
Título del artículo : Aumento de la precisión y la robustez de los modelos de estudiantes a través de la destilación antagónica adaptativa
Enlace del artículo : https://openaccess.thecvf.com/content/CVPR2023/papers/Huang_Boosting_Accuracy_and_Robustness_of_Student_Models_via_Adaptive_Adversarial_CVPR_2023_paper.pdf
Afiliación del autor : Universidad de Ciencia y Tecnología de Hong Kong (Guangzhou), Universidad de Ciencia y Tecnología de Hong Kong, Instituto de Tecnología de Dongguan, Universidad Macquarie
Enlace de código : https://github.com/boyellow/AdaAD
guía
Hoy en día, el aprendizaje automático, especialmente el aprendizaje profundo, se usa ampliamente en varios campos. En aplicaciones en tiempo real y dispositivos perimetrales, a menudo es necesario implementar modelos livianos [1]. Sin embargo, en las implementaciones perimetrales, los modelos livianos a menudo carecen de suficientes mecanismos de protección debido a los presupuestos limitados. En comparación con los modelos a gran escala, los modelos livianos son más vulnerables al riesgo de ataques adversarios (Adversarial Attacks) con fines maliciosos [2,3].
Por lo tanto, en aplicaciones prácticas, es muy importante mejorar la robustez de los modelos ligeros frente a ataques maliciosos. Muchos estudios han demostrado que el entrenamiento adversario ( Adversarial Training) es efectivo para mejorar la robustez de los modelos. Sin embargo, algunos estudios han demostrado que para modelos grandes con sobrecuantificación de parámetros, el entrenamiento adversarial es mejor [4], mientras que el efecto de mejorar la robustez en modelos livianos es muy limitado e incluso reduce seriamente la precisión en muestras naturales.
Las investigaciones recientes se centran en mejorar el rendimiento robusto de los modelos livianos a través de la destilación de robustez adversaria [5]. A diferencia de la destilación de conocimiento tradicional [1], la destilación robusta contradictoria requiere no solo un rendimiento preciso sino también un rendimiento robusto heredado por el modelo de estudiante del modelo de maestro robusto.
motivación
Los métodos de destilación robusta contradictorios existentes generalmente adoptan dos formas de guiar el proceso de destilación robusta, a saber:
- etiqueta dura (
Hard Label) - etiqueta blanda (
Soft Label)
El objetivo de optimización de estos métodos es hacer que las predicciones del modelo del estudiante sean consistentes con las etiquetas fijas en todos los puntos de muestra de la vecindad. Sin embargo, hacerlo necesariamente introduce el problema de la sobrecorrección de la suavidad del modelo. Se ha demostrado en la literatura que este problema de sobrecorrección es una razón importante para el compromiso entre precisión y robustez [6,7]. Por lo tanto, los métodos de destilación robustos contradictorios existentes tienen limitaciones en términos de precisión y robustez en modelos livianos.
En este artículo, el autor propone un AdaADmétodo de destilación antagónica adaptativa (Adaptive Adversarial Distillation), que encuentra de manera adaptativa el punto de coincidencia óptimo (Puntos de coincidencia) para el proceso de entrenamiento de destilación. AdaADPuede aliviar eficazmente el problema de la corrección excesiva y permitir que se utilice un radio de búsqueda más grande (Radio de búsqueda) para buscar. Los experimentos muestran que, en comparación con los métodos existentes, AdaADla precisión y la solidez del modelo del estudiante se pueden mejorar significativamente.
método
AdaAD
El autor cree que el objetivo deseado de la destilación robusta antagónica es que el modelo del alumno pueda maximizar la alineación de la predicción con el modelo robusto del profesor en todos los puntos de muestra y en la vecindad de los puntos de muestra. Este objetivo de alineación maximizada se puede definir formalmente como:
LAD = ∬ re ( S ( x + δ ) , T ( x + δ ) ) re δ dx , \mathcal{L}_{\mathrm{AD}} = \iint \mathcal{D}(S(x+\delta ), T(x+\delta)) d \delta dx,Lanuncio=∬re ( s ( x+d ) ,T ( x+d )) d d d x ,
donde D \mathcal{D}D representa una medida de distancia,S ( ⋅ ) S(\cdot)S ( ⋅ )和T ( ⋅ ) T(\cdot)T ( ⋅ ) denota el modelo de estudiante y el modelo de maestro respectivamente. Sin embargo, debido a la naturaleza altamente dimensional del aprendizaje profundo, es muy difícil optimizar directamente los objetivos anteriores. Los autores proponen AdaAD, un marco basado en min-max para aproximar el objetivo de optimización anterior:
min max ∣ ∣ δ ∣ ∣ pags ≤ ϵ re ( S ( x + δ ) , T ( x + δ ) ) , \min \max_{||\delta ||_p \le \epsilon } \mathcal{D }(S(x+\delta), T(x+\delta)),min∣∣ δ ∣ ∣pag≤ ϵmáximore ( s ( x+d ) ,T ( x+d )) ,
Este marco consta de dos pasos. El primer paso está en el punto de muestra original dado x 0 x_0X0y su ϵ \epsilonϵ - Neighborhood encuentra el puntox ∗ x^*X∗ , a saber:
x ∗ = x + arg max ∣ ∣ δ ∣ ∣ p ≤ ϵ KL ( S ( x + δ ) ∣ ∣ T ( x + δ ) ), x^{*}=x+\underset{||\delta| |_{p} \leq \epsilon}{\arg\max } \ \mathrm{KL}(S(x+\delta) ||T(x+\delta)) ,X∗=X+∣∣ δ ∣ ∣pag≤ ϵar gmáximo KL ( S ( x+d ) ∣∣ T ( x+d )) ,
En el artículo, los autores utilizan la divergencia KL como una medida de distancia para la diferencia entre las predicciones de dos modelos. El segundo paso es alinear los dos modelos minimizando la diferencia máxima predicha entre el modelo del estudiante y el modelo del maestro:
arg min θ s KL ( S ( X ∗ ) ∣ ∣ T ( X ∗ ) ) . \underset{\theta_{s}}{\arg\min } \ \mathrm{KL}(S(x^*) ||T(x^*)).isar gminuto KL ( S ( x∗ )∣∣T(x∗ )).
Específicamente, los detalles de optimización de la capa interna de AdaAD se muestran en la siguiente figura:
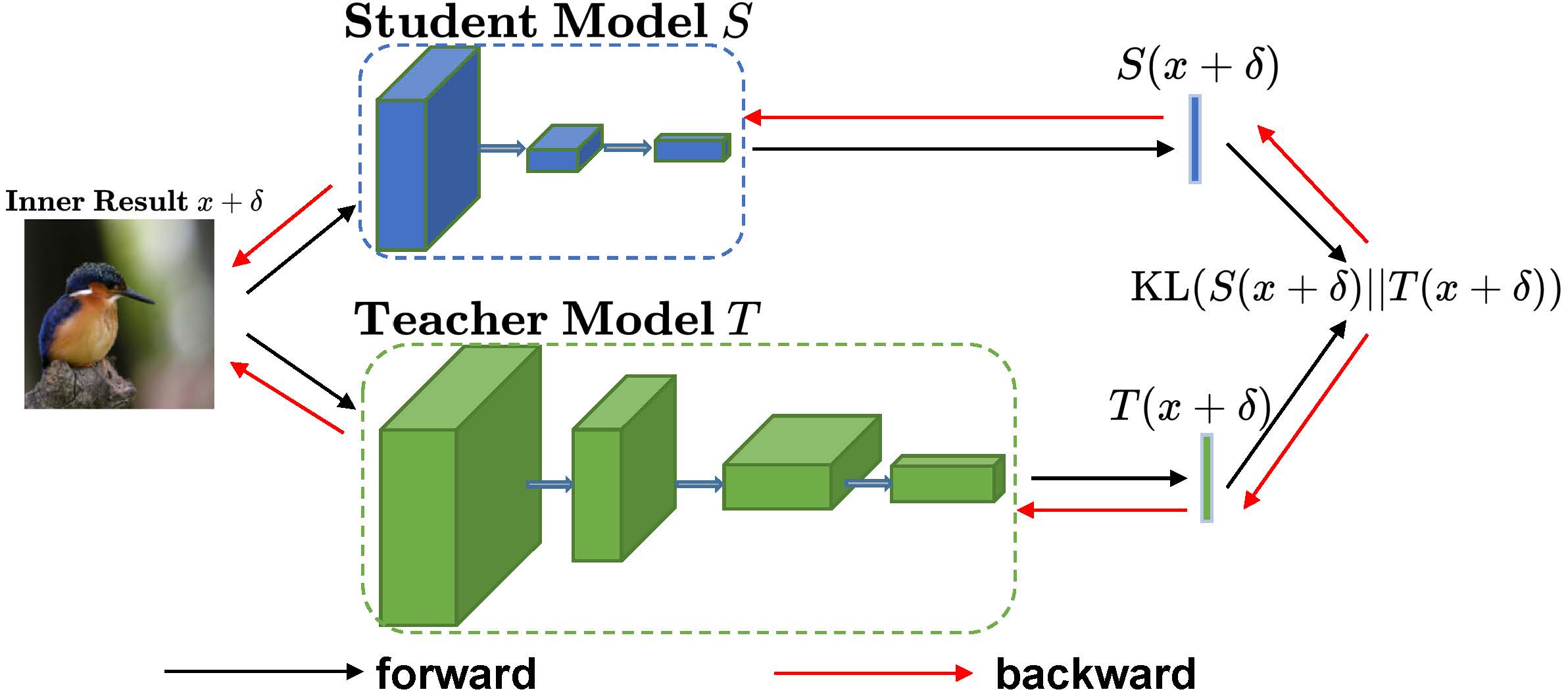
Beneficios de AdaAD
1. Aliviar el problema de corrección excesiva de la suavidad del modelo
Los métodos existentes de entrenamiento contradictorio y de destilación robusta contradictoria generalmente consideran el uso de una etiqueta dura fija (etiqueta dura) o una etiqueta blanda fija (etiqueta blanda) para guiar el proceso de destilación robusta. El objetivo de optimización de estos métodos es alinear los valores pronosticados del modelo de estudiante en todos los puntos de la región de vecindad de un punto de muestra con una etiqueta fija. Dado un punto muestral original x 0 x_0X0, y su ϵ \epsilonϵ -vecindario, este objetivo de alineación se puede expresar como:
∀ x ∈ segundo ( x 0 , ϵ ) , S ( x ) = p ( y ∣ x 0 ) o S ( x ) = T ( x 0 ) , \forall x \in \mathcal{B}(x_0, \epsilon ), S(x)=p(y|x_0) \ \text{o} \ S(x)=T(x_0),∀ x∈segundo _ _0,) , _S ( X )=p ( y ∣ x0) o S ( x ) =T ( x0) ,
Entre ellos, p ( y ∣ x 0 ) p(y|x_0)p ( y ∣ x0) y T(x_0) denotan las etiquetas duras en el conjunto de datos y las etiquetas blandas de las muestras originales del modelo del maestro, respectivamente. Este problema de sobrecorrección conduce a un serio compromiso (Trade-off) entre la precisión y la robustez del modelo entrenado. El AdaAD propuesto promueve la alineación de los valores pronosticados del modelo de estudiante en todos los puntos de un vecindario de puntos de muestra con la distribución pronosticada del modelo de maestro en este vecindario, lo que alivia significativamente el problema de sobrecorrección. Específicamente, el objetivo de alineación de AdaAD se expresa como:
∀ X ∈ segundo ( X 0 , ϵ ) , S ( X ) = T ( X ) . \forall x \in \mathcal{B}(x_0, \epsilon), S(x)=T(x).∀ x∈segundo _ _0,) , _S ( X )=T ( x ) .
2. Permite un mayor radio de búsqueda
A diferencia del entrenamiento contradictorio y los métodos de destilación robustos contradictorios existentes, los puntos coincidentes que AdaAD encuentra en la optimización máxima de la capa interna representan los puntos donde la diferencia de predicción entre el modelo del estudiante y el modelo del maestro es mayor, y estos puntos no son necesariamente altamente contradictorios. Por lo tanto, a diferencia del entrenamiento contradictorio existente y los métodos de destilación robusta contradictorios, AdaAD puede permitir un radio de búsqueda más grande en la optimización máxima de la capa interna. Un radio de búsqueda más grande también significa restricciones de alineación más fuertes entre el modelo de estudiante y el modelo de maestro, y los experimentos muestran que aumentar el radio de búsqueda puede mejorar significativamente el rendimiento sólido del modelo de estudiante.
experimento
Evaluación de ataques de caja blanca
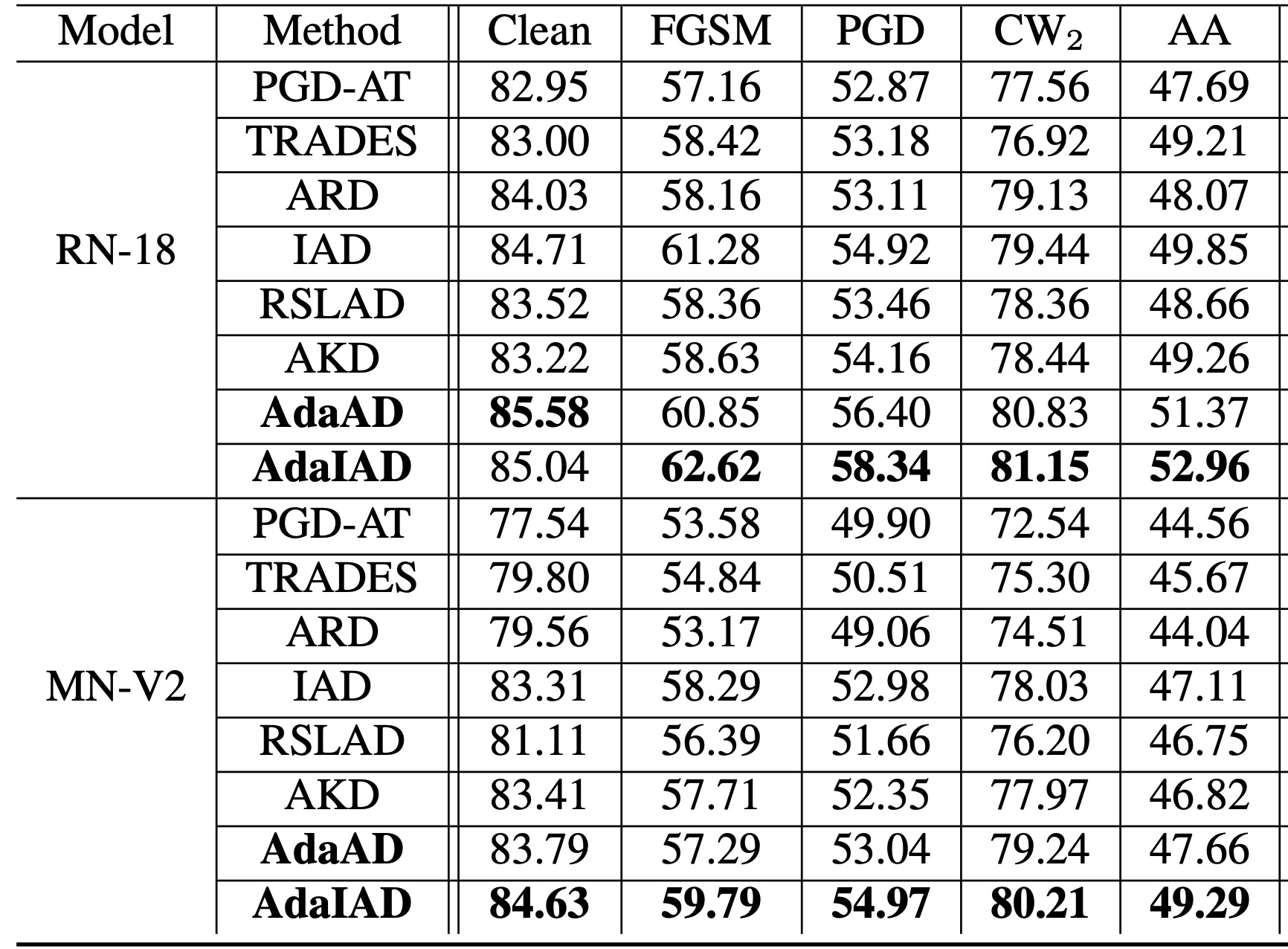
La tabla anterior muestra la precisión de reconocimiento de AdaAD y AdaIAD propuestos y otros métodos de última generación para diferentes ataques adversarios en el conjunto de datos CIFAR-10. En primer lugar, se puede ver en la tabla anterior que el método de destilación robusta contradictoria es significativamente mejor que el método de entrenamiento contradictorio en términos de precisión y robustez, lo que demuestra que es más efectivo que el entrenamiento contradictorio para mejorar la robustez de los modelos livianos. competitivo. En segundo lugar, AdaAD y AdaIAD claramente superan los métodos más avanzados en términos de precisión y robustez, lo que demuestra que AdaAD y AdaIAD pueden mejorar significativamente el equilibrio entre precisión y robustez. Vale la pena señalar que dado que los ataques AA (AutoAttack) incluyen dos métodos de ataque basados en consultas, la eficacia de AdaAD y AdaIAD para mejorar la precisión del reconocimiento AA muestra que también son confiables para los ataques basados en consultas.
aumentar el radio de búsqueda
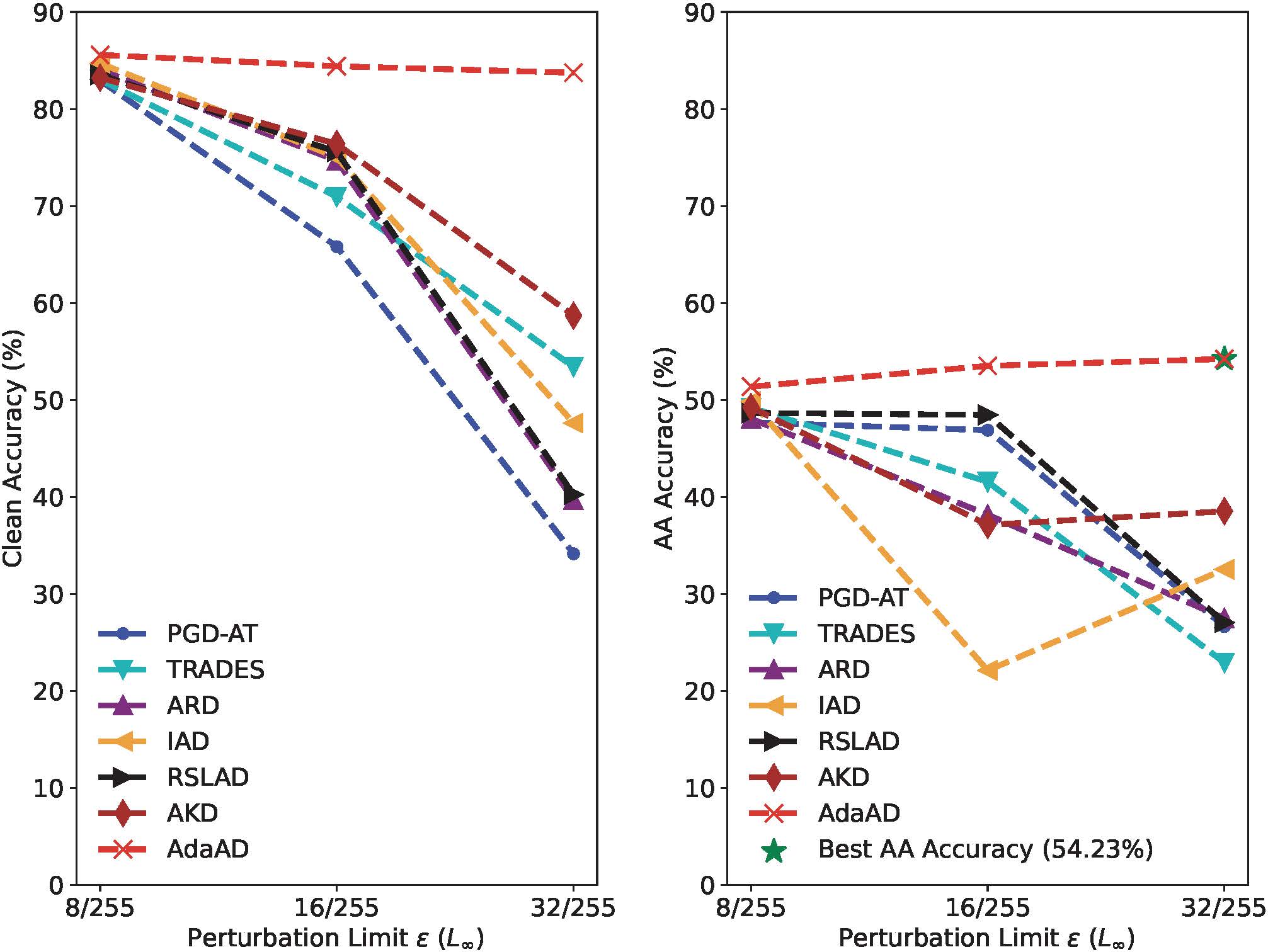
La figura anterior evalúa el conjunto de datos CIFAR-10 utilizando un radio de búsqueda creciente ϵ \epsilonPrecisión del modelo de estudiante ResNet-18 entrenado y precisión de reconocimiento AutoAttack (precisión AA). En general, el AdaAD propuesto es en todoϵ \epsilonEn el caso del valor ϵ , la precisión y la robustez mejoran significativamente, lo que supera con creces a otros métodos. Específicamente, al aumentar ε de 8/255 a 32/255, la precisión de AdaAD permanece casi sin cambios, mientras que la precisión de AA muestra una tendencia creciente continua, mientras que la precisión de todos los métodos comparados cae bruscamente por debajo del 60%. la precisión cae por debajo del 40%. Sin utilizar un aumento de datos adicional, nuestro método AdaAD propuesto puede lograrϵ \epsilonCuando ϵ se establece en 32/255, la precisión de AA es del 54,23 %. Estos resultados verifican que la naturaleza adaptativa le permite a AdaAD buscar el límite superior de la diferencia de predicción entre el modelo de estudiante y el modelo de maestro en un área local grande, de modo que el modelo de estudiante pueda heredar mejor la robustez del modelo de maestro y apenas la pérdida de exactitud.
Resumir
min-maxEste artículo propone una nueva función objetivo de destilación contradictoria al maximizar la diferencia de predicción entre el modelo de maestro y el modelo de estudiante en el marco. Además, los autores diseñan un esquema de destilación antagónica adaptable, es decir AdaAD, la destilación robusta antagónica se realiza mediante la búsqueda adaptativa del mejor "punto de coincidencia" en la optimización de la capa interna. Finalmente, una gran cantidad de experimentos demuestran que el método propuesto es significativamente mejor que los métodos actuales de entrenamiento contradictorio y destilación contradictoria de última generación en términos de precisión y robustez.
referencias
[1] Geoffrey E. Hinton, Oriol Vinyals y Jeffrey Dean. Destilando el conocimiento en una red neuronal. CoRR, abs/1503.02531, 2015
[2] Battista Biggio, Igino Corona, Davide Maiorca, Blaine Nelson, Nedim Srndic, Pavel Laskov, Giorgio Giacinto y Fabio Roli. Ataques de evasión contra el aprendizaje automático en tiempo de prueba. En ECML PKDD, páginas 387–402, 2013
[3] Ian J. Goodfellow, Jonathon Shlens y Christian Szegedy. Explicar y aprovechar ejemplos contradictorios. En ICLR, 2015
[4] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras y Adrian Vladu. Hacia modelos de aprendizaje profundo resistentes a los ataques adversarios. En ICLR, 2018.
[5] Micah Goldblum, Liam Fowl, Soheil Feizi y Tom Goldstein. Destilación adversarialmente robusta. En AAAI, páginas 3996– 4003, 2020.
[6] Stutz, Matthias Hein y Bernt Schiele. Entrenamiento contradictorio calibrado con confianza: generalización a ataques invisibles. En ICML, páginas 9155–9166, 2020.
[7] Tianyu Pang, Min Lin, Xiao Yang, Jun Zhu y Shuicheng Yan. Robustez y precisión podrían reconciliarse mediante una definición (adecuada). En ICML, páginas 17258–17277, 2022.