[Uso de la evaluación del aprendizaje profundo para predecir el riesgo de recurrencia del cáncer de pulmón: predicción del riesgo de recurrencia del cáncer de pulmón a través de la evaluación integrada del aprendizaje profundo]
Fondo
1) Problemas existentes
Se han hecho pocos avances significativos recientes en la predicción del riesgo de progresión del cáncer en el estadio IA de cánceres de pulmón de células no pequeñas (NSCLC, un tipo de cáncer de pulmón) después de la resección quirúrgica completa del tumor. Aunque algunos biomarcadores han mostrado algún valor predictivo, no está claro si estos marcadores agregan valor a la estadificación del sistema TNM tradicional, que es la mejor herramienta para predecir el riesgo de recurrencia en pacientes con cáncer. Recientemente, se ha avanzado poco en los factores de riesgo pronósticos para el cáncer de pulmón de células no pequeñas (CPCNP) en estadio IA completamente resecado. Aunque se ha encontrado que algunos biomarcadores están asociados con la recurrencia del cáncer, su valor agregado para la estadificación TNM y el grado del tumor no está claro.
Aunque la terapia dirigida neoadyuvante o adyuvante o la inmunoterapia, sola o en combinación con quimioterapia, ha tenido éxito en mejorar los resultados en pacientes con NSCLC resecable en estadio IB o superior, esto ha generado dudas sobre el beneficio potencial de estos tratamientos para mejorar aún más la curación. Existe un interés creciente en los subgrupos de pacientes con NSCLC en estadio IA. Actualmente, no existen marcadores de pronóstico validados para guiar la terapia adyuvante en pacientes con NSCLC en estadio IA resecado.
La identificación temprana del NSCLC en etapa IA con alto riesgo de progresión tiene un papel importante en la orientación de los médicos para que traten agresivamente a los pacientes que pueden beneficiarse de la terapia del cáncer en etapa temprana para contrarrestar el desarrollo de la enfermedad metastásica. Aunque se encontró que muchos biomarcadores sanguíneos o radiológicos prometedores estaban asociados con la progresión del NSCLC, ninguno tenía un valor agregado significativo para la estratificación del riesgo de recurrencia y muerte del cáncer de pulmón sobre los criterios aceptados de estadificación TNM y grado tumoral. Y la progresión del cáncer es un proceso complejo que involucra muchos factores antes y después de la cirugía.
Con respecto al nivel técnico de la predicción de recurrencia del cáncer de pulmón por IA, todavía existen los siguientes cuatro problemas:
1. Problemas de recopilación y etiquetado de datos: el rendimiento predictivo y la precisión de los modelos de IA están limitados por la calidad y la cantidad de datos. La mayoría de los estudios actuales se basan en muestras pequeñas o conjuntos de datos de un solo centro, lo que puede conducir a una capacidad de generalización insuficiente del modelo, lo que dificulta la adaptación a diferentes regiones y diferentes tipos de pacientes. Además, existen diferencias en la definición y los estándares de recurrencia, y también se debe considerar la consistencia y precisión de los datos etiquetados.
2. El problema de la selección de características y la optimización del modelo: para diferentes tipos de pacientes con cáncer de pulmón, los factores de riesgo de recurrencia pueden ser diferentes. Cómo seleccionar las características más relevantes y cómo diseñar y optimizar el modelo para mejorar el rendimiento y la estabilidad de la predicción aún necesita más exploración e investigación.
3. Viabilidad y confiabilidad de la aplicación práctica: en la aplicación clínica real, el modelo de predicción de recurrencia del cáncer de pulmón de IA debe combinarse con la experiencia clínica y el conocimiento de los médicos para mejorar el diagnóstico y el efecto del tratamiento. Además, cómo garantizar la privacidad y la seguridad de los datos y evitar la fuga y el abuso de datos también son cuestiones que deben tenerse en cuenta.
4. Problemas de interpretación e interpretabilidad: la naturaleza de caja negra de los modelos de IA puede reducir la confianza y la aceptación de los resultados de predicción por parte de pacientes y médicos. Por lo tanto, cómo mejorar la interpretabilidad y la interpretabilidad de los modelos de IA, para que sus resultados de predicción sean más fáciles de entender y aceptar, también es una dirección que debe estudiarse y mejorarse.
2) Para los problemas existentes, ¿cuál es el estudio principal del método de aprendizaje profundo?
En este estudio, los autores desarrollaron una puntuación de Evaluación Integrativa de Aprendizaje Profundo (IDLE, por sus siglas en inglés) que combina la apariencia de la imagen de TC de pulmón preoperatoria con la evaluación patológica posoperatoria y encontraron que la puntuación predecía mejor la progresión del cáncer que el estadio TNM y el riesgo de grado tumoral. La mejora en el valor predictivo de la puntuación IDLE se debió principalmente al uso complementario de mediciones tumorales en imágenes de TC de todo el pulmón, así como características histológicas microscópicas. El estudio de los autores respalda el uso de distintos marcadores tumorales que no se superponen en la evaluación del riesgo de cáncer. El estudio tiene el potencial no solo de ayudar a los oncólogos tratantes a mejorar el manejo clínico del NSCLC en etapa temprana, sino también de ayudar a los investigadores a definir mejor los criterios de selección de pacientes y determinar qué mediciones recopilar en futuros diseños de ensayos clínicos.
3) En comparación con los algoritmos tradicionales, ¿cuáles son las ventajas?
1. Mayor precisión y rendimiento predictivo: los modelos de IA pueden procesar datos médicos más grandes y complejos, y pueden aprender y analizar entre diferentes características de datos, para predecir con mayor precisión el riesgo de recurrencia del cáncer de pulmón en los pacientes.
2. Velocidad de predicción más rápida: el modelo de IA puede procesar y analizar automáticamente una gran cantidad de datos médicos, por lo que puede dar resultados de predicción rápidamente en un corto período de tiempo, ayudando a los médicos a tomar decisiones de diagnóstico y tratamiento más oportunas.
3. Evaluación de riesgos más completa: el modelo de IA puede considerar de manera integral varios factores, como la edad, el sexo, el tipo de tumor, el método de tratamiento, etc., para realizar una evaluación más completa del riesgo de recurrencia del cáncer de pulmón del paciente y ayuda los médicos formulan mejor un plan de tratamiento personalizado.
4. Menos interferencia de factores subjetivos: el modelo de IA hace predicciones basadas en datos, lo que reduce la interferencia de los factores subjetivos de los médicos, lo que brinda resultados de predicción más objetivos y creíbles y ayuda a los médicos a comprender mejor la condición y el pronóstico del paciente.
La tecnología de predicción de la recurrencia del cáncer de pulmón con IA tiene ventajas en cuanto a precisión, velocidad, exhaustividad y objetividad, y se espera que se convierta en una herramienta importante y un medio auxiliar en el tratamiento del cáncer de pulmón y la evaluación del pronóstico.
4) ¿Cuáles son los escenarios de aplicación de la evaluación de aprendizaje profundo para predecir el riesgo de recurrencia del cáncer de pulmón?
1. Apoyo a la decisión clínica: la tecnología de predicción de recurrencia del cáncer de pulmón de IA puede proporcionar a los médicos una evaluación precisa del riesgo de recurrencia del cáncer de pulmón y ayudar a los médicos a formular planes de tratamiento y planes de seguimiento más personalizados, mejorando así el efecto del tratamiento y la tasa de supervivencia de los pacientes.
2. Investigación y ensayos clínicos: la tecnología de predicción de la recurrencia del cáncer de pulmón con IA puede ayudar a los investigadores a comprender mejor los factores de riesgo y los mecanismos de la recurrencia del cáncer de pulmón, lo que guiará la investigación y los ensayos sobre el tratamiento del cáncer de pulmón y la evaluación del pronóstico.
3. Gestión y prevención de la salud: la tecnología de predicción de recurrencia del cáncer de pulmón con IA puede detectar y monitorear grupos de alto riesgo y detectar signos de recurrencia del cáncer de pulmón de manera temprana, mejorando así el efecto de la prevención y el tratamiento, y reduciendo el sufrimiento y los gastos médicos de los pacientes.
4. Seguro médico y evaluación de riesgos: la tecnología de predicción de recurrencia del cáncer de pulmón de IA puede proporcionar a las compañías de seguros médicos y a las instituciones de gestión de la salud modelos de predicción y evaluación de riesgos para ayudarlos a evaluar mejor los riesgos de los pacientes y los costos del seguro, y mejorar la precisión y la eficiencia del seguro.
5) Análisis de factibilidad
En la actualidad, la tecnología de IA se ha utilizado ampliamente en el campo de la medicina, y el algoritmo y el modelo de la tecnología de predicción de recurrencia del cáncer de pulmón de IA también han sido relativamente maduros. Por lo tanto, desde un punto de vista técnico, la recurrencia del cáncer de pulmón de IA proyecto de predicción es factible. El cáncer de pulmón es un problema de salud importante en todo el mundo, y la evaluación y predicción del riesgo de recurrencia del cáncer de pulmón siempre ha sido un tema candente de preocupación para los trabajadores médicos y los pacientes. Por lo tanto, la demanda del mercado de la tecnología de predicción de recurrencia del cáncer de pulmón de IA es muy grande y tiene amplias perspectivas de aplicación y espacio de mercado. El modelo de negocio de la tecnología de predicción de la recurrencia del cáncer de pulmón con IA puede tomar varias formas, como ventas directas por parte de hospitales y clínicas, servicios personalizados por parte de compañías de seguros médicos e instituciones de gestión de la salud, cooperación en investigación científica entre instituciones de investigación y compañías farmacéuticas, etc. Por lo tanto, desde la perspectiva del modelo de negocio, el proyecto de predicción de recurrencia del cáncer de pulmón de IA también es factible.
conjunto de datos
- Conjunto de datos de cáncer de pulmón
| tipo de datos | Imágenes (funciones múltiples) y archivos comprimidos |
|---|---|
| tamaño | Alrededor de 1100 carpetas (cada carpeta tiene diferentes imágenes y archivos comprimidos de conjuntos de datos) |
| Número de instancias | 32 |
| número de atributos | 56 |
| Atributos | Todos los atributos predichos son nominales, tomando valores enteros de 0-3 |
| Etiqueta | El atributo 1 es la etiqueta de clase |
| Resumen | Hong y Young usaron estos datos para ilustrar la capacidad de los planos discriminativos óptimos, incluso en entornos mal colocados. La aplicación del método KNN en los planos generados dio una precisión del 77 %. Sin embargo, estos resultados están muy sesgados (ver la segunda referencia de Aeberhard arriba, o enviar un correo electrónico a stefan'@'coral.cs.jcu.edu.au). Los resultados obtenidos por Aeberhard et al., son: RDA: 62,5%, KNN 53,1%, Opt. Disc. Plane: 59,4%, los datos describen 3 tipos de cáncer de pulmón patológico. Los autores no brindan información sobre las variables individuales, ni sobre dónde se usaron originalmente los datos. |
| fuente de datos | https://archive.ics.uci.edu/ml/datasets/lung+cancer ; https://archive.ics.uci.edu/ml/machine-learning-databases/lung-cancer/ |
| Información de referencia de datos | Hong, ZQ y Yang, JY “Plano discriminante óptimo para un pequeño número de muestras y método de diseño del clasificador en el plano”, Reconocimiento de patrones, vol. 24, No. 4, págs. 317-324, 1991. |
- Datos del Ensayo Nacional de Detección de Pulmones (NLST)
| tipo de datos | TC o imágenes patológicas |
|---|---|
| tamaño | Más de 75 000 imágenes de exámenes de detección por TC, más de 200 000 series de imágenes de patología |
| Conjunto de entrenamiento | Aproximadamente 2100, un registro para cada cáncer de pulmón |
| conjunto de validación | 54.000 participantes |
| equipo de prueba | Más de 1200 imágenes patológicas de unas 500 personas |
| Etiqueta | 48 |
| Resumen | Los conjuntos de datos son completos; incluyen datos sobre las características de los participantes, los resultados de las pruebas de detección, los procedimientos de diagnóstico, el cáncer de pulmón y la mortalidad. Proporciona imágenes de más de 75 000 exámenes de detección por TC. Están disponibles más de 1200 imágenes de patología (aproximadamente 500 de más de 2000 pacientes) de un subconjunto de pacientes con cáncer de pulmón NLST. |
| fuente de datos | https://cdas.cancer.gov/nlst/ |
| Información de referencia de datos | Pan Z, Zhang R, Shen S, et al. OWL: un modelo de predicción de aprendizaje automático optimizado y validado de forma independiente para la detección del cáncer de pulmón basado en las poblaciones de UK Biobank, PLCO y NLST [J]. EBioMedicine, 2023, 88. |
- Datos del Consorcio de base de datos de imágenes pulmonares (LIDC)
| tipo de datos | conjunto de imágenes |
|---|---|
| tamaño | 244527 imágenes (124GB) |
| Forma | CT (tomografía computarizada) DX (radiografía digital) CR (radiografía computarizada) |
| El número de participantes | 1010 |
| número de estudios | 1308 |
| número de serie | 1308 |
| Resumen | 肺部图像数据库联盟图像集 (LIDC-IDRI) 包括诊断和肺癌筛查胸部计算机断层扫描 (CT) 扫描,带有标记的注释病变。它是一种可通过网络访问的国际资源,用于开发、培训和评估用于肺癌检测和诊断的计算机辅助诊断 (CAD) 方法。这种公私合作伙伴关系由美国国家癌症研究所 (NCI) 发起,由美国国立卫生研究院 (FNIH) 基金会进一步推动,并在美国食品和药物管理局 (FDA) 的积极参与下,证明了这一公私合作伙伴关系的成功联盟建立在基于共识的过程之上。七个学术中心和八个医学影像公司合作创建了这个包含 1018 个案例的数据集。每个受试者都包括来自临床胸部 CT 扫描的图像和一个关联的 XML 文件,该文件记录了由四位经验丰富的胸部放射科医生执行的两阶段图像注释过程的结果。 |
| 数据源 | https://wiki.cancerimagingarchive.net/pages/viewpage.action?pageId=1966254 |
| 数据引用信息 | Armato III S G, McLennan G, Bidaut L, et al. The lung image database consortium (LIDC) and image database resource initiative (IDRI): a completed reference database of lung nodules on CT scans[J]. Medical physics, 2011, 38(2): 915-931. |
- IQ-OTH/NCCD - Lung Cancer Dataset
| 数据类型 | 图像集 |
|---|---|
| 大小 | 1190张图像,代表110例病例的CT扫描切片 |
| 类别 | 分为三类:正常、良性和恶性 |
| 每类样本数 | 40例被诊断为恶性;诊断为良性的15例,分类为正常的55例 |
| 摘要 | 专科医院收集了为期三个月的伊拉克癌症教学医院/癌症国家中心(IQ-OTH/NCCD)癌症数据集。它包括不同阶段被诊断患有癌症的患者以及健康受试者的CT扫描。这两个中心的肿瘤学家和放射科医生对IQ-OTH/NCD玻片进行了标记。每次扫描包含多个切片。这些切片的数量从80到200个不等,每个切片代表不同侧面和角度的人体胸部图像。110例病例的性别、年龄、教育程度、居住地区和生活状况各不相同。 |
| 数据源 | https://data.mendeley.com/datasets/bhmdr45bh2/2 |
| 数据引用信息 | alyasriy, hamdalla; AL-Huseiny, Muayed (2021), “The IQ-OTHNCCD lung cancer dataset”, Mendeley Data, V2, doi: 10.17632/bhmdr45bh2.2 |
- Data from 4D Lung Imaging of NSCLC Patients (4D-Lung)
| 数据类型 | 图像集 |
|---|---|
| 大小 | 347330个图片,共183GB |
| 方式 | CT、RTSTRUCT |
| 属性 | 参加人数:20;研究数量:589;系列数:6690 |
| 摘要 | 该数据集包括 20 名局部晚期非小细胞肺癌患者在放化疗期间获取的图像。这些图像包括四维 (4D) 扇形束 (4D-FBCT) 和 4D 锥形束 CT (4D-CBCT)。所有患者均接受同步放化疗,总剂量为 64.8-70 Gy,每日 1.8 或 2 Gy。4D-FBCT 图像是在 16 层螺旋 CT 扫描仪(Brilliance Big Bore,Philips Medical Systems,Andover,MA)上采集的,作为呼吸相关 CT,具有 10 个呼吸阶段(0 到 90%,基于相位的合并)和 3 mm切片厚度。 |
| 数据源 | https://wiki.cancerimagingarchive.net/pages/viewpage.action?pageId=21267414 |
| 数据引用信息 | Hugo G D, Weiss E, Sleeman W C, et al. Data from 4D lung imaging of NSCLC patients[J]. The Cancer Imaging Archive, 2016, 10: K9. |
技术方案
官方代码
R语言 for Windows或R for Linux 或 R for macOS(官方源代码)
库和依赖:
• texture.roi<- read.csv(“CT+HE features.csv”)
• library(survivalROC)
• library(survival)
• library(pROC)
• library(Hmisc)
• library(timeROC)
• library(e1071)
• library(Matrix)
• library(gplots)
自适应卷积神经网络肺癌预测代码
Pythpn语言,依赖和相关库函数:
• GPU optimized AWS EC2 instance
• Matplotlib
• Numpy
• OpenCv
• Pandas
• Pickle
• PIL
• Pydicom
• Scikit-image
• Scikit-learn
• Tensorflow
IDLE: Integrated Deep Learning Engine
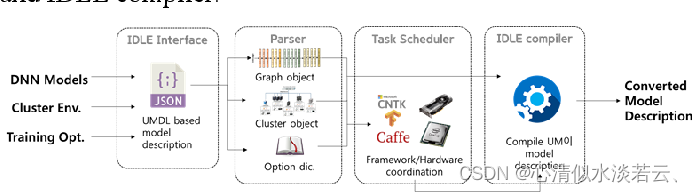
图1 IDLE中编译模型描述的总体过程
IDLE: https://ieeexplore.ieee.org/document/8650284

图2 在IDLE中算法编译的流程
IDLE建立在后端深度学习DL框架之上,是一种开发和维护DL应用程序的方便软件工具。为了提供方便、灵活的编程接口,借用一种JSON的统一模型描述语言(Unified Modeling Language, UMDL)来声明模型描述,并定义了一个层包装器,使最终用户能够从定义卷积、全连接和校正线性单元层的隐藏层级函数修改为矩阵乘法和累加等低级函数。一旦模型描述文件在UMDL中格式化,它就可以在计算节点中构建的任何后端框架上执行,而不考虑命令性或声明性接口。此外,它还使用任务调度方案协调后端框架和计算节点,同时考虑处理时间。在IDLE中编译模型描述的总体过程如上图所示。IDLE中有两个关键组件:任务调度程序和IDLE编译器。
(UMDL:https://en.wikipedia.org/wiki/Unified_Modeling_Language)
任务调度器旨在缓解异构GPU集群上执行大规模DL应用程序时的选择问题。它决定了参数服务器和工作程序,以及DL框架,以最大限度地减少总体处理时间。在调度器中,首先配置给定应用程序和GPU集群的信息,并使用启发式方法进行调度决策。它使最终用户能够有效地使用计算资源。IDLE编译器解析以UMDL格式格式化的模型描述,并将其转换为文件,以便在调度器确定的后端框架上执行。
将IDLE应用到肺癌复发中,即根据研究结合术前肺部 LDCT 图像纹理特征和切除肿瘤的组织学,使用集成深度学习评估 (IDLE) 预测肺癌进展风险的价值。其主要终点是无进展生存期,定义为从初始原发性肿瘤手术日期到肺癌复发、转移或肺癌相关死亡日期的时间,以先到者为准。死于肺癌以外的原因或存活但没有进展的患者在最后接触日期被删失。在模型中选择使用多层感知器MLP的理由是:(1)研究样本对于CNN算法开发来说不够大;(2)很难从自动创建的CNN图像特征中解码深度学习黑匣子来识别导致最终预测结果的驱动力分数。
整体架构
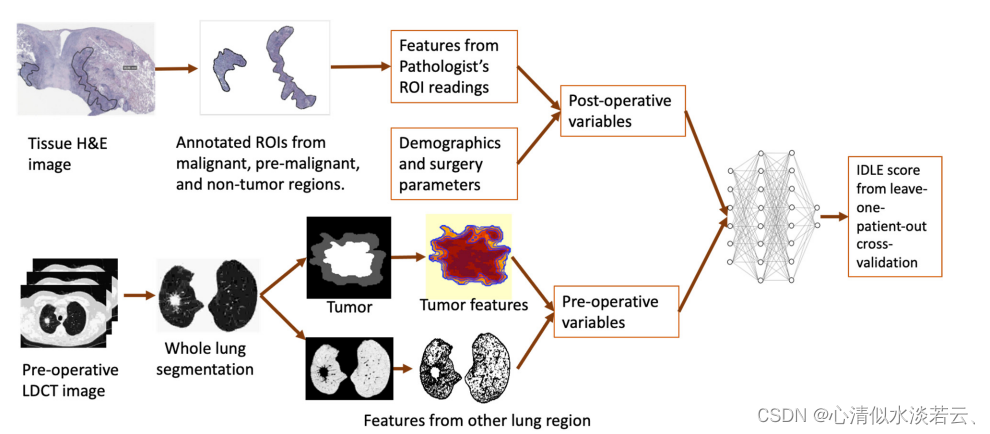 图3 学习程序
图3 学习程序
对于IDLE使用了以下输入变量,如图3所示。具体流程为:(1)手术时的患者人口统计数据,(2)手术类型(亚肺叶切除术或肺叶切除术),(3)手术后残留病灶(R0或R1),(4) 接受淋巴结切除术,(5) 手术组织相关特征(在补充表S1中列出),(6) 术前LDCT肺图像特征(在补充表 S2 中列出)在不同的肺解剖位置,以及(7) 间隔(在天)在术前 LDCT 肺筛查和手术之间。我们使用具有两个隐藏层和最后一层的 MLP,类似于我们之前的出版物 [25]。第一个隐藏层激活函数是从输入变量创建的,第二个隐藏层激活函数是从第一个隐藏层变量创建的,并具有适当的权重。带有L2惩罚参数的交叉熵损失函数用于两个隐藏层的特征选择和权重优化。最后一层使用随机生存林,输入变量和权重来自第二个隐藏层。网络的最终输出来自标准化为0和1之间的随机生存森林预测值。IDLE 分数通过留一患者交叉验证方法计算为预测风险分数。
(补充文件:https://www.mdpi.com/article/10.3390/cancers14174150/s1)
具体流程和方法
预处理:所有直径≥4mm的非钙化病变均纳入分析。手术切除的肿瘤与病理诊断有关,没有病理诊断的病变被视为不确定。为了分割肿瘤(或病变),我们首先使用3D立方体来定义其总体积,该立方体以至少1cm的边缘覆盖整个肿瘤。接下来,在应用形态学操作来定义肿瘤的表面体素之前,我们应用中值滤波器来去除图像噪声。从肿瘤和肿瘤周围体素值中减去来自相邻正常肺组织的体素强度中值,以归一化体素强度。然后,我们将300加到所有体素强度值上,使其为非负,从而使放射组学能量特征能够更有效地量化病变强度分布。
使用分割病变内的所有体素来定义其加权中心:
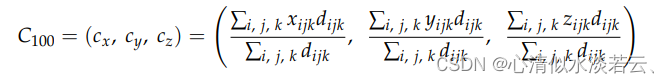
其中总和是在具有坐标 的所有肿瘤体素上,并且dijk是上公位置处的体素强度值。肿瘤体素空间分布的标准偏差通过以下公式计算:
的所有肿瘤体素上,并且dijk是上公位置处的体素强度值。肿瘤体素空间分布的标准偏差通过以下公式计算:

使用以下特征来比较分割病变(或肿瘤)内的体素与肿瘤周围区域的体素之间的强度分布:
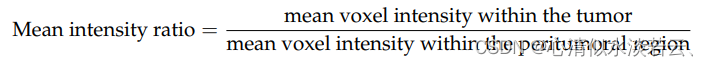
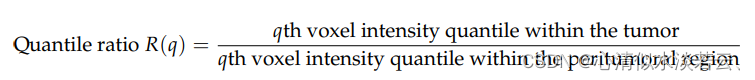
其中q分别为50和90。从每个LDCT图像中总共提取了173个特征。预测准确性评估标准包括5年和10年时间相关ROC曲线下面积(AUC)、时间相关阳性预测值(PPV)、时间相关性阴性预测值(NPV)以及高风险和低风险亚组之间无进展生存的风险比(HR)。选择最大化危险比的IDLE临界值来定义其高风险亚组。AUC的标准偏差是在500个bootstrap模拟中使用截尾加权估计量的逆概率计算的。使用贝叶斯规则计算与时间相关的PPV:

其中S(t)是t年无进展生存概率的Kaplan–Meier估计。与时间相关的净现值也进行了类似的计算。IDLE评分对TNM分期和肿瘤分级的附加值通过多变量Cox比例风险模型进行进一步评估,该模型根据手术、化疗和放疗时的年龄进行了调整。
我们采用了一种与IDLE使用的“不让一个患者参与”交叉验证方法略有不同的方法来了解深度学习黑匣子中的功能是如何使用。具体:使用相同的IDLE输入变量重新构建了IDLE网络,跟踪了输入变量在网络中的处理方式,根据在隐藏层中选择的次数对输入特征进行排名,最后使用在单变量logrank检验中最大化其风险比的阈值将这些变量分为两类,以癌症进展时间为终点。此外,重复了同样的分析,分别使用局部复发时间和远处转移时间作为终点。为了了解深度学习如何增强特征以及这些特征的集成方式,我们将输入变量与网络中的所有隐藏层特征相结合,并使用所有182名患者计算其值。使用t-检验(对于连续特征)和χ2检验(对于离散特征)来比较患有和不患有癌症进展的患者,进行单变量测试,以检查这些特征与癌症进展状态的相关性。从t检验或卡方检验中选择p值最小的前25个特征来构建热图,以可视化这些特征如何协同工作以提高预测精度。我们使用:

将这些z分数绘制在热图上。为了进一步评估术前LDCT图像特征和组织H&E图像特征之间的协同作用,我们使用完全相同的方法构建IDLE预测因子,以导出两个额外的深度学习预测因子:不使用H&E特征的LDCT特征衍生预测因子和不使用LDCT特征的H&E特征衍生预测函数。通过时间相关ROC分析将其预测精度与IDLE进行比较。
原型调制自适应卷积神经网络肺癌预测
整体流程
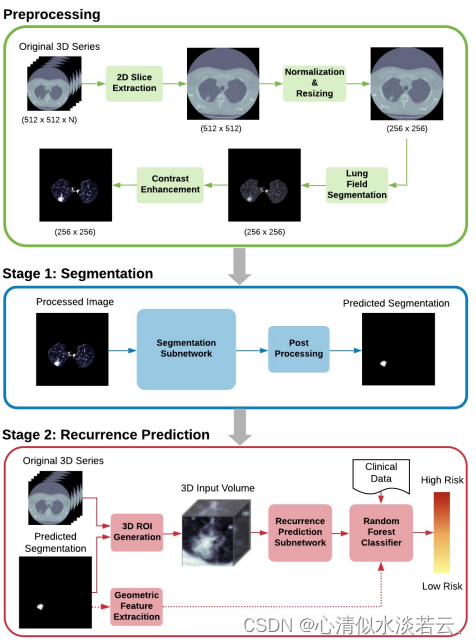
图4 提出方法的结节分割和复发预测框架
如图4整体流程。首先,对原始2D切片(包含最大肿瘤直径的切片)进行预处理,以调整图像大小并使其标准化,隔离肺野,并增加对比度。然后将其输入分割网络,在分割网络中预测肿瘤掩模并进行后处理。接下来,预测的掩模用于从原始CT序列中检索3D ROI,该3D ROI被馈送到3D CNN中用于复发预测。最后,将从预测分割中提取的CNN的输出、临床数据和肿瘤的几何特征用作随机森林分类器的特征。
分割结构
对于肺结节的分割模型,选择使用自适应U-Net。U-Net是CNN的一种变体,最近已成为许多分割任务的最新技术。改进:对原始架构进行了调整,以包含剩余连接。如图5所示。
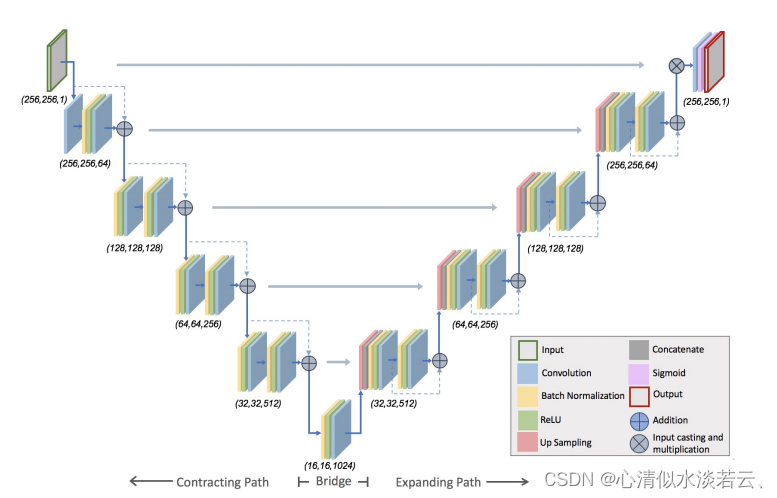
图5 用于分割的残差U-Net的体系结构
输出形状(图像x大小、图像y大小和通道数量)表示在每个单元下方。蓝色箭头表示网络的主路径,虚线箭头表示剩余连接,灰色箭头表示收缩和扩展路径的镜像单元之间的连接。图层的颜色表示不同的操作。沿着扩展路径,图像通过 (1×1) 卷积和 sigmoid激活。此激活之后是应用二元掩码以消除在肺部区域外检测到的任何误报。掩码是从网络的原始输入生成的。具体来说,由于我们的预处理程序会生成去除背景的归一化图像,因此对该图像应用天花板操作会创建肺野的二元掩膜。然后,将掩码应用于 sigmoid 的输出,从肺部区域外部移除任何错误激活的像素。
分割训练
预处理程序过后,将图像随机划分为基于患者ID的训练集、测试集和验证集。为了最大限度地增加用于训练的图像数量,所有包含结节组织的切片都包含在训练和验证集中。然而,对于测试集,仅考虑具有最大横截面肿瘤直径的图像。(在系统下一阶段的复发预测中,仅使用横截面肿瘤直径最大的切片来分割每个结节)
该模型是使用Keras 2.2.4实现的,使用tensorflow 1.14.0作为后端。由于非结节到结节像素的显著不平衡,使用加权二进制交叉熵作为损失函数:
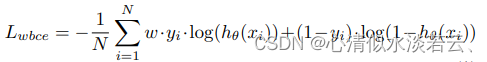
其中,N是样本数,w是给正类的权重,yi是第i个样本的真实标签,h(θ)是具有权重θ的网络,xi是第i个例的输入。我们对正类使用12.0的权重。对于我们的优化器,我们使用全局学习率为0.0001的Adam优化器
分割的后期处理。在网络的最终输出之后,进行少量的后处理。对于某些预测的分割,存在多个激活区域。这可能是由于同一图像中存在多个结节,或假阳性。为了简化向系统下一阶段的过渡(对单个结节进行复发分类)并消除潜在的假阳性,我们只选择其中一个区域在最终分割中保持激活状态。该区域将其选为激活最密集的区域。
公开项目源
项目代码开源,但是R语言编写,需要准备R语言编程环境:
项目开源地址:https://github.com/ph202203/stage-IA-NSCLC
论文链接:
Researchgate.net
MDPI
Ncbi.nlm.nih.gov
Automated Segmentation and Recurrence Risk Prediction of Surgically Resected Lung Tumors with Adaptive Convolutional Neural Networks
概述:
文章使用卷积神经网络 (CNN) 对术前计算机断层扫描 (CT) 图像中存在的肺部肿瘤进行分割和复发风险预测。首先,扩展医学图像分割的最新进展,使用残差 U-Net 来定位和表征每个结节。然后,将识别出的肿瘤传递给第二个 CNN 进行复发风险预测。该系统的最终结果由随机森林分类器生成,该分类器将第二个网络的预测与临床属性相结合。 分割阶段使用 LIDC-IDRI 数据集并获得 70.3% 的 dice 分数。 复发风险阶段使用美国国家癌症研究所的 NLST 数据集,AUC 达到 73.0%。提出的框架表明:首先,自动结节分割方法可以概括为广泛的多任务系统启用管道,其次,深度学习和图像处理有可能改进当前的预后工具。此外它还是第一个全自动分割和复发风险预测系统。
项目代码:https://github.com/maggiebasta/lung-cancer-thesis
论文pdf:https://arxiv.org/pdf/2209.08423v1.pdf
评价:此深度学习代码是第一个全自动分割和复发风险预测系统,给定肺部CT的2D轴向切片,可以返回图像中肺部区域的二进制掩码。
Multimodal fusion of imaging and genomics for lung cancer recurrence prediction
概述:
文中研究了多模态融合在这项任务中的潜力。通过结合计算机断层扫描 (CT) 图像和基因组学,展示了使用具有弹性网络正则化的线性Cox比例风险模型改进的复发预测。研究了最近包含 130 名患者的非小细胞肺癌 (NSCLC) 放射基因组学数据集,并观察到一致性指数值增加了高达 10%。 采用神经网络文献中的非线性方法,例如多层感知器和视觉问答融合模块,并没有持续提高性能。 这表明需要更好地适应这种生物环境的更大的多模式数据集和融合技术。
线性模型
-> 可以从 linear_cox.ipynb 运行
项目代码:https://github.com/svaishnavi411/multimodal-recurrence
数据集:https://wiki.cancerimagingarchive.net/display/Public/NSCLC+Radiogenomics
论文pdf:https://arxiv.org/pdf/2002.01982.pdf