Haga clic en la tarjeta a continuación para prestar atención a la cuenta pública " Automatic Driving Heart "
Productos secos ADAS Jumbo, puedes conseguirlo
Hoy, Heart of Autopilot tiene el honor de invitar a Garfield a compartir el último desarrollo del algoritmo de preentrenamiento unificado BEV Occ-BEV. Garfield también es nuestro autor contratado. Si tiene un trabajo relacionado para compartir, comuníquese con nosotros al final del ¡artículo!
>>Haga clic para ingresar → El corazón de la conducción autónoma [Percepción BEV] Grupo de intercambio técnico
El corazón del piloto automático Autor | Garfield
Editor | El corazón del piloto automático
1. Información en papel
Título de la tesis: Occ-BEV: preentrenamiento unificado multicámara a través de la reconstrucción de escenas 3D
Autor: Chen Min
Enlace: https://arxiv.org/pdf/2305.18829.pdf
Código: https://github.com/chaytonmin/Occ-BEV
2. Introducción

Los sistemas de percepción 3D de múltiples cámaras en la conducción autónoma brindan una solución rentable para recopilar información ambiental alrededor del vehículo y, por lo tanto, se han convertido en un punto crítico de investigación en los últimos años. Sin embargo, los modelos de percepción 3D multicámara actuales generalmente se basan en modelos ImageNet o modelos de estimación de profundidad entrenados previamente en imágenes monoculares. Estos modelos no tienen en cuenta las correlaciones espaciales y temporales inherentes presentes en los sistemas multicámara. Además, aunque el entrenamiento previo monocular mejora la capacidad de extracción de características de la imagen, no puede abordar completamente los requisitos de entrenamiento previo de las tareas posteriores. Los vehículos autónomos recopilan una gran cantidad de pares de imagen-LiDAR, que contienen valiosa información espacial y estructural en 3D. Por lo tanto, la utilización efectiva de estos pares de imagen-LiDAR sin etiquetar puede ayudar a mejorar el rendimiento de los sistemas de conducción autónomos.
Estudios recientes, como BEVDepth y DD3D, han destacado la importancia de la estimación de la profundidad en los algoritmos de percepción basados en la visión. La estimación de profundidad monocular juega un papel clave en la obtención de información de ubicación espacial de los objetos. Sin embargo, los métodos de estimación de profundidad generalmente se enfocan en estimar la profundidad de la superficie del objeto, ignorando la estructura 3D general y los elementos de oclusión del objeto. Para los sistemas de percepción multicámara, se puede utilizar una cuadrícula de ocupación geométrica 3D para describir la escena 3D. La predicción precisa de la ocupación geométrica es crucial para mejorar la precisión de la percepción 3D general en los sistemas de percepción multicámara. Por lo tanto, en el campo de la percepción de conducción autónoma, frente a solo enfatizar la predicción de profundidad, el entrenamiento previo del modelo traerá mayores beneficios al priorizar la reconstrucción de la cuadrícula de ocupación de toda la escena 3D.
Los seres humanos tienen una capacidad asombrosa para reconstruir mentalmente la geometría 3D completa de una escena ocluida, lo cual es fundamental para el reconocimiento y la comprensión. Para dotar al sistema de percepción de los vehículos autónomos de capacidades similares, proponemos un método de preentrenamiento unificado multicámara denominado Occ-BEV. Nuestro método explota el concepto intuitivo de utilizar un sistema multicámara para reconstruir una escena 3D como escenario base, que luego se ajusta en las tareas posteriores. En el caso de la percepción BEV multicámara, se utilizan técnicas avanzadas como LSS o Transformer para convertir imágenes multicámara de entrada en espacio BEV, y luego se agregan cabezales de predicción de ocupación geométrica para aprender la distribución de ocupación 3D, mejorando así la comprensión del modelo de Escenas circundantes en 3D. Debido a la escasez de nubes de puntos de un solo cuadro, empleamos la fusión de nubes de puntos de varios cuadros como punto de referencia para la generación de etiquetas de ocupación. El decodificador solo se usa para el entrenamiento previo, mientras que el modelo bien entrenado se usa para inicializar el modelo de percepción multicámara. Mediante el diseño de un método de preentrenamiento unificado multicámara eficiente, permitimos que los modelos preentrenados exploten la rica información espacial y temporal inherente a los datos sin etiquetar. Esto no solo mejora la capacidad del modelo para comprender escenas 3D complejas, sino que también reduce la dependencia de anotaciones 3D manuales costosas y que consumen mucho tiempo.
Para evaluar la efectividad de nuestro método, llevamos a cabo extensos experimentos utilizando nuScenes, un conjunto de datos de conducción autónoma ampliamente utilizado. Los resultados experimentales muestran que nuestro método logra un rendimiento de vanguardia en varias tareas clave, como la detección de obstáculos, la segmentación semántica y el seguimiento de objetos. En particular, en el entorno semisupervisado, nuestro método puede mejorar en gran medida el rendimiento de los sistemas de conducción autónomos, acercándose o incluso superando el nivel de aprendizaje supervisado. Además, también validamos experimentalmente la capacidad de generalización y escalabilidad de nuestro método, demostrando su potencial y practicidad. En resumen, el método de preentrenamiento unificado multicámara es un algoritmo de percepción de conducción autónoma efectivo y juega un papel importante en la utilización de datos no etiquetados. Este método mejora la percepción 3D de los vehículos autónomos aprendiendo la distribución de ocupación de toda la escena 3D, mejorando así su rendimiento en entornos complejos. Esto tiene implicaciones importantes para la realización de sistemas de conducción autónomos seguros, fiables y eficientes.
3. Método
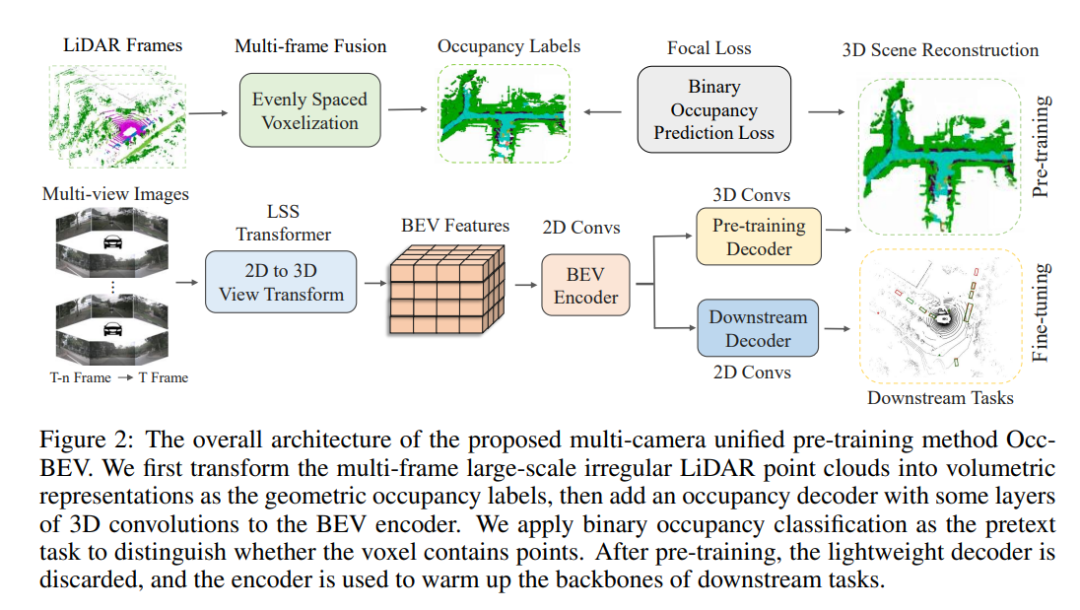
El método propuesto en este artículo es Occ-BEV, que es un modelo preentrenado unificado multicámara para tareas de percepción de Bird's Eye View (BEV) en conducción autónoma. A continuación, se presentará este método a partir de los aspectos de la revisión de la percepción de BEV, el decodificador de ocupación geométrica, el objetivo de preentrenamiento y el preentrenamiento para la predicción de ocupación semántica circundante.
3.1 Revisión de la percepción de BEV
Este documento revisa los métodos existentes basados en la visión para la percepción de BEV e introduce el flujo de trabajo de un modelo preentrenado unificado multicámara. Este flujo de trabajo implica el procesamiento de imágenes de entrada de varias cámaras mediante una red troncal de imágenes para generar mapas de características para cada vista de cámara. Estos mapas de características se convierten en una representación BEV unificada y, a través de un procesamiento de cabeza específico, se realizan una variedad de tareas de percepción de conducción autónoma, como detección de objetos 3D, segmentación de mapas, seguimiento de objetos, etc. Los algoritmos de percepción de BEV actuales generalmente se basan en modelos de extracción de características (como ImageNet) o modelos de estimación de profundidad (como V2-99) entrenados en imágenes monoculares. Sin embargo, estos métodos ignoran las relaciones espaciales y temporales entre las vistas de diferentes cámaras y fotogramas, por lo que carecen de un modelo preentrenado unificado multicámara. Para aprovechar al máximo las relaciones espaciales y temporales entre las diferentes vistas de cámara, este artículo propone un modelo preentrenado unificado multicámara.
3.2 Preentrenamiento unificado multicámara
El preentrenamiento unificado multicámara es un método de preentrenamiento para tareas de percepción de Bird's Eye View (BEV) en conducción autónoma. Genera mapas de funciones para cada vista de cámara mediante el uso de imágenes de entrada de varias cámaras y convierte estos mapas de funciones en una representación BEV unificada, lo que permite una variedad de tareas de percepción de conducción autónoma, como detección de objetos 3D, segmentación de mapas, espera de seguimiento de objetos. El núcleo de este método de preentrenamiento es usar un decodificador de ocupación geométrica y un objetivo preentrenado para predecir escenas 3D a partir de imágenes de vistas múltiples. Específicamente, el objetivo de preentrenamiento es la tarea de clasificación de ocupación geométrica binaria, y la red está entrenada para predecir con precisión la distribución de ocupación geométrica de escenas 3D basadas en imágenes de vista múltiple. El decodificador de ocupación geométrica consta de capas convolucionales 3D ligeras y proporciona la probabilidad de que cada vóxel contenga un punto a través de una capa final. Durante el preentrenamiento, el objetivo principal del decodificador es reconstruir los vóxeles ocupados.
3.2.1 Decodificador de ocupación geométrica
Bien, ahora combinaré las fórmulas para presentar los tres aspectos del decodificador de ocupación geométrica, el objetivo de preentrenamiento y el preentrenamiento para la predicción de ocupación semántica circundante.
En primer lugar, el decodificador de ocupación geométrica es un decodificador para predecir la ocupación geométrica en 3D. Puede procesar el mapa de características a través de capas convolucionales 3D ligeras y proporcionar la probabilidad de que cada vóxel contenga un punto a través de la capa final. La salida de este decodificador se puede expresar como la siguiente fórmula:
Entre ellos, está la probabilidad de que cada vóxel contenga un punto, es la función sigmoidea, es la operación de convolución 3D y es el mapa de características BEV. El valor del decodificador de ocupación geométrica radica en la capacidad de predecir la probabilidad de que cada vóxel en una escena 3D contenga un punto mediante el procesamiento de imágenes de múltiples vistas. Esto es muy importante para las tareas de percepción de la conducción autónoma, ya que los vehículos autónomos necesitan percibir con precisión el entorno que los rodea para conducir con seguridad. Predecir la probabilidad de que cada vóxel en una escena 3D contenga un punto puede ayudar a los vehículos autónomos a comprender mejor la geometría y la ocupación de su entorno.
3.2.2 Objetivo de pre-entrenamiento
En segundo lugar, Pre-training Target es un método para generar objetivos de pre-entrenamiento. Utiliza la nube de puntos LiDAR para generar etiquetas de ocupación, divide la nube de puntos LiDAR en vóxeles espaciados uniformemente y cada vóxel indica si un punto está contenido o no. La ocupación de estos vóxeles, es decir, si cada vóxel está ocupado, sirve como verdad fundamental. El entrenamiento previo se enfoca en la tarea de clasificación de ocupación geométrica binaria y entrena a la red para predecir con precisión la distribución de ocupación geométrica de escenas 3D basadas en imágenes de vista múltiple. La función de pérdida del objetivo de preentrenamiento se puede expresar con la siguiente fórmula:
donde es el número de vóxeles, es el valor real y es el valor predicho. El valor de Pre-training Target es proporcionar un objetivo de pre-entrenamiento preciso para entrenar la red para predecir con precisión la distribución de ocupación geométrica de escenas 3D basadas en imágenes de vista múltiple. Dado que el objetivo de preentrenamiento es la tarea de clasificación de ocupación geométrica binaria, y la pérdida focal se utiliza para resolver el problema de clasificación binaria desequilibrada, esto puede mejorar en gran medida la precisión y la estabilidad del modelo preentrenado. Además, la nube de puntos LiDAR se usa para generar etiquetas de ocupación para que esté más en línea con la escena real, mejorando así la capacidad de generalización del modelo pre-entrenado.
3.2.3 Pre-entrenamiento para predicción de ocupación semántica del entorno
Finalmente, el entrenamiento previo para la predicción de ocupación semántica circundante extiende el algoritmo de entrenamiento previo a la escena semántica circundante para completar la tarea. En función de la predicción de ocupación geométrica, el modelo preentrenado se ajusta para predecir la semántica 3D de imágenes de múltiples vistas. Específicamente, la función de pérdida de ajuste fino del modelo pre-entrenado se puede expresar como la siguiente fórmula:
donde es el valor verdadero de las etiquetas semánticas circundantes, las etiquetas semánticas circundantes pronosticadas, el número de etiquetas semánticas circundantes y el coeficiente de ponderación de la función de pérdida de ajuste fino. El valor del entrenamiento previo para la predicción de ocupación semántica circundante radica en extender el algoritmo de entrenamiento previo a la escena semántica circundante para completar la tarea. La ventaja de esto es que evita la sobrecarga y el costo de tiempo de recopilar una gran cantidad de anotaciones semánticas 3D para entrenar el modelo. Mediante el ajuste fino de los modelos preentrenados para predecir la semántica 3D a partir de imágenes multivista, los objetos y las escenas del entorno se pueden comprender mejor, mejorando así la percepción y la seguridad de los vehículos autónomos.
4. Experimenta
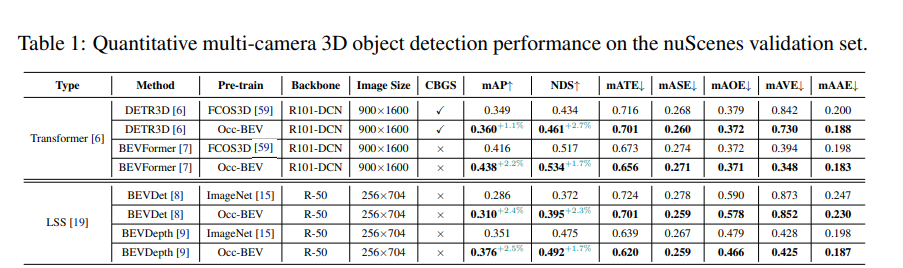
Los resultados experimentales muestran el rendimiento del método occbev y el método anterior en el conjunto de validación de nuScenes. El experimento utiliza cuatro modelos diferentes, a saber, DETR3D, BEVFormer, BEVDet y BEVDepth, y compara su rendimiento cuando se utiliza el preentrenamiento ImageNet u Occ-BEV. Al mismo tiempo, el experimento también investigó la influencia de factores tales como diferentes columnas vertebrales, tamaños de imagen y CBGS (es decir, si se usa muestreo equilibrado por categorías) en el rendimiento del modelo. Los resultados muestran que el modelo pre-entrenado con Occ-BEV se desempeña mejor en la tarea de detección de objetos 3D de vista múltiple. Tomando el modelo DETR3D como ejemplo, el modelo preentrenado con Occ-BEV ha mejorado significativamente mAP y NDS (1,1 % y 2,7 % respectivamente) en comparación con el modelo preentrenado con ImageNet. Además, se observaron resultados similares en otros modelos. Esto muestra que el método de preentrenamiento Occ-BEV puede mejorar efectivamente el rendimiento de la detección de objetos 3D de vista múltiple. Además, los experimentos también muestran que con el método de preentrenamiento Occ-BEV, el rendimiento del modelo se puede mejorar incluso sin CBGS. Esto demuestra que Occ-BEV puede utilizar de forma efectiva información de vistas múltiples y mejorar la solidez del modelo.

Los resultados experimentales demuestran el rendimiento de dos métodos diferentes (DD3D y Occ-BEV) en una tarea de detección de objetos 3D de vista múltiple, evaluados con el conjunto de prueba nuScenes. Los resultados muestran que el modelo DETR3D preentrenado con Occ-BEV es un 1,9% y un 1,7% más alto en mAP y NDS que el modelo preentrenado con DD3D. Esto demuestra que el método de preentrenamiento Occ-BEV puede mejorar efectivamente el rendimiento de la detección de objetos 3D de vista múltiple, especialmente en escenas complejas. Al mismo tiempo, los indicadores de error como mATE, mASE, mAOE, mAVE y mAAE del modelo preentrenado con Occ-BEV también disminuyeron, lo que indica que el método puede estimar con mayor precisión la posición y la actitud de los objetos 3D.

Los resultados experimentales demuestran el rendimiento de la segmentación utilizando diferentes métodos (BEVFormer, BEVDet4D, BEVStereo+Occ-BEV) en el desafío de predicción de ocupación 3D. Los resultados muestran que en el caso de utilizar Swin-B como red troncal, el método BEVStereo con preentrenamiento Occ-BEV mejora el índice mIoU en un 3,14% en comparación con los métodos BEVFormer y BEVDet4D. Por su parte, el método BEVStereo+Occ-BEV supera a la mayoría de las categorías, especialmente a las categorías “barrera”, “bicicleta” y “conducible”, que aumentan un 26,21%, 33,41% y 4,69%, respectivamente. Esto muestra que el método de preentrenamiento Occ-BEV puede mejorar efectivamente el rendimiento de la predicción de escenas semánticas multicámara, especialmente en escenas complejas.
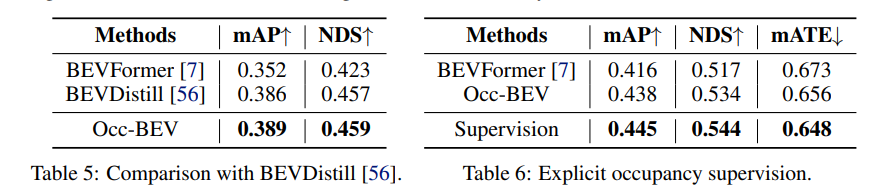
Para las tareas posteriores, el método ha logrado un buen rendimiento en las tareas de detección de objetos 3D de múltiples vistas y predicción de escenas semánticas de múltiples cámaras. En la tarea de detección de objetos 3D de vista múltiple, el modelo preentrenado con Occ-BEV ha mejorado significativamente en comparación con otros métodos en el conjunto de verificación de nuScenes. Por ejemplo, en comparación con el modelo BEVFormer preentrenado con ImageNet, los dos indicadores de NDS y mAp 1,7% y 2,2% respectivamente. En la tarea de predicción de escena semántica multicámara, el modelo preentrenado con Occ-BEV mejora el índice mIoU en el desafío de predicción de ocupación 3D en un 3 % en comparación con el método BEVStereo. Esto muestra que el método puede mejorar efectivamente el rendimiento de la detección de objetos 3D de múltiples vistas y la predicción de escenas semánticas de múltiples cámaras.
5. Discusión

En comparación con el método anterior, el método occbev tiene las siguientes diferencias:
El método occbev adopta imágenes de entrada de múltiples cámaras y logra una mejor comprensión y una predicción más precisa de entornos dinámicos mediante el uso de información de imágenes de múltiples vistas. En comparación con el método de preentrenamiento de imagen monocular anterior, el método occbev tiene una mejor capacidad de fusión espacio-temporal.
El método occbev adopta una representación BEV unificada, lo que permite que el modelo aprenda una representación compartida entre diferentes vistas de cámara, lo que facilita una mejor transferencia de conocimientos y reduce la necesidad de un entrenamiento previo específico para la tarea. En comparación con el método de preentrenamiento de estimación de profundidad anterior, el método occbev tiene una mejor capacidad de fusión de información de múltiples vistas.
El método occbev también tiene la capacidad de percibir objetos ocluidos y, al predecir la ocupación de cada vóxel, se puede lograr una reconstrucción 3D más completa de los objetos ocluidos. En comparación con el método de destilación de conocimiento anterior, el método occbev no requiere una gran cantidad de datos de anotación 3D ni un modelo de detección LiDAR preentrenado, lo que reduce los requisitos y costos de la anotación 3D. Además, el método occbev también puede utilizar escenas 3D generadas por tecnologías como Nerf como etiquetas, eliminando así la dependencia de los datos LiDAR.
Aunque el rendimiento de los métodos Occ-BEV en escenarios de conducción autónoma ha mostrado un gran potencial, todavía hay margen de mejora. Aquí hay algunas posibles direcciones de mejora:
Mejores métodos de reconstrucción de escenas 3D: el rendimiento de los métodos Occ-BEV depende en gran medida de la calidad de los métodos de reconstrucción de escenas 3D, por lo que mejorar los métodos de reconstrucción de escenas 3D puede ayudar a mejorar el rendimiento de los métodos Occ-BEV.
Mejor conjunto de datos de preentrenamiento: el método Occ-BEV actual utiliza datos LiDAR de imágenes sin etiquetar a gran escala para entrenar previamente el modelo. Sin embargo, puede haber algo de ruido e inexactitud en estos conjuntos de datos, por lo que recopilar conjuntos de datos previos al entrenamiento más precisos y ricos puede ayudar a mejorar el rendimiento del método Occ-BEV.
Mejor estrategia de fusión multicámara: el método Occ-BEV utiliza una estrategia simple de fusión multicámara, que promedia las características BEV de cada cámara. Sin embargo, mejores estrategias de fusión pueden mejorar aún más el rendimiento del modelo, por ejemplo, considerando la distancia y el ángulo entre diferentes cámaras, así como la resolución y el campo de visión de las cámaras.
Mejores métodos de posprocesamiento: el método Occ-BEV utiliza algunos métodos simples de posprocesamiento, como la supresión no máxima y el llenado de agujeros, para mejorar aún más el rendimiento del modelo. Sin embargo, mejores métodos de posprocesamiento pueden mejorar aún más el rendimiento del modelo, por ejemplo, incorporando conocimientos previos para eliminar algunas predicciones erróneas.
6. Conclusión
Definimos una tarea de preentrenamiento unificada multicámara y proponemos el primer algoritmo de preentrenamiento unificado que demuestra un rendimiento sobresaliente en múltiples tareas de conducción autónoma, como la detección de objetos 3D de múltiples vistas y la finalización de escenas semánticas circundantes. El entrenamiento previo de escenas 3D con datos LiDAR de imagen sin etiquetar puede reducir efectivamente la dependencia de los datos 3D etiquetados y brindar una oportunidad prometedora para construir modelos básicos para la conducción autónoma. El trabajo futuro debería centrarse en abordar las limitaciones mencionadas y mejorar aún más el rendimiento y la aplicabilidad de nuestro método en escenarios reales de conducción autónoma.
(1) ¡El video curso está aquí!
El corazón de la conducción autónoma reúne fusión de visión de radar de ondas milimétricas, mapas de alta precisión, percepción BEV, calibración de sensores, despliegue de sensores, percepción cooperativa de conducción autónoma, segmentación semántica, simulación de conducción autónoma, percepción L4, planificación de decisiones, predicción de trayectoria, etc. Video de aprendizaje de dirección, bienvenido a tomarlo usted mismo (escanee el código para ingresar al aprendizaje)

(Escanea el código para conocer el último video)
Sitio web oficial del vídeo: www.zdjszx.com
(2) La primera comunidad de aprendizaje de conducción autónoma en China
Una comunidad de comunicación de casi 1,000 personas y más de 20 rutas de aprendizaje de pila de tecnología de conducción autónoma, desea obtener más información sobre la percepción de conducción autónoma (clasificación, detección, segmentación, puntos clave, líneas de carril, detección de objetos 3D, Ocupación, fusión de sensores múltiples, seguimiento de objetos, estimación de flujo óptico, predicción de trayectoria), posicionamiento y mapeo de conducción automática (SLAM, mapa de alta precisión), planificación y control de conducción automática, soluciones técnicas de campo, implementación de implementación de modelos de IA, tendencias de la industria, publicaciones de trabajo, bienvenido a escanear el Código QR a continuación, Únase al planeta del conocimiento del corazón de la conducción autónoma, este es un lugar con productos secos reales, intercambie varios problemas para comenzar, estudiar, trabajar y cambiar de trabajo con los grandes en el campo, comparta papeles + códigos + videos diarios , esperamos el intercambio!

(3) [ Corazón de la conducción automatizada ] Grupo de intercambio de tecnología de pila completa
El corazón de la conducción autónoma es la primera comunidad de desarrolladores para la conducción autónoma, que se centra en la detección de objetos, la segmentación semántica, la segmentación panorámica, la segmentación de instancias, la detección de puntos clave, las líneas de carril, el seguimiento de objetos, la detección de objetos en 3D, la percepción de BEV, la fusión de sensores múltiples, SLAM, estimación de flujo de luz, estimación de profundidad, predicción de trayectoria, mapa de alta precisión, NeRF, control de planificación, implementación de modelos, prueba de simulación de conducción automática, administrador de productos, configuración de hardware, búsqueda de trabajo y comunicación de IA, etc.;

Agregue la invitación de Autobot Assistant Wechat para unirse al grupo
Observaciones: escuela/empresa + dirección + apodo