Segmentación semántica LiDAR en tiempo real basada en una red de fusión de malla de puntos en cascada
0 resumen
La segmentación semántica LiDAR, que es fundamental para la conducción autónoma avanzada, debe ser precisa, rápida y fácil de implementar en una plataforma móvil. Los métodos anteriores basados en puntos o basados en vóxeles dispersos están muy lejos de las aplicaciones en tiempo real debido a las búsquedas de vecinos que consumen mucho tiempo o las convoluciones 3D escasas. Los métodos recientes basados en la proyección 2D , incluida la vista de rango y la fusión de múltiples vistas, pueden ejecutarse en tiempo real, pero son menos precisos debido a la pérdida de información durante la proyección 2D. Además, para mejorar el rendimiento, los métodos anteriores suelen emplear el aumento del tiempo de prueba (TTA), lo que ralentiza aún más el proceso de inferencia. Para lograr una mejor compensación entre velocidad y precisión, proponemos la red de fusión de cuadrícula de puntos en cascada (CPGNet), que utiliza principalmente las siguientes dos técnicas para garantizar la eficacia y la eficiencia: 1) Nueva cuadrícula de puntos (PG de cuadrícula de puntos). ) El bloque de fusión extrae principalmente características semánticas en cuadrículas proyectadas en 2D para mejorar la eficiencia, mientras que simultáneamente extrae características 2D y 3D en puntos 3D para reducir la pérdida de información; 2) La pérdida de consistencia de transformación propuesta reduce la inferencia del modelo de disparo único con Gap between TTAs. Los experimentos en los puntos de referencia de SemanticKITTI y nuScenes muestran que CPGNet sin modelos de conjunto o TTA es comparable al RPVNet de última generación, mientras que funciona 4,7 veces más rápido.
1. Introducción
Los sensores de detección de luz y alcance (lidar) se utilizan ampliamente en la conducción autónoma y la robótica. Los datos de nube de puntos 3D que capturan proporcionan una gran cantidad de información sobre la escena circundante. Estas segmentaciones semánticas lidar 3D asignan etiquetas semánticas a nubes de puntos, como automóviles, peatones, ciclistas, carreteras, edificios y, por lo tanto, están directamente relacionadas con la precisión y la seguridad de la transmisión. En los últimos años, se han propuesto varios modelos de aprendizaje profundo para procesar nubes de puntos 3D LiDAR, pero estos métodos no pueden garantizar tanto la precisión como la velocidad, especialmente en plataformas móviles (como automóviles y robots).
Los métodos de nube de puntos 3D basados en LiDAR existentes se pueden dividir en tres categorías: métodos basados en puntos, métodos basados en vóxeles dispersos y métodos basados en proyección 2D.
Los métodos basados en puntos incluyen PointNet [1], PointNet++ [2], PointCNN [3], RandLA-Net [4], etc. Se aplican directamente a nubes de puntos 3D sin ordenar sin pérdida de información. Sin embargo, estos métodos generalmente emplean operaciones que consumen mucho tiempo, a saber, reducción de muestreo uniforme con muestreo del punto más lejano (FPS) y búsqueda de vecino local con k-vecino más cercano (kNN) o consulta de bola.
Dado que los puntos LiDAR 3D son muy dispersos, los métodos basados en vóxeles dispersos cuantifican los puntos 3D en vóxeles y luego aplican operaciones de convolución 3D solo en estos vóxeles dispersos. Aunque estos métodos inevitablemente tienen pérdida de información debido a la cuantificación, logran un rendimiento de última generación. Sin embargo, estos métodos son computacionalmente costosos y no pueden ejecutarse en tiempo real.
Los métodos basados en proyección 2D aplican CNN 2D bien establecidas en mapas de características de malla 2D proyectados desde nubes de puntos 3D. Inspirados en las redes totalmente convolucionales (FCN) [5] y sus variantes [6], [7], [8], [9], [10], estos métodos basados en proyección 2D, generalmente consideran una vista de pájaro [11 ] o vista de rango [12], que se puede diseñar e implementar fácilmente en algunos marcos de inferencia de aprendizaje profundo efectivos (como TensorRT [13]). Cada escaneo LiDAR puede durar casi 15 ms. Sin embargo, estos métodos sufren de baja precisión debido a la grave pérdida de información de proyección 2D. Todavía funcionan peor, aunque RangeNet++ [14] a continuación intenta usar kNN como posprocesamiento, mientras que MPF [15] combina la vista de pájaro y la vista de rango.
Con este fin, proponemos CPGNet para una segmentación semántica lidar precisa en tiempo real. El bloque de fusión PG propuesto por CPGNet primero proyecta y extrae características semánticas en una cuadrícula 2D de vista de pájaro y vistas de rango, y luego transfiere y fusiona estas características en puntos 3D . Como puede verse, el bloque de fusión PG combina las ventajas de los métodos basados en puntos (información completa) con la rápida velocidad de los métodos basados en proyección 2d . El bloque de fusión CPGNet PG se aplica repetidamente para fortalecer aún más las características de los puntos. Además, inspirado en la pérdida de transición aumentada en el tiempo de prueba (TTA) entre las nubes de puntos originales y aumentadas, se propone un protocolo para garantizar un resultado consistente. Finalmente, comparamos CPGNet con métodos de código abierto, como se muestra en la Figura 1, y CPGNet logra el mejor mIoU (65.9) en el conjunto de validación SemanticKITTI [16], cuando se ejecuta en PyTorch FP32 NVIDIA RTX 2080 ti GPU en un tiempo de 43 ms. Las contribuciones se pueden enumerar de la siguiente manera:
- · Proponemos una CPGNet precisa, rápida y fácil de implementar para la segmentación semántica LiDAR. Incorpora un marco en cascada de capacidades de punto, vista de pájaro y vista de rango.
- Proponemos una pérdida de consistencia de transformación inspirada en el aumento del tiempo de prueba (TTA) y logramos un mayor rendimiento con una sola inferencia.
- La CPGNet propuesta logra la mejor compensación entre velocidad y precisión en los puntos de referencia de SemanticKITTI y nuScenes.
2. Trabajo relacionado
A diferencia de las imágenes 2D con estructuras de cuadrícula densa, las nubes de puntos están desordenadas, dispersas y sin estructura, lo que dificulta la aplicación de operaciones de aprendizaje profundo (como las circunvoluciones). Los enfoques anteriores han intentado abordar este problema de tres maneras.
A: método basado en puntos
Los métodos basados en puntos actúan directamente sobre el punto original. PointNet [1] aplica un perceptrón multicapa (MLP) compartido en cada punto y una agrupación máxima entre puntos para obtener características de puntos para tareas de segmentación adicionales. Sin embargo, PointNet realiza escenas más complejas por falta de extracción de contexto local. Los siguientes trabajos [2], [3] proponen consultas esféricas y χ-Conv para simular convoluciones 2D, que logran grandes resultados en escenas de interior. Sin embargo, no se pueden aplicar a la computación en la nube de puntos LIDAR ni al costo de la memoria. Para acelerar la inferencia de redes, RandLA-Net [4] emplea muestreo aleatorio y agregación de características locales, pero adolece de baja precisión debido al muestreo aleatorio. KPConv [17] propone un método novedoso basado en la convolución espacial para extraer la estructura local, y KPRNet [18] combina KPConv y ResNext [19] para lograr los mejores resultados en métodos punto a punto. Aunque el método integral se aplica directamente a los puntos originales sin borrar información, está menos estudiado para conducción autónoma debido a su ineficiente extracción de estructura local.
B. Enfoque de vóxel disperso
Construya vóxeles dispersos para facilitar las operaciones de convolución. SPVNAS [21] introdujo Neural Architecture Search (NAS) en [20] y logró mejores resultados con un menor costo computacional. Más recientemente, se han propuesto variantes de métodos basados en vóxeles dispersos [22], [23], [24]. Cylinder3D [22] cuantifica puntos 3D en un sistema de coordenadas cilíndricas y demuestra su eficiencia. AF2S3Net [23] propone el módulo de fusión de características de atención (AF2M) y el módulo de selección de características adaptativas (AFSM) para extraer de manera eficiente estructuras locales y globales simultáneamente. RPVNet [24] fusiona funciones de vista de rango, punto y vóxel disperso en un solo cuadro para mitigar el error de cuantificación y logra los mejores resultados en los puntos de referencia de SemanticKITTI y nuScenes. Si bien estos métodos dominan los puntos de referencia de segmentación semántica de LiDAR, sufren dificultades de implementación y no pueden ejecutarse en tiempo real en plataformas móviles.
C. Métodos basados en proyección 2D
Recientemente, los métodos basados en proyección 2D atraen más atención porque son rápidos y fáciles de implementar. Estos métodos utilizan FCN 2D para proyectar puntos 3D en cuadrículas 2D y rangos que incluyen principalmente fusión de vista y vista múltiple. Consulta proyectos que van desde puntos 3d hasta mallas esféricas 2d y hay muchas variantes. RangeNet++ [14] propone un posprocesamiento de información acelerado, que es un módulo integral en los siguientes métodos basados en rangos. SqueezeSegV3 [25] demuestra la superioridad de la convolución espacialmente adaptable. SalsaNext [26] diseña una nueva red de codificador-decodificador basada en SalsaNet [27], y emplea una lista de valores ´asz-Softmax loss [28] que pueden optimizar directamente la métrica de intersección media sobre unión (mIoU). Recientemente, Lite-HDSeg [29] propuso una elevación armónicamente densa y un enfoque basado en el rango para lograr los mejores resultados. Debido a la inevitable pérdida de información de proyección 2D de una sola vista o cuadrícula 2D, el siguiente proyecto de fusión de múltiples puntos de vista 3D se divide en dos o más tipos diferentes de cuadrículas 2D. MPF [15] y AMVNet [30] combinan vista de pájaro y vistas de rango. A diferencia de este enfoque, se comportan semánticamente de forma independiente en cada vista y fusionan los resultados de segmentación de los módulos de fusión tardía de dos vistas.
3 MÉTODO PROPUESTO
Para realizar la segmentación semántica LiDAR con precisión y rapidez, es necesario no solo extraer las características semánticas de manera eficiente, sino también mantener la integridad de la información de la nube de puntos. Por lo tanto, proponemos el bloque de fusión Point Grid (PG) para CPGNet para extraer características de puntos gradualmente. Como se muestra en la Figura 2, el bloque de fusión PG consta de cuatro pasos:
1) La operación de punto a cuadrícula (P2G) proyecta las características del punto de entrada en los mapas de características de vista de pájaro y vista de rango, respectivamente;
2) Aplicar 2D FCN en el mapa de características 2D para extraer características semánticas de manera eficiente;
3) Las operaciones de cuadrícula a punto (G2P) transfieren características de cuadrícula 2D a puntos 3D;
4) La fusión de puntos fusiona las funciones desde el punto 3D, la vista de pájaro y las ramas de la vista de rango para garantizar una información completa de la nube de puntos.
Se puede ver que CPGNet combina las ventajas de los métodos basados en proyección 2D y basados en puntos. A excepción de P2G y G2P, los componentes de CPGNet se pueden implementar directamente en TensorRT. Las operaciones P2 G y G2 P se pueden implementar con código CUDA eficiente. Cada bloque de fusión PG de CPGNet comparte la misma arquitectura de red pero no tiene parámetros. Consulte las subsecciones a continuación para obtener más detalles.
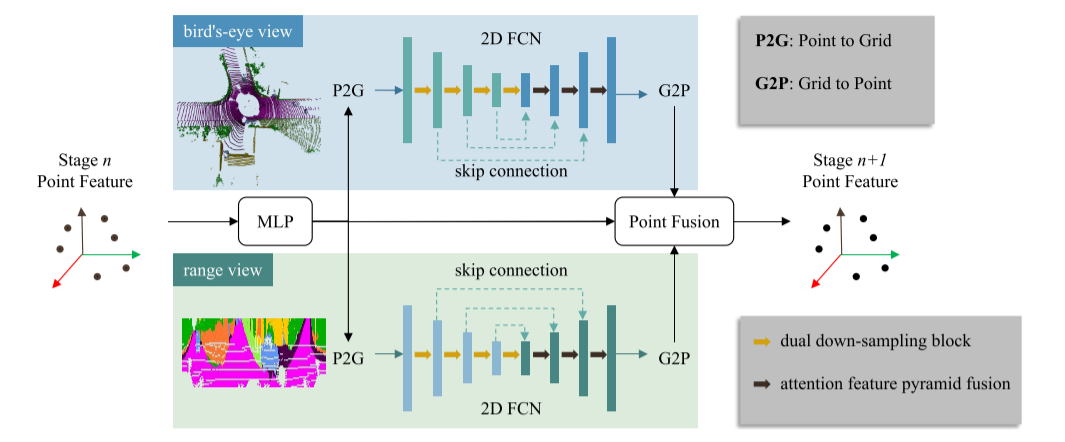
Figura 2. Bloque de fusión punto-rejilla (PG). El algoritmo toma las características de punto del último bloque de fusión PG como entrada y pasa por las ramas de punto, vista de pájaro y vista de distancia, respectivamente. Las características del punto de salida se obtienen fusionando las características de las tres ramas.
A. Punto a cuadrícula
Las operaciones de punto a cuadrícula (P2G) tienen como objetivo transformar las características de puntos 3D en mapas de características de cuadrícula 2D. Como se muestra en la Figura 3a, primero proyecta el k-ésimo punto 3D en una cuadrícula 2D para obtener las coordenadas 2D correspondientes
. El conjunto
contiene los índices de los puntos que caen en la misma cuadrícula 2D (h, w), es decir, Rh, w = {k|uk Luego, las características F3 D k de los puntos en se agregan por agrupación máxima para formar el 2D
correspondiente Característica de malla G2 D h, w. La fórmula es la siguiente:
![]()
Puede haber varios puntos que caen en la cuadrícula 2D. Para evitar conflictos paralelos, se utiliza la función atomicMax de CUDA cuando se procesa la misma cuadrícula 2D.

En el método propuesto se utilizan la vista de pájaro y la vista de rango . La vista de pájaro omite la dimensión z, la vista de rango omite la dimensión r. Por lo tanto, las dos vistas son complementarias para mitigar la pérdida de información de la proyección 2D. De hecho, ambas vistas usan operaciones P2G similares. Simplemente difieren en la forma en que se proyectan en 2D. Para una vista de pájaro, proyecta puntos 3D en un plano xy discretizado utilizando una cuadrícula 2D rectangular (xmin, ymin, xmax, ymax) con un ancho predefinido Wbev y una altura Hbev, como se resume en la siguiente ecuación de,

Para las vistas de rango, los puntos 3D se asignan desde el espacio cartesiano 3D al espacio esférico psph k(rk, θk, φk) aplicando la siguiente ecuación:

rk, θkφk representan distancia, cenit y azimut, respectivamente. Posteriormente, los rangos de Wrv con anchos de cuadrícula de vista predefinidos y alturas Hrv se discretizan mediante θkφk pero se desprecia rk,
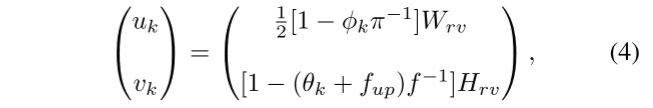
(De hecho, es para proyectar el punto 3D al plano y la vista frontal)
B. FCN 2D
FCN 2D con arquitecturas de codificador y decodificador se aplican a mapas de características de vista de pájaro y vista de rango para extraer características semánticas, respectivamente. Ocupan más del 90% del coste computacional de CPGNet. Por lo tanto, la red del codificador usa ResNet [31] con solo 9 capas como una red troncal liviana con hasta 128 canales. Para preservar la información durante la reducción de resolución, proponemos un bloque de reducción de resolución dual que utiliza convoluciones 2D y 2D MaxPool para reducción de resolución paralela, como se muestra en la Figura 4a. En los experimentos, se demuestra que el bloque de reducción de muestreo doble funciona mejor con una latencia insignificante.

Las estructuras de decodificación existentes [10], [26] generalmente emplean la fusión de pirámides de características para fusionar mapas de características de capa alta y baja. Los mapas de características de alto nivel contienen más información semántica, mientras que los mapas de características de bajo nivel revelan más detalles. Para la segmentación semántica, algunas partes (p. ej., carreteras, edificios) requieren características semánticas de alto nivel, mientras que otras (p. ej., peatones, límites de objetos) requieren características detalladas. En lugar de utilizar un mapa de funciones simple, proponemos la fusión de pirámides de funciones atencionales para seleccionar automáticamente funciones de diferentes niveles, como se muestra en la Figura 4b.
C. Cuadrícula a punto
A diferencia de las operaciones punto a cuadrícula (P2G), cuadrícula a punto (G2P) transfiere características de cuadrículas 2D a puntos 3D de acuerdo con las coordenadas 2D correspondientes p2D k = (uk, vk). Como se muestra en la Figura 3b, aplica interpolación bilineal dentro de cuatro cuadrículas adyacentes. La fórmula es la siguiente:
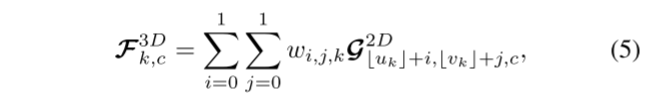
wi,j,k = (1 − |uk − (uk + i)|)(1 − |vk − (vk + j)|) significa interpolación bilineal. Tenga en cuenta que las cuadrículas vecinas fuera de los límites de la cuadrícula 2D se tratan como ceros. Se puede ver que cada punto y cada canal de características se calculan de forma independiente, lo que es más adecuado para la computación paralela CUDA.
D. Punto de Fusión
El módulo de fusión de puntos es responsable de fusionar características de puntos, vista de pájaro y vista de distancia. Para mayor eficiencia, solo adopta una cascada de características y dos capas MLP. A diferencia de MPF [15] y AMVNet [30], la fusión puntual no se realiza en el posprocesamiento, sino como un módulo de fusión intermedio, que es una parte importante de la CPGNet de extremo a extremo propuesta. El marco integral tiene dos ventajas: 1) es fácil de implementar con menos procesamiento posterior; 2) puede reducir la brecha entre las fases de capacitación y evaluación. La parte experimental demuestra su superioridad.
Aunque las características de los puntos en una vista particular, más allá de la extensión de la cuadrícula 2D, se tratan como ceros, la información se puede transmitir desde otras vistas. Por ejemplo, para que una vista de pájaro del alcance esté fuera del alcance, pero en el alcance del alcance, las características significativas se ven desde el alcance. En los experimentos, analizamos las distribuciones en dos vistas y descubrimos que casi todos los puntos se encuentran dentro del rango de al menos una vista.
E. Función de pérdida
Las predicciones de segmentación se obtienen aplicando una capa totalmente conectada (FC) a las características de salida del bloque de fusión PG. Los conjuntos de datos de segmentación semántica LiDAR (por ejemplo, SemanticKITTI, nuScenes) tienen categorías muy desequilibradas. Por ejemplo, las carreteras, las aceras y los edificios superan en número a las personas y las motocicletas cientos de veces. Con este fin, empleamos una pérdida de entropía cruzada ponderada (WCE) para enfatizar manualmente las clases raras. La pérdida WCE se puede formular como

donde yc define la etiqueta de verdad fundamental, yc es la probabilidad predicha, Fc es la frecuencia y αc es el peso de la c-ésima categoría. C es el número de categoría del conjunto de datos. En los experimentos, se fijó en 0,001. También adoptamos la pérdida de Lov'aszSoftmax [28], que puede optimizar la métrica de intersección media sobre unión (mIoU) como el segundo término de pérdida Lls. Como se muestra en [27], [29], mejora la métrica mIoU para tareas de segmentación. Ver [28] para más detalles.
Los métodos anteriores [21], [22] emplean el aumento del tiempo de prueba (TTA) para mejorar el rendimiento, lo que requiere múltiples inferencias del modelo. Por eficacia y eficiencia, proponemos una transformación de pérdida de consistencia Ltc para reducir la diferencia entre los puntos originales y mejorados. La fórmula es la siguiente:

representan las probabilidades pronosticadas del punto original y el punto mejorado respectivamente, y la función de pérdida total es la suma de tres partes
![]()
4 resultados experimentales
Evaluamos el rendimiento de la CPGNet propuesta en los puntos de referencia SemanticKITTI [16] y nuScenes [32].
SemanticKITTI Contiene 43.552 escaneos LiDAR de 360° de 22 secuencias recopiladas en una ciudad de Alemania. Equipado con un lidar giratorio Velodyne HDL-64 E con 64 haces verticales, cada escaneo lidar tiene alrededor de 130 000 puntos. El conjunto de entrenamiento (19.130 escaneos) consistió en secuencias de 00 a 10 (excepto 08), y la secuencia 08 (4.071 escaneos) se utilizó para la validación. Las secuencias restantes (20 351 escaneos) del 11 al 21 proporcionaron solo nubes de puntos LiDAR para tablas de clasificación en línea. El conjunto de datos está etiquetado con 28 clases, pero se usa un conjunto de etiquetas de alto nivel de 19 clases para la segmentación semántica LiDAR de escaneo único.
nuScenes , un conjunto de datos de segmentación semántica LiDAR recientemente lanzado, contiene 1000 escenas recopiladas de diferentes regiones de Boston y Singapur. Cada escena es recopilada por un LiDAR giratorio Velodyne HDL-32 E de 20 segundos de duración, con 32 haces verticales. Utiliza 28.130 muestras para entrenamiento, 6.019 para validación y 6.008 para pruebas. Anotó 32 clases, y después de fusionar algunas clases similares y eliminar clases raras, solo se usaron 16 clases para la evaluación oficial.
Métricas de evaluación. Empleamos la métrica más popular, la intersección media sobre la unión (mIoU), para evaluar la CPGNet propuesta y sus competidores. se puede expresar como
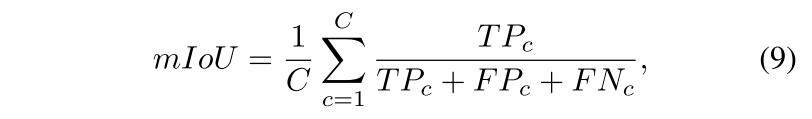
Donde TPc, FPc y FNc son verdaderos positivos, falsos positivos y falsos negativos de categoría c, respectivamente. C es el número total de clases.
A. Configuración experimental
configuración de la red. Como se muestra en la Figura 2, cada bloque de fusión PG de CPGNet tiene una arquitectura de red similar pero diferentes parámetros. En los experimentos, empleamos dos bloques de fusión PG en cascada. El número de canales de características de puntos de entrada para estos dos bloques es 9, 64, respectivamente. Los 9 canales de entrada del primer bloque se refieren a x, y, z, intensidad, r, ∆x, ∆y, ∆θ, ∆φ, donde ∆x, ∆y, ∆θ, ∆φ representan el centro de cuadrícula 2D correspondiente compensar. La primera capa MLP de cada bloque genera 64 canales de características, que se convierten en mapas de características de vista de pájaro y vista de rango mediante operaciones P2G posteriores. Ambas vistas utilizan una red FCN 2D similar con tres etapas de muestreo descendente y tres de muestreo ascendente, pero la vista de rango no aplica el muestreo descendente a lo largo de la dimensión de altura. Los canales de funciones de cada nivel en 2D FCN son 64, 32, 64, 128, 128, 96, 64, 64, respectivamente. Por lo tanto, la entrada de fusión puntual es de 64 × 3 canales característicos de tres ramas. Los canales de salida de estos dos bloques de fusión PG son 64, 96, respectivamente.
Para SemanticKITTI, la rama Bird's Eye Map acepta mapas de características 2D con forma (Wbev = 600, Hbev = 600) y rango (xmin = -50, ymin = -50, xmax = 50, ymax = 50). Y la rama de vista de rango establece la forma de entrada en (Wrv=2048, Hrv=64). nuEscenas con la misma configuración excepto Hrv=32. Con base en estos hiperparámetros, encontramos que el 99.99% de los puntos caen en al menos una vista de SemanticKITTI, como se muestra en la Tabla I.
Detalles de entrenamiento. Todos los experimentos se realizan con PyTorch FP32 en una GPU NVIDIA RTX 2080Ti. La CPGNet propuesta se entrena desde cero durante 30 épocas con un tamaño de lote de 16. El proceso de entrenamiento dura unas 15 horas en 8 GPU. El optimizador utiliza un descenso de gradiente estocástico (SGD) con una tasa de aprendizaje inicial de 0,02 y un decaimiento de 0,1 cada 6 épocas. Otros métodos utilizan el código oficial para el entrenamiento. Además, aplicamos aumento de datos durante el entrenamiento, incluidas rotaciones aleatorias alrededor del eje z, escalas globales aleatorias muestreadas de [0.95, 1.05], giros aleatorios a lo largo de los ejes x e y, y ruido gaussiano aleatorio N(0, 0.02) .
B. Resultados
Como se muestra en la Tabla II, comparamos la CPGNet propuesta con el conjunto de pruebas SemanticKITTI de última generación. De arriba a abajo, estos métodos se clasifican en métodos basados en puntos, métodos basados en proyección 2D y métodos basados en vóxeles dispersos. Descubrimos que CPGNet supera a todos los métodos basados en puntos y en proyección 2D, y es comparable al RPVNet [24] mejor clasificado en la mayoría de las categorías, excepto en motociclistas. Esta categoría tiene menos muestras de entrenamiento y se confunde con ciclistas y motociclistas, que pueden ser abordados por LiDAR y fusión de imágenes. En las categorías de camiones y señales de tráfico, CPGNet supera a RPVNet por un amplio margen.

Además, CPGNet se ejecuta mucho más rápido que los principales métodos, incluidos SPVCNN [21], Cylinder3D [22], DRINet [33] y RPVNet [24]. Tenga en cuenta que también probamos la velocidad de CPGNet en una GPU NVIDIA Tesla V100 (marcada con *) para una comparación justa con RPVNet.
Informamos los resultados en el conjunto de validación de nuScenes. Como se muestra en la Tabla 3, CPGNet sigue superando a los métodos basados en proyección 2D y es comparable a RPVNet, que ocupa el primer lugar.
C. Estudio de ablación
Para aclarar la eficacia de los componentes propuestos, realizamos estudios de ablación en el conjunto de validación SemanticKITTI utilizando la misma configuración experimental.
En primer lugar, realizamos bloques de fusión de cuadrícula de punto de medición (PG) de análisis de ablación. Como se muestra en la Tabla IV, la línea de base (primera fila) está replicando MPF [15], adoptando nuestra arquitectura 2D FCN y transformando la pérdida de consistencia. De la última línea, podemos encontrar que: 1) la fusión de +0.9 puntos es mejor que mIoU para un posprocesamiento de MPF más fuerte; 2) logra una ganancia de 2.1 cuando mIoU introduce características de puntos; 3) el bloque de fusión CPGNet 2 PG conduce a la mayor mejora en mIoU, mientras que la versión singleblock.
Posteriormente, analizamos el impacto de otros componentes, incluida la arquitectura 2D FCN, la pérdida de consistencia de la transformación y la implementación de TensorRT FP 16, como se muestra en la Tabla V. Para la arquitectura 2D FCN, Double Downsampling Block (DDB) y Attention Pyramid Feature Fusion (APFN) mejoran mIoU en 0,3 y 0,7 respectivamente, lo que demuestra su eficacia. En los experimentos, TTA aumenta la nube de puntos tres veces, es decir, gira a lo largo del eje x, gira a lo largo del eje y y gira a lo largo de ambos. Como puede verse, TTA mejora el rendimiento (+1,2 mIoU), pero requiere cuatro veces la inferencia del modelo. Cuando agregamos una pérdida de consistencia de transformación durante el entrenamiento y eliminamos TTA durante la inferencia, funciona ligeramente mejor (+0,2 mIoU) que la inferencia del modelo TTA. Además, CPGNet se puede implementar fácilmente en el modo de inferencia TensorRT FP 16, funcionando a 26,8 ms por escaneo con una caída de rendimiento insignificante (-0,1 mIoU).
5. Conclusión
En este documento, proponemos una segmentación semántica lidar de CPGNet precisa, rápida y fácil de implementar, donde las características de punto, vista de pájaro y vista de rango se fusionan en un marco en cascada. En comparación con el algoritmo TTA, se propone un algoritmo de pérdida de consistencia de transformación, que ahorra tiempo de inferencia sin reducir el rendimiento del algoritmo. Además, encontramos que las características de puntos 3D dentro del caparazón mantienen información completa de la nube de puntos, mientras que las características de malla 2D son adecuadas para la extracción eficiente de características semánticas. mIoU Velocidad (ms) Automóviles Bicicletas Motocicletas Camiones Otros Vehículos Personas Ciclistas Motociclistas Carreteras Estacionamientos Aceras Otro Terreno Edificios Cercas Vegetación Troncos Terreno Poste Señales de tránsito.
Resume tú mismo:
Método basado en puntos + método basado en proyección planar (vista frontal + vista de pájaro)
principalmente más rápido
En duda
Las partes APFN y TTA no se entienden bien, bienvenido a discutir ~