LSTM (memoria a largo plazo a corto plazo) red de memoria a largo plazo a corto plazo, la teoría específica no se describirá una por una, solo comience directamente
proceso
-
- 1. Importación de datos
- 2. Normalización de datos
- 3. Divida el conjunto de entrenamiento y el conjunto de prueba
- 4. Divide etiquetas y atributos
- 5. Convertir al formato de entrada LSTM
- 6. Diseño del modelo LSTM
- 7. Pruebas y visualización gráfica
- 8. Guarde el modelo en el archivo pkl
- 9. Modelo de llamada
1. Importación de datos
- Los pandas normales leen los datos y convierten la columna de tiempo en un índice (vea otros tutoriales para hacer esto, se siente inútil, solo siga el orden cronológico)
# 获取数据
import pandas as pd
from datetime import datetime
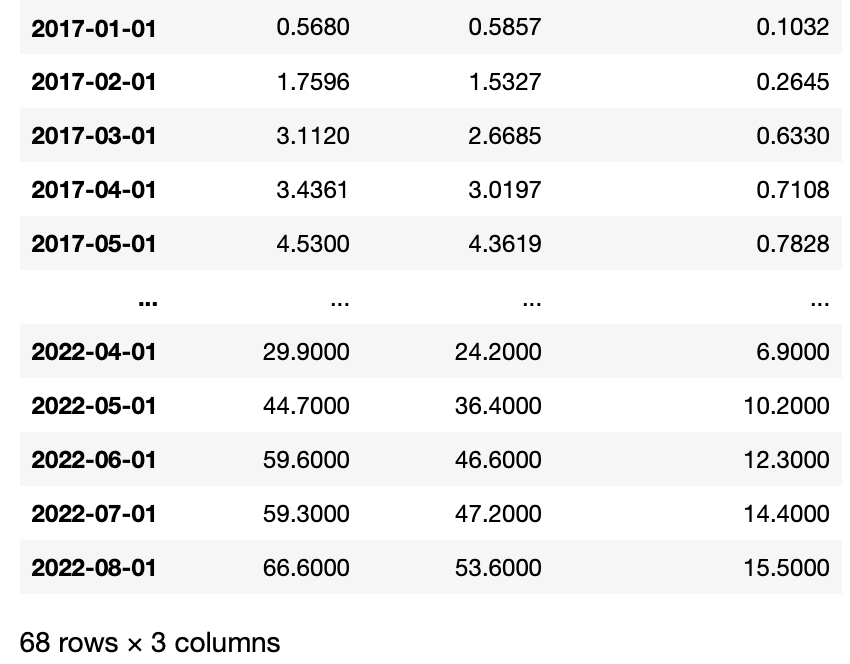
dataset = pd.read_csv('../data.csv', index_col='时间', usecols=[0,2,3,5], date_parser=lambda x:datetime.strptime(x, '%Y年%m月'))
dataset
2. Normalización de datos
- Reduzca los datos al rango de 0 a 1. Aquí agrupo todos los datos en una columna, de modo que el rango de reducción sea el mismo. Puede usar esto para convertir directamente más tarde
# 数据归一化
from sklearn.preprocessing import MinMaxScaler
values = dataset.values
# 转换成一列
values_res = values.reshape(values.shape[0] * values.shape[1], 1)
scaler = MinMaxScaler(feature_range=(0, 1))
# 训练 scaler
scaled = scaler.fit_transform(values_res)
# 再转换成原来的样子
scaled_dataset = scaled.reshape(values.shape)
scaled_dataset

3. Divida el conjunto de entrenamiento y el conjunto de prueba
- Los datos deben estar en orden cronológico, así que aquí cortamos un 20 % antes y después
# 切分训练集和测试集
split = round(len(scaled_dataset)*0.20)
train = scaled_dataset[:-split]
test = scaled_dataset[-split:]
test

4. Divide etiquetas y atributos
- La primera columna de datos son datos de etiquetas, y la segunda y tercera columnas son datos de condiciones de atributos.
# 划分标签和属性
train_x, train_y = train[:, 1:], train[:, 0]
test_x, test_y = test[:, 1:], test[:, 0]
test_x

5. Convertir al formato de entrada LSTM
- Convertir al formato de entrada del modelo LSTM (muestras, intervalos de tiempo, características)
train_x_input = train_x.reshape((train_x.shape[0], 1, train_x.shape[1]))
test_x_input = test_x.reshape((test_x.shape[0], 1, test_x.shape[1]))
test_x_input

6. Diseño del modelo LSTM
- Hay dos formas de diseñar un modelo LSTM. La primera es saber cuáles son los mejores parámetros y la segunda es ingresar algunos parámetros más y luego encontrar los mejores parámetros.
6.1 Modelado Directo
# 设计 LSTM 模型
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(50, input_shape=(1, 2)))
model.add(Dense(1))
model.compile(loss="mae", optimizer="adam")
model.fit(train_x_input, train_y, epochs=10, batch_size=1, validation_data=(test_x_input, test_y), verbose=2, shuffle=False)
6.2 Encuentra lo mejor
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import GridSearchCV
def build_model(optimizer):
grid_model = Sequential()
grid_model.add(LSTM(50,return_sequences=True,input_shape=(1,2)))
grid_model.add(LSTM(50))
grid_model.add(Dropout(0.2))
grid_model.add(Dense(1))
grid_model.compile(loss = 'mse',optimizer = optimizer)
return grid_model
grid_model = KerasRegressor(build_fn=build_model,verbose=1,validation_data=(test_x_input,test_y))
# 把各种可能的参数都丢上去
parameters = {
'batch_size' : [1],
'epochs' : [10,11],
'optimizer' : ['adam', 'rmsprop'] }
grid_search = GridSearchCV(estimator = grid_model,
param_grid = parameters,
cv = 2)
# 训练
grid_search = grid_search.fit(train_x_input, train_y)
# 最好的参数
print(grid_search.best_params_)
# 最好参数对应的模型
model = grid_search.best_estimator_.model
7. Pruebas y visualización gráfica
from matplotlib import pyplot as plt
from sklearn.metrics import mean_squared_error
import math
# 测试
pred = model.predict(test_x_input)
# 获取原始值
real = scaler.inverse_transform(test_y.reshape(1, -1)).reshape(-1, 1)
predicted = scaler.inverse_transform(pred)
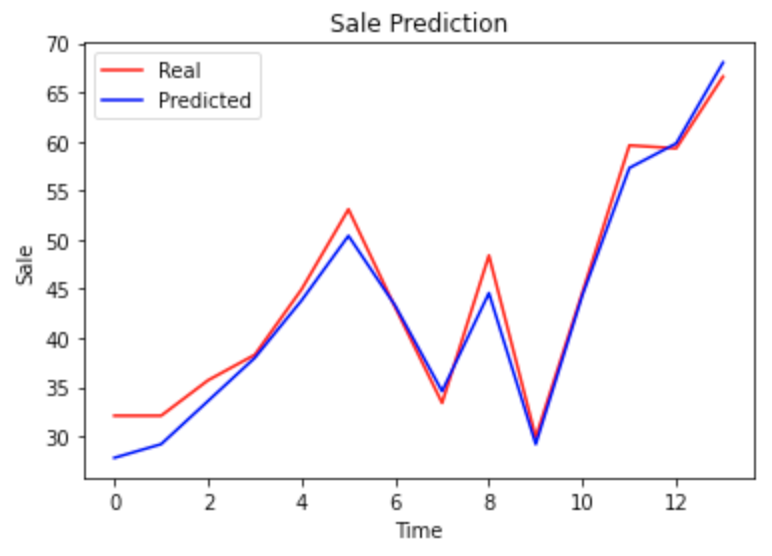
plt.plot(real, color = 'red', label = 'Real')
plt.plot(predicted, color = 'blue', label = 'Predicted')
plt.title('Sale Prediction')
plt.xlabel('Time')
plt.ylabel('Sale')
plt.legend()
plt.show()
rmse = math.sqrt(mean_squared_error(real, predicted))
print("均方根误差:" + str(rmse))
Error cuadrático medio de la raíz: 2.1375958318221455
8. Guarde el modelo en el archivo pkl
# 保存模型
import dill
with open('./sale_predict_model.pkl', 'wb') as outfile:
dill.dump({
'scaler': scaler,
'model': model
}, outfile)
9. Modelo de llamada
- Si el modelo debe implementarse en línea para la invocación, puede escribir directamente un script para la invocación. Al mismo tiempo, teniendo en cuenta que el modelo debe leerse una vez para cada invocación, lo que desperdicia rendimiento, los parámetros se pasan directamente en forma de enchufes, y un servicio residente se forma en el fondo.
- Formato de entrada fijo de socket "a, b"
9.1 Llamador del modelo de Python
import socket
import threading
import numpy as np
import pickle
# Socket 操作
sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sk.bind(('127.0.0.1', 10001))
sk.listen(5)
count = 0
# 读取模型
file = 'sale_predict_model.pkl'
with open(file, 'rb') as f:
model = pickle.load(f)
# 模型预测
def predict(a, b):
data = np.array([[a, b]])
# 转换格式,使用的是模型训练时训练出来的编译器
data_scaled = model['scaler'].transform(data.reshape(data.shape[0] * data.shape[1], 1)).reshape(data.shape)
# 直接导入模型,一样要进行转换格式
data_res = model['model'].predict(data_scaled.reshape((data_scaled.shape[0], 1, data_scaled.shape[1])))
# 返回最终结果
return model['scaler'].inverse_transform(data_res)[0][0]
# 处理 Socket 连接
def tcp(sock, addr):
try:
print('Accept new connection from %s:%s...' % addr)
print('Request count: %d' % count)
# 读取参数
data = sock.recv(1024)
# 解码参数
data_str = data.decode('utf-8')
print("Param: %s" % data_str)
# 切割参数
data_list = data_str.split(',')
# 判断参数合法性
if len(data_list) == 2:
# 合法参数调用模型并返回数据
sock.send(str(predict(data_list[0], data_list[1])).encode('utf-8'))
print("Invoke success")
else:
sock.send(('Error param: %s' % data_str).encode('utf-8'))
print('Error param: %s' % data_str)
except Exception as e:
print('Except:', e)
sock.send('Invoke error'.encode('utf-8'))
finally:
sock.close()
if __name__ == '__main__':
while True:
# 监听连接
data, addr = sk.accept()
count += 1
# 交给线程处理
thread = threading.Thread(target=tcp, args=(data, addr))
# 启动线程
thread.start()
9.2 Llamador de programa Java
package org.example.service;
import java.io.IOException;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
public class InvokeModel {
// service 测试
public static void main(String[] args){
System.out.println(invoke(54.4, 14.4));
}
// service 调用方法
public static String invoke(Double sale1, Double sale2) {
// 拼装参数
String req = sale1 + "," + sale2;
Socket socket = null;
try {
// 创建 Socket
socket = new Socket("127.0.0.1", 10001);
// 传输数据
socket.getOutputStream().write(req.getBytes(StandardCharsets.UTF_8));
System.out.println("Request param: " + req);
byte[] buf = new byte[256];
// 读取返回的数据
int len = socket.getInputStream().read(buf);
// 返回最终的结果(是一个 Double,方便操作直接用 String)
return new String(buf, 0, len);
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
try {
if (socket != null)
socket.close();
} catch (IOException e) {
System.err.println("Invoke model error");
}
}
}
}