Hash especial de algoritmo, mapa de bits, conjunto, filtro Bloom, segmentación de palabras chinas, índice invertido de Lucene
Picadillo
pensar:
- Déle N (1<N<10) números naturales, y el rango de cada número es (1~100). Ahora deja que juzgues si un cierto número está dentro de estos N números a la velocidad más rápida, y no debes usar la clase empaquetada.
- Déle N (1<N<10) números naturales, y el rango de cada número es (1~10000000000). Ahora deja que juzgues si un cierto número está dentro de estos N números a la velocidad más rápida, y no debes usar la clase empaquetada, cómo lograrlo. A[] = nuevo int[N+1]?
tabla de picadillo
La tabla hash es Hash Table en inglés, que es como solemos llamar a la tabla hash, seguro que la has oído muchas veces, de hecho, el ejemplo que acabamos de mencionar arriba se resuelve usando la idea de la tabla hash.
La tabla hash utiliza la característica de que la matriz admite el acceso aleatorio a los datos de acuerdo con el subíndice. 散列表其实就是数组的一种扩展,由数组演化而来。Se puede decir que si no hay matriz, no habrá tabla hash
De hecho, este ejemplo ya ha utilizado la idea de hashing. En este ejemplo, N es un número natural y forma un mapeo uno a uno con el subíndice de la matriz, por lo que se utiliza la función de acceso aleatorio basada en el subíndice de la matriz.
La complejidad temporal de la búsqueda es O(1), lo que puede determinar rápidamente si el elemento existe en la secuencia
Conflicto de hash
Direccionamiento abierto: la idea central del método de direccionamiento abierto es que si hay una colisión hash, volveremos a detectar una ubicación libre y la insertaremos
Cuando insertamos datos en la tabla hash, si la función hash codifica ciertos datos y la ubicación de almacenamiento ya está ocupada, comenzamos desde la ubicación actual y buscamos hacia atrás uno por uno para ver si hay una ubicación libre hasta que encontremos eso...
defecto:
- La eliminación requiere un manejo especial
- Si se insertan demasiados datos, se producirán muchos conflictos en la tabla hash. La búsqueda puede degenerar en transversal.
Dirección de enlace: use una lista enlazada, el método de lista enlazada es un método de resolución de conflictos hash más comúnmente utilizado, que es mucho más simple que el método de direccionamiento abierto
Optimización de lista enlazada de HashMap Hash conflict
Dado que la estructura de la lista enlazada tiene algunas deficiencias, se ha optimizado en nuestro JDK y se ha introducido una estructura de datos más eficiente:
árbol negro rojo
-
Tamaño inicial: el tamaño inicial predeterminado de HashMap es 16. Este valor predeterminado se puede configurar.Si conoce el volumen de datos aproximado de antemano, puede reducir la cantidad de expansiones dinámicas modificando el tamaño inicial predeterminado, lo que mejorará en gran medida el rendimiento de Hash Map.
-
Expansión dinámica: el factor de carga máximo es 0,75 por defecto. Cuando se supera el número de elementos en HashMap
0.75*capacity(la capacidad indica la capacidad de la tabla hash), la expansión comenzará y cada expansión se expandirá al doble del tamaño original -
Resolución de conflictos hash: JDK1.7 utiliza el método de lista enlazada en la parte inferior. En la versión JDK1.8, para optimizar aún más HashMap, introdujimos un árbol rojo-negro. Y cuando la longitud de la lista enlazada es demasiado larga (el valor predeterminado supera los 8), la lista enlazada se convierte en un árbol rojo-negro. Podemos usar las características del árbol rojo-negro para agregar, eliminar, modificar y verificar rápidamente para mejorar el rendimiento de HashMap. Cuando el número de nodos del árbol rojo-negro es inferior a 8, el árbol rojo-negro se convertirá en una lista enlazada. Porque en el caso de una pequeña cantidad de datos, el árbol rojo-negro necesita mantener el equilibrio y la ventaja de rendimiento no es obvia en comparación con la lista enlazada.
int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & (capitity -1); //capicity表示散列表的大小,最好使用2的整数倍
}
Diseñe una tabla hash de nivel empresarial eficiente
Aquí puedes aprender de las ideas de diseño de HashMap:
- Debe ser eficiente: es decir, la inserción, el borrado y la búsqueda deben ser rápidos.
- Memoria: no ocupe demasiada memoria, considere usar otras estructuras, como B+Tree, HashMap 1 billón, algoritmo para almacenar disco duro: mysql B+tree
- Función hash: esto debe considerarse de acuerdo con la situación real.%
- Expansión: Es para estimar el tamaño de los datos.El espacio por defecto de HashMap es 16? Sé que necesito guardar 10000 números,
2^n > 10000 or 2^n-1 - Cómo resolver el conflicto Hash: matriz de lista enlazada
aplicación hash
- Cifrado: algoritmo hash MD5, irreversible
- Determinar si el video se repite
- detección de similitud
- balanceo de carga
- Sub-base de datos distribuida y sub-tabla
- almacenamiento distribuido
- Algoritmo de búsqueda HashMap
Problemas con el algoritmo de expansión Hash en subprocesos múltiples
- Operación de colocación de subprocesos múltiples, obtendrá un bucle infinito (). De hecho, esto se puede optimizar. Por ejemplo, al expandir la capacidad, abrimos un nuevo arreglo en lugar de usar el arreglo compartido.
- La opción de subprocesos múltiples puede causar un error de obtención de valor
¿Por qué hay un bucle infinito?
- Cuando hay un conflicto hash, usaremos una estructura de cadena para guardar el valor en conflicto. Si estamos atravesando la lista enlazada como esta 1->2->3->null
- Si viajamos a 3 en sí, debería ser nulo. En este momento, alguien acaba de calcular el valor de este nulo, nulo => 1-> 3, y esto ha terminado. Se suponía que el 3 original apuntaba al final de nulo , y ahora cambia de nuevo. Cheng apunta a 1, y este 1 solo apunta a 3, por lo que continuará en bucle
mapa de bits
Escenas
- Juicio de peso de datos
- Ordenar sin repetir datos
defecto
- los datos no se pueden repetir
- No hay ninguna ventaja cuando la cantidad de datos es pequeña
- No se pueden manejar las colisiones de hash de cadenas
Reflexión: ¿Cómo juzgar si existe un cierto número entre 300 millones de enteros (0~200 millones)? Límite de memoria 500M, una máquina
- Dividir:
- Filtros Bloom: Artefactos
- redis
- Hash: ¿Abrir 300 millones de espacios, HashMap (200 millones)?
- Matrices: pregunta de edad; ¿datos[200000000]?
- Bit: mapa de bits, mapa de bits;
Tipo de base: la unidad de memoria más pequeña en informática es bit, que solo puede representar 0, 1
- 1 byte = 8 bits
- 1int = 4 bytes 32 bits
- Flotante = 4 bytes 32 bits
- Largo = 8 bytes 64 bits
- Char 2 bytes 16 bits
Int a = 1, ¿cómo se almacena este 1 en el cálculo?
0000 0000 0000 0000 0000 0000 0000 0001 toBinaryString (1) =1
base de operadores
desplazar a la izquierda<<
8 << 2 = 8 * (2 ** 2) = 8 * 4 = 328 << 1 = 8 * (2 ** 1) = 8 * 2 = 16
0000 0000 0000 0000 0000 0000 0000 1000
<< 2
0000 0000 0000 0000 0000 0000 0010 0000
Mover a la derecha>>
8 >> 2 = 8 / (2 ** 2) = 8 / 4 = 28 >> 1 = 8 / (2 ** 1) = 8 / 2 = 4
0000 0000 0000 0000 0000 0000 0000 1000
>> 2
0000 0000 0000 0000 0000 0000 0000 0010
poco y &
8 & 7
0000 0000 0000 0000 0000 0000 0000 1000 = 8
&
0000 0000 0000 0000 0000 0000 0000 0111 = 7
=
0000 0000 0000 0000 0000 0000 0000 0000 = 0
poco o |
8 | 7
0000 0000 0000 0000 0000 0000 0000 1000 = 8
&
0000 0000 0000 0000 0000 0000 0000 0111 = 7
=
0000 0000 0000 0000 0000 0000 0000 1111 = 2 3 + 2 2 + 2 1 + 2 0 = 8+4+2+1=15
mapa de bits
Un int ocupa 32 bits. Si usamos el valor de cada uno de los 32 bits para representar un número, ¿puede representar 32 números, es decir, 32 números solo necesitan el espacio que ocupa un int, y se puede hacer en un instante Reducir el espacio por 32 veces
Por ejemplo, supongamos que tenemos el mayor número de N{2, 3, 64} MAX, entonces solo necesitamos abrir int[MAX/32+1]una matriz int para almacenar los datos. Para obtener más detalles, consulte la siguiente estructura:
Int a : 0000 0000 0000 0000 0000 0000 0000 0000Aquí hay 32 posiciones, podemos usar 0 o 1 en cada posición para indicar si el número en esta posición existe, por lo que podemos obtener la siguiente estructura de almacenamiento:
Data[0]: 0~31 32位
Data[1]: 32~63 32位
Data[2]: 64~95 32位
Data[MAX / 32+1]
/**
* 解决:
* 1. 数据去重
* 2. 对没有重复的数据排序
* 3. 根据1和2扩展其他应用,比如不重复的数,统计数据
* 缺点: 数据不能重复、字符串hash冲突、数据跨多比较大的也不适合
*
* 求解2亿个数,判断某个数是否存在
*
* 最大的数是64 data[64/32] = 3
* data[0] 0000 0000 0000 0000 0000 0000 0000 0000 0~31
* data[1] 0000 0000 0000 0000 0000 0000 0000 0000 32~63
* data[2] 0000 0000 0000 0000 0000 0000 0000 0000 64~95
*
* 数字 2 65 2亿分别位置
* 2/32=0 说明放在data[0]数组位置, 2%32=2说明放在数组第3个位置
* 65/32=2 说明放在data[2]数组位置, 65%32=1说明放在数组第2个位置
*
* 2亿=M
* 开2亿个数组 2亿*4(byte) / 1024 /1024 = 762M
* 如果用BitMap: 2亿*4(byte)/32 / 1024 /1024 = 762/32 = 23M (int数组)
* 判断66是否存在 66/32=2 -> 66%32=2 -> data[2]里面找第三个位置是否是1
*/
public class BitMap {
byte[] bits; //如果是byte那就是只能存8个数
int max; //最大的那个数
public BitMap(int max) {
this.max = max;
this.bits = new byte[(max >> 3) + 1]; // max / 8 + 1
}
public void add(int n) {
//添加数字
int bitsIndex = n >> 3; // 除8就可以知道在哪一个byte
int loc = n % 8; // n % 8 与运算可以标识求余 n & 8
//接下来要把bit数组里面bitsIndex下标的byte里面第loc个bit位置设置为1
// 0000 0100
// 0000 1000
// 或运算(|)
// 0000 1100
bits[bitsIndex] |= 1 << loc;
}
public boolean find(int n) {
int bitsIndex = n >> 3;
int loc = n % 8;
int flag = bits[bitsIndex] & (1 << loc);
if (flag == 0) {
return false; //不存在
} else {
return true; //存在
}
}
public static void main(String[] args) {
BitMap bitMap = new BitMap(100);
bitMap.add(2);
bitMap.add(3);
bitMap.add(65);
bitMap.add(64);
bitMap.add(99);
System.out.println(bitMap.find(2));
System.out.println(bitMap.find(5));
System.out.println(bitMap.find(64));
}
}
Colocar
Comparación de varios contenedores.
- Lista:
los objetos se pueden almacenar repetidamente.
El orden de inserción y el orden de recorrido son consistentes.
Métodos de implementación comunes: lista enlazada + matriz (ArrayList, LinkedList, Vector) - Conjunto:
No se permiten objetos duplicados,
no se puede garantizar el orden de inserción y salida de cada elemento, un contenedor desordenado.
TreeSet está ordenado y
utiliza métodos de implementación comunes: HashSet, TreeSet, LinkedHashSet (obligado a garantizar que el orden de salida y el orden de inserción sean consistentes, lista doblemente enlazada, ocupando espacio) - Mapa: el
mapa se almacena en forma de pares clave-valor, y habrá clave+valor:
el mapa no permite que aparezca la misma clave y sobrescribirá
la secuencia Mapa., su estructura subyacente también es un árbol rojo-negro )
Filtro Bloom (si no existe, no debe existir)
Ideas implementadas:
- Inserción: use funciones hash K para realizar cálculos k en un elemento insertado y establezca el subíndice de la matriz de bits correspondiente al valor Hash obtenido en 1
- Búsqueda: Al igual que la inserción, use k funciones para realizar k cálculos en los elementos buscados, encuentre el subíndice de matriz de bits correspondiente para el valor obtenido y juzgue si es 1, si son todos 1, significa que el valor puede estar en la secuencia, de lo contrario definitivamente no está en la secuencia
¿Por qué es posible en secuencia? Hay una tasa de falsos positivos
- Eliminar: decirle muy claramente que esta cosa no admite la eliminación
/**
* 应用场景 -- 允许一定误差率 0.1%
* 1. 爬虫
* 2. 缓存击穿 小数据量用hash或id可以用bitmap
* 3. 垃圾邮件过滤
* 4. 秒杀系统
* 5. hbase.get
*/
public class BloomFilter {
private int size;
private BitSet bitSet;
public BloomFilter(int size) {
this.size = size;
bitSet = new BitSet(size);
}
public void add(String key) {
bitSet.set(hash_1(key), true);
bitSet.set(hash_2(key), true);
bitSet.set(hash_3(key), true);
}
public boolean find(String key) {
if (bitSet.get(hash_1(key)) == false)
return false;
if (bitSet.get(hash_2(key)) == false)
return false;
if (bitSet.get(hash_3(key)) == false)
return false;
return true;
}
public int hash_1(String key) {
int hash = 0;
for (int i = 0; i < key.length(); ++i) {
hash = 33 * hash + key.charAt(i);
}
return hash % size;
}
public int hash_2(String key) {
int p = 16777169;
int hash = (int) 2166136261L;
for (int i = 0; i < key.length(); i++) {
hash = (hash ^ key.length()) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return Math.abs(hash) % size;
}
public int hash_3(String key) {
int hash, i;
for (hash = 0, i = 0; i < key.length(); ++i) {
hash += key.charAt(i);
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return Math.abs(hash) % size;
}
public static void main(String[] args) {
BloomFilter bloomFilter = new BloomFilter(Integer.MAX_VALUE);//21亿/8/1024/1024=250M
System.out.println(bloomFilter.hash_1("1"));
System.out.println(bloomFilter.hash_2("1"));
System.out.println(bloomFilter.hash_3("1"));
bloomFilter.add("1111");
bloomFilter.add("1112");
bloomFilter.add("1113");
System.out.println(bloomFilter.find("1"));
System.out.println(bloomFilter.find("1112"));
}
}
Prueba de guayaba de Google
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId> <!-- google bloomfilter 布隆过滤器 -->
<version>22.0</version>
</dependency>
public class GoogleGuavaBloomFilterTest {
public static void main(String[] args) {
int dataSize = 1000000; //插入的数据N
double fpp = 0.001; //0.1% 误判率
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), dataSize, fpp);
for (int i = 0; i < 1000000; i++) {
bloomFilter.put(i);
}
//测试误判率
int t = 0;
for (int i = 2000000; i < 3000000; i++) {
if (bloomFilter.mightContain(i)) {
t++;
}
}
System.out.println("误判个数:" + t);
}
}
participio chino
arbol de tria
-
Qué es un árbol Trie: El árbol Trie es lo que solemos llamar un árbol de diccionario.Es una estructura de datos especialmente utilizada para procesar la coincidencia de cadenas. Es especialmente adecuado para encontrar rápidamente una cadena específica entre muchas cadenas. árbol de prefijos, árbol de huffman, codificación de prefijos
-
Trie estructura de datos: supongamos que tenemos las siguientes palabras en inglés: my name apple age sex, si queremos saber si existe una determinada cadena, ¿cómo la encuentras? Usando el prefijo común de la cadena, los repetidos se combinan para formar un árbol, que es el árbol trie del que estamos hablando.
-
La construcción del árbol Trie: necesitamos dividir la palabra en letras una por una, y luego insertarlas en el árbol por turno. Como se muestra a la derecha, el nodo raíz raíz, si queremos insertar la aplicación,
primero divida la aplicación en: a, p, p, y luego comience desde el punto raíz, insertando capa por capa, tenga en cuenta que
P se colgará debajo de a, detrás de A p de colgará en la p anterior. Al final de la palabra usaremos morado.
Cabe señalar aquí que las letras de cada capa están en orden cuando las insertamos. -
Búsqueda de Trie:
para buscar, comenzamos desde el punto raíz, luego buscamos la primera letra en la primera capa y luego encontramos la palabra que queremos a su vez.
Tenga en cuenta que la búsqueda de una palabra se completa solo cuando se encuentra la marca al final. Por ejemplo, app, estamos buscando ap
Aunque hay ap en el árbol del diccionario, pero esta p no es púrpura, entonces ap no existe en el árbol del diccionario. -
Implementación de Trie Tree: Trie Tree es un árbol de múltiples bifurcaciones. Aquí deberíamos pensar en B+Tree&B-Tree, que son algo similares.
El árbol Trie usa hábilmente el subíndice de la matriz, porque hay exactamente 26 letras en inglés, por lo que podemos abrir una matriz de 26 longitudes
A[] = new int[26];
A[0] = 'a' => el subíndice es 'a'-97, que es simplemente aquí mismo es 0, usando cálculo ascii.
Entonces su estructura de datos debe ser
class TrieNode {
Char c;//存储当前这个字符
TrieNode child[26] = new TrieNode[];//存储这个字符的子节点
}
- Análisis del árbol de Trie:
- Complejidad de tiempo: muy eficiente O (longitud de palabra)
- Complejidad del espacio: una estructura de datos que intercambia espacio por eficiencia. Como cada palabra teóricamente tiene 26 nodos secundarios, su complejidad espacial es 26^n, donde n representa la altura del árbol.
- mejoramiento:
- Las letras repetidas no se repiten
- Porque hemos abierto 26 espacios para cada nodo para almacenar nodos. Pero la situación real puede no necesitar tantos, por lo que aquí podemos considerar usar una tabla hash para implementarla. Aquí puede
ir al código fuente de IK. Cuando hay pocos nodos secundarios, es una matriz, pero es se usa cuando hay más de 3 nodos.hashMap, esto puede ahorrar mucho espacio hasta cierto punto.
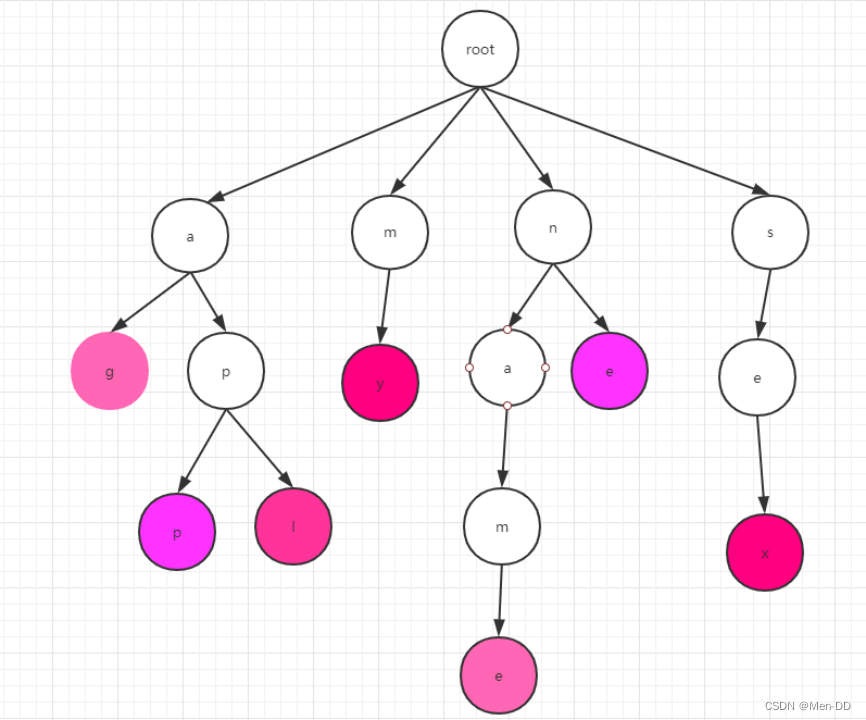
participio chino
-
El principio de la segmentación de palabras:
(1) Segmentación de palabras en inglés: mi nombre es WangLi
(2) Segmentación de palabras en chino: Soy chino -
Separador de palabras chino IK
-
Se debe prestar especial atención a la segmentación de palabras chinas porque tiene dos métodos:
- Inteligente: Segmentación inteligente de palabras, aquí no se separarán todas las situaciones de una oración, por ejemplo, soy chino, se dividirá en yo/es/chino
- La partícula más pequeña (no inteligente): Separará todas las situaciones en una oración, por ejemplo, si soy chino, se dividirá en Yo/Sí/China/Chino/Chino
-
Ambigüedad en chino: uso de diccionario de sinónimos, tecnología de inteligencia artificial compleja, algoritmos de aprendizaje automático, etc.
Puente del río Yangtze de Wuhan- Ciudad de Wuhan/Puente del río Yangtze
- Wuhan/Alcalde/Puente del río
Índice invertido de Lucene
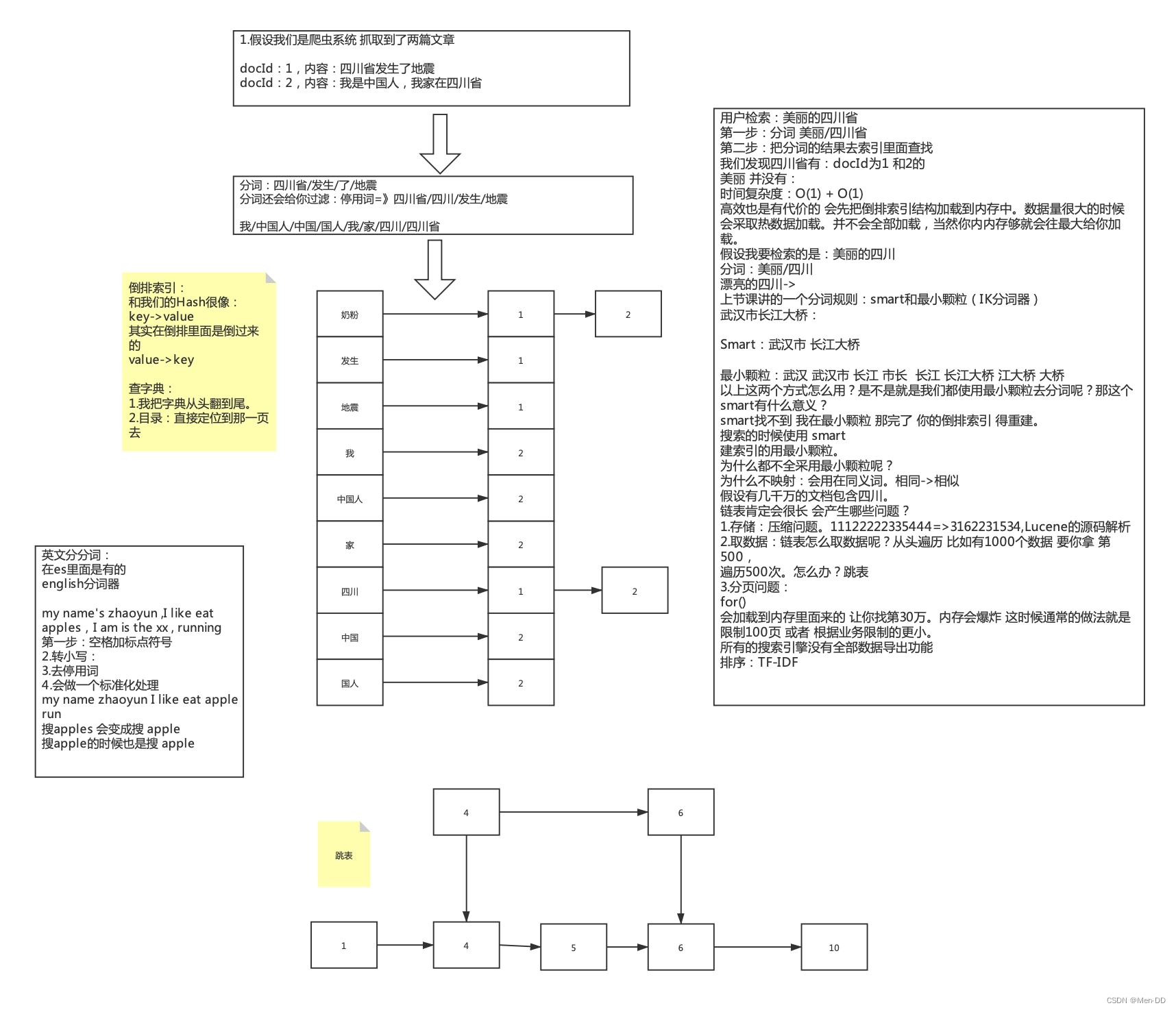
buscador
-
Estructura de datos: cuántas veces aparece la estructura de datos en todos los documentos. Si hay 10 artículos, las estructuras de datos aparecen en todos ellos. ¿Significa que no hay distinción?
-
TF: Frecuencia de palabras Cuántas palabras se incluyen en un documento, cuanto más contiene, más relevante es. Contar solo el número de documentos
-
DF: el número total de documentos cuya frecuencia de documento contiene esta palabra, DF se cuenta una vez en un documento
-
IDF: La inversión de DF es 1/DF, si hay menos documentos que contengan la palabra, es decir, cuanto menor sea el DF y mayor sea el IDF, mayor será la importancia de la palabra para este documento
-
TF-IDF: La idea principal de TF*IDF es: si una palabra o frase aparece en un artículo con una alta frecuencia de TF y rara vez aparece en otros artículos, se considera que la palabra o frase tiene una buena distinción de categoría habilidad, mayor será la puntuación de este artículo.
¿Cuál es el problema? La longitud varía, un artículo tiene solo 2 palabras, buscar una de ellas es el 50% del peso, hay un artículo con 100 palabras y 48 palabras. -
Procesamiento de normalización: principalmente para procesar TF-IDF, según la longitud del artículo
-
Puntuación de bonificación personalizada