниже. Присоединяйтесь к планете знаний в сердце автономного вождения, это место с настоящими галантереями, обменивайтесь различными проблемами при начале работы, учебе, работе и смене работы с большими парнями в этой области, делитесь документами + кодами. + видео ежедневно , ждем обмена!

(3) [ Сердце автоматизированного вождения ] Группа полного цикла по обмену технологиями
The Heart of Autonomous Driving — это первое сообщество разработчиков для автономного вождения, основное внимание в котором уделяется обнаружению объектов, семантической сегментации, панорамной сегментации, сегментации экземпляров, обнаружению ключевых точек, линиям полосы движения, отслеживанию объектов, обнаружению 3D-объектов, восприятию BEV, объединению нескольких датчиков, SLAM, оценка светового потока, оценка глубины, прогнозирование траектории, высокоточная карта, NeRF, управление планированием, развертывание модели, тест автоматического моделирования вождения, менеджер по продукту, конфигурация оборудования, поиск работы и общение с ИИ и т. д .;

Добавить приглашение Autobot Assistant Wechat присоединиться к группе
Примечания: школа/компания + направление + никнейм