1. Categorías de extractores de características comunes
-
Red neuronal convolucional (CNN): CNN es un extractor de características de uso común, que puede realizar la extracción de características en datos bidimensionales o unidimensionales, como imágenes y audio.
-
Red neuronal recurrente (RNN): RNN es un extractor de funciones que puede procesar datos de secuencias y puede realizar la extracción de funciones en datos de secuencias como texto y voz.
-
Transformer: Transformer es un modelo de aprendizaje profundo para el procesamiento del lenguaje natural (NLP) y otras tareas de secuencia a secuencia (Seq2Seq). A diferencia del modelo tradicional de red neuronal recurrente (RNN), el modelo Transformer utiliza un mecanismo de atención (Mecanismo de atención) para procesar la secuencia de entrada.
-
Pirámide de características: La pirámide de características es un algoritmo para la extracción de características de múltiples escalas, que puede extraer simultáneamente características de diferentes escalas y fusionarlas.
-
Modelos preentrenados: los modelos preentrenados se refieren a modelos de aprendizaje profundo entrenados previamente en datos a gran escala, como ResNet y VGG entrenados en ImageNet. La parte de extracción de características de estos modelos preentrenados se puede usar como un extractor de características sin volver a entrenar todo el modelo.
Principalmente tome RNN, CNN y Transformer en el campo natural ChatGPT más popular como ejemplos.
2. El auge y la decadencia de RNN en la PNL
Red neuronal recurrente (RNN para abreviar) es un modelo de aprendizaje profundo que puede procesar datos de secuencia. En RNN, cada paso de tiempo de los datos se considera como una entrada y se relaciona con el paso de tiempo anterior.
La unidad básica de RNN es la unidad recurrente (Recurrent Unit), también conocida como unidad RNN (RNN Cell). La unidad RNN recibe la entrada del paso de tiempo actual y el estado oculto (Estado Oculto) del paso de tiempo anterior, y genera un nuevo estado oculto y la salida del paso de tiempo actual. El estado oculto se puede ver como la memoria del pasado del modelo, que puede preservar la información al pasar continuamente al siguiente paso de tiempo.
El algoritmo Backpropagation Through Time (BPTT) de RNN es similar a la red neuronal tradicional, que puede actualizar los parámetros del modelo minimizando la función de pérdida. Dado que el estado oculto de RNN se puede pasar al siguiente paso de tiempo, BPTT necesita expandir el gradiente de cálculo en la dimensión de tiempo, lo que causará el problema de la desaparición o explosión del gradiente. Para aliviar este problema, se proponen algunas variantes de modelos, como la red de memoria a corto plazo (LSTM) y la unidad recurrente cerrada (GRU), que pueden manejar mejor los datos de secuencia larga.
¿Por qué RNN puede volverse popular en PNL tan rápido y ocupar una posición dominante?
Basado en las características anteriores de RNN, la razón principal es que la estructura de RNN se adapta naturalmente para resolver el problema de NLP.La entrada de NLP es a menudo una oración de secuencia lineal de longitud variable, mientras que la estructura de RNN en sí es un frente. secuencia inversa que puede aceptar entradas de longitud variable La estructura de red de conducción lineal de información, después de introducir tres puertas en LSTM, también es muy efectiva para capturar características de larga distancia. Por lo tanto, RNN es especialmente adecuado para escenarios de aplicación de secuencia lineal como NLP, que es la razón fundamental por la que RNN es tan popular en el mundo de NLP.
¿Por qué RNN está disminuyendo rápidamente en NLP?
El éxito también tiene sus características y el fracaso también tiene sus características. La estructura dependiente de la secuencia de RNN en sí misma es bastante hostil para la computación paralela a gran escala. En términos sencillos, es difícil que RNN tenga capacidades de cómputo paralelo eficientes A primera vista, esto no parece ser un gran problema, pero en realidad es un problema serio. Si solo está satisfecho con publicar un documento cambiando RNN, entonces esto realmente no es un gran problema, pero si la industria selecciona la tecnología, es poco probable que elija un modelo tan lento bajo la premisa de que hay disponible un modelo mucho más rápido. el modelo.
Entonces, ¿por qué no funciona la capacidad de computación paralela de RNN? Aquí radica el problema. Debido a que el cálculo en el momento T depende del resultado del cálculo de la capa oculta en el momento T-1, y el cálculo en el momento T-1 depende del resultado del cálculo de la capa oculta en el momento T-2... Esto forma el -llamada dependencia de secuencia.
Resumen simplificado: la estructura dependiente de la secuencia es naturalmente adecuada para los problemas de NLP, pero el cálculo depende de los resultados del cálculo de la capa oculta en el tiempo T-1, y el cálculo en el tiempo T-1 depende de la dependencia de la secuencia formada por el cálculo de la capa oculta resultados en el tiempo T-2, también limita naturalmente el poder de cómputo paralelo y quiere mejorar el poder de cómputo paralelo en la estructura dependiente de la secuencia, lo que conduce a CNN.
3. CNN alguna vez fue brillante
La red neuronal convolucional (CNN para abreviar) es un modelo de aprendizaje profundo que se usa comúnmente para procesar datos de imagen y voz. [Gran éxito en el campo visual]
En el campo de la PNL, se han publicado muchos artículos sobre las razones de los defectos de computación paralela causados por la estructura dependiente de la secuencia de RNN.Están explorando la nueva estructura de RNN, pero esta nueva estructura se está acercando gradualmente a la estructura de CNN. lo que lleva al desarrollo de CNN en aplicaciones de campo de PNL.
La siguiente es una explicación específica del principio CNN:
CNN se compone principalmente de capa convolucional, capa de agrupación y capa totalmente conectada. Entre ellos, la capa convolucional y la capa de agrupación constituyen la parte de extracción de características de CNN, y la capa totalmente conectada es responsable de asignar las características extraídas a la categoría de salida.
La capa de convolución es la parte central de CNN, que utiliza un conjunto de núcleos de convolución aprendibles (Convolution Kernel) para realizar operaciones de convolución en el mapa de características de entrada (Mapa de características). La operación de convolución puede extraer características locales en el mapa de características mientras conserva la información de ubicación espacial de las características. El resultado de la operación de convolución se denomina mapa de características convolucionales (Mapa de características convolucionales).
En aplicaciones prácticas, la operación de convolución generalmente aplica múltiples núcleos de convolución de diferentes tamaños y realiza operaciones de activación no lineales en los mapas de características convolucionales, como ReLU.
La capa de agrupación se utiliza para reducir el tamaño espacial del mapa de características y reducir la cantidad de parámetros del modelo, evitando así el sobreajuste. Las operaciones de agrupación comúnmente utilizadas incluyen Max Pooling y Average Pooling. La operación de agrupación máxima toma el valor máximo en cada región del mapa de características de entrada como salida, y la operación de agrupación promedio toma el valor promedio en cada región como salida.
Las capas completamente conectadas asignan las características obtenidas por operaciones de convolución y agrupación a categorías de salida. Por lo general, las características obtenidas por las capas de convolución y agrupación se expanden en vectores unidimensionales, y luego las tareas como la clasificación o la regresión se realizan a través de múltiples capas completamente conectadas.
El entrenamiento de CNN generalmente adopta el algoritmo de retropropagación para actualizar los parámetros del modelo. Debido a la estructura jerárquica del modelo CNN, el cálculo de la retropropagación se puede aplicar fácilmente a toda la red, mejorando así la eficiencia de entrenamiento del modelo.
Diagrama de ejemplo del proceso de convolución:
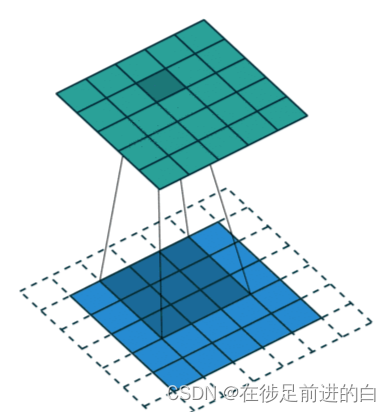
La convolución binaria es la convolución más utilizada:
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=2,
bias=False, dilation=1) # 前两个参数为通道数
Explicación de los parámetros en la función:
Tamaño del núcleo: el tamaño del núcleo de convolución define el campo de visión de la convolución. Una opción común en 2 dimensiones es 3, es decir, una matriz de píxeles de 3x3.
Paso: El paso define el tamaño del paso del movimiento del kernel de convolución al atravesar la imagen. Aunque su valor predeterminado suele ser 1, podemos usar un tamaño de paso de 2 para reducir la resolución de las imágenes de forma similar a MaxPooling.
Relleno: el relleno define cómo manejar los límites de las muestras. El propósito de Padding es mantener el tamaño de salida de la operación de convolución igual al tamaño de entrada, porque si el kernel de convolución es mayor que 1, ningún relleno hará que el tamaño de salida de la operación de convolución sea más pequeño que el tamaño de entrada.
Canales de entrada y salida (Canales): las capas convolucionales generalmente requieren una cierta cantidad de canales de entrada (I) y calculan una cierta cantidad de canales de salida (O). Los parámetros necesarios se pueden calcular mediante I * O * K, donde K es igual al número de parámetros en el kernel de convolución, es decir, el tamaño del kernel de convolución.
[La convolución bidimensional es la más utilizada, y hay diferentes convoluciones, habrá un resumen especial más adelante]
4. La tendencia general de la extracción de características de transformadores
Transformador se refiere al marco completo de Codificador-Decodificador, y aquí estoy hablando desde la perspectiva del extractor de características. Puede entenderlo simplemente como la parte Codificador del documento. Debido a que el propósito de la parte del Codificador es relativamente simple, que es extraer características de la oración original, mientras que la parte del Decodificador tiene relativamente más funciones.Además de la función de extracción de características, también incluye la función del modelo de lenguaje y la función del modelo de traducción. expresada por el mecanismo de atención.
Hay dos versiones de Transformer: Transformer base y Transformer Big. La estructura de los dos es en realidad la misma. La principal diferencia es que el número de Transformer Blocks incluidos es diferente. El Transformer base contiene 12 superposiciones de Block, mientras que el Transformer Big se duplica y contiene 24 Blocks.

No es solo la autoatención lo que puede hacer que Transformer funcione bien, sino que todos los elementos de este bloque, incluida la autoatención de varios cabezales, la conexión de salto, la norma de capa y FF, funcionan juntos.
Sabemos que Transformer Block en realidad no es solo un componente, sino un pequeño sistema compuesto por varios componentes, como atención de múltiples cabezas/conexión de salto/Norma de capa/red de avance.Si conectamos RNN o CNN en Transformer Block, ¿qué sucederá? ¿Qué pasa?

5. Explicación detallada del modelo de transformador
[Las palabras son más complicadas y el texto es más, solo entiende el proceso aproximadamente]
El modelo Transformer consta de dos partes: un codificador (Encoder) y un decodificador (Decoder), donde el codificador es responsable de convertir la secuencia de entrada en un conjunto de vectores de características, y el decodificador es responsable de convertir estos vectores de características en una salida. secuencia. Tanto el codificador como el decodificador se componen de múltiples capas idénticas (capa), cada capa contiene un módulo de autoatención de múltiples cabezales (autoatención de múltiples cabezales) y un módulo de red neuronal directa (red neuronal de avance).
En el codificador, cada posición de la secuencia de entrada se convierte en un vector de características y se procesa en cada capa. En el módulo de autoatención, los vectores de características de cada ubicación interactúan con los vectores de características de otras ubicaciones, donde los pesos de atención se calculan por la similitud entre cada ubicación y todas las ubicaciones. Este proceso puede verse como una autoatención a la secuencia de entrada (Autoatención), que puede aprender la importancia de las diferentes posiciones en la secuencia. Luego, el vector de características de cada posición es transformado de forma no lineal por el módulo de red neuronal directa para obtener una nueva representación de vector de características.
En el decodificador, similar al codificador, cada posición de la secuencia de salida también se convierte en un vector de características y se procesa en cada capa. Pero a diferencia del codificador, el decodificador también necesita atender los vectores de características producidos por el codificador a través de otro módulo de autoatención, de modo que toda la información producida por el codificador se considere al generar cada salida. En el módulo de autoatención, los pesos de atención se calculan a partir de la similitud entre los vectores de características en cada posición del decodificador y los vectores de características en cada posición del codificador. Luego, el vector de características de cada posición es transformado de forma no lineal por el módulo de red neuronal directa para obtener una nueva representación de vector de características.
Al alternar el procesamiento de las capas de codificador y decodificador, el modelo Transformer puede aprender la correspondencia entre la secuencia de entrada y la secuencia de salida, y se usa para varias tareas de NLP de secuencia a secuencia, como traducción automática, resumen de texto, reconocimiento de voz, etc En comparación con el modelo RNN tradicional, el modelo Transformer puede procesar secuencias más largas y puede procesarse en paralelo, y la velocidad de entrenamiento es más rápida.
6. Pirámide de características
Hay objetivos de diferentes tamaños en la imagen, y diferentes objetivos tienen diferentes características. Los objetivos simples se pueden distinguir mediante el uso de características superficiales; los objetivos complejos se pueden distinguir mediante el uso de características profundas. [Este extractor de funciones se utiliza principalmente en tareas de visión artificial, como la detección de objetivos y la segmentación de imágenes. 】
Explicación detallada del principio:
En los algoritmos de detección de objetos tradicionales, generalmente se usa una ventana deslizante de tamaño fijo para detectar la imagen de entrada. Sin embargo, el tamaño del objetivo es diferente en diferentes escalas, y si se utiliza una ventana deslizante de tamaño fijo, es posible que se pasen por alto algunos objetivos o que se detecten algunos objetivos incorrectos. La tecnología de pirámide de características puede resolver este problema, puede extraer características de la imagen a diferentes escalas, de modo que se puedan detectar objetos de diferentes tamaños.
La pirámide de características se implementa reduciendo la resolución de la imagen de entrada varias veces para obtener una serie de imágenes de diferentes escalas. Para las imágenes de cada escala, las características se pueden extraer utilizando una red neuronal convolucional entrenada y se puede generar un mapa de características. Dado que el tamaño de la imagen se reducirá después de la reducción de resolución, el tamaño del objeto detectado en cada mapa de funciones también se reducirá en consecuencia. Para detectar objetos de diferentes tamaños, se pueden usar filtros de diferentes tamaños para realizar operaciones de ventana deslizante en mapas de características de diferentes escalas.
Finalmente, la pirámide de características generará mapas de características de múltiples escalas y luego fusionará estos mapas de características para obtener el mapa de características final y realizará la detección de objetivos en este mapa de características. La tecnología de pirámide de características puede mejorar efectivamente la precisión y la recuperación de la detección de objetos, pero también aumenta la complejidad computacional y la dificultad del entrenamiento del modelo.
Aquí hay un código de ejemplo para crear un modelo FeaturePyramid con 5 niveles de características:
import torch.nn as nn
class FeaturePyramid(nn.Module):
def __init__(self, in_channels=256, out_channels=256, levels=5):
super(FeaturePyramid, self).__init__()
self.levels = levels
self.convs = nn.ModuleList()
self.upsamples = nn.ModuleList()
# bottom-up pathway
for level in range(self.levels):
self.convs.append(nn.Conv2d(in_channels, out_channels, kernel_size=1))
# lateral connections
for level in range(self.levels - 1):
self.convs.append(nn.Conv2d(in_channels, out_channels, kernel_size=1))
self.upsamples.append(nn.Upsample(scale_factor=2, mode='nearest'))
# top-down pathway
self.top_down = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, stride=1)
self.smooth = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, stride=1)
def forward(self, inputs):
# bottom-up pathway
features = [self.convs[0](inputs)]
for level in range(1, self.levels):
features.append(self.convs[level](features[-1]))
# top-down pathway
for level in range(self.levels - 2, -1, -1):
lateral = self.convs[self.levels + level](features[level])
upsampled = self.upsamples[level](lateral)
top_down = self.top_down(features[level+1])
features[level] = self.smooth(upsampled + top_down)
# upsample highest level feature map
features[-1] = self.upsamples[-1](features[-1])
return features
En PyTorch, puede usar nn.ModuleList para definir una lista de módulos y agregar todos los módulos a la lista. Se puede pasar una lista de módulos a la clase FeaturePyramid como argumentos del constructor. Para cada nivel de mapas de características, las operaciones de convolución se pueden definir utilizando capas nn.Conv2d. El mapa de características final se generará utilizando una cascada de capas nn.Conv2d y capas nn.Upsample.
En este ejemplo, la clase FeaturePyramid define tres listas de módulos mediante nn.ModuleList: self.convs, self.upsamples y self.downscales. Entre ellos, la lista self.convs contiene la capa de convolución de cada nivel de función desde abajo hacia arriba, la lista self.upsamples contiene la capa de muestreo ascendente de cada nivel de función desde abajo hacia arriba, y self.smooth y self Las capas .top_down se utilizan para conectar las rutas superior e inferior.
En el método directo, las características subyacentes se calculan primero a partir de la imagen de entrada y luego se pasan como parámetros a las capas convolucionales de cada nivel, y los mapas de características de cada nivel se calculan gradualmente. Luego, las rutas superior e inferior se recorren usando el orden de la capa más alta a la más baja, combinando características desde abajo y desde arriba usando una combinación de capas de muestreo ascendente, convolución y suavizado en cada nivel. Finalmente, los mapas de características de todos los niveles se devuelven en forma de lista.
Para obtener el modelo, niveles = 5 en la clase FeaturePyramid, simplemente cree una instancia de FeaturePyramid.
import torch
import torch.nn.functional as F
class FeaturePyramid:
def __init__(self, model, levels=5):
self.model = model
self.levels = levels
def __call__(self, image):
pyramid = []
for i in range(self.levels):
factor = 2 ** i
h, w = image.shape[-2:]
new_h, new_w = h // factor, w // factor
scaled_image = F.interpolate(image, size=(new_h, new_w), mode='bilinear', align_corners=False)
pyramid.append(scaled_image)
features = []
for i in range(self.levels):
feature_map = self.model(pyramid[i])
features.append(feature_map)
sizes = [(f.shape[-2], f.shape[-1]) for f in features]
return features, sizes
#该类的初始化函数接受一个已训练好的卷积神经网络模型和金字塔层数作为参数。调用对象时,需要传入输入#图像,并返回特征金字塔中每个尺度的特征图和大小。Código de muestra para la detección de objetos usando esta clase de pirámide de características:
class ObjectDetector:
def __init__(self, model, pyramid_levels=5, num_scales=3, score_thresh=0.5, nms_thresh=0.5):
self.model = model
self.pyramid = FeaturePyramid(model, levels=pyramid_levels)
self.num_scales = num_scales
self.score_thresh = score_thresh
self.nms_thresh = nms_thresh
def __call__(self, image):
detections = []
features, sizes = self.pyramid(image)
for i in range(len(features)):
feature_map = features[i]
h, w = sizes[i]
for j, size in enumerate([64, 128, 256][:self.num_scales]):
detection_map = self.model(feature_map)
detection_map = F.interpolate(detection_map, size=(h, w), mode='bilinear', align_corners=False)
scores, labels, boxes = self.decode_detection_map(detection_map)
# keep only detections with score above threshold
keep = scores > self.score_thresh
scores, labels, boxes = scores[keep], labels[keep], boxes[keep]
# apply non-maximum suppression
keep = self.non_max_suppression(scores, labels, boxes)
scores, labels, boxes = scores[keep], labels[keep], boxes[keep]
# convert boxes from relative to absolute coordinates
boxes[:, 0::2] *= w
boxes[:, 1::2] *= h
# append detections for this scale
detections.append((scores, labels, boxes))
# concatenate detections across all scales and sort by score
all_scores = torch.cat([s for s, _, _ in detections], dim=0)
all_labels = torch.cat([l for _, l, _ in detections], dim=0)
all_boxes = torch.cat([b for _, _, b in detections], dim=0)
_, idx = all_scores.sort(descending=True)
all_scores = all_scores[idx]
all_labels = all_labels[idx]
all_boxes = all_boxes[idx]
return all_scores, all_labels, all_boxes
def decode_detection_map(self, detection_map):
scores, labels = detection_map[:, :, 0], detection_map[:, :, 1:].argmax(dim=-1)
num_classes = detection_map.shape[-1] - 1
boxes = torch.zeros_like(detection_map[:, :, 1:])
for i in range(num_classes):
# compute center, width and height of boxes
ctr_x = torch.arange(detection_map.shape[1], dtype=torch.float32, device=detection_map.device) + 0.5
ctr_y = torch.arange(detection_map.shape[2], dtype=torch.float32, device=detection_map.device) + 0.5
ctr_x, ctr_y = torch.meshgrid(ctr_x, ctr_y)
ctr_x, ctr_y = ctr_x.reshape(-1), ctr_y.reshape(-1)
w = torch.exp(detection_map[:, :, i+1])
h = torch.exp(detection_map[:, :, num_classes+i+1])
# compute left, top, right and bottom coordinates of boxes
x1 = ctr_x - 0.5 * w
y1 = ctr_y - 0.5 * h
x2 = ctr_x + 0.5 * w
y2 = ctr_y + 0.5 * h
# concatenate box coordinates
boxes[:, :, i] = torch.stack([x1, y1, x2, y2], dim=-1)
return scores, labels, boxes
Esta función acepta un mapa de detección (un tensor 3D, la primera dimensión es el tamaño del lote, la segunda y tercera dimensiones son el ancho y el alto del mapa de detección, respectivamente, y la cuarta dimensión es el número de canales de salida de la categoría objetivo y cuadro delimitador), y devolver el resultado de detección de destino. En primer lugar, la función extrae la puntuación y la predicción de clase para cada píxel del mapa de detección y, a continuación, utiliza una función exponencial para restaurar las predicciones de anchura y altura del cuadro delimitador a los valores reales. A continuación, la función calcula las coordenadas superior izquierda e inferior derecha del cuadro delimitador en cada píxel de la imagen y, finalmente, devuelve la puntuación, la clase y el cuadro delimitador.
Siete, modelo de pre-entrenamiento
Un modelo preentrenado generalmente consta de dos partes: la arquitectura del modelo y los parámetros del modelo. La arquitectura del modelo define la estructura y el gráfico de cálculo del modelo, incluidas varias capas convolucionales, capas de agrupación, capas totalmente conectadas, etc. Los parámetros del modelo son los términos de ponderación y sesgo del modelo, que se aprenden durante el entrenamiento.
El uso de un modelo previamente entrenado puede acelerar en gran medida el entrenamiento del modelo y mejorar la precisión del modelo. Los modelos preentrenados se han convertido en lo último en muchas tareas de procesamiento de lenguaje natural y visión artificial. Por ejemplo, usar un modelo BERT previamente entrenado para tareas de clasificación de texto puede lograr mejores resultados que usar un modelo entrenado desde cero.
Los pasos para aplicar un modelo pre-entrenado se pueden resumir de la siguiente manera:
1. Seleccione un modelo de preentrenamiento apropiado: seleccione un modelo de preentrenamiento apropiado de acuerdo con las necesidades de tareas específicas. Por ejemplo, puede elegir BERT, GPT y otros modelos en tareas de procesamiento de lenguaje natural, y puede elegir ResNet, Inception y otros modelos en tareas de visión artificial.
2. Cargue el modelo preentrenado: cargue los parámetros y la arquitectura del modelo preentrenado en la memoria, generalmente usando la API proporcionada por el marco de entrenamiento del modelo, como PyTorch, TensorFlow y otros marcos.
3. Ajuste el modelo para tareas específicas: dado que el modelo previamente entrenado se entrena en un conjunto de datos a gran escala, sus parámetros ya tienen capacidades sólidas de extracción de características. Sin embargo, en tareas específicas, es posible que sea necesario ajustar el modelo previamente entrenado para satisfacer las necesidades de la tarea. Se puede realizar un ajuste fino entrenando el modelo en un conjunto de datos específico de la tarea.
4. Evaluación y ajuste del modelo: use el conjunto de datos de evaluación para evaluar el modelo ajustado y ajuste el modelo para lograr el mejor rendimiento.
5. Aplicar el modelo: utilice el modelo ajustado para tareas específicas, como clasificación de texto, detección de objetos, segmentación de imágenes, etc.
Estos son algunos ejemplos de modelos preentrenados de uso común:
1. Modelo de pre-entrenamiento de procesamiento de lenguaje natural:
- BERT (Representaciones de codificador bidireccional de transformadores)
- GPT (Transformador preentrenado generativo)
- RoBERTa (enfoque de preentrenamiento BERT robustamente optimizado)
- XLNet (comprensión extrema de idiomas multilingües)
- ALBERT (Un ligero BERT)
- T5 (Transformador de transferencia de texto a texto)
- ELECTRA (aprendizaje eficiente de un codificador que clasifica los reemplazos de tokens con precisión)
2. Modelo de pre-entrenamiento de visión artificial:
- ResNet (red residual)
- Inicio (Inicio de GoogleNet)
- VGG (Grupo de Geometría Visual)
- MobileNet (Red móvil)
- EfficientNet (Red Neuronal Eficiente)
- DenseNet (red convolucional densamente conectada)
Estos modelos previamente entrenados han sido previamente entrenados en conjuntos de datos a gran escala y han logrado buenos resultados en sus respectivos campos, y pueden aplicarse directamente a las tareas correspondientes o ajustarse para satisfacer las necesidades de tareas específicas.