Directorio de artículos
prefacio
Recientemente, estoy trabajando en un proyecto de código abierto con mis amigos. La dirección es el almacenamiento de datos. Recientemente, he estudiado muchos conocimientos y leído algunos documentos. KVELL es uno de ellos. Creo que es muy bueno, así que lo haré. Compártelo.
Los amigos interesados pueden echarle un vistazo, el título es KVell: el diseño y la implementación de un almacén rápido y persistente de valores-clave.
1. Antecedentes
1. Dos paradigmas de almacenamiento actualmente populares
Actualmente existen dos paradigmas principales para los KV persistentes:
- Los LSM KV
se consideran ampliamente como la mejor opción para cargas de trabajo dominadas por escritura. Los LSM KV se utilizan en sistemas populares como RocksDB y Cassandra. - Los KV de árbol B
se consideran más adecuados para cargas de trabajo de lectura intensiva. Los árboles B y sus variantes se utilizan en MongoDB
2. Desarrollo del rendimiento de SSD
Consideremos tres dispositivos que se han introducido en los últimos 5 años:
• Configuración-SSD. Un Intel Xeon de 32 núcleos a 2,4 GHz, 128 GB de RAM y un SSD Intel DC S3500 de 480 GB (2013).
• Config-Amazon-8NVMe. Una instancia A WS i3.metal, con 36 CPU (72 núcleos) que se ejecutan a 2,3 GHz, 488 GB de RAM y 8 unidades SSD NVMe de 1,9 TB cada una (marca desconocida, tecnología de 2016).
• Configuración-Optane. Un Intel i7 de 4 núcleos a 4,2 GHz, 60 GB de RAM y un Intel Optane 905P (2018) de 480 GB.
IOPS
(La cantidad de E/S por segundo es una medida que se utiliza para probar el rendimiento de los dispositivos de almacenamiento de computadoras, como unidades de disco duro (HDD), unidades de estado sólido (SSD) o redes de área de almacenamiento (SAN). La Tabla 1 muestra los tres dispositivos. número máximo de IOPS de lectura y escritura y ancho de banda aleatorio y secuencial. Primero, la cantidad de IOPS y el ancho de banda aumentan significativamente. En segundo lugar, las escrituras aleatorias eran mucho más lentas que las escrituras secuenciales en dispositivos más antiguos, pero ya no es así. Del mismo modo, mezclar lecturas y escrituras aleatorias ya no genera un rendimiento deficiente como ocurría en los dispositivos más antiguos. Por ejemplo, Config-Optane utiliza la unidad Intel Optane 905P lanzada en el tercer trimestre de 2018, que puede mantener más de 500 000 IOPS independientemente de la combinación de lecturas y escrituras, y el acceso aleatorio es solo un poco más lento que el acceso secuencial.
Latencia y ancho de banda
La siguiente tabla muestra las mediciones de latencia y ancho de banda para tres dispositivos en función de la profundidad de la cola del dispositivo, con un núcleo realizando escrituras aleatorias. Los dispositivos de la generación anterior solo podían soportar tiempos de respuesta de submilisegundos con una pequeña cantidad de solicitudes de E/S simultáneas (32 en el caso de Config-SSD). Config-Amazon-8NVMe y Config-Optane admiten un mayor paralelismo, con ambas unidades capaces de responder a 256 solicitudes simultáneas con una latencia de submilisegundos. Estos dos controladores solo pueden alcanzar una fracción de su ancho de banda cuando hay muy pocas solicitudes en la cola del dispositivo. Por lo tanto, incluso en los dispositivos modernos, tiene que haber un buen equilibrio entre enviar muy pocas solicitudes simultáneas (lo que resulta en un ancho de banda subóptimo) y enviar demasiadas (lo que resulta en una alta latencia).

reducción de rendimiento
La siguiente tabla muestra las IOPS a lo largo del tiempo en los tres dispositivos. Este gráfico también muestra los avances en tecnología de dispositivos. Por ejemplo, el ssd de configuración puede soportar 50 000 IOPS de escritura durante 40 minutos, pero luego su rendimiento desciende lentamente a 11 000 IOPS. Los SSD más nuevos no tienen este problema y el IOPS se mantiene alto con el tiempo.

ráfaga de E/S
La figura 2 muestra la latencia de una operación de escritura de 4K con una profundidad de cola de 64 en Config-Amazon-8NVMe y Config-Optane. Las SSD de generaciones anteriores sufren picos de latencia en las cargas de trabajo de escritura intensa debido a las operaciones de mantenimiento interno. En Config-SSD, observamos picos de latencia de hasta 100 ms después de 5 horas, en comparación con una latencia de escritura normal de 1,5 ms. Estos resultados no se muestran en la Figura 2 porque el tamaño máximo de este dispositivo oscurecería los resultados de otros dispositivos. Las unidades Config-Amazon-8 NVMe también sufren picos de latencia periódicos. La latencia máxima observada es de 15 ms (mientras que el 99,1 % es de 3 ms). En el controlador Config-Optane, los picos de latencia se producen de forma irregular y su magnitud suele ser inferior a 1 ms, con el pico más grande observado en 3,6 ms (en comparación con 700 us para el 99 % de los picos).

3. Problemas con los KV actuales en NVMe ssd
3.1 CPU es el cuello de botella
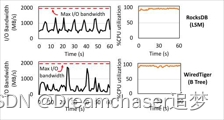
Figura 3. Configuración-Optane.
Líneas de tiempo de ancho de banda de E/S (izquierda) y consumo de CPU (derecha) para RocksDB (LSM KV) y WiredTiger (B-tree KV). Ningún sistema puede utilizar el ancho de banda de E/S de todo el dispositivo. Carga de trabajo: YCSB escribe 50 %, lee 50 %, distribución uniforme de claves, el tamaño del elemento KV es de 1 KB.
La CPU es el cuello de botella de los LSM KV
Los LSM KV optimizan las cargas de trabajo de escritura intensiva al absorber las actualizaciones en los búferes de memoria. Cuando el búfer está lleno, se descarga en el disco. Luego, un subproceso en segundo plano fusiona los búfer vaciados en la estructura de árbol mantenida en el almacenamiento persistente. La estructura en disco consta de múltiples niveles con tamaños de nivel crecientes. Cada capa contiene varios archivos ordenados inmutables con rangos de valores clave inconsistentes (excepto la primera capa, que está reservada para los búferes de memoria de escritura). Para preservar esta estructura en el disco, los LSM KV implementan una operación de mantenimiento intensiva de E/S y CPU llamada compactación, que fusiona datos de nivel inferior con datos de nivel superior en el árbol LSM, mantiene el orden de los elementos y descarta los duplicados.
En los dispositivos más antiguos, la compresión compite por el ancho de banda del disco, pero la combinación, la indexación y el código del kernel también compiten por el tiempo de CPU, y en los dispositivos más nuevos, la CPU se ha convertido en el principal cuello de botella. El análisis muestra que RocksDB gasta hasta el 60 % del tiempo de la CPU en la compresión (28 % para fusionar datos, 15 % para crear índices y el resto para leer y escribir datos en el disco). La necesidad de compresión surge de los requisitos de diseño de LSM, a saber, el acceso secuencial al disco y el mantenimiento de los datos ordenados en el disco. Este diseño es beneficioso para unidades más antiguas en las que vale la pena gastar ciclos de CPU para mantener los datos ordenados y garantizar largos accesos secuenciales al disco.
La CPU es el cuello de botella de los KV de árbol B
Hay dos variantes de árboles B diseñados para el almacenamiento persistente: árboles B+ y árboles Bϵ. Los árboles B+ contienen entradas KV en las hojas. Los nodos internos solo contienen claves y se utilizan para el enrutamiento. Por lo general, los nodos internos residen en la memoria y las hojas residen en el almacenamiento persistente. Cada nodo de hoja tiene un rango ordenado de elementos KV, y los nodos de hoja están vinculados en una lista vinculada para facilitar el escaneo. Los árboles B+ de última generación (por ejemplo, WiredTiger) se basan en el almacenamiento en caché para lograr un buen rendimiento. Las actualizaciones se escriben primero en el registro de confirmación de cada subproceso y luego en la memoria caché. Eventualmente, cuando los datos se desalojan del caché, el árbol se actualiza con la nueva información. Las actualizaciones usan un número de serie, que es necesario para escanear. Las operaciones de lectura atraviesan el caché, visitando el árbol solo si el elemento no está en caché.
Hay dos tipos de operaciones que persisten datos en el árbol:
- puesto de control y
- expulsión.
Los puntos de control se producen periódicamente o cuando se alcanza un determinado umbral de tamaño en el registro. Los puntos de control son necesarios para mantener limitado el tamaño del registro de confirmación. El desalojo escribe datos sucios del caché en el árbol. El desalojo se activa cuando la cantidad de datos sucios en el caché supera un cierto umbral.
Los árboles Bϵ son una variante de los árboles B+, mejorados con almacenamiento temporal de claves y valores en búferes en cada nodo. Eventualmente, cuando el búfer está lleno, las entradas de KV viajan por la estructura de árbol y se escriben en el almacenamiento persistente.
El diseño de árbol B es propenso a la sobrecarga de sincronización. La creación de perfiles en WiredTiger revela esto: los subprocesos de trabajo pasan el 47 % de su tiempo ocupados esperando un espacio en el registro (en la función __log_wait_for_earlier_slot, que usa la llamada al sistema sched_yield para esperar ocupado). El problema radica en no poder avanzar el número de serie lo suficientemente rápido para una actualización. En la ruta del código principal actualizada, excluyendo el tiempo que se pasa en el kernel, WiredTiger solo pasa el 18 % de su tiempo ejecutando la lógica de solicitud del cliente, y el resto del tiempo lo pasa esperando. WiredTiger también necesita realizar operaciones en segundo plano: eliminar los datos sucios de la memoria caché de la página requiere el 12 % del tiempo total y administrar el registro de confirmación requiere el 5 % del tiempo total. Solo el 25% del tiempo en el kernel se usa para llamadas de lectura y escritura, y el resto del tiempo se usa para funciones futex y yield.
Los árboles Bϵ también experimentan una sobrecarga de sincronización. Debido a que el árbol Bϵ mantiene los datos ordenados en el disco, los subprocesos de trabajo terminan modificando la estructura de datos compartida, lo que genera contención. El análisis de TokuMX muestra que los subprocesos dedican el 30 % de su tiempo a bloqueos u operaciones atómicas que se utilizan para proteger las páginas compartidas. También se ha demostrado que el almacenamiento en búfer es una fuente importante de sobrecarga en los árboles Bϵ. En YCSB, una carga de trabajo TokuMX pasó más del 20 % del tiempo moviendo datos del búfer a la ubicación correcta en las hojas. Estos gastos generales de sincronización superan en gran medida los otros gastos generales.
3.2 Fluctuaciones de rendimiento de LSM y KV de árbol B
Además de estar limitado por la CPU, los KV LSM y B-tree sufren fluctuaciones de rendimiento significativas. La figura 4 muestra la fluctuación del rendimiento a lo largo del tiempo para RocksDB y WiredTiger que ejecutan la carga de trabajo principal de YCSB a. El rendimiento se mide cada segundo. En LSM y B-tree KV, el problema básico es similar: las actualizaciones del cliente se detendrán debido a las operaciones de mantenimiento.
En LSM KV, el rendimiento cae porque a veces las actualizaciones deben esperar a que se complete la compactación. Cuando el primer nivel del árbol LSM está lleno, las actualizaciones deben esperar hasta que haya espacio disponible mediante la compactación. Sin embargo, hemos visto que la compresión puede ser un cuello de botella en la CPU cuando los LSM KV se ejecutan en unidades modernas. La diferencia de rendimiento en términos de rendimiento aumenta en un orden de magnitud con el tiempo: RocksDB mantiene un promedio de 63 000 solicitudes por segundo, pero cae a 1,5 000 cuando las escrituras se detienen. El análisis muestra que el subproceso de escritura se retiene aproximadamente el 22% del tiempo, esperando que se vacíen los componentes de la memoria. La actualización de los componentes de la memoria se retrasa porque la compactación no puede seguir el ritmo de las actualizaciones.
Se han propuesto soluciones para reducir el impacto de las compactaciones en el rendimiento, es decir, retrasar las compactaciones o ejecutarlas solo cuando el sistema está inactivo, pero estas soluciones no son adecuadas para ejecutarse en SSD de gama alta. Por ejemplo, las máquinas Config-Otane actualizan los componentes de la memoria a 2 GB/s. Retrasar la compresión por más de unos pocos segundos puede resultar en una gran acumulación de trabajo y espacio desperdiciado.
En los árboles B, las pausas en las cargas de trabajo de los usuarios también pueden afectar el rendimiento. Las escrituras de los usuarios se retrasan porque los desalojos no pueden ocurrir lo suficientemente rápido. La pausa hizo que el rendimiento cayera en un orden de magnitud, de 120 Kops/s a 8,5 Kops/s. Concluimos que en ambos casos, las operaciones de mantenimiento como compactaciones y desalojos interrumpieron severamente las cargas de trabajo de los usuarios, provocando pausas de varios segundos. Por lo tanto, los nuevos diseños de KV deben evitar las operaciones de mantenimiento.

2. KVELL
1. Principios de diseño de KV
-
No compartas. En KVell, esto se traduce en admitir el paralelismo y minimizar el estado compartido entre los subprocesos de trabajo de KV para reducir la sobrecarga de la CPU.
-
No ordene en el disco, pero mantenga el índice en la memoria. KVell mantiene los elementos sin clasificar en su ubicación final en el disco, evitando costosas operaciones de reordenación.
-
El objetivo es reducir las llamadas al sistema, no las E/S secuenciales. En lugar de enfocarse en el acceso secuencial al disco, KVell aprovecha el hecho de que el acceso aleatorio es casi tan eficiente como el acceso secuencial en los SSD modernos. En su lugar, se esfuerza por minimizar la sobrecarga de la CPU de las llamadas al sistema mediante el procesamiento por lotes de E/S.
-
Los registros no están comprometidos. KVell no almacena actualizaciones en el búfer, por lo que no necesita depender del registro de confirmación, lo que evita operaciones de E/S innecesarias.
1.1 Sin compartir
Para el caso común de una sola lectura y escritura, el subproceso de trabajo que procesa la solicitud no necesita sincronizarse con otros subprocesos. Cada subproceso maneja las solicitudes de un subconjunto determinado de claves y mantiene un conjunto de estructuras de datos privado de subprocesos para administrar este conjunto de claves.
Las estructuras de datos clave son:
- (i) Un índice de árbol B ligero en memoria para rastrear la ubicación de las claves en el almacenamiento persistente
- (ii) colas de E/S, responsables de almacenar y recuperar de manera eficiente la información del almacenamiento persistente
- (iii) Lista libre, parte de la lista de bloqueo del disco de memoria contiene para almacenar elementos y (iv) caché de página: KVell usa su propio caché de página interno que no depende de las estructuras de nivel del sistema operativo. Los escaneos son las únicas operaciones que requieren una sincronización mínima en un índice de árbol B en memoria.
Este enfoque de nada compartido es una diferencia clave en comparación con los diseños KV tradicionales, donde todas o la mayoría de las estructuras de datos principales son compartidas por todos los subprocesos de trabajo. El enfoque tradicional requiere sincronización en cada solicitud, lo que KVell evita por completo. Las solicitudes de partición pueden causar desequilibrios de carga, pero hemos descubierto que este efecto es mínimo si se utiliza la partición adecuada.
1.2 No ordene en el disco, pero mantenga el índice en la memoria
KVell no ordena los datos en el conjunto de trabajo del subproceso de trabajo. Debido a que KVell no ordena las claves, puede mantener los elementos en su ubicación final en el disco. No tener ningún orden en el disco reduce la sobrecarga de insertar elementos (es decir, encontrar el lugar correcto para insertar) y elimina la sobrecarga de la CPU asociada con las operaciones de mantenimiento en el disco (o la clasificación antes de escribir en el disco). El almacenamiento de claves desordenadas en el disco es especialmente beneficioso para las operaciones de escritura y ayuda a lograr latencias de cola bajas.
Durante los escaneos, las claves consecutivas ya no están en el mismo bloque de disco, lo que puede ser una desventaja. Sin embargo, quizás sorprendentemente, para las cargas de trabajo con términos kv medianos y grandes (como los escaneos en el punto de referencia YCSB o las cargas de trabajo de producción, como mostramos en la Sección 6), el rendimiento del escaneo no sufre una influencia significativa.
1.3 El objetivo es reducir las llamadas al sistema, no las E/S secuenciales
En KVell, todas las operaciones (incluidas las exploraciones) realizan un acceso aleatorio al disco. Debido a que el acceso aleatorio es tan eficiente como el acceso secuencial, KVell no desperdicia ciclos de CPU forzando E/S secuenciales.
Al igual que los LSM KV, los KVell envían solicitudes al disco en lotes. Sin embargo, los objetivos son diferentes. Los KV de LSM utilizan principalmente E/S por lotes y ordenan los elementos de KV para aprovechar el acceso secuencial al disco. KVell procesa las solicitudes de E/S por lotes, el objetivo principal es reducir la cantidad de llamadas al sistema, lo que reduce la sobrecarga de la CPU.
El procesamiento por lotes es una compensación, como se vio en la Sección 2, el disco debe estar constantemente ocupado para lograr su pico de IOPS, pero solo si la cola de hardware contiene menos de un número determinado de solicitudes (por ejemplo, en solicitudes de Config-Optane 256), el disco responde con una latencia de submilisegundos. Un sistema eficiente debe enviar suficientes solicitudes a los discos para mantenerlos ocupados, pero no abrumarlos con grandes colas de solicitudes, lo que provoca una alta latencia.
En configuraciones con varios discos, cada trabajador almacena archivos en un solo disco. Esta decisión de diseño es fundamental para limitar la cantidad de solicitudes pendientes por disco. De hecho, dado que los trabajadores no se comunican entre sí, no saben cuántas solicitudes envían otros trabajadores a un disco determinado. Si los trabajadores almacenan datos en un solo disco, la cantidad de solicitudes al disco es limitada (tamaño del lote multiplicado por la cantidad de trabajadores en cada disco). Si los trabajadores van a acceder a todos los discos, entonces los discos pueden tener hasta (el tamaño del lote multiplicado por el número total de trabajadores) solicitudes pendientes.
1.4 No envíe registros
KVell solo reconoce las actualizaciones después de que se hayan conservado en el disco en la ubicación final, sin depender de un registro de confirmación. Una vez que se confirma una actualización en un subproceso de trabajo, se conservará en el disco en el siguiente lote de E/S. La eliminación del registro de confirmación permite que KVell use el ancho de banda del disco solo para el procesamiento útil de solicitudes de clientes.
2. Realización de KVELL
2.1 Interfaz de operación del cliente
KVell implementa las mismas interfaces principales que los LSM KV:
- Escribir Actualizar(k,v)
asocia el valor v con la clave k. Update(k,v) regresa solo después de que el valor se haya guardado en el disco - Leer Get(k)
Get(k) devuelve el valor más reciente de k - Escaneo de rango Escaneo (k1, k2).
Devuelve el rango de elementos KV entre k1 y k2.
2.2 Estructura de datos del disco
Para evitar la fragmentación, los elementos que se ajustan al mismo rango de tamaño se almacenan en el mismo archivo. Llamamos a estos archivos losas. KVell accede a la losa en granularidad de bloque, que es el tamaño de página (4 KB) en nuestra máquina.
Si el elemento es más pequeño que el tamaño de la página (por ejemplo, varios elementos pueden caber en una página), KVell antepone el elemento en la losa con una marca de tiempo, un tamaño de clave y un tamaño de valor. Los elementos de más de 4K tienen un encabezado de marca de tiempo al comienzo de cada bloque en el disco. Los elementos que son más pequeños que el tamaño de la página se actualizarán en su lugar. Para artículos más grandes, una actualización consiste en adjuntar el artículo a la losa y luego escribir una lápida donde solía estar el artículo. Cuando un elemento cambia de tamaño, KVell primero escribe el elemento actualizado en la losa nueva y luego lo elimina de la losa anterior.
2.3 Estructuras de datos en memoria
índice
KVell se basa en índices en memoria rápidos y livianos con tiempos de inserción y búsqueda predecibles para encontrar la ubicación de los elementos en el disco. KVell utiliza un árbol B en memoria para que cada trabajador almacene la ubicación de los elementos en el disco. Los elementos se indexan según su clave (prefijo). Usamos prefijos en lugar de hash para preservar el orden de las claves para los escaneos de rango. Los árboles B funcionan mal cuando se almacenan datos medianos/grandes, pero son rápidos cuando los datos (en su mayoría) caben en la memoria y las claves son pequeñas. KVell aprovecha esta propiedad y solo usa árboles B para almacenar información de búsqueda (la información de prefijo y ubicación ocupa 13B).
La implementación del árbol de KVell actualmente utiliza un promedio de 19 B por entrada (prefijo de almacenamiento, información de ubicación y estructura de árbol B), lo que equivale a 1,7 GB de RAM para almacenar 100 millones de entradas. En una carga de trabajo YCSB (elementos de 1 KB), el índice equivale al 1,7 % del tamaño de la base de datos. Encontramos que este valor es razonable en la práctica. Actualmente, KVell no admite explícitamente el vaciado de partes de árboles B en el disco, pero los datos de árboles B se asignan desde archivos mmap-ed y el kernel puede recuperarlos.
caché de página
KVell mantiene su propio caché de página interno para evitar obtener páginas a las que se accede con frecuencia desde el almacenamiento persistente. El tamaño de la página en caché es un parámetro del sistema. La memoria caché de la página recuerda qué páginas se almacenan en la memoria caché en el índice y expulsa las páginas de la memoria caché en orden LRU.
Asegurarse de que las búsquedas e inserciones en el índice tengan una sobrecarga de CPU mínima es fundamental para un buen rendimiento. Nuestra implementación de caché de primera página utiliza una tabla hash uthash rápida como índice. Sin embargo, cuando la memoria caché de la página es grande, las inserciones en el hash pueden tardar hasta 100 ms (tiempo para hacer crecer la tabla hash), lo que aumenta la latencia final. Cambiar a árboles B elimina estos picos de latencia.
lista libre
Cuando se elimina un elemento de una losa, su posición en esa losa se inserta en la pila de memoria de cada losa, que llamamos la lista libre de la losa. Luego escriba una lápida en la ubicación del proyecto en el disco. Para vincular el uso de la memoria, solo mantenemos las últimas N ubicaciones liberadas en la memoria (actualmente, N se establece en 64). Su objetivo es limitar el uso de la memoria y, al mismo tiempo, mantener la capacidad de reutilizar varios espacios libres por lote de E/S sin necesidad de acceso adicional al disco.
Cuando se libera el elemento (N+1), KVell hace que su lápida de disco apunte a la primera ubicación liberada. Luego, KVell elimina la primera ubicación liberada de la pila de memoria e inserta (N+1) ubicaciones liberadas. Cuando se libera el (N+2) elemento, su lápida apunta a la segunda ubicación liberada, y así sucesivamente. En pocas palabras, KVell mantiene N pilas independientes cuyas cabezas residen en la memoria y el resto en el disco. Esto permite que Kvell reutilice hasta N puntos inactivos por lote de E/S. Si solo hay una pila, KVell debe leer secuencialmente N lápidas del disco para encontrar las próximas N ubicaciones que se liberarán.
2.4 Realizar E/S de manera eficiente
KVell se basa en la API de E/S asíncrona de Linux (AIO) para enviar solicitudes al disco en lotes de hasta 64 solicitudes. Al agrupar las solicitudes, KVell amortiza los gastos generales de las llamadas al sistema en varias solicitudes de clientes. Elegimos usar E/S asíncrona de Linux porque nos brinda una manera de realizar múltiples E/S con una sola llamada al sistema. Estimamos que el rendimiento sería casi el mismo si dichas llamadas estuvieran disponibles en la API de E/S síncrona.
Rechazamos dos alternativas populares para realizar E/S: (1) usar mmap que se basa en la caché de la página del sistema operativo (p. ej., RocksDB) y (2) usar llamadas directas al sistema de E/S de lectura y escritura (p. ej., TokuMX). Ninguna técnica es tan eficiente como usar una interfaz AIO. La Tabla 3 resume nuestros hallazgos y muestra el IOPS máximo que se puede lograr en Config-Optane, escribiendo aleatoriamente en bloques de 4K (esto requiere operaciones de lectura, modificación y escritura en el dispositivo). El conjunto de datos al que se accede es 3 veces más grande que la RAM disponible.

El primer enfoque es confiar en la memoria caché de la página a nivel del sistema operativo. El rendimiento de este enfoque no es óptimo en el caso de subproceso único, ya que solo puede emitir una lectura de disco a la vez cuando se produce un error de página (el valor de lectura anticipada se establece en 0, ya que se accede a los datos de forma aleatoria). Además, las páginas sucias solo se descargan en el disco periódicamente. Esto da como resultado profundidades de cola subóptimas en la mayoría de los casos, seguidas de una ráfaga de E/S. Cuando el conjunto de datos no cabe completamente en la RAM, el núcleo también debe asignar y desasignar páginas fuera del espacio de direcciones virtuales del proceso, lo que genera una sobrecarga de CPU significativa. Para subprocesos múltiples, la memoria caché de la página sufre una sobrecarga de bloqueo cuando se vacía la LRU (cada 32 KB se vacía un bloqueo en el disco en promedio) y la rapidez con la que el sistema invalida las entradas de TLB para los núcleos remotos. De hecho, cuando una página no está asignada del espacio de direcciones virtuales, la asignación de virtual a físico debe invalidarse en todos los núcleos que han accedido a la página, lo que genera una sobrecarga enorme para la comunicación IPI.
El segundo método es confiar en la E/S directa. Sin embargo, las llamadas al sistema de lectura/escritura de E/S directas no llenan la cola del disco cuando las solicitudes se completan sincrónicamente (cada subproceso tiene una solicitud pendiente). Se prefiere esta técnica sobre el método mmap porque no hay necesidad de lidiar con la lógica compleja de mapear y desasignar páginas del espacio de direcciones virtuales.
Por el contrario, la E/S por lotes requiere solo una llamada al sistema por lote y permite que KVell controle la longitud de la cola del dispositivo para baja latencia y alto ancho de banda. Aunque, en teoría, las técnicas de procesamiento por lotes de E/S se pueden aplicar a los LSM y los KV de árbol B, la implementación requerirá un esfuerzo significativo. En un árbol B, diferentes operaciones pueden tener efectos conflictivos en la E/S (por ejemplo, una división de una hoja provocada por una inserción seguida de una fusión de dos hojas). Además, los datos pueden moverse en el disco debido a la reordenación, lo que también dificulta el procesamiento por lotes asincrónico de las solicitudes. El procesamiento por lotes de solicitudes de escritura se ha implementado en LSM KV a través del componente de memoria. Sin embargo, el procesamiento por lotes aumenta ligeramente la complejidad de la ruta de lectura, ya que el trabajador debe asegurarse de que el subproceso de compactación no elimine todos los archivos que necesita leer.
2.5 Implementación de la operación del cliente
El algoritmo 1 resume la arquitectura KVell. Para simplificar, el algoritmo solo muestra una sola página de elementos KV. Cuando una solicitud ingresa al sistema, se asigna a un trabajador de acuerdo con su clave (líneas 3 y 5, algoritmo 1). El subproceso del trabajador realiza la E/S del disco y maneja la lógica de la solicitud del cliente.
obtener (k). Leer un elemento (líneas 17 a 22, algoritmo 1) implica obtener su ubicación en disco a partir del índice y leer la página correspondiente. Si la página ya está en caché, no se requiere acceso al almacenamiento persistente y los valores se devolverán sincrónicamente al cliente. De lo contrario, el trabajador que maneja la solicitud la inserta en la cola del motor de E/S.
actualizar (k, v). Actualizar un elemento (líneas 24 a 35, algoritmo 1) implica primero leer la página que lo almacena, modificar el valor y luego escribir la página en el disco. Eliminar un elemento implica escribir un valor de lápida y agregar la posición del elemento a la lista libre de la losa. Reutiliza las ubicaciones liberadas al agregar nuevos elementos o agrega elementos si no existen ubicaciones libres. KVell solo confirma que la actualización se completó cuando el elemento actualizado se conserva por completo en el disco (es decir, la llamada al sistema io_getevents nos notifica que la operación de escritura en disco correspondiente a la actualización se completó (línea 37 del Algoritmo 1). Sucio los datos se descargan inmediatamente en el disco, porque la caché de la página de KVell no se utiliza para las actualizaciones del búfer. De esta manera, KVell proporciona garantías de durabilidad más sólidas que los KV de última generación. Por ejemplo, RocksDB solo garantiza la durabilidad en la granularidad del registro de confirmación. sincronización con el disco En una configuración típica, la sincronización solo ocurre en lotes de actualizaciones.
Explorar (k1, k2). Un escaneo consiste en (1) obtener la ubicación de la clave del índice y (2) leer la página correspondiente. Para calcular la lista de claves, KVell escanea todos los índices: un hilo simplemente bloquea, escanea y desbloquea secuencialmente todos los índices de los trabajadores y finalmente combina los resultados para obtener una lista de claves para leer desde KVell. Luego, la lectura se realiza mediante el comando Get(), que omite la búsqueda del índice (dado que KVell ya tiene acceso al índice). El escaneo es la única operación que debe compartirse entre subprocesos. KVell devuelve el último valor asociado con cada tecla tocada por el escaneo. Por el contrario, tanto RocksDB como WiredTiger realizan escaneos en instantáneas KV.
2.6 Modelo de falla y recuperación
La implementación actual de KVell está optimizada para un funcionamiento sin problemas. En caso de accidente, se escanean todas las matrículas y se reconstruye el índice en memoria. Incluso con escaneos que maximizan el ancho de banda secuencial del disco, la recuperación aún puede llevar minutos en conjuntos de datos muy grandes.
Si un elemento aparece dos veces en el disco (por ejemplo, se produce un bloqueo durante la migración de un elemento de un bloque a otro), solo el elemento más reciente se mantiene en el índice de memoria mientras que el otro se inserta en la lista libre. Para elementos más grandes que el tamaño del bloque, KVell utiliza un encabezado de marca de tiempo para descartar elementos que solo están parcialmente escritos.
KVell está diseñado para unidades capaces de escribir automáticamente páginas de 4 KB, incluso en caso de un corte de energía. Esta restricción se puede eliminar evitando una modificación en el lugar de la página, escribiendo el nuevo valor en la nueva página y luego agregando la ubicación anterior a la lista libre de la losa después de que se complete la primera operación de escritura.
pd: La implementación de este documento es de código abierto, KVELL
Resumir
KVELL es una solución de almacenamiento de datos relativamente nueva, diseñada principalmente para SSD cuyo rendimiento se ha mejorado continuamente en los últimos años.
Su núcleo es índice de memoria + almacenamiento no secuencial. Al mismo tiempo, hay algunas optimizaciones para SSD, como el mecanismo Slab similar a fatcache, la E/S por lotes subyacente, el diseño no compartido, etc.
En resumen, KVELL es una solución de almacenamiento diseñada para el almacenamiento SSD moderno y, en cierta medida, vuelve a la forma original de lectura y escritura (lectura y escritura secuencial -> lectura y escritura aleatoria).
Tengo que suspirar, ¡el encanto del diseño radica en el intercambio!