El rápido desarrollo reciente de grandes modelos de lenguaje ha deslumbrado a todos. Siento que el rápido desarrollo de LLM es comparable a la explosión del Cámbrico, y la relación entre varios modelos también es confusa. Recientemente, algunos académicos compilaron un diagrama de árbol evolutivo del desarrollo de modelos de lenguaje como ChatGPT, para que todos puedan ver la relación entre los LLM de un vistazo.
Papel: https://arxiv.org/abs/2304.13712
Github (recursos relacionados): https://github.com/Mooler0410/LLMsPracticalGuide
Los diagramas de árbol evolutivo más importantes:
Diagrama de árbol de la evolución
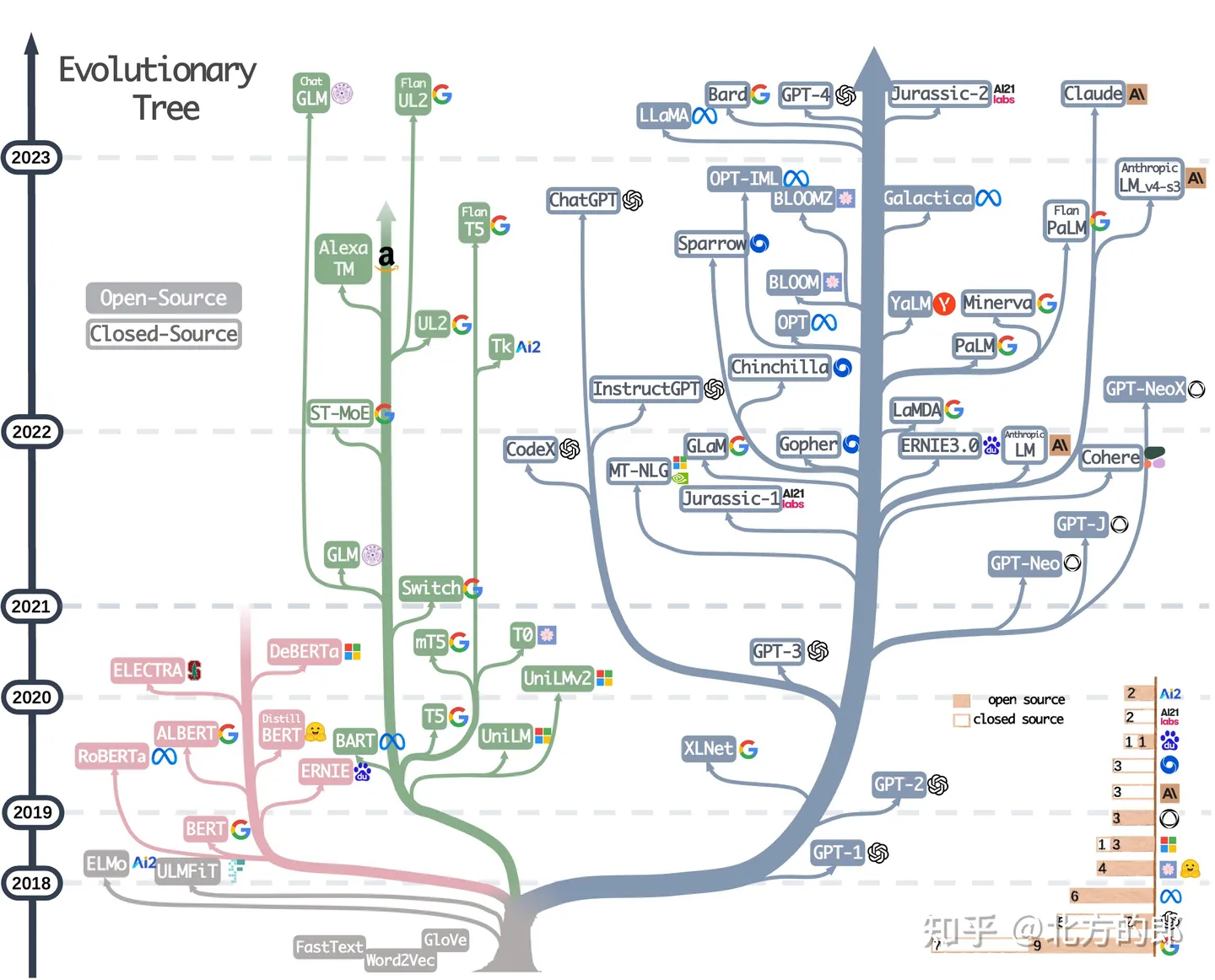
El árbol evolutivo de los modelos lingüísticos modernos rastrea el desarrollo de los modelos lingüísticos en los últimos años y destaca algunos de los modelos más famosos. Los modelos en la misma rama están más cerca. Los modelos basados en transformadores se muestran en colores que no son grises: el modelo de solo decodificador se muestra como la rama azul , el modelo de solo codificador se muestra como la rama rosa y el modelo de codificador-decodificador se muestra como la rama verde . La posición vertical del modelo en el eje del tiempo representa su fecha de lanzamiento. Los modelos de código abierto están representados por cuadrados sólidos, mientras que los modelos de código cerrado están representados por cuadrados abiertos. El gráfico de barras apiladas en la parte inferior derecha muestra la cantidad de modelos de cada empresa e institución.
Luego hay una imagen en movimiento de la evolución por año, el contenido principal es el mismo que el de la imagen de arriba.
Introducción al contenido del documento ( Aprovechando el poder de los LLM en la práctica: una encuesta sobre ChatGPT y más allá )
Dirección en papel: https://arxiv.org/abs/2304.13712

tendencia

a) Los modelos de solo decodificador dominan gradualmente el desarrollo de modelos de lenguaje. En las primeras etapas del desarrollo del modelo de lenguaje, los modelos de solo decodificador eran menos populares que los modelos de solo codificador y codificador-decodificador. Sin embargo, después de 2021, los modelos solo con decodificador experimentan un auge significativo con la introducción del revolucionario modelo de lenguaje GPT-3. Al mismo tiempo, después de la explosión inicial provocada por BERT, los modelos de solo codificador comenzaron a desvanecerse gradualmente.
b) OpenAI siempre ha mantenido una posición de liderazgo en el campo de los modelos de lenguaje, tanto en la actualidad como en el futuro. Otras empresas e instituciones están tratando de ponerse al día con OpenAI para desarrollar modelos comparables a GPT-3 y al actual GPT-4. Este liderazgo se puede atribuir a la firme adhesión de OpenAI a su línea técnica, aunque inicialmente no fue ampliamente reconocida.
c) Meta ha hecho contribuciones significativas a los modelos de lenguaje de código abierto y ha facilitado la investigación de modelos de lenguaje. Al considerar las contribuciones a la comunidad de código abierto, especialmente aquellas relacionadas con los modelos de lenguaje, Meta se destaca como una de las empresas comerciales más generosas, ya que todos los modelos de lenguaje desarrollados por Meta son de código abierto.
d) Los modelos de lenguaje muestran una tendencia hacia el código cerrado. En las primeras etapas del desarrollo del modelo de lenguaje (antes de 2020), la mayoría de los modelos son de código abierto. Sin embargo, con la introducción de GPT-3, las empresas se están inclinando cada vez más hacia el abastecimiento cerrado de sus modelos, como PaLM, LaMDA y GPT-4. Como resultado, es más difícil para los investigadores académicos experimentar con el entrenamiento del modelo de lenguaje. Por lo tanto, la investigación basada en API puede convertirse en un enfoque general en la academia.
e) Los modelos de codificador-decodificador siguen siendo prometedores, ya que tales arquitecturas todavía se exploran activamente y la mayoría son de código abierto. Google ha realizado contribuciones significativas a la arquitectura de codificador y decodificador de código abierto. Sin embargo, la flexibilidad y versatilidad del modelo de solo decodificador parece hacer menos prometedor para Google seguir en esta dirección.
En conclusión, los modelos de solo decodificador y los modelos de código abierto han dominado en los últimos años, mientras que OpenAI y Meta han realizado contribuciones significativas en la promoción de la innovación del modelo de lenguaje y el código abierto. Al mismo tiempo, los modelos de codificador-decodificador y los modelos de código cerrado también han impulsado el desarrollo hasta cierto punto. Las empresas e instituciones enfrentan diferentes perspectivas en el camino del desarrollo tecnológico.
Guía Práctica para Modelos
Una lista seleccionada (y aún en actualización activa) de recursos de guías prácticas para el LLM. Se basa en el documento de encuesta: Aprovechar el poder de LLM en la práctica: una encuesta sobre ChatGPT y más allá . Estos recursos están diseñados para ayudar a los profesionales a navegar por modelos de lenguaje extenso (LLM) y su aplicación a aplicaciones de procesamiento de lenguaje natural (NLP).
Modelo de lenguaje de estilo BERT: codificador-descodificador o solo codificador
- BERT BERT: Entrenamiento previo de transformadores bidireccionales profundos para la comprensión del lenguaje , 2018, Papel
- Roberta ALBERT: A Lite BERT for Self-supervised Learning of Language Representations , 2019, Paper
- DistilBERT DistilBERT, una versión destilada de BERT: más pequeño, más rápido, más barato y más ligero , 2019, Papel
- ALBERT ALBERT: A Lite BERT for Self-supervised Learning of Language Representations , 2019, Paper
- Preentrenamiento del modelo de lenguaje unificado UniLM para la comprensión y generación del lenguaje natural , documento de 2019
- ELECTRA ELECTRA: CODIFICADORES DE TEXTO PRE-ENTRENAMIENTO COMO DISCRIMINADORES EN LUGAR DE GENERADORES , 2020, Papel
- T5 "Explorando los límites del aprendizaje por transferencia con un transformador unificado de texto a texto" . Colin Raffel et al. JMLR 2019. Papel
- GLM "GLM-130B: un modelo preentrenado bilingüe abierto" . 2022. Papel
- AlexaTM "AlexaTM 20B: Aprendizaje de pocas tomas usando un modelo Seq2Seq multilingüe a gran escala" . Saleh Soltan et al. arXiv 2022. Papel
- ST-MoE ST-MoE: diseño de modelos expertos dispersos estables y transferibles . 2022 Papel
Modelo de lenguaje de estilo GPT: solo decodificador
- GPT Mejorando la Comprensión del Lenguaje por Pre-Entrenamiento Generativo . 2018. Papel
- Los modelos de lenguaje GPT-2 son estudiantes multitarea no supervisados . 2018. Papel
- GPT-3 "Los modelos lingüísticos son aprendices de pocas oportunidades" . NeurIPS 2020. Papel
- OPT "OPT: Modelos de lenguaje de transformadores preentrenados abiertos" . 2022. Papel
- PaLM "PaLM: modelado de lenguaje escalable con rutas" . Aakanksha Chowdhery et al. arXiv 2022. Papel
- BLOOM "BLOOM: un modelo de lenguaje multilingüe de acceso abierto con parámetros 176B" . 2022. Papel
- MT-NLG "Uso de DeepSpeed y Megatron para entrenar Megatron-Turing NLG 530B, un modelo de lenguaje generativo a gran escala" . 2021. Papel
- GLaM "GLaM: escalado eficiente de modelos de lenguaje con mezcla de expertos" . ICML 2022. Papel
- Gopher "Modelos de lenguaje escalables: métodos, análisis e información del entrenamiento de Gopher" . 2021. Papel
- chinchilla "Entrenamiento Compute-Optimal Large Language Models" . 2022. Papel
- LaMDA "LaMDA: modelos de lenguaje para aplicaciones de diálogo" . 2021. Papel
- LLaMA "LLaMA: Modelos de Lenguaje Fundamentados Abiertos y Eficientes" . 2023. Papel
- GPT-4 "Informe técnico GPT-4" . 2023. Papel
- BloombergGPT BloombergGPT: un modelo de lenguaje extenso para finanzas , 2023, papel
- GPT-NeoX-20B: "GPT-NeoX-20B: un modelo de lenguaje autorregresivo de código abierto" . 2022. Papel
Una guía práctica de datos
datos previos al entrenamiento
- RedPajama, 2023. Repo
- The Pile: An 800GB Dataset of Diverse Text for Language Modeling , Arxiv 2020. Papel
- ¿Cómo afecta el objetivo de pre-entrenamiento lo que los grandes modelos de lenguaje aprenden sobre las propiedades lingüísticas? , ACL 2022. Papel
- Leyes de escala para modelos de lenguaje neural , 2020. Papel
- Inteligencia artificial centrada en datos: una encuesta , 2023. Papel
- ¿Cómo obtiene GPT su habilidad? Seguimiento de las habilidades emergentes de los modelos de lenguaje hasta sus fuentes , 2022. Blog
datos de ajuste fino
- Evaluación comparativa de la clasificación de texto de disparo cero: Conjuntos de datos, evaluación y enfoque de vinculación , EMNLP 2019. Papel
- Language Models are Few-Shot Learners , NIPS 2020. Papel
- ¿La generación de datos sintéticos de LLM ayuda a la minería de textos clínicos? Papel Arxiv 2023
Datos de prueba/Datos de usuario
- Aprendizaje abreviado de modelos lingüísticos grandes en la comprensión del lenguaje natural: una encuesta , Arxiv 2023. Documento
- Sobre la solidez de ChatGPT: una perspectiva contradictoria y fuera de distribución Arxiv, 2023. Documento
- SuperGLUE: un punto de referencia más sólido para los sistemas de comprensión de lenguajes de propósito general Arxiv 2019. Papel
Una guía práctica para las tareas de la PNL
Los investigadores crearon un flujo de decisiones ~\protect\footnotemark para elegir un LLM o ajustar un modelo para la aplicación de NLP de un usuario. El proceso de decisión ayuda a los usuarios a evaluar si su aplicación NLP descendente en cuestión cumple con ciertos criterios y, en función de esa evaluación, decidir si un LLM o un modelo ajustado es el más adecuado para su aplicación.
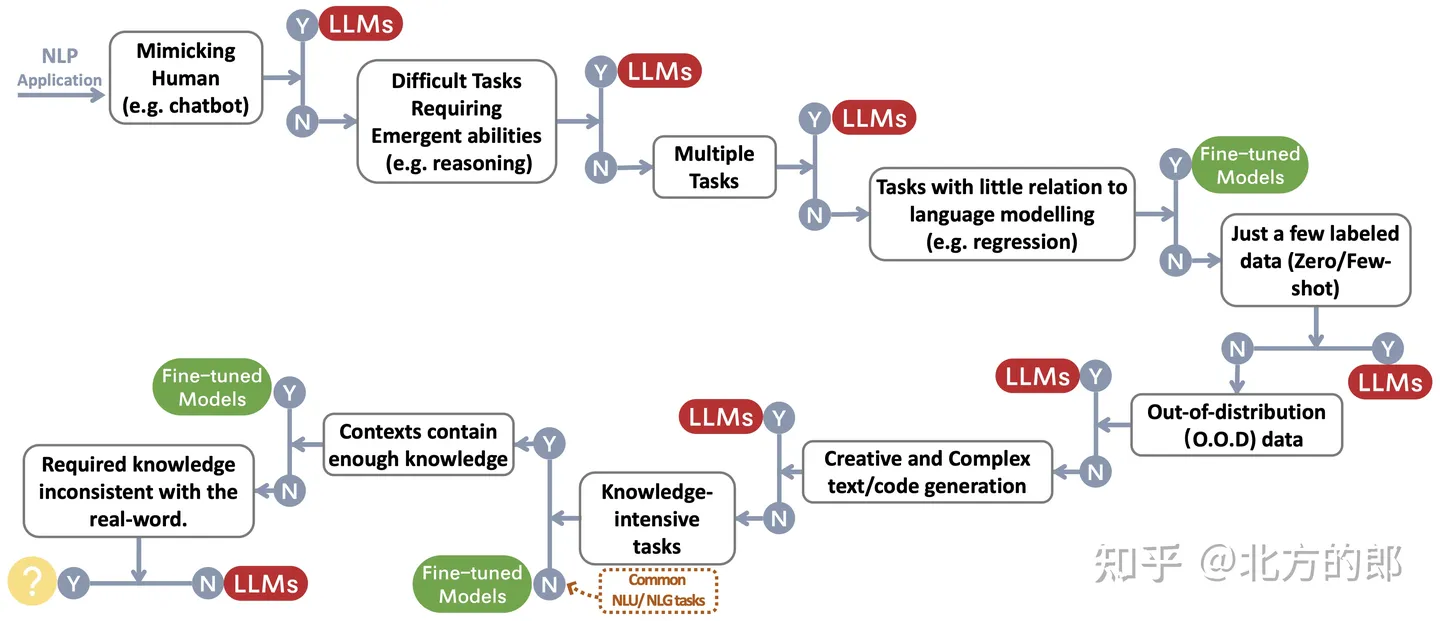
Tareas tradicionales de procesamiento no lingüístico (tareas NLU)
- Un punto de referencia para la clasificación de comentarios tóxicos en el conjunto de datos de comentarios civiles Arxiv 2023 Paper
- ¿Chatgpt es un solucionador de tareas de procesamiento de lenguaje natural de propósito general? Papel Arxiv 2023
- Evaluación comparativa de modelos de lenguaje grande para el resumen de noticias Arxiv 2022 Paper
construir tarea
- Resumen y evaluación de noticias en la era de gpt-3 Arxiv 2022 Paper
- ¿Es chatgpt un buen traductor? si con gpt-4 como motor Arxiv 2023 Paper
- Sistemas de traducción automática multilingüe de Microsoft para tareas compartidas WMT21 , WMT2021 Paper
- ¿ChatGPT también puede entender? un estudio comparativo sobre chatgpt y fine-tuned bert , Arxiv 2023, Paper
tareas intensivas en conocimiento
- Medición de la comprensión lingüística multitarea masiva , ICLR 2021 Paper
- Más allá del juego de la imitación: cuantificación y extrapolación de las capacidades de los modelos lingüísticos , Arxiv 2022 Paper
- Premio escala inversa , 2022 Link
- Atlas: aprendizaje de pocas tomas con recuperación de modelos de lenguaje aumentados , artículo de Arxiv 2022
- Los modelos de lenguaje grande codifican el conocimiento clínico , artículo de Arxiv 2022
capacidad de zoom
- Capacitación de modelos de lenguaje grande óptimos para cómputo , artículo de NeurIPS 2022
- Leyes de escala para modelos de lenguaje neuronal , artículo de Arxiv 2020
- Resolución de problemas matemáticos verbales con retroalimentación basada en procesos y resultados , documento Arxiv 2022
- La cadena de pensamiento provoca el razonamiento en grandes modelos lingüísticos , artículo de NeurIPS 2022
- Habilidades emergentes de los grandes modelos lingüísticos , Documento TMLR 2022
- La escala inversa puede convertirse en forma de U , papel Arxiv 2022
- Hacia el razonamiento en modelos de lenguaje extenso: una encuesta , artículo de Arxiv 2022
Tareas específicas
- Imagen como lengua extranjera: Preentrenamiento BEiT para todas las tareas de visión y visión-lenguaje , artículo de Arixv 2022
- PaLI: un modelo de imagen de idioma multilingüe de escala conjunta , artículo de Arxiv 2022
- AugGPT: aprovechamiento de ChatGPT para el aumento de datos de texto , artículo de Arxiv 2023
- ¿Es gpt-3 un buen anotador de datos? , Arxiv 2022 Papel
- ¿Quiere reducir el costo de etiquetado? GPT-3 puede ayudar , hallazgos de EMNLP 2021 Paper
- GPT3Mix: Aprovechamiento de modelos de lenguaje a gran escala para el aumento de texto , hallazgos de EMNLP 2021 Paper
- LLM para coincidencia de pacientes y ensayos: aumento de datos consciente de la privacidad hacia un mejor rendimiento y generalizabilidad , artículo de Arxiv 2023
- ChatGPT supera a Crowd-Workers en tareas de anotación de texto , artículo de Arxiv 2023
- G-Eval: evaluación de NLG usando GPT-4 con mejor alineación humana , artículo de Arxiv 2023
- GPTScore: Evalúe como desee , documento Arxiv 2023
- Los modelos lingüísticos grandes son evaluadores de última generación de la calidad de la traducción , artículo de Arxiv 2023
- ¿Es ChatGPT un buen evaluador de NLG? Un estudio preliminar , artículo Arxiv 2023
"Tareas" del mundo real
- Chispas de inteligencia artificial general: primeros experimentos con GPT-4 , artículo Arxiv 2023
eficiencia
1. Costo
- Modelo de lenguaje gpt-3 de Openai: una descripción técnica , 2020. Entrada de blog
- Medición de la intensidad de carbono de ia en instancias de nube , FaccT 2022. Documento
- En IA, ¿más grande siempre es mejor? , Naturaleza Artículo 2023. Artículo
- Language Models are Few-Shot Learners , NeurIPS 2020. Papel
- Precios , Open AI. Entrada en el blog
2. Retraso
- HELM: Evaluación holística de modelos de lenguaje , Arxiv 2022. Papel
3. Ajuste eficiente de los parámetros
- LoRA: Adaptación de bajo rango de modelos de lenguaje grande , Arxiv 2021. Papel
- Ajuste de prefijo: optimización de avisos continuos para generación , ACL 2021. Documento
- P-Tuning: Prompt Tuning puede ser comparable a Fine-tuning a través de escalas y tareas , ACL 2022. Documento
- P-Tuning v2: El ajuste rápido puede compararse con el ajuste fino universalmente en todas las escalas y tareas , Arxiv 2022. Papel
4. Sistema de pre-entrenamiento
- ZeRO: Optimizaciones de memoria para entrenar trillones de modelos de parámetros , Arxiv 2019. Papel
- Megatron-LM: Entrenamiento de modelos de lenguaje de parámetros multimillonarios mediante el paralelismo de modelos , Arxiv 2019. Papel
- Capacitación eficiente de modelos de lenguaje a gran escala en clústeres de GPU con Megatron-LM , Arxiv 2021. Papel
- Reducción del recálculo de activación en modelos de transformadores grandes , Arxiv 2021. Papel
Crédito
- Robustez y Calibración
- Calibrar antes de usar: mejorar el rendimiento de pocos disparos de los modelos de lenguaje , ICML 2021. Documento
- SPeC: una calibración suave basada en indicaciones para mitigar la variabilidad del rendimiento en el resumen de notas clínicas , Arxiv 2023. Papel
2. Sesgos espurios
- Aprendizaje abreviado de modelos lingüísticos grandes en la comprensión del lenguaje natural: una encuesta , artículo de 2023
- Mitigar el sesgo de género en el sistema de subtítulos , WWW 2020 Paper
- Calibrar antes de usar: mejorar el rendimiento de pocos disparos de los modelos de lenguaje , documento ICML 2021
- Aprendizaje de accesos directos en redes neuronales profundas , artículo de Nature Machine Intelligence 2020
- ¿Los modelos basados en mensajes realmente entienden el significado de sus mensajes? , Papel NAACL 2022
3. Problemas de seguridad
- Tarjeta del sistema GPT-4 , papel 2023
- La ciencia de detectar textos generados por películas , Arxiv 2023 Paper
- Cómo se comparten los estereotipos a través del lenguaje: una revisión e introducción del marco de comunicación de categorías sociales y estereotipos (scsc) , Revisión de la investigación en comunicación, Documento de 2019
- Tonos de género: disparidades de precisión interseccional en la clasificación de género comercial , documento FaccT 2018
Ajuste de instrucciones de referencia
- FLAN: Los modelos de lenguaje perfeccionados son estudiantes de tiro cero , artículo de Arxiv 2021
- T0: La capacitación impulsada por tareas múltiples permite la generalización de tareas de disparo cero , artículo de Arxiv 2021
- Generalización de tareas cruzadas a través de instrucciones de crowdsourcing en lenguaje natural , Documento ACL 2022
- Tk-INSTRUCT: Super-NaturalInstructions: Generalización a través de instrucciones declarativas en más de 1600 tareas de NLP , EMNLP 2022 Paper
- FLAN-T5/PaLM: instrucción de escalado: modelos de lenguaje ajustados , papel Arxiv 2022
- The Flan Collection: Diseño de datos y métodos para el ajuste efectivo de la instrucción , artículo de Arxiv 2023
- OPT-IML: Metaaprendizaje de la instrucción del modelo de lenguaje a escala a través de la lente de la generalización , artículo de Arxiv 2023
Alineación
- Aprendizaje por refuerzo profundo a partir de las preferencias humanas , artículo de NIPS 2017
- Aprender a resumir a partir de la retroalimentación humana , Arxiv 2020 Paper
- Un asistente lingüístico general como laboratorio para la alineación , artículo Arxiv 2021
- Capacitación de un asistente útil e inofensivo con el aprendizaje por refuerzo a partir de la retroalimentación humana , artículo de Arxiv 2022
- Enseñanza de modelos lingüísticos para respaldar respuestas con comillas verificadas , artículo Arxiv 2022
- InstructGPT: Entrenamiento de modelos de lenguaje para seguir instrucciones con retroalimentación humana , Arxiv 2022 Paper
- Mejorando la alineación de los agentes de diálogo a través de juicios humanos específicos , Arxiv 2022 Paper
- Leyes de escala para la sobreoptimización del modelo de recompensa , documento de Arxiv 2022
- Supervisión escalable: Medición del progreso en la supervisión escalable para modelos de lenguaje grandes , artículo de Arxiv 2022
Calibración segura (inofensiva)
- Red Teaming Language Models with Language Models , Arxiv 2022 Paper
- Inteligencia artificial constitucional: inofensividad a partir de la retroalimentación de inteligencia artificial , documento Arxiv 2022
- La capacidad de autocorrección moral en grandes modelos lingüísticos , artículo Arxiv 2023
- OpenAI: Nuestro enfoque de la seguridad de la IA , 2023 Blog
Autenticidad Coherencia (Honestidad)
- Aprendizaje por refuerzo para modelos de lenguaje , 2023 Blog
Consejos Guía Práctica (Útil)
- Libro de cocina de OpenAI . Blog
- Ingeniería rápida . Blog
- ¡Ingeniería rápida de ChatGPT para desarrolladores! Curso
El trabajo de la comunidad de código abierto
- Autoinstrucción: alineación del modelo de lenguaje con instrucciones autogeneradas , artículo de Arxiv 2022
- alpaca _ Repo
- Vicuña . Repo
- muñequita _ Blog
- DeepSpeed-Chat . Blog
- GPT4Todos . Repo
- Asistente Abierto . Repo
- ChatGLM . Repo
- MUSGO . Repo
- Laminados . Informe / Blog
Amigos que se sientan útiles, bienvenidos a estar de acuerdo, seguir y compartir Sanlian. ^-^